机器学习速成第三集——无监督学习之聚类(理论部分)!
目录
聚类的定义和原理
常见的聚类算法
应用场景
总结
无监督学习中聚类算法的最新进展是什么?
K-Means聚类算法在处理大规模数据集时的性能优化方法有哪些?
并行计算模型:
多核处理器优化:
分层抽样:
特征缩放和数据降维:
自动确定聚类数量:
多线程和多核优化:
超参数优化:
DBSCAN聚类算法的参数如何选择,以提高对噪声数据的鲁棒性?
1.邻域半径(Eps) :
2.最小点数(MinPts) :
噪声处理:
并行计算:
t-SNE聚类算法在大规模数据集上的计算效率提升策略有哪些?
谱聚类算法在复杂结构数据集上的应用案例和效果评估

无监督学习中的聚类部分是机器学习中一个重要的领域,它旨在发现数据集中的自然分组或模式。聚类算法不需要预先标记的数据,而是根据数据本身的特征进行分类。
聚类的定义和原理
聚类是一种将大量未知标注的数据集按其内在相似性划分为多个类别(簇)的方法,使得同一簇内的数据对象尽可能相似,而不同簇之间的数据对象尽可能不相似. 这种方法通常通过计算数据点之间的距离或相似度来实现。
常见的聚类算法
-
K-Means聚类:
- 原理:K-Means算法通过迭代将数据划分为K个簇,使得每个对象到其所属簇的质心的距离最小。
- 优缺点:简单易实现,但需要预先指定簇的数量,并且对初始质心的选择敏感。
-
层次聚类(Hierarchical Clustering) :
- 原理:层次聚类可以分为凝聚层次聚类和分裂层次聚类。凝聚层次聚类从单个数据点开始,逐步合并最相似的点形成更大的簇;分裂层次聚类则相反,从整体数据集开始,逐步拆分成更小的簇。
- 优缺点:能够处理任意形状的簇,但计算复杂度较高。
3.DBSCAN聚类:
- 原理:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它可以根据任意形状的簇和噪声数据进行聚类。
- 优缺点:对噪声数据不敏感,可以发现任意形状的簇,但参数选择较为复杂。
4.t-SNE聚类:
- 原理:t-SNE(t-Distributed Stochastic Neighbor Embedding)主要用于降维和可视化,但也可用于聚类分析。它通过保持近邻点之间的距离来进行低维嵌入。
- 优缺点:适合高维数据的降维和可视化,但在大规模数据集上计算成本较高。
5.其他聚类算法:
- 均值偏移(Mean Shift) :一种基于模式识别的非参数聚类方法,通过迭代寻找局部密度峰值来确定簇中心。
- 谱聚类(Spectral Clustering) :利用图论中的谱方法进行聚类,适用于具有复杂结构的数据集。
应用场景
聚类算法广泛应用于多个领域,包括但不限于:
- 数据挖掘:用于发现数据中的模式和关联。
- 医学影像分析:用于图像分割和特征提取。
- 市场分析:用于客户细分和产品分类。
- 计算机视觉:用于图像识别和对象检测。
- 自然语言处理:用于文档分类、主题发现和情感分析。
总结
无监督学习中的聚类部分是机器学习中不可或缺的一部分,它通过发现数据中的自然分组来揭示数据的内在结构和模式。不同的聚类算法有各自的优缺点和适用场景,选择合适的聚类算法需要根据具体问题的需求和数据的特点来决定。
无监督学习中聚类算法的最新进展是什么?
无监督学习中聚类算法的最新进展主要集中在以下几个方面:
基于自动编码器的深度聚类:自动编码器是一种应用于无监督学习的神经网络,由编码器和解码器两部分组成。输入数据通过编码器得到潜在空间,解码器重构潜在空间特征向量,得到输出。自动编码器最小化原始输入数据与重构数据的误差,尽可能地保留数据的特征。
多实例聚类:无监督多实例学习在某些情况下可能比有监督多实例学习更具挑战性,但它仍然重要且值得关注,因为它可以帮助识别具有相似特性的数据点并揭示数据集的内在结构。文中提出了一种名为Bamict(BAg-level Multi-Instance Clustering)的多实例聚类算法,该算法使用Hausdorff度量来将未标记的训练袋分为k个离散组,并采用适应性的人群聚类算法来执行聚类任务。
子空间聚类、半监督聚类和谱聚类:子空间聚类解决了传统聚类算法只能在整个空间中寻找簇的问题,而自然簇可能只存在于某些子空间中。半监督聚类允许用户提供初始信息来引导聚类过程,例如选择初始种子或指定约束条件。谱聚类则从VLSI和计算机视觉等多个领域中汲取灵感,通过计算相似性矩阵的特征值对数据点进行聚类。
无监督判别极限学习提升聚类准确率:利用无监督判别极限学习提升聚类准确率的研究表明,USELM(无监督ELM)在计算和准确性方面与几种最先进的无监督算法进行比较时,在聚类方面表现出优异的性能,但更注重数据的局部结构。
K-Means聚类算法的新成果:K-Means聚类算法在2024年有了新的成果,预测准确率高达94.61%,这种算法的核心在于它可以通过迭代计算,将数据点归入预设数量的簇中,让簇内数据点相似度高,簇间数据点相似度低,从而实现高效的数据聚类。
无监督学习中聚类算法的最新进展包括基于自动编码器的深度聚类、多实例聚类、子空间聚类、半监督聚类、谱聚类、无监督判别极限学习以及K-Means聚类算法的新成果等。
K-Means聚类算法在处理大规模数据集时的性能优化方法有哪些?
K-Means聚类算法在处理大规模数据集时的性能优化方法有多种,以下是一些主要的优化策略:
-
并行计算模型:
- 结合MapReduce计算模型,利用Hash函数进行样本抽取,并使用PAM算法获取初始中心的并行聚类方法可以显著提高K-means算法对大规模数据聚类的效率。
- 基于Spark技术的并行框架,通过稀疏化相似矩阵、构建Laplacian矩阵和距离计算的并行优化,以及近似特征向量计算来减少计算量,从而提升大规模数据集上的聚类性能。
-
多核处理器优化:
在多核处理器环境下,将K-means算法的四个主要阶段(数据读取、判断数据点类别、计算簇中心和准则函数)分别进行并行化,充分利用多核特性,以提高单节点和整体的聚类效率。
-
分层抽样:
采用基于分层抽样的大数据快速聚类算法(FCASS),首先将原始数据集进行分层,使得层内数据相似度较大,层间数据相似度较小。然后引入抽样时间函数,求得各层样本量的最优分配方案,最后用K-means算法对样本集进行聚类,得到最终结果。这种方法能够有效缩短迭代时间,提高聚类精度和运行速度。
-
特征缩放和数据降维:
数据预处理中的特征缩放和数据降维是提高K-means算法性能的重要步骤。这些方法可以有效减少计算复杂度,提高算法的准确性和效率。
-
自动确定聚类数量:
使用基于KD树的方法来自动估计聚类数量,该方法不仅能够自动确定聚类数量,还能在处理大量数据时保持较好的聚类质量和处理时间。
-
多线程和多核优化:
利用现代CPU的多核计算能力,将K-means聚类任务按数据集等分为多个相互独立的子任务,并动态分配给多个线程并行执行,从而充分利用多核计算资源。
-
超参数优化:
提出了一种新的方法来确定k-means聚类算法中最佳的超参数,并解决了如何自动选择数据分区方法以处理工作负载的问题。
DBSCAN聚类算法的参数如何选择,以提高对噪声数据的鲁棒性?
DBSCAN聚类算法的参数选择对于提高对噪声数据的鲁棒性至关重要。以下是几个关键参数及其选择方法:
1.邻域半径(Eps) :
- 选择方法:可以通过KNN距离图来帮助选择适当的ε值。具体来说,可以采用k-distance函数来确定合适的ε值。
- 影响因素:ε的选择需要根据实际数据集来确定,一般通过可视化的方式来选择。对于较为均匀分布的数据,可以选择较小的ε值。
2.最小点数(MinPts) :
- 选择方法:通常需要在多组值中选择一个合适的阈值。例如,在scikit-learn中,默认值是5,但可以根据数据的具体情况调整。
- 影响因素:MinPts的大小直接影响核心点的定义和簇的数量。较大的MinPts值可能会导致更多的噪声点被识别为边缘点或单独的噪声点。
-
噪声处理:
- 改进方法:可以通过引入新的阈值或规则来判断哪些点应该被视为噪声点,从而提高算法对噪声的鲁棒性。
- 实践应用:例如,可以在不同ε值下进行交叉验证,以找到最佳的ε和MinPts组合,从而减少噪声的影响并提高聚类效果。
-
并行计算:
优化建议:为了提高效率,可以考虑使用并行计算技术来加速DBSCAN算法的执行。
总结而言,DBSCAN算法的参数选择需要综合考虑数据的特性、噪声水平以及聚类目标。
t-SNE聚类算法在大规模数据集上的计算效率提升策略有哪些?
在处理大规模数据集时,t-SNE聚类算法的计算效率可以通过多种策略来提升。以下是一些主要的优化方法:
并行化计算:利用GPU加速t-SNE的底层计算代码,实现并行化处理,可以显著提高计算效率。例如,使用CUDA编写的tsne-cuda库能够通过并行化计算大幅提高t-SNE的运行速度。
减少算术运算:在许多t-SNE实现中,吸引力计算(弹簧拉力)被拆分为先在点a上,后在点b上进行计算。如果同时计算交互,而不是单独计算,可以将乘法和地址的数量从原来的9个减少到大约4个,并使此计算速度提高50%。
Barnes-Hut t-SNE:这是一种高效的降维算法,适用于处理大规模数据集。它通过近似高维概率分布来减少计算复杂度,从而提高计算效率。
优化内存使用:通过减少GPU内存的使用来计算更高的维度概率,可以有效提高t-SNE在GPU上的性能。
沿行广播优化:这种优化方法可以进一步提高t-SNE在GPU上的性能。
对称t-SNE:将sne变为对称sne,提高了计算效率,效果稍有提升。
谱聚类算法在复杂结构数据集上的应用案例和效果评估。
谱聚类算法在处理复杂结构数据集上的应用案例和效果评估可以从多个角度进行分析。首先,根据,多路谱聚类算法的改进版本通过利用局部近邻关系更新初始相似度矩阵,能够有效地对复杂结构数据集进行聚类,理论分析表明该方法能够保证聚类划分的正确性。这表明谱聚类算法在复杂结构数据集上的应用具有一定的理论基础和实践效果。
进一步强调了谱聚类算法在处理非线性、复杂结构的数据集时的优越性。与传统的聚类方法如K-means相比,谱聚类能够更好地识别出数据中的簇结构,尤其是在特征向量构成的新特征空间中,应用K-means或其他聚类算法对数据点进行聚类时,图拉普拉斯矩阵作为谱聚类的核心,反映了数据点之间的连接关系,从而提高了聚类的准确性。
指出,谱聚类算法在处理复杂数据结构、大规模数据集和无监督学习方面具有显著的优势。它通过将数据点视为图中的顶点,并根据数据点之间的相似性建立连接边,将聚类问题转化为图的划分问题,这使得谱聚类算法在处理各种复杂形状的数据集时表现出色。
提供了具体的案例和效果评估。提到,Scikit-learn的SpectralClustering函数可以有效地处理复杂数据集上的聚类任务,通过调整不同的可调参数,可以实现对不同数据集的具体优化。的研究发现,谱聚类算法要比K-means提供更好的聚类结果,尤其在实验条件较苛刻时,谱聚类算法更加稳健,线型结构聚类效果最好,收敛型和发散型相近,独立型结构的聚类效果也较好。
展示了谱聚类算法在大数据和复杂数据集上的应用。基于自适应Nyström采样的大数据谱聚类算法能够优化数据的结构,得到令人满意的聚类效果。则提出了基于流形距离核的自适应迁移谱聚类算法,通过自适应调整核函数和引入迁移学习方法,提高了谱聚类对复杂数据集的处理能力,实验验证表明该算法与原始谱聚类算法相比有明显提升。
相关文章:
机器学习速成第三集——无监督学习之聚类(理论部分)!
目录 聚类的定义和原理 常见的聚类算法 应用场景 总结 无监督学习中聚类算法的最新进展是什么? K-Means聚类算法在处理大规模数据集时的性能优化方法有哪些? 并行计算模型: 多核处理器优化: 分层抽样: 特征缩…...

【机器学习】CNN的基本架构模块
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 CNN的基本架构模块1. 引言2. 卷积层2.1 基本原理2.2 卷积层的特性2.3 卷积层的超…...
)
第八节AWK报告生成器(2)
3,1,2 printf 语法: printf("format\n", [arguments])格式说明 format是一个用来描述输出格式的字符串,format格式的指示符都以%开头,后跟一个字符,如下: format含义%c显示字符的asicll%d,%i十进制整数%e,%E科学计数法显示数值…...
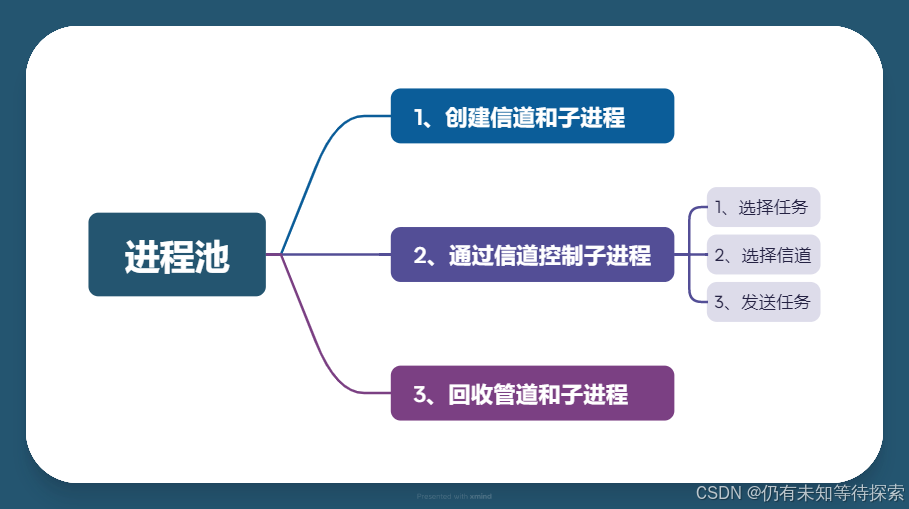
Linux 进程间通信之管道
个人主页:仍有未知等待探索-CSDN博客 专题分栏: Linux 目录 一、通信 1、进程为什么要通信? 1.数据的类型 2.父进程和子进程算通信吗? 2、进程如何通信? 3、进程通信的常见方式? 二、管道 1、概念…...

IDEA 无法启动,点击之后没有任何提示或者界面
当你尝试通过双击或以管理员身份启动程序时,均未能成功,且未收到任何提示信息或界面反馈,这确实令人困扰。为了诊断问题并获取有用的错误信息,你可以按照以下步骤操作: 1. 启用并查看错误信息 首先,你需要…...

ctf 堆栈结构
CTF(Capture The Flag)竞赛中,理解堆栈结构对于解决涉及二进制分析、逆向工程和利用开发的挑战至关重要。堆栈是在程序执行过程中用于临时存储数据和管理函数调用的关键数据结构。以下是堆栈结构的基本概念及其在CTF竞赛中的应用:…...

sqlserver的openquery配置
1.命令Demo ---openquery--开启Ad Hoc Distributed Queries组件,在sql查询编辑器中执行如下语句exec sp_configure show advanced options,1reconfigureexec sp_configure Ad Hoc Distributed Queries,1reconfigure--关闭Ad Hoc Distributed Queries组件࿰…...

Spring boot logback日志框架加载初始化源码
##LoggingApplicationListener监听 Overridepublic void onApplicationEvent(ApplicationEvent event) {if (event instanceof ApplicationStartingEvent) {onApplicationStartingEvent((ApplicationStartingEvent) event);}else if (event instanceof ApplicationEnvironment…...

qt-11基本对话框(消息框)
基本对话框--消息框 msgboxdlg.hmsgboxdlg.cppmain.cpp运行图QustionMsgInFormationMsgWarningMsgCriticalMsgAboutMsgAboutAtMsg自定义 msgboxdlg.h #ifndef MSGBOXDLG_H #define MSGBOXDLG_H#include <QDialog> #include <QLabel> #include <QPushButton>…...

Windows11下wsl闪退的解决
wsl闪退 1. 原因分析 解释:WSL(Windows Subsystem for Linux)闪退通常指的是在Windows操作系统中运行的Linux环境突然关闭。这可能是由于多种原因造成的,包括系统资源不足、WSL配置问题、兼容性问题或者是Linux内核的问题。&…...

通过调整JVM的默认内存配置来解决内存溢出(OutOfMemoryError)或栈溢出(StackOverflowError)等错误
文章目录 引言I 调整JVM的默认堆内存配置java命令启动jar包Tomcat服务器部署java应用引言 问题: org.springframework.web.util.estedServletException: Handlerdispatch failed: nested exception isjava.lang.0utOfMemoryError: Java heap space原因分析: 查询查询平台所…...

RCE---eval长度限制绕过技巧
目录 题目源码 方法一:命令执行的利用 方法二:file_put_contents(本地文件包含的利用) 方法三:usort(…$_GET); 题目源码 <?php $param $_REQUEST[param]; if(strlen($param)<17 && stripos($par…...
- 算法库 - 类似 std::accumulate,但不依序执行 -(std::reduce))
C++11标准模板(STL)- 算法库 - 类似 std::accumulate,但不依序执行 -(std::reduce)
算法库 算法库提供大量用途的函数(例如查找、排序、计数、操作),它们在元素范围上操作。注意范围定义为 [first, last) ,其中 last 指代要查询或修改的最后元素的后一个元素。 类似 std::accumulate,但不依序执行 std…...

反射机制的介绍
什么是反射 Java反射机制是Java语言一个很重要的特性,它使得Java具有了“动态性”。在Java程序运行时,对于任意的一个类,我们能不能知道这个类有哪些属性和方法呢?对于任意的一个对象,我们又能不能调用它任意的方法&a…...

AI图文带货,手把手教学,傻瓜操作,轻松日入500+,小白教程
通过自媒体的力量,帮助普通人成为企业家。 建立自己的财富事业,用你的影响力帮助更多的人。 从而实现你更加自由的生活方式。 记住关注我,不要错过每一次分享。 对标账号 作为公司的一个项目实际拆解者,最热门的项目怎么能不拆…...

java:实现简单的验证码功能
效果 实现思路 验证码图片的url由后端的一个Controller生成,前端请求这个Controller接口的时候根据当前时间生成一个uuid,并把这个uuid在前端使用localStorage缓存起来,下一次还是从缓存中获取。 Controller生成验证码之后,把前…...

MybatisPlus使用指南
MybatisPlus 1. 快速入门1.1 入门案例1.2 常见注解1.3 常见配置 2. 核心功能2.1 条件构造器2.2 自定义SQL2.3 Service接口 3. 扩展功能3.1 代码生成3.2 静态工具3.3 逻辑删除 4. 插件功能4.1 分页插件4.2 通用分页实体 1. 快速入门 1.1 入门案例 步骤一:引入Mybat…...

5. MongoDB 集合创建、更新、删除
1. 创建集合 1.1 语法 db.createCollection(name, options) 参数说明: name: 要创建的集合名称。options: 可选参数, 指定有关内存大小及索引的选项。 options 可以是如下参数: 参数名类型描述示例值capped布尔值是否创建一个固定大小的集合。truesize…...

PHP中如何将变量从函数传递给acf_add_filter
在PHP开发中,我们有时需要将变量从函数传递给acf的add_filter钩子。这样做可以让我们在acf字段加载时,对字段值进行动态修改。下面,我将详细介绍如何实现这一功能。 在acf中,我们使用add_filter来添加钩子,对字段的加…...

KNN算法的使用
目录 一、KNN 算法简介 二、KNN算法的使用 1.读取数据 2.处理数据 三、训练模型 1.导入KNN模块 2.训练模型 3.出厂前测试 四、进行测试 1.处理数据 2.进行测试 总结 一、KNN 算法简介 KNN 是一种基于实例的学习算法。它通过比较样本之间的距离来进行预测。算法的核心…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...