【机器学习】深度强化学习–RL的基本概念、经典场景以及算法分类
引言
深度强化学习(Deep Reinforcement Learning, DRL)是机器学习的一个分支,它结合了深度学习(Deep Learning)和强化学习(Reinforcement Learning, RL)的技术
文章目录
- 引言
- 一、深度强化学习–RL的基本概念
- 1.1 强化学习基础
- 1.2 强化学习的核心概念
- 1.2.1 探索(Exploration)与利用(Exploitation)
- 1.2.2 价值函数(Value Function)
- 1.2.3 Q函数(Q-function)
- 1.3 深度强化学习
- 1.3.1 深度神经网络
- 1.3.2 经验回放(Experience Replay)
- 1.3.3 目标网络(Target Network)
- 1.4 流行算法
- 1.4.1 深度Q网络(DQN)
- 1.4.2 异步优势演员评论家(A3C)
- 1.4.3 信任区域策略优化(TRPO)
- 1.4.4 近端策略优化(PPO)
- 1.4.5 模型预测控制(MPC)
- 1.5 应用领域
- 1.6 挑战
- 1.7 总结
- 二、强化学习的典型场景
- 三、强化学习算法分类
- 3.1 根据学习策略分类
- 3.1.1 策略学习(Policy Learning)
- 3.1.2 模型学习(Model Learning)
- 3.2 根据策略类型分类
- 3.3 根据学习方法分类
- 3.3.1 基于模型的强化学习(Model-Based Reinforcement Learning)
- 3.3.2 无模型强化学习(Model-Free Reinforcement Learning)
- 3.4 根据应用领域分类
- 3.4.1 离线强化学习(Off-Policy Reinforcement Learning)
- 3.4.2 在线强化学习(On-Policy Reinforcement Learning)
- 3.4.3 离线到在线学习(Off-Policy to On-Policy Learning)
- 3.5 总结
一、深度强化学习–RL的基本概念
1.1 强化学习基础
- 代理(Agent):执行动作并学习策略的主体
- 环境(Environment):代理与之交互的整个外部世界
- 状态(State):代理在环境中的当前情况
- 动作(Action):代理可以执行的操作
- 奖励(Reward):代理执行某个动作后,环境给予的正面或负面反馈
- 策略(Policy):代理用于决策的函数或规则,即给定当前状态,选择下一步动作的方法
1.2 强化学习的核心概念
1.2.1 探索(Exploration)与利用(Exploitation)
探索是指尝试新的动作以获取更多信息,而利用是基于现有信息做出最佳决策
1.2.2 价值函数(Value Function)
预测从某个状态开始,遵循特定策略能够获得的期望回报
1.2.3 Q函数(Q-function)
对于给定状态和动作,预测采取该动作后能够获得的期望回报
1.3 深度强化学习
深度强化学习结合了深度学习的感知能力和强化学习的决策能力
1.3.1 深度神经网络
用于近似价值函数或策略函数,处理复杂的输入,如图像
1.3.2 经验回放(Experience Replay)
存储代理的经验,并在训练时随机抽取批次来打破数据间的相关性,稳定学习过程
1.3.3 目标网络(Target Network)
用于生成目标Q值,帮助稳定训练过程
1.4 流行算法
1.4.1 深度Q网络(DQN)
使用深度神经网络来近似Q函数,能够处理高维输入空间
1.4.2 异步优势演员评论家(A3C)
并行训练多个代理,每个代理都在不同的环境中执行,以学习一个共享的全球策略
1.4.3 信任区域策略优化(TRPO)
一种策略梯度方法,使用信任区域来优化策略,保证改进的稳定性
1.4.4 近端策略优化(PPO)
TRPO的改进版本,更加简单且稳定
1.4.5 模型预测控制(MPC)
使用模型来预测未来状态,并基于这些预测做出最优决策
1.5 应用领域
- 游戏:如DeepMind的AlphaGo在围棋上的胜利
- 机器人技术:如机械臂的操控、自动驾驶汽车
- 资源优化:如数据中心能源管理
- 金融:如算法交易策略
1.6 挑战
- 稳定性和收敛性:深度强化学习算法可能会遇到训练不稳定的问题
- 样本效率:强化学习通常需要大量的交互数据
- 安全性:在现实世界中部署的代理需要能够安全地与动态环境互动
1.7 总结
深度强化学习是一个快速发展的领域,随着算法和计算资源的进步,它有望在更多领域实现突破
二、强化学习的典型场景
在 Flappy bird 这个游戏中,我们需要简单的点击操作来控制小鸟,躲过各种水管,飞的越远越好,因为飞的越远就能获得更高的积分奖励
- 机器有一个明确的小鸟角色——代理
- 需要控制小鸟飞的更远——目标
- 整个游戏过程中需要躲避各种水管——环境
- 躲避水管的方法是让小鸟用力飞一下——行动
- 飞的越远,就会获得越多的积分——奖励

三、强化学习算法分类
了解强化学习中常用到的几种方法,以及他们的区别,对我们根据特定问题选择方法时很有帮助。强化学习是一个大家族,发展历史也不短,具有很多种不同方法。比如说比较知名的控制方法 Q learning,Policy Gradients,还有基于对环境的理解的 model-based RL 等等
3.1 根据学习策略分类
3.1.1 策略学习(Policy Learning)
- 策略迭代(Policy Iteration):一种确定性策略,通过策略评估和策略改进来寻找最优策略。
- 值迭代(Value Iteration):一种策略评估方法,通过迭代更新状态值函数来找到最优策略。
3.1.2 模型学习(Model Learning)
- 模型预测控制(Model Predictive Control, MPC):在每一步都通过预测模型来选择动作。
- 无模型强化学习(Model-Free Reinforcement Learning):不需要了解环境模型的强化学习,如Q-Learning
3.2 根据策略类型分类
- 确定性策略(Deterministic Policy):在给定状态下,总是选择同一个动作
- 随机策略(Stochastic Policy):在给定状态下,选择动作的概率分布
3.3 根据学习方法分类
3.3.1 基于模型的强化学习(Model-Based Reinforcement Learning)
- 模型预测控制(MPC):在每一步都使用预测模型来选择动作
3.3.2 无模型强化学习(Model-Free Reinforcement Learning)
- Q-Learning:基于状态-动作值函数的强化学习算法
- Sarsa:与Q-Learning类似,但在选择下一个动作时使用当前策略
- 深度Q网络(DQN):结合了深度学习和Q-Learning的强化学习算法
- 策略梯度(Policy Gradient):直接学习策略,通过策略梯度来优化策略
- 近端策略优化(PPO):一种改进的策略梯度方法,通过近端策略优化来稳定训练过程
3.4 根据应用领域分类
3.4.1 离线强化学习(Off-Policy Reinforcement Learning)
- Q-Learning:学习状态-动作值函数,可以与离线数据一起使用
3.4.2 在线强化学习(On-Policy Reinforcement Learning)
- Sarsa:在线学习状态-动作值函数,需要实时与环境交互
3.4.3 离线到在线学习(Off-Policy to On-Policy Learning)
- 信任区域策略优化(TRPO):一种从离线策略转移到在线策略的方法
3.5 总结
这些分类方式可以帮助我们更好地理解强化学习算法的不同特性和适用场景。随着研究的不断深入,新的算法和分类方式也在不断涌现
相关文章:
【机器学习】深度强化学习–RL的基本概念、经典场景以及算法分类
引言 深度强化学习(Deep Reinforcement Learning, DRL)是机器学习的一个分支,它结合了深度学习(Deep Learning)和强化学习(Reinforcement Learning, RL)的技术 文章目录 引言一、深度强化学习–…...

【git】将本地文件上传到github
安装git 选择一个文件夹作为git仓库,cd到文件夹输入 git init文件夹出现.git文件夹,该文件夹默认为隐藏文件夹,设置为不隐藏 在cmd中输入 ssh-keygen -t rsa -C "xxxxxx.com"该邮箱为github邮箱,然后一路enter出现以…...

安卓应用开发学习:手机摇一摇功能应用尝试--摇骰子和摇红包
一、引言 前几天,我发布的日志《安卓应用开发学习:查看手机传感器信息》记录了如何查看手机传感器的信息,通过上述的方法,可以看到我的OPPO手机支持19种传感器。本篇日志就记录一下常见的加速度传感器的典型应用——“摇一摇”功…...

HTML中的<fieldset>标签元素框的使用
HTML 提供的 <fieldset> 标签用于在表单中分组相关元素。 <fieldset> 标签会在相关元素周围绘制一个框。 <legend> 标签为 fieldset 元素定义标题。 语法如下: <fieldset><legend>标题</legend><!-- 元素内容... -->…...
Linux驱动入门实验班——SR501红外模块驱动(附百问网视频链接)
目录 一、工作方式 二、接口图 三、编写思路 1.构造file_operations结构体 2.实现read函数 3.编写入口函数 4.编写中断处理函数 5.编写出口函数 6.声明出入口函数以及协议 四、源码 五、课程链接 一、工作方式 SR501人体红外感应模块有两种工作模式: …...
)
windows C++- Com技术简介(上)
在介绍C和winrt与COM组件技术的关系之前,有必要介绍一下com组件技术,这项技术比较古老,但是它一直作为windows的基石存在。COM 是一类独立于平台且面向对象的分布式系统,用于创建可交互的二进制软件组件。 COM 技术是 Microsoft O…...

Jenkins持续集成工具学习
一、从装修厨房看项目开发效率优化 二、持续集成工具 三、JavaEE项目部署方式对比 四、JenkinsSVN持续集成环境搭建 五、JenkinsGitHub持续集成环境搭建...

Redis:查询是否包含某个字符/字符串之三
上一篇:Redis:查询是否包含某个字符/字符串之二-CSDN博客 摘要: 遍历key,在跟进value的类型遍历value是否包含指定字符串 search_strings ,这里使用redis-py库,默认只能处理utf-8编码,如果存在…...
【Redis】数据类型详解及其应用场景
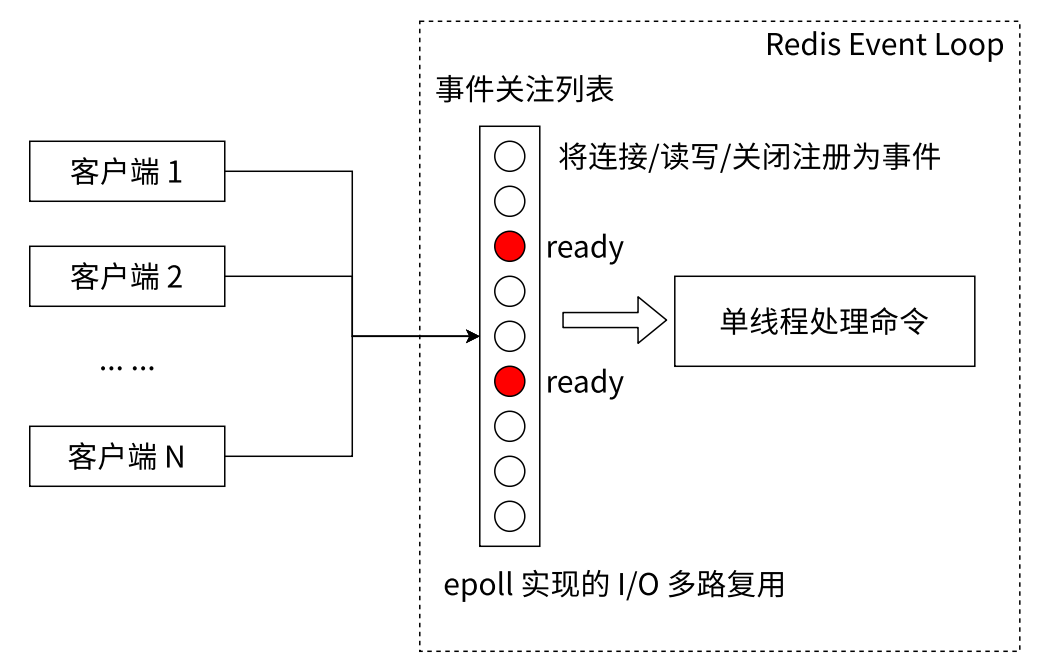
目录 Redis 常⻅数据类型预备知识基本全局命令小结 数据结构和内部编码单线程架构引出单线程模型为什么单线程还能这么快 Redis 常⻅数据类型 Redis 提供了 5 种数据结构,理解每种数据结构的特点对于 Redis 开发运维⾮常重要,同时掌握每种数据结构的常⻅…...

PARA-Drive:设计并行模型实现端到端自动驾驶
论文链接 https://openaccess.thecvf.com/content/CVPR2024/papers/Weng_PARA-Drive_Parallelized_Architecture_for_Real-time_Autonomous_Driving_CVPR_2024_paper.pdfhttps://openaccess.thecvf.com/content/CVPR2024/papers/Weng_PARA-Drive_Parallelized_Architecture_fo…...

vs2022 x64 C/C++和汇编混编 遇到的坑
vs2022 x64 C/C和汇编混编 遇到的坑 遇到的问题二、问题复现1.出错代码2.问题分析2.1 堆栈对齐问题 3.解决方案 总结奇数和偶数个寄存器的影响为什么 sub rsp, 8 对奇数个寄存器有用?结论 遇到的问题 0x00007FFFFAE24A29 (msvcp140.dll)处(位于 TestCompileConsole…...
PHP概述、环境搭建与基本语法讲解
目录 【学习目标、重难点知识】 什么是网站? 1. PHP 介绍 1.1. PHP 概述 1.1.1. PHP 是什么? 1.1.2. PHP 都能做什么? 1.2. PHP 环境搭建 1.2.1. PhpStudy 2. PHP 基本语法 2.1. PHP 语法入门 2.1.1. 第一个 PHP 程序 2.1.2. PHP …...
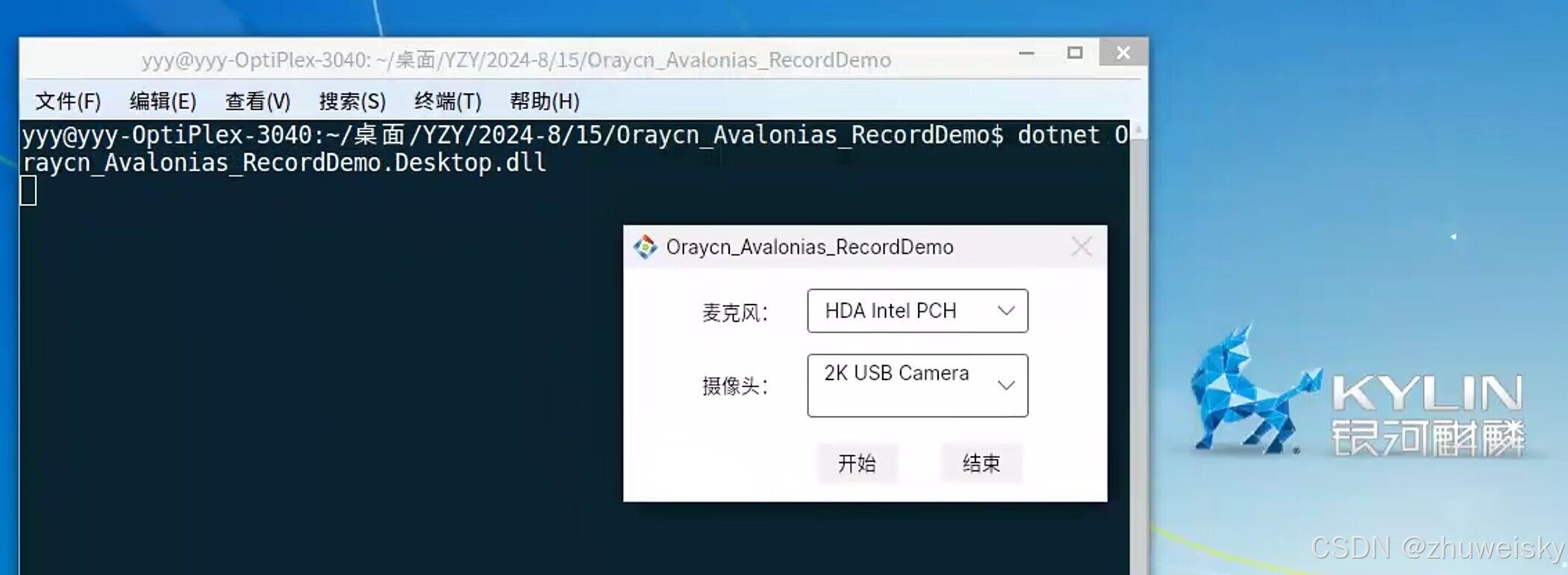
实现信创Linux麦克风摄像头录制(源码,银河麒麟、统信UOS)
随着信创国产化浪潮的来临,在国产操作系统上的应用开发的需求越来越多,其中一个就是需要在银河麒麟或统信UOS上实现录制摄像头视频和麦克风声音,将它们录制成一个mp4文件。那么这个要如何实现了? 一. 技术方案 要完成这些功能&a…...

深度学习9--目标检测
1.概念介绍 目标检测不仅可以检测数字,而且可以检测动物的种类、汽车的种类等。例如,自动驾驶车辆需要自动识别前方物体是车辆还是行人,需要自动识别道路两 旁的指示牌和前方的红绿灯颜色。对于自动检测的算法,有两个要求…...

第131天:内网安全-横向移动Kerberos 攻击SPN扫描WinRMWinRSRDP
案例一:域横向移动-RDP-明文&NTLM RDP利用的三种方式 1.直接在当前被控主机上进行远程连接 2.建立节点进行连接 3.端口转发,(访问当前主机的2222端口等于访问目标的3389) 第一种方式(动静太大) 直接利用被控主机进行远程连接…...

微信小程序的四种弹窗使用
在做小程序的过程中,弹窗也算是非常实用的功能了,这几天写的几个功能就用到了弹窗,也可能是初学者的问题,比较菜,想找一个可以带图片的自定义的弹窗,,这里简单介绍一下官方封装好的四个弹窗…...

我的第一个CUDA程序
MatAdd算法 实现两个矩阵对应元素相加 #include <stdio.h> #include <stdlib.h>// 矩阵加法函数 void MatAdd(int height, int width) {// 在主机内存中为 A、B 和 C 分配内存float* A (float*)malloc(height * width * sizeof(float));float* B (float*)malloc…...

workerman下的webman路由浏览器跨域的一种问题
软件版本 "php": ">7.2", "workerman/webman-framework": "^1.5.0",问题情景 使用“分组路由”做API接口前后端分离跨域,在接口测试工具调试是能正常获取数据的;但在网页浏览器上调试就遇到了CORS、404的错…...

Windows11 -MASKRCNN-部署测试
文章目录 Detectron2环境配置搭建python 环境安装Cuda \CUDNN 、PyTorch、 torchvision、cudatoolkit1、Cuda \CUDNN2、 PyTorch、 torchvision、cudatoolkit进入python测试:错误信息 3、detectron2环境在安装detecteron中,遇到报错:编译的时…...

函数(子程序)的常见、易混淆概念详解【对初学者有帮助】
C语⾔中的函数也被称做子程序,意思就是⼀个完成某项特定的任务的⼀小段代码。 C语⾔标准中提供了许多库函数,点击下面的链接可以查看c语言的库函数和头文件。 C/C官⽅的链接:https://zh.cppreference.com/w/c/header 目录 一、函数头与函…...

如何用Chinese-STD-GB-T-7714-related-csl解决学术论文参考文献格式难题
如何用Chinese-STD-GB-T-7714-related-csl解决学术论文参考文献格式难题 【免费下载链接】Chinese-STD-GB-T-7714-related-csl GB/T 7714相关的csl以及Zotero使用技巧及教程。 项目地址: https://gitcode.com/gh_mirrors/chi/Chinese-STD-GB-T-7714-related-csl Chinese…...

5个步骤玩转AntiMicroX:让任何游戏手柄适配PC游戏
5个步骤玩转AntiMicroX:让任何游戏手柄适配PC游戏 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gitcode.com/GitHub_Tr…...

重新定义扩散模型开发:DiffSynth-Studio的模块化架构深度解析
重新定义扩散模型开发:DiffSynth-Studio的模块化架构深度解析 【免费下载链接】DiffSynth-Studio DiffSynth Studio 是一个扩散引擎。我们重组了包括 Text Encoder、UNet、VAE 等在内的架构,保持了与开源社区模型的兼容性,同时提高了计算性能…...

南北阁Nanbeige 4.1-3B多语言支持:技术文档翻译与本地化实践
南北阁Nanbeige 4.1-3B多语言支持:技术文档翻译与本地化实践 最近在折腾一些开源项目时,发现不少优秀的工具和框架,文档只有英文版。对于国内开发者来说,这多少是个门槛。虽然现在翻译工具不少,但技术文档的翻译是个精…...
HGT实战:如何用Heterogeneous Graph Transformer处理学术图谱中的多类型节点关系
HGT实战:从学术图谱到工业级应用的异构注意力建模 在推荐系统与知识图谱构建领域,数据科学家们常常需要处理包含论文-作者-机构-会议等多类型节点的复杂网络。传统图神经网络(GNN)的同构假设在这里遇到了瓶颈——当不同类型的节点共享同一套特征转换规则…...
打造Windows任务栏美化新体验:TranslucentTB轻量级透明工具全攻略
打造Windows任务栏美化新体验:TranslucentTB轻量级透明工具全攻略 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 在Windows桌…...
)
Windows开发者必备:dumpbin工具实战指南(附VS2022配置)
Windows开发者必备:dumpbin工具实战指南(附VS2022配置) 在Windows开发过程中,二进制文件分析是一个无法绕开的关键环节。无论是排查DLL依赖问题,还是验证函数导出表,亦或是分析崩溃模块,dumpbin…...

Notepad--跨平台文本编辑器:提升效率的三个核心应用场景与进阶技巧
Notepad--跨平台文本编辑器:提升效率的三个核心应用场景与进阶技巧 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad…...

激活函数调参指南:用PyTorch可视化ReLU/GELU/LeakyReLU的梯度差异与训练效果
激活函数调参实战:PyTorch可视化与梯度差异深度解析 在深度学习模型调优过程中,激活函数的选择往往被忽视,却直接影响着模型的收敛速度和最终性能。本文将带您深入ReLU、GELU和LeakyReLU三大主流激活函数的微观世界,通过PyTorch动…...

3分钟上手Rufus:轻松制作Windows/Linux启动盘的开源神器
3分钟上手Rufus:轻松制作Windows/Linux启动盘的开源神器 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 你是否曾经为制作系统启动盘而烦恼?下载了Windows 11镜像却无法在…...