ShardingSphere中的ShardingJDBC常见分片算法的实现
文章目录
- ShardingJDBC
- 快速入门
- 修改雪花算法和分表策略
- 核心概念
- 分片算法
- 简单INLINE分片算法
- STANDARD标准分片算法
- COMPLEX_INLINE复杂分片算法
- CLASS_BASED自定义分片算法
- HINT_INLINE强制分片算法
- 注意事项
ShardingJDBC
Git地址
快速入门
现在我存在两个数据库,并且各自都有两个数据表。我现在先新增一批用户,分别插入两个数据库的多张数据表中

基本环境搭建
实体类
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
// 注意,我这里给的表名是sys_user 这是一个逻辑表名 而上图中是不存在这个数据表的,
@TableName("sys_user")
@ApiModel(value="User对象", description="用户表")
public class User implements Serializable {private static final long serialVersionUID = 1L;/*** 实体类中的属性最好不用使用id,因为mybatisplus会自动识别id属性,并在新增时使用雪花算法为id属性赋值。* 而不会使用ShardingSphere的雪花算法生成,如果一定要使用id属性名,那么就要加上@TableId(value = "uid", type = IdType.AUTO)** 也不要在分片键上使用 @TableId(value = "uid", type = IdType.ASSIGN_ID) 这样是使用的mybatisplus的雪花算法生成的key,* 也不会使用ShardingSphere的雪花算法生成*/@ApiModelProperty(value = "uid")
// @TableId(value = "uid", type = IdType.ASSIGN_ID)private Long uid;@ApiModelProperty(value = "用户名")private String username;@ApiModelProperty(value = "密码")private String password;@ApiModelProperty(value = "姓名")private String name;@ApiModelProperty(value = "描述")private String description;@ApiModelProperty(value = "状态(1:正常 0:停用)")private Integer status;@ApiModelProperty(value = "创建时间")@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone = "GMT+8")@TableField(fill = FieldFill.INSERT)private Date createTime;@ApiModelProperty(value = "最后修改时间")@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone = "GMT+8")@TableField(fill = FieldFill.INSERT_UPDATE)private Date updateTime;
}
Mapper接口
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
maven依赖
<!-- shardingJDBC核心依赖 -->
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.2.1</version><exclusions><exclusion><artifactId>snakeyaml</artifactId><groupId>org.yaml</groupId></exclusion></exclusions>
</dependency><!-- 坑爹的版本冲突 -->
<dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.33</version>
</dependency><!-- SpringBoot依赖 -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId><exclusions><exclusion><artifactId>snakeyaml</artifactId><groupId>org.yaml</groupId></exclusion></exclusions>
</dependency><!-- 数据源连接池 -->
<!--注意不要用这个依赖,他会创建数据源,跟上面ShardingJDBC的SpringBoot集成依赖有冲突 -->
<!-- <dependency>-->
<!-- <groupId>com.alibaba</groupId>-->
<!-- <artifactId>druid-spring-boot-starter</artifactId>-->
<!-- <version>1.1.20</version>-->
<!-- </dependency>-->
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.20</version>
</dependency>
上方 snakeyaml 依赖冲突会报下面的错误
Description:An attempt was made to call a method that does not exist. The attempt was made from the following location:org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1.<init>(ShardingSphereYamlConstructor.java:44)The following method did not exist:org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1.setCodePointLimit(I)VThe method's class, org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1, is available from the following locations:jar:file:/D:/softwareDev/maven/myMaven/repository/org/apache/shardingsphere/shardingsphere-infra-util/5.2.1/shardingsphere-infra-util-5.2.1.jar!/org/apache/shardingsphere/infra/util/yaml/constructor/ShardingSphereYamlConstructor$1.classThe class hierarchy was loaded from the following locations:null: file:/D:/softwareDev/maven/myMaven/repository/org/apache/shardingsphere/shardingsphere-infra-util/5.2.1/shardingsphere-infra-util-5.2.1.jarorg.yaml.snakeyaml.LoaderOptions: file:/D:/softwareDev/maven/myMaven/repository/org/yaml/snakeyaml/1.26/snakeyaml-1.26.jarAction:Correct the classpath of your application so that it contains a single, compatible version of org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1

yml配置文件的内容
server:port: 8084spring:shardingsphere:props:# 打印shardingjdbc的日志 shardingsphere5之前的版本配置项是 spring.shardingsphere.props.sql.show,而这里是sql-showsql-show: true# 数据源配置datasource:# 虚拟库的名字,并指定对应的真实库names: hsdb0,hsdb1hsdb0:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/sharding_sphere1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8username: rootpassword: 1234hsdb1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/sharding_sphere2?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8username: rootpassword: 1234# 分布式序列算法配置rules:sharding:key-generators:# 雪花算法,生成Long类型主键。# alg_snowflake为我们程序员自定义的字符串名字,可以更改alg_snowflake:type: SNOWFLAKE # 建议使用COSID_SNOWFLAKE雪花算法,避免数据分布不均匀props:worker:id: 1sharding-algorithms:# 指定分库策略 按2取模方式 sys_user_db_alg是我们程序员自定义的字符串名字,可以更改sys_user_db_alg:type: MODprops:sharding-count: 2# 指定分表策略 INLINE:按单一分片键分表sys_user_tbl_alg:type: INLINEprops:# 通过uid对2取模 + 1 最终就会是使用sys_user1 sys_user2两张数据表algorithm-expression: sys_user$->{uid%2+1}# 指定分布式主键生成策略tables:# sys_user为虚拟表名,可以更改,但需要和实体类中的表名对应上sys_user:# 指定虚拟表的分片键,以及分片键的生成策略key-generate-strategy:# 指定分片建为 uid 这个是和数据表中的字段对应的column: uid# 指定分片键字段的生成策略, alg_snowflake 也就是我们上面自定义的雪花算法key-generator-name: alg_snowflake# 配置实际分片节点 $->{1..2}表达式的功能就是[1,2] hsdb0.sys_user1 hsdb0.sys_user2 hsdb1.sys_user1 hsdb1.sys_user2actual-data-nodes: hsdb$->{0..1}.sys_user$->{1..2}# 配置分库策略,按uid字段取模database-strategy:standard:sharding-column: uidsharding-algorithm-name: sys_user_db_alg# 指定分表策略 standard-按单一分片键进行精确或范围分片table-strategy:standard:sharding-column: uidsharding-algorithm-name: sys_user_tbl_alg
测试类,进行新增10条记录
@SpringBootTest
@RunWith(SpringRunner.class)
public class TestShardingJDBC {@Autowiredprivate UserMapper userMapper;@Testpublic void testAdd(){for (int i = 0; i < 10; i++) {User user = new User();user.setUsername("husahng" + i);user.setPassword("123456");userMapper.insert(user);}}
}
日志信息

插入结果,我们能发现,目前新增的数据被分到了两张数据表中,数据的分布并不平衡。这是因为我们在yml配置文件中指定的分库策略和分表策略导致的
我们的分库策略是根据uid%2 最终决定使用哪一个数据库,分表策略是uid%2+1 。
所以就导致了如果uid为偶数就会存放在hsdb0.sys_user1数据表;如果uid是奇数就会存放在hsdb1.sys_user2数据表


修改雪花算法和分表策略
我们接下来就修改一下分表策略
而将sys_user_tbl_alg的计算表达式从sys_user$->{uid%2+1}改成 sys_user$->{((uid+1)%4).intdiv(2)+1} 后,理论上,如果uid是连续递增的,就可以将数据均匀分到四个表里。但是snowflake雪花算法生成的ID并不是连续的,所以有时候还是无法分到四个表。
如下图所示,已经修改了分表策略,但还是只分到hsdb0.sys_user1数据表和hsdb1.sys_user2数据表

20240803120302397.png&pos_id=img-SabPy9cD-1722676476932)

所以我们还需要修改一下雪花算法,不使用snowflake雪花算法。关于这一块,后续文档会详细介绍,这里就简单使用mybatisplus的主键通过雪花算法生成
@TableId(value = "uid", type = IdType.ASSIGN_ID)
private Long uid;
或者是使用COSID_SNOWFLAKE雪花算法

此时数据就平衡的插入到多张数据表中了

核心概念
-
虚拟库
ShardingSphere的核心就是提供一个具备分库分表功能的虚拟库,他是一个ShardingSphereDatasource实例。应用程序只需要像操作单数据源一样访问这个ShardingSphereDatasource即可。
上方案例中,hsdb1 hsdb2就是虚拟库
-
真实库
实际保存数据的数据库。真实库被包含在ShardingSphereDataSource实例中,由ShardingSphere来决定未来使用哪一个真实库
上方案例中,sharding_sphere1和sharding_sphere2就是真实库
-
逻辑表
应用程序直接操作的逻辑表。
上方案例中,sys_user就是逻辑表
-
真实表
真实保存数据的表。逻辑表和真实表的表名不需要一致,但需要有一致的表结构。应用程序可以维护一个真实表与逻辑表的对应关系。
上方案例中,sys_ser1 sys_user2就是真实表
-
分布式主键生成算法
给逻辑表生成唯一的主键。
由于逻辑表的数据是分布在多个真实表当中的,所以单表的索引就无法保证逻辑表的ID唯一性。ShardingSphere集成了几种常见的基于单机生成的分布式主键生成器。比如SNOWFLAKE,COSID_SNOWFLAKE雪花算法可以生成单调递增的long类型的数字主键,还有UUID,NANOID可以生成字符串类型的主键。当然,ShardingSphere也支持应用自行扩展主键生成算法。比如基于Redis,Zookeeper等第三方服务,自行生成主键。
-
分片策略
表示逻辑表要如何分配到真实库和真实表当中,分为分库策略和分表策略两个部分。
分片策略由分片键和分片算法组成。分片键是进行数据水平拆分的关键字段。如果没有分片键,ShardingSphere将只能进行全路由,SQL执行的性能会非常差。分片算法则表示根据分片键如何寻找对应的真实库和真实表。
分片算法
简单INLINE分片算法
可以对分片键使用 = 或者是 in 进行精确查找。uid通过下面的分片表达式计算出要查询的真实库和真实表。
如果in操作涉及到了多个分片 并且 涉及到了多个数据表,也会进行多分片多数据表的查询
默认情况下不能使用范围查询
我们现在yml的配置的分表策略是
spring:shardingsphere:rules:sharding:sharding-algorithms:sys_user_tbl_alg:# 分片策略是 INLINEtype: INLINEprops:# 通过(uid+1) %4 /2 +1algorithm-expression: sys_user$->{((uid+1)%4).intdiv(2)+1}
// 使用 = 对分片进行精确查询
@Test
public void testInline(){QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.eq("uid", 1819587788580864004L);User user = userMapper.selectOne(queryWrapper);System.out.println(user);
}
日志信息,仅仅查询到一个库的一个表进行查询
Logic SQL: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user WHERE (uid = ?)Actual SQL: hsdb0 ::: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user1
WHERE (uid = ?) ::: [1819587788580864004]
// in操作 涉及到的都在是一个分片库中
@Test
public void testInline(){QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.in("uid", 1819587788580864004L,1819587788513755138L);List<User> users = userMapper.selectList(queryWrapper);System.out.println(users);
}
日志信息,会查询hsdb0分片库中的sys_user1 和 sys_user2 数据表,并通过union关键字进行组合查询
Logic SQL: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user WHERE (uid IN (?,?))Actual SQL: hsdb0 ::: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user1
WHERE (uid IN (?,?))
UNION
ALL SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user2
WHERE (uid IN (?,?)) ::: [1819587788580864004, 1819587788513755138, 1819587788580864004, 1819587788513755138]
// in操作 涉及到两个分片中的sys_user1数据表
@Test
public void testInline(){QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.in("uid", 1819587788580864004L,1819587788580864003L);List<User> users = userMapper.selectList(queryWrapper);System.out.println(users);
}
此时我更改一个查询的uid,让它涉及到两个分片中的sys_user1数据表,此时从打印的日志就可以发现这里只查询了两个分片的sys_user1数据表
Logic SQL: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user WHERE (uid IN (?,?))Actual SQL: hsdb0 ::: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user1 WHERE (uid IN (?,?)) ::: [1819587788580864004, 1819587788580864003]
Actual SQL: hsdb1 ::: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user1 WHERE (uid IN (?,?)) ::: [1819587788580864004, 1819587788580864003]
// in操作 涉及到两个分片中的两张数据表,主要就是sys_user$->{((uid+1)%4).intdiv(2)+1}这个分片表达式不能很好的进行区分了
@Test
public void testInline(){QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.in("uid", 1819587788580864004L,1819587784852127745L);List<User> users = userMapper.selectList(queryWrapper);System.out.println(users);
}
此时我更改一个查询的uid,让它设计到两个分片的两个数据表,此时从打印的日志就可以发现这里进行了两个分片与两个数据表的查询
Logic SQL: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user WHERE (uid IN (?,?))ctual SQL: hsdb0 ::: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user1
WHERE (uid IN (?,?)) UNION ALL SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user2
WHERE (uid IN (?,?)) ::: [1819587788580864004, 1819587784852127745, 1819587788580864004, 1819587784852127745]Actual SQL: hsdb1 ::: SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user1 WHERE (uid IN (?,?)) UNION ALL SELECT uid,username,password,name,description,status,create_time,update_time FROM sys_user2 WHERE (uid IN (?,?)) ::: [1819587788580864004, 1819587784852127745, 1819587788580864004, 1819587784852127745]
STANDARD标准分片算法
使用简单INLINE分片算法,它默认情况下不支持范围查询。
我们可以通过添加下面这个参数让它支持范围查询,只不过此时的查询是通过全分片路由查询
# 允许在inline策略中使用范围查询。 sys_user_tbl_alg 是自定义名称
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.props.allow-range-query-with-inline-sharding=true
@Test
public void testInline(){QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.between("uid", 1819587788513755138L, 1819587788580864004L);List<User> users = userMapper.selectList(queryWrapper);System.out.println(users);
}
报错信息

# 添加下面的配置 允许在inline策略中使用范围查询。 sys_user_tbl_alg 是自定义名称
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.props.allow-range-query-with-inline-sharding=true
此时的查询就会通过全分片路由查询
在Class_based自定义分片算法中,如果使用标准分片算法则实现下面的接口StandardShardingAlgorithm
public interface StandardShardingAlgorithm<T extends Comparable<?>> extends ShardingAlgorithm {String doSharding(Collection<String> var1, PreciseShardingValue<T> var2);// 如果是范围查询,那么我们就可以通过使用RangeShardingValue 对象来进行自定义范围查询的分片算法Collection<String> doSharding(Collection<String> var1, RangeShardingValue<T> var2);
}
COMPLEX_INLINE复杂分片算法
complex_inline复杂分片策略,它支持多个分片键。
建议所有的分片键是同一个类型
修改yml配置
# 分表策略-COMPLEX:按多个分片键组合分表 sys_user_tbl_alg 为我们自定义字符串 可以修改
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.type=COMPLEX_INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.props.algorithm-expression=sys_user$->{(uid+status+1)%2+1}#给sys_user表指定分表策略 sys_user是虚拟表名 按uid, status多个分片键进行组合分片 sys_user_tbl_alg要和上面的对应上
spring.shardingsphere.rules.sharding.tables.sys_user.table-strategy.complex.sharding-columns=uid, status
spring.shardingsphere.rules.sharding.tables.sys_user.table-strategy.complex.sharding-algorithm-name=sys_user_tbl_alg

进行新增
@Test
public void testAdd(){for (int i = 0; i < 10; i++) {User user = new User();user.setUsername("husahng" + i);user.setPassword("123456");user.setName("name");user.setDescription("描述信息");// 给status也设置值user.setStatus(1);userMapper.insert(user);}
}
通过两个分片字段进行查询
@Test
public void testComplexInline(){QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.in("uid", 1026510115563372545L,1026510115626287104L);queryWrapper.eq("status", 0);List<User> users = userMapper.selectList(queryWrapper);System.out.println(users);
}
CLASS_BASED自定义分片算法
我们可以通过自定义分片算法,能够提前判断一些不合理的查询条件。就比如我当前status的值只有0和1,如果查询的时候status为3就根本没必要去查询数据库了。
对于complex_inline复杂的分片算法,用一个简单的分片表达式也有点不太够用了。
我们可以创建一个java类,实现ShardingSphere提供的ComplexKeysShardingAlgorithm接口 自己在java代码中写相应的分片策略
STANDARD-> StandardShardingAlgorithm
COMPLEX->ComplexKeysShardingAlgorithm 这里就拿复杂的分片策略举例
HINT -> HintShardingAlgorithm
package com.hs.sharding.algorithm;import com.google.common.collect.Range;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import org.apache.shardingsphere.sharding.exception.syntax.UnsupportedShardingOperationException;import java.util.*;/*** 实现自定义COMPLEX分片策略* 声明算法时,ComplexKeysShardingAlgorithm接口可传入一个泛型,这个泛型就是分片键的数据类型。* 这个泛型只要实现了Comparable接口即可。* 但是官方不建议声明一个明确的泛型出来,建议是在doSharding中再做类型转换。这样是为了防止分片键类型与算法声明的类型不符合。* <p>* 我此时uid就是long status是int 我进行测试** @auth roykingw*/
public class MyComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {private Properties props;@Overridepublic Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Long> complexKeysShardingValue) {// 假如此时SQL为 select * from sys_user where uid in (xxx,xxx,xxx) and status between {lowerEndpoint} and {upperEndpoint};Collection<Long> uidList = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("uid");Range<Long> status = complexKeysShardingValue.getColumnNameAndRangeValuesMap().get("status");// 拿到status的查询范围if (status != null) {Long lowerEndpoint = status.lowerEndpoint();Long upperEndpoint = status.upperEndpoint();if (lowerEndpoint > upperEndpoint) {// 如果下限 > 上限 抛出异常,终止去数据库查询的操作throw new UnsupportedShardingOperationException("empty record query", "sys_user");} else if (lowerEndpoint < 0 || upperEndpoint > 1) {// 如果查询范围明显不在status字段的区间中//抛出异常,终止去数据库查询的操作throw new UnsupportedShardingOperationException("error range query param", "sys_user");}}// 校验都通过后,就按照自定义的分片规则来进行分片,我这里就按照uid的奇偶来进行List<String> result = new ArrayList<>();// 获取逻辑表名 sys_user 而我们的真实表为sys_user1 sys_user2String logicTableName = complexKeysShardingValue.getLogicTableName();for (Long uid : uidList) {String resultTableName = logicTableName + ((uid + 1) % 4 /2 + 1);if (!result.contains(resultTableName)) {result.add(resultTableName);}}return result;}@Overridepublic Properties getProps() {return props;}@Overridepublic void init(Properties properties) {this.props = props;}
}
在核心的dosharding方法当中,就可以按照我们之前的规则进行判断。不满足规则,直接抛出UnsupportedShardingOperationException异常,就可以组织ShardingSphere把SQL分配到真实数据库中执行。
接下来,还是需要增加策略配置,让course表按照这个规则进行分片。
# 使用CLASS_BASED分片算法- 不用配置SPI扩展文件
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.type=CLASS_BASED
# 指定策略 STANDARD|COMPLEX|HINT
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.props.strategy=COMPLEX
# 指定算法实现类。这个类必须是指定的策略对应的算法接口的实现类。
# STANDARD-> StandardShardingAlgorithm; COMPLEX->ComplexKeysShardingAlgorithm; HINT -> HintShardingAlgorithm
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.props.algorithmClassName=com.roy.shardingDemo.algorithm.MyComplexAlgorithm

此时,新增或查询就都会经过上方我们自定义的MyComplexAlgorithm.doSharding()方法来选择具体的分表策略了
HINT_INLINE强制分片算法
使用常见,查询虚拟字段的情况,HINT强制路由可以用一种与SQL无关的方式进行分库分表。
就比如我仅仅查询uid是奇数的情况,如果是单机就可以直接在Mapper接口中添加下面的sql即可
@Select("select * from sys_user where MOD(uid,2)=1")
我们使用ShardingSphere当然也能查询,只不过又是全分片路由查询。因为此时我们是根据uid的奇偶来进行分片的,所以自然是希望只去查询某一个真实表,这种基于虚拟列的查询语句,ShardingSphere不知道该去进行解析,那么就只能是全路由查询了。
实际上ShardingSphere无法正常解析的语句还有很多。基本上用上分库分表后,你的应用就应该要和各种多表关联查询、多层嵌套子查询、distinct查询等各种复杂查询分手了。
这个uid的奇偶关系并不能通过SQL语句正常体现出来,这时,就需要用上ShardingSphere提供的另外一种分片算法HINT强制路由。HINT强制路由可以用一种与SQL无关的方式进行分库分表。
注释掉之前给course表分配的分表算法,重新分配一个HINT_INLINE类型的分表算法
#给sys_user表指定分表策略 sys_user为虚拟表 可以修改 hint-与SQL无关的方式进行分片
spring.shardingsphere.rules.sharding.tables.sys_user.table-strategy.hint.sharding-algorithm-name=sys_user_tbl_alg
# 分表策略-HINT:用于SQL无关的方式分表,使用value关键字。 sys_user_tbl_alg 为自定义string
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.type=HINT_INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.sys_user_tbl_alg.props.algorithm-expression=sys_user$->{value}

然后,在应用进行查询时,使用HintManager给HINT策略指定value的值。
@Test
public void queryCourseByHint(){HintManager hintManager = HintManager.getInstance();// 强制查sys_user1表hintManager.addTableShardingValue("sys_user","1");try {List<User> users = userMapper.selectList(null);System.out.println(users);} finally {//线程安全,所有用完要注意关闭。hintManager.close();//hintManager关闭的主要作用是清除ThreadLocal,释放内存。HintManager实现了AutoCloseable接口,// 所以建议使用try-resource的方式,用完自动关闭。//try(HintManager hintManager = HintManager.getInstance()){ xxxx }}}
注意事项
-
实体类分片键属性名不要使用id,mybatisplus会自动识别id,并为它使用雪花算法生成值。如果想使用ShardingSphere的雪花算法生成值就需要注意这个问题
-
ShardingSphere的雪花算法不是自增长的,对它进行取模分片时可能出现数据分片不均匀情况,可以自定义雪花算法
-
不要使用批量插入
insert into course values (1,'java',1001,1),(2,'java',1001,1);但是这样的SQL语句如果交给ShardingSphere去执行,那么这个语句就会造成困惑。到底应该往course_1还是course_2里插入?对于这种没有办法正确执行的SQL语句,ShardingSphere就会抛出异常。
Insert statement does not support sharding table routing to multiple data nodes. -
简单inline分片算法,默认支持单分片键的 = in 精确查询,默认情况下不支持范围查询。需要开启一个配置
allow-range-query-with-inline-sharding=true -
standard标准分片算法,支持精确查询和范围查询
-
complex_inline 复杂分片算法,支持多分片键。但是建议分片键的类型是统一的
-
class_based自定义分片算法,比较灵活,可以通过java代码来指定使用的分片逻辑。可以通过实现相应的接口来实现该功能
-
hint_inline强制分片算法,直接在代码中强制指定查询的分片逻辑
相关文章:
ShardingSphere中的ShardingJDBC常见分片算法的实现
文章目录 ShardingJDBC快速入门修改雪花算法和分表策略核心概念分片算法简单INLINE分片算法STANDARD标准分片算法COMPLEX_INLINE复杂分片算法CLASS_BASED自定义分片算法HINT_INLINE强制分片算法 注意事项 ShardingJDBC Git地址 快速入门 现在我存在两个数据库,并…...

SpringBoot整合Flink CDC实时同步postgresql变更数据,基于WAL日志
SpringBoot整合Flink CDC实时同步postgresql变更数据,基于WAL日志 一、前言二、技术介绍(Flink CDC)1、Flink CDC2、Postgres CDC 三、准备工作四、代码示例五、总结 一、前言 在工作中经常会遇到要实时获取数据库(postgresql、m…...

ThinkPHP事件的使用
技术说明 1.ThinkPHP版本:支持6.0、8.0 2.使用场景:用户登陆后日志记录、通知消息发送等主流程、次流程分离等场景 3.说明:网上很多帖子说的不明不白的,建议大家自己手动尝试总结一下 4.事件手动绑定的时候,一定要…...

【Nuxt】服务端渲染 SSR
SSR 概述 服务器端渲染全称是:Server Side Render,在服务器端渲染页面,并将渲染好HTML返回给浏览器呈现。 SSR应用的页面是在服务端渲染的,用户每请求一个SSR页面都会先在服务端进行渲染,然后将渲染好的页面…...

Spring Boot整合WebSocket
说明:本文介绍如何在Spirng Boot中整合WebSocket,WebSocket介绍,参考下面这篇文章: WebSocket 原始方式 原始方式,指的是使用Spring Boot自己整合的方式,导入的是下面这个依赖 <dependency><g…...

《LeetCode热题100》---<5.③普通数组篇五道>
本篇博客讲解LeetCode热题100道普通数组篇中的五道题 第五道:缺失的第一个正数(困难) 第五道:缺失的第一个正数(困难) 方法一:将数组视为哈希表 class Solution {public int firstMissingPosi…...

Cocos Creator文档学习记录
Cocos Creator文档学习记录 一、什么是Cocos Creator 官方文档链接:Hello World | Cocos Creator 百度百科:Cocos Creator_百度百科 Cocos Creator包括开发和调试、商业化 SDK 的集成、多平台发布、测试、上线这一整套工作流程,可多次的迭…...

插入数据优化 ---大批量数据插入建议使用load
一.insert优化 1.批量插入 2.手动提交事务 3.主键顺序插入 二.大批量插入数据 如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。操作如下 1.客户端连接服务端时,加入参数 --local-infine mysql --local-infine…...
【Linux】一篇总结!什么是重定向?输出重定向的作用是什么?什么又是追加重定向?
欢迎来到 CILMY23 的博客 🏆本篇主题为:一篇总结!什么是重定向?输出重定向的作用是什么?什么又是追加重定向? 🏆个人主页:CILMY23-CSDN博客 🏆系列专栏:Py…...

svn软件总成全内容
SVN软件总成 概述:本文为经验型文档 目录 D:\安装包\svn软件总成 的目录D:\安装包\svn软件总成\svn-base添加 的目录D:\安装包\svn软件总成\tools 的目录D:\安装包\svn软件总成\tools\sqlite-tools-win32-x86-3360000 的目录D:\安装包\svn软件总成\安装包-----bt lo…...

[激光原理与应用-118]:电源系统的接地详解:小信号的噪声干扰优化,从良好外壳接地开始
目录 一、电路的基本原理:电流回路 1、电流回路的基本概念 2、电流回路的特性 3、电流回路的类型 4、电流回路的应用 五、电流回路的注意事项 二、交流设备的接地 1.1 概述 1、交流工作接地的定义 2、交流工作接地的作用 3、交流工作接地的规范要求 4、…...
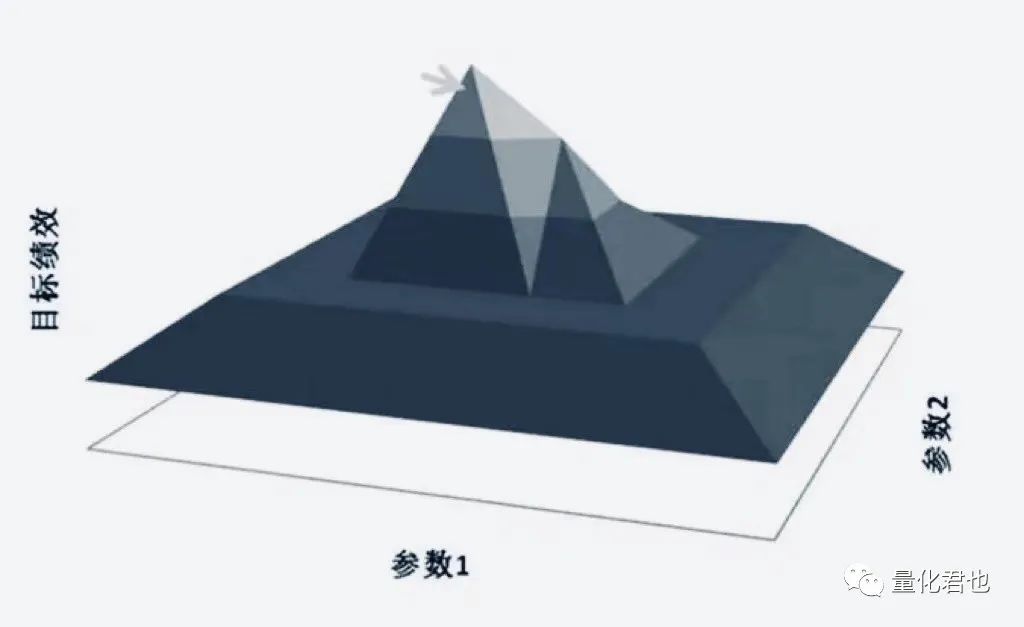
回测本身就是一种过度拟合?
这也许是一个絮絮叨叨的专题,跟大伙儿唠一唠量化相关的小问题,有感而发写到哪算哪,这是第一期,先唠个10块钱的~ 前段时间在某乎上看到这样一个问题『您怎么理解回测本身就是一种过度拟合?』 个人看来,回测本…...

什么是Arduino?
Arduino是一款便捷灵活、方便上手的开源电子原型平台,由欧洲的一个开发团队于2005年冬季开发。以下是关于Arduino的详细介绍: 一、基本概述 定义:Arduino是一个基于开放源代码的软硬件平台,它让电子设计更加简单快捷。通过Arduin…...

【机器学习基础】Scikit-learn主要用法
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,…...
python-素数回文数的个数(赛氪OJ)
[题目描述] 求 11 到 n 之间(包括 n),既是素数又是回文数的整数有多少个。输入: 一个大于 11 小于 10000 的整数 n。输出: 11 到 n 之间的素数回文数个数。样例输入1 23 样例输出1 1 提示: 回文数指左右对…...
-网格划分算法)
OCC 网格化(二)-网格划分算法
目录 一、概述 二、详解 1. 线性偏转 (Linear Deflection) 2. 角偏转 (Angular Deflection) 三、示例 3.1 示例1 3.2 示例2 一、概述 在 Open CASCADE Technology (OCC) 中默认的网格划分算法BRepMesh_IncrementalMesh有两个主要的选项来定义三角剖分—线性和角偏转。 …...

pyecharts模块
PyEcharts 一个基于ECharts库的Python封装库,它使得开发者可以方便地在Python环境中创建交互式的图表,包括折线图、柱状图、饼图、地图等多种可视化效果。 优点: 易用性:PyEcharts提供了简单易懂的API,通过链式调用…...

深⼊理解指针(3)
1. 字符指针变量 2. 数组指针变量 3. ⼆维数组传参的本质 4. 函数指针变量 5. 函数指针数组 6. 转移表 1. 字符指针变量 在指针的类型中我们知道有⼀种指针类型为字符指针 ⼀般使⽤: char* 这两种方式都是把字符串中的首字符的地址赋值给pc。 在这串代码中 str1内容的地…...

黑马头条vue2.0项目实战(四)——首页—文章列表
目录 1. 头部导航栏 1.1 页面布局 1.2 样式调整中遇到的问题 2. 频道列表 2.1 页面布局 2.2 样式调整 2.3 展示频道列表 3. 文章列表 3.1 思路分析 3.2 使用 List 列表组件 3.3 加载文章列表数据 3.4 下拉刷新 3.5 设置上下padding固定头部和频道列表 3.6 记住列…...

UE5.4内容示例(4)UI_UMG - 学习笔记
https://www.unrealengine.com/marketplace/zh-CN/product/content-examples 《内容示例》是学习UE5的基础示例,可以用此熟悉一遍UE5的功能 UI示例 UI_UMG :基本UMGUI_CommonUI :UMG多层应用UI_SlatePostBuffer UI :FX的示例&…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

【UniApp小程序开发】解决无法使用Vue自定义指令的完美替代方案:权限组件封装
在 UniApp 开发中,你是否遇到过这样的困惑:明明在 Vue Web 项目中用得顺手的 v-permission 自定义指令,一到小程序端就完全失效?本文将深入剖析其原因,并提供一套可直接复用的组件化解决方案,让你在小程序中…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

Unity项目DrawCall降不下来?试试用Mesh Baker合并贴图集,保姆级图文教程
Unity性能优化实战:用Mesh Baker合并贴图集降低DrawCall全流程解析当你的Unity项目帧率开始卡顿,Profiler里DrawCall数字居高不下时,合并贴图集往往是解决问题的关键一步。本文将以一个实际项目为例,带你从零开始使用Mesh Baker的…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...

KMS智能激活工具:如何一键永久激活Windows和Office的完整指南
KMS智能激活工具:如何一键永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题而烦恼吗?每次系统重装后都要…...