构建实时数据仓库:流式处理与实时计算技术解析
目录
一、流式处理
请求与响应
批处理
二、实时计算
三、Lambda架构
Lambda架构的缺点
四、Kappa架构
五、实时数据仓库解决方案
近年来随着业务领域的不断拓展,尤其像互联网、无线终端APP等行业应用的激增,产生的数据量呈指数级增长,对海量数据的处理需求也提出了新的挑战。具体到数据仓库,尤其突出的一点是人们对数据分析的实时性要求越来越高,从而衍生出所谓实时数据仓库的概念。为解决数据实时性问题,也涌现出一批相关的技术。
本文将解释什么是流式处理,然后讨论实时计算的基本概念和适用场景,它们都与实时数据仓库的实施密不可分。最后从技术实现的角度介绍几种流行的实时数据仓库架构。
一、流式处理
流式处理,顾名思义,是一种处理数据流的技术。与传统的批处理方式不同,流式处理不是等待一大批数据积累完毕再进行处理,而是实时处理数据流中的每一条信息。这种方法使得系统能够即时响应变化,进行实时决策。
人们对数据流并不陌生,数据从业务系统产生,经过一系列转换进入数据仓库,再进入分析系统提供报表、仪表盘展现分析结果,最终经过数据挖掘和机器学习以辅助决策,整个过程就形成了一个数据流。当然除了直觉以外,严格的定义更有意义。数据流是无边界数据集的抽象表示。无边界意味着无限和持续增长,无边界数据集之所以是无限的,是因为随着时间的推移,新的记录会不断加入进来。这个定义已经被包括Google和Amazon在内的大部分公司所采纳。
除无边界外,数据流还有其它一些属性:有序、不可变、可重放。数据的产生总有先后顺序,这是数据流与数据库表的不同点之一,数据库表里的记录是无序的。数据一旦产生就不能被改变。假设你熟悉数据库的二进制日志(binlog)、预写日志(Write Ahead Log,WAL)和重做日志(redo log)的概念,那么就会知道,如果往数据库表插入一条记录,然后将其删除,表里就不会再有这条记录,但日志里包含了插入和删除两个事务。可重放是数据流非常有价值的一个属性。对于大多数业务来说,重放发生在几天前(甚至几个月前)的原始数据流是一个很重的需求。可能是为了尝试使用新的分析方法纠正过去的错误,或是为了进行审计。
知道什么是数据流以后,是时候了解“流式处理”的真正含义了。流式处理是指实时处理一个或多个数据流。流式处理是一种编程范式,就像请求与响应范式和批处理范式那样。下面对这三种范式进行比较,以便更好地理解如何在软件架构中应用流式处理。
请求与响应
这是延迟最小的一种范式,响应时间处于亚毫秒到毫秒之间,而且响应时间一般非常稳定。这种处理方式一般是阻塞的,应用程序向处理系统发出请求,然后等待响应。在数据库领域,这种范式就是联机事务处理(OLTP)。
批处理
这种范式具有高延迟和高吞吐量的特点。处理系统按照预定的时间启动处理进程,比如每天凌晨两点开始启动,每小时启动一次等。它读取所有的输入数据(从上一次执行之后的所有可用数据),输出结果,然后等待下一次启动。处理时间从几分钟到几小时不等,并且用户从结果里读到的都是滞后数据。在数据库领域,它们就是传统的数据仓库或商业智能系统。它们每天装载巨大批次的数据,并生成报表,用户在下一次装载数据之前看到的都是相同的报表。从规模上来说,这种范式既高效又经济。但在近几年,为了能够更及时、高效地做出决策,业务要求在更短的时间内能够提供可用数据。这就给那些为探索规模经济而开发却无法提供低延迟报表的系统带来了巨大的压力。
流式处理介于上述两种之间。某些业务不要求毫秒级的响应,不过也接受不了要等到第二天才知道结果。大部分业务流程都是持续进行的,只要业务报告保持更新,业务产品线更够保持响应,那么业务流程就可以进行下去,而无需等待特定的响应,也不要求在几毫秒内得到响应。
流式处理的整个处理过程必须是持续的。一个在每天凌晨两点启动的流程,从流里读取500条记录,生成结果,然后结束,这样的流程不是流式处理。对数据仓库来说,也许从粒度的角度理解流式处理更容易。
二、实时计算
要做到实时读写数据,必须采用有别于传统数据仓库的实现技术,实时计算的概念和技术引擎应运而生,它们是成功创建实时数据仓库的前提条件。实时计算一般针对海量数据处理,并且要求响应时间为秒级。由于大数据兴起之初,以Hadoop为代表的分布式框架并没有给出实时计算解决方案,随后便出现了Storm、Spark Streaming、Flink等实时计算框架,而Kafka、ES的兴起使得实时计算领域的技术越来越完善,而随着物联网、机器学习等技术的推广,实时流式计算将在这些领域得到充分应用。实时计算是流式处理的一种具体实现方式,因此必然具有无限数据、无界数据处理、低延迟等特征。
现在大数据应用比较火爆的领域,比如推荐系统在实践之初受技术所限,可能要一分钟、一小时、甚至更久才能对用户进行推荐,这远远不能满足需要,我们需要更快的完成对数据的处理,而不是进行离线的批处理。实时计算的应用场景主要包括实时智能推荐、实时欺诈检测、舆情分析、物联网、客服系统、实时机器学习等。
在某些场景中,数据的价值随着时间的推移而逐渐减少。所以在传统数据仓库的基础上,逐渐对数据的实时性提出了更高的要求。于是随之诞生了实时数据仓库,并且衍生出了两种主流技术架构:Lambda和Kappa。
三、Lambda架构
Lambda属于较早的一种架构方式,早期的流处理不如现在这样成熟,在准确性、扩展性和容错性上,流处理层无法直接取代批处理层,只能给用户提供一个近似结果,还不能为用户提供一个一致准确的结果。因此在Lambda架构中出现了批处理和流处理并存的现象。
在Lambda架构中,每层都有自己所肩负的任务。批处理层使用可处理大量数据的分布式处理系统预先计算结果。它通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复任何错误,然后更新现有的数据视图。输出通常存储在只读数据库中,更新则采用全量替换方式,完全取代现有的预先计算好的视图。流处理层通过提供最新数据的实时视图来最小化延迟。流处理层所生成的数据视图可能不如批处理层最终生成的视图那样准确或完整,但它们几乎在收到数据后立即可用。而当同样的数据在批处理层处理完成后,在速度层的数据就可以被替代掉了。
Lambda架构经历多年的发展,其优点是稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整体批量计算,这样把实时计算和离线计算高峰分开,这种架构支撑了数据行业的早期发展,但是它也有一些致命缺点,并在当今时代越来越不适应数据分析业务的需求。

Lambda架构的缺点
使用两套大数据处理引擎:维护两个复杂的分布式系统,成本非常高。
批量计算在计算窗口内无法完成:当数据量越来越大,经常发现夜间只有4、5个小时的时间窗口,已经无法完成白天20多个小时累计的数据,保证早上准时出数据已成为每个大数据团队头疼的问题。
数据源变化都要重新开发,开发周期长:每次需求变更后,业务逻辑的变化都需要针对ETL和Streaming做开发修改,整体开发周期很长,业务反应不够迅速。
资源占用增多:同样的逻辑计算两次,整体资源占用会增多(多出实时计算这部分)。
导致Lambda 架构的缺点根本原因是要同时维护两套系统:批处理层和速度层。我们已经知道,在架构中加入批处理层是因为从批处理层得到的结果具有高准确性,而加入速度层是因为它在处理大规模数据时具有低延时性。那我们能不能改进其中某一层的架构,让它具有另外一层架构的特性呢?例如,改进批处理层的系统让它具有更低的延迟,又或者是改进速度层的系统,让它产生的数据视图更具准确性和更加接近历史数据呢?另外一种在大规模数据处理中常用的架构——Kappa,便是在这样的思考下诞生的。
四、Kappa架构
Kappa架构可以被认为是Lambda架构的简化版,只是去除掉了Lambda架构中的离线批处理部分。
这种架构只关注流式计算,数据以流的方式被采集,实时计算引擎将计算结果放入数据服务层以供查询。Kappa架构的兴起主要有两个原因:
消息队列(如Kafka)支持数据持久化,可以保存更长时间的历史数据,以替代Lambda架构中批处理层数据仓库部分。流处理引擎以一个更早的时间作为起点开始消费,起到了批处理的作用。
流处理引擎解(如Flink)决了事件乱序下计算结果的准确性问题。
Kappa架构相对更简单,实时性更好,所需的计算资源远小于Lambda架构,最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。随着实时处理的需求在不断增长,更多的企业开始使用Kappa架构,但这不意味着Kappa架构能够取代Lambda架构。Lambda和Kappa架构都有各自的适用领域,对于流处理与批处理分析流程比较统一,且允许一定的容错,用Kappa比较合适,少量关键指标,例如交易金额、业绩统计等使用Lambda架构进行批量计算,增加一次校对过程。还有一些比较复杂的场景,批处理与流处理产生不同的结果,如使用不同的机器学习模型、专家系统,或者实时计算难以处理的复杂计算,可能更适合Lambda架构。
五、实时数据仓库解决方案
从传统的经验来讲,数据仓库有一个很重要的功能是记录数据变化历史。通常,数据仓库都希望从业务上线的第一天开始有数据,然后一直记录到现在。但实时处理技术,又是强调当前处理状态的一门技术,所以当这两个相对对立的方案重叠在一起的时候,它注定不是用来解决一个比较广泛问题的方案。于是,我们把实时数据仓库建设的目的定位为解决由于传统数据仓库数据时效性低解决不了的问题。
实时数据仓库也引入了类似于离线数据仓库的分层理念,主要是为了提高模型的复用率,同时兼顾易用性、一致性以及计算成本。通常离线数据仓库采用空间换取时间的方式,所以层级划分比较多从而提高数据计算效率。实时数据仓库的分层架构在设计上考虑到时效性问题,分层设计尽量精简,避免数据在流转过程中造成的不必要的延迟响应,并降低中间流程出错的可能性。
构建实时数仓需要根据业务需求选择合适的技术架构,并通过ETL工具来实现数据的实时采集、处理和分析,最终将结果存储到实时数据仓库中,并进行数据可视化和应用开发。
帆软软件推出的FineDataLink提供了一套完整而灵活的解决方案,可以帮助用户快速构建可靠的高时效/近实时数据仓库系统。在构建高时效/近实时数据仓库时,帆软FDL有以下优势:
1. 操作界面简洁清晰,无代码配置,字段自动映射,无需专业的编程能力即可完成任务配置。

2. 提供统一的错误队列管理、预警机制、日志管理,支持脏数据阈值设置和通知功能,可通过短信、邮件、平台消息等进行消息提醒,保证企业敏感数据的安全性。

3. 打破数据壁垒,实现低成本业务系统的数据实时同步,从多个业务数据库实时捕获源数据库的变化并毫秒内更新到目的数据库。

综上所述,数仓建设是企业数据管理和决策支持的关键环节,在实践中,企业需要根据自身业务需求和数据规模,选择合适的数仓建设方案和技术方案,以提高企业数据资产的价值和利用效率。
FineDataLink——小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,另外它可以满足数据实时同步的场景,应有尽有,功能很强大。如果您需要进行实时数仓建设,帆软FDL会是您的最优解。
免费试用、获取更多信息,点击了解更多>>>体验FDL功能
了解更多数据仓库与数据集成关干货内容请关注>>>FineDataLink官网
往期推荐:
代表性大数据技术:Hadoop、Spark与Flink的框架演进-CSDN博客
【大数据】什么是数据架构?-CSDN博客
什么是流批一体?怎样理解流批一体?_流批一体计算框架技术-CSDN博客
相关文章:
构建实时数据仓库:流式处理与实时计算技术解析
目录 一、流式处理 请求与响应 批处理 二、实时计算 三、Lambda架构 Lambda架构的缺点 四、Kappa架构 五、实时数据仓库解决方案 近年来随着业务领域的不断拓展,尤其像互联网、无线终端APP等行业应用的激增,产生的数据量呈指数级增长,对海量数…...

python算术表达式遗传算法
import random import operator import math# 定义可能的运算符和操作 ops {: ,-: -,*: *,/: /,sin: math.sin,cos: math.cos }# 随机生成一个表达式(个体) def generate_expression(depth0):if depth > 2: # 限制表达式的最大深度return str(rando…...

net.sf.jsqlparser.statement.select.SelectItem
今天一启动项目,出现了这个错误,仔细想了想,应该是昨天合并代码,导致的mybatis-plus版本冲突,以及分页PageHelper版本不兼容 可以看见这个我是最下边的 Caused by 报错信息,这个地方提示我 net .s…...

lua匹配MAC地址 正则表达式
LUA的正则表达式匹配很弱智,能不用lua就不要用lua。 %x表示十六进制数值 (%x%x):(%x%x):(%x%x):(%x%x):(%x%x):(%x%x)它不允许这样用: ((%x%x):){5}(%x%x)mac这还算好办,ipv4就难了,ipv6不可能,这样写下来那一串表达…...

Chainlit快速实现AI对话应用并将聊天数据的AWS S3 和 Azure Blob云服务中
自定义数据层 Literal AI 提供了最简单的方法来保存、分析和监控您的数据。 如果您正在考虑实现自定义数据层,请查看此处的示例以获取一些启发。 此外,我们非常希望看到社区主导的开源数据层实现并将其列在这里。如果您有兴趣做出贡献,请通过 Discord 与我们联系。 您需…...

浅谈性能优化(基于C++)
本文主要针对C的性能优化方法展开讨论。虽然这些方法也适用于一些其他语言,但由于C经常用于底层操作,提供了更多的优化空间;相比之下,诸如Python、Kotlin等高级语言由于其抽象程度更高,优化空间较少。 性能优化原理 …...

Python 报错:ModuleNotFoundError: No module named ‘Crypto‘
Crypto报错解决方案 Python 报错:ModuleNotFoundError: No module named Crypto前言问题解决方案 Python 报错:ModuleNotFoundError: No module named ‘Crypto’ 前言 Crypto是一个加密模块,它包含了多种加密算法,如 AES、DES、…...
 和 UA(User Agent))
UE(User Equipment) 和 UA(User Agent)
UE(User Equipment) UE 是 用户设备,这是一个泛指的术语,涵盖了所有类型的终端设备,例如手机、电脑、平板、智能手表等。这些设备可以连接到网络并进行通信。UE可以包含多种功能,包括对话(语音…...
视觉SLAM ch3补充——在Linux中配置VScode以及CMakeLists如何添加Eigen库
ch3中的所有代码,除了在kdevelop中运行,还可以在VScode中运行。下面将简要演示配置过程,代码不再做解答,详细内容在下面的文章中。(这一节中的pangolin由于安装过程中会出现很多问题,且后续内容用不到该平台…...
开关电源:优化电子产品中的能源使用
电压转换器是许多技术系统的支柱。根据应用的不同,所需的电源单元由变压器、整流器 AC/DC 转换器实现。当高性能开关电源尚未上市时,几乎只使用 50 Hz 变压器解决方案。 电源注意事项 电能几乎完全以三相电流的形式提供,系统电压为 10 ...3…...

Java语言程序设计——篇十三(2)
🌿🌿🌿跟随博主脚步,从这里开始→博主主页🌿🌿🌿 欢迎大家:这里是我的学习笔记、总结知识的地方,喜欢的话请三连,有问题可以私信🌳🌳&…...

python结合csv和正则实现条件筛选数据统计分数
前景提要: 有一个项目的数值和员工统计的对不上,如果一页一页翻找自己手动算,一个就有16、7页, 功能实现 1、创建csv文件 需要将每一个模块的所有数据头提取出来,这个可以直接用爬虫或者手工复制出来,因…...

Ubuntu系统的基础操作和使用|Linux|安装|网络连接|更新与升级系统|系统维护|故障排除|监控|桌面环境|虚拟机|快捷键
目录 1. Ubuntu系统的安装与初步设置 1.1 下载与安装Ubuntu 1.2 创建用户和设置密码 1.3 配置网络连接 1.4 更新与升级系统 2. Ubuntu的基本操作 2.1 文件与目录管理 2.2 系统进程管理 2.3 软件安装与管理 2.4 权限与用户管理 3. 系统维护与故障排除 3.1 系统日志查…...

day 38
2824.统计和小于目标的下标对数目 int countPairs(int* nums, int numsSize, int target){int x0;for(int i0;i<numsSize;i){for(int ji1;j<numsSize;j){if(nums[i]nums[j]<target){x;}}}return x; }2951.找出峰值 int* findPeaks(int* mountain, int mountainSize,…...

352532
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm1001.2014.3001.5343 给大家分享一句我很喜欢我话: 知不足而奋进,望远山而前行&am…...

Day.38 | 1143.最长公共子序列 1035.不相交的线 53.最大子序和 392.判断子序列
1143.最长公共子序列 要点:dp[i][j] dp[i - 1][j - 1] 1; dp[i][j] max(dp[i - 1][j], dp[i][j - 1]); class Solution { public:int longestCommonSubsequence(string text1, string text2) {vector<vector<int>> dp(text1.size() 1, vector<…...

pytorch 3 计算图
计算图结构 分析: 起始节点 ab 5 - 3ac 2b 3d 5b 6e 7c d^2f 2e最终输出 g 3f - o(其中 o 是另一个输入) 前向传播 前向传播按照上述顺序计算每个节点的值。 反向传播过程 反向传播的目标是计算损失函数(这里假设为…...

一文吃透:暗水印是什么?企业防泄密可以加暗水印吗?
设计部主管:昨天下班的时候我在办公室捡到一张文件,上面可是我们最新产品的设计草稿,严禁打印的,到底是谁干的? 员工:办公室没有监控,似乎很难查到哦。 网络部经理:不用担心&#…...

Ajax-02.Axios
Axios入门 1.引入Axios的js文件 <script src"js/axios-0.18.0.js"></script> Axios 请求方式别名: axios.get(url[,config]) axios.delete(url[,config]) axios.post(url[,data[,config]]) axios.put(url[,data[,config]]) 发送GET/POST请求 axios.get…...

NodeJS的核心配置文件package.json和package.lock.json详解
package.json 文件 package.json 文件是 Node.js 项目的核心配置文件,它包含了项目的基本信息、依赖关系以及一些脚本命令等。以下是 package.json 文件的主要字段说明: name:项目的名称,必须是小写,可以包含字母、数…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...
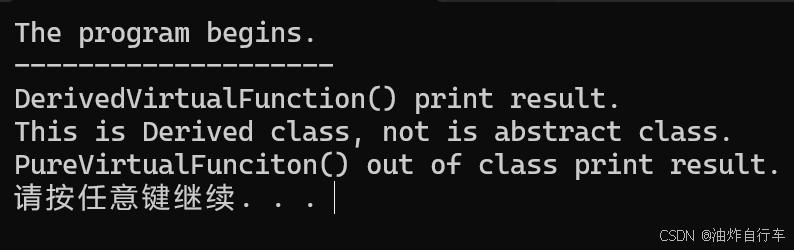
【C++】纯虚函数类外可以写实现吗?
1. 答案 先说答案,可以。 2.代码测试 .h头文件 #include <iostream> #include <string>// 抽象基类 class AbstractBase { public:AbstractBase() default;virtual ~AbstractBase() default; // 默认析构函数public:virtual int PureVirtualFunct…...