初见scikit-learn之基础教程
初见scikit-learn之基础教程
- scikit-learn 基础教程
- 1. scikit-learn 简介
- 1.1 什么是 scikit-learn?
- 1.2 scikit-learn 的主要功能
- 2. 安装 scikit-learn
- 2.1 安装方法
- 2.2 验证安装
- 3. scikit-learn 基本使用
- 3.1 数据加载与预处理
- 3.1.1 加载数据集
- 3.1.2 数据拆分
- 3.1.3 数据标准化
- 3.2 分类模型
- 3.2.1 逻辑回归
- 3.2.2 决策树
- 3.3 回归模型
- 3.3.1 线性回归
- 3.4 聚类模型
- 3.4.1 K-Means 聚类
- 3.5 降维
- 3.5.1 主成分分析(PCA)
- 3.6 模型选择与评估
- 3.6.1 交叉验证
- 3.6.2 网格搜索
- 4. 实战案例
- 4.1 房价预测
- 4.1.1 数据准备
- 4.1.2 数据预处理
- 4.1.3 模型训练与评估
- 4.2 客户细分
- 4.2.1 数据准备
- 4.2.2 K-Means 聚类
- 4.2.3 可视化
- 5. 总结
scikit-learn 基础教程
scikit-learn 是一个广泛使用的 Python 机器学习库,提供了简单而高效的工具来进行数据挖掘和数据分析。它涵盖了数据预处理、特征选择、模型训练和评估等多个方面。本文将详细介绍 scikit-learn 的基础知识,包括基本概念、常用模块和功能、以及实际应用示例。
1. scikit-learn 简介
1.1 什么是 scikit-learn?
scikit-learn 是一个开源的 Python 库,用于机器学习和数据挖掘。它提供了一系列简单而高效的工具来处理数据预处理、特征选择、模型训练和评估等任务。scikit-learn 构建于 NumPy、SciPy 和 matplotlib 之上,并且符合 SciPy 生态系统的设计原则。
1.2 scikit-learn 的主要功能
- 分类:用于将数据分为不同的类别(例如,垃圾邮件分类)。
- 回归:预测连续的数值(例如,房价预测)。
- 聚类:将数据分组为不同的簇(例如,客户细分)。
- 降维:减少数据的维度(例如,PCA)。
- 模型选择:选择和评估模型(例如,交叉验证)。
- 数据预处理:数据清理和特征工程(例如,标准化、归一化)。
2. 安装 scikit-learn
2.1 安装方法
可以使用 pip 来安装 scikit-learn:
pip install scikit-learn
或者,使用 conda 安装:
conda install scikit-learn
2.2 验证安装
安装完成后,可以通过以下代码验证 scikit-learn 是否安装成功:
import sklearn
print(sklearn.__version__)
3. scikit-learn 基本使用
3.1 数据加载与预处理
3.1.1 加载数据集
scikit-learn 提供了一些内置的数据集,例如鸢尾花数据集(Iris Dataset):
from sklearn.datasets import load_iris# 加载鸢尾花数据集
data = load_iris()
X = data.data
y = data.target
3.1.2 数据拆分
将数据集拆分为训练集和测试集:
from sklearn.model_selection import train_test_split# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
3.1.3 数据标准化
标准化数据,使其均值为 0,方差为 1:
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
3.2 分类模型
3.2.1 逻辑回归
逻辑回归是一种线性分类算法:
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 创建逻辑回归模型
model = LogisticRegression()
model.fit(X_train_scaled, y_train)# 预测
y_pred = model.predict(X_test_scaled)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
3.2.2 决策树
决策树是一种基于树结构的分类方法:
from sklearn.tree import DecisionTreeClassifier# 创建决策树模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
3.3 回归模型
3.3.1 线性回归
线性回归用于预测连续变量:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 创建线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.2f}')
3.4 聚类模型
3.4.1 K-Means 聚类
K-Means 是一种常用的聚类算法:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt# 创建 K-Means 模型
model = KMeans(n_clusters=3, random_state=42)
model.fit(X)# 获取聚类结果
labels = model.predict(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('K-Means Clustering')
plt.show()
3.5 降维
3.5.1 主成分分析(PCA)
PCA 用于减少数据维度:
from sklearn.decomposition import PCA# 创建 PCA 模型
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)# 可视化降维后的数据
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.show()
3.6 模型选择与评估
3.6.1 交叉验证
交叉验证用于评估模型的性能:
from sklearn.model_selection import cross_val_score# 创建模型
model = LogisticRegression()# 进行交叉验证
scores = cross_val_score(model, X, y, cv=5)print(f'Cross-Validation Scores: {scores}')
print(f'Mean Score: {scores.mean():.2f}')
3.6.2 网格搜索
网格搜索用于调整模型的超参数:
from sklearn.model_selection import GridSearchCV# 创建模型
model = LogisticRegression()# 定义参数范围
param_grid = {'C': [0.1, 1, 10],'penalty': ['l1', 'l2']
}# 创建网格搜索
grid_search = GridSearchCV(model, param_grid, cv=5)# 训练网格搜索
grid_search.fit(X_train_scaled, y_train)# 输出最佳参数
print(f'Best Parameters: {grid_search.best_params_}')
print(f'Best Score: {grid_search.best_score_:.2f}')
4. 实战案例
4.1 房价预测
4.1.1 数据准备
假设我们有一个房价数据集,包含房屋的各种特征和价格:
import pandas as pd# 读取数据集
data = pd.read_csv('house_prices.csv')# 特征选择和标签
X = data[['num_rooms', 'size', 'location']]
y = data['price']
4.1.2 数据预处理
对数据进行预处理和标准化:
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split# 数据拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 标准化数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
4.1.3 模型训练与评估
使用线性回归模型进行训练和评估:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 创建模型
model = LinearRegression()
model.fit(X_train_scaled, y_train)# 预测
y_pred = model.predict(X_test_scaled)# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.2f}')
4.2 客户细分
4.2.1 数据准备
假设我们有一个客户数据集,包含客户的特征信息:
# 读取数据集
data = pd.read_csv('customer_data.csv')# 特征选择
X = data[['age', 'income', 'spending_score']]
4.2.2 K-Means 聚类
使用 K-Means 聚类进行客户细分:
from sklearn.cluster import KMeans# 创建 K-Means 模型
model = KMeans(n_clusters=4, random_state=42)
model.fit(X)# 获取聚类结果
labels = model.predict(X)# 添加聚类标签到数据中
data['cluster'] = labels
4.2.3 可视化
可视化客户聚类结果:
import matplotlib.pyplot as plt# 可视化聚类结果
plt.scatter(data['age'], data['income'], c=labels, cmap='viridis')
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Customer Clustering')
plt.show()
5. 总结
scikit-learn 是一个功能强大的机器学习库,提供了丰富的工具和功能来处理各种数据分析任务。这里我嫩介绍了 scikit-learn 的基础知识,包括数据加载与预处理、分类与回归模型、聚类与降维技术、模型选择与评估等内容。scikit-learn 官方文档
相关文章:

初见scikit-learn之基础教程
初见scikit-learn之基础教程 scikit-learn 基础教程 1. scikit-learn 简介1.1 什么是 scikit-learn?1.2 scikit-learn 的主要功能 2. 安装 scikit-learn2.1 安装方法2.2 验证安装 3. scikit-learn 基本使用3.1 数据加载与预处理3.1.1 加载数据集3.1.2 数据拆分3.1.3…...

基于STM32的嵌入式深度学习系统教程
目录 引言环境准备嵌入式深度学习系统基础代码实现:实现嵌入式深度学习系统 数据采集与预处理深度学习模型训练与优化模型部署与推理实时数据处理与反馈应用场景:智能物联网设备常见问题与解决方案收尾与总结 引言 随着深度学习在各种应用中的广泛采用…...

hive udf去掉map中的一个或者多个key
实现一个hive udf,可以将Map中的某一个或者多个key去掉,这里要继承GenericUDF 这个抽象类,然后Override evaluate这个函数即可,可以把执行这个udf前初始化的一些内容放在initialize方法内,比如参数的判断,函数的返回值类型等等。 代码写好之后,可以用如下方法创建这个函…...
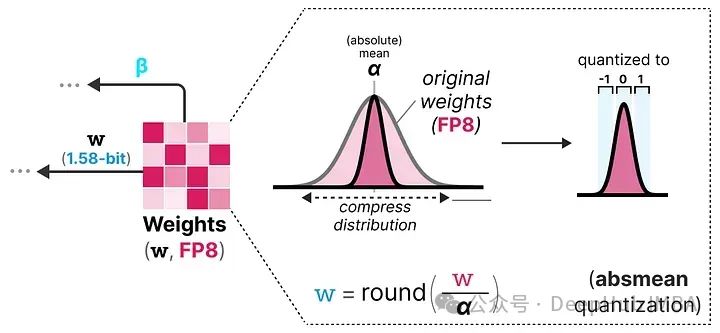
模型量化技术综述:揭示大型语言模型压缩的前沿技术
大型语言模型(LLMs)通常因为体积过大而无法在消费级硬件上运行。这些模型可能包含数十亿个参数,通常需要配备大量显存的GPU来加速推理过程。 因此越来越多的研究致力于通过改进训练、使用适配器等方法来缩小这些模型的体积。在这一领域中&am…...

一文掌握Prompt:万能框架+优化技巧+常用指标
👉目录 1 写在前面 2 Prompt 万能框架 3 框架的细化 4 在框架上增加更多信息(RAG) 5 让大模型更好的思考(CoT) 6 附加技巧 7 优化方式及常用指标 8 写在最后 随着大模型在2023年横空出世,“Prompt 工程” 应…...

Vue 常用组件间通信方式
Vue 常用组件间通信方式 1. 父子组件通信 1.1 Props 父组件通过 props 向子组件传递数据,子组件通过 props 接收数据。 <!-- ParentComponent.vue --> <template><ChildComponent :message"parentMessage"></ChildComponent>…...
NineData云原生智能数据管理平台新功能发布|2024年7月版
本月发布 12 项更新,其中性能优化 3 项、功能优化 8 项、安全性发布 1 项。 1. 性能优化 数据复制 - SQL Server 增量性能优化 调整读取和写入方式,让 SQL Server 增量复制的性能轻松达到 5000 RPS 以上。 数据复制 - Doris|SelectDB|StarRocks 性能优…...

验收测试:确保软件符合业务需求和合同要求
目录 前言1. 验收测试的概念1.1 用户验收测试(UAT)1.2 操作验收测试(OAT) 2. 验收测试的主要作用2.1 确认业务需求的满足2.2 验证合同要求的实现2.3 提升用户信心 3. 验收测试在整个测试中的地位3.1 测试的最后一道关卡3.2 用户与…...
+QPieSeries(饼图))
Qt | QChartView+QDateTimeAxis(日期和时间数据图表)+QPieSeries(饼图)
点击上方"蓝字"关注我们 01、QDateTimeAxis QDateTimeAxis 是 Qt 中用于图表的轴类,它专门用于处理日期和时间数据。这个类允许你在图表上显示和解释与日期和时间相关的数据点。例如,在 Qt 的图表库中,你可以使用 QDateTimeAxis 来创建一个时间序列图表,展示股票…...

用闲置的阿里云服务器使用 NPS 实现内网穿透
最近有个项目需要给外地的同事预览一下,但是公司没有可以公网访问的测试服务器,所以想到用内网穿透的方式让外地同事可以访问到我的本机。刚好我有一台阿里云的服务器,双十一打折买了3年,1000左右,2核8G,买…...

一款免费开源绿色免安装的透明锁屏工具
一款免费开源绿色免安装的透明锁屏工具 这个工具的特点就是电脑锁屏的时候,仍然显示原桌面,但是无法操作,需要输入密码才可以解锁。输入密码界面也是隐藏的需要按键才能显示输入密码框。 电脑★★★★★透明锁屏工具:https://pa…...

程序员保持健康的 10 个技巧
长时间坐在电脑前,整天甚至通宵编程、处理 bug 和面对 dealine 的压力。作为一名软件工程师绝对不是一个非常健康的职业。 我经常去欧洲和美国会见许多开发人员。我经常注意到的是:许多开发人员把自己当成机器。他们已经完全放弃了感受身体的感觉&#…...

Java并发迷宫:同步的魔法与死锁的诅咒
在Java编程的宇宙中,有一个充满神秘与挑战的维度——并发编程。它如同一座错综复杂的迷宫,每个角落都潜藏着惊喜与陷阱。在这篇博客里,我们将一起探索这座迷宫的深处,揭开同步的魔法与死锁的诅咒。 第一章:同步魔法的…...

CoderGuide
CoderGuide是一个针对同学们前后端求职面试的开源项目,作为一名互联网/IT从业人员,经常需要搜索一些书籍、面试题等资源,在这个过程中踩过很多坑、浪费过很多时间。欢迎大家 Watch、Star,供各位同学免费使用,永不收费&…...

链式二叉树
链式二叉树,也称为二叉链表,是数据结构中一种非常重要的树形结构表示方法。在链式二叉树中,每个节点不仅包含数据域,还包含两个指针域,分别指向其左子节点和右子节点。这种结构允许二叉树动态地增长和缩减,…...

PHP高校迎新系统-计算机毕业设计源码08468
摘要 随着高校规模的不断扩大和新生人数的增加,传统的手工登记和管理方式已经无法满足高效、准确的需求。为了提升大学新生入学迎新工作的效率和质量,本研究设计开发了一套高校迎新系统。系统通过信息技术的应用,集成了首页、交流论坛、通知公…...

泛微开发修炼之旅--41Ecology基于触发器实现增量数据同步(人员、部门、岗位、人员关系表、人岗关系表)
一、需求背景 我们在项目上遇到一个需求,需要将组织机构数据(包含人员信息、部门信息、分部信息、人岗关系)生成的增量数据,实时同步到三方的系统中,三方要求,只需要增量数据即可。 那么基于ecology系统&a…...

FVM安装及配置
一、下载fvm 包 git:Release fvm 3.1.7 leoafarias/fvm GitHub 解压到本地文件夹,然后添加环境变量 管理员模式打开cmd,查看是否成功 fvm --version 二、安装Dart SDK 下载Dart SDK:Dart for Windows 三、安装GIT 四、指定…...

[Git][认识Git]详细讲解
目录 1.什么是仓库?2.认识工作区、暂存区、版本库3.认识 .git1.index2.HEAD && master3.objects4.总结 1.什么是仓库? 仓库:进⾏版本控制的⼀个⽂件⽬录 2.认识工作区、暂存区、版本库 工作区:在电脑上写代码或⽂件的⽬录…...

Win11系统Docker部署Blazor程序
1. 开发环境 Windows 11 家庭版,默认支持WSL2 2. Docker安装 安装Docker Desktop需要启用Win11的Linux子系统和虚拟机。以管理员身份运行命令行程序,执行如下命令: 启用适用于 Linux 的 Windows 子系统 dism.exe /online /enable-featur…...

第 22 篇 系列收官:进阶路线与就业面试指南
目录 一、第一优先级:深入 Linux 内核核心原理 二、第二优先级:行业垂直领域深入 三、第三优先级:安卓系统深度定制与开发 四、第四优先级:硬件与原理图设计 五、第五优先级:RTOS 实时操作系统 大家好,我是黒漂技术佬。从第一篇的安卓驱动核心架构,到今天的收官篇,…...
的伪效率问题)
如何看待AI Agent(智能体)的伪效率问题
对 **AI Agent 的“伪效率提升”**(或者说很多场景下的假性/虚幻生产力增长)有几个比较清晰的观察角度,目前(2026年3月)整个行业其实已经开始从“狂热宣传期”进入“冷静复盘期”,很多早期吹得天花乱坠的效…...

金仓数据库SQL防火墙构建主动防御,让恶意SQL无处遁形
开发留的坑,数据库来填!金仓数据库SQL防火墙,精准拦截99.99%的恶意SQL在数字化转型的浪潮中,数据已成为企业的核心资产。然而,SQL注入攻击如同潜伏在阴影中的“不速之客”,时刻威胁着数据库的安全。即使开发…...

如何实现多语言编程书籍:milewski-ctfp-pdf项目的国际化实践指南
如何实现多语言编程书籍:milewski-ctfp-pdf项目的国际化实践指南 【免费下载链接】milewski-ctfp-pdf Bartosz Milewskis Category Theory for Programmers unofficial PDF and LaTeX source 项目地址: https://gitcode.com/gh_mirrors/mi/milewski-ctfp-pdf …...

Clang工具链深度探索:超越C/C++编译的10大实用功能
Clang工具链深度探索:超越C/C编译的10大实用功能 【免费下载链接】llvm-project llvm-project - LLVM 项目是一个编译器和工具链技术的集合,用于构建中间表示(IR)、优化程序代码以及生成机器代码。 项目地址: https://gitcode.com/GitHub_Trending/ll/…...

泰思特电子分享_EMC测试电流探头选型差异性及影响因素探讨
本文主要进行EMC测试电流探头选型差异性及影响因素探讨,围绕电流探头核心技术指标进行介绍,根据EMC测试不同标准、不同测试项目对电流探头的需求差异,分析了电流探头选型的关键影响因素以及国内外主流厂家不同型号产品的对比,为EM…...

GD32时钟树配置实战:从理论到代码实现
1. GD32时钟树基础概念解析 第一次接触GD32的时钟配置时,我完全被那些专业术语搞懵了。什么HXTAL、PLL、AHB分频,听起来就像天书一样。但后来我发现,时钟系统其实就像城市里的交通网络,理解了基本规则后,一切都变得清晰…...

从零开始:Qwen3-ForcedAligner部署到生成第一条SRT字幕全记录
从零开始:Qwen3-ForcedAligner部署到生成第一条SRT字幕全记录 1. 工具概览:为什么选择Qwen3-ForcedAligner? 1.1 双模型协同工作原理 Qwen3-ForcedAligner不是普通的语音转文字工具,而是由两个专业模型组成的流水线:…...

Ubuntu18.04下ZED SDK的安装、配置与深度数据调试指南
1. 环境准备与CUDA版本适配 在Ubuntu18.04系统上安装ZED SDK前,需要先确认显卡驱动和CUDA环境是否就绪。我遇到过不少开发者卡在这一步,主要原因是对CUDA版本兼容性理解不够透彻。ZED SDK对CUDA版本有严格要求,比如v3.7.0版本需要CUDA10.2&am…...
)
ComfyUI进阶玩法:用SD3模型+自定义节点打造AI绘画工作流(附6个效率技巧)
ComfyUI进阶玩法:用SD3模型自定义节点打造AI绘画工作流(附6个效率技巧) 当你在ComfyUI中第一次看到那些错综复杂的节点连线时,是否感到既兴奋又困惑?作为Stable Diffusion生态中最具工程思维的可视化工具,C…...