数据结构初阶(c语言)-排序算法
数据结构初阶我们需要了解掌握的几种排序算法(除了直接选择排序,这个原因我们后面介绍的时候会解释)如下:

其中的堆排序与冒泡排序我们在之前的文章中已经详细介绍过并对堆排序进行了一定的复杂度分析,所以这里我们不再过多介绍。
一,插入排序
1.1直接插入排序
1.1.1概念及实现代码
直接插入排序是⼀种简单的插⼊排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到⼀个新的有序序列 。
就像我们玩扑克牌一样,当我们将发给我们的牌拿到我们自己手中进行排序一样,当插⼊第 i(i>=1) 个元素时,前⾯的 array[0],array[1],…,array[i-1] 已经排好序,此时用array[i] 的排序码与 array[i-1],array[i-2],… 的排序码顺序进行比较,找到插入位置即将 array[i] 插入,原来位置上的元素顺序后移。实现代码如下:
void InsertSort(int* arr, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = arr[end + 1];while (end >= 0){if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else{break;}}arr[end + 1] = tmp;}
}从实现代码中我们不难看出, 直接插入的思想为先将前两个元素排好,再一个一个的往后进行,如果后面数据比我们上一次排好的数据的末尾数据大时,让末尾数据后移,再与末尾数据的前一个数据进行比较,直到找到小于的数据为止。插入的方法思想可以类比下我们顺序表中的头插法。
1.1.2复杂度的计算
空间复杂度由于未创建辅助空间,所以为O(1)。时间复杂度从代码中我们可以得知,最好情况下为O(N)(数组本身即为顺序),最坏的情况下(即数组逆序的情况下)为O(N^2)。所以直接插入的时间复杂度为O(N^2)。
1.2希尔排序
1.1.1概念及实现代码
希尔排序是对直接插入排序的改良,再原有的排序方式上加入预排序,以达到减小时间复杂度的目的,实现代码如下:
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;}}
}希尔排序一般先将原有数组分为三份,不断的三分对每份里面的数据进行排序,到了最后gap为1时数组已经基本有序,但我们不能直接设gap=n/3,比如我们的数组有效元素个数为9个,分三次之后为0,但我们需要让它的最后一次为一,所以我们的gap每次循环都设置为除三加以,从而确保最后进入循环的gap值为一。
1.1.2复杂度的简要计算
空间复杂度与直接插入一致为O(1)。而时间复杂度对于外层(预排序),我们可以联想树,一直三分其实时间复杂度就为树的深度h=logn。所以外层的时间复杂度为logn。对于内层的时间复杂度,博主智商有限,难以推出,因为它的gap能够取得的值太多了,从而导致内层的复杂度难以计算,所以我们直接给出希尔排序的粗略时间复杂度的估算:O(N^1.3)。需要详细推理过程的读者可以自行上网搜寻。
二,选择排序
这一部分我们不细讲,堆排序上篇文章已经详细介绍过,直接选择排序给出代码我们即可理解其思想:
void SelectSort(int* arr, int n)
{int begin = 0;int end = n - 1;while (begin < end){int max = begin;int min = begin;for(int i = begin;i <= end;i++){if (arr[max] < arr[i]){max = i;}if (arr[min] > arr[i]){min = i;}}if (max == begin){max = min;}Swap(&arr[min], &arr[begin]);Swap(&arr[max], &arr[end]);begin++;end--;}
}它的思想是逐步的将数据向中间集拢,第一遍找数组中的最大(小)值,并将最大(小)值分别放到头尾,接着让头++尾--。再次重复第一次的操作,最后直到没有数据为止。
可见直接选择排序,无论是最好的情况顺序还是最坏的情况逆序,他的时间复杂度均为O(N^2)。在实际学习与生产过程中都不可能使用,这也是我们简略介绍的原因。
三,快速排序
快速排序是Hoare于1962年提出的⼀种⼆叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均子于基准值,右子序列中所有元素均⼤于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
其实快速排序最主要的思想即为基准值,无限的二分去寻找基准值,与我们前面学习的二叉树非常类似。所以它的递归版本基础框架为(key为我们每次寻找到的基准值):
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}int key = _QuickSort3(arr, left, right);QuickSort(arr, left, key - 1);QuickSort(arr, key + 1, right);
}3.1hoare版本快排
hoare版本的思想为,开始设首数据为基准值,同时设左右指针,左边先找比基准值大的数据,找到停下,右边找比基准值小的数据,停下后于左指针的数据交换,循环下去,直到左指针的对应数组下标小于右指针截止。实现代码如下:
int _QuickSort1(int* arr, int left, int right)
{int key = left;++left;while (left <= right){while (left <= right && arr[left] < arr[key]){left++;}while (left <= right && arr[right] > arr[key]){right--;}if (left <= right){Swap(&arr[left++], &arr[right--]);}}Swap(&arr[right], &arr[key]);return right;
}为什么left=right时还要进入循环,是因为每次我们交换完后,right--,left++。万一此时它们正好重合,此处数据若小于或大于基准值都会导致最终基准值的落脚点错误。
3.2挖坑版本快排
创建左右指针。首先从右向左找出比基准小的数据,找到后立即放入左边坑中,当前位置变为新的"坑",然后从左向右找出比基准⼤的数据,找到后立即放⼊右边坑中,当前位置变为新的"坑",结束循环后将最开始存储的分界值放⼊当前的"坑"中,返回当前"坑"下标(即分界值下标)。实现代码如下:
int _QuickSort2(int* arr, int left, int right)
{int key = arr[left];int hole = left;while (left < right){while (left < right && arr[right] >= key){--right;}Swap(&arr[hole], &arr[right]);hole = right;while (left < right && arr[left] <= key){left++;}Swap(&arr[hole], &arr[left]);hole = left;}arr[hole] = key;return hole;
}这里我们不需要去考虑left与right的相等的情况,因为我们最终基准值的位置与hole相关,所以不会影响我们基准值的落脚点正确。
3.3lomuto前后指针版本
创建前后指针,从左往右找比基准值小的进行交换,使得小的都排在基准值的左边。实现代码如下:
int _QuickSort3(int* arr, int left, int right)
{int key = left;int slow = left;int fast = left + 1;while (fast <= right){if (arr[fast] < arr[key] && ++slow != fast){Swap(&arr[fast], &arr[slow]);}fast++;}Swap(&arr[slow], &arr[key]);return slow;
}3.4非递归版本的快排框架
由于每次我们的快排对基准值的寻找都需要上一次的基准值给出首尾位置,这里我们就可以借助我们之前学习到的堆的知识来进行首尾位置的记录:
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}void STInit(Stack* ps)
{assert(ps);ps->top = ps->capacity = 0;ps->arr = NULL;
}void DestoryST(Stack* ps)
{assert(ps);assert(ps->arr);free(ps->arr);ps->capacity = ps->top = 0;
}void STpush(Stack* ps, STDataType x)
{assert(ps);if (ps->top == ps->capacity){int exchange = ps->capacity == 0 ? 4 : ps->capacity * 2;STDataType* new = (STDataType*)realloc(ps->arr, sizeof(STDataType) * exchange);if (new == NULL){perror("new:");exit(1);}ps->arr = new;ps->capacity = exchange;}ps->arr[ps->top++] = x;
}void STDelt(Stack* ps)
{assert(ps);assert(!EmptyST(ps));--ps->top;
}STDataType EleSTop(Stack* ps)
{assert(ps && !EmptyST(ps));return ps->arr[ps->top - 1];
}int EmptyST(Stack* ps)
{assert(ps);return (ps->top == 0);
}
void QuickSortNone(int* arr, int left, int right)
{Stack st;STInit(&st);STpush(&st, right);STpush(&st, left);while (!EmptyST(&st)){int begin = EleSTop(&st);STDelt(&st);int end = EleSTop(&st);STDelt(&st);int meet = _QuickSort3(arr, begin, end);if (begin < meet - 1){STpush(&st, meet-1);STpush(&st, begin);}if (end > meet + 1){STpush(&st, end);STpush(&st, meet+1);}}DestoryST(&st);
}这里我们使用之前文章所给出的堆的实现方法来实现我们的非递归版本的快排的基本架构,这样及做到了减少时间复杂度,又减少了空间复杂度。
3.5复杂度的计算
快速排序由于是以二叉树的方式进行栈的创建与销毁,所以其空间复杂度为logn,时间复杂度则与我们之前的向下建堆的时间复杂度一致为O(NlogN)。
四,归并排序
归并排序(MERGE-SORT)是建立在归并操作上的⼀种有效的排序算法,该算法是采用分治法(Divide and Conquer)的⼀个非常典型的应用。将已有序的子序列合并,得到完全有序的序列。即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成⼀个有序表,称为⼆路归并。 归并排序核心步骤:
初始数组:
初始未排序数组是 [10, 6, 7, 1, 3, 9, 4, 2]。
-
分解阶段(自顶向下):
- 数组被递归地分解成更小的子数组,直到每个子数组包含一个元素。
- 第一次分解:[10, 6, 7, 1] 和 [3, 9, 4, 2]。
- 第二次分解:
- [10, 6, 7, 1] 分解为 [10, 6] 和 [7, 1]。
- [3, 9, 4, 2] 分解为 [3, 9] 和 [4, 2]。
- 第三次分解:
- [10, 6] 分解为 [10] 和 [6]。
- [7, 1] 分解为 [7] 和 [1]。
- [3, 9] 分解为 [3] 和 [9]。
- [4, 2] 分解为 [4] 和 [2]。
-
合并阶段(自底向上):
- 分解到最小子数组后,开始两两合并,并在合并过程中进行排序。
- 第一次合并:
- [10] 和 [6] 合并为 [6, 10]。
- [7] 和 [1] 合并为 [1, 7]。
- [3] 和 [9] 合并为 [3, 9]。
- [4] 和 [2] 合并为 [2, 4]。
- 第二次合并:
- [6, 10] 和 [1, 7] 合并为 [1, 6, 7, 10]。
- [3, 9] 和 [2, 4] 合并为 [2, 3, 4, 9]。
- 第三次合并:
- [1, 6, 7, 10] 和 [2, 3, 4, 9] 合并为 [1, 2, 3, 4, 6, 7, 9, 10]
图示如下:

实现归并排序的代码如下:
void _MergeSort(int* arr, int left, int right, int* tmp)
{if (left >= right){return;}int mid = (left + right) / 2;_MergeSort(arr, left, mid, tmp);_MergeSort(arr, mid + 1, right, tmp);int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int index = begin1;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[index++] = arr[begin1++];}else {tmp[index++] = arr[begin2++];}}while (begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}for (int i = left; i <= right; i++){arr[i] = tmp[i];}
}void MergeSort(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(arr, 0, n - 1, tmp);free(tmp);
}
五,各类排序算法的时间及空间复杂度的比较
 5.1对于稳定性的解释
5.1对于稳定性的解释
稳定性的概念在排序算法中指的是如果两个元素在原始数组中有相同的值,那么在排序完成后,它们的相对顺序是否保持不变。
5.1.1稳定排序算法
一个稳定的排序算法会保持相同值的元素在原数组中的相对顺序。例如,考虑以下数组:
[5a, 3, 4, 5b, 2]
在这里,5a 和 5b 是两个相同值的元素,但它们是不同的个体。
如果使用稳定的排序算法(例如冒泡排序或插入排序),那么排序后的数组可能是:
[2, 3, 4, 5a, 5b]
注意,5a 仍然在 5b 之前,这保持了它们在原始数组中的相对顺序。
5.1.2不稳定排序算法
一个不稳定的排序算法则不保证相同值的元素在排序后的相对顺序。例如,考虑同样的数组:
[5a, 3, 4, 5b, 2]
如果使用不稳定的排序算法(例如选择排序或快速排序),那么排序后的数组可能是:
[2, 3, 4, 5b, 5a]
在这里,5a 和 5b 的相对顺序被改变了。
相关文章:
数据结构初阶(c语言)-排序算法
数据结构初阶我们需要了解掌握的几种排序算法(除了直接选择排序,这个原因我们后面介绍的时候会解释)如下: 其中的堆排序与冒泡排序我们在之前的文章中已经详细介绍过并对堆排序进行了一定的复杂度分析,所以这里我们不再过多介绍。 一&#x…...

网络云相册实现--nodejs后端+vue3前端
目录 主页面 功能简介 系统简介 api 数据库表结构 代码目录 运行命令 主要代码 server apis.js encry.js mysql.js upload.js client3 index.js 完整代码 主页面 功能简介 多用户系统,用户可以在系统中注册、登录及管理自己的账号、相册及照片。 每…...

【JS】Object.defineProperty与Proxy
一、Object.defineProperty 这里只是简单描述,具体请看另一篇文章:Object.defineProperty。 Object.defineProperty 是 JavaScript 中用于定义或修改对象属性的功能强大的方法。它可以精确地控制属性的行为,如是否可枚举、可配置、可写等。…...

《计算机网络》(第8版)第8章 互联网上的音频/视频服务 复习笔记
第 8 章 互联网上的音频/视频服务 一、概述 1 多媒体信息的特点 多媒体信息(包括声音和图像信息)最主要的两个特点如下: (1)多媒体信息的信息量往往很大; (2)在传输多媒体数据时&a…...

linux进程控制——进程替换——exec函数接口
前言: 本节内容进入linux进程控制板块的最后一个知识点——进程替换。 通过本板块的学习, 我们了解了进程的基本控制方法——进程创建, 进程退出, 进程终止, 进程替换。 进程控制章节和上一节进程概念板块都是在谈进程…...
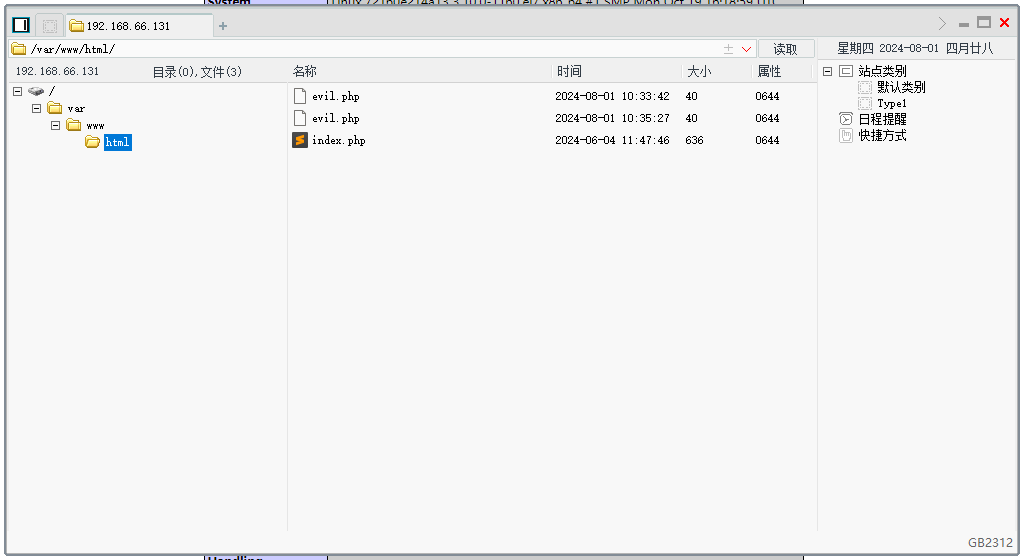
Apache解析漏洞~CVE-2017-15715漏洞分析
Apache解析漏洞 漏洞原理 # Apache HTTPD 支持一个文件拥有多个后缀,并为不同后缀执行不同的指令。比如如下配置文件: AddType text/html .html AddLanguage zh-CN .cn# 其给 .html 后缀增加了 media-type ,值为 text/html ;给 …...

Xilinx管脚验证流程及常见问题
1 流程 1.1 新建I/O Planning Project I/O Planning Project中可以不需要RTL的top层.v代码,仅图形化界面即可配置管脚约束XDC文件的生成: Create I/O Ports: 导出XDC文件和自动生成的top_interface.v文件: 1.2 新建test Project …...

格雷厄姆的《聪明的投资者》被誉为“投资圣经”
本杰明格雷厄姆的《聪明的投资者》(The Intelligent Investor: A Book of Practical Counsel)是投资领域的一部经典之作,被誉为“投资圣经”。以下是对该书的详细解析: 一、书籍基本信息 书名:《聪明的投资者》&…...

TypeScript声明文件
TypeScript声明文件 在JavaScript的生态系统中,随着项目的复杂度和规模不断增加,开发者对于类型安全和代码质量的追求也日益增长。TypeScript,作为JavaScript的一个超集,通过添加静态类型检查和ES6等新特性支持,极大地…...

.NET_WPF_使用Livecharts数据绑定图表
相关概念 LiveCharts 是一个开源的图表库,适用于多种 .NET 平台,包括 WPF、UWP、WinForms 等。LiveCharts 通过数据绑定与 MVVM 模式兼容,使得视图模型可以直接控制图表的显示,无需直接操作 UI 元素。这使得代码更加模块化&#x…...

一句JS代码,实现随机颜色的生成
今天我们只用 一句JS代码,实现随机颜色的生成,首先看一下效果: 每次刷新浏览器背景颜色都不一样 实现此效果的JS函数 : let randomColor () > ...: 定义一个箭头函数randomColor,用于生成一个随机颜色。 Math.ra…...

校园抢课助手【7】-抢课接口限流
在上一节中,该接口已经接受过风控的处理,过滤掉了机器人脚本请求,剩下都是人为的下单请求。为了防止用户短时间内高频率点击抢课链接,海量请求造成服务器过载,这里使用接口限流算法。 先介绍下几种常用的接口限流策略…...

char类型和int类型
一、char类型 在Java中,char(字符)类型用于表示单个字符,它是基本数据类型之一。以下是关于Java中char类型的一些重要信息: 表示方式: char类型用于存储Unicode字符,占用16位(即2个字…...

C++参悟:stl中的比较最大最小操作
stl中的比较最大最小操作 一、概述二、最小值1. min2. min_element 三、最大值1. max2. max_element 四、混合1. minmax2. minmax_element 一、概述 记录这里C11中常用的最小值和最大值的比较函数,最好的参考资料其实就是 https://zh.cppreference.com 最重要的查…...

JAVA读取netCdf文件并绘制热力图
读取netCdf的依赖 <dependency><groupId>ucar</groupId><artifactId>netcdfAll</artifactId><version>5.5.3</version><scope>system</scope><exclusions><exclusion><groupId>org.slf4j</groupId…...

数据结构——八大排序
一.排序的概念和其应用 1.1排序的概念 排序:排列或排序是将一组数据按照一定的规则或顺序重新组织的过程,数据既可以被组织成递增顺序(升序),或者递减顺序(降序)。稳定性:假定在待…...
流程与UI界面(终章))
【Unity】RPG2D龙城纷争(十九)流程与UI界面(终章)
更新日期:2024年8月1日。 项目源码:第五章发布(正式开始游戏逻辑的章节) 索引 简介一、游戏流程1.初始化流程2.开始流程3.关卡流程4.关卡结束流程5.启用所有流程二、UI界面逻辑1.开始界面2.存档界面3.关卡界面DataRegion 数据显示逻辑区域RoundRegion 回合逻辑区域RoleMenu…...

C#类和结构体的区别
1、类class是引用类型,多个引用类型变量的值会互相影响。存储在堆(heap)上 2、结构体struct是值类型,多个值类型变量的值不会互相影响。存储在栈(stack)上 类结构关键字classstruct类型引用类型值类型存储…...

【RabbitMQ】RabbitMQ持久化
一、简介 RabbitMQ的持久化机制是一种确保数据在RabbitMQ服务重启或异常情况下不会丢失的重要特性。RabbitMQ的持久化主要包括三个方面的内容:交换器的持久化、队列的持久化、消息的持久化。 二、交换器的持久化 1、实现方式 在RabbitMQ中,实现交换器…...
)
算法刷题笔记 Kruskal算法求最小生成树(详细算法介绍,详细注释C++代码实现)
文章目录 题目描述基本思路实现代码 题目描述 给定一个n个点m条边的无向图,图中可能存在重边和自环,边权可能为负数。求最小生成树的树边权重之和,如果最小生成树不存在则输出impossible。 最小生成树的概念:给定一张边带权的无向…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...