Flink-StarRocks详解:第五部分查询数据湖(第55天)
系列文章目录
4.查询数据湖
4.1 Catalog
4.1.1 概述
4.1.1.1 基本概念
4.1.1.2 Catalog
4.1.1.3 访问Catalog
4.1.2 Default catalog
4.1.3 External Catalog
4.2 文件外部表
4.2.1 使用限制
4.2.2 开源版本语法
4.2.3 阿里云版本
5. 查询及优化
文章目录
- 系列文章目录
- 前言
- 4.查询数据湖
- 4.1 Catalog
- 4.1.1 概述
- 4.1.1.1 基本概念
- 4.1.1.2 Catalog
- 4.1.1.3 访问Catalog
- 4.1.2 Default catalog
- 4.1.3 External Catalog
- 4.2 文件外部表
- 4.2.1 使用限制
- 4.2.2 开源版本语法
- 4.2.3 阿里云版本
- 5. 查询及优化
前言
本文为Flink-StarRocks详解后续章节:主要详解StarRocks查询数据湖
由于篇幅过长,后续接着下面进行详解:
数仓场景:即席查询大案例
4.查询数据湖
4.1 Catalog
4.1.1 概述
StarRocks 自 2.3 版本起支持 Catalog(数据目录)功能,实现在一套系统内同时维护内、外部数据,方便轻松访问并查询存储在各类外部源的数据。
4.1.1.1 基本概念
内部数据:指保存在 StarRocks 中的数据。
外部数据:指保存在外部数据源(如 Apache Hive™、Apache Iceberg、Apache Hudi、Delta Lake、JDBC)中的数据。
4.1.1.2 Catalog
当前 StarRocks 提供两种类型 Catalog:internal catalog 和 external catalog。

Internal catalog: 内部数据目录,用于管理 StarRocks 所有内部数据。例如,执行 CREATE DATABASE 和 CREATE TABLE 语句创建的数据库和数据表都由 internal catalog 管理。 每个 StarRocks 集群都有且只有一个 internal catalog 名为 default_catalog。
External catalog: 外部数据目录,用于连接外部 metastore。在 StarRocks 中,可以通过 external catalog 直接查询外部数据,无需进行数据导入或迁移。当前支持创建以下类型的 external catalog:
Hive catalog:用于查询 Hive 数据。
Iceberg catalog:用于查询 Iceberg 数据。
Hudi catalog:用于查询 Hudi 数据。
Delta Lake catalog:用于查询 Delta Lake 数据。
JDBC catalog:用于查询 JDBC 数据源的数据。
4.1.1.3 访问Catalog
可以使用 SET CATALOG 切换当前会话里生效的 Catalog,然后通过该 Catalog 查询数据。
语法:
SET CATALOG <catalog_name>
参数:
catalog_name:当前会话里生效的 Catalog,支持 Internal Catalog 和 External Catalog。如果指定的 Catalog 不存在,则会引发异常。
示例:
通过如下命令,切换当前会话里生效的 Catalog 为 Hive Catalog hive_metastore:
SET CATALOG hive_metastore;
如想在一个 catalog 中查询其他 catalog 中数据,可通过 catalog_name.db_name.table_name 的格式来引用目标数据。
例如,在 default_catalog.olap_db 下查询 hive_catalog 中的 hive_table。
SELECT * FROM hive_catalog.hive_db.hive_table;
4.1.2 Default catalog
StarRocks 2.3 及以上版本提供了 Internal Catalog(内部数据目录),用于管理 StarRocks 的内部数据。每个 StarRocks 集群都有且只有一个 Internal Catalog,名为 default_catalog。StarRocks 暂不支持修改 Internal Catalog 的名称,也不支持创建新的 Internal Catalog。
使用:
默认是default_catalog,也可以显示切换。
SET CATALOG default_catalog;
然后通过 SELECT 查询内部数据
SELECT * FROM <table_name>;
如在以上步骤中未指定数据库,则可以在查询语句中直接指定。
SELECT * FROM <db_name>.<table_name>;
或
SELECT * FROM default_catalog.<db_name>.<table_name>;
4.1.3 External Catalog
External Catalog(外部数据目录),用于管理外部数据源的访问信息。
语法:
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
("type" = "<type>",MetastoreParams
)
参数说明:
catalog_name:External Catalog的名称,必选参数。
命名要求如下:
总长度不能超过64个字符。
必须由字母(az或AZ)、数字(0~9)或下划线(_)组成,且只能以字母开头。
comment:External Catalog的描述,可选参数。
type:数据源的类型,必选参数。
目前开源版本支持hive、hudi、iceberg、delta lake、jdbc、elasticsearch、paimon七种类型的数据源,阿里云EMR Serverless StarRocks目前只支持hive、hudi、iceberg三种。
MetastoreParams:StarRocks访问相应数据源的相关参数配置
示例:
开源版本:
CREATE EXTERNAL CATALOG hive_catalog_hms
PROPERTIES
("type" = "hive","hive.metastore.type" = "hive","hive.metastore.uris" = "thrift://xx.xx.xx:9083"
);
阿里云版本:
CREATE EXTERNAL CATALOG hive
PROPERTIES
("type" = "hive","dlf.catalog.endpoint" = "dlf-vpc.cn-beijing.aliyuncs.com","dlf.catalog.region" = "cn-beijing","dlf.catalog.proxyMode" = "DLF_ONLY","dlf.catalog.akMode" = "MANUAL","hive.metastore.type" = "DLF","dlf.catalog.id" = "dlf_test","dlf.catalog.accessKeyId" = "*******","dlf.catalog.accessKeySecret" = "*****"
);
4.2 文件外部表
文件外部表 (File External Table) 是一种特殊的外部表。可以通过文件外部表直接查询外部存储系统上的 Parquet 和 ORC 格式的数据文件,无需导入数据。同时,文件外部表也不依赖任何 Metastore。StarRocks 当前支持的外部存储系统包括 HDFS、Amazon S3 及其他兼容 S3 协议的对象存储、阿里云对象存储 OSS 和腾讯云对象存储 COS。
该特性从 StarRocks 2.5 版本开始支持。
4.2.1 使用限制
当前仅支持在 default_catalog 下的数据库内创建文件外部表,不支持 external catalog。可以通过 SHOW CATALOGS 来查询集群下的 catalog。
仅支持查询 Parquet 和 ORC 格式的数据文件。
目前仅支持读取目标数据文件中的数据,不支持例如 INSERT,DELETE,DROP 等写入操作。
4.2.2 开源版本语法
切换到目前数据库后,可以使用如下语法创建一个文件外部表。
CREATE EXTERNAL TABLE <table_name>
(<col_name> <col_type> [NULL | NOT NULL] [COMMENT "<comment>"]
)
ENGINE=FILE
COMMENT ["comment"]
PROPERTIES
(FileLayoutParams,StorageCredentialParams
)
参数说明:
参数 必选 说明


具体参考:https://docs.starrocks.io/zh/docs/data_source/file_external_table/
示例:
USE db_example;
CREATE EXTERNAL TABLE table_1
(name string, id int
)
ENGINE=file
PROPERTIES
("path" = "s3://bucket-test/folder1/", "format" = "orc","aws.s3.use_instance_profile" = "false","aws.s3.access_key" = "<iam_user_access_key>","aws.s3.secret_key" = "<iam_user_access_key>","aws.s3.region" = "us-west-2"
);
4.2.3 阿里云版本
在阿里云EMR Serverless StarRocks中,通过配置正确的OSS AccessKey和OSS Endpiont信息,即可以轻松地连接到OSS Bucket,并在StarRocks中使用SQL语句对数据进行查询和分析等操作。
操作步骤:
(1)进入EMR Serverless StarRocks实例配置页面。
1)在EMR控制台,点击StarRocks,单击待查看的实例名称。

2)单击实例配置页签。
(2)修改core-site.xml配置。
1)单击core-site.xml页签。
2)搜索并修改以下配置项。

①配置accessKey步骤:
登录AccessKey管理页面,
https://ram.console.aliyun.com/manage/ak?spm=a2c4g.11186623.0.0.389247f8OlOaMw
首次进入需勾选并点击确定

因为安全原因,这里使用子用户的AccessKey

点击创建用户

登录名为写自己得,显示名称为自己的名称,勾选两种访问方式
点击自定义密码,设置为88888666!
然后是不需要重置密码,不需要MFA多因素认证
点击确定
然后通过手机号或者扫脸进行验证。
验证成功后,复制对应的AccessKey ID 和 Secret

②通过查询访问域名和数据中心
https://help.aliyun.com/zh/oss/user-guide/regions-and-endpoints 得到 北京的内网Endpoint为 oss-cn-beijing-internal.aliyuncs.com
(3)修改BE配置。
1)单击BE页签。
2)搜索并修改以下配置项。


(4)生效配置。
1)单击提交参数。
2)在弹出的对话框中,输入原因说明,单击确定。
(5)查询示例
接paimon章节在oss中创建的表
CREATE DATABASE test;CREATE EXTERNAL TABLE test.UpdateTable
(a STRING,b INT,c INT
)
ENGINE=file
PROPERTIES
("path" = "oss://*******-paimon/test.db/UpdateTable/bucket-0/", "format" = "orc"
);SELECT * FROM test.UpdateTable;
查询结果如下:

注意:如果查询报错,原因可能是子账号没有OSS访问权限,所以需要给子账号开通权限

开通方式,就是在RAM访问控制中,点击用户,然后添加权限。

然后把OSS权限授权给子用户。

5. 查询及优化
查询SQL参考:
https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/all-commands/
常用函数参考:
https://docs.starrocks.io/zh/docs/sql-reference/sql-functions/function-list/
另外,为了获取更快的查询速度,StarRocks也提供了一些查询加速的方法,主要的方式有使用CBO 优化器、物化视图、Colocata Join、索引、数据去重等。
具体详见:
https://docs.starrocks.io/zh/docs/using_starrocks/Cost_based_optimizer/
相关文章:
Flink-StarRocks详解:第五部分查询数据湖(第55天)
系列文章目录 4.查询数据湖 4.1 Catalog 4.1.1 概述 4.1.1.1 基本概念 4.1.1.2 Catalog 4.1.1.3 访问Catalog 4.1.2 Default catalog 4.1.3 External Catalog 4.2 文件外部表 4.2.1 使用限制 4.2.2 开源版本语法 4.2.3 阿里云版本 5. 查询及优化 文章目录 系列文章目录前言4.查…...

【MySQL】常用数据类型
目录 数据类型 数据类型分类 数值类型 tinyint类型 bit类型 小数类型 float decimal 字符串类型 char varchar 日期和时间类型 enum和set 数据类型 数据类型分类 数值类型 tinyint类型 tinyint类型只占用一个字节类似于编程语言中的字符char。有带符号和无符号两…...

创建第一个rust tauri项目
安装nodejs curl -sL https://deb.nodesource.com/setup_20.x | sudo bash node -vproxychains4 npm create tauri-applatest✔ Project name tauri-app ✔ Choose which language to use for your frontend TypeScript / JavaScript - (pnpm, yarn, npm, bun) ✔ Choose yo…...

【课程总结】day19(中):Transformer架构及注意力机制了解
前言 本章内容,我们将从注意力的基础概念入手,结合Transformer架构,由宏观理解其运行流程,然后逐步深入了解多头注意力、多头掩码注意力、融合注意力等概念及作用。 注意力机制(Attension) 背景 深度学…...

4.4 标准正交基和格拉姆-施密特正交化
本节的两个目标就是为什么和怎么做(why and how)。首先是知道为什么正交性很好:因为它们的点积为零; A T A A^TA ATA 是对角矩阵;在求 x ^ \boldsymbol{\hat x} x^ 和 p A x ^ \boldsymbol pA\boldsymbol{\hat x} pAx^ 时也会很简单。第二…...

spring事务的8种失效的场景,7种传播行为
Spring事务大部分都是通过AOP实现的,所以事务失效的场景大部分都是因为AOP失效,AOP基于动态代理实现的 1.方法没有被public修饰 原因:Spring会为方法创建代理、AOP添加事务通知前提条件是该方法时public的。 2.类没有被Spring容器所托管 …...

进程的虚拟内存地址(C++程序的内存分区)
严谨的说法: 一个C、C程序实际就是一个进程,那么C的内存分区,实际上就是一个进程的内存分区,这样的话就可以分为两个大模块,从上往下,也就是0地址一直往下,假如是x86的32位Linux系统,…...

英特尔移除超线程与AMD多线程性能对比
#### 英特尔Lunar Lake架构取消超线程 在英特尔宣布Lunar Lake架构时,一个令人惊讶的消息是下一代轻薄优化架构将移除Hyper-Threading(超线程,简称SMT)。而AMD最新的Zen 5/Zen5C多线程基准测试结果显示,该特性依然为A…...

定期自动巡检,及时发现机房运维管理中的潜在问题
随着信息化技术的迅猛发展,机房作为企业数据处理与存储的核心场所,其运维管理的复杂性和挑战性也与日俱增。为确保机房设备的稳定运行和业务的连续性,运维团队必须定期进行全面的巡检。然而,传统的手工巡检方式不仅效率低下&#…...
)
八股文(一)
1. 为什么不使用本地缓存,而使用Redis? Redis相比于本地缓存(如JVM中的缓存)有以下几个显著优势: 高性能与低延迟:Redis是一个基于内存的数据库,其读写性能非常高,通常可以达到几万…...

灵茶八题 - 子数组 ^w^
灵茶八题 - 子数组 w 题目描述 给你一个长为 n n n 的数组 a a a,输出它的所有连续子数组的异或和的异或和。 例如 a [ 1 , 3 ] a[1,3] a[1,3] 有三个连续子数组 [ 1 ] , [ 3 ] , [ 1 , 3 ] [1],[3],[1,3] [1],[3],[1,3],异或和分别为 1 , 3 , …...

git clone private repo
Create personal access token Clone repo $ git clone https://<user_name>:<personal_access_tokens>github.com/<user_name>/<repo_name>.git...

vue3+ts+pinia+vant-项目搭建
1.pnpm介绍 npm和pnpm都是JavaScript的包管理工具,用于自动化安装、配置、更新和卸载npm包依赖。 pnpm节省了大量的磁盘空间并提高了安装速度:使用一个内容寻址的文件存储方式,如果多个项目使用相同的包版本,pnpm会存储单个副本…...

自动化测试概念篇
目录 一、自动化 1.1 自动化概念 1.2 自动化分类 1.3 自动化测试金字塔 二、web自动化测试 2.1 驱动 2.2 安装驱动管理 三、selenium 3.1 ⼀个简单的web自动化示例 3.2 selenium驱动浏览器的工作原理 一、自动化 1.1 自动化概念 在生活中: 自动洒水机&am…...
详解)
Mojo值的生命周期(Life of a value)详解
到目前为止,我们已经解释了 Mojo 如何允许您使用 Mojo 的所有权模型构建内存安全的高性能代码而无需手动管理内存。但是,Mojo 是为 系统编程而设计的,这通常需要对自定义数据类型进行手动内存管理。因此,Mojo 允许您根据需要执行此操作。需要明确的是,Mojo 没有引用计数器…...
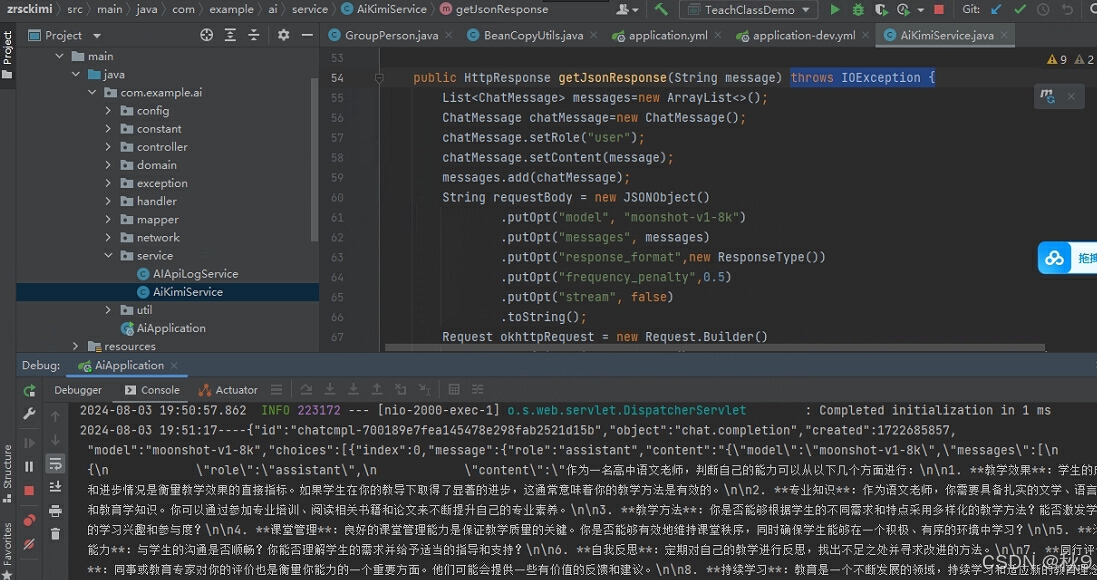
java对接kimi详细说明,附完整项目
需求: 使用java封装kimi接口为http接口,并把调用kimi时的传参和返回数据,保存到mysql数据库中 自己记录一下,以做备忘。 具体步骤如下: 1.申请apiKey 访问:Moonshot AI - 开放平台使用手机号手机号验证…...

鸿蒙媒体开发【基于AVCodec能力的视频编解码】音频和视频
基于AVCodec能力的视频编解码 介绍 本实例基于AVCodec能力,提供基于视频编解码的视频播放和录制的功能。 视频播放的主要流程是将视频文件通过解封装->解码->送显/播放。视频录制的主要流程是相机采集->编码->封装成mp4文件。 播放支持的原子能力规…...

django集成pytest进行自动化单元测试实战
文章目录 一、引入pytest相关的包二、配置pytest1、将django的配置区分测试环境、开发环境和生产环境2、配置pytest 三、编写测试用例1、业务测试2、接口测试 四、进行测试 在Django项目中集成Pytest进行单元测试可以提高测试的灵活性和效率,相比于Django自带的测试…...

48天笔试训练错题——day40
目录 选择题 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 编程题 1. 发邮件 2. 最长上升子序列 选择题 1. DNS 劫持又称域名劫持,是指在劫持的网络范围内拦截域名解析的请求,分析请求的域名,把审查范围以外的请求放行,否则返回…...

LabVIEW在DCS中的优势
DCS(Distributed Control System,分布式控制系统)是一种用于工业过程控制的自动化系统。它将控制任务分散到多个控制单元中,通过网络连接和协调这些单元来实现对整个过程的监控和控制。DCS通常用于大型工业设施,如化工…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...