图像文本擦除无痕迹!复旦提出EAFormer:最新场景文本分割新SOTA!(ECCV`24)

文章链接:https://arxiv.org/pdf/2407.17020
git链接:https://hyangyu.github.io/EAFormer/
亮点直击
- 为了在文本边缘区域实现更好的分割性能,本文提出了边缘感知Transformer(EAFormer),该方法明确预测文本边缘,并利用这些边缘来引导后续的编码器。
- 针对COCO_TS和MLT_S数据集的注释质量较低的问题,对这些数据集进行了重新标注,以提高EAFormer在这两个数据集上的实验结果的可靠性。
- 在六个场景文本分割基准上的广泛实验表明,所提出的EAFormer能够达到最先进的性能,尤其在文本边缘区域表现更佳。
场景文本分割旨在从场景图像中裁剪文本,这通常用于帮助生成模型编辑或去除文本。现有的文本分割方法通常涉及各种文本相关的监督以获得更好的性能。然而,大多数方法忽略了文本边缘的重要性,而文本边缘对下游应用至关重要。本文提出了边缘感知Transformer(Edge-Aware Transformers),简称EAFormer,以更准确地分割文本,特别是文本的边缘。
具体而言,首先设计了一个文本边缘提取器,以检测边缘并滤除非文本区域的边缘。然后,提出了一个边缘引导编码器,使模型更加关注文本边缘。最后,采用了一个基于MLP的解码器来预测文本mask。在常用基准上进行了广泛的实验,以验证EAFormer的有效性。实验结果表明,所提出的方法在文本边缘的分割上优于以前的方法。考虑到一些基准数据集(如COCO_TS和MLT_S)的注释不够准确,无法公平评估本文的方法,重新标注了这些数据集。通过实验观察到,当使用更准确的注释进行训练时,本文的方法能够获得更高的性能提升。
方法
本节详细介绍了所提出的EAFormer。首先,介绍EAFormer的提出动机。然后,详细说明EAFormer的每个模块,包括文本边缘提取器、边缘引导编码器和文本分割解码器。最后,介绍了本文方法的损失函数。
动机
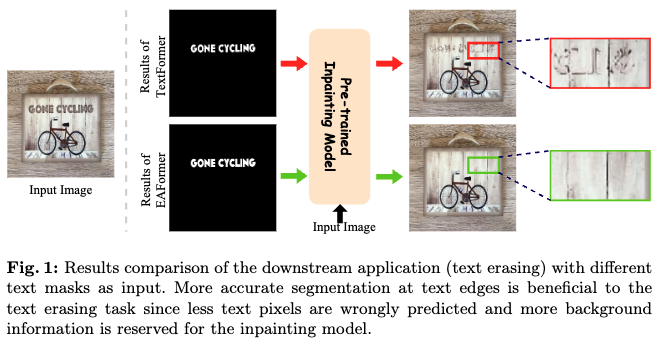
不可否认,文本边缘对场景文本分割任务至关重要,尤其是对于其下游任务如文本擦除。准确分割文本边缘可以为文本擦除模型提供更多的背景信息,以填补文本区域。如下图1所示,利用一个预训练的修复模型,输入不同类型的文本mask,以在场景图像中擦除文本。通过实验观察到,文本边界框mask过于粗糙,无法为修复模型提供更多的背景信息。此外,边缘分割不准确的文本mask使得修复模型错误地将属于文本的像素视为背景,导致擦除效果不佳。只有提供具有准确边缘分割的文本mask时,修复模型才能生成令人满意的文本擦除结果。
尽管PGTSNet已经意识到文本边缘的重要性,并使用了二元交叉熵损失来检测文本边缘的像素,但它未能明确地将易于获取的文本边缘信息作为输入信息之一。为了验证其感知文本边缘的能力,对主干网络输出的特征进行了K均值聚类,其中K设置为3,分别代表背景、文本边缘和文本中心。通过下图2中的可视化结果,观察到该方法在感知文本边缘方面仍存在一定的不足。

此外,研究者们发现传统的边缘检测算法可以获得准确的文本边缘,这可能有助于场景文本分割任务。然而,由于传统的边缘检测方法无法区分文本区域和非文本区域,因此大多数边缘都被检测到了非文本区域。如果直接将边缘检测结果作为输入来辅助文本分割,可能会使文本分割模型产生混淆,从而对其性能产生不利影响。
边缘感知Transformer(EAFormer)
如下图3所示,所提出的EAFormer由三个模块组成:文本边缘提取器、边缘引导编码器和文本分割解码器。给定输入的场景文本图像 X ∈ R 3 × H × W X \in \mathbb{R}^{3 \times H \times W} X∈R3×H×W,文本边缘提取器用于获得文本区域的边缘 E t E_t Et。然后,文本图像 X X X 和检测到的文本边缘 E t E_t Et 被输入到边缘引导编码器中,以提取边缘感知特征。最后,文本分割解码器以编码器生成的特征作为输入,生成相应的文本mask M t M_t Mt。

文本边缘提取器。 由于文本边缘对场景文本分割任务至关重要,研究者们提出了一个文本边缘提取器以获得文本区域的边缘。首先,使用传统的边缘检测算法Canny来获取整个输入图像的边缘 E w E_w Ew。如前所述, E w E_w Ew 中的非文本区域的边缘可能对文本分割产生负面影响。因此,在文本边缘提取器中引入了一个轻量级的文本检测模型来执行边缘过滤。具体而言,首先使用类似ResNet的[16] 主干网络提取多级视觉特征 F d = { F 1 d , F 2 d , F 3 d , F 4 d } F^d = \{F^d_1, F^d_2, F^d_3, F^d_4\} Fd={F1d,F2d,F3d,F4d},其中 $F^d_i \in \mathbb{R}^{C_i \times H_i \times W_i} $表示ResNet-like主干网络第 i i i-层的特征(有关文本检测主干网络的更多细节介绍见补充材料)。然后,采用文本检测头来预测文本区域的mask M a M_a Ma,可以表示为

其中, Conv 1 × 1 ( ⋅ ) \text{Conv}_{1 \times 1}(\cdot) Conv1×1(⋅) 和 Concat ( ⋅ ) \text{Concat}(\cdot) Concat(⋅) 分别表示1 × 1卷积层和拼接操作。借助文本区域的mask $M_a $,可以通过对文本区域mask M a M_a Ma 和检测到的边缘 E w E_w Ew 进行逐像素相乘,过滤掉非文本区域的边缘。因此,文本区域的边缘 E t E_t Et 可以通过以下方式获得:

值得一提的是,在进行乘法操作之前对 E w E_w Ew施加了软argmax操作,因为联合优化文本检测和分割分支可以实现更好的文本检测性能。然后,经过过滤的文本边缘 E t E_t Et 被输入到接下来的边缘引导编码器中,以增强其区分文本边缘周围像素的能力。
边缘引导编码器。 由于SegFormer在语义分割中表现出色,采用它作为边缘引导编码器的基础框架。如前面图3所示,边缘引导编码器由四个阶段组成,过滤后的文本边缘在第一个阶段被合并。每个编码阶段包含三个子模块:重叠补丁embedding、有效自注意力和前馈网络。重叠补丁embedding用于提取每个补丁周围的局部特征。随后,这些特征被输入到自注意力层中,以挖掘像素之间的相关性。基本自注意力层的公式如下:

其中, Q Q Q、 K K K 和 V V V 是通过对相同特征应用不同的embedding层获得的。为了减少计算成本,遵循 [43] 引入了空间降维操作来处理 K K K 和 V V V。有关空间降维的更多细节见补充材料。最后,对于第 i i i 阶段,使用前馈网络生成输出特征 F i s F^s_i Fis。与此不同的是,在第一个阶段的前馈网络之后额外引入了一个对称交叉注意力层,以融合提取的边缘引导 E t E_t Et。具体而言,对称交叉注意力层包括两个交叉注意力操作,分别在第一个阶段的特征 F 1 s F^s_1 F1s和边缘引导 E t E_t Et 之间进行。一方面, E t E_t Et 被视为查询(Query),以提取边缘感知的视觉信息 F e v F^{ev} Fev,其中 F 1 s F^s_1 F1s 被视为键(Key)和值(Value);另一方面, F 1 s F^s_1 F1s 被用作查询(Query),进一步挖掘有用的文本边缘信息 F t e F^{te} Fte,其中 E t E_t Et 被视为键(Key)和值(Value)。
因此,第一个阶段的最终输出 F ^ 1 s \hat{F}^s_1 F^1s 可以表示为:

其中, SA ( ⋅ ) \text{SA}(\cdot) SA(⋅) 代表上述的自注意力操作, ⊕ \oplus ⊕ 表示逐像素相加。随后, F ^ 1 s \hat{F}^s_1 F^1s和其他阶段的输出被输入到文本分割解码器中。
文本分割解码器。 类似于之前的方法,采用几个MLP层来融合特征并预测最终的文本mask M t M_t Mt。首先,通过相应的MLP层统一四个阶段输出的通道维度。然后,这些特征被上采样到相同的分辨率,并通过一个MLP层进一步融合。最后,融合后的特征用于预测文本mask。假设第 i i i 阶段特征的分辨率为 H i × W i × C i H_i \times W_i \times C_i Hi×Wi×Ci,解码过程可以表示为:

其中, MLP ( C in , C out ) ( ⋅ ) \text{MLP}(\text{C}_{\text{in}}, \text{C}_{\text{out}})(\cdot) MLP(Cin,Cout)(⋅)表示MLP中输入特征和输出特征的通道数分别为 C in \text{C}_{\text{in}} Cin 和 C out \text{C}_{\text{out}} Cout。 Fuse ( ⋅ ) \text{Fuse}(\cdot) Fuse(⋅)表示输入特征首先被拼接在一起,然后通过MLP层在通道维度上进行降维。
损失函数
以前的文本分割方法通常引入各种损失函数来提高性能,这可能会带来选择适当超参数的困难。在所提出的EAFormer中,仅使用了两种交叉熵损失:文本检测损失 L det L_{\text{det}} Ldet 和文本分割损失 L seg L_{\text{seg}} Lseg 进行优化,它们可以表示为:

其中, λ \lambda λ 是用于平衡 L det L_{\text{det}} Ldet 和 L seg L_{\text{seg}} Lseg 的超参数; M ^ a \hat{M}_a M^a 和 M ^ t \hat{M}_t M^t 分别是 M a M_a Ma 和 M t M_t Mt 的真实标注。请注意,用于 M a M_a Ma 的边界框级别监督可以从语义级别的标注中获得,这意味着所提出的方法与之前的方法一样,仅需要语义级别的标注。
实验
实施细节
所提出的方法使用PyTorch实现,所有实验都在8个NVIDIA RTX 4090 GPU上进行。采用AdamW优化器,所有实验中的初始学习率设置为 6 × 1 0 − 5 6 \times 10^{-5} 6×10−5,权重衰减设为0.01。批量大小设置为4。与之前的方法 [32,41,45] 一样,在训练阶段也采用了一些数据增强操作,如随机裁剪和翻转。不同于现有方法使用预训练模型来检测文本区域或识别字符,所提出的EAFormer中的所有模块都是联合训练的。换句话说,训练EAFormer时没有使用额外的数据集。Canny边缘检测的两个阈值分别设置为100和200。为了评估所提出方法的性能,同时使用前景交并比(fgIoU)和前景像素F值。fgIoU的度量标准采用百分比格式,F值采用小数格式。
实验结果
定量比较。 为了全面评估EAFormer,研究者们在英文和双语文本分割数据集上进行了实验。下表2显示了在五个英文文本分割数据集上的实验结果。

与之前的方法相比,EAFormer在大多数基准测试中在前景交并比(fgIoU)和F值上都有明显的提升。例如,在TextSeg数据集上,EAFormer在fgIoU和F值上分别超越了之前的SOTA方法TextFormer 0.64% 和0.6%。尽管原始的COCO_TS和MLT_S数据集有粗糙的注释,所提出的EAFormer仍然能表现出更好的性能,例如在COCO_TS数据集上比 TFT 提升了7.63%的fgIoU。考虑到基于不准确注释的实验结果不够令人信服,重新标注了COCO_TS和MLT_S的训练数据集和测试数据集。基于重新标注的数据集的实验结果显示在下表3中。实验表明,当使用注释更准确的数据集进行训练和测试时,EAFormer仍然能够实现显著的性能提升。与原始数据集的结果相比,重新标注数据集上的性能似乎下降了很多。

以下两个原因可能解释了这一现象:
- 数据集中有许多模糊的文本,这确实给模型处理文本边缘带来了挑战;
- 重新标注的测试数据集更为准确,评估中没有忽略的区域。
此外,还在双语文本分割数据集BTS上进行了实验,结果显示在下表4中。尽管PGTSNet不公平地引入了一个预训练的文本检测器,EAFormer在fgIoU/F值上仍然能实现1.6%/2.8%的提升,这验证了所提出方法的有效性。由于引入了一个轻量级的文本检测头,不可避免地增加了更多参数。评估了参数数量和推理速度。与之前的SOTA方法TextFormer(85M参数和每张图像0.42秒)相比,所提出的模型有92M参数,平均每张图像需要0.47秒。虽然参数数量略有增加,但本文的方法仍能显著提升性能。

定性比较。 研究者们还通过可视化将EAFormer与之前的方法在分割质量上进行了比较。如图5所示,所提出的EAFormer在文本边缘的表现优于之前的方法,这得益于引入的边缘信息。此外,对于COCO_TS和MLT_S,比较了基于原始和修改后注释的分割结果。尽管上表3表明,当使用重新标注的数据集进行训练和测试时,本文的方法性能有所下降,但下图5中的可视化结果表明,本文的模型在重新标注的数据集上能够实现更好的分割结果。

消融研究
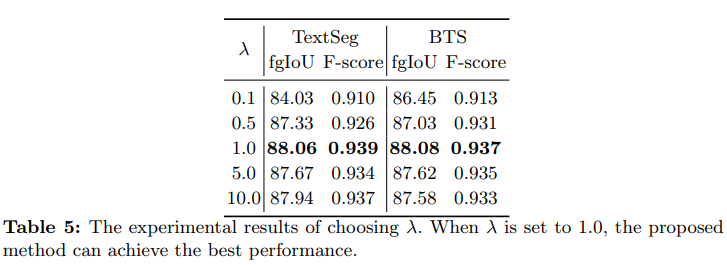
超参数 λ \lambda λ。 在训练EAFormer时,使用了两种损失函数进行优化。超参数 λ \lambda λ 用于平衡 L det L_{\text{det}} Ldet 和 L seg L_{\text{seg}} Lseg 的权重,适当的 λ \lambda λ 可能会带来更好的性能。因此,进行了几次实验来选择 λ \lambda λ,范围为 {0.1, 0.5, 1.0, 5.0, 10.0},实验结果见下表5。当 λ \lambda λ 设置为1.0时,EAFormer在TextSeg数据集上达到了最佳性能,相比于基线模型,其fgIoU/F值分别提高了3.47% 和2.3%。表5的结果表明,当 λ \lambda λ 范围在 {0.5, 1.0, 5.0, 10.0} 时,对性能的影响较小。然而,如果 λ \lambda λ 设置为0.1,则EAFormer的性能不佳,这可能是由于过小的 λ \lambda λ 使得文本检测模块难以收敛,从而进一步影响文本分割的性能。因此,在本文中,将 λ \lambda λ 设置为1.0。
边缘过滤和边缘引导。 在所提出的EAFormer中,文本边缘提取器中的边缘过滤和边缘引导编码器中的边缘引导是两个关键组件。为了评估这两种策略的性能提升效果,进行了消融实验,结果见下表6。请注意,当仅使用边缘过滤时,提取的边缘信息与输入图像拼接后输入到基于SegFormer的编码器中。如表6所示,引入边缘过滤可以显著提升性能。然而,如果仅引入边缘引导,本文的方法性能较差。一个可能的原因是非文本区域的边缘引入了更多的干扰信息,导致模型无法有效利用提取的边缘来辅助文本分割。因此,边缘过滤和边缘引导对本文的方法都是必要的,当两者都被采用时,EAFormer能够实现SOTA性能。

讨论
过滤非文本区域的边缘。 在文本边缘提取器模块中,提出了过滤非文本区域边缘信息的方法,以避免这些信息对模型性能的负面影响。在消融实验部分中,可以得知,过滤非文本区域的边缘信息可以明显提高性能。通过可视化(见补充材料),观察到,当所有边缘信息用于辅助分割时,模型会错误地认为具有边缘信息的区域应该被分类为前景。因此,为了给模型提供明确的边缘引导,所提出的方法仅保留文本区域的边缘信息作为输入。
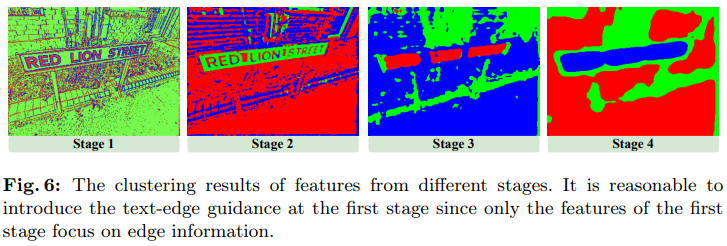
在不同层引入文本边缘。 在边缘引导编码器中,通过对称交叉注意机制仅在第一阶段提取增强的边缘特征信息。众所周知,低层特征对文本边缘信息更为敏感。在下图6中对不同阶段的特征进行聚类结果的可视化,结果表明只有第一阶段的特征关注边缘信息。因此,在早期阶段引入检测到的边缘是合理且有效的。还尝试在其他阶段引入边缘引导进行实验。实验结果表明,检测到的边缘引入的阶段越高,EAFormer的性能提升越小。特别是,当在第三或第四阶段引入检测到的边缘时,EAFormer的性能甚至低于基线。
利用现成的文本检测器。 在文本边缘提取器中,采用了一个轻量级的文本检测器,包括一个基于ResNet的骨干网络和一个MLP解码器。实际上,可以利用一个在文本检测数据集上预训练的现成文本检测器,这可以帮助EAFormer在实际应用中取得更好的性能。由于这可能对之前的方法不公平,只探讨了EAFormer的性能上限。在实验中,使用预训练的DBNet 替换轻量级文本检测器模块,EAFormer在TextSeg上的性能可以达到新的SOTA水平(fgIoU/F值分别为90.16%和95.2%)。
与之前边缘引导方法的区别。 实际上,将边缘信息融入分割中是一个被广泛探索的策略。然而,本文的方法与之前的工作仍有一些区别。首先,BCANet和 BSNet需要边缘监督,而本文的方法直接使用Canny提取边缘。尽管EGCAN也使用Canny,但本文的方法额外引入了边缘过滤以保留有用的边缘信息,这特别为文本分割设计。此外,EGCAN在所有编码器层中融合边缘信息,而本文的方法通过设计的对称交叉注意机制仅在第一层融合边缘信息。
局限性。 为了过滤非文本区域的边缘,引入了一个轻量级的文本检测器,这可能会略微增加可学习参数的数量。此外,仅利用了现成的边缘检测算法Canny来提取文本边缘,而没有使用更先进的深度学习边缘检测方法。引入SOTA边缘检测方法可能会进一步提高本文方法的性能。
结论
本文提出了边缘感知Transformer(Edge-Aware Transformers),称为EAFormer,以解决文本边缘处文本分割不准确的问题。具体而言,采用传统的边缘检测算法Canny来提取边缘。为了避免涉及非文本区域的边缘,引入了一个轻量级文本检测模块,用于过滤掉无用的边缘,以进行文本分割。此外,基于SegFormer,提出了一个边缘引导编码器,以增强其感知文本边缘的能力。考虑到某些数据集的低质量注释可能影响实验结果的可信度,对这些数据集进行了重新标注。在公开可用的基准测试上进行了广泛的实验,SOTA结果验证了EAFormer在文本分割任务中的有效性。
参考文献
[1]EAFormer: Scene Text Segmentation with Edge-Aware Transformers
相关文章:
图像文本擦除无痕迹!复旦提出EAFormer:最新场景文本分割新SOTA!(ECCV`24)
文章链接:https://arxiv.org/pdf/2407.17020 git链接:https://hyangyu.github.io/EAFormer/ 亮点直击 为了在文本边缘区域实现更好的分割性能,本文提出了边缘感知Transformer(EAFormer),该方法明确预测文…...

Codeforces Round 966 (Div. 3)(A,B,C,D,E,F)
A. Primary Task 签到 void solve() {string s;cin>>s;bool bltrue;if(s.size()<2)blfalse;else{if(s.substr(0,2)"10"){if(s[2]0)blfalse;else if(s[2]1&&s.size()<3)blfalse; }else blfalse;}if(bl)cout<<"YES\n";else cout…...

【代码随想录算法训练营第42期 第六天 | LeetCode242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和】
代码随想录算法训练营第42期 第六天 | LeetCode242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和 一、242.有效的字母异位词 解题代码C: bool isAnagram(char* s, char* t) {int len1 strlen(s);int len2 strlen(t);int al[26] {0};int b…...

WebRTC音视频开发读书笔记(一)
一、基本概念 WebRTC(Web Real-Time Communication,网页即时通信)于2011年6月1日开源,并被纳入万维网联盟的W3C推荐标准,它通过简单API为浏览器和移动应用提供实时通信RTC功能。 1、特点 跨平台:可以在Web,Android、…...

llama3.1本地部署方式
llama3.1 资源消耗情况 Llama 3.1 - 405B、70B 和 8B 的多语言与长上下文能力解析  70B版本,FP1616K token需要的资源约为75G;FP16128K token需要的资源约为110G  1、ollama ollama工具部署及使用…...
——色差仪颜色观察者视角)
相机光学(三十四)——色差仪颜色观察者视角
1.为什么会有观察者视角 颜色观察角度主要涉及到人眼观察物体时,视角的大小以及屏幕显示颜色的方向性对颜色感知的影响。 人眼观察物体的视角:在黑暗条件下,人眼主要依靠杆体细胞来分辨物体的轮廓,而杆体细胞分布在视网…...

思二勋:web3.0是打造应对复杂市场敏捷组织的关键
本文内容摘自思二勋所著的《分布式商业生态战略》一书。 数字化时代,需要企业具备敏捷应对变化的能力,以敏捷反应应对客户和市场的迅速变化。敏捷能力的建设需要触点网络、信息系统、IT 架构、业务流程等同时实现敏捷。尤其是在多变且复杂环境中,特别要求战略管理的敏捷性和…...

一文带你快速了解——HAProxy负载均衡
一、HAProxy简介 1.1、什么是Haproxy HAProxy是法国开发者 威利塔罗(Willy Tarreau)在2000年使用C语言开发的一个开源软件是一款具备高并发(万级以上)、高性能的TCP和HTTP负载均衡器支持基于cookie的持久性,自动故障切换,支持正则表达式及web状态统计。…...

【C++高阶】哈希—— 位图 | 布隆过滤器 | 哈希切分
✨ 人生如梦,朝露夕花,宛若泡影 🌏 📃个人主页:island1314 🔥个人专栏:C学习 ⛺️ 欢迎关注:👍点赞 👂&am…...
启发式算法之模拟退火算法
文章目录 1. 模拟退火算法概述1.1 算法起源与发展1.2 算法基本原理 2. 算法实现步骤2.1 初始化过程2.2 迭代与降温策略 3. 模拟退火算法的优化策略3.1 冷却进度表的设计3.2 参数调整与策略 4. 模拟退火算法的应用领域4.1 组合优化问题4.1.1 旅行商问题(TSPÿ…...

编码器汇总:光学编码器,霍尔编码器,磁性编码器,电容式编码器,单圈编码器,多圈编码器,增量式编码器,绝对值式编码器等
系列文章目录 1.元件基础 2.电路设计 3.PCB设计 4.元件焊接 5.板子调试 6.程序设计 7.算法学习 8.编写exe 9.检测标准 10.项目举例 11.职业规划 文章目录 前言一、光学编码器二、霍尔编码器三、磁性编码器四、电容式编码器五、单圈编码器六、多圈编码器七、增量式编码器八、…...

有哪些性价比高的蓝牙耳机可入?四款百万好评实力品牌推荐!
蓝牙耳机大家都再熟悉不过了,作为最常用的智能配件之一,谁还没有用过几款蓝牙耳机呢,但是选购蓝牙耳机上还是有一些需要注意的地方,市面上的吹风机可谓是五花八门。有哪些性价比高的蓝牙耳机可入?本人花了一些时间整理…...
)
MySQL数据库——表的CURD(Update)
3.Update 语法:update table_name set column expr 案例 将孙悟空的数学成绩变更为80 mysql> select name,math from result; ----------------- | name | math | ----------------- | 唐三藏 | 98 | | 孙悟空 | 78 | | 猪悟能 | 98 |…...

性能测试 —— linux服务器搭建JMeter+Grafana+Influxdb监控可视化平台!
前言 在当前激烈的市场竞争中,创新和效率成为企业发展的核心要素之一。在这种背景下,如何保证产品和服务的稳定性、可靠性以及高效性就显得尤为重要。 而在软件开发过程中,性能测试是一项不可或缺的环节,它可以有效的评估一个系…...

python基础命令学习
1.Python基础知识 目录 1.Python基础知识1.1 变量及类型1.2 标识符与关键字1.3 输出与输入1.3.1格式化符号1.3.2转义字符1.3.3结束符1.3.4输入的特点 1.4 运算符1.4.1 算数运算符1.4.2 赋值运算符1.4.3 比较(即关系)运算符1.4.4 逻辑运算符 1.5 数据类型转换1.6 判断与循环语句…...
)
程序设计基础(试题及答案)
一、填空题 1.__ ____函数是程序启动时惟一的入口。 2.算法的复杂性包含两方面: 和 。 3.已知 char c= a ; int x=2,k; 执行语句k=c&&x++ ; 则x为 ,k为 。 4.数值0x34对应的十进制为 。 5…...

日常收录资源
日常收录资源 工具类绘图浏览器插件 软件类DockerGoJavaJavaScriptSpring Boot架构计算机网络算法其他 设计类配色素材图标图片 工具类 绘图 ProcessOnGitMind 浏览器插件 ColorPick Eyedropper:取色器 软件类 Docker Docker - 从入门到实践 Go Golang tuto…...

索引——电子学
电子学 教程 2N2222简介及用Arduino模拟 创意电子学:第000课——注册Tinkercad 网站账号 创意电子学-第01课:点亮LED 创意电子-第05课:串联和并联 创意电子学-第04课:使用欧姆定律 创意电子学-第03课:初学者如何…...

【学习笔记】A2X通信的协议(九)- 广播远程ID(BRID)
3GPP TS 24.577 V18.1.0的技术规范,主要定义了5G系统中A2X通信的协议方面,特别是在PC5接口和Uu接口上的A2X服务。以下是文件的核心内容分析: 7. 广播远程ID(BRID) 7.1 概述 本条款描述了以下程序: 在用…...
HoloLens 和 Unity 空间坐标系统
所有的 3D 图形应用程序都使用笛卡尔坐标系统来推理虚拟物体的位置和朝向。 这些坐标系建立三个垂直轴:X、Y 和 Z。 添加到场景的每个对象在其坐标系中都有一个 XYZ 位置。 Windows 调用在物理世界中具有实际意义的坐标系统,该系统以米为单位表示其坐…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...