python字符串与变量名互相转换,字典,list操作
locals是python的内置函数,他可以以字典的方式去访问局部和全局变量
vars()本函数是实现返回对象object的属性和属性值的字典对象
eval()将字符串str当成有效的表达式来求值并返回计算结果
#!/usr/bin/python3
#-*- coding = uft-8 -*-
guo = 666
str1 = "guo"
str2 = "__doc__"
class c:a = 100
print("第一种方法:", locals()[str1])
#flag = locals()[str2]print("第二种方法:", vars()[str1])print("第三种方法:", eval(str1))字符串→变量名
eval 执行表达式
exec 执行语句
字符串←变量名
globals 全局变量
locals 局部变量
vars 类的成员
i = 0
exec('j = 0')
print(globals())class Dummy(object):def __init__(self) -> None:self.i = 0exec('self.j = 0')dummy = Dummy()
print(vars(dummy))class EasyArgs(object):def __init__(self, **kvps):self.add(**kvps)def add(self, **kvps): # 函数参数名转化成字符串(字典的键)for k,v in kvps.items():exec(f'self.{k} = None') # 字符串转化成示例的成员变量名vars(self)[k] = vif __name__ == '__main__':args = EasyArgs(batch_size = 32)args.add(epochs = 64)print(vars(args)) # 成员变量名转化成字符串print(args.batch_size) # 直接根据成员变量名使用变量print(args.epochs)#exec 会把字符串两边的引号去掉info_dict = {'create_time':'ct','user_id':'uid', 'cookie_id':'ci', 'product_name':'pn', 'product_version':'pv', 'device':'di'}for i in info_dict.items():exec(i[0] + "='%s'" % i[1])print create_time #这里在打印时create_time必须全部写,不会提示。
编号函数描述
| 序号 | 函数 | 注释 |
|---|---|---|
| 1 | int(x [,base]) | 将x转换为整数。如果x是字符串,则要base指定基数。 |
| 2 | float(x) | 将x转换为浮点数。 |
| 3 | complex(real [,imag]) | 创建一个复数。 |
| 4 | str(x) | 将对象x转换为字符串表示形式。 |
| 5 | repr(x) | 将对象x转换为表达式字符串。 |
| 6 | eval(str) | 评估求值一个字符串并返回一个对象。 |
| 7 | tuple(s) | 将s转换为元组。 |
| 8 | list(s) | 将s转换为列表。 |
| 9 | set(s) | 将s转换为集合。 |
| 10 | dict(d) | 创建一个字典,d必须是(key,value)元组的序列 |
| 11 | frozenset(s) | 将s转换为冻结集 |
| 12 | chr(x) | 将整数x转换为字符 |
| 13 | unichr(x) | 将整数x转换为Unicode字符。 |
| 14 | ord(x) | 将单个字符x转换为其整数值。 |
| 15 | hex(x) | 将整数x转换为十六进制字符串。 |
| 16 | oct(x) | 将整数x转换为八进制字符串 |
删除开头空白lstrip()、删除末尾空白rstrip()、删除两端空白strip()
a='pp '
a.rstrip()
print(a)
#字符串中添加制表符可以使用字符组合\t
print("\tppp")
字符串中添加换行,可以使用换行符\n
print("\tppp\n")
同时包含制表符和换行符,字符串 \n\t
print("\tppp\n")
name = "Ada Lovelace"print(name.upper())print(name.lower())
Python-python强制转换成字符串
a = 123
b = str(a)
print(b, type(b)) # '123', <class 'str'>
a = 123
b = repr(a)
print(b, type(b)) # '123', <class 'str'>
a = '中文'
b = unicode(a, 'utf-8')
print(b, type(b)) # u'\u4e2d\u6587', <class 'unicode'>
def namestr(obj, namespace):return [name for name in namespace if namespace[name] is obj]
print(namestr(lr_origin,globals()),'\n',
namestr(lr_origin,globals())[0])import inspect, re
def varname(p):for line in inspect.getframeinfo(inspect.currentframe().f_back)[3]:m = re.search(r'\bvarname\s*\(\s*([A-Za-z_][A-Za-z0-9_]*)\s*\)', line)if m:return m.group(1)
varname(lr_origin)Python如何创建字典
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict)
#访问字典的值
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict['语文']) # 通过键“语文”获取对应的值#添加键值对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict['物理'] = 97 # 添加 ‘物理’: 97
print(scores_dict) # {'语文': 105, '数学': 140, '英语': 120, '物理': 97}
#删除键值对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
del scores_dict['数学'] # 删除 ’语文‘: 105
print(scores_dict) # 输出 {'语文': 105, '英语': 120}
#修改字典值
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict['数学'] = 120 # 修改将“数学”修改为120
print(scores_dict) # 输出 {'语文': 105, '数学': 120, '英语': 120}
判断键值对是否存在
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
# 判断scores_dict是否包含名为'语文'的key
print('语文' in scores_dict) # True
# 判断scores_dict不包含'历史'的key
print('历史' not in scores_dict) # True
#clear()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict) # 输出 {'语文': 105, '数学': 140, '英语': 120}scores_dict.clear() # 删除字典所有内容
print(scores_dict) # 输出{}
#get()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.get('历史')) # 输出 None
print(scores_dict['历史']) # 报错 KeyError: '历史'
#update()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict.update({'语文': 120, '数学': 110})
print(scores_dict) # 输出{'语文': 120, '数学': 110, '英语': 120}#items()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.items()) # 输出 dict_items([('语文', 105), ('数学', 140), ('英语', 120)])
#keys()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.keys()) # 输出 dict_keys(['语文', '数学', '英语'])#values()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.values()) # 输出 dict_values([105, 140, 120])
#pop()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
scores_dict.pop('英语') # 删除'英语'的键和值
print(scores_dict) # 输出{'语文': 105, '数学': 140}
#popitem()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(scores_dict.popitem()) # 输出('英语', 120)
#setdefault()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
# 设置'语文'默认值为100
scores_dict.setdefault('语文', 100)
print(scores_dict) # 输出{'语文': 105, '数学': 140, '英语': 120}# 设置'历史'默认值为140
scores_dict.setdefault('历史', 140)
print(scores_dict) # 输出{'语文': 105, '数学': 140, '英语': 120, '历史': 140}
#fromkeys()方法
scores_dict = dict.fromkeys(['语文', '数学'])
print(scores_dict) # 输出{'语文': None, '数学': None}scores_dict = dict.fromkeys(('语文', '数学'))
print(scores_dict) # 输出{'语文': None, '数学': None}# 使用元组创建包含2个key的字典,指定默认的value
scores_dict = dict.fromkeys(('语文', '数学'), 100)
print(scores_dict) # 输出{'语文': 100, '数学': 100}
#len()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(len(scores_dict)) # 输出 3
#str()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(str(scores_dict)) # 输出{'语文': 105, '数学': 140, '英语': 120}
#type()方法
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
print(type(scores_dict)) # 输出<class 'dict'>
#Python字典的for循环遍历
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for key in scores_dict:
print(key)
#遍历value的值
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for value in scores_dict.values():print(value)
#遍历字典键值对
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for key in scores_dict:
print(key + ":" + str(scores_dict[key])) # 返回字符串
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for i in scores_dict.items():
print(i) # 返回元组
scores_dict = {'语文': 105, '数学': 140, '英语': 120}
for key, value in scores_dict.items():print(key + ':' + str(value))#将两个列表组成一个字典
list_a = ['zhangsan', 'lisi', 'wangwu']
list_b = ['14', '42', '23']dicts = dict(zip(list_a, list_b))print(type(dicts))
print(dicts)# 输出结果
>>> <class 'dict'>{'zhangsan': '14', 'lisi': '42', 'wangwu': '23'}
#将元组转换为列表
# 定义元组
GFG_tuple = (1, 2, 3)# 将元组转换为列表
GFG_list = list(GFG_tuple)
print(GFG_list)
#使用 map() 函数将元组转换为列表
# 定义元组
GFG_tuple = (1, 2, 3)# 使用 map 函数将元组转换为列表
GFG_list = list(map(lambda x: x, GFG_tuple))print(GFG_list)
#把列表转成元组 使用tuple
list_a = [1, 2, 3, 4, 5, 6]
list_b = tuple(list_a)
print(list_b)
#列表的基本操作
#修改元素: 列表名【索引】= 新值
#增加元素 append()方法
#insert()方法
guests = ['张三','李四','王五','小阿丁']
guests.insert(0,'小红')
#注意:列表每次增加的元素可以是任何类型的
#删除元素:del命令
del guests[0]
#pop()方法默认删除最后一个元素
guests=['张三', '李四', '王五', '小阿丁']
guests.pop(1)
#remove()方法
guests.remove('李四')
'''
len() #统计和返回指定列表的长度
in() not in() #判断指定元素是否在列表中
index() #在列表中那个查找指定的元素,若存在则返回指定元素在列表中的索引,若存在多个则返回最小的,若不存在会报错
count() #统计并返回列表中指定元素的个数
sort() #列表元素从小到大升序排序,改变了源列表的元素的顺序
sorted() #列表元素从小到大升序排序,生成排序后的副本,不改变原列表的顺序
nums.sort()
nums.sort(reverse = True)'''
#列表的扩充 “+”运算可以将两个列表“加”起来,生成一个新的列表,但是原来的列表并没有发生变化。
# extend()方法不同于“+”方法,因为“+”必须通过赋值语句才能将结果写入新的列表中,而extend()方法可以直接将新的列表添加至原列表之后
#列表的乘法运算是指将列表中的元素重复多遍
#copy() 方法
#列表的切片实现复制
list3 = list1[1:3]
#del 列表名#字符串与列表之间的转换
name = '小阿丁,小红'
list1 = list(name)
#split()方法是处理字符串的方法,用来根据指定的分隔符拆分字符串,并生成列表sentence = 'I want to be split by spcaes.'name = '小阿丁,小红'sentencelist = sentence.split()sentencelist
['I', 'want', 'to', 'be', 'split', 'by', 'spcaes.']namelist = name.split(',')namelist
['小阿丁', '小红']
# 定义一个字符串列表
str_list = ['Hello', 'World', 'Python', 'is', 'awesome']# 使用空字符串作为连接符,将列表转换为字符串
result = ''.join(str_list)
# 定义一个字符串列表
str_list = ['Moonshot', 'AI', 'Assistant']# 初始化一个空字符串
result = ''# 循环遍历列表,将每个元素添加到字符串中
for item in str_list:result += item# 输出结果
print(result) # 输出: MoonshotAIAssistant
#字符串的索引与切片
#字符串的处理与操作
'''
len(x) #返回字符串x的长度
str(x) #将任意类型的x转化为字符串类型
chr(x) #返回Unicode编码为x的字符
ord(x) #返回字符x的Unicode编码
hex(x) #将整数x转化为十六进制数
oct(x) #将整数x转化为八进制数
find() #查找一个字符串在另一个字符串指定范围内(默认是整个字符串)中首次出现的位置,若不存在则返回-1
rfind() #查找一个字符串在另一个字符串指定范围内(默认是整个字符串)中最后一次出现的位置,若不存在则返回-1
index() #查找一个字符串在另一个字符串指定范围内(默认是整个字符串)中首次出现的位置,若不存在则抛出异常
rindex() #查找一个字符串在另一个字符串指定范围内(默认是整个字符串)中最后一次出现的位置,若不存在则抛出异常
count() #用来返回一个字符串在另一个字符串中出现的次数,若不存在则返回0
split() #以指定字符为分隔符,从原字符串的左端开始将其分割为多个字符串,并返回包含分割结果的列表
rsplit() #以指定字符为分隔符,从原字符串的右端开始将其分割为多个字符串,并返回包含分割结果的列表
partition() #以指定字符串为分隔符将原字符串分割为3个部分,分隔符之前的字符串,分隔符字符串和分隔符之后的字符串
rpartition() #以指定字符串为分隔符将原字符串分割为3个部分,分隔符之前的字符串,分隔符字符串和分隔符之后的字符串
join() #将列表中多个字符串进行连接,并在相邻两个字符串之间插入指定字符,返回新字符串
lower() #将字符串转换为小写字符串
uppper() #将字符串转换为大写字符串
capitalize() #将字符串首字母变为大写
title() #将字符串中每个单词的首字母都变为大写
swapcase() #将字符串中的字符大小写互换
replace() #替换字符串中指定字符或子字符串
strip() #删除字符串两端空白字符
rstrip() #删除字符串右端空白字符
lstrip() #删除字符串左端空白字符
startswith() #判断字符串是否以指定字符开始
endswith() #判断字符串是否以指定字符结束
isupper() #是否全为大写
islower() #是否全为小写
isdigit() #是否全为数字
isalnum() #是否全为字母或汉字或数字
isalpha() #是否全为字母或汉字
center() #字符串居中对齐
ljust() #字符串居左对齐
rjust() #字符串居右对齐
zfill() #输出指定宽度,不足的左边填0
format()格式化方法
当使用format()方法格式化字符串的时候,首先需要在"{}”中输入“:”,然后在":"之后分别设置<填充字符><对齐方式><宽度>
"{:*^20}".format("milke")#split() 和 join() 方法示例
my_string = "apple, banana, cherry"
splitted_str = my_string.split(", ")
print(splitted_str) # 输出:['apple', 'banana', 'cherry']fruits = ['apple', 'banana', 'cherry']
joined_str = ", ".join(fruits)
print(joined_str) # 输出:apple, banana, cherry
#find() 方法示例
my_string = "Hello, World!"
index = my_string.find("World")
if index != -1:print(f"Substring found at index: {index}")
else:print("Substring not found")
#replace() 方法示例
my_string = "Hello, World!"
new_string = my_string.replace("World", "Python")
print(new_string) # 输出:Hello, Python!#count() 方法用于计算字符串中指定子字符串出现的次数
my_string = "How much wood would a woodchuck chuck if a woodchuck could chuck wood?"
count = my_string.count("wood")
print(f"The word 'wood' appears {count} times in the string.")
#isalpha() 方法用于检查字符串是否只包含字母字符
alpha_str = "Hello"
if alpha_str.isalpha():print("The string contains only alphabetic characters.")
else:print("The string contains non-alphabetic characters.")
#isdigit() 方法用于检查字符串是否只包含数字字符
digit_str = "12345"
if digit_str.isdigit():print("The string contains only digits.")
else:print("The string contains non-digit characters.")
#isalnum() 方法用于检查字符串是否只包含字母和数字字符的组合
alnum_str = "Hello123"
if alnum_str.isalnum():print("The string contains only alphanumeric characters.")
else:print("The string contains non-alphanumeric characters.")# 多行字符串示例
multiline_string = """Hello,
World!"""
print(multiline_string)# 字符编码转换示例
my_string = "你好"
encoded_string = my_string.encode("utf-8")
decoded_string = encoded_string.decode("utf-8")
print(encoded_string)
print(decoded_string)
# 文本处理示例
text = "Hello, this is a sample text. #example"
cleaned_text = text.replace("#example", "").strip()
print(cleaned_text)# 字符串拼接优化示例
items = ['apple', 'banana', 'cherry']
joined_string = ''.join(items)
print(joined_string)def reverse_string(input_str):reversed_str = ''for char in input_str:reversed_str = char + reversed_strreturn reversed_str# 测试函数
input_string = "Hello, World!"
reversed_string = reverse_string(input_string)
print(reversed_string) # 输出结果为:!dlroW ,olleH
'''相关文章:

python字符串与变量名互相转换,字典,list操作
locals是python的内置函数,他可以以字典的方式去访问局部和全局变量 vars()本函数是实现返回对象object的属性和属性值的字典对象 eval()将字符串str当成有效的表达式来求值并返回计算结果 #!/usr/bin/python3 #-*- coding uft-8 -*- guo 666 str1 "guo&qu…...

企业及园区电力能源管理系统方案
概述 面对中小型的用能集团、园区能耗监测分析等场景需求,拓扑未来公司推出标准化的企业及园区电力能源管理系统方案,力求高效高质地为目标客户提供高效部署、轻松运维的本地化能源管理解决方案。 本方案以软硬件一体的方式,集成了标准电力监…...

5.3 需求分析
需求分析 软件需求定义分类练习题 需求工程需求获取练习题 需求分析状态转化图数据流图DFD顶层数据流图0层数据流图1层数据流图 练习题 需求规约需求定义方法 需求验证需求管理版本控制需求跟踪变更控制练习题 考试大概3分 软件需求 定义 软件需求:是指用户对目标…...
)
【C++】list介绍以及模拟实现(超级详细)
欢迎来到我的Blog,点击关注哦💕 list的介绍和模拟实现 前言list介绍标准库容器 std::list 与 std::vector 的优缺点缺点 list的基本操作构造函数list iteratorlist capcacitylist modify list模拟实现存贮结构(双向带头循环)itera…...
从艺术创作到作物生长,农业AI迎来“GPT“时刻
(于景鑫 国家农业信息化工程技术研究中心)"GPT"一词早已不再神秘,其在文本、图像生成领域掀起的风暴正以摧枯拉朽之势席卷全球。人们惊叹于ChatGPT对话之智能、思维之敏捷,更对Stable Diffusion、Midjourney创作的艺术画作赞叹不已。而大语言模…...

前端使用 Konva 实现可视化设计器(19)- 连接线 - 直线、折线
本章响应小伙伴的反馈,除了算法自动画连接线(仍需优化完善),实现了可以手动绘制直线、折线连接线功能。 请大家动动小手,给我一个免费的 Star 吧~ 大家如果发现了 Bug,欢迎来提 Issue 哟~ github源码 gitee…...

C#:通用方法总结—第15集
大家好,今天继续分享我们的通用方法系列。 下面是今天的通用方法: (1)这个通用方法为用文件流写数据 /// <summary> /// 用文件流写数据 /// </summary> /// <param name"data"></param> //…...

LoadRunner12 添加事务并添加检查点
1、先要添加事务开始函数lr_start_transaction("登陆事务");,在接口上方右击点击-插入-开始事务。输入事务名称; 2、在某个接口想法 右击点击-插入-结束事务,输入事务名称,与开始事务名称要保持一致,lr_end_…...

python中的文件
绝对路径和相对路径 一般情况下绝对路径就是从根目录开始描述的路径 相对路径就是相对于当前目录 . 没错,就是一个点,表示的是当前文件夹;.. 两个点表示的是上一层文件夹 os模块与os.path os 和 os.path 是两个非常重要的标准库模块,它们分别用于操作系统相关的功能操…...

Powerdesigner连接mysql数据库,逆向工程生成ER图 (保姆级教程:下载->连接->配置)看这一篇就够了
一、下载powerdesigner 下载的教程请看如下链接,我太懒了,直接借鉴! 把别大佬的博客搬过来了嘿嘿~我真聪明!ㄟ( ▔, ▔ )ㄏ 操作到完成汉化就好!!第5步不看了,别按那个走,因为新手…...

商家转账到零钱分销返佣申请方案及驳回处理办法
分销返佣场景是商家申请最多的场景,因而申请被驳回也是最多的,根据我们上万次成功开通商家转账到零钱的经验,当商家转账到零钱的分销返佣场景被驳回时,按照以下步骤,商家都可以快速过审: 一、分析驳回原因 …...

荟萃科技:国外问卷调查有没有实时更新的题库?
有的,口子查和渠道查都是。 口子查的题目都是国外的公司发放在网络上,都是实时发布,所以我们需要去国外的各大社交平台做题。 这些题目不是集中的,而是散布在网站里面,需要我们去找,都是老外上班实时发放…...

【课程总结】Day18:Seq2Seq的深入了解
前言 在上一章【课程总结】Day17(下):初始Seq2Seq模型中,我们初步了解了Seq2Seq模型的基本情况及代码运行效果,本章内容将深入了解Seq2Seq模型的代码,梳理代码的框架图、各部分组成部分以及运行流程。 框…...

C++利用开发人员命令提示工具查看对象模型
1.跳转文件路径 cd 具体路径 2.输入c1 /d1 reportSingleClassLayout类名 文件名 操作示例如下图:...

白骑士的PyCharm教学高级篇 3.4 服务器部署与配置
系列目录 上一篇:白骑士的PyCharm教学高级篇 3.3 Web开发支持 在开发完成后,将代码部署到服务器上是一个关键步骤。PyCharm不仅提供了强大的本地开发支持,还为远程服务器配置与部署、自动化部署流程提供了便捷的工具和功能。本文将详细介绍如…...
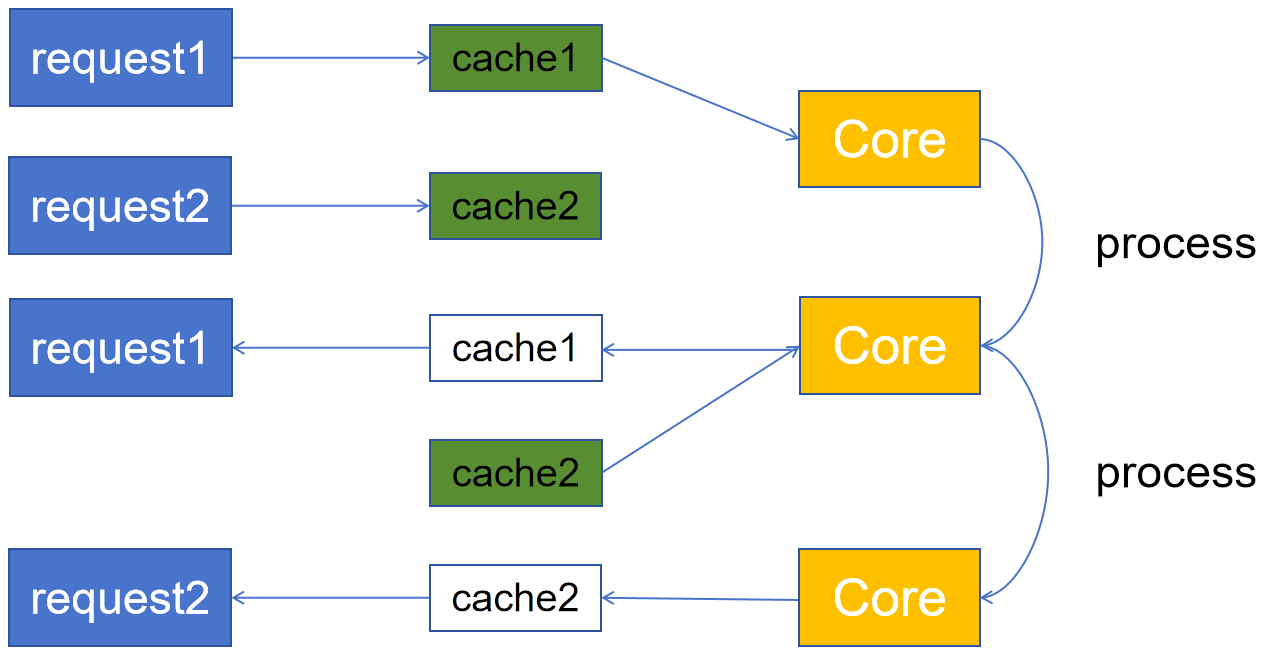
数据库管理-第226期 内存至超线程(20240805)
数据库管理226期 2024-08-05 数据库管理-第226期 内存至超线程(20240805)1 CPU内缓存结构2 缓存与内存3 单核单线程4 超线程5 超线程的利弊总结 数据库管理-第226期 内存至超线程(20240805) 作者:胖头鱼的鱼缸…...

Django学习-数据迁移与数据导入导出
文章目录 一、数据迁移二、数据导入导出1. 数据导出2. 数据导入 一、数据迁移 数据迁移是将项目里定义的模型生成相应的数据表。主要的迁移指令如下: # 第一次生成自定义模型与django admin自带模型迁移文件,后续只生成新增模型迁移文件。后面加App名…...

【Nuxt】编程式导航和动态路由
编程式导航 navigateTo: 更多用法:navigateTo <template><div class"app-container"><button click"goToCategory">Category</button><NuxtPage/></div> </template> <script setup&…...

14. 计算机网络HTTPS协议(二)
1. 前言 上一章节中我们主要就 HTTPS 协议的前置知识进行介绍,下面会继续介绍 HTTPS 的通信过程以及抛出一些常见问题的探讨。因为候选人准备面试的时间和精力是比较有限的,我们在学习的过程要抓住重点,如果感觉对于细节缺乏了解,可以通过维基百科和查阅 StackOverflow 等…...

【算法设计题】实现以字符串形式输入的简单表达式求值,第2题(C/C++)
目录 第2题 实现以字符串形式输入的简单表达式求值 得分点(必背) 题解 1. 初始化和变量定义 2. 获取第一个数字并存入队列 3. 遍历表达式字符串,处理运算符和数字 4. 初始化 count 并处理加减法运算 代码详解 🌈 嗨…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...