Python酷库之旅-第三方库Pandas(062)
目录
一、用法精讲
241、pandas.Series.view方法
241-1、语法
241-2、参数
241-3、功能
241-4、返回值
241-5、说明
241-6、用法
241-6-1、数据准备
241-6-2、代码示例
241-6-3、结果输出
242、pandas.Series.compare方法
242-1、语法
242-2、参数
242-3、功能
242-4、返回值
242-5、说明
242-6、用法
242-6-1、数据准备
242-6-2、代码示例
242-6-3、结果输出
243、pandas.Series.update方法
243-1、语法
243-2、参数
243-3、功能
243-4、返回值
243-5、说明
243-6、用法
243-6-1、数据准备
243-6-2、代码示例
243-6-3、结果输出
244、pandas.Series.asfreq方法
244-1、语法
244-2、参数
244-3、功能
244-4、返回值
244-5、说明
244-6、用法
244-6-1、数据准备
244-6-2、代码示例
244-6-3、结果输出
245、pandas.Series.asof方法
245-1、语法
245-2、参数
245-3、功能
245-4、返回值
245-5、说明
245-6、用法
245-6-1、数据准备
245-6-2、代码示例
245-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
241、pandas.Series.view方法
241-1、语法
# 241、pandas.Series.view方法
pandas.Series.view(dtype=None)
Create a new view of the Series.Deprecated since version 2.2.0: Series.view is deprecated and will be removed in a future version. Use Series.astype() as an alternative to change the dtype.This function will return a new Series with a view of the same underlying values in memory, optionally reinterpreted with a new data type. The new data type must preserve the same size in bytes as to not cause index misalignment.Parameters:
dtype
data type
Data type object or one of their string representations.Returns:
Series
A new Series object as a view of the same data in memory.241-2、参数
241-2-1、dtype(可选,默认值为None):数据类型,可以是NumPy数据类型或pandas数据类型。如果未指定,返回相同dtype的视图。
241-3、功能
用于创建Series的视图,并且可以通过指定不同的数据类型来查看同一数据在内存中的不同表示,这在数据转换和内存管理方面非常有用。
241-4、返回值
返回的视图是一个新的Series对象,但它与原始Series共享同一块内存,因此对视图所做的修改会直接影响原始Series。
241-5、说明
此方法目前仍然能用,但后续将被pandas.Series.astype方法所替代。
241-6、用法
241-6-1、数据准备
无241-6-2、代码示例
# 241、pandas.Series.view方法
# 241-1、创建一个视图并查看不同的数据类型表示
import pandas as pd
# 创建一个Series
s = pd.Series([1, 2, 3, 4])
# 以float64数据类型查看Series
view_as_float = s.view(dtype='float64')
print("Original Series:")
print(s)
print("Viewed as float64:")
print(view_as_float, end='\n\n')# 241-2、修改视图中的数据,影响原始Series
import pandas as pd
# 创建一个Series
s_original = pd.Series([1, 2, 3, 4])
# 创建一个视图
s_view = s_original.view()
# 修改视图中的数据
s_view[0] = 10
print("Original Series after modification:")
print(s_original)
print("Modified view:")
print(s_view)241-6-3、结果输出
# 241、pandas.Series.view方法
# 241-1、创建一个视图并查看不同的数据类型表示
# Original Series:
# 0 1
# 1 2
# 2 3
# 3 4
# dtype: int64
# Viewed as float64:
# 0 4.940656e-324
# 1 9.881313e-324
# 2 1.482197e-323
# 3 1.976263e-323
# dtype: float64# 241-2、修改视图中的数据,影响原始Series
# Original Series after modification:
# 0 10
# 1 2
# 2 3
# 3 4
# dtype: int64
# Modified view:
# 0 10
# 1 2
# 2 3
# 3 4
# dtype: int64242、pandas.Series.compare方法
242-1、语法
# 242、pandas.Series.compare方法
pandas.Series.compare(other, align_axis=1, keep_shape=False, keep_equal=False, result_names=('self', 'other'))
Compare to another Series and show the differences.Parameters:
otherSeries
Object to compare with.align_axis{0 or ‘index’, 1 or ‘columns’}, default 1
Determine which axis to align the comparison on.0, or ‘index’Resulting differences are stacked vertically
with rows drawn alternately from self and other.1, or ‘columns’Resulting differences are aligned horizontally
with columns drawn alternately from self and other.keep_shapebool, default False
If true, all rows and columns are kept. Otherwise, only the ones with different values are kept.keep_equalbool, default False
If true, the result keeps values that are equal. Otherwise, equal values are shown as NaNs.result_namestuple, default (‘self’, ‘other’)
Set the dataframes names in the comparison.New in version 1.5.0.Returns:
Series or DataFrame
If axis is 0 or ‘index’ the result will be a Series. The resulting index will be a MultiIndex with ‘self’ and ‘other’ stacked alternately at the inner level.If axis is 1 or ‘columns’ the result will be a DataFrame. It will have two columns namely ‘self’ and ‘other’.242-2、参数
242-2-1、other(必须):表示另一个与当前Series进行比较的Series。
242-2-2、align_axis(可选,默认值为1):表示对齐轴,可选0或1:1表示列对齐,0表示行对齐。
242-2-3、keep_shape(可选,默认值为False):是否保留原始的Series形状,如果为True,则保留NaN值。
242-2-4、keep_equal(可选,默认值为False):是否在结果中保留相等的元素,如果为True,相等的元素也会显示在结果中。
242-2-5、result_names(可选,默认值为('self', 'other')):表示结果中显示的列名。
242-3、功能
用于对比两个Series对象,找出不同之处。
242-4、返回值
返回一个DataFrame,其中包含两个Series对比后的差异部分。
242-5、说明
无
242-6、用法
242-6-1、数据准备
无242-6-2、代码示例
# 242、pandas.Series.compare方法
import pandas as pd
# 创建两个Series
s1 = pd.Series([5, 11, 10, 8])
s2 = pd.Series([3, 6, 10, 24])
# 对比两个Series
result = s1.compare(s2)
print("Comparison result:")
print(result, end='\n\n')242-6-3、结果输出
# 242、pandas.Series.compare方法
# Comparison result:
# self other
# 0 5.0 3.0
# 1 11.0 6.0
# 3 8.0 24.0243、pandas.Series.update方法
243-1、语法
# 243、pandas.Series.update方法
pandas.Series.update(other)
Modify Series in place using values from passed Series.Uses non-NA values from passed Series to make updates. Aligns on index.Parameters:
other
Series, or object coercible into Series243-2、参数
243-2-1、other(必须):表示另一个Series或DataFrame,用于更新当前Series的值,如果other是DataFrame,必须和当前Series具有相同的索引。
243-3、功能
用于使用另一个Series的值来更新当前Series的值,它直接修改原Series,并且不返回新的对象。
243-4、返回值
没有返回值,它是一个inplace操作,这意味着它会直接修改调用该方法的Series对象,而不是返回一个新的Series。
243-5、说明
无
243-6、用法
243-6-1、数据准备
无243-6-2、代码示例
# 243、pandas.Series.update方法
# 243-1、基本更新
import pandas as pd
# 创建两个Series
s1 = pd.Series({'a': 3, 'b': 6, 'c': 10, 'd': 24})
s2 = pd.Series({'b': 5, 'd': 11, 'e': 10, 'f': 8})
# 使用s2更新s1
s1.update(s2)
print("Updated Series:")
print(s1, end='\n\n')# 243-2、带有NaN值的更新
import pandas as pd
# 创建两个Series,其中包含NaN值
s3 = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': None})
s4 = pd.Series({'b': 20, 'd': None, 'e': 50})
# 使用s4更新s3
s3.update(s4)
print("Updated Series with NaN values:")
print(s3)243-6-3、结果输出
# 243、pandas.Series.update方法
# 243-1、基本更新
import pandas as pd
# 创建两个Series
s1 = pd.Series({'a': 3, 'b': 6, 'c': 10, 'd': 24})
s2 = pd.Series({'b': 5, 'd': 11, 'e': 10, 'f': 8})
# 使用s2更新s1
s1.update(s2)
print("Updated Series:")
print(s1, end='\n\n')# 243-2、带有NaN值的更新
import pandas as pd
# 创建两个Series,其中包含NaN值
s3 = pd.Series({'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': None})
s4 = pd.Series({'b': 20, 'd': None, 'e': 50})
# 使用s4更新s3
s3.update(s4)
print("Updated Series with NaN values:")
print(s3)244、pandas.Series.asfreq方法
244-1、语法
# 244、pandas.Series.asfreq方法
pandas.Series.asfreq(freq, method=None, how=None, normalize=False, fill_value=None)
Convert time series to specified frequency.Returns the original data conformed to a new index with the specified frequency.If the index of this Series/DataFrame is a PeriodIndex, the new index is the result of transforming the original index with PeriodIndex.asfreq (so the original index will map one-to-one to the new index).Otherwise, the new index will be equivalent to pd.date_range(start, end, freq=freq) where start and end are, respectively, the first and last entries in the original index (see pandas.date_range()). The values corresponding to any timesteps in the new index which were not present in the original index will be null (NaN), unless a method for filling such unknowns is provided (see the method parameter below).The resample() method is more appropriate if an operation on each group of timesteps (such as an aggregate) is necessary to represent the data at the new frequency.Parameters:
freq
DateOffset or str
Frequency DateOffset or string.method
{‘backfill’/’bfill’, ‘pad’/’ffill’}, default None
Method to use for filling holes in reindexed Series (note this does not fill NaNs that already were present):‘pad’ / ‘ffill’: propagate last valid observation forward to next valid‘backfill’ / ‘bfill’: use NEXT valid observation to fill.how
{‘start’, ‘end’}, default end
For PeriodIndex only (see PeriodIndex.asfreq).normalize
bool, default False
Whether to reset output index to midnight.fill_value
scalar, optional
Value to use for missing values, applied during upsampling (note this does not fill NaNs that already were present).Returns:
Series/DataFrame
Series/DataFrame object reindexed to the specified frequency.244-2、参数
244-2-1、freq(必须):字符串或DataOffset对象,表示指定目标频率,常见的频率字符串包括:
- 'D': 每日
- 'M': 每月
- 'A': 每年
- 'H': 每小时
- 'T'或'min': 每分钟
- 'S': 每秒
244-2-2、method(可选,默认值为None):字符串('pad','ffill','backfill','bfill')或None,指定当重新采样时如何填充缺失的值。
- 'pad'或'ffill':用前一个有效值填充缺失值。
- 'backfill'或'bfill':用下一个有效值填充缺失值。
244-2-3、how(可选,默认值为None):字符串,在较新的版本中已经被移除,可以忽略此参数。
244-2-4、normalize(可选,默认值为False):布尔值,如果为True,则将时间戳规范化到午夜时间。
244-2-5、fill_value(可选,默认值为None):标量值,指定用于填充缺失值的标量值。
244-3、功能
用于将时间序列重新采样为指定的频率,可能会填充或不填充缺失值,具体取决于method和fill_value参数。
244-4、返回值
返回一个新的Series,其索引为指定频率的时间戳,数据根据指定的填充方法处理。
244-5、说明
无
244-6、用法
244-6-1、数据准备
无244-6-2、代码示例
# 244、pandas.Series.asfreq方法
import pandas as pd
# 创建一个时间序列
rng = pd.date_range('2024-01-01', periods=6, freq='2D')
ts = pd.Series(range(6), index=rng)
# 将时间序列转换为每日频率,使用前向填充方法
ts_daily_ffill = ts.asfreq('D', method='ffill')
# 将时间序列转换为每日频率,不填充缺失值
ts_daily_no_fill = ts.asfreq('D')
# 将时间序列转换为每日频率,填充缺失值为0
ts_daily_fill_value = ts.asfreq('D', fill_value=0)
print("原始时间序列:")
print(ts)
print("\n转换为每日频率,使用前向填充方法:")
print(ts_daily_ffill)
print("\n转换为每日频率,不填充缺失值:")
print(ts_daily_no_fill)
print("\n转换为每日频率,填充缺失值为0:")
print(ts_daily_fill_value)244-6-3、结果输出
# 244、pandas.Series.asfreq方法
# 原始时间序列:
# 2024-01-01 0
# 2024-01-03 1
# 2024-01-05 2
# 2024-01-07 3
# 2024-01-09 4
# 2024-01-11 5
# Freq: 2D, dtype: int64
#
# 转换为每日频率,使用前向填充方法:
# 2024-01-01 0
# 2024-01-02 0
# 2024-01-03 1
# 2024-01-04 1
# 2024-01-05 2
# 2024-01-06 2
# 2024-01-07 3
# 2024-01-08 3
# 2024-01-09 4
# 2024-01-10 4
# 2024-01-11 5
# Freq: D, dtype: int64
#
# 转换为每日频率,不填充缺失值:
# 2024-01-01 0.0
# 2024-01-02 NaN
# 2024-01-03 1.0
# 2024-01-04 NaN
# 2024-01-05 2.0
# 2024-01-06 NaN
# 2024-01-07 3.0
# 2024-01-08 NaN
# 2024-01-09 4.0
# 2024-01-10 NaN
# 2024-01-11 5.0
# Freq: D, dtype: float64
#
# 转换为每日频率,填充缺失值为0:
# 2024-01-01 0
# 2024-01-02 0
# 2024-01-03 1
# 2024-01-04 0
# 2024-01-05 2
# 2024-01-06 0
# 2024-01-07 3
# 2024-01-08 0
# 2024-01-09 4
# 2024-01-10 0
# 2024-01-11 5
# Freq: D, dtype: int64245、pandas.Series.asof方法
245-1、语法
# 245、pandas.Series.asof方法
pandas.Series.asof(where, subset=None)
Return the last row(s) without any NaNs before where.The last row (for each element in where, if list) without any NaN is taken. In case of a DataFrame, the last row without NaN considering only the subset of columns (if not None)If there is no good value, NaN is returned for a Series or a Series of NaN values for a DataFrameParameters:
wheredate or array-like of dates
Date(s) before which the last row(s) are returned.subsetstr or array-like of str, default None
For DataFrame, if not None, only use these columns to check for NaNs.Returns:
scalar, Series, or DataFrame
The return can be:scalar : when self is a Series and where is a scalarSeries: when self is a Series and where is an array-like, or when self is a DataFrame and where is a scalarDataFrame : when self is a DataFrame and where is an array-like245-2、参数
245-2-1、where(必须):单个索引值或索引值的列表,指定要查找的索引位置,如果是单个索引值,则返回该位置之前的最新有效值;如果是索引值的列表,则对每个索引值执行查找操作。
245-2-2、subset(可选,默认值为None):列名或列名的列表(仅用于DataFrame),指定在DataFrame中应用查找操作的列,如果未指定,则默认使用所有列。
245-3、功能
用于返回给定索引位置之前(或恰好在该位置)的最新有效值,它在处理时间序列数据时特别有用。
245-4、返回值
返回给定索引位置之前的最新有效值,对于单个索引值,返回一个标量值;对于索引值的列表,返回一个包含查找结果的Series。
245-5、说明
无
245-6、用法
245-6-1、数据准备
无245-6-2、代码示例
# 245、pandas.Series.asof方法
import pandas as pd
import numpy as np
# 创建一个包含缺失值的时间序列
dates = pd.date_range('2024-01-01', periods=10, freq='D')
values = [np.nan, 1.2, np.nan, 3.4, np.nan, np.nan, 7.8, np.nan, 9.0, np.nan]
ts = pd.Series(values, index=dates)
# 使用asof方法找到指定日期之前的最新有效值
print(ts.asof('2024-01-05'))
# 使用asof方法填充缺失值
filled_ts = ts.copy()
filled_ts = filled_ts.fillna(method='ffill')
print(filled_ts)245-6-3、结果输出
# 245、pandas.Series.asof方法
# 3.4
# 2024-01-01 NaN
# 2024-01-02 1.2
# 2024-01-03 1.2
# 2024-01-04 3.4
# 2024-01-05 3.4
# 2024-01-06 3.4
# 2024-01-07 7.8
# 2024-01-08 7.8
# 2024-01-09 9.0
# 2024-01-10 9.0
# Freq: D, dtype: float64二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-第三方库Pandas(062)
目录 一、用法精讲 241、pandas.Series.view方法 241-1、语法 241-2、参数 241-3、功能 241-4、返回值 241-5、说明 241-6、用法 241-6-1、数据准备 241-6-2、代码示例 241-6-3、结果输出 242、pandas.Series.compare方法 242-1、语法 242-2、参数 242-3、功能 …...

python学习之旅(基础篇看这篇足够了!!!)
目录 前言 1.输入输出 1.1 输入 1.2 输出 2. 变量与常量 2.1 变量 2.2 常量 2.3 赋值 2.4格式化输出 3. 数据类型 4. 四则运算 5.“真与假” 5.1 布尔数 5.2 比较运算和逻辑运算 5.3 布尔表达式 6.判断语句 6.1 基本的if语句 6.2 if-else语句 6.3 if-elif-el…...

Azure OpenAI Embeddings vs OpenAI Embeddings
题意:Azure OpenAI 嵌入与 OpenAI 嵌入的比较 问题背景: Is anyone getting different results from Azure OpenAI embeddings deployment using text-embedding-ada-002 than the ones from OpenAI? Same text, same model, and the results are cons…...

重生奇迹MU职业成长三步走
在重生奇迹MU游戏中,转职是最重要的玩法之一。每个职业在转职后都会发生巨大的变化,经过三次转职后,你才有资格成为该游戏中最强大的冒险者。 一转,一切才刚刚开始 玩家完成第一次转职任务后,标志着我们成功度过了游…...

2024年中国数据中台行业研究报告
数据中台丨研究报告 核心摘要: 数据中台是企业数字化建设的重要构成,其通过整合企业基础设施和数据能力,实现数据资产化和服务复用,降低运营成本,支撑业务创新。受宏观经济影响,部分企业减少了对数据中台等…...

MySQL——数据表的基本操作(一)创建数据表
数据库创建成功后,就需要创建数据表。所谓创建数据表指的是在已存在的数据库中建立新表。需要注意的是,在操作数据表之前,应该使用 “ USE 数据库名 ” 指定操作是在哪个数据库中进行,否则会抛出 “ No database selected ” 错误。创建数据表…...
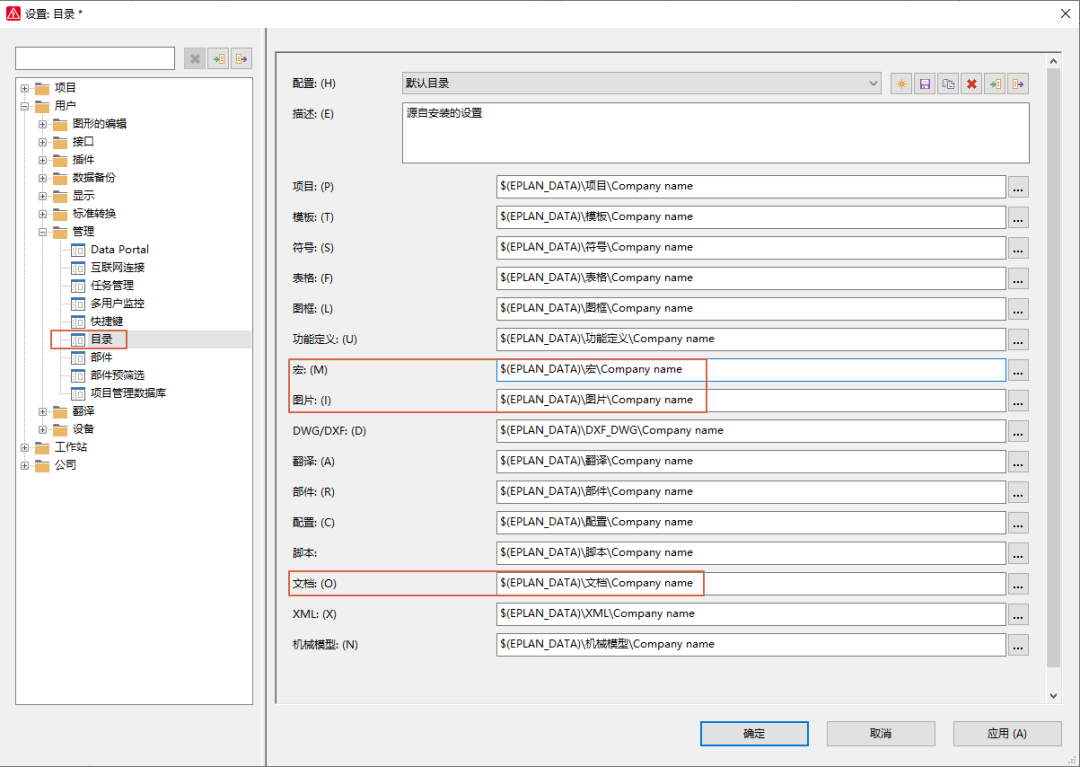
EPLAN EDZ 文件太大导入很慢如何解决?
目前各个品牌都在提供 EPLAN EDZ部件库文件,但是一般都是一个总的EDZ文件,导入过程中,因为电脑配置和其他问题,导致导入过程中EPLAN会崩溃或者长时间不动。 我们分析下EDZ文件的构成,这是个压缩文件,换了个壳而已。用压缩软件把edz打开,这里不是解压,直接右键,用解压…...

刷题——缺失的第一个正整数
缺失的第一个正整数_牛客题霸_牛客网 我选择了一个我比较能看懂的, int minNumberDisappeared(vector<int>& nums) {// write code heremap<int, int>hash;int n nums.size();//哈希表记录数组中出现的每个数字for(int i 0; i < n; i)hash[n…...

代理设置--一些库的代理设置
首先最好能获取一个免费代理,来继续下面的阅读和实验 也可以在本机设置代理,具体流程由于比较敏感,请自行搜索 代理设置成功后的测试网站是 http://www.httpbin.org/get , 访问该链接可以得到请求相关的信息,返回结果中的 ori…...

Debezium系列之:PostgreSQL数据库赋予账号数据采集权限的详细步骤
Debezium系列之:PostgreSQL数据库赋予账号数据采集权限的详细步骤 一、账号需要的权限二、创建账号,赋予登陆、复制权限三、赋予账号数据库权限四、赋予账号对表的权限五、创建PostgreSQL数据库复制组六、账号权限授予完整案例七、扩展——分区表设置八、扩展-撤销账号的权限…...

javascript:判断输入值是数字还是字母
1 代码示例 要判断输入值是数字还是字母,我们可以通过JavaScript获取输入框的值,然后使用isNaN函数来检查输入值是否为数字。 <!DOCTYPE html> <html><head><meta charset"UTF-8"><title></title><s…...

Java-排序算法-复盘知识点
刷了24道简单排序题,18道中等排序题之后,给排序算法来个简单的复盘(从明天开始刷动态规划咯) 1.对于找多数元素(出现次数超过一半的元素)可以使用摩尔投票法。 2.HashSet的add方法非常实用:如…...

HarmonyOS 原生智能之语音识别实战
HarmonyOS 原生智能之语音识别实战 背景 公司很多业务场景使用到了语音识别功能,当时我们的语音团队自研了语音识别模型,方案是云端模型加端侧SDK交互,端侧负责做语音采集、VAD、opus编码,实时传输给云端,云端识别后…...
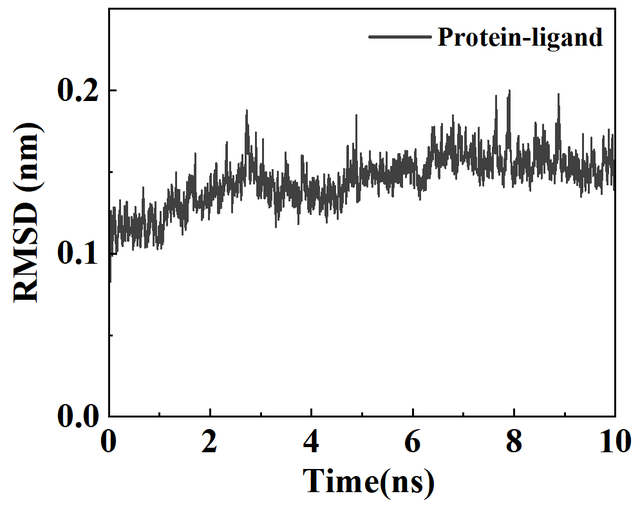
基于Gromacs的蛋白质与小分子配体相互作用模拟教程
在生命科学的广阔领域中,蛋白质与小分子配体之间的相互作用扮演着至关重要的角色。这些相互作用不仅影响着生物体内的各种生命活动,如信号传导、代谢调控和药物作用等,同时也是药物设计和开发的核心内容。因此,深入理解并模拟这些…...

Ubuntu下python3.12安装, 分布式 LLM 推理 exo 安装调试过程, 运行自己的 AI 集群
创作不易 只因热爱!! 热衷分享,一起成长! “你的鼓励就是我努力付出的动力” —调试有点废,文章有点长,希望大家用心看完,肯定能学废,感谢. 1. Ubuntu下python3.12安装 1.1 导入 Python 的稳定版 PPA,不用编译 sudo add-apt-repository ppa:deadsnakes/ppa sudo…...

pytest-bdd 行为驱动自动化测试
引言 pytest-bdd 是一个专为Python设计的行为驱动开发(BDD)测试框架,它允许开发人员使用自然语言(如Gherkin)来编写测试用例,从而使测试用例更易于理解和维护。 安装 通过pip安装 pip install pytest-b…...

PostgreSQL11 | 触发器
本文章代码已在pgsql11.22版本上运行且通过,展示页由pgAdmin8.4版本提供 上一篇总结了原著的第十章有关pgsql的视图的用法,本篇将总结pgsql的触发器的用法。 触发器 使用触发器可以自动化完成一些在插入数据或修改数据时,某些需要同期同步的…...
cesium canvas广告牌
在有些业务中,对场景中的广告牌样式要求比较高,需要动态显示一些数据,这个时候,我们可以通过将复杂背景样式制作成图片,通过canvas绘制图片和动态数据,从而达到比较好的显示效果。 1 CanvasMarker 类封装 …...

使用Floyd算法求解两点间最短距离
Floyd算法 Floyd算法又称为Floyd-Warshell算法,其实Warshell算法是离散数学中求传递闭包的算法,两者的思想是一致的。Floyd算法是求解多源最短路时通常选用的算法,经过一次算法即可求出任意两点之间的最短距离,并且可以处理有负权…...

linux“how_paras.sh“ E212: 无法打开并写入文件
经过一番测试和查找, [6localhost bin]$ find / -name "hello.sh" 2>/dev/null /home/6/bin/hello.sh [6localhost bin]$ ls hello.sh ls: 无法访问hello.sh: 没有那个文件或目录,为什么在/bin文件下却不能打开, [6localhost …...
)
2026奇点智能大会前瞻:为什么92%的AI工程团队将在Q3前重构Agent框架?(Gartner未公开预警报告首曝)
第一章:2026奇点智能技术大会:大模型Agent框架 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次将大模型Agent框架确立为核心技术范式,聚焦于可推理、可规划、可协作的自主智能体系统设计。与传统微调或提示工程不同,…...

终极指南:3步掌握IwaraDownloadTool高效视频批量下载
终极指南:3步掌握IwaraDownloadTool高效视频批量下载 【免费下载链接】IwaraDownloadTool Iwara 下载工具 | Iwara Downloader 项目地址: https://gitcode.com/gh_mirrors/iw/IwaraDownloadTool 你是否曾为Iwara平台上的精彩视频无法离线保存而烦恼ÿ…...

3分钟为MusicBee安装网易云歌词插件:告别无歌词音乐体验
3分钟为MusicBee安装网易云歌词插件:告别无歌词音乐体验 【免费下载链接】MusicBee-NeteaseLyrics A plugin to retrieve lyrics from Netease Cloud Music for MusicBee. 项目地址: https://gitcode.com/gh_mirrors/mu/MusicBee-NeteaseLyrics 还在为MusicB…...

零样本分类避坑指南:AI万能分类器使用中的注意事项与技巧
零样本分类避坑指南:AI万能分类器使用中的注意事项与技巧 1. 零样本分类技术概述 零样本分类(Zero-Shot Classification)是自然语言处理领域的一项突破性技术,它允许模型在没有特定任务训练数据的情况下,仅凭用户提供…...

基于影墨·今颜的微信小程序开发:打造个人AI绘画工具
基于影墨今颜的微信小程序开发:打造个人AI绘画工具 最近发现身边不少朋友都在玩AI绘画,但要么得用电脑,要么得下载专门的App,总感觉不够方便。我就琢磨着,能不能把这事儿搬到微信小程序里?随时随地打开微信…...

告别依赖冲突!Miniconda-Python3.9新手快速部署指南
告别依赖冲突!Miniconda-Python3.9新手快速部署指南 1. 为什么你需要Miniconda? 你是否遇到过这样的情况:昨天还能运行的代码,今天突然报错"ModuleNotFoundError"?或者团队中有人能跑通的项目,…...

使用 Alertmanager 配置智能告警
在微服务与云原生架构盛行的当下,系统监控与告警管理成为保障业务稳定性的关键环节。Alertmanager作为Prometheus生态中的核心告警组件,通过灵活的配置和智能路由策略,能够将海量告警转化为精准的行动指令,帮助运维团队快速响应问…...

CISSP域3知识点 安全工程基础
🏗️ CISSP 域3安全工程基础丨把安全"建"进系统里Domain 3 安全架构与工程 OSG第十版第8章核心内容 占域3(13%总权重)30%以上,概念题场景题双高频 这一块是整个 CISSP 的理论地基,不搞透,后面很…...

把 Flask 搬进 ESP,高中生自研嵌入式 Web 框架 MicroFlask !舶
如果有多个供应商,你也可以使用 [[CC-Switch]] 来可视化管理这些API key,以及claude code 的skills。 # 多平台安装指令 curl -fsSL https://claude.ai/install.sh | bash ## Claude Code 配置 GLM Coding Plan curl -O "https://cdn.bigmodel.cn/i…...

NunchukLib:轻量级嵌入式Nunchuk驱动库设计与应用
1. NunchukLib 库概述NunchukLib 是一个专为嵌入式平台设计的轻量级 C 语言库,用于驱动任天堂 Wii 游戏机配套的 Nunchuk 手柄模块。该手柄通过标准 IC 总线与主控 MCU 通信,内部集成三轴加速度计(MMA7260Q 或兼容型号)、双轴模拟…...