DATAX自定义KafkaWriter
因为datax目前不支持写入数据到kafka中,因此本文主要介绍如何基于DataX自定义KafkaWriter,用来同步数据到kafka中。本文偏向实战,datax插件开发理论宝典请参考官方文档:
https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md。
首先我们需要克隆datax源码到本地,此处不再赘述。然后使用开发工具打开datax项目,项目结构如下:

可以看到不论是reader还是writer都是独立的项目,所以我们也需要新建kafkawriter的项目。可以直接新建,也可以复制一个现有的writer项目然后进行修改。注意包结构需要与现有的writer保持一致,如下所示:

基本上所有插件的目录结构都是这样,main文件夹下面分为三个目录,分别为assembly、java、resources。其中assembly下面主要用来存放打包文件,java则是存放我们的代码,resources中存放插件相关的配置信息。
创建完kafkawriter项目之后,需要在datax的pom文件中添加上我们的插件,如下图所示: 然后我们需要在datax的打包文件中加入我们的kafkawriter插件,如下图所示:
然后我们需要在datax的打包文件中加入我们的kafkawriter插件,如下图所示: 接下来从上到下依次介绍各文件的内容。
接下来从上到下依次介绍各文件的内容。
<assemblyxmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd"><id></id><formats><format>dir</format></formats><includeBaseDirectory>false</includeBaseDirectory><fileSets><fileSet><directory>src/main/resources</directory><includes><include>plugin.json</include><include>plugin_job_template.json</include></includes><outputDirectory>plugin/writer/kafkawriter</outputDirectory></fileSet><fileSet><directory>target/</directory><includes><include>kafkawriter-0.0.1-SNAPSHOT.jar</include></includes><outputDirectory>plugin/writer/kafkawriter</outputDirectory></fileSet></fileSets><dependencySets><dependencySet><useProjectArtifact>false</useProjectArtifact><outputDirectory>plugin/writer/kafkawriter/libs</outputDirectory><scope>runtime</scope></dependencySet></dependencySets></assembly>该文件主要配置插件的打包信息,基本上所有的插件内容也都是类似的,主要修改的地方如图所示:

如果我们想自定义s3的writer,也只需要修改图中所标识的几个地方。
- KafkaWriter
该类为我们实现写入数据到kafka的主要逻辑实现类,其主要结构可以参照上文中提到的datax官方文档,代码示例如下,每个地方的处理逻辑可以参考代码中的注释。
package com.alibaba.datax.plugin.writer.kafkawriter;import com.alibaba.datax.common.element.Column;import com.alibaba.datax.common.element.Record;import com.alibaba.datax.common.exception.DataXException;import com.alibaba.datax.common.plugin.RecordReceiver;import com.alibaba.datax.common.spi.Writer;import com.alibaba.datax.common.util.Configuration;import com.alibaba.datax.plugin.writer.kafkawriter.entity.*;import com.alibaba.fastjson2.JSON;import com.alibaba.fastjson2.JSONObject;import com.alibaba.fastjson2.JSONWriter;import org.apache.commons.lang3.ObjectUtils;import org.apache.commons.lang3.StringUtils;import org.apache.kafka.clients.admin.AdminClient;import org.apache.kafka.clients.admin.ListTopicsResult;import org.apache.kafka.clients.admin.NewTopic;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.Producer;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.common.header.internals.RecordHeader;import org.apache.kafka.common.header.internals.RecordHeaders;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.IOException;import java.nio.charset.StandardCharsets;import java.util.*;//首先自定义的writer需要继承Writer类public class KafkaWriter extends Writer {//创建Job类继承Writer.Jobpublic static class Job extends Writer.Job {private static final Logger logger = LoggerFactory.getLogger(Job.class);//存放同步任务的配置信息private Configuration conf = null;//重写split方法,任务切分逻辑,writer切分主要依据上游reader任务的切分数@Overridepublic List<Configuration> split(int mandatoryNumber) {List<Configuration> configurations = new ArrayList<Configuration>(mandatoryNumber);for (int i = 0; i < mandatoryNumber; i++) {configurations.add(conf);}return configurations;}//重写init方法,进行相关的初始化操作@Overridepublic void init() {//获取同步任务相关的配置this.conf = super.getPluginJobConf();logger.info("kafka writer params:{}", conf.toJSON());//校验配置中的必要参数this.validateParameter();}private void validateParameter() {this.conf.getNecessaryValue(Key.BOOTSTRAP_SERVERS, KafkaWriterErrorCode.REQUIRED_VALUE);this.conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE);this.conf.getNecessaryValue(Key.COLUMN, KafkaWriterErrorCode.REQUIRED_VALUE);}//重写destroy方法,主要用来处理数据同步任务结束之后需要收尾的事情,比如删除同步过程中可能产生的临时文件,关闭连接等@Overridepublic void destroy() {}}public static class Task extends Writer.Task {private static final Logger logger = LoggerFactory.getLogger(Task.class);//存放同步任务的配置信息private Configuration conf;//存放同步的数据表列信息private List<String> columns;//保存kafka的相关配置private Properties properties;//定义kafka生产者private Producer<String, String> producer;//数据同步的目标topicprivate String topic;//kafka消息header(如果单纯同步数据,不需要定义消息头,可以删除该字段)private RecordHeaders recordHeaders = new RecordHeaders();//控制消息是否格式化为cdc格式(如果单纯同步数据,不需要定义特殊的消息格式,可以删除该字段及下面代码的相关逻辑)private Boolean cdcValue = false;//源表主键信息(如果单纯同步数据,不需要定义特殊的消息格式,可以删除该字段及下面代码的相关逻辑)private List<String> primaryKeys;//init()方法主要对任务配置的解析赋值以及一些认证处理逻辑@Overridepublic void init() {this.conf = super.getPluginJobConf();//kerberos逻辑处理,如果开启kerberos认证可以参考,如果没有可以删除String haveKerberos = conf.getUnnecessaryValue(Key.HAVE_KERBEROS, "false", null);if (StringUtils.isNotBlank(haveKerberos) && haveKerberos.equalsIgnoreCase("true")) {String kerberosPrincipal = conf.getString(Key.KERBEROS_PRINCIPAL);String kerberosKrb5ConfigPath = conf.getString(Key.KERBEROS_KRB5CONFIG_PATH);String kerberosKeytabFilePath = conf.getString(Key.KERBEROS_KEYTABFILE_PATH);if (StringUtils.isBlank(kerberosPrincipal) || StringUtils.isBlank(kerberosKrb5ConfigPath) || StringUtils.isBlank(kerberosKeytabFilePath)) {throw new DataXException(KafkaWriterErrorCode.KERBEROS_VALUE, KafkaWriterErrorCode.KERBEROS_VALUE.getDescription());}try {LoginUtil.securityPrepare(kerberosPrincipal, kerberosKrb5ConfigPath, kerberosKeytabFilePath);} catch (IOException e) {throw new DataXException(KafkaWriterErrorCode.KERBEROS_AUTH, KafkaWriterErrorCode.KERBEROS_AUTH.getDescription());}}//初始化message header,此处是业务特定需求需要给同步到kafka中的message加上header,如果有(特殊的处理逻辑,如果不需要可以删除)if (StringUtils.isNotBlank(conf.getString(Key.KAFKAHEADER))) {JSONObject jsonObject = JSONObject.parseObject(conf.getString(Key.KAFKAHEADER));jsonObject.forEach((key, value) -> {if (StringUtils.isBlank(String.valueOf(value)) || String.valueOf(value).equals("null")) {RecordHeader recordHeader = new RecordHeader(key, null);recordHeaders.add(recordHeader);} else {RecordHeader recordHeader = new RecordHeader(key, String.valueOf(value).getBytes(StandardCharsets.UTF_8));recordHeaders.add(recordHeader);}});}//控制message格式的开关if (conf.getBool(Key.CDCVALUE) != null) {this.cdcValue = conf.getBool(Key.CDCVALUE);}//获取列属性并保存this.columns = conf.getList(Key.COLUMN, String.class);//获取源表主键信息并保存this.primaryKeys = conf.getList(Key.PRIMARYKEYS, String.class);//获取配置的目标topicthis.topic = conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE);//设置kafka配置信息properties = new Properties();properties.put("bootstrap.servers", conf.getString(Key.BOOTSTRAP_SERVERS));properties.put("key.serializer", conf.getUnnecessaryValue(Key.KEY_SERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null));properties.put("value.serializer", conf.getUnnecessaryValue(Key.VALUE_SERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null));properties.put("acks", conf.getUnnecessaryValue(Key.ACK, "0", null));properties.put("retries", conf.getUnnecessaryValue(Key.RETRIES, "0", null));properties.put("batch.size", conf.getUnnecessaryValue(Key.BATCH_SIZE, "16384", null));producer = new KafkaProducer<String, String>(properties);}//prepare() 方法主要用来进行一些同步前的准备工作,比如创建目标topic@Overridepublic void prepare() {//创建目标topicif (Boolean.valueOf(conf.getUnnecessaryValue(Key.NO_TOPIC_CREATE, "false", null))) {ListTopicsResult topicsResult = AdminClient.create(properties).listTopics();try {if (!topicsResult.names().get().contains(this.topic)) {NewTopic newTopic = new NewTopic(this.topic,Integer.valueOf(conf.getUnnecessaryValue(Key.TOPIC_NUM_PARTITION, "1", null)),Short.valueOf(conf.getUnnecessaryValue(Key.TOPIC_REPLICATION_FACTOR, "1", null)));AdminClient.create(properties).createTopics(Arrays.asList(newTopic));}} catch (Exception e) {throw new DataXException(KafkaWriterErrorCode.CREATE_TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE.getDescription());}}//特殊处理,数据开始同步前,首先发送一条特定格式的消息(特殊处理逻辑,可以参考,不需要可以删除)if (cdcValue) {FirstCdcValueTemplate firstCdcValueTemplate = new FirstCdcValueTemplate();JSONObject tableId = new JSONObject();//tableId的值为topic名称tableId.put("tableName", this.conf.getString(Key.TOPIC));firstCdcValueTemplate.setTableId(tableId);SchemaTemplate schemaTemplate = new SchemaTemplate();schemaTemplate.setColumns(buildFirstMessageColumns());if (this.primaryKeys != null && this.primaryKeys.size() > 0) {schemaTemplate.setPrimaryKeys(this.primaryKeys);} else {schemaTemplate.setPrimaryKeys(Arrays.asList());}schemaTemplate.setPartitionKeys(Arrays.asList());schemaTemplate.setOptions(new JSONObject());firstCdcValueTemplate.setSchema(schemaTemplate);producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),null, null, null, JSON.toJSONString(firstCdcValueTemplate, JSONWriter.Feature.WriteMapNullValue), this.recordHeaders));}}//依次写入数据到kafka@Overridepublic void startWrite(RecordReceiver lineReceiver) {Record record = null;while ((record = lineReceiver.getFromReader()) != null) {producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),null, null, null, buildMessage(record), this.recordHeaders));}}//进行收尾工作,关闭生产者客户端@Overridepublic void destroy() {if (ObjectUtils.isNotEmpty(this.producer)) {this.producer.close();}}//组装特殊message格式private List<ColumnTemplate> buildFirstMessageColumns() {List<ColumnTemplate> columnTemplates = new ArrayList<>();JSONObject jsonObject = JSONObject.parseObject(conf.getString(Key.KAFKAHEADER));List<HeaderSchemaTemplate> schemaJson = jsonObject.getList("schemaJson", HeaderSchemaTemplate.class);for (HeaderSchemaTemplate temp : schemaJson) {ColumnTemplate columnTemplate = new ColumnTemplate();columnTemplate.setName(temp.getName());columnTemplate.setType(temp.getType());columnTemplates.add(columnTemplate);}return columnTemplates;}//组装message格式private String buildMessage(Record record) {JSONObject jo = new JSONObject();for (int i = 0; i < columns.size(); i++) {String columnName = columns.get(i);Column columnValue = record.getColumn(i);if (!Objects.isNull(columnValue)) {if (Objects.isNull(columnValue.getRawData())) {jo.put(columnName, null);} else {switch (columnValue.getType()) {case INT:jo.put(columnName, columnValue.asBigInteger());break;case BOOL:jo.put(columnName, columnValue.asBoolean());break;case LONG:jo.put(columnName, columnValue.asLong());break;case DOUBLE:jo.put(columnName, columnValue.asDouble());break;default:jo.put(columnName, columnValue.asString());}}} else {jo.put(columnName, null);}}if (cdcValue) {ValueTemplate valueTemplate = new ValueTemplate();valueTemplate.setBefore(null);valueTemplate.setAfter(jo);valueTemplate.setOp("c");return JSON.toJSONString(valueTemplate, JSONWriter.Feature.WriteMapNullValue);} else {return jo.toJSONString();}}}}
可以注意到上文中的Task内部类中定义了几个特殊的变量:recordHeaders、cdcValue、primaryKeys,这几个变量主要是用来定义特殊的kafka消息格式,比如当前代码的逻辑是要将消息转换为CDC相关的格式,所以做了额外处理。可以参考该思路,如果有其他的类似的需求,也可以通过任务配置传递进来,然后构建消息的时候进行处理。
- KafkaWriterErrorCode
定义错误码,抛出异常的时候用来提示。
package com.alibaba.datax.plugin.writer.kafkawriter;import com.alibaba.datax.common.spi.ErrorCode;public enum KafkaWriterErrorCode implements ErrorCode {REQUIRED_VALUE("KafkaWriter-00", "您缺失了必须填写的参数值."),KERBEROS_VALUE("KafkaWriter-02", "您缺失了必须填写的kerberos参数值."),KERBEROS_AUTH("KafkaWriter-03", "kerberos认证失败"),CREATE_TOPIC("KafkaWriter-01", "写入数据前检查topic或是创建topic失败.");private final String code;private final String description;private KafkaWriterErrorCode(String code, String description) {this.code = code;this.description = description;}@Overridepublic String getCode() {return this.code;}@Overridepublic String getDescription() {return this.description;}@Overridepublic String toString() {return String.format("Code:[%s], Description:[%s].", this.code,this.description);}}
- Key
该类定义数据同步任务配置文件中的Key
package com.alibaba.datax.plugin.writer.kafkawriter;public class Key {public static final String BOOTSTRAP_SERVERS = "bootstrapServers";public static final String TOPIC = "topic";public static final String KEY_SERIALIZER = "keySerializer";public static final String VALUE_SERIALIZER = "valueSerializer";public static final String COLUMN = "column";public static final String ACK = "ack";public static final String BATCH_SIZE = "batchSize";public static final String RETRIES = "retries";public static final String NO_TOPIC_CREATE = "noTopicCreate";public static final String TOPIC_NUM_PARTITION = "topicNumPartition";public static final String TOPIC_REPLICATION_FACTOR = "topicReplicationFactor";//是否开启kerberos认证public static final String HAVE_KERBEROS = "haveKerberos";public static final String KERBEROS_KEYTABFILE_PATH = "kerberosKeytabFilePath";public static final String KERBEROS_PRINCIPAL = "kerberosPrincipal";public static final String KERBEROS_KRB5CONFIG_PATH = "kerberosKrb5ConfigPath";public static final String KAFKAHEADER = "kafkaHeader";public static final String CDCVALUE = "cdcValue";public static final String PRIMARYKEYS = "primarykeys";}
- LoginUtil
该类主要是定义了kerberos认证的相关逻辑,可以参考
package com.alibaba.datax.plugin.writer.kafkawriter;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;import java.io.FileWriter;import java.io.IOException;public class LoginUtil {private static final Logger LOG = LoggerFactory.getLogger(LoginUtil.class);public enum Module {KAFKA("KafkaClient"), ZOOKEEPER("Client");private String name;private Module(String name) {this.name = name;}public String getName() {return name;}}/*** line operator string*/private static final String LINE_SEPARATOR = System.getProperty("line.separator");/*** jaas file postfix*/private static final String JAAS_POSTFIX = ".jaas.conf";/*** is IBM jdk or not*/private static final boolean IS_IBM_JDK = System.getProperty("java.vendor").contains("IBM");/*** IBM jdk login module*/private static final String IBM_LOGIN_MODULE = "com.ibm.security.auth.module.Krb5LoginModule required";/*** oracle jdk login module*/private static final String SUN_LOGIN_MODULE = "com.sun.security.auth.module.Krb5LoginModule required";/*** Zookeeper quorum principal.*/public static final String ZOOKEEPER_AUTH_PRINCIPAL = "zookeeper.server.principal";/*** java security krb5 file path*/public static final String JAVA_SECURITY_KRB5_CONF = "java.security.krb5.conf";/*** java security login file path*/public static final String JAVA_SECURITY_LOGIN_CONF = "java.security.auth.login.config";/*** 设置jaas.conf文件** @param principal* @param keytabPath* @throws IOException*/public static void setJaasFile(String principal, String keytabPath)throws IOException {String jaasPath =new File(System.getProperty("java.io.tmpdir")) + File.separator + System.getProperty("user.name")+ JAAS_POSTFIX;// windows路径下分隔符替换jaasPath = jaasPath.replace("\\", "\\\\");// 删除jaas文件deleteJaasFile(jaasPath);writeJaasFile(jaasPath, principal, keytabPath);System.setProperty(JAVA_SECURITY_LOGIN_CONF, jaasPath);}/*** 设置zookeeper服务端principal** @param zkServerPrincipal* @throws IOException*/public static void setZookeeperServerPrincipal(String zkServerPrincipal) throws IOException {System.setProperty(ZOOKEEPER_AUTH_PRINCIPAL, zkServerPrincipal);String ret = System.getProperty(ZOOKEEPER_AUTH_PRINCIPAL);if (ret == null) {throw new IOException(ZOOKEEPER_AUTH_PRINCIPAL + " is null.");}if (!ret.equals(zkServerPrincipal)) {throw new IOException(ZOOKEEPER_AUTH_PRINCIPAL + " is " + ret + " is not " + zkServerPrincipal + ".");}}/*** 设置krb5文件** @param krb5ConfFile* @throws IOException*/public static void setKrb5Config(String krb5ConfFile) throws IOException {System.setProperty(JAVA_SECURITY_KRB5_CONF, krb5ConfFile);String ret = System.getProperty(JAVA_SECURITY_KRB5_CONF);if (ret == null) {throw new IOException(JAVA_SECURITY_KRB5_CONF + " is null.");}if (!ret.equals(krb5ConfFile)) {throw new IOException(JAVA_SECURITY_KRB5_CONF + " is " + ret + " is not " + krb5ConfFile + ".");}}/*** 写入jaas文件** @throws IOException 写文件异常*/private static void writeJaasFile(String jaasPath, String principal, String keytabPath)throws IOException {FileWriter writer = new FileWriter(new File(jaasPath));try {writer.write(getJaasConfContext(principal, keytabPath));writer.flush();} catch (IOException e) {throw new IOException("Failed to create jaas.conf File");} finally {writer.close();}}private static void deleteJaasFile(String jaasPath) throws IOException {File jaasFile = new File(jaasPath);if (jaasFile.exists()) {if (!jaasFile.delete()) {throw new IOException("Failed to delete exists jaas file.");}}}private static String getJaasConfContext(String principal, String keytabPath) {Module[] allModule = Module.values();StringBuilder builder = new StringBuilder();for (Module modlue : allModule) {builder.append(getModuleContext(principal, keytabPath, modlue));}return builder.toString();}private static String getModuleContext(String userPrincipal, String keyTabPath, Module module) {StringBuilder builder = new StringBuilder();if (IS_IBM_JDK) {builder.append(module.getName()).append(" {").append(LINE_SEPARATOR);builder.append(IBM_LOGIN_MODULE).append(LINE_SEPARATOR);builder.append("credsType=both").append(LINE_SEPARATOR);builder.append("principal=\"" + userPrincipal + "\"").append(LINE_SEPARATOR);builder.append("useKeytab=\"" + keyTabPath + "\"").append(LINE_SEPARATOR);builder.append("debug=true;").append(LINE_SEPARATOR);builder.append("};").append(LINE_SEPARATOR);} else {builder.append(module.getName()).append(" {").append(LINE_SEPARATOR);builder.append(SUN_LOGIN_MODULE).append(LINE_SEPARATOR);builder.append("useKeyTab=true").append(LINE_SEPARATOR);builder.append("keyTab=\"" + keyTabPath + "\"").append(LINE_SEPARATOR);builder.append("principal=\"" + userPrincipal + "\"").append(LINE_SEPARATOR);builder.append("useTicketCache=false").append(LINE_SEPARATOR);builder.append("storeKey=true").append(LINE_SEPARATOR);builder.append("debug=true;").append(LINE_SEPARATOR);builder.append("};").append(LINE_SEPARATOR);}return builder.toString();}public static void securityPrepare(String principal, String keyTabFilePath, String krb5ConfigPath) throws IOException {// windows路径下分隔符替换keyTabFilePath = keyTabFilePath.replace("\\", "\\\\");krb5ConfigPath = krb5ConfigPath.replace("\\", "\\\\");LoginUtil.setKrb5Config(krb5ConfigPath);LoginUtil.setZookeeperServerPrincipal("zookeeper/hadoop.hadoop.com");LoginUtil.setJaasFile(principal, keyTabFilePath);}/** 判断文件是否存在*/private static boolean isFileExists(String fileName) {File file = new File(fileName);return file.exists();}}
上文中截图的java目录下有一个entity包,该包是上文提到过的特殊处理kafka message格式所用到的一些实体类,没什么借鉴意义,就不进行展示了。
- plugin.json
该文件主要是用来定义插件的信息,方便datax加载到我们的插件。其中name与class属性需要跟实际名称及路径保持一致。
{"name": "kafkawriter","class": "com.alibaba.datax.plugin.writer.kafkawriter.KafkaWriter","description": "kafka writer","developer": "alibaba"}- plugin_job_template.json
该文件主要定义同步任务的配置示例。
{"name": "kafkawriter","parameter": {"bootstrapServers": "11.1.1.111:9092","topic": "test-topic","ack": "all","column": ["id","name","description","weight"],"batchSize": 1000,"retries": 0,"keySerializer": "org.apache.kafka.common.serialization.StringSerializer","valueSerializer": "org.apache.kafka.common.serialization.StringSerializer","topicNumPartition": 1,"topicReplicationFactor": 1}}
上文基本将kafka writer中的相关代码都展示完毕,至此也是基本完成了kafkawriter插件的开发。打包完成之后,就可以愉快的进行测试了。
相关文章:
DATAX自定义KafkaWriter
因为datax目前不支持写入数据到kafka中,因此本文主要介绍如何基于DataX自定义KafkaWriter,用来同步数据到kafka中。本文偏向实战,datax插件开发理论宝典请参考官方文档: https://github.com/alibaba/DataX/blob/master/dataxPlug…...

Mybatis分页多表多条件查询
个人总结三种方式: Xml、queryWrapper、PageHelper第三方组件这三种方式进行查询; 方式一: xml中联表查询,在mapper中传参IPage<T>和条件Map(这里用map装参数)。 代码示例: Mapper层 M…...

SpringBoot快速入门(手动创建)
目录 案例:需求 步骤 1 创建Maven项目 2 导入SpringBoot起步依赖 3 定义Controller 4 编写引导类 案例:需求 搭建简单的SpringBoot工程,创建hello的类定义h1的方法,返回Hello SpringBoot! 步骤 1 创建Maven项目 大家&…...

C 408—《数据结构》算法题基础篇—数组(通俗易懂)
目录 Δ前言 一、数组的合并 0.题目: 1.算法设计思想: 2.C语言描述: 3.算法的时间和空间复杂度 : 二、数组元素的倒置 0.题目 : 1.算法设计思想 : 2.C语言描述 : 3.算法的时间和空间复杂度 : 三、数组中特定值元素的删除 0.题目 : …...
)
AI秘境-墨小黑奇遇记 - 初体验(一)
“怎么可能!”墨小黑盯着屏幕上的代码,整个人都不好了。调试了三遍,翻了几遍书,结果还是不对。就像你以为自己早起赶车,结果发现闹钟根本没响一样崩溃。 这是他第一次真正接触人工智能实战任务——实现一个简单的感知…...

文件IO813
标准IO文件定位: fseek函数: 功能:将stream流文件中的文件指针从whence位置开始偏移offset个字节的长度。 int fseek(FILE *stream , long offset, int whence); FILE *stream 指的是所需要定位的文件(文化定位前提是文件要被打…...

STP(生成树)的概述和工作原理
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:Linux运维老纪的首页…...

从AGV到立库,物流自动化的更迭与未来
AGV叉车 随着柔性制造系统的广泛应用,小批量、多批次的生产需求不断增强,“订单导向”生产已经成为趋势。这也让越来越多的企业认识到,产线的智能设备导入只是第一步,要想达到生产效率的最优解,物流系统的再优化必须提…...

阴阳脚数码管
1.小故事 最近,我接到了一个既“清肺”又“烧脑”的新任务,设计一个低功耗蓝牙肺活量计。在这个项目中我们借鉴了一款蓝牙跳绳的硬件设计方案,特别是它的显示方案——数码管。 在电子工程领域,初学者往往从操作LED开始ÿ…...

【Vue3-Typescript】<script setup lang=“ts“> 使用 ref标签 怎么获取 refs子组件呢
注意:请确保子组件已经正确挂载,并且通过 defineExpose 暴露了您想要在父组件中访问的属性或方法 parent.vue <template><child ref"childRef"></child><button click"fun">点击父组件</button> &l…...

npm 超详细使用教程
文章目录 一、简介二、npm安装三、npm 的使用3.1 npm初始化项目3.2 安装包3.3 安装不同版本包3.4 避免系统权限3.5 更新包3.6 卸载包3.7 执行脚本3.8 pre- 和 post- 脚本3.9 npm link3.10 发布和卸载发布的包3.11 使用npm版本控制3.22 npm资源 四、总结 一、简介 npmÿ…...

TypeScript函数
函数 函数:复用代码块 函数可以不写返回值 调用函数-----函数名() function a(){console.log(无参函数); } a();需要再函数后,写上返回值类型 没有返回值 使用void function e():string{return 可乐 } console.log(我得到了e()); function d():void{console.l…...
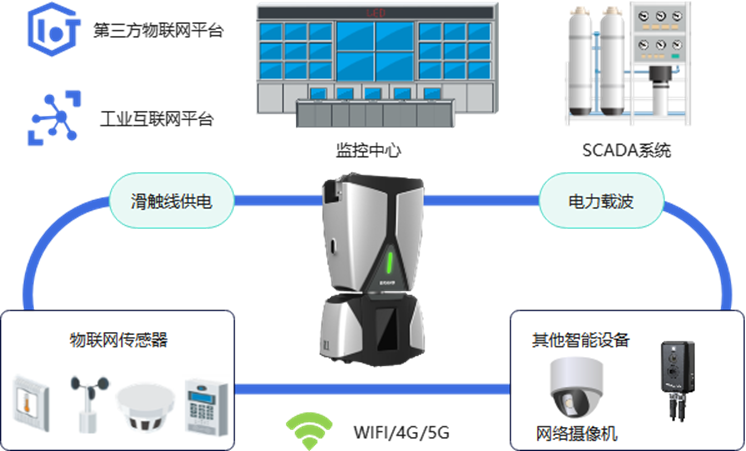
中海油某海上平台轨道巡检机器人解决方案
配电房作为能源传输和分配的核心枢纽,其安全运行直接影响到企业的生产稳定性和安全性。对于中海油这样的大型能源企业,配电房的运行状况至关重要。然而,传统的人工巡检方式存在效率低、作业风险高、巡检误差大等问题。为提升巡检效率、降低安…...

【NXP-MCXA153】SPI驱动移植
介绍 SPI总线由摩托罗拉公司开发,是一种全双工同步串行总线,由四个IO口组成:CS、SCLK、MISO、MOSI;通常用于CPU和外设之间进行通信,常见的SPI总线设备有:TFT LCD、QSPI FLASH、时钟模块、IMU等;…...

Python if 编程题|Python一对一辅导教学
你好,我是悦创。 以下为 if 编程练习题: 1. 奇数乘积问题 题目描述: 编写一个程序,判断给定的两个整数是否都是奇数,如果是,返回它们的乘积;如果不是,返回它们的和。输入: num1, num2输出: n…...

机器学习——第十一章 特征选择与稀疏学习
11.1 子集搜索与评价 对一个学习任务来说,给定属性集,其中有些属性可能很关键、很有用,另一些属性则可能没什么用.我们将属性称为"特征" (feature) ,对当前学习任务有用的属性称为"相关特征" (relevant featu…...

花式表演无人机技术详解
花式表演无人机作为现代科技与艺术融合的典范,以其独特的飞行姿态、绚烂的灯光效果及精准的控制能力,在各类庆典、体育赛事、音乐会等合中展现出非凡的魅力。本文将从以下几个方面对花式表演无人机技术进行详细解析。 1. 三维建模与编程 在花式表演无人…...

服务器那点事--防火墙
Linux服务器那点事--防火墙 Ⅰ、开启关闭Ⅱ、放开端口 Ⅰ、开启关闭 禁止防火墙开机自启systemctl disable firewalld 关闭防火墙systemctl stop firewalld 查看防火墙状态systemctl status firewalldⅡ、放开端口 例如:放开3306端口 设置放开3306端口 [rootbpm2…...

C:每日一题:单身狗
一、题目: 在一个整型数组中,只有一个数字出现一次,其他数组都是成对出现的,请找出那个只出现一次的数字。 整型数组 int arr[ ] {1,1,2,2,3,4,4} 二、思路分析: 1.,明确目标,选择…...

SQL之使用存储过程循环插入数据
1、已经创建了任务日志表 CREATE TABLE t_task_log (id bigint NOT NULL AUTO_INCREMENT,task_id bigint NOT NULL COMMENT 任务ID,read_time bigint NOT NULL COMMENT 单位秒,读取耗时,write_time bigint NOT NULL COMMENT 单位秒,写入耗时,read_size …...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...