Executable Code Actions Elicit Better LLM Agents
Executable Code Actions Elicit Better LLM Agents

Github: https://github.com/xingyaoww/code-act
一、动机
大语言模型展现出很强的推理能力。但是现如今大模型作为Agent的时候,在执行Action时依然还是通过text-based(文本模态)后者JSON的形式呈现。通过text-based或JSON来实现工具的理解调用、memory的管理等。
然而,基于文本或JSON的动作空间通常比较局限,且灵活性较差。例如某些动作可能需要借助变量暂存,或者是一些较为复杂的动作(取均值、排序)等。
最近大模型也被发现能够在代码理解和生成任务上展现很强的能力。那么是否可以将代码作为Agent执行Action的基础呢?
二、方法
本文提出CodeAct(Code as actions),试图全部使用Python代码(Jupyter Notebook内核环境)来代替原始的基于文本或JSON的Action。
python实现Jupyter Notebook内核的调用示例:https://github.com/xingyaoww/code-act/blob/main/mint/tools/python_tool.py
CodeAct与Text/JSON的对比如下图所示:

- 当给定一个指令、候选API工具时,基于Text/JSON的Action推理过程则需要给出文本模态的推理(解释),涉及到的工具则转换为JSON格式,并根据预先设置好的API函数执行调用,从而获得环境的反馈;
- 基于CodeAct的Action,此时直接生成相应的Python代码,并且通过Python环境来执行代码获得结果;
- 可发现CodeAct可以降低多轮对话的轮次,提高效率,且准确性也高于Text/JSON。
前提假设:code data广泛应用于当今大模型的预训练中。这些模型已经熟悉结构化编程语言,允许LLM生成可执行的Python(因为Python代码数量最多且软件包也很丰富)代码作为Action:
- CodeAct与Python Interpreter集成,可以执行代码行动,并动态调整先前的行动,或根据通过多轮交互(代码执行)收到的观察结果发出新行动。
- 代码行动允许LLM利用现有软件包。CodeAct可以使用现成的Python包来扩展行动空间,而不是手工制作的特定于任务的工具 + Self-Refine/Debug,根据执行反馈调整动作
- 与JSON和预定义格式的文本相比,代码本质上支持控制和数据流,允许将中间结果存储为变量以供重用
CodeAct框架如下图所示:
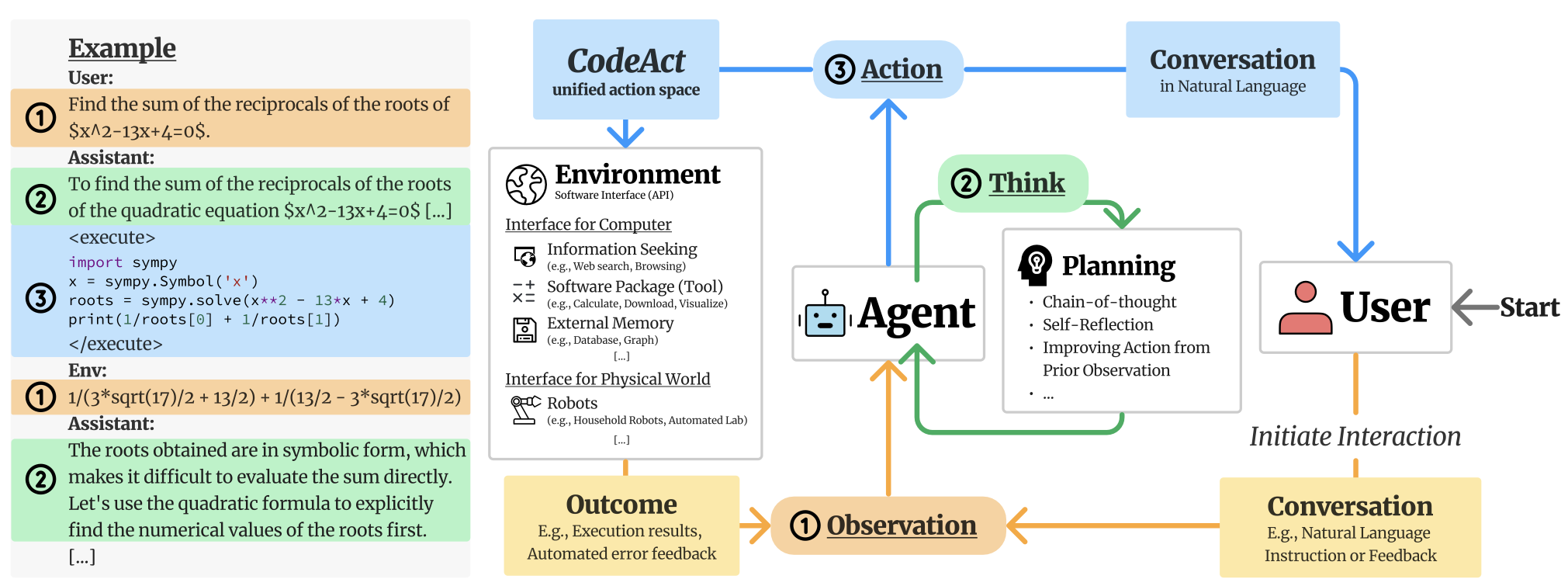
首先定义三个元素,分别是
- Agent:大模型
- User:提供Query的用户
- Environment:这里是Python执行环境,可以提供执行结果;
CodeAct以多轮交互的形式实现这三个元素之间的交流。
For each turn of interaction, the agent receives an observation (input) either from the user (e.g., natural language instruction) or the environment (e.g., code execution result), optionally planning for its action through chain-of-thought (Wei et al., 2022), and emits an action (output) to either user in natural language or the environment. CodeAct employs Python code to consolidate all actions for agent-environment interaction. In CodeAct, each emitted action to the environment is a piece of Python code, and the agent will receive outputs of code execution (e.g., results, errors) as observation.
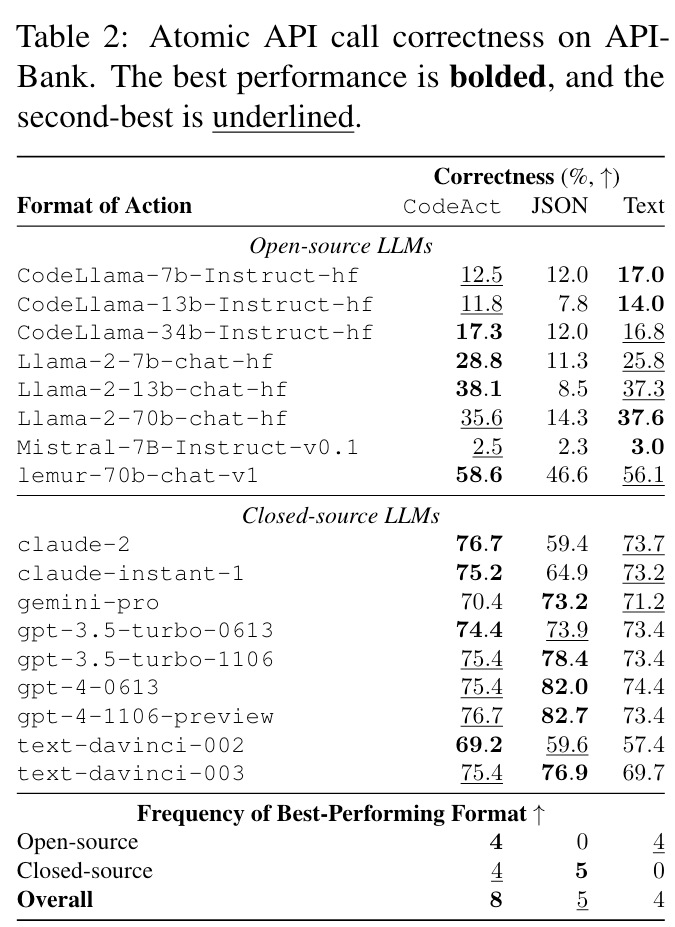
预实验一:作为工具使用框架的前景
对照实验,以了解哪种格式(文本、JSON、CodeAct)更有可能引导LLM生成正确的原子工具调用。
- 开源模型效果好
- 闭源模型部分不如JSON,作者认为这是因为openai的模型针对JSON格式数据优化过
预实验二:CodeAct以更少的交互完成更多工作
实验部分主要基于作者自己提出的M3ToolEval benchmark(82个样本)
- CodeAct通常具有更高的任务成功率(17个已评估LLM中有12个)。
- 使用CodeAct执行任务所需的平均交互轮数也较低。与操作格式(文本)相比,最佳模型gpt-4-1106可以减少1/5的交互

应用:多轮交互和使用Libraries
作者展示了LLM agents如何与Python tools
- 使用现有软件在多轮交互中执行复杂的任务。得益于在预训练期间学到的Python code,LLM Agents可以自动导入正确的Python库来解决任务
- 不需要用户提供的tools或demonstrations(因为python代码作为action可以自行实现软件包调用,并通过代码实现)

完整的推理过程:https://chat.xwang.dev/conversation/Vqn108G
增强开源LLM Agents
和Tool LLM一样的套路:再整一个包含智能体与环境交互轨迹的指令微调数据集:CodeActInstruct
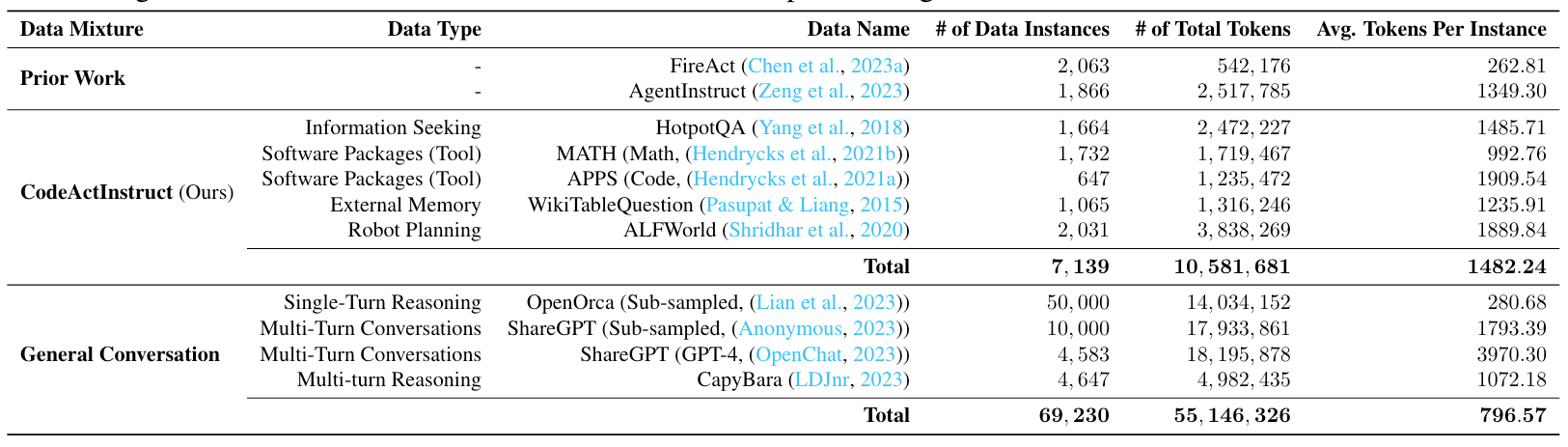
主要来自如下四种数据源,对原始训练数据做了一些调整后获得:

实验结果:
CodeActAgent(Mistral)的性能优于类似规模(7B/13B)的开源模型,有70B模型相似的性能。

总结:这个文章主要是对existing codellms的技术(包括代码执行反馈等) + agent actions / planning + tune轨迹的整合,technical novelty适中,但是整个工作覆盖的面很广
实现
CodeAct整体上作出的优化点应该是纯Prompt,即设计Prompt来让大模型通过Python代码来执行Action。
CodeAct的指令提示:

prompt母版
You are a helpful assistant assigned with the task of problem-solving. To achieve this, you will be using an interactive coding environment equipped with a variety of tool functions to assist you throughout the process.At each turn, you should first provide your step-by-step thinking for solving the task. Your thought process should be enclosed using "<thought>" tag, for example: <thought> I need to print "Hello World!" </thought>.After that, you have two options:1) Interact with a Python programming environment and receive the corresponding output. Your code should be enclosed using "<execute>" tag, for example: <execute> print("Hello World!") </execute>.
2) Directly provide a solution that adheres to the required format for the given task. Your solution should be enclosed using "<solution>" tag, for example: The answer is <solution> A </solution>.You have {max_total_steps} chances to interact with the environment or propose a solution. You can only propose a solution {max_propose_solution} times.{tool_desc}---{in_context_example}---{task_prompt}
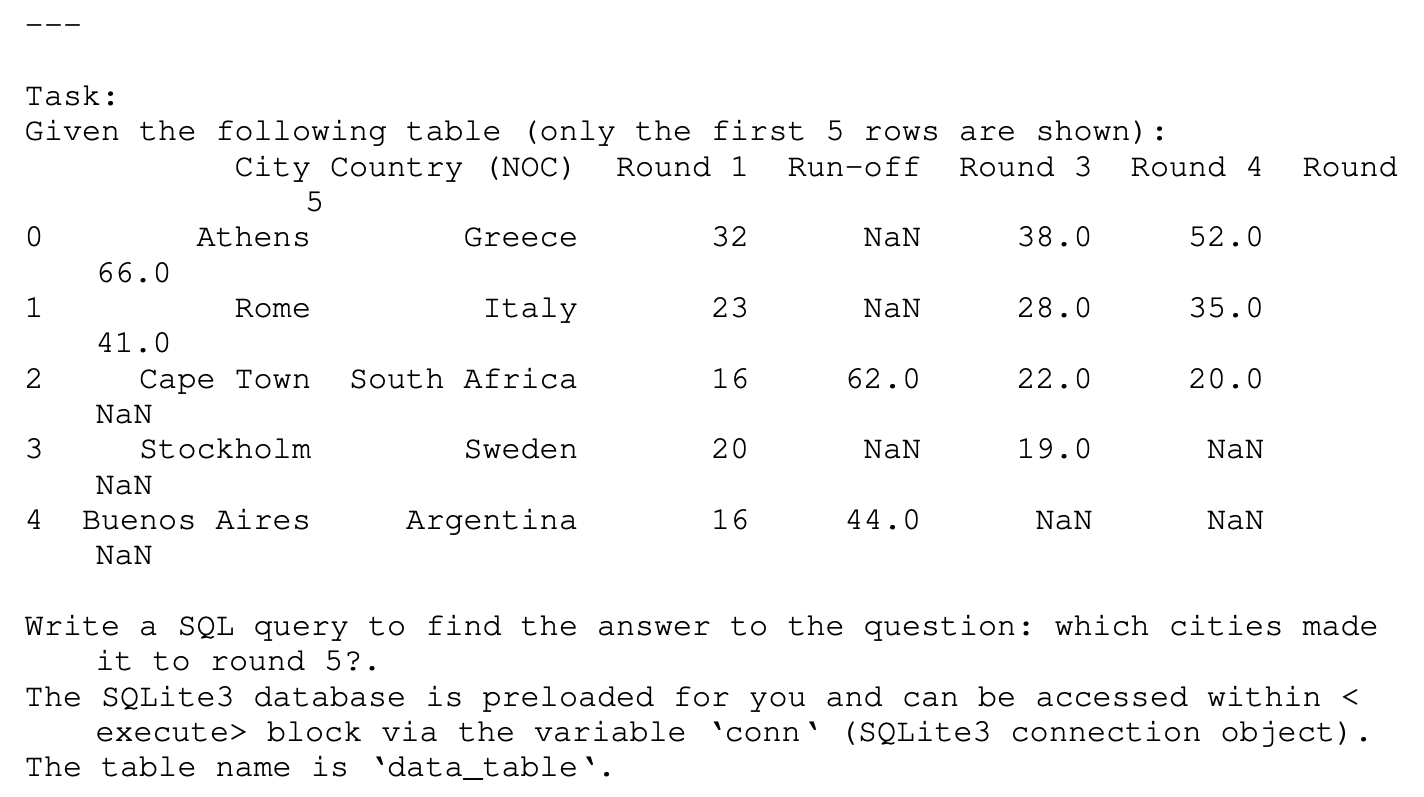
以WikiTableQuestion任务为例,1-shot exemplar可以定义如下:
system prompt:
exemplar-input:
exemplar-output:

核心代码如下:
- LLM Agent类
from .base import LMAgent
import openai
import logging
import traceback
from mint.datatypes import Action
import backoffLOGGER = logging.getLogger("MINT")class OpenAILMAgent(LMAgent):def __init__(self, config):super().__init__(config)assert "model_name" in config.keys()@backoff.on_exception(backoff.fibo,# https://platform.openai.com/docs/guides/error-codes/python-library-error-types(openai.error.APIError,openai.error.Timeout,openai.error.RateLimitError,openai.error.ServiceUnavailableError,openai.error.APIConnectionError,),)def call_lm(self, messages):# Prepend the prompt with the system messageresponse = openai.ChatCompletion.create(model=self.config["model_name"],messages=messages,max_tokens=self.config.get("max_tokens", 512),temperature=self.config.get("temperature", 0),stop=self.stop_words,)return response.choices[0].message["content"], response["usage"]def act(self, state):messages = state.historytry:lm_output, token_usage = self.call_lm(messages)for usage_type, count in token_usage.items():state.token_counter[usage_type] += countaction = self.lm_output_to_action(lm_output)return actionexcept openai.error.InvalidRequestError: # mostly due to model context window limittb = traceback.format_exc()return Action(f"", False, error=f"InvalidRequestError\n{tb}")# except Exception as e:# tb = traceback.format_exc()# return Action(f"", False, error=f"Unknown error\n{tb}")
- 环境类,负责追溯当前的Agent的状态,执行Python代码并获得结果等;
import re
import logging
import traceback
from typing import Any, Dict, List, Mapping, Tuple, OptionalLOGGER = logging.getLogger("MINT")from mint import agents
from mint.envs.base import BaseEnv
from mint.prompt import ToolPromptTemplate
from mint.datatypes import State, Action, StepOutput, FeedbackType
from mint.tools import Tool, get_toolset_description
from mint.tasks import Task
from mint.tools.python_tool import PythonREPL
from mint.utils.exception import ParseErrorINVALID_INPUT_MESSAGE = ("I don't understand your input. \n""If you want to execute code, please use <execute> YOUR_CODE_HERE </execute>.\n""If you want to give me an answer, please use <solution> YOUR_SOLUTION_HERE </solution>.\n""For example: The answer to the question is <solution> 42 </solution>. \n"
)class GeneralEnv(BaseEnv):def __init__(self,task: Task,tool_set: List[Tool],feedback_config: Dict[str, Any],environment_config: Dict[str, Any],):self.task: Task = taskself.tool_set: List[Tool] = tool_set + getattr(self, "tool_set", [])self.state = State()self.config = environment_config# Feedbackself.feedback_config = feedback_configfeedback_agent_config = feedback_config["feedback_agent_config"]if feedback_config["pseudo_human_feedback"] in ["GT", "no_GT"]:self.feedback_agent: agents = getattr(agents, feedback_agent_config["agent_class"])(feedback_agent_config)else:self.feedback_agent = Noneif self.feedback_config["pseudo_human_feedback"] == "None":self.feedback_type = FeedbackType.NO_FEEDBACKelif self.feedback_config["pseudo_human_feedback"] == "no_GT":self.feedback_type = FeedbackType.FEEDBACK_WO_GTelif self.feedback_config["pseudo_human_feedback"] == "GT":self.feedback_type = FeedbackType.FEEDBACK_WITH_GTelse:raise ValueError(f"Invalid feedback type {self.feedback_config['pseudo_human_feedback']}")self.env_outputs: List[StepOutput] = []LOGGER.info(f"{len(self.tool_set)} tools loaded: {', '.join([t.name for t in self.tool_set])}")# Initialize the Python REPLuser_ns = {tool.name: tool.__call__ for tool in self.tool_set}user_ns.update(task.user_ns)self.python_repl = PythonREPL(user_ns=user_ns,)def parse_action(self, action: Action) -> Tuple[str, Dict[str, Any]]:"""Define the parsing logic."""lm_output = "\n" + action.value + "\n"output = {}try:if not action.use_tool:answer = "\n".join([i.strip()for i in re.findall(r"<solution>(.*?)</solution>", lm_output, re.DOTALL)])if answer == "":raise ParseError("No answer found.")output["answer"] = answerelse:env_input = "\n".join([i.strip()for i in re.findall(r"<execute>(.*?)</execute>", lm_output, re.DOTALL)])if env_input == "":raise ParseError("No code found.")output["env_input"] = env_inputexcept Exception as e:raise ParseError(e)return outputdef get_feedback(self, observation: str) -> Tuple[str, FeedbackType]:if self.feedback_type == FeedbackType.NO_FEEDBACK:return ""elif self.feedback_type == FeedbackType.FEEDBACK_WO_GT:gt = Noneelse:gt = self.task.referencefeedback = self.feedback_agent.act(self.state,observation=observation,form=self.feedback_config["feedback_form"],gt=gt,task_in_context_example=self.task.in_context_example(use_tool=self.config["use_tools"],with_feedback=True,),tool_desc=get_toolset_description(self.tool_set),)return feedback.valuedef check_task_success(self, answer: str) -> bool:LOGGER.info(f"REFERENCE ANSWER: {self.task.reference}")return self.task.success(answer)def log_output(self, output: StepOutput) -> None:if self.state.finished:returncontent = output.to_str()self.state.history.append({"role": "user", "content": content})self.state.latest_output = output.to_dict()self.state.latest_output["content"] = contentdef handle_tool_call(self, action: Action) -> str:"""Use tool to obtain "observation."""try:parsed = self.parse_action(action)env_input = parsed["env_input"]obs = self.python_repl(env_input).strip()self.env_outputs.append(StepOutput(observation=obs))self.state.agent_action_count["use_tool"] += 1return obsexcept ParseError:self.state.agent_action_count["invalid_action"] += 1return INVALID_INPUT_MESSAGEexcept Exception as e:error_traceback = traceback.format_exc()return f"{error_traceback}"def handle_propose_solution(self, action: Action) -> Optional[str]:"""Propose answer to check the task success.It might set self.state.finished = True if the task is successful."""self.state.agent_action_count["propose_solution"] += 1try:parsed = self.parse_action(action)task_success = self.check_task_success(parsed["answer"])if task_success:self.state.finished = Trueself.state.success = Trueself.state.terminate_reason = "task_success"# NOTE: should not return the function now, because we need to log the output# Set state.finished = True will terminate the episodeexcept ParseError:return INVALID_INPUT_MESSAGEexcept Exception as e:error_traceback = traceback.format_exc()return f"{error_traceback}"def check_max_iteration(self):"""Check if the agent has reached the max iteration limit.It might set self.state.finished = True if the agent has reached the max iteration limit."""if self.state.finished:# ignore if the episode is already finished (e.g., task success)returnif (# propose solution > max output solutionself.state.agent_action_count["propose_solution"]>= self.config["max_propose_solution"]):self.state.finished = Trueself.state.success = Falseself.state.terminate_reason = "max_propose_steps"elif (# (propose_solution + use_tool) > max iteration limitsum(self.state.agent_action_count.values())>= self.config["max_steps"]):self.state.finished = Trueself.state.success = Falseself.state.terminate_reason = "max_steps"def step(self, action: Action, loaded=None) -> State:assert (not self.state.finished), "Expecting state.finished == False for env.step()."# Update state by logging the actionif action.value:assistant_action = ("Assistant:\n" + action.valueif not action.value.lstrip().startswith("Assistant:")else action.value)self.state.history.append({"role": "assistant", "content": assistant_action + "\n"})if action.error:# Check if error (usually hit the max length)observation = f"An error occurred. {action.error}"self.state.finished = Trueself.state.success = Falseself.state.error = action.errorself.state.terminate_reason = "error"LOGGER.error(f"Error:\n{action.error}")elif action.use_tool:observation = self.handle_tool_call(action)else:# It might set self.state.finished = True if the task is successful.observation = self.handle_propose_solution(action)# Check if the agent has reached the max iteration limit.# If so, set self.state.finished = True# This corresponds to a no-op if the episode is already finishedself.check_max_iteration()# record the turn infoif self.config["count_down"]:turn_info = (self.config["max_steps"] - sum(self.state.agent_action_count.values()),self.config["max_propose_solution"]- self.state.agent_action_count["propose_solution"],)else:turn_info = None# Get feedback if the episode is not finishedif loaded != None:feedback = loaded["feedback"]LOGGER.info(f"Loaded feedback: {feedback}")elif not self.state.finished:# This is the output without feedback# use to generate an observation for feedback agenttmp_output = StepOutput(observation=observation,success=self.state.success,turn_info=turn_info,)feedback = self.get_feedback(observation=tmp_output.to_str())else:feedback = ""# Log the output to state regardless of whether the episode is finishedoutput = StepOutput(observation=observation,feedback=feedback,feedback_type=self.feedback_type,success=self.state.success,turn_info=turn_info,)self.log_output(output)return self.statedef reset(self) -> State:use_tool: bool = self.config["use_tools"]if use_tool and len(self.tool_set) > 0:LOGGER.warning(("No tool is provided when use_tools is True.\n""Ignore this if you are running code generation."))user_prompt = ToolPromptTemplate(use_tool=use_tool)(max_total_steps=self.config["max_steps"],max_propose_solution=self.config["max_propose_solution"],tool_desc=get_toolset_description(self.tool_set),in_context_example=self.task.in_context_example(use_tool=use_tool,with_feedback=self.feedback_type != FeedbackType.NO_FEEDBACK,),task_prompt="Task:\n" + self.task.prompt,)self.state.history = [{"role": "user", "content": user_prompt}]self.state.latest_output = {"content": user_prompt}self.state.agent_action_count = {"propose_solution": 0,"use_tool": 0,"invalid_action": 0,}if use_tool:# reset tool setfor tool in self.tool_set:tool.reset()return self.state# destructordef __del__(self):self.task.cleanup()
- 逻辑执行
from mint.envs import GeneralEnv, AlfworldEnv
from mint.datatypes import Action, State
from mint.tasks import AlfWorldTask
from mint.tools import Tool
import mint.tasks as tasks
import mint.agents as agents
import logging
import os
import json
import pathlib
import importlib
import argparse
from typing import List, Dict, Any
from tqdm import tqdm
from tqdm.contrib.logging import logging_redirect_tqdm# Configure logging settings
logging.basicConfig(format="%(asctime)s [%(levelname)s] %(name)s: %(message)s",datefmt="%Y-%m-%d %H:%M:%S",
)
LOGGER = logging.getLogger("MINT")def interactive_loop(task: tasks.Task,agent: agents.LMAgent,tools: List[Tool],feedback_config: Dict[str, Any],env_config: Dict[str, Any],interactive_mode: bool = False,
):if isinstance(task, AlfWorldTask):LOGGER.info("loading Alfworld Env")env = AlfworldEnv(task, tools, feedback_config, env_config)else:env = GeneralEnv(task, tools, feedback_config, env_config)state: State = env.reset()init_msg = state.latest_output['content']if interactive_mode:# omit in-context examplesplited_msg = init_msg.split("---")init_msg = splited_msg[0] + "== In-context Example Omitted ==" + splited_msg[2]LOGGER.info(f"\nUser: \n\033[94m{state.latest_output['content']}\033[0m")num_steps = 0if task.loaded_history is not None:for turn in task.loaded_history:action = agent.lm_output_to_action(turn["lm_output"])LOGGER.info(f"\nLoaded LM Agent Action:\n\033[92m{action.value}\033[0m")state = env.step(action, loaded=turn)LOGGER.info("\033[1m" + "User:\n" + "\033[0m" +f"\033[94m{state.latest_output['content']}\033[0m")num_steps += 1while not state.finished:# agent actif interactive_mode:to_continue = "n"while to_continue not in ["y", "Y"]:to_continue = input("\n> Continue? (y/n) ")action: Action = agent.act(state)# color the action in green# LOGGER.info(f"\nLM Agent Action:\n\033[92m{action.value}\033[0m")LOGGER.info(f"\n\033[1m" + "LM Agent Action:\n" + "\033[0m" +f"\n\033[92m{action.value}\033[0m")# environment stepstate: State = env.step(action)# color the state in blueif not state.finished:user_msg = state.latest_output['content']if "Expert feedback:" in user_msg:obs, feedback = user_msg.split("Expert feedback:")feedback = "Expert feedback:" + feedback# color the observation in blue & feedback in redLOGGER.info("\n" +"\033[1m" + "User:\n" + "\033[0m" +f"\033[94m{obs}\033[0m" + "\n" + f"\033[93m{feedback}\033[0m" + "\n")else:# color the observation in blueLOGGER.info("\n" +"\033[1m" + "User:\n" + "\033[0m" +f"\033[94m{user_msg}\033[0m" + "\n")num_steps += 1LOGGER.info(f"Task finished in {num_steps} steps. Success: {state.success}")return statedef main(args: argparse.Namespace):with open(args.exp_config) as f:exp_config: Dict[str, Any] = json.load(f)DEFAULT_FEEDBACK_CONFIG = exp_config["feedback_config"]DEFAULT_ENV_CONFIG = exp_config["env_config"]LOGGER.info(f"Experiment config: {exp_config}")# initialize all the taskstask_config: Dict[str, Any] = exp_config["task"]task_class: tasks.Task = getattr(tasks, task_config["task_class"])todo_tasks, n_tasks = task_class.load_tasks(task_config["filepath"],**task_config.get("extra_load_task_kwargs", {}))# initialize the agentagent_config: Dict[str, Any] = exp_config["agent"]agent: agents.LMAgent = getattr(agents, agent_config["agent_class"])(agent_config["config"])# initialize the feedback agent (if exist)feedback_config: Dict[str, Any] = exp_config.get("feedback", DEFAULT_FEEDBACK_CONFIG)# initialize all the toolstools: List[Tool] = [getattr(importlib.import_module(module), class_name)()for module, class_name in task_config["tool_imports"]]env_config: Dict[str, Any] = exp_config.get("environment", DEFAULT_ENV_CONFIG)pathlib.Path(exp_config["output_dir"]).mkdir(parents=True, exist_ok=True)if args.interactive:output_path = os.path.join(exp_config["output_dir"], "results.interactive.jsonl")else:output_path = os.path.join(exp_config["output_dir"], "results.jsonl")done_task_id = set()if os.path.exists(output_path):with open(output_path) as f:for line in f:task_id = json.loads(line)["task"].get("task_id", "")if task_id == "":task_id = json.loads(line)["task"].get("id", "")done_task_id.add(task_id)LOGGER.info(f"Existing output file found. {len(done_task_id)} tasks done.")if len(done_task_id) == n_tasks:LOGGER.info("All tasks done. Exiting.")return# run the loop for all tasksLOGGER.info(f"Running interactive loop for {n_tasks} tasks.")n_tasks_remain = n_tasks - len(done_task_id) # only run the remaining tasksLOGGER.info(f"Running for remaining {n_tasks_remain} tasks. (completed={len(done_task_id)})")if args.n_max_tasks is not None:n_tasks_remain = min(n_tasks_remain, args.n_max_tasks - len(done_task_id))LOGGER.info(f"Running for remaining {n_tasks_remain} tasks due to command line arg n_max_tasks. (n_max_tasks={args.n_max_tasks}, completed={len(done_task_id)})")with open(output_path, "a") as f, logging_redirect_tqdm():pbar = tqdm(total=n_tasks_remain)for i, task in enumerate(todo_tasks):# # Only test 10 tasks in debug mode# if args.debug and i == 3:# breakif i >= n_tasks_remain + len(done_task_id):LOGGER.info(f"Finished {n_tasks_remain} tasks. Exiting.")break# skip done tasksif task.task_id in done_task_id:continuestate = interactive_loop(task, agent, tools, feedback_config, env_config, args.interactive)if not os.path.exists(exp_config["output_dir"]):os.makedirs(exp_config["output_dir"])f.write(json.dumps({"state": state.to_dict(),"task": task.to_dict()}) + "\n")f.flush() # make sure the output is written to filepbar.update(1)pbar.close()if __name__ == "__main__":parser = argparse.ArgumentParser("Run the interactive loop.")parser.add_argument("--exp_config",type=str,default="./configs/gpt-3.5-turbo-0613/F=gpt-3.5-turbo-16k-0613/PHF=GT-textual/max5_p2+tool+cd/reasoning/scienceqa.json",help="Config of experiment.",)parser.add_argument("--debug",action="store_true",help="Whether to run in debug mode (10 ex per task).",)parser.add_argument("--n_max_tasks",type=int,help="Number of tasks to run. If not specified, run all tasks.",)parser.add_argument("--interactive",action="store_true",help="Whether to run in interactive mode for demo purpose.",)args = parser.parse_args()LOGGER.setLevel(logging.DEBUG if args.debug else logging.INFO)main(args)
最核心的就是这两行:
action: Action = agent.act(state) # 根据当前的环境的状态state(对话历史),让大模型给出思考以及Action(生成Python代码)
state: State = env.step(action)# 根据action,调用Python代码获得结果,得到新的state
思考
- CodeAct貌似就是回到了最初的代码大模型中,用户提出Query(只不过不是明显的代码生成意图),通过Prompt来引导大模型通过生成文本推理和Python代码(也类似于PAL、PoT),并给出Python代码的执行结果。执行错误就进行Re-Fine。
- CodeAct完全依赖于Python代码以及Python环境中随时可以pip install的软件包,从而避免了人工实现API函数,或者让模型写工具的问题。大多数的Action基本上也都可以用Python代码来覆盖。
- 缺点:依然有一些Action可能无法通过Python代码来实现,例如搜索、或者本地的一些库(也许可以,但是需要大模型写一大段代码来做)。
相关文章:

Executable Code Actions Elicit Better LLM Agents
Executable Code Actions Elicit Better LLM Agents Github: https://github.com/xingyaoww/code-act 一、动机 大语言模型展现出很强的推理能力。但是现如今大模型作为Agent的时候,在执行Action时依然还是通过text-based(文本模态)后者JSO…...

循环结构(三)——do-while语句
目录 🍁引言 🍁一、语句格式 🚀格式1 🚀格式2 🍁二、语句执行过程 🍁三、实例 🚀【例1】 🚀【例2】 🚀【例3】 🍁总结 🍁备注 &am…...

pandas 或筛选
pandas 或筛选 在Pandas中,可以使用DataFrame.loc方法结合逻辑运算符来实现或筛选。这里提供一个简单的例子: import pandas as pd 创建示例DataFrame df pd.DataFrame({ ‘A’: [1, 2, 3, 4], ‘B’: [5, 6, 7, 8], ‘C’: [9, 10, 11, 12] }) 设定…...

工具(1)—截屏和贴图工具snipaste
演示和写代码文档的时候,总是需要用到截图。在之前的流程里面,一般是打开WX或者QQ,找到截图工具。但是尴尬的是,有时候,微信没登录,而你这个时候就在写文档。为了截个图,还需要启动微信…...
【从零开始一步步学习VSOA开发】快速体验SylixOS
快速体验SylixOS 安装完毕RealEvo-IDE 后,同时也安装了RealEvo-Simulator。RealEvo-Simulator 是一个虚拟运行环境,可以模拟各种体系结构并在其上运行 SylixOS。相比于物理板卡,在 RealEvo-Simulator 进行运行调测更加的方便快捷且成本低廉。…...

Ansible自动化:简化IT基础设施管理的艺术
目录 一.前言 二.Ansible简介 2.1什么是Ansible? 2.2Ansible的主要特点 2.3Ansible的应用场景 三.探索Ansible的高级功能 3.1 高级Playbook特性 3.2 Ansible Vault 3.3 动态Inventory 3.4Ansible Tower(AWX) 3.5模块开发 3.6 Ans…...

【Rust光年纪】探索Rust语言中的WebSocket库和框架:优劣一览
Rust语言中的实时通信利器:WebSocket库与框架全面解析 前言 随着Rust语言的不断发展,其在Web开发领域也变得越来越受欢迎。WebSocket作为实现实时通信的重要技术,在Rust的生态系统中也有多个库和框架提供了支持。本文将介绍几个主流的Rust …...

HTML 基础结构
目录 1. 文档声明 2. 根标签 3. 头部元素 4. 主题元素 5. 注释 6. 演示 1. 文档声明 <!DOCTYPE html>:声明文档类型,表示该文档是 html 文档, 2. 根标签 (1)所有的其他标签都要放在一对根标签中&#…...

多页合同怎么盖骑缝章_电子合同怎么盖骑缝章?
多页合同怎么盖骑缝章?电子合同怎么盖骑缝章? 对于纸质多页合同,盖骑缝章是一种常见的做法,用于确保合同的完整性,防止任何页面被替换或篡改。以下是盖骑缝章的基本步骤: 将所有合同页面平铺在桌面上。用…...

GD 32 IIC通信协议
前言: ... 通信方式 通信方式分为串行通信和并行通信。常见的串口就是串行通信的方式 常用的串行通信接口 常用的串行通信方式有USART,IIC,USB,CAN总线 同步与异步 同步通信:IIC是同步通信,有两个线一个是时钟信号线,一个数数据…...

Spring Task初学
介绍 Spring Task 是Spring框架提供的任务调度工具,可以按照约定的时间自动执行某个代码逻辑 为什么要在Java程序中使用Spring Task? 运行效果 cron表达式:一般日和周不会同时出现 入门案例 启动类添加注解EnableScheduling开始任务调度 创建MyTask类…...

决策树可解释性分析
决策树可解释性分析 决策树是一种广泛使用的机器学习算法,以其直观的结构和可解释性而闻名。在许多应用场景中,尤其是金融、医疗等领域,模型的可解释性至关重要。本文将从决策路径、节点信息、特征重要性等多个方面分析决策树的可解释性&…...

BUGKU-WEB never_give_up
解题思路 F12查看请求和响应,查找线索 相关工具 base64解码URL解码Burp Suit抓包 页面源码提示 <!--1p.html--> 2. 去访问这个文件,发现直接跳转到BUGKU首页,有猫腻那就下载看看这个文件内容吧 爬虫下载这个文件 import requests …...

hive自动安装脚本
使用该脚本注意事项 安装hive之前确定机子有网络。或者yum 更改为本地源,因为会使用epel仓库下载一个pv的软件使用该脚本前提是自行安装好mysql数据库准备好tomcat软件包,该脚本使用tomcat9.x版本测试过能正常执行安装成功,其他版本没有测试…...

unix 用户态 内核态
在UNIX操作系统中,"用户态"和"内核态"是两种不同的运行模式,它们定义了程序在执行时的权限级别: 用户态(User Mode): 用户态是程序运行的常规状态,大多数应用程序在执行时…...

GD32 IAP升级——boot和app相互切换
GD32 IAP升级——boot和app相互切换 目录 GD32 IAP升级——boot和app相互切换1 Keil工程设置1.1 修改ROM1.2 Keil烧录配置 2 代码编写2.1 app跳转2.2 软件重启2.3 app中断向量表偏移 结束语 1 Keil工程设置 1.1 修改ROM GD32内部Flash是一整块连续的内存,但是因为…...

C++11革新之旅:探索C++编程的无限可能
C11革新之旅:探索C编程的无限可能 C11,作为C语言的一个重要标准,为C编程带来了革命性的变革。它不仅引入了众多新特性和改进,还极大地增强了C的表达能力、提高了程序的性能和资源利用率。本文将从多个方面深入探讨C11的新特性&am…...

免费自动化AI视频剪辑工具
下载地址:https://pan.quark.cn/s/3c5995da512e FunClip是一款完全开源、本地部署的自动化视频剪辑工具,通过调用阿里巴巴通义实验室开源的FunASR Paraformer系列模型进行视频的语音识别,随后用户可以自由选择识别结果中的文本片段或说话人&a…...

Linux中安装C#的.net,创建运行后端或控制台项目
安装脚本命令: 创建一个sh文件并将该文件更改权限运行 sudo apt update wget https://packages.microsoft.com/config/ubuntu/20.04/packages-microsoft-prod.deb -O packages-microsoft-prod.deb sudo dpkg -i packages-microsoft-prod.deb sudo apt-get upd…...

最长上升子序列LIS(一般+优化)
1. 题目 题目链接: B3637 最长上升子序列 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 输入样例: 6 1 2 4 1 3 4 输出样例: 4 说明/提示: 分别取出 1、2、3、4 即可。 2. 具体实现 2.1 一般做法 dp[i]表示第i个位置的…...

AI教育系统架构实战:从个性化学习到智能辅导与自动化评估
1. 项目概述:当AI走进课堂,我们到底在谈论什么?“AI驱动教育变革”这个标题听起来宏大,但落到一线教师、课程设计师或者教育科技产品经理的桌上,它立刻会分解成一系列具体而微、甚至有些棘手的问题。我在这行摸爬滚打十…...

Phi-4-mini-flash-reasoning一文详解:轻量级开源模型在教育SaaS中的降本提效实践
Phi-4-mini-flash-reasoning一文详解:轻量级开源模型在教育SaaS中的降本提效实践 1. 模型概述与教育场景价值 Phi-4-mini-flash-reasoning是一款专为复杂推理任务优化的轻量级语言模型,在教育科技领域展现出独特的应用价值。相比传统大模型,…...

动态思维链与并行强化学习在自动定理证明中的应用
1. 项目背景与核心价值自动定理证明作为形式化方法的核心技术,正在经历从静态推理到动态学习的范式转变。这个项目聚焦于两大前沿方向:动态思维链(CoT)和并行强化学习(RL)的协同优化,本质上是在…...

给RK3568的Linux 4.19内核打RT-Preempt补丁,我踩过的那些坑都帮你填好了
给RK3568的Linux 4.19内核打RT-Preempt补丁:实战排坑全记录 在嵌入式开发领域,实时性往往是决定系统可靠性的关键因素。RK3568作为一款广泛应用于工业控制、边缘计算场景的ARM处理器,其Linux内核的实时性优化一直是开发者关注的焦点。本文将深…...

CANN/metadef Add函数API文档
Add 【免费下载链接】metadef Ascend Metadata Definition 项目地址: https://gitcode.com/cann/metadef 函数功能 新增一个ContinuousVector元素,其中新增ContinuousVector元素的容量为inner_vector_capacity。 函数原型 template<typename T> Con…...

多智能体系统协同韧性:从概念到量化评估的工程实践
1. 项目概述:从“各自为战”到“协同共生”的韧性挑战在人工智能的演进浪潮中,多智能体系统正从实验室走向现实世界的复杂场景。无论是自动驾驶车队的协同调度、工业机器人的集群作业,还是在线游戏中的NPC协作,其核心都是多个自主…...

Honey Select 2 插件安装避坑指南:从BepInEx到花瓣显示的完整配置流程
Honey Select 2 插件安装避坑指南:从BepInEx到花瓣显示的完整配置流程 在《Honey Select 2》的Mod生态中,BepInEx框架作为基础支撑,承载着各类功能插件的运行。但对于刚接触Mod安装的新手玩家来说,插件依赖关系复杂、安装顺序不当…...
)
Chrome升级后网页错乱?别慌!手把手教你回退到稳定版本(Windows/Mac/Linux全平台指南)
Chrome升级后网页错乱?全平台降级指南与深度解决方案 早上打开电脑,发现Chrome自动更新后最常访问的网站排版全乱了,插件图标变成灰色,工作效率瞬间归零——这种场景对现代办公族来说简直是噩梦。浏览器作为数字生活的枢纽&#…...

Windows驱动仓库管理神器:Driver Store Explorer全方位指南
Windows驱动仓库管理神器:Driver Store Explorer全方位指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否注意到Windows系统盘空间在不知不觉中被占用?那…...

Hitboxer终极指南:免费解决游戏按键冲突的专业SOCD重映射工具
Hitboxer终极指南:免费解决游戏按键冲突的专业SOCD重映射工具 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的格斗游戏中,因为同时按下左右方向键而无法准确释放必杀技&…...