每日学术速递8.5—1
1.SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency

标题: SV4D:具有多帧和多视图一致性的动态 3D 内容生成
作者:Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, Varun Jampani
文章链接:https://arxiv.org/abs/2407.17470
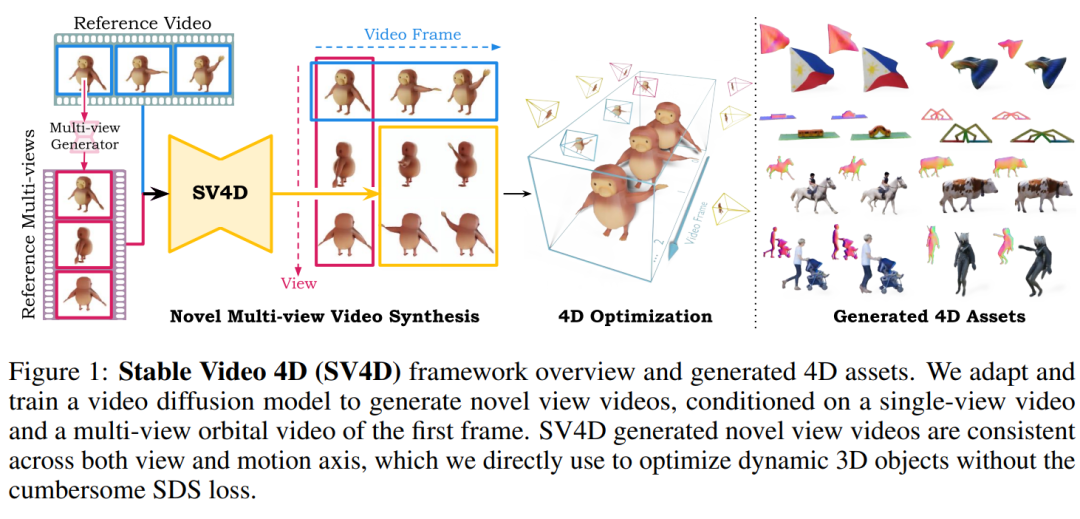
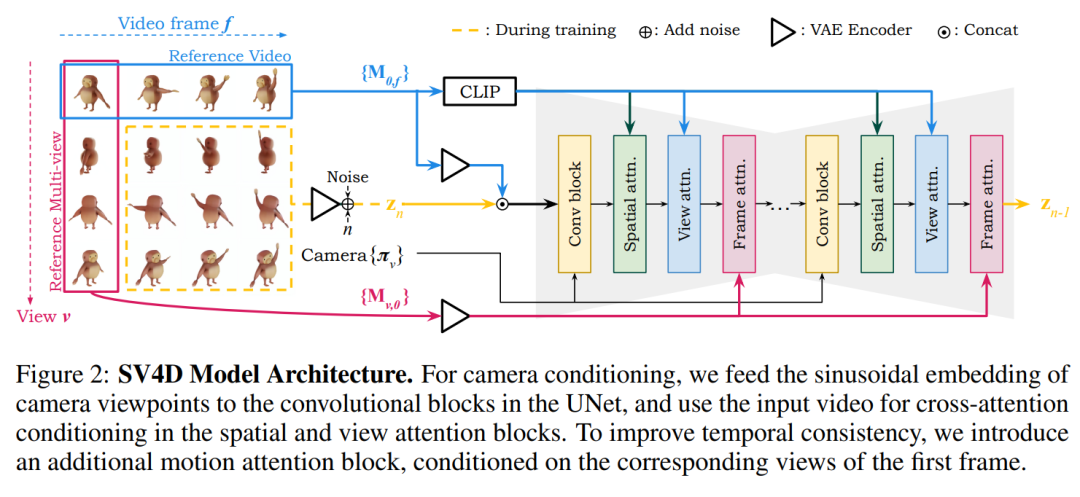
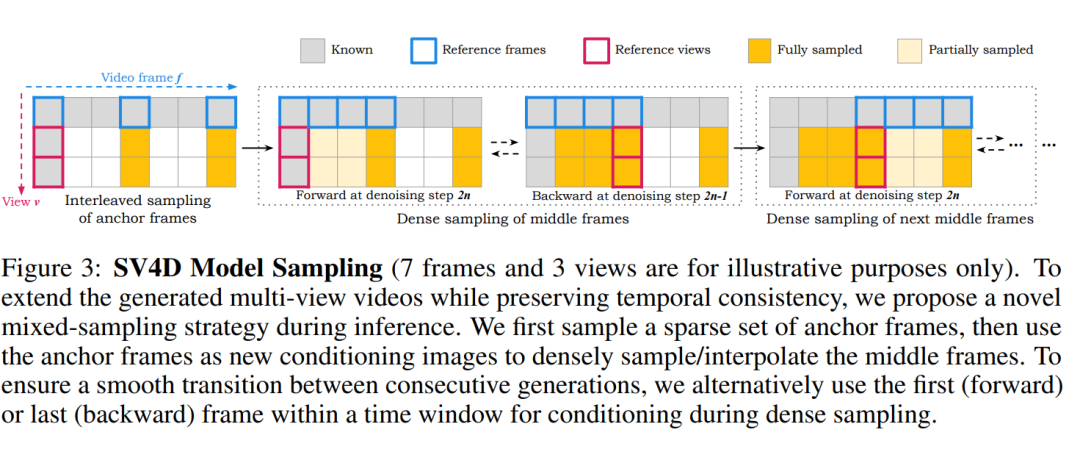
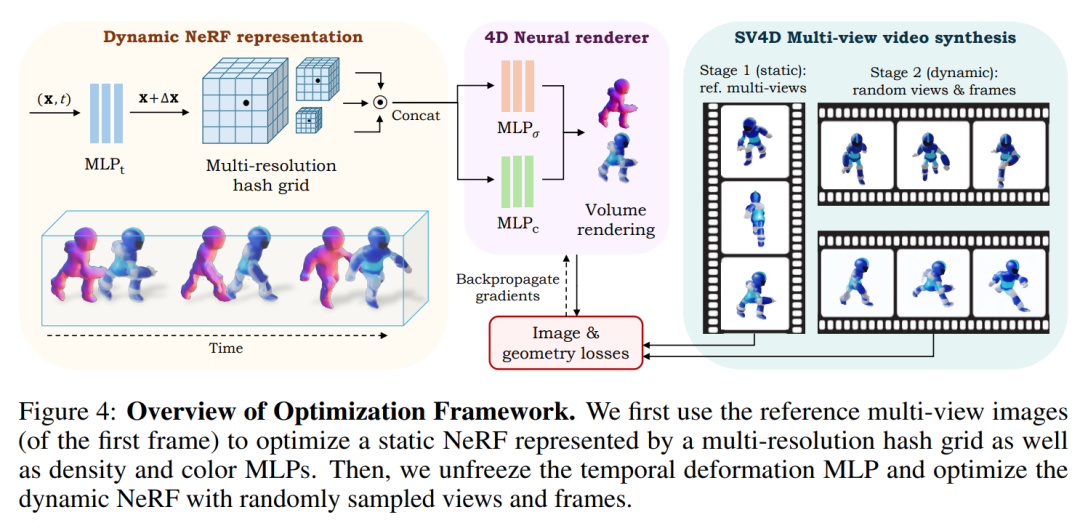
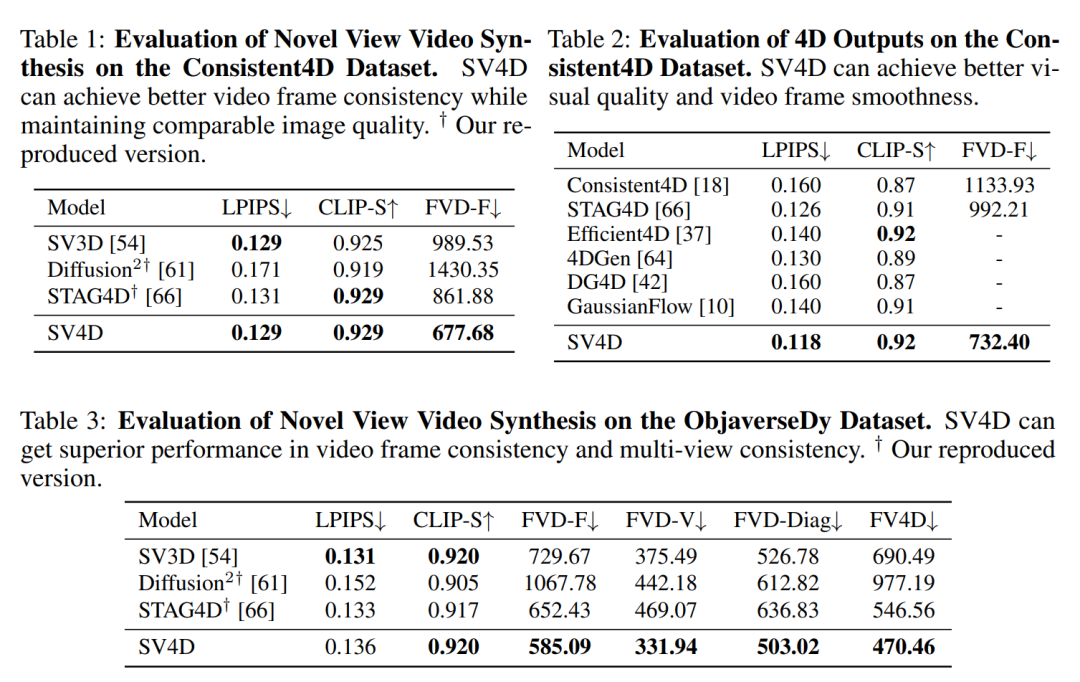


摘要:
我们提出了稳定视频 4D (SV4D),这是一种用于多帧和多视图一致动态 3D 内容生成的潜在视频扩散模型。与之前依赖单独训练的生成模型进行视频生成和新视图合成的方法不同,我们设计了一个统一的扩散模型来生成动态 3D 对象的新视图视频。具体来说,给定单目参考视频,SV4D 为每个视频帧生成时间一致的新颖视图。然后,我们使用生成的新颖视图视频来有效地优化隐式 4D 表示(动态 NeRF),而无需在大多数先前的工作中使用繁琐的基于 SDS 的优化。为了训练我们统一的新颖视图视频生成模型,我们从现有的 Objaverse 数据集中策划了一个动态 3D 对象数据集。多个数据集和用户研究的广泛实验结果证明,与之前的作品相比,SV4D 在新视角视频合成和 4D 生成方面具有最先进的性能。
这篇论文试图解决什么问题?
这篇论文提出了一种名为Stable Video 4D (SV4D) 的模型,旨在解决动态3D内容生成中的两个主要问题:
-
数据集的缺乏:目前没有大规模的4D对象数据集来训练一个健壮的生成模型。4D生成涉及到3D形状、外观(纹理)以及对象在3D空间中的运动,需要大量的参数来表示,因此需要大规模的数据集来训练。
-
生成模型的独立性问题:以往的方法依赖于分别训练的视频生成和新视角合成的生成模型,这导致在对象运动和新视角合成的独立建模中产生不满意的结果。此外,这些方法在生成单个4D对象时往往需要耗费数小时,因为它们基于耗时的得分蒸馏采样(SDS)优化。
为了解决这些问题,SV4D设计了一个统一的扩散模型,用于从单目参考视频生成动态3D对象的新视角视频,并且这些视频在时间上是一致的。然后使用这些生成的新视角视频来高效地优化隐式4D表示(动态NeRF),无需使用大多数先前工作中的SDS优化。这种方法提高了新视角视频合成以及4D生成的性能,并在多个数据集和用户研究中展示了其相对于先前工作的最先进性能。
论文如何解决这个问题?
论文通过提出Stable Video 4D (SV4D)模型来解决动态3D内容生成的问题,具体方法如下:
-
统一的扩散模型:SV4D设计了一个统一的扩散模型,与以往分别训练视频生成和新视角合成模型的方法不同,该模型可以同时处理视频帧和视角的一致性。
-
双注意力机制:SV4D引入了视图注意力(view attention)和帧注意力(frame attention)两个模块。视图注意力模块确保每个视频帧中的多视图图像在空间上的一致性,而帧注意力模块确保每个视点的多帧图像在时间上的一致性。
-
优化4D表示:使用SV4D生成的新视角视频来优化一个隐式的4D表示(动态NeRF),这个过程不需要使用传统的基于SDS的优化,从而提高了效率。
-
数据集构建:由于缺乏大规模的4D数据集,研究者从现有的Objaverse数据集中筛选并构建了一个动态3D对象数据集,称为ObjaverseDy,用于训练SV4D模型。
-
混合采样方案:为了处理长视频输入时的内存限制问题,SV4D采用了一种混合采样方案,该方案能够顺序处理输入帧的子集,同时保持输出图像网格的多帧和多视图一致性。
-
实验验证:通过在多个数据集上进行广泛的实验和用户研究,验证了SV4D在新视角视频合成和4D生成方面的性能,与先前的工作相比,SV4D在多帧和多视图一致性方面取得了更好的结果。
-
评估指标:使用修改版的FVD度量标准来评估视频帧和视图的一致性,从而验证了SV4D方法的有效性和设计选择。
通过这些方法,SV4D能够生成与输入视频在动态和多视图上一致的新视角视频,并有效地优化4D表示,从而在动态3D对象生成方面实现了最先进的性能。
论文做了哪些实验?
论文中进行了一系列实验来评估SV4D模型在新视角视频合成和4D生成方面的性能。以下是实验的主要部分:
-
数据集:评估使用了合成数据集(ObjaverseDy, Consistent4D)和真实世界视频数据集(DAVIS)。
-
度量标准:使用了多种度量标准,包括Learned Perceptual Similarity (LPIPS)、CLIP-score (CLIP-S) 以及修改版的FVD度量标准,后者用于评估视频帧和视图的一致性。
-
基线比较:与几种能够从单视图生成多视图视频的方法进行了比较,包括SV3D、Diffusion2、STAG4D等。
-
定量比较:
-
对于新视角视频合成,SV4D在视频帧一致性(FVD-F)方面表现优于基线方法,同时在图像质量方面保持了可比性。
-
在4D生成方面,SV4D在视觉质量、运动平滑度、多视图平滑度和运动-多视图联合平滑度方面均优于基线方法。
-
-
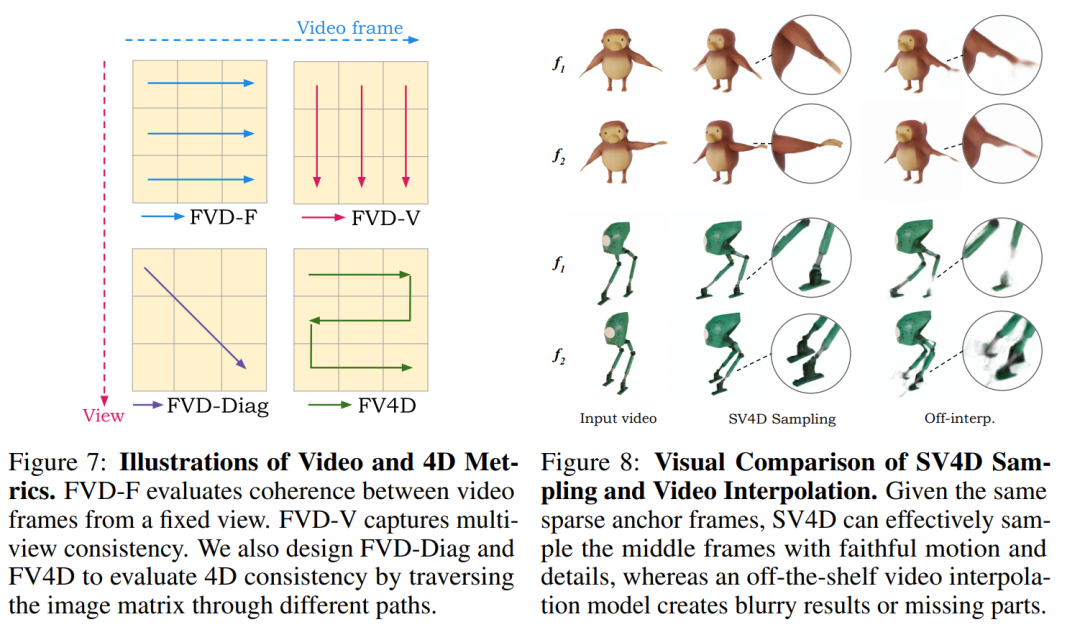
视觉比较:展示了SV4D与其他方法在多视角视频合成和4D生成方面的可视化结果,突出了SV4D在细节、忠实度和时间一致性方面的优势。
-
用户研究:进行了用户研究,让用户评估不同方法生成的新视角视频和4D输出的稳定性、现实感和与参考主题的相似度。SV4D在用户偏好方面取得了显著优势。
-
消融研究:进行了消融实验来验证模型设计选择的有效性,包括:
-
验证SV4D生成的锚帧在视频帧和多视图一致性方面的优势。
-
比较SV4D采样与现成的插值方法在生成完整图像矩阵时的效果。
-
-
不同采样策略的评估:评估了SV4D采样策略与独立采样和交错采样等其他直观采样策略的效果。
这些实验全面评估了SV4D模型的性能,证明了其在动态3D对象生成方面的先进性和实用性。
论文的主要内容:
SV4D论文的主要内容可以总结如下:
-
问题提出:论文针对动态3D内容生成(4D生成)中的挑战,包括缺乏大规模4D数据集和现有方法在生成一致性方面的不足。
-
方法介绍:提出了Stable Video 4D (SV4D)模型,一个统一的潜在视频扩散模型,用于多帧和多视角一致的动态3D内容生成。
-
技术亮点:
-
引入视图注意力和帧注意力机制,增强模型在多视角和时间上的一致性。
-
无需传统的得分蒸馏采样(SDS)优化,直接使用生成的新视角视频优化隐式4D表示(动态NeRF)。
-
-
数据集构建:创建了ObjaverseDy数据集,从现有的Objaverse数据集中筛选出适合训练的动态3D对象。
-
实验验证:在多个数据集上进行了广泛的实验,包括合成数据集(ObjaverseDy, Consistent4D)和真实世界视频数据集(DAVIS),并与现有的方法进行了比较。
-
性能评估:使用LPIPS、CLIP-score和修改版的FVD度量标准来评估生成视频的视觉质量和一致性。
-
用户研究:通过用户研究验证了SV4D在多视角视频合成和4D生成方面的性能优势。
-
消融实验:进行消融实验来展示SV4D模型设计选择的有效性,包括锚帧生成质量和采样策略。
-
结论:SV4D提供了一个坚实的基础模型,用于进一步研究动态3D对象生成,并在新视角视频合成和4D生成方面达到了最先进的性能。
-
致谢:感谢所有在模型开发和发布过程中提供帮助的人。
论文通过提出创新的方法和进行广泛的实验验证,展示了SV4D在动态3D内容生成方面的潜力和应用前景。
2.AHMF: Adaptive Hybrid-Memory-Fusion Model for Driver Attention Prediction

标题:AHMF:用于驾驶员注意力预测的自适应混合记忆融合模型
作者:Dongyang Xu, Qingfan Wang, Ji Ma, Xiangyun Zeng, Lei Chen
文章链接:https://arxiv.org/abs/2407.17442
项目代码:https://github.com/THUDM/ImageReward
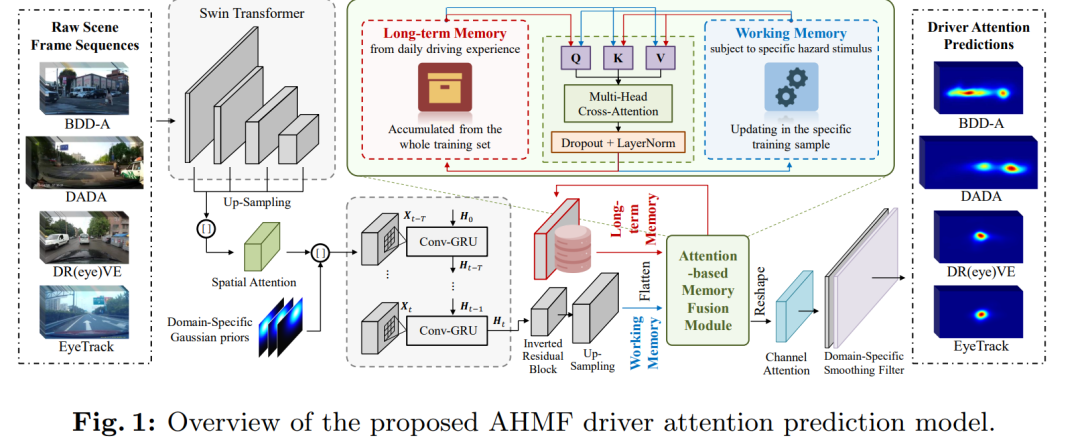
摘要:
准确的驾驶员注意力预测可以为智能汽车理解交通场景并做出明智的驾驶决策提供重要参考。尽管现有的驾驶员注意力预测研究通过结合先进的显着性检测技术提高了性能,但他们忽视了通过从认知科学角度分析驾驶任务来实现人类启发预测的机会。在驾驶过程中,驾驶员的工作记忆和长期记忆分别在场景理解和经验检索中发挥着至关重要的作用。它们共同形成态势感知,帮助驾驶员快速了解当前的交通状况,并根据过去的驾驶经验做出最佳决策。为了明确整合这两种类型的记忆,本文提出了一种自适应混合记忆融合(AHMF)驾驶员注意力预测模型,以实现更类似于人类的预测。具体来说,该模型首先对当前场景中特定危险刺激的信息进行编码,以形成工作记忆。然后,它自适应地从长期记忆中检索类似的情境经历以进行最终预测。该模型利用域适应技术,在多个数据集上进行并行训练,从而丰富长期记忆模块中积累的驾驶经验。与现有模型相比,我们的模型在多个公共数据集的各种指标上表现出了显着的改进,证明了在驾驶员注意力预测中集成混合记忆的有效性。
这篇论文试图解决什么问题?
这篇论文提出了一个名为Adaptive Hybrid-Memory-Fusion (AHMF) 的驾驶员注意力预测模型,旨在解决现有驾驶员注意力预测方法在实现类似人类的预测性能方面的不足。具体来说,论文指出虽然现有的研究通过整合先进的显著性检测技术提高了性能,但它们忽视了从认知科学的角度分析驾驶任务,实现人类启发式预测的机会。驾驶员在驾驶过程中,其工作记忆和长期记忆在场景理解以及基于经验的决策中发挥着关键作用。然而,现有模型并没有很好地模拟这两种记忆机制。
为了解决这个问题,AHMF模型明确地将工作记忆和长期记忆整合到驾驶员注意力预测中,以实现更加类似人类的预测。这包括:
-
工作记忆编码:模型首先编码当前场景中特定危险刺激的信息,形成工作记忆。
-
长期记忆检索:然后,模型从长期记忆中自适应地检索类似的情景经验,用于最终预测。
-
域适应技术:通过跨多个数据集的并行训练,丰富长期记忆模块中积累的驾驶经验,提高模型的泛化能力。
论文通过在多个公共数据集上的比较实验,证明了整合混合记忆在驾驶员注意力预测中的有效性。
论文如何解决这个问题?
论文通过提出一个名为Adaptive Hybrid-Memory-Fusion (AHMF) 的模型来解决驾驶员注意力预测的问题。AHMF模型的解决策略主要包括以下几个关键方面:
-
工作记忆编码:模型首先对当前场景中特定的危险刺激进行编码,形成工作记忆。这涉及到使用Swin Transformer提取关键的语义特征,并通过空间注意力机制来增强局部特征之间的关联。
-
长期记忆建模:长期记忆被视为一个离线知识库,初始化为一组可学习的参数。在训练过程中,长期记忆会根据工作记忆的查询检索关键的驾驶经验,并不断更新以整合新编码的特征。
-
混合记忆融合:模型设计了一个基于注意力机制的高效自适应记忆融合模块,灵感来源于人类驾驶员的情景意识机制。通过两个多头交叉注意力模块,促进两种记忆之间的信息转移。
-
域特定模块:为了提高模型的泛化能力,论文还整合了一系列域适应技术,包括域特定的批量归一化、高斯先验和平滑滤波器,以在多个数据集上进行并行训练。
-
实验验证:通过在多个公共数据集上的比较实验,论文证明了AHMF模型在多个评价指标上优于现有的最先进方法。
-
认知科学与深度学习的结合:论文的方法与现有方法不同之处在于,它明确地模拟了人类驾驶员在驾驶过程中的工作记忆和长期记忆,以及它们的情景意识机制。
通过这些策略,AHMF模型能够更准确地预测驾驶员的注意力,从而为智能车辆提供更接近人类驾驶员认知的决策支持。
论文做了哪些实验?
论文中进行了一系列的实验来验证所提出的Adaptive Hybrid-Memory-Fusion (AHMF) 模型的性能。以下是实验的主要方面:
-
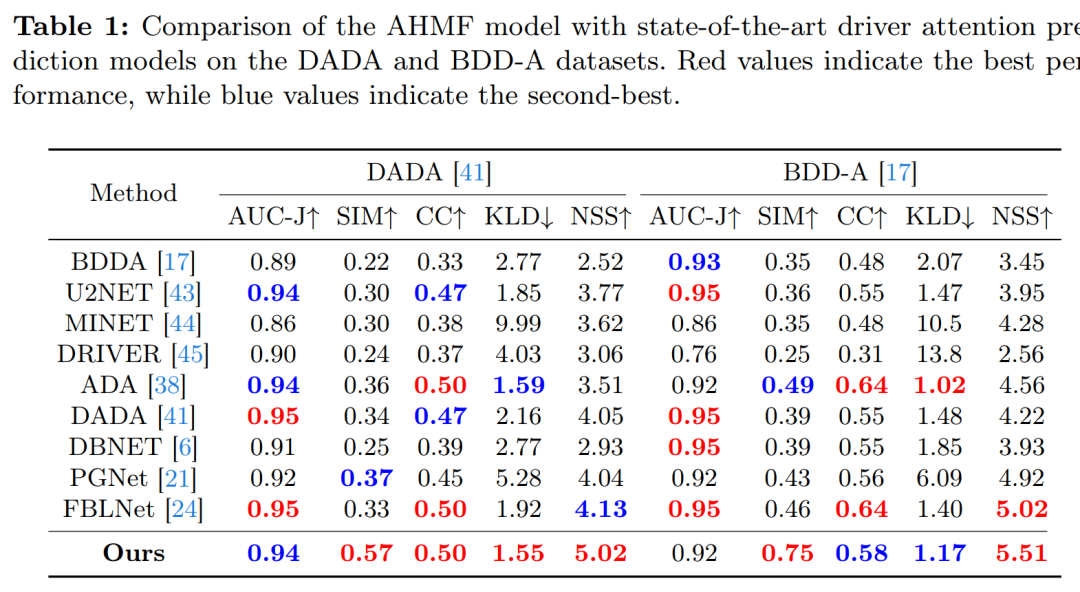
数据集:AHMF模型在四个广泛使用的公共大规模驾驶员注意力数据集上进行了训练和测试,包括Driver Attention and Driver Accident (DADA)、Berkeley DeepDrive attention (BDD-A)、DReyeVE和EyeTrack。
-
评估指标:为了全面评估模型性能,使用了多种显著性评估指标,包括三个基于分布的指标(Similarity (SIM)、Kullback-Leibler divergence (KLD)、Pearson’s correlation coefficient (CC))和两个基于位置的指标(Normalized Scanpath Saliency (NSS) 和 Area Under ROC Curve Judd (AUC-J))。
-
与现有方法的比较:AHMF模型与多个现有的最先进(state-of-the-art, SOTA)驾驶员注意力预测模型进行了定量和定性比较。
-
定量结果:在DADA和BDD-A数据集上,AHMF模型在多个指标上展示了令人满意的性能,特别是在SIM和NSS指标上,与现有最佳方法相比取得了显著的改进。
-
定性结果:通过可视化的方式展示了AHMF模型与MLNet和PGNet等模型在预测驾驶员注意力图方面的差异,结果表明AHMF模型能够更准确地模拟人类驾驶员的注意力分布。
-
消融研究:进行了消融研究来分析AHMF模型中不同设计选择的影响,包括不同组件(如空间注意力、通道注意力和混合记忆融合模块)的贡献,以及工作记忆持续时间对模型性能的影响。
-
域适应技术的影响:研究了域特定模块对模型泛化能力的影响,包括域特定批量归一化、高斯先验和平滑滤波器。
-
不同骨干网络的比较:评估了使用不同骨干网络(如Swin-Transformer-Tiny和Resnet-50)对模型性能的影响。
-
历史输入序列长度的影响:研究了不同长度的历史输入序列对模型性能的影响,以了解在工作记忆中编码更多时间信息的重要性。
通过这些实验,论文证明了AHMF模型在驾驶员注意力预测方面的有效性和优越性。
论文的主要内容:
这篇论文的主要内容可以概括为以下几个要点:
-
问题定义:论文针对驾驶员注意力预测问题,指出现有方法主要依赖计算机视觉技术的进步,而忽视了从认知科学角度分析驾驶任务的必要性。
-
研究目标:提出了一个名为Adaptive Hybrid-Memory-Fusion (AHMF) 的模型,旨在通过模拟人类的工作记忆和长期记忆机制,实现更类似于人类的驾驶员注意力预测。
-
模型结构:AHMF模型包含两个核心模块:时间-空间工作记忆编码和基于注意力的混合记忆融合。此外,还整合了域特定的模块以增强模型的泛化能力。
-
工作记忆编码:使用Swin Transformer提取场景特征,并通过空间注意力机制增强局部特征之间的关系。
-
长期记忆建模:长期记忆作为一个离线知识库,通过训练过程中的检索和更新,积累驾驶经验。
-
混合记忆融合:设计了基于注意力机制的自适应记忆融合模块,模拟人类驾驶员的情景意识机制。
-
域适应技术:通过跨多个数据集的并行训练,使用域特定模块减少数据异质性,丰富长期记忆。
-
实验验证:在多个公共数据集上进行了实验,包括定量和定性结果,证明了AHMF模型在多个评价指标上优于现有的最先进方法。
-
消融研究:通过一系列消融实验,分析了模型中不同组件的贡献,以及工作记忆持续时间对性能的影响。
-
结论与未来工作:论文总结了AHMF模型的主要贡献,并提出了未来可能的研究方向,如改进记忆建模方法和进行更深入的跨学科研究。
论文通过提出一个新颖的驾驶员注意力预测模型,不仅在技术上取得了进步,也为未来相关研究提供了新的思路和方法。
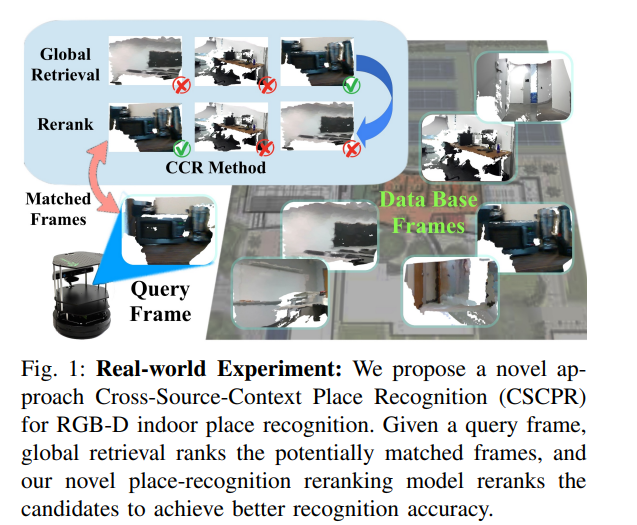
3.CSCPR: Cross-Source-Context Indoor RGB-D Place Recognition

标题: CSCPR:跨源上下文室内 RGB-D 地点识别
作者: Jing Liang, Zhuo Deng, Zheming Zhou, Min Sun, Omid Ghasemalizadeh, Cheng-Hao Kuo, Arnie Sen, Dinesh Manocha
文章链接:https://arxiv.org/abs/2407.17457
摘要:
我们提出了一种新的算法,即跨源上下文地点识别 (CSCPR),用于 RGB-D 室内地点识别,它将全局检索和重新排序集成到单个端到端模型中。与之前主要关注 RGB 域的方法不同,CSCPR 旨在处理 RGB-D 数据。我们扩展了集群上下文(CoC)来处理嘈杂的彩色点云,并引入了两个用于重新排名的新颖模块:自上下文集群(SCC)和跨源上下文集群(CSCC),它们增强了特征表示和匹配查询 -分别基于局部特征的数据库对。我们还展示了两个新的数据集:ScanNetIPR 和 ARKitIPR。我们的实验表明,CSCPR 在 ScanNet-PR 数据集的 Recall@1 中明显优于这些数据集上最先进的模型至少 36.5%,在新数据集中优于最新模型 44%。代码和数据集将被发布。
这篇论文试图解决什么问题?
这篇论文提出了一种新的算法,名为Cross-Source-Context Indoor RGB-D Place Recognition (CSCPR),旨在解决室内RGB-D(红绿蓝-深度)场景识别问题。具体来说,CSCPR算法试图解决以下挑战:
-
不同传感器数据的融合:算法需要处理来自不同传感器的数据,如RGB、RGB-D、LiDar等,这些数据源要求特定的特征处理方式。
-
环境挑战:包括光照变化、动态物体、遮挡和尺度变化等因素,这些都会影响场景识别的准确性。
-
RGB-D室内场景识别的不足:当前的许多方法主要关注于全局检索,而没有充分利用RGB-D数据的潜力,尤其是在室内环境中,深度信息对于场景识别至关重要。
-
缺乏大规模清洁数据集:对于室内视觉任务,虽然存在许多设计用于对象分类、分割等的数据集,但这些数据集并不专门针对RGB-D场景识别任务的训练目的,这些任务需要具有重叠的正负匹配帧和大规模数据集。
CSCPR算法通过集成全局检索和重排序到一个端到端模型中,提出了一种新颖的端到端架构来处理RGB-D室内场景识别问题。此外,论文还引入了两个新的大规模RGB-D室内场景识别数据集,ScanNetIPR和ARKitIPR,以解决现有数据集的不足。
论文如何解决这个问题?
论文通过提出一种名为Cross-Source-Context Indoor RGB-D Place Recognition (CSCPR) 的新算法来解决室内RGB-D场景识别问题。CSCPR算法的解决方案主要包括以下几个关键点:
-
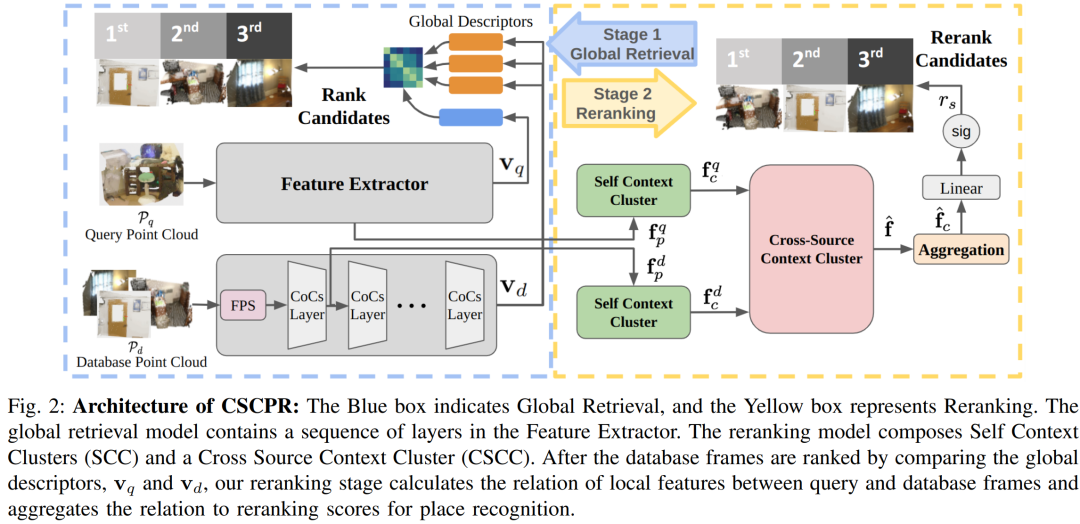
端到端架构:CSCPR设计为一个整合了全局检索和重排序的端到端模型,能够同时处理RGB和深度信息。
-
全局检索:使用CoCs(Context-of-Clusters)结构作为特征提取器的骨干,适应于从RGB图像处理转换到点云处理,通过PointConvFormer块来提取特征。
-
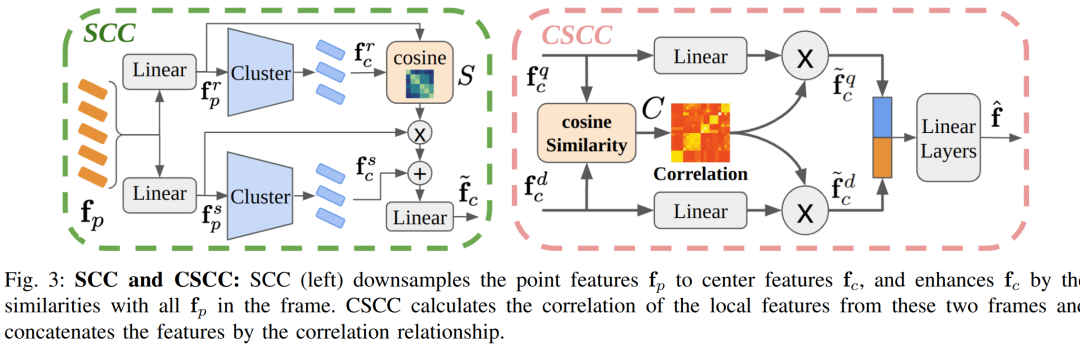
重排序模块:引入了两个新颖的模块,Self-Context Cluster (SCC) 和 Cross Source Context Cluster (CSCC),用于增强局部特征表示,并基于局部特征匹配查询和数据库对。
-
多尺度特征学习:SCC模块通过从局部细节尺度和全局粗尺度学习特征,以处理室内RGB-D数据的大变化。
-
特征增强:通过将局部特征与帧的全局信息相结合,增强了特征的表达能力。
-
相关性计算:CSCC模块通过计算查询和数据库帧之间的局部特征的相关性,快速准确地进行重排序。
-
数据集生成:为了解决大规模清洁数据集的缺乏问题,论文提出了两个新的大规模RGB-D室内场景识别数据集,ScanNetIPR和ARKitIPR,通过选择具有重叠的帧来生成数据集。
-
性能评估:在多个数据集上评估CSCPR的性能,包括ScanNet-PR、ScanNetIR和ARKitIPR,并与现有的最先进方法进行比较。
-
损失函数和训练策略:使用Triplet Loss和Entropy Loss Function进行全局检索和重排序的训练,采用Adam优化器和余弦退火学习率调度器。
通过这些方法,CSCPR算法在RGB-D室内场景识别任务上取得了显著的性能提升,至少在Recall@1指标上超越了现有最先进模型36.5%。
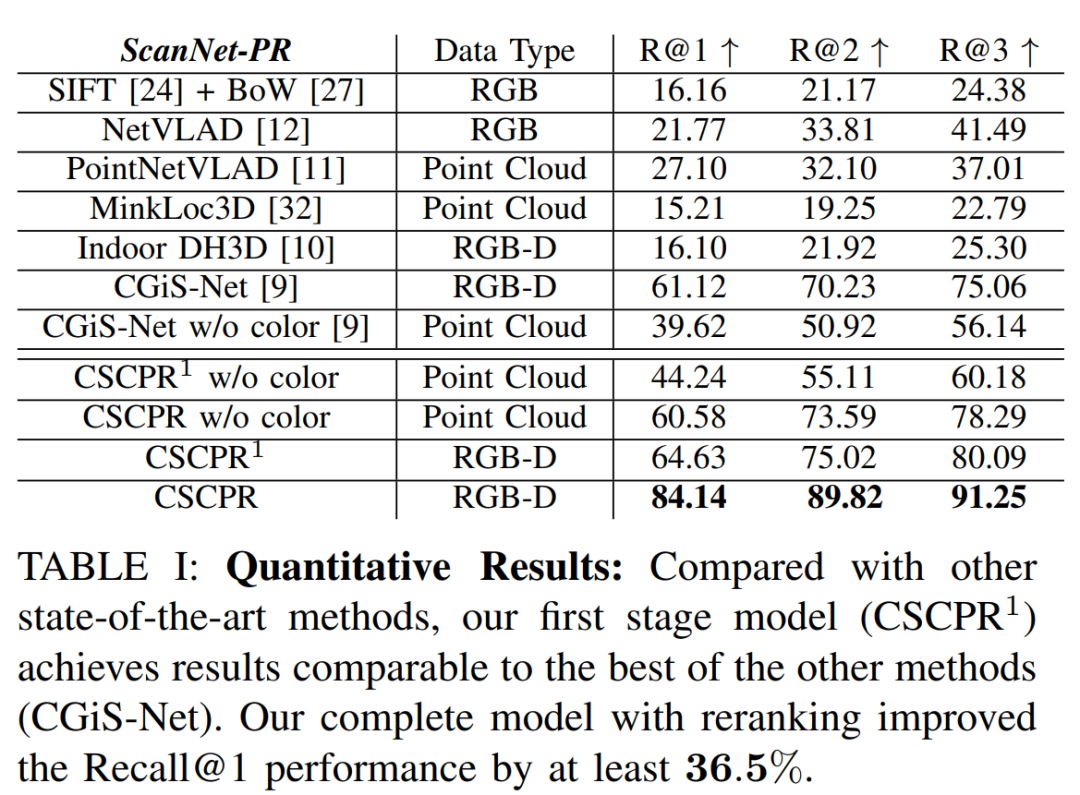
论文做了哪些实验?
论文中进行了一系列的实验来评估CSCPR算法的性能,并与现有的最先进方法进行比较。以下是论文中进行的主要实验:
-
端到端解决方案评估 (E1):
-
在公共大型RGB-D数据集ScanNet-PR上,将CSCPR的全局检索模型(CSCPR1)与其他最新技术方法进行比较。
-
在新提出的数据集ScanNetIPR和ARKitIPR上,评估CSCPR模型的性能,包括RGB-D和纯点云方法。
-
-
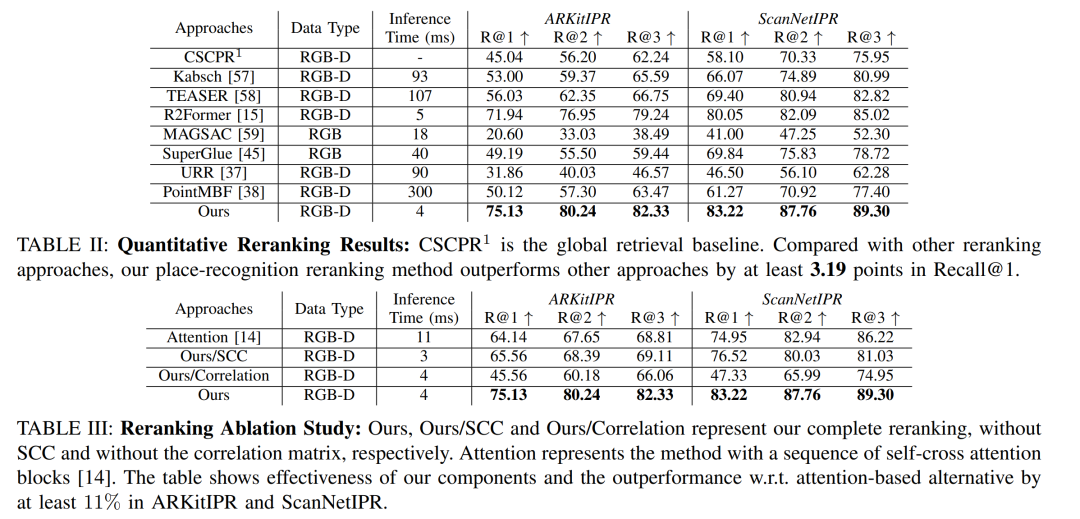
场景识别重排序评估 (E2):
-
比较所有场景识别重排序方法,包括经典的基于RANSAC的几何验证方法和基于学习的重排序方法。
-
将CSCPR与其他重排序相似方法进行比较,包括匹配方法和注册方法。
-
-
定量重排序结果:
-
在ARKitIPR和ScanNetIPR数据集上,展示CSCPR方法在Recall@1、Recall@2和Recall@3指标上的性能,并与其它方法进行比较。
-
-
消融研究:
-
通过比较CSCPR的不同变体(包括完整模型、不含SCC的模型、不含相关性矩阵的模型),来展示CSCPR各个组成部分的有效性。
-
-
定性结果:
-
展示CSCPR在RGB-D室内场景识别中的可视化结果,包括与其他方法的比较。
-
-
性能与效率的比较:
-
对CSCPR的推理时间进行测量,并与其它方法进行比较,以展示其效率。
-
-
数据集生成方法:
-
描述了用于生成ScanNetIPR和ARKitIPR数据集的方法,包括选择具有重叠的帧来生成训练和测试数据。
-
-
数据集差异分析:
-
比较了ScanNet-PR和ScanNetIPR数据集之间的差异,以及为什么ScanNetIPR更适合训练和评估场景识别任务。
-
这些实验不仅验证了CSCPR算法的性能,还为RGB-D室内场景识别领域提供了有价值的数据集和基准。通过这些实验,论文展示了CSCPR在准确度、效率和实用性方面的优势。
论文的主要内容:
这篇论文的主要内容可以概括为以下几个要点:
-
问题定义:论文针对的是室内RGB-D场景识别问题,这是一个在机器人导航、增强现实等领域具有重要应用的计算机视觉任务。
-
现有挑战:室内场景识别面临多种挑战,包括不同传感器数据的融合、环境变化(如光照、动态物体、遮挡等)、RGB-D数据的潜力未被充分利用,以及大规模清洁数据集的缺乏。
-
CSCPR算法:提出了一种新的算法Cross-Source-Context Indoor RGB-D Place Recognition (CSCPR),它是一个端到端模型,集成了全局检索和重排序机制,专门设计用于处理RGB-D数据。
-
关键创新:
-
扩展了Context-of-Clusters (CoCs)方法,以增强局部特征表示。
-
引入了Self-Context Cluster (SCC)和Cross Source Context Cluster (CSCC)两个新颖模块,用于改善特征表示和基于局部特征的匹配。
-
-
数据集贡献:为了解决数据集缺乏的问题,论文提出了两个新的大规模RGB-D室内场景识别数据集:ScanNetIPR和ARKitIPR。
-
性能评估:通过在多个数据集上的实验,论文展示了CSCPR算法在场景识别任务上显著超越了现有最先进模型,至少在Recall@1指标上提高了36.5%。
-
实验设计:论文进行了包括端到端解决方案评估、场景识别重排序评估、定量重排序结果、消融研究和定性结果等多方面的实验。
-
结论与未来工作:论文总结了CSCPR算法的主要贡献,并指出了其局限性和未来可能的研究方向。
-
技术细节:论文详细描述了CSCPR算法的架构、训练策略、损失函数以及数据集生成方法。
这篇论文通过提出新的算法和数据集,为RGB-D室内场景识别领域做出了重要贡献,并为未来的研究提供了新的方向和工具。
相关文章:
每日学术速递8.5—1
1.SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency 标题: SV4D:具有多帧和多视图一致性的动态 3D 内容生成 作者:Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, Varun Jampani 文章链接&…...

1、操作系统相关概念
1、操作系统是计算机上的第一层软件,用于管理计算机硬件设备,提高他们的利用率和通吐量,并为用户和应用程序提供一个接口。不同操作系统目标不同,查询设备的操作系统,侧重人机交互性;武器控制操作系统&…...

【ModelSim】仿真问题记录
1、波形出不全: 1、甚至连clk波形都出不来 2、个别波形只有到仿真结束的时候才出现 解决办法: 1、添加波形需要是实例中的net 2、排查是否存在声明与示例的位宽不一致的信号 3、观察是否存在未初始化的变量寄存器 4、缩短整个仿真的步长 2、Instance列…...

如何提高深度学习中数据运行的稳定性
在深度学习中,模型的训练通常会受到随机性因素的影响,如参数初始化、数据加载顺序等。这会导致每次训练得到的结果有所不同。要减少这种不稳定性,可以采取以下措施: 1.固定随机种子 通过设置随机种子,可以使得每次训…...

【连续数组】python刷题记录
R3-前缀和专题 绝对要用字典记录 ben神,前缀和字典 class Solution:def findMaxLength(self, nums: List[int]) -> int:#前缀和字典,key为差值,value为坐标dict{0:-1}#当前1和0的差值counter0ret0for i,num in enumerate(nums):#多1+1if…...

JavaScript青少年简明教程:DOM和CSS简介
JavaScript青少年简明教程:DOM和CSS简介 DOM简介 DOM(Document Object Model)将文档表示为一个树形结构,其中每个节点都是一个对象,每个对象都有其自身的属性和方法。 通过对DOM的操作,开发者可以使用编…...

架构师知识梳理(一):计算机硬件
目录 计算机硬件组成 CPU CPU的组成 CPU的功能 校验码 奇偶校验 CRC CRC计算案例 指令 指令指行过程 指令系统 指令系统分类 指令流水线技术 流水线技术相关计算公式 存储 计算机存储系统设计 高速缓存Cache 缓存的局部性原理 地址映射 替换算法 关于命中…...

从根儿上学习spring 四 之run方法启动第一段
图1 由上图我们可以看到,我把run方法分成了5个小段,每小段使用红框圈了起来,这一篇我们先开始讲第一段。大家需要关注下行号,我讲的时候可能会使用行号对应具体某行代码。 图1-289-290行: 没啥好说的定义了两个变量&…...

智能闹钟如何判断用户已经醒了?
智能闹钟判断用户是否已经醒来的方式主要依赖于其内置的传感器和算法系统。以下是一些常见的判断方法: 一、传感器监测 体动传感器:智能闹钟通常配备有体动传感器,用于监测用户的身体运动。当用户从睡眠状态转变为清醒状态,并开始…...

【算法】动态规划解决背包问题
应用场景——01背包问题 有一个背包,背包的容量为 4,现有如下物品 要求 1.目标为装入背包的总价值最大,并且重量不超出 2.要求装入的物品不能重复 动态规划算法介绍 1.动态规划算法的核心是:将大问题划分为小问题进行解决&…...

day09 工作日报表
日期 30日07月2024年 任务安排 今天主要就是讲了security类工作的原理,然后就是让我们自己做项目 工作中的问题 今天做项目的时候发现有时候用postman测试返回20001,说错误见控制台,但是控制台一片祥和,于是就尝试用tr…...

C++学习之路(1)— 第一个HelloWorld程序
C学习之路(1)— 第一个HelloWorld程序 一、前言 C在C语言的基础上添加了对面向对象编程和泛型编程的支持,在 20世纪90年代便是最重要的编程语言之一,并在21世纪仍保持强劲势头。C继承了C语言高效、简洁、快速和可移植性的传统。 …...

python3 pyside6图形库学习笔记及实践(三)
目录 前言菜单栏相关控件使用QtDesigner快速构建菜单栏结构语法 上下文菜单概念为窗体添加上下文菜单为控件添加上下文菜单 折叠菜单资源的加载内置图标Rcc的使用创建资源文件加载资源文件 前言 本系列文章为b站PySide6教程以及官方文档的学习笔记 原视频传送门:【…...

03 库的操作
目录 创建查看修改删除备份和恢复查看连接情况 1. 创建 语法 CRATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] …] create_specification: CHARACTER SET charset_name CPLLATE collation_name 说明: 大写的标识关键…...

嵌入式人工智能(44-基于树莓派4B的扩展板-LED按键数码管TM1638)
树莓派性能非常强悍,但是对于某些复杂的项目来说,会出现心有余而口不足的情况,为了解决这类问题,可以在树莓派上使用扩展板,我们介绍几款常见的扩展板,不仅可以扩展到树莓派,其他单片机或嵌入式…...

linux通过抓包工具tcpdump查看80端口访问量情况
方法: tcpdump -i ens32 -tn dst port 80 -c 10 | awk -F"." {print $1"."$2"."$3"."$4} | sort | uniq -c | sort -nr |head -n 10 #-i:指定端口 #-t:在输出的每一行不打印时间戳 #-nÿ…...

Mac 上安装和卸载 SDKMAN 及管理多个 JDK
前言 当电脑上有多个 JDK 环境的时候,切换管理比较麻烦,这时候可以使用 SDKMAN 来安装、管理 JDK。 一、安装 SDKMAN! 1. 安装前置条件 首先,确保已经安装了 curl 。如果没有,可以通过 Homebrew 来安装: brew inst…...

字节测开一面面经
1 . 自我介绍 2 . 讲一下常见的数据结构 : 讲了数组,set,list,map,树,图,队列 , 栈等 ; 3 . 讲一下java反射场景和作用 ; 4 . 讲一下你了解的机器学习算法 ; 5 . 我讲完ML之后 , 问了knn和贝叶斯的使用的场景区别(没答上来) ; 6 .…...

HTML 段落
HTML 段落 概述 HTML(超文本标记语言)是构建网页的标准语言,而段落是构成网页内容的基本单元。在HTML中,段落是通过<p>标签来定义的。本文将详细介绍HTML段落的相关知识,包括段落的基本结构、样式设置、以及在…...
【Mind+】掌控板入门教程04 迷你动画片
还记得小时候每天放学必看的动画片吗?还记得那些年陪伴我一起长大的卡通人物吗?勇救爷爷的葫芦娃,我们的朋友小哪吒,相信这些经典的动画形象已经成为了一代人童年的美好回忆。今天就让我们用掌控板来制作一部迷你动画片吧。 项目示…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

GAN模式奔溃的探讨论文综述(一)
简介 简介:今天带来一篇关于GAN的,对于模式奔溃的一个探讨的一个问题,帮助大家更好的解决训练中遇到的一个难题。 论文题目:An in-depth review and analysis of mode collapse in GAN 期刊:Machine Learning 链接:...
:PyQuery 框架)
Python爬虫(四):PyQuery 框架
PyQuery 框架详解与对比 BeautifulSoup 第一部分:PyQuery 框架介绍 1. PyQuery 是什么? PyQuery 是一个 Python 的 HTML/XML 解析库,它采用了 jQuery 的语法风格,让开发者能够用类似前端 jQuery 的方式处理文档解析。它的核心特…...
Python 解释器安装全攻略(适用于 Linux / Windows / macOS)
目录 一、Windows安装Python解释器1.1 下载并安装Python解释1.2 测试安装是否成功1.3 设置pip的国内镜像------永久配置 二、macOS安装Python解释器三、Linux下安装Python解释器3.1 Rocky8.10/Rocky9.5安装Python解释器3.2 Ubuntu2204/Ubuntu2404安装Python解释器3.3 设置pip的…...