【Python快速入门和实践013】Python常用脚本-目标检测之按照类别数量划分数据集
一、功能介绍
这段代码实现了从给定的图像和标签文件夹中分割数据集为训练集、验证集和测试集的功能。以下是代码功能的总结:
-
创建目标文件夹结构:
- 在指定的根目录(
dataset_root)下创建images和labels两个文件夹。 - 在这两个文件夹下分别创建
train、val和test三个子文件夹,用于存放不同阶段的数据。
- 在指定的根目录(
-
统计类别数量:
- 遍历标签文件夹中的所有文本文件,统计每个类别在所有标签文件中出现的总次数。
-
计算分割比例:
- 根据给定的比例(默认为训练集80%,验证集10%,测试集10%),计算每个类别在训练集、验证集和测试集中应该有的数量。
-
随机分配数据:
- 遍历图像文件夹中的所有图片。
- 对于每个图片,检查其对应的标签文件是否存在。
- 读取标签文件,提取其中的类别信息。
- 根据随机数决定图片属于训练集、验证集还是测试集。
- 将图片和对应的标签文件复制到相应的文件夹中,同时更新类别数量记录。
-
最终结果:
- 数据集按照指定的比例被划分为训练集、验证集和测试集。
- 每个类别在各个数据集中的分布尽量保持均衡。
二、代码
import os
import random
import shutildef split_dataset(image_folder, label_folder, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1):"""将图像和标签文件按指定比例分割成训练集、验证集和测试集。参数:image_folder (str): 图像文件夹路径。label_folder (str): 标签文件夹路径。train_ratio (float): 训练集所占比例,默认为0.8。val_ratio (float): 验证集所占比例,默认为0.1。test_ratio (float): 测试集所占比例,默认为0.1。"""# 创建目标文件夹dataset_root = r'E:\pythonProject\pythonProject\after_neu'os.makedirs(dataset_root, exist_ok=True)# 创建images和labels文件夹images_folder = os.path.join(dataset_root, 'images')labels_folder = os.path.join(dataset_root, 'labels')os.makedirs(images_folder, exist_ok=True)os.makedirs(labels_folder, exist_ok=True)# 创建train、val和test子文件夹for split in ['train', 'val', 'test']:os.makedirs(os.path.join(images_folder, split), exist_ok=True)os.makedirs(os.path.join(labels_folder, split), exist_ok=True)# 统计每个类别的图片数量category_counts = {}for filename in os.listdir(label_folder):label_path = os.path.join(label_folder, filename)with open(label_path, 'r') as label_file:lines = label_file.readlines()categories = [line.split()[0] for line in lines]for category in categories:category_counts[category] = category_counts.get(category, 0) + 1# 计算每个类别在训练集、验证集和测试集中的数量train_category_counts = {}val_category_counts = {}test_category_counts = {}for category, count in category_counts.items():train_count = int(count * train_ratio)val_count = int(count * val_ratio)test_count = count - train_count - val_counttrain_category_counts[category] = train_countval_category_counts[category] = val_counttest_category_counts[category] = test_count# 遍历图片文件夹for filename in os.listdir(image_folder):image_path = os.path.join(image_folder, filename)label_path = os.path.join(label_folder, os.path.splitext(filename)[0] + '.txt')# 确保标注文件存在if not os.path.exists(label_path):continue# 读取标注文件获取类别信息with open(label_path, 'r') as label_file:lines = label_file.readlines()categories = [line.split()[0] for line in lines]# 确定将图片放入的集合rand = random.random()if rand < train_ratio:destination_folder = 'train'category_counts = train_category_countselif rand < train_ratio + val_ratio:destination_folder = 'val'category_counts = val_category_countselse:destination_folder = 'test'category_counts = test_category_counts# 移动图片和标注文件到目标文件夹for category in categories:category_folder_images = os.path.join(images_folder, destination_folder)category_folder_labels = os.path.join(labels_folder, destination_folder)os.makedirs(category_folder_images, exist_ok=True)os.makedirs(category_folder_labels, exist_ok=True)if category_counts[category] > 0:shutil.copy(image_path, os.path.join(category_folder_images, filename))shutil.copy(label_path, os.path.join(category_folder_labels, os.path.splitext(filename)[0] + '.txt'))category_counts[category] -= 1# 图片文件夹路径
image_folder = r'E:\pythonProject\pythonProject\NEU-DET\images'# 标注文件夹路径
label_folder = r'E:\pythonProject\pythonProject\NEU-DET\txt'# 调用函数进行数据集分割
split_dataset(image_folder, label_folder)这个数据集划分代码相比与其他的不是随机划分,考虑到每个类别的图片样张可能不均衡,所以按照类别去划分数据集。需要先把xml转成yolo的txt格式,然后指定图片、txt标签、保存文件夹路径即可。在NEU-DET数据集上运行结果如下:

相关文章:
【Python快速入门和实践013】Python常用脚本-目标检测之按照类别数量划分数据集
一、功能介绍 这段代码实现了从给定的图像和标签文件夹中分割数据集为训练集、验证集和测试集的功能。以下是代码功能的总结: 创建目标文件夹结构: 在指定的根目录(dataset_root)下创建images和labels两个文件夹。在这两个文件夹下…...

C++ Primer 总结索引 | 第十八章:用于大型程序的工具
1、大规模应用程序的特殊要求包括: 在独立开发的子系统之间 协同处理错误的能力使用各种库(可能包含独立开发的库)进行 协同开发的能力对比较复杂的应用 概念建模的能力 对应 异常处理、命名空间和多重继承 1、异常处理 1、异常处理机制 …...
图像修复算法)
Python实现GAN(生成对抗网络)图像修复算法
目录 1. GAN简介与图像修复2. PyTorch和CUDA简介3. 数据加载与预处理3.1 安装依赖3.2 数据加载3.3 数据遮挡4. 构建GAN图像修复模型4.1 生成器4.2 判别器5. 训练GAN模型5.1 损失函数与优化器5.2 训练循环6. 测7. 实现GUI进行图像修复8. 总结与扩展扩展方向:1. GAN简介与图像修…...

java语言中的websocket
你好!我是TensGPT,一个由TensGPT团队开发的AI助手。我可以帮助你了解和使用Java语言中的WebSocket。如果你有任何问题或需要示例代码,请告诉我。 ### 什么是WebSocket? WebSocket是一种在单个TCP连接上进行全双工通信的协议。它被…...

ASP.NET在线交流论坛管理系统
ASP.NET在线交流论坛管理系统 说明文档 运行前附加数据库.mdf(或sql生成数据库) 主要技术: 基于asp.net架构和sql server数据库 用户功能有个人信息管理 帖了信息管理 意见反馈信息管理 点赞管理 收藏管理 后台管理员可以进行用户管理 …...

【Kubernetes】身份认证与鉴权
一,认证 所有 Kubernetes 集群有两类用户:由Kubernetes管理的ServiceAccounts(服务账户)和(Users Accounts)普通账户。 两种账户的区别: 普通帐户是针对(人)用户的,服务账户针对Pod进程普通帐户是全局性。在集群所有namespaces…...
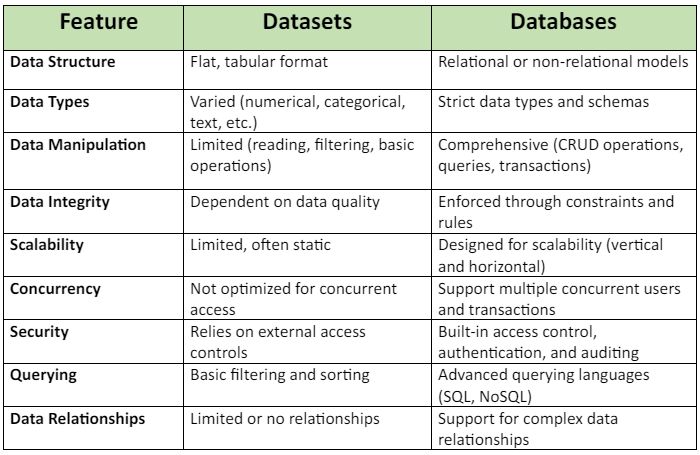
数据集与数据库:有什么区别?
数据集和数据库是我们在处理数据时经常听到的两个常用词。虽然它们听起来很相似,但它们具有不同的特征并用于不同的用途。本文深入探讨数据集和数据库之间的主要区别,探索了它们的结构、数据类型和各种其他功能,以帮助您做出明智的决定&#…...
BurpSuite
如果只能用一个Web渗透工具,我选BurpSuite。 Web应用程序(Web Application) 不同于传统的静态网站所有程序的特点是接收、处理用户输入并返回结果服务器端是个程序,需要程序代码实现业务功能(java、php、asp.nse&…...

NetApp数据恢复—NetApp存储误删除文件如何恢复数据?
NetApp数据恢复环境&故障: 某公司一台NetApp存储,该存储中有24块磁盘。 工作人员误删除了NetApp存储中一个文件夹,文件夹中有非常重要的数据。 数据恢复工程师在现场对该存储进行了初检。虽然这个文件夹被删除很长时间,但是根…...

基于springboot的医药管理系统
TOC springboot194基于springboot的医药管理系统 绪论 1.1 选题背景 当人们发现随着生产规模的不断扩大,人为计算方面才是一个巨大的短板,所以发明了各种计算设备,从结绳记事,到算筹,以及算盘,到如今的…...

Android中的EventBus的用法
1. EventBus简介 EventBus是一个优化了的事件发布/订阅模式实现的库,常用于Android程序组件间的通信。它可以简化不同组件之间的通信工作,避免复杂和耦合的依赖关系。EventBus通过事件驱动来降低代码耦合度,提高开发效率和代码清晰性。 2. …...
:数据库在数据处理中是如何利用缓存机制的)
梧桐数据库(WuTongDB):数据库在数据处理中是如何利用缓存机制的
数据库在数据处理中利用缓存机制主要是为了提高数据访问速度和系统性能。缓存机制通过将频繁访问的数据存储在内存中,减少了对磁盘I/O操作的需求,从而提高了数据查询的效率。以下是数据库利用缓存机制的一些主要方式: 1. 查询缓存࿰…...

C语言-数据类型
在x64编译器平台下,C语言数据类型的取值范围主要取决于数据类型的大小(即字节数)以及它们是有符号的还是无符号的。以下是根据常见实现总结的x64平台下C语言数据类型的取值范围: 整数类型 浮点类型 指针类型 在x64编译器平台下…...

左值引用、右值引用、移动构造
1、为啥使用引用? // An highlighted block void function(string str) {... ... }看上面这段代码,如果不采用引用的方法,那么在函数被调用的时候,编译器会有一个参数赋值的过程,这就导致了内存和效率的浪费。 // An…...

tekton通过ceph挂载node_modules的时候报错failed to execute command: copying dir: symlink
分析: 如果ceph的mountPath和workingDir路径一致的话,就会报错。 解决:node_modules挂载到/workspace下,workingDir的代码mv到/workspace下进行构建。...

Xil_DCacheFlushRange的用法
概述: 当使用Zynq的PS (Processing System) 与PL (Programmable Logic) 进行通信时,特别是涉及到高速数据传输时,可能会遇到缓存一致性问题。这是因为处理器系统通常具有缓存机制来加快对常用数据的访问速度,但在某些情况下&…...

k8s使用subpathexpr和hostpath分pod名字持久化日志
在k8s中,服务日志除了标准输出,还有写入日志文件,若要对这些日志文件进行持久化存储,无论是通过网络文件存储还是hostpath,都会面临一个问题,多个pod会往同一个存储目录的同一个文件进行写入,导…...

FChen的408学习日记--三次握手和四次握手
一、三次握手 在建立连接的过程中,首先SYN1,随机发送sqex。服务器接受后要反过来对客户端发送连接请求,SYN1,随机发送sqey,ackx1。然后客户端还要发送连接确认报文,原因如下 例题: 二、四次…...

Unity技巧:轻松实现鼠标悬停文本时的动态变色效果
文章目录 前言一、Text二、TMP_Text二、颜色转换总结 前言 在游戏或应用中,给用户的界面添加一些小的互动效果能让它们更加吸引人。比如,当策划要求你这样做的时候 ,当用户将鼠标悬停在文字上时,文字颜色改变,这样的效…...
谷歌账号活动异常,或者申诉回来以后需要手机验证的原因,以及验证手机号的错误操作和正确操作
有一些朋友在使用谷歌账号的时候,会遇到无法直接登录的情况,输入用户名、密码以后,提示说账号活动异常,需要验证手机号。 通常有以下两种情形和界面,出现这种情形的原因分别如下。 一、谷歌账号登录需要输入手机号码…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...