PyFilesystem2 - Python 操作文件系统
文章目录
- 一、关于 PyFilesystem2
- 二、安装
- 三、快速使用
- 四、指南
- 为什么要使用 PyFilesystem ?
- 打开文件系统
- 树打印
- 关闭
- 目录信息
- 子目录
- 处理文件
- 遍历 Walking
- Globbing
- 移动和复制
- 五、概念
- 路径
- 系统路径
- 沙盒
- 错误
- 六、资源信息
- 信息对象
- 命名空间
- 基本命名空间
- 细节命名空间
- 访问命名空间
- Stat命名空间
- LStat命名空间
- 链接命名空间
- 其他命名空间
- 缺少命名空间
- 原始信息
- 七、FS URL
- 格式
- URL参数
- 打开FS URL
- 手动注册Openers
- 八、Walking 遍历
- 步行方法
- 搜索算法
- 九、Globbing
- 匹配文件和目录
- 接口
- 批处理方法
- 十、文件系统API
一、关于 PyFilesystem2
Python的文件系统抽象层。
- github : https://github.com/PyFilesystem/pyfilesystem2
- 官方文档:https://docs.pyfilesystem.org/en/latest/
- 官网: https://www.pyfilesystem.org/
- blog : https://www.willmcgugan.com/tag/fs/
- 贡献者 : https://github.com/PyFilesystem/pyfilesystem2/blob/master/CONTRIBUTORS.md
二、安装
您可以使用pip安装PyFilessystem,如下所示:
pip install fs
或升级到最新版本:
pip install fs --upgrade
在conda上也可以使用PyFilessystem:
conda install fs -c conda-forge
或者,如果您想从源代码安装,您可以检查 从Github的代码。
三、快速使用
将 PyFilessystem 的 FS 对象 视为下一个逻辑步骤 Python的file对象。
就像文件对象 抽象一个 单个文件,FS 对象抽象出整个文件系统。
让我们看一段简单的代码作为示例。
以下函数使用 PyFilessystem API 计算非空白的数量目录中的Python代码行。
它递归地工作,所以它会 在所有子目录中查找 .py文件。
def count_python_loc(fs):"""Count non-blank lines of Python code."""count = 0for path in fs.walk.files(filter=['*.py']):with fs.open(path) as python_file:count += sum(1 for line in python_file if line.strip())return count
我们可以这样调用 count_python_loc:
from fs import open_fsprojects_fs = open_fs('~/projects')print(count_python_loc(projects_fs))
project_fs = open_fs('~/projects') 行打开一个FS对象 映射到主文件夹中的projects目录。
该对象是 由 count_python_loc 在计算代码行数时使用。
要计算 zip 文件中 Python 代码的行数,我们可以进行以下更改:
projects_fs = open_fs('zip://projects.zip')
或者计算 FTP服务器上 的Python行数:
projects_fs = open_fs('ftp://ftp.example.org/projects')
不需要更改 count_python_loc,因为 PyFileystem 为类似于 文件和目录的集合。
本质上,它允许你写 独立于文件物理位置和方式的代码 存储。
与纯粹使用标准库的版本形成对比:
def count_py_loc(path):count = 0for root, dirs, files in os.walk(path):for name in files:if name.endswith('.py'):with open(os.path.join(root, name), 'rt') as python_file:count += sum(1 for line in python_file if line.strip())return count
此版本类似于上面的 PyFilessystem 代码,但只会 使用操作系统文件系统。
任何其他文件系统都需要 完全不同的API,您可能必须重新实现 os. walk的目录os.walk。
四、指南
PyFilesytem接口简化了处理文件和目录的大部分方面。
本指南涵盖了您需要了解的有关使用FS对象的知识。
为什么要使用 PyFilesystem ?
如果您习惯使用Python标准库,您可能想知道;为什么要学习另一个处理文件的API?
一般来说,PyFilesystem API比os和io模块更简单,边缘情况更少,搬起石头砸自己的脚的方法也更少。
这可能是使用它的唯一原因,但还有其他令人信服的原因,即使是简单的文件系统代码也应该使用import fs。
FS对象提供的抽象意味着您可以编写与文件物理位置无关的代码。
例如,如果您编写了一个在目录中搜索重复文件的函数,它将与硬盘驱动器上的目录、zip文件、FTP服务器上的目录、Amazon S3等保持不变。
只要您选择的文件系统(或任何类似于文件系统的数据存储)存在FS对象,您就可以使用相同的API。
这意味着您可以将有关数据存储位置的决定推迟到以后。
如果您决定将配置存储在云中,它可能是单行更改,而不是主要重构。
PyFilessystem也有利于单元测试;通过将操作系统文件系统与内存文件系统交换,您可以编写测试,而无需管理(或模拟)文件IO。
您可以确保您的代码可以在Linux、MacOS和Windows上运行。
打开文件系统
有两种方法可以打开文件系统。
第一种也是最自然的方法是导入适当的文件系统类并构造它。
以下是如何打开 OSFS(操作系统文件系统),它映射到硬盘驱动器的文件和目录:
from fs.osfs import OSFS
home_fs = OSFS("~/")
这将构造一个FS对象,用于管理给定系统路径下的文件和目录。
在本例中,'~/'是主目录的快捷方式。
以下是您在主目录中列出文件/目录的方式:
home_fs.listdir('/')
# ——> ['world domination.doc', 'paella-recipe.txt', 'jokes.txt', 'projects']
注意,listdir的参数是单个正斜杠,表示我们要列出文件系统的根,这是因为从home_fs的角度来看,根是我们用来构造OSFS的目录。
另请注意,它是正斜杠,即使在Windows上也是如此。
这是因为无论平台如何,FS路径都采用一致的格式。
分隔符和编码等详细信息被抽象出来。
有关详细信息,请参阅路径。
其他文件系统接口可能对其构造函数有其他要求。
例如,以下是打开FTP文件系统的方式:
from ftpfs import FTPFS
debian_fs = FTPFS('ftp.mirror.nl')
debian_fs.listdir('/')
# -> ['debian-archive', 'debian-backports', 'debian', 'pub', 'robots.txt']
打开文件系统对象的第二种也是更通用的方法是通过打开器从类似URL的语法打开文件系统。
这是打开主目录的另一种方法:
from fs import open_fs
home_fs = open_fs('osfs://~/')
home_fs.listdir('/')
# -> ['world domination.doc', 'paella-recipe.txt', 'jokes.txt', 'projects']
当您想将应用程序文件的物理位置存储在配置文件中时,opener系统特别有用。
如果您没有在FS URL中指定协议,那么PyFilessystem将假定您想要当前工作目录中的OSFS相对对象。
因此,以下是打开主目录的等效方法:
from fs import open_fs
home_fs = open_fs('.')
home_fs.listdir('/')
# -> ['world domination.doc', 'paella-recipe.txt', 'jokes.txt', 'projects']
树打印
在FS对象上调用tree() 将打印文件系统的ascii树视图。
from fs import open_fs
my_fs = open_fs('.')
my_fs.tree()├── locale
│ └── readme.txt
├── logic
│ ├── content.xml
│ ├── data.xml
│ ├── mountpoints.xml
│ └── readme.txt
├── lib.ini
└── readme.txt
这可能是一个有用的调试帮助!
关闭
FS对象有一个close()方法,它将执行任何所需的清理操作。
对于许多文件系统(尤其是OSFS),close方法做的很少。
其他文件系统可能只在调用close()后才最终确定文件或释放资源。
使用完文件系统后,可以显式调用close。
home_fs = open_fs('osfs://~/')
home_fs.writetext('reminder.txt', 'buy coffee')
home_fs.close()
如果你使用FS对象作为上下文管理器,close将被自动调用。
下面等价于前面的例子:
with open_fs('osfs://~/') as home_fs:
... home_fs.writetext('reminder.txt', 'buy coffee')
建议使用FS对象作为上下文管理器,因为它将确保关闭每个FS。
目录信息
文件系统对象有一个listdir()方法,类似于os.listdir;它获取目录的路径并返回文件名列表。
home_fs.listdir('/projects')
['fs', 'moya', 'README.md']
存在列出目录的替代方法;scandir()返回可迭代对象的资源信息。
directory = list(home_fs.scandir('/projects'))
directory
[<dir 'fs'>, <dir 'moya'>, <file 'README.md'>]
与文件名相比,info对象有许多优点。
例如,您可以判断info对象是否引用具有is_dir属性的文件或目录,而无需额外的系统调用。
如果您在namespaces参数中请求,Info对象还可能包含大小、修改时间等信息。
注:之所以scandir返回可迭代而不是列表,是因为如果目录非常大,或者必须通过网络检索信息,那么以块的形式检索目录信息会更有效。
此外,FS对象有一个filterdir()方法,该方法扩展了scandir,能够通过通配符过滤目录内容。
code_fs = OSFS('~/projects/src')
directory = list(code_fs.filterdir('/', files=['*.py']))
默认情况下,scandir和listdir返回的资源信息对象将仅包含文件名和is_dir标志。
您可以使用namespaces参数请求其他信息。
以下是请求其他详细信息(如文件大小和文件修改时间)的方法:
directory = code_fs.filterdir('/', files=['*.py'], namespaces=['details'])
这将向资源信息对象添加size和modified属性(以及其他)。
这使得这样的代码工作:
sum(info.size for info in directory)
有关详细信息,请参阅资源信息。
子目录
PyFilessystem没有当前工作目录的概念,因此您不会在FS对象上找到chdir方法。
幸运的是,您不会错过它;使用PyFilessystem处理子目录轻而易举。
您始终可以使用接受路径的方法指定目录。
例如,home_fs.listdir('/projects')将获取 projects目录的目录列表。
或者,您可以调用opendir(),它为子目录返回一个新的FS对象。
例如,以下是如何在主目录中列出projects文件夹的目录内容:
home_fs = open_fs('~/')
projects_fs = home_fs.opendir('/projects')
projects_fs.listdir('/')
# ——> ['fs', 'moya', 'README.md']
当您调用opendir时,FS对象返回一个SubFS实例。
如果您调用SubFS对象上的任何方法,就好像您在父文件系统上调用了与子目录相关的路径相同的方法。
对于新创建的目录,makedir和makedirs 方法也返回SubFS对象。
下面介绍如何在~/projects中创建一个新目录,并使用几个文件对其进行初始化:
home_fs = open_fs('~/')
game_fs = home_fs.makedirs('projects/game')
game_fs.touch('__init__.py')
game_fs.writetext('README.md', "Tetris clone")
game_fs.listdir('/')
# ——> ['__init__.py', 'README.md']
使用SubFS对象 意味着您通常可以避免编写太多路径操作代码,这往往容易出错。
处理文件
您可以使用open()从FS对象打开文件,这与标准库中的io.open非常相似。
以下是如何在主目录中打开一个名为“提醒”的文件:
with open_fs('~/') as home_fs:
... with home_fs.open('reminder.txt') as reminder_file:
... print(reminder_file.read())
# ——> buy coffee
对于OSFS,将返回一个标准的类似文件的对象。
其他文件系统可能返回支持相同方法的不同对象。
例如,MemoryFS 将返回一个io.BytesIO对象。
PyFilesystem 还为常见的文件相关操作提供了许多快捷方式。
例如,readbytes() 将以字节形式返回文件内容,而readtext() 将读取unicode文本。
这些方法通常比显式打开文件更可取,因为FS对象可能具有优化的实现。
其他快捷方式是download(),upload(),writebytes(),writetext()。
遍历 Walking
通常,您需要扫描给定目录和任何子目录中的文件。
这称为遍历文件系统。
以下是如何打印主目录中所有Python文件的路径:
from fs import open_fs
home_fs = open_fs('~/')
for path in home_fs.walk.files(filter=['*.py']):
... print(path)
FS对象上的walk属性是BoundWalker的实例,它应该能够处理大多数目录遍历需求。
有关步行目录的更多信息,请参阅步行。
Globbing
与遍历文件系统密切相关的是 global,这是一种稍高级别的扫描文件系统的方式。
路径可以通过 glob 模式过滤,这类似于通配符(如*.py),但可以匹配目录结构的多个级别。
这是一个 globbing 示例,它会删除项目目录中的所有.pyc文件:
from fs import open_fs
open_fs('~/project').glob('**/*.pyc').remove()
# ——> 62
有关更多信息,请参阅Globbing。
移动和复制
您可以移动和复制文件内容 与 move() 和 copy()方法,以及等效的movedir() 和 copydir() 方法操作目录而不是文件。
这些移动和复制方法在可能的情况下进行了优化,并且根据实现,它们可能比读取和写入文件更高性能。
要在文件系统之间 移动 和/或 复制 文件(如在同一文件系统中),请使用move 和 copy 模块。
这些模块中的方法接受 FS 对象和 FS URL。
例如,以下内容将压缩项目文件夹的内容:
from fs.copy import copy_fs
copy_fs('~/projects', 'zip://projects.zip')
这相当于这个更冗长的代码:
from fs.copy import copy_fs
from fs.osfs import OSFS
from fs.zipfs import ZipFS
copy_fs(OSFS('~/projects'), ZipFS('projects.zip'))
copy_fs()和copy_dir()函数也接受Walker参数,您可以使用它来过滤将要复制的文件。
例如,如果您只想备份python文件,您可以使用如下内容:
from fs.copy import copy_fs
from fs.walk import Walker
copy_fs('~/projects', 'zip://projects.zip', walker=Walker(filter=['*.py']))
复制的另一种选择是镜像,它将复制文件系统,它们通过仅复制更改的文件/目录来保持最新。
参见mirror()。
五、概念
下面描述了使用 PyFilessystem 时的一些核心概念。
如果您要浏览此文档,请特别注意路径的第一部分。
路径
除了构造函数可能的例外,文件系统中的所有路径都是PyFilessystem路径,它们具有以下属性:
- 路径在Python3中是
str类型,在Python2中是unicode。 - 路径组件由正斜杠(
/)分隔 - 以a
/开头的路径是绝对的 - 不以正斜杠开头的路径是相对的
- 一个点(
.)表示当前目录 - 双点(
..)表示以前的目录
请注意,FS接口使用的路径将使用这种格式,但 特别是OSFS构造函数 需要一个操作系统路径-其格式取决于平台。
注:有许多有用的函数可以在 path模块。
PyFilessystem 路径 platform-independent,并将自动转换为操作系统期望的格式 —— 因此您无需对文件系统代码进行任何修改即可使其在其他平台上运行。
系统路径
并非所有Python模块都可以使用类似文件的对象,尤其是那些 与C库接口。
对于这些情况,您需要 检索系统路径。
您可以使用 getsyspath() 方法,用于转换 FS对象到绝对路径的上下文,该路径将被理解 你的操作系统。
例如:
from fs.osfs import OSFS
home_fs = OSFS('~/')
home_fs.getsyspath('test.txt')
# ——> '/home/will/test.txt'
并非所有文件系统都映射到系统路径(例如, MemoryFS只会存在于内存中)。
如果调用getsyspath的文件系统不映射到系统 路径,它将引发NoSysPath异常。
如果你 喜欢一个看之前你飞跃方法,你可以检查如果一个资源 有一个系统路径通过调用hassyspath()
沙盒
不允许FS对象处理其之外的任何文件 根。
如果您尝试打开外部的文件或目录 文件系统实例(带有一个backref,例如"../foo.txt"),一个 IllegalBackReference 将抛出异常。
这 确保任何使用FS对象的代码都无法读取或修改 任何你不打算做的事情,从而限制了任何错误的范围。
与您的操作系统不同,中没有当前工作目录的概念 PyFilessystem。
如果要使用FS对象的子目录, 您可以使用opendir()方法返回另一个 表示该子目录内容的FS对象。
例如,考虑以下目录结构。
目录 foo包含两个子目录;bar和baz:
--foo |--bar | |--readme.txt | `--photo.jpg`--baz |--private.txt`--dontopen.jpg
我们可以使用以下代码打开foo目录:
from fs.osfs import OSFS
foo_fs = OSFS('foo')
该foo_fs对象可以处理bar和 baz,如果我们把foo_fs交给一个 有可能删除文件的函数。
幸运的是,我们可以 使用opendir()隔离单个opendir() 方法:
bar_fs = foo_fs.opendir('bar')
这将创建一个全新的FS对象,该对象代表 的foo/bar目录。
bar_fs的根目录已被重新- 位置,以便从bar_fs的角度来看,readme. txt和 Photo. jpg文件在根目录中:
--bar |--readme.txt`--photo.jpg
注:此沙盒仅在您的代码独占使用文件系统接口时才有效。
它不会阻止使用标准操作系统级别文件操作的代码。
错误
PyFilessystem将错误转换为常见的异常层次结构。
这 确保错误处理代码可以编写一次,无论 正在使用的文件系统。
有关详细信息,请参阅errors。
六、资源信息
资源信息(或信息)描述标准文件详细信息,例如名称、类型、大小等,以及可能与文件或目录关联的其他不太常见的信息。
您可以通过调用来检索单个资源的资源信息 getinfo(),或通过调用scandir() 它返回内容的资源信息迭代器 此外,filterdir()可以过滤 按类型和通配符划分的目录中的资源。
以下是检索文件信息的示例:
from fs.osfs import OSFS
fs = OSFS('.')
fs.writetext('example.txt', 'Hello, World!')
info = fs.getinfo('example.txt', namespaces=['details'])
info.name
# ——> 'example.txt'
info.is_dir
# ——> False
info.size
# ——> 13
信息对象
PyFilessystem通过以下属性公开资源信息 Info对象。
命名空间
所有资源信息都包含在许多潜在命名空间之一中,这些命名空间是逻辑键/值组。
您可以使用 getinfo()参数到namespaces。
例如 以下检索details和access命名空间 文件:
resource_info = fs.getinfo('myfile.txt', namespaces=['details', 'access'])
除了指定的命名空间,文件系统还将返回 包含资源名称的basic命名空间,以及 指示资源是否为目录的标志。
基本命名空间
总是返回basic命名空间 钥匙:
| 名称 | 类型 | 描述 |
|---|---|---|
| 名称 | str | 资源的名称。 |
| is_dir | bool | 指示资源是否为目录的布尔值。 |
此命名空间中的键通常可以非常快速地检索。
在 在OSFS的情况下,可以在没有 一个潜在昂贵的系统调用。
细节命名空间
该details命名空间包含以下键。
| 名称 | 类型 | 描述 |
|---|---|---|
| 访问 | 日期时间 | 上次访问文件的时间。 |
| 创建 | 日期时间 | 文件创建的时间。 |
| metadata_changed | 日期时间 | 最后一次元数据(例如所有者、组)更改的时间。 |
| 修改 | 日期时间 | 最后一次更改时间文件数据。 |
| 大小 | int | 用于存储资源的字节数。 |
| 对于文件,这是文件中的字节数。 | ||
| 对于目录,大小是用于存储目录条目的开销(以字节为单位)。 | ||
| 类型 | ResourceType | 资源类型,值之一 在ResourceType。 |
时间值(accessed_time、created_time等)可能是 None,如果文件系统不存储该信息。
size 和type键保证可用,尽管type可能 是unknown的,如果文件系统无法 检索资源类型。
访问命名空间
该access命名空间报告权限和所有权信息, 并包含以下键。
| 名称 | 类型 | 描述 |
|---|---|---|
| gid | int | 组ID. |
| group | str | 组名称. |
| 权限 | 权限 | 的一个实例 Permissions, 其中包含对 资源。 |
| uid | int | 用户ID。 |
| user | str | 所有者的用户名。 |
此命名空间是可选的,因为并非所有文件系统都有以下概念 所有权或权限。
OSFS支持。
一些 如果文件系统不支持,值可能None。
Stat命名空间
此stat命名空间包含调用 OS.stat。
这个命名空间是由OSFS 和可能的其他 直接映射到操作系统文件系统的文件系统。
大多数其他 文件系统将不支持此命名空间。
LStat命名空间
此lstat命名空间包含调用 OS. lstat.这个 命名空间是由OSFS和可能的其他 直接映射到操作系统文件系统的文件系统。
大多数其他 文件系统将不支持此命名空间。
链接命名空间
该link命名空间包含有关符号链接的信息。
| 名称 | 类型 | 描述 |
|---|---|---|
| 目标 | str | 符号链接目标的路径,如果None则 此路径不是符号链接。 注意,这个目标的意义有些 文件系统相关,并且可能不是有效的 FS对象上的路径。 |
其他命名空间
某些文件系统可能支持此处未涵盖的其他命名空间。
有关支持哪些命名空间的信息,请参阅特定文件系统的文档。
您可以检索此类实现特定的资源信息 使用get()方法。
注:请求文件系统不支持的命名空间(或多个命名空间)不是错误。
任何未知的命名空间都将被忽略。
缺少命名空间
Info对象上的某些属性要求给定的命名空间是 存在。
如果您尝试在没有命名空间的情况下引用它们 存在(因为您没有请求它,或者文件系统没有 支持它)然后一个MissingInfoNamespace例外 将被抛出。
以下是您处理此类异常的方法:
try:print('user is {}'.format(info.user))
except errors.MissingInfoNamespace:# No 'access' namespacepass
如果你更喜欢在跳跃前看一眼,你可以使用 has_namespace()方法。
这是一个例子:
if info.has_namespace('access'):print('user is {}'.format(info.user))
有关info属性的详细信息,请参见Info。
原始信息
这个Info类是一个简单数据的包装器 包含原始信息的结构。
您可以使用 的info.raw属性。
注:以下内容可能仅在您打算自己实现文件系统时才感兴趣。
原始信息数据由一个字典组成,该字典将命名空间名称映射到信息字典上。
这是一个例子:
{'access': {'group': 'staff','permissions': ['g_r', 'o_r', 'u_r', 'u_w'],'user': 'will'},'basic': {'is_dir': False,'name': 'README.txt'},'details': {'accessed': 1474979730.0,'created': 1462266356.0,'metadata_changed': 1473071537.0,'modified': 1462266356.0,'size': 79,'type': 2}
}
原始资源信息仅包含基本类型(字符串、数字、列表、判决、无)。
这使得资源信息很容易通过网络发送,因为它可以简单地序列化为JSON或其他数据格式。
由于这个要求,时间存储为 ***********. Info对象 将这些转换为标准库中的日期时间对象。
此外,Info对象将从列表中转换权限 字符串到Permissions对象。
七、FS URL
Py文件系统可以通过FS URL打开文件系统,这类似于您可能在浏览器中输入的URL。
如果您想动态指定文件系统,例如在conf文件中或从命令行中,FS URL很有用。
格式
FS URL的格式如下:
<protocol>://<username>:<password>@<resource>
组成部分如下:
<protocol>标识要创建的文件系统的类型。
例如osfs,ftp。<username>可选用户名。<password>可选密码。<resource>一种资源,可以是域、路径或两者。
这里有几个例子:
osfs://~/projects
osfs://c://system32
ftp://ftp.example.org/pub
mem://
ftp://will:daffodil@ftp.example.org/private
如果未指定<type>,则假定它是一个OSFS,即以下FS URL是等效的:
osfs://~/projects
~/projects
注:在username和passwords字段中不能包含冒号(:)或@符号。
如果需要这些符号,可以按百分比编码。
URL参数
FS URL也可以附加一个?符号,后跟一个url编码的查询字符串。
例如:
myprotocol://example.org?key1=value1&key2
查询字符串将被解码为{"key1": "value1", "key2": ""}。
查询字符串用于提供打开时使用的附加文件系统特定信息。
有关支持哪些查询字符串参数的信息,请参阅文件系统文档。
打开FS URL
要使用FS URL打开文件,可以使用open_fs(),可以按如下方式导入和使用:
from fs import open_fs
projects_fs = open_fs('osfs://~/projects')
手动注册Openers
在fs.opener注册表中使用切入点来安装外部打开器 (参见创建一个扩展),它只做一次,当你导入第一个fs时 时间。
在一些入口点不可用的罕见情况下(例如, 运行嵌入式解释器时)或安装扩展后 解释器已启动(例如在笔记本中,请参阅 PyFilesystem2#485)。
但是,可以随时手动安装新的开瓶器 fs.opener.registry.install 方法 可以将s3fs扩展添加到 注册表:
import fs.opener
from fs_s3fs.opener import S3FSOpenerfs.opener.registry.install(S3FSOpener)
# fs.open_fs("s3fs://...") should now work
八、Walking 遍历
遍历文件系统意味着递归访问目录和任何子目录。
这是复制、搜索等相当常见的要求。
要遍历文件系统(或目录),您可以构造一个Walker对象并使用其方法进行遍历。
以下示例打印项目目录中每个Python文件的路径:
from fs import open_fs
from fs.walk import Walker
home_fs = open_fs('~/projects')
walker = Walker(filter=['*.py'])
for path in walker.files(home_fs):
... print(path)
然而,一般来说,如果您想自定义步行算法的某些行为,您只需要构造一个Walker对象。
这是因为您可以通过FS对象上的walk属性访问Walker对象的功能。
这里有一个例子:
from fs import open_fs
home_fs = open_fs('~/projects')
for path in home_fs.walk.files(filter=['*.py']):
... print(path)
注意上面的files方法不需要fs参数,这是因为walk属性是一个返回BoundWalker对象的属性,该对象将文件系统与walker相关联。
步行方法
如果在BoundWalker上调用walk属性,它将返回具有三个值的Step命名元组的可迭代对象;目录的路径、目录的Info对象列表和文件的Info对象列表。
for step in home_fs.walk(filter=['*.py']):print('In dir {}'.format(step.path))print('sub-directories: {!r}'.format(step.dirs))print('files: {!r}'.format(step.files))
注:BoundWalker的方法使用绑定文件系统调用Walker对象上的相应方法。
这个walk属性看上去是一个方法,但实际上是一个可调用的对象。
它支持其他方便的方法,可以提供不同于walk的信息。
例如,files(),它返回一个可迭代的文件路径。
下面是一个例子:
for path in home_fs.walk.files(filter=['*.py']):print('Python file: {}'.format(path))
对files的补充是dirs(),它只返回目录的路径(忽略文件)。
for dir_path in home_fs.walk.dirs():print("{!r} contains sub-directory {}".format(home_fs, dir_path))
该info()方法返回一个元组生成器,其中包含一个路径和一个Info对象。
您可以使用is_dir属性来知道路径是否引用目录或文件。
for path, info in home_fs.walk.info():if info.is_dir:print("[dir] {}".format(path))else:print("[file] {}".format(path))
最后,这是一个计算主目录中Python代码字节数的好例子:
bytes_of_python = sum(info.sizefor info in home_fs.walk.info(namespaces=['details'])if not info.is_dir
)
搜索算法
搜索目录树有两种通用算法。
第一种方法是"breadth",它首先产生目录树顶部的资源,然后再移动到子目录。
第二种是"depth",它产生嵌套最深的资源,并向后工作到最顶部的目录。
一般来说,只有在浏览资源时删除资源时才需要深度搜索。
默认的广度搜索通常是查看文件系统的更有效方法。
您可以使用大多数Walker方法的search参数指定所需的方法。
九、Globbing
Globbing 是根据 Unix shell使用的规则匹配路径的过程。
一般来说,您可以将全局模式视为包含一个或多个通配符模式的路径,由正斜杠分隔。
匹配文件和目录
在全局模式中,A*表示匹配文件名中的任何文本。
? 匹配任意单个字符。
**匹配任意数量的子目录, 使全局递归。
如果全局模式以/结尾,它会 只匹配目录路径,否则会匹配文件和目录。
注:递归全局需要PyFilessystem扫描大量文件,对于大型(或基于网络的)文件系统来说可能会很慢。
以下是全局模式的摘要:
*: 匹配当前目录中的所有文件。*.py: 匹配当前目录中的所有. py文件。*.py?: 匹配当前目录中的所有. py文件和.pyi、.pyc等。project/*.py: 匹配名为project的目录中的所有. py文件。*/*.py: 匹配任何子目录中的所有. py文件。**/*.py: 递归匹配所有. py文件。**/.git/: 递归匹配所有git目录。
接口
PyFilessystem支持通过每个FS上的glob属性进行全局化 实例,这是BoundGlobber的一个实例。
这里 如何使用它来查找文件系统中的所有Python文件:
for match in my_fs.glob("**/*.py"):print(f"{match.path} is {match.info.size} bytes long")
使用模式调用.glob将返回一个迭代器 GlobMatch为每个匹配文件命名元组或 目录。
全局匹配包含两个属性;path是 文件系统中的完整路径,以及info是 fs.info.Info匹配资源的info对象。
批处理方法
除了迭代结果之外,您还可以调用方法 适用于每个匹配路径的Globber。
例如,以下是如何使用Glob删除所有.pyc文件 从项目目录:
import fs
fs.open_fs('~/projects/my_project').glob('**/*.pyc').remove()
29
下一个上一页
十、文件系统API
以下是PyFilessystem对象上的方法的完整列表。
appendbytes()将字节附加到文件。appendtext()将文本附加到文件。check()检查文件系统是否打开或引发错误。close()关闭文件系统。copy()将文件复制到另一个位置。copydir()将目录复制到另一个位置。create()创建或截断文件。desc()获取资源的描述。download()将文件系统上的文件复制到类似文件的对象。exists()检查路径是否存在。filterdir()迭代资源,按通配符过滤。getbasic()获取资源的基本信息命名空间。getdetails()获取资源的详细信息命名空间。getinfo()获取有关文件或目录的信息。getmeta()获取资源的元信息。getmodified()获取资源的最后修改时间。getospath()获取操作系统期望的编码路径。getsize()获取文件的大小。getsyspath()获取资源的系统路径(如果存在)。gettype()获取资源的类型。geturl()获取资源的URL(如果存在)。hassyspath()检查资源是否映射到操作系统文件系统。hash()获取文件内容的哈希值。hasurl()检查资源是否具有URL。isclosed()检查文件系统是否关闭。isempty()检查目录是否为空。isdir()检查路径是否映射到目录。isfile()检查路径是否映射到文件。islink()检查path是否为链接。listdir()获取目录中的资源列表。lock()获取线程锁上下文管理器。makedir()创建一个目录。makedirs()创建目录和中间目录。match()根据路径匹配一个或多个通配符模式。move()将文件移动到另一个位置。movedir()将目录移动到另一个位置。open()在文件系统上打开一个文件。openbin()打开一个二进制文件。opendir()获取目录的文件系统对象。readbytes()以字节形式读取文件。readtext()将文件作为文本读取。remove()删除一个文件。removedir()删除一个目录。removetree()递归删除文件和目录。scandir()扫描文件和目录。setinfo()设置资源信息。settimes()设置资源的修改时间。touch()创建文件或更新时间。tree()呈现文件系统的树形视图。upload()将二进制文件复制到文件系统。validatepath()检查路径是否有效并返回归一化路径。writebytes()将文件写入字节。writefile()将类似文件的对象写入文件系统。writetext()将文件写成文本。
2024-08-03(六)
相关文章:

PyFilesystem2 - Python 操作文件系统
文章目录 一、关于 PyFilesystem2二、安装三、快速使用四、指南为什么要使用 PyFilesystem ?打开文件系统树打印关闭目录信息子目录处理文件遍历 WalkingGlobbing移动和复制 五、概念路径系统路径沙盒错误 六、资源信息信息对象命名空间基本命名空间细节命名空间访问…...

Bug小记:关于servlet后端渲染界面时出现的问题小记1P
问题1: 问题描述: int delete(Integer Sno);后端在该方法调用时传入参数 req.getParameter("Sno")报错参数应该为Integer类型问题分析:后端通过请求获取到的前端数据都是字符串类型,需要手动转换参数类型 解决方法&a…...

智慧水务项目(二)django(drf)+angular 18 创建通用model,并对orm常用字段进行说明
一、说明 上一篇文章建立一个最简单的项目,现在我们建立一个公共模型,抽取公共字段,以便于后续模块继承,过程之中会对orm常用字段进行说明,用到的介绍一下 二、创建一个db.py 目录如下图 1、代码 from importlib im…...

<数据集>人员摔倒识别数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:8605张 标注数量(xml文件个数):8605 标注数量(txt文件个数):8605 标注类别数:1 标注类别名称:[fall] 序号类别名称图片数框数1fall860512275 使用标注工具…...

npm install 报错 ‘proxy‘ config is set properly. See: ‘npm help config‘
解决 参考链接:npm install 报错 ‘proxy‘ config is set properly. See: ‘npm help config‘-阿里云开发者社区 (aliyun.com)...

爬虫问题---ChromeDriver的安装和使用
一、安装 1.查看chrome的版本 在浏览器里面输入 chrome://version/ 回车查看浏览器版本 Chrome的版本要和ChromeDriver的版本对应,否则会出现版本问题。 2.ChromeDriver的版本选择 114之前的版本:https://chromedriver.storage.googleapis.com/index.ht…...

Spring的配置类分为Full和Lite两种模式
Spring的配置类分为Full和Lite两种模式 首先查看 Configuration 注解的源码, 如下所示: Target({ElementType.TYPE}) Retention(RetentionPolicy.RUNTIME) Documented Component public interface Configuration {AliasFor(annotation Component.class)String value() defau…...

探索Perl的代码生成艺术:利用编译器后端释放潜能
探索Perl的代码生成艺术:利用编译器后端释放潜能 Perl,作为一种解释型语言,通常不通过编译器后端直接生成机器代码。然而,通过一些高级技术,Perl 程序员可以利用编译器后端来生成代码,从而提高性能或实现特…...
)
21 B端产品经理之技术常识(1)
产品经理需要掌握一些基本的技术知识。 了解公司前端与后端 前端 前端开发:创建WEB页面或APP等前端界面呈现给用户的过程,即前端负责用户界面交互。 前端技能: HTML:一种标记语言,能够实现Web页面并在浏览器中显示。…...
:单链表_定义_初始化_插入_删除_查找_建立操作_纯c语言代码注释讲解)
数据结构基础详解(C语言):单链表_定义_初始化_插入_删除_查找_建立操作_纯c语言代码注释讲解
单链表理论知识详解 文章目录 单链表理论知识详解1.单链表的定义2.单链表的初始化3.单链表的插入和删除3.1 单链表的插入3.1.1 按位序插入3.1.2 在指定结点的前后插入一.后插操作二.前插操作 4.单链表的删除4.1 按位序删除4.2 指定结点的删除 5.单链表的查找5.1 按位序查找5.2 …...

【智能时代的创新工具】LangChain快速入门指南:轻松掌握语言模型的集成与运用
一、LangChain:连接语言模型与现实世界的桥梁 1.1 LangChain的定义与重要性 LangChain是一个开源的Python库,它旨在为开发人员提供一种简便的方式来集成和运用语言模型。它不仅仅是一个简单的API调用工具,而是一个具有丰富功能的框架&#x…...

文献阅读:细胞分辨率全脑图谱的交互式框架
文献介绍 文献题目: An interactive framework for whole-brain maps at cellular resolution 研究团队: Daniel Frth(瑞典卡罗林斯卡学院)、Konstantinos Meletis(瑞典卡罗林斯卡学院) 发表时间ÿ…...

YAML基础语言深度解析
引言 YAML(YAML Aint Markup Language,即YAML不是一种标记语言)是一种直观、易于阅读的数据序列化格式,常用于配置文件、数据交换和程序间的通信。其设计目标是易于人类阅读和编写,同时也便于机器解析和生成。在本文中…...

xcode使用
1. 界面 1.1. Build Settings,Build Phases和Build Rules三个设置项 Build Settings(编译设置): 每个选项由标题(Title)和定义(Definition)组成。这里主要定义了Xcode在编译项目时的一些具体配置 Build Phases(编译资源):用于指定编译过程中项目所链接的原文件,依赖对象,库…...

OV2640引脚的定义(OV2640 FPC模组规格书(接口线序))
OV2640是一款由Omni Vision公司生产的1/4寸CMOS UXGA(1632x1222)图像传感器。这款传感器以其小巧的体积、低工作电压和强大的功能而著称,它集成了单片UXGA摄像头和影像处理器,能够通过SCCB总线控制输出各种分辨率的8/10位影像数据…...

CTFSHOW 萌新 web10 解题思路和方法(passthru执行命令)
点击题目链接,分析页面代码。发现代码中过滤了system、exec 函数,这意味着我们不能通过system(cmd命令)、exec(cmd命令)的方式运行命令。 在命令执行中,常用的命令执行函数有: system(cmd_code);exec(cmd_…...

深入Java数据库连接和JDBC
引言 Java数据库连接(JDBC)是Java语言中用于执行SQL语句的标准API。通过JDBC,开发者可以方便地与关系型数据库进行交互。然而,直接使用JDBC API面临着数据库连接管理复杂、性能瓶颈等问题。数据库连接池作为一种解决方案,可以有效地管理数据库连接,提高应用程序的性能。…...
与长短期记忆网络(LSTM)结合的预测模型(GWO-LSTM)及其Python和MATLAB实现)
灰狼优化算法(GWO)与长短期记忆网络(LSTM)结合的预测模型(GWO-LSTM)及其Python和MATLAB实现
#### 一、背景 在现代数据科学和人工智能领域,预测模型的准确性和效率是研究者和工程师不断追求的目标,尤其是在时间序列预测、金融市场分析、气象预测等领域。长短期记忆(LSTM)网络是一种解决传统递归神经网络(RNN&a…...

电路板热仿真覆铜率,功率,结温,热阻率信息计算获取方法总结
🏡《电子元器件学习目录》 目录 1,概述2,覆铜率3,功率4,器件尺寸5,结温6,热阻1,概述 电路板热仿真操作是一个复杂且细致的过程,旨在评估和优化电路板内部的热分布及温度变化,以确保电子元件的可靠性和性能。本文简述在进行电路板的热仿真时,元器件热信息的计算方法…...

C#中多线程编程中的同步、异步、串行、并行及并发及死锁
在C#中,多线程编程是一个强大的功能,它允许程序同时执行多个任务。然而,这也带来了复杂性,特别是在处理同步、异步、串行、并行、并发以及死锁等问题时。下面我将详细解释这些概念,并给出一些C#中的示例和注意事项。 …...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
JDK 17 序列化是怎么回事
如何序列化?其实很简单,就是根据每个类型,用工厂类调用。逐个完成。 没什么漂亮的代码,只有有效、稳定的代码。 代码中调用toJson toJson 代码 mapper.writeValueAsString ObjectMapper DefaultSerializerProvider 一堆实…...
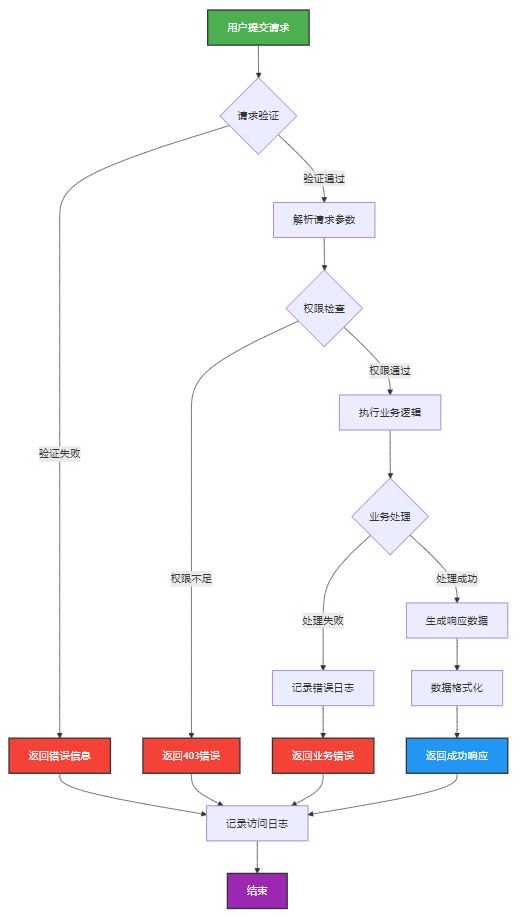
如何做好一份技术文档?从规划到实践的完整指南
如何做好一份技术文档?从规划到实践的完整指南 🌟 嗨,我是IRpickstars! 🌌 总有一行代码,能点亮万千星辰。 🔍 在技术的宇宙中,我愿做永不停歇的探索者。 ✨ 用代码丈量世界&…...
)
Electron简介(附电子书学习资料)
一、什么是Electron? Electron 是一个由 GitHub 开发的 开源框架,允许开发者使用 Web技术(HTML、CSS、JavaScript) 构建跨平台的桌面应用程序(Windows、macOS、Linux)。它将 Chromium浏览器内核 和 Node.j…...
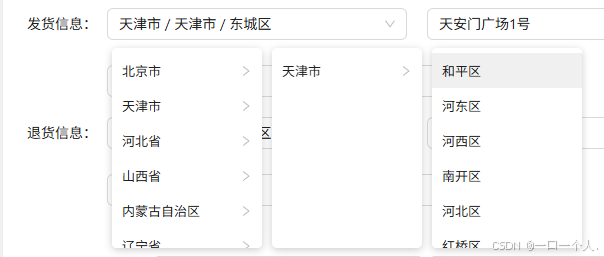
vue3 手动封装城市三级联动
要做的功能 示意图是这样的,因为后端给的数据结构 不足以使用ant-design组件 的联动查询组件 所以只能自己分装 组件 当然 这个数据后端给的不一样的情况下 可能组件内对应的 逻辑方式就不一样 毕竟是 三个 数组 省份 城市 区域 我直接粘贴组件代码了 <temp…...
)
GitHub 常见高频问题与解决方案(实用手册)
1.Push 提示权限错误(Permission denied) 问题: Bash Permission denied (publickey) fatal: Could not read from remote repository. 原因: 没有配置 SSH key 或使用了 HTTPS 而没有权限…...

rk3506上移植lvgl应用
本文档介绍如何在开发板上运行以及移植LVGL。 1. 移植准备 硬件环境:开发板及其配套屏幕 开发板镜像 主机环境:Ubuntu 22.04.5 2. LVGL启动 出厂系统默认配置了 LVGL,并且上电之后默认会启动 一个LVGL应用 。 LVGL 的启动脚本为/etc/init.d/pre_init/S00-lv_demo,…...
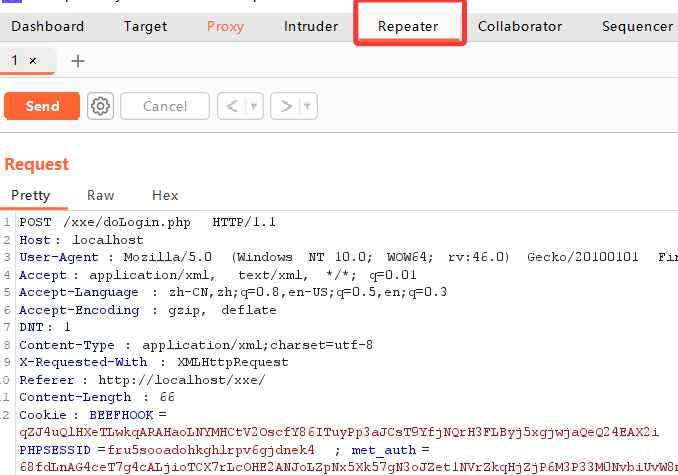
【靶场】XXE-Lab xxe漏洞
前言 学习xxe漏洞,搭了个XXE-Lab的靶场 一、搭建靶场 现在需要登录,不知道用户名密码,先随便试试抓包 二、判断是否存在xxe漏洞 1.首先登录抓包 看到xml数据解析,由此判断和xxe漏洞有关,但还不确定xxe漏洞是否存在。 2.尝试xxe 漏洞 判断是否存在xxe漏洞 A.send to …...