浅学爬虫-爬虫维护与优化
在实际项目中,爬虫的稳定性和效率至关重要。通过错误处理与重试机制、定时任务以及性能优化,可以确保爬虫的高效稳定运行。下面我们详细介绍这些方面的技巧和方法。
错误处理与重试机制
在爬虫运行过程中,网络不稳定、目标网站变化等因素可能会导致请求失败。为了确保爬虫的健壮性,需要实现错误处理与重试机制。
示例:实现错误处理与重试机制
我们将修改之前的新闻爬虫示例,加入错误处理与重试机制。
import requests
from bs4 import BeautifulSoup
import csv
import time# 文章列表页URL模板
base_url = "http://news.example.com/page/"
max_retries = 3 # 最大重试次数# 爬取文章详情的函数
def fetch_article(url):for attempt in range(max_retries):try:response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.content, 'html.parser')title = soup.find('h1', class_='article-title').textauthor = soup.find('span', class_='article-author').textdate = soup.find('span', class_='article-date').textcontent = soup.find('div', class_='article-content').textreturn {'title': title,'author': author,'date': date,'content': content}except requests.exceptions.RequestException as e:print(f"请求失败: {e},重试 {attempt + 1} 次...")time.sleep(2 ** attempt) # 指数退避算法return None# 爬取文章列表页的函数
def fetch_articles_from_page(page):url = f"{base_url}{page}"for attempt in range(max_retries):try:response = requests.get(url)response.raise_for_status()articles = []soup = BeautifulSoup(response.content, 'html.parser')links = soup.find_all('a', class_='article-link')for link in links:article_url = link['href']article = fetch_article(article_url)if article:articles.append(article)return articlesexcept requests.exceptions.RequestException as e:print(f"请求失败: {e},重试 {attempt + 1} 次...")time.sleep(2 ** attempt) # 指数退避算法return []# 保存数据到CSV文件
def save_to_csv(articles, filename):with open(filename, 'w', newline='', encoding='utf-8') as csvfile:fieldnames = ['title', 'author', 'date', 'content']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()for article in articles:writer.writerow(article)# 主程序
if __name__ == "__main__":all_articles = []for page in range(1, 6): # 假设要爬取前5页articles = fetch_articles_from_page(page)all_articles.extend(articles)save_to_csv(all_articles, 'news_articles.csv')print("新闻数据已保存到 news_articles.csv")代码解释:
- 错误处理: 使用
try-except块捕获请求异常,并打印错误信息。 - 重试机制: 使用
for循环和指数退避算法(time.sleep(2 ** attempt))实现重试机制。
定时任务
为了定期运行爬虫,可以使用系统的定时任务工具,如Linux的cron或Windows的任务计划程序。这里以cron为例,介绍如何定期运行爬虫。
步骤1:编写爬虫脚本
假设我们已经编写好了一个爬虫脚本news_spider.py。
步骤2:配置cron任务
打开终端,输入crontab -e编辑定时任务。添加以下内容,每天凌晨2点运行爬虫脚本:
0 2 * * * /usr/bin/python3 /path/to/news_spider.py代码解释:
- 定时配置:
0 2 * * *表示每天凌晨2点运行。 - 运行脚本: 指定Python解释器和爬虫脚本的路径。
性能优化
为了提高爬虫的性能和效率,可以采用以下优化策略:
- 并发和多线程: 使用多线程或异步编程加速爬取速度。
- 减少重复请求: 使用缓存或数据库存储已爬取的URL,避免重复请求。
- 优化解析速度: 使用更高效的HTML解析库,如
lxml。
示例:使用多线程优化爬虫
import concurrent.futures
import requests
from bs4 import BeautifulSoup
import csv# 文章列表页URL模板
base_url = "http://news.example.com/page/"
max_workers = 5 # 最大线程数# 爬取文章详情的函数
def fetch_article(url):try:response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.content, 'html.parser')title = soup.find('h1', class_='article-title').textauthor = soup.find('span', class_='article-author').textdate = soup.find('span', class_='article-date').textcontent = soup.find('div', class_='article-content').textreturn {'title': title,'author': author,'date': date,'content': content}except requests.exceptions.RequestException as e:print(f"请求失败: {e}")return None# 爬取文章列表页的函数
def fetch_articles_from_page(page):url = f"{base_url}{page}"try:response = requests.get(url)response.raise_for_status()soup = BeautifulSoup(response.content, 'html.parser')links = soup.find_all('a', class_='article-link')article_urls = [link['href'] for link in links]return article_urlsexcept requests.exceptions.RequestException as e:print(f"请求失败: {e}")return []# 主程序
if __name__ == "__main__":all_articles = []with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:# 爬取前5页的文章URLarticle_urls = []for page in range(1, 6):article_urls.extend(fetch_articles_from_page(page))# 并发爬取文章详情future_to_url = {executor.submit(fetch_article, url): url for url in article_urls}for future in concurrent.futures.as_completed(future_to_url):article = future.result()if article:all_articles.append(article)# 保存数据到CSV文件save_to_csv(all_articles, 'news_articles.csv')print("新闻数据已保存到 news_articles.csv")代码解释:
- 并发爬取文章详情: 使用
concurrent.futures.ThreadPoolExecutor实现多线程并发爬取文章详情。 - 优化爬取速度: 使用多线程提高爬取速度。
结论
通过错误处理与重试机制、定时任务和性能优化,可以显著提高爬虫的稳定性和效率。本文详细介绍了这些维护与优化技术,帮助我们编写高效稳定的爬虫程序。
相关文章:

浅学爬虫-爬虫维护与优化
在实际项目中,爬虫的稳定性和效率至关重要。通过错误处理与重试机制、定时任务以及性能优化,可以确保爬虫的高效稳定运行。下面我们详细介绍这些方面的技巧和方法。 错误处理与重试机制 在爬虫运行过程中,网络不稳定、目标网站变化等因素可…...

STM32G070系列芯片擦除、写入Flash错误解决
在用G070KBT6芯片调用HAL_FLASHEx_Erase(&EraseInitStruct, &PageError)时,调试发现该函数返回HAL_ERROR,最后定位到FLASH_WaitForLastOperation(FLASH_TIMEOUT_VALUE)函数出现错误,pFlash.ErrorCode为0xA0,即FLASH错误标…...

08.02_111期_Linux_NAT技术
NAT(network address translation)技术说明 IP报文在转发的时候需要考虑 源IP地址 和 目的IP地址, IP报文每到达一个节点,就会更改一次IP地址和目的IP地址,其中节点是指主机、服务器、路由器 那么这个更改是如何进行的呢? 除了…...

【2024蓝桥杯/C++/B组/小球反弹】
题目 分析 Sx 2 * k1 * x; Sy 2 * k2 * y; (其中k1, k2为整数) Vx * t Sx; Vy * t Sy; k1 / k2 (15 * y) / (17 * x); 目标1:根据k1与k2的关系,找出一组最小整数组(k1, k2)ÿ…...

PHP中如何实现函数的可变参数列表
在PHP中,实现函数的可变参数列表主要有两种方式:使用func_get_args()函数和使用可变数量的参数(通过...操作符,自PHP 5.6.0起引入)。 1. 使用func_get_args()函数 func_get_args()函数用于获取传递给函数的参数列表&…...

串---链串实现
链串详解 本文档将详细介绍链串的基本概念、实现原理及其在 C 语言中的具体应用。通过本指南,读者将了解如何使用链串进行各种字符串操作。 1. 什么是链串? 链串是一种用于存储字符串的数据结构,它使用一组动态分配的节点来保存字符串中的…...

科技赋能生活——便携气象站
传统气象站往往庞大而复杂,需要专业人员维护,它小巧玲珑,设计精致,可以轻松放入背包或口袋,随身携带,不占空间。无论是城市白领穿梭于高楼大厦间,还是户外爱好者深入山林湖海,都能随…...

Golang——GC原理
1.垃圾回收的目的 将未被引用到的对象销毁,回收其所占的内存空间。 2.根对象是什么 全局变量:在编译器就能确定的存在于程序整个生命周期的变量。 执行栈:每个goroutine都包含自己的执行栈,这些执行栈上包含栈上的变量及指向分配…...
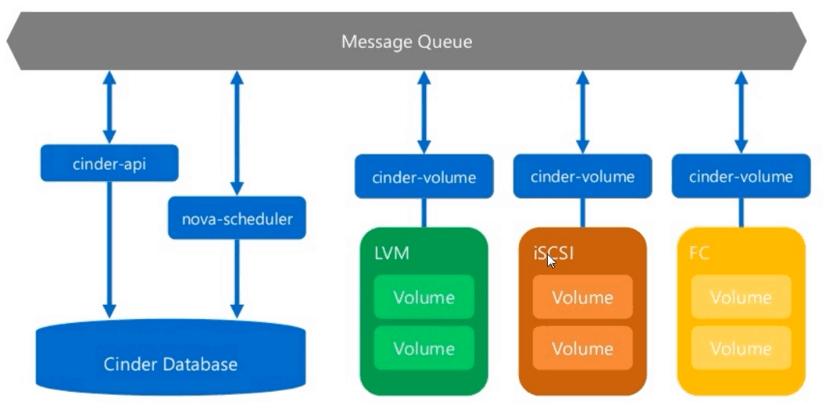
OpenStack概述
一、初识OpenStack OpenStack Docs: 概况 一)OpenStack架构简述 1、理解OpenStack OpenStack既是一个社区,也是一个项目和一个开源软件,提供开放源码软件,建立公共和私有云,它提供了一个部署云的操作平台或工具集&…...
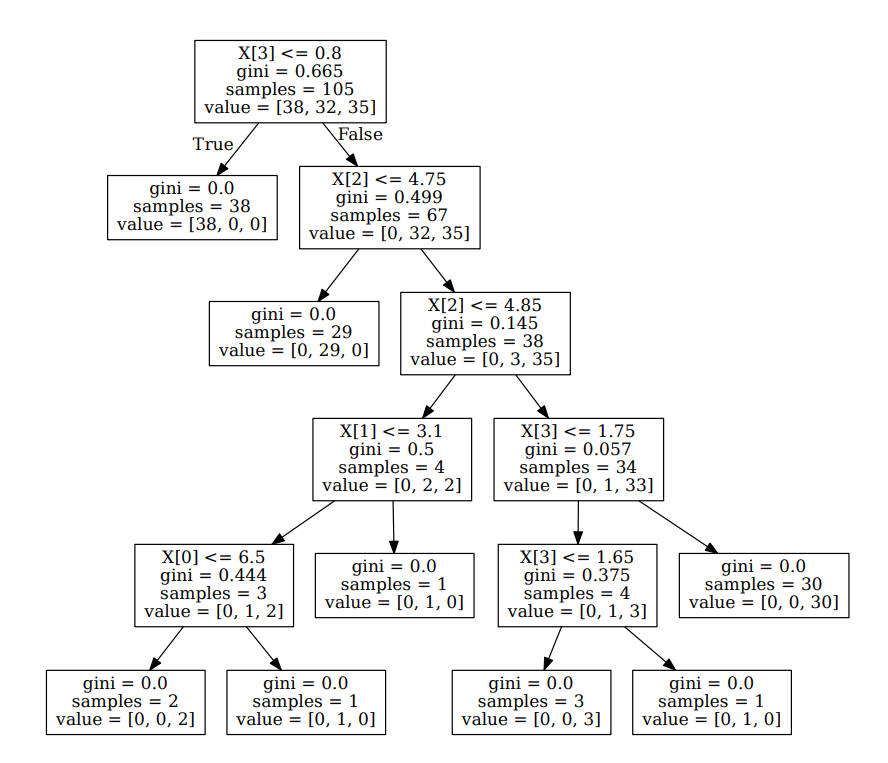
机器学习练手(三):基于决策树的iris 多分类和波士顿房价预测
总结:本文为和鲸python 可视化探索训练营资料整理而来,加入了自己的理解(by GPT4o) 原活动链接 原作者:vgbhfive,多年风控引擎研发及金融模型开发经验,现任某公司风控研发工程师,对…...

PS 2024 百种常用插件下载安装教程【免费使用,先到先得】
文章目录 软件介绍软件下载安装步骤 专栏推荐: 超多精品软件(持续更新中…) 软件推荐: PS 2024 PR 2024 软件介绍 PS常用插件 此软件整合了市面近百款ps处理插件,可实现:一键制作背景,一键抠图…...

逻辑推理之lora微调
逻辑推理微调 比赛介绍准备内容lora微调lora微调介绍lora优势代码内容 start_vllm相关介绍调用 运行主函数提交结果总结相应连接 比赛介绍 本比赛旨在测试参与者的逻辑推理和问题解决能力。参与者将面对一系列复杂的逻辑谜题,涵盖多个领域的推理挑战。 比赛的连接:…...

前端-防抖代码
//防抖debounce(fn, time 1000) {let timer null;return function (...args) {if (timer) clearTimeout(timer);timer setTimeout(() > {fn.apply(this, args);}, time);};},// 输入变化处理函数async inputChange(value) {if (!this.debouncedInputChange) {this.deboun…...

langchain 入门指南 - 让 LLM 自动选择不同的 Prompt
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 让 LLM 自动选择不同的 Prompt 在上一篇文章中,我们学会了如何让 langchain 来自动选择不同的 LLM Chain,以便回…...

web浏览器播放rtsp视频流,海康监控API
概述 这里记录一下如何让前端播放rtsp协议的视频流 项目中调用海康API,生成的视频流(hls、ws、rtmp等)通过PotPlayer播放器都无法播放,说明视频流有问题,唯独rtsp视频流可以播放。 但是浏览器本身是无法播放rtsp视频的,即使…...

操作系统原理:程序、进程、线程的概念
文章目录 程序、进程、线程的概念程序(Program)进程(Process)线程(Thread)关系总结 在日常对操作系统的使用中,大家肯定对程序、进程和线程多少有所耳闻。作为操作系统的重要一部分,…...

Golang是如何实现动态数组功能的?Slice切片原理解析
Hi 亲爱的朋友们,我是 k 哥。今天,咱们聊一聊Golang 切片。 当我们需要使用数组,但是又不能提前定义数组大小时,可以使用golang的动态数组结构,slice切片。在 Go 语言的众多特性里,slice 是我们经常用到的数…...

SQL注入 报错注入+附加拓展知识,一篇文章带你轻松入门
第5关--------------------------------------------> 前端直接不会显示账号密码的打印;但是在接收前端的数据的那部分后端那里,会看前端传递过来的值是否正确,如果不正确,后端接收值那里就会当MySQL语句执行错误,…...

springboot项目里的包spring-boot-dependencies依赖介绍
springboot项目里的包’spring-boot-dependencies‘依赖 我们一般是在项目的pom dependencyManagement标签里引入spring-boot-dependencies,或者根spring-boot-starter-parent里也是继承了它,也正是因为继承了这个依赖,所以我们在写依赖时才不需要写版本…...

C# 下的限定符运算详解(全部,任意,包含)与示例
文章目录 1.限定符概述2. 全部限定符运算(All)3. 任意限定符运算(Any)4. 包含限定符运算(Contains)总结 当我们在C#编程中需要进行条件判断或集合操作时,限定符(qualifiersÿ…...

MedGemma-X插件开发指南:基于VSCode的医疗AI扩展工具
MedGemma-X插件开发指南:基于VSCode的医疗AI扩展工具 1. 引言 作为一名医疗AI开发者,你是否曾经遇到过这样的困扰:想要快速分析医学影像,却不得不在多个工具之间来回切换;或者需要编写复杂的脚本来处理DICOM文件&…...
)
Qt 5.14实战:用QGraphicsView打造可交互的2D绘图工具(附完整代码)
Qt 5.14实战:用QGraphicsView打造可交互的2D绘图工具(附完整代码) 1. 项目概述与核心组件 在Qt框架中构建2D绘图工具时,QGraphicsView架构提供了完美的解决方案。这个架构由三个核心类组成: QGraphicsScene:…...

AIGlasses_for_navigation多场景落地:盲道导航/过街辅助/物品查找三模协同
AIGlasses_for_navigation多场景落地:盲道导航/过街辅助/物品查找三模协同 1. 引言:当眼镜成为你的“智能向导” 想象一下,你戴上一副看似普通的眼镜,眼前的世界却变得“会说话”了。脚下的盲道会告诉你“请直行”,前…...

解决跨版本材质兼容难题:Geyser资源包转换技术全解析
解决跨版本材质兼容难题:Geyser资源包转换技术全解析 【免费下载链接】Geyser A bridge/proxy allowing you to connect to Minecraft: Java Edition servers with Minecraft: Bedrock Edition. 项目地址: https://gitcode.com/GitHub_Trending/ge/Geyser Mi…...

FP6296|内置MOS,5-12V宽供,30W大功率拉满
FP6296简要概述:FP6296是一款高性能电流控制模式升压转换器,凭借内置大功率MOSFET、宽电压适配、高转换效率及丰富保护功能,可轻松实现单节锂电池15W(5V/3A)、双节锂电池30W(12V/2.5A)的输出能力…...

告别重复操作:用快马平台ai生成comfyui高效工作流模块代码
最近在折腾ComfyUI,发现搭建复杂工作流时,最耗时的不是创意构思,而是那些重复性的节点配置和连线。比如每次都要手动拖拽加载模型、设置提示词编码、配置采样器参数,步骤繁琐且容易出错。为了提高效率,我尝试用Python写…...

乡合农服土壤改良:给土地“治病”,让丰收“生根”
在什邡市洛水镇银池村的蒜田里,种植大户黎昌勇抓起一把泥土,眼角笑意满满:“这地真的‘活’过来了!”三年前,这片田土壤酸化严重,种下的大蒜不是瘦小枯黄,就是中途坏死,收成远不及以…...

金仓数据库在MySQL迁移中的技术观察:兼容性、性能与一体化部署实践
金仓数据库在MySQL迁移中的技术观察:兼容性、性能与一体化部署实践 在数字化转型持续深化的当下,企业对数据基础设施的稳定性、可维护性与成本效益提出了更高要求。面对传统商业数据库授权费用持续走高、技术路线受制于人、运维复杂度日益增加等现实挑战…...

mathtype加载到WPS灰色无法使用
具体安装教程很多,步骤都是对的,我这只是说一下我安装好几次在自己电脑上的问题,就是把两个文件复制到startup之后,也安装了VBA,但是打开WPS文档还是灰的不能用,我搞了几次发现在工具选项卡里宏无法运行&am…...

金三银四的安全招聘市场
金三银四的安全招聘市场 “金三银四”,身边有朋友在找工作,同时也收到一些朋友内推的求助。 经过对今年安全求职市场的了解后,只能感概能有一份合适的安全工作对于杭州的兄弟来说真不容易。 随着年终奖打了骨折,期权变得毫无价…...