分析 avformat_open_input 数据读取过程
------------------------------------------------------------
author: hjjdebug
date: 2024年 08月 13日 星期二 17:31:43 CST
descriptor: 分析 avformat_open_input 数据读取过程
------------------------------------------------------------
avformat_open_input 中读取数据.
0 in read of libc 中的 read 函数入口.
1 in file_read of libavformat/file.c:114
2 in retry_transfer_wrapper of libavformat/avio.c:370
3 in ffurl_read of libavformat/avio.c:405
4 in read_packet_wrapper of libavformat/aviobuf.c:521
5 in fill_buffer of libavformat/aviobuf.c:570
6 in avio_read of libavformat/aviobuf.c:663
7 in av_probe_input_buffer2 of libavformat/format.c:262
8 in init_input of libavformat/utils.c:450
9 in avformat_open_input of libavformat/utils.c:548
10 in open_input_file of filtering_video.c:39
11 in main of filtering_video.c:212
第10层,11层是用户代码,就不用分析了,
测试代码是ffmpeg自带的Doc/example/filtering_video.c
avformat_open_input 函数打开一个本地文件必然要做的三件事情是
1. 打开文件
2. 读取数据
3. 分析数据.
本博客针对的是
2. 读取数据,
3.分析数据, 顺便提及了一下h264文件的头部读取,它很简单,就没有读数据,见后分析.
关于1.打开文件, 可参考 avformat_open_input 打开URL的流程-CSDN博客
所附代码是精简化后的代码,帮助理解.
汉字注释都是我的心得体会,都是关键点,就不用醒目标注了.
下面倒序分析:
第1层: file_read
----------------------------------------
输入参数: URLContext *h
输出参数: buf, size
返回值: 读取的字节数
功能: 从URLContext 中读取数据到buf
----------------------------------------
static int file_read(URLContext *h, unsigned char *buf, int size)
{
FileContext *c = h->priv_data;
size = FFMIN(size, c->blocksize); //size 是32768, c->blocksize是个很大的数
int ret = read(c->fd, buf, size); // libc 接口 read 函数
return (ret == -1) ? AVERROR(errno) : ret;
}
现在是面向对象编程了. 给你传个对象handle, 你要先从对象中取到FileContext ,再取到fd,
这才是保留的文件描述符号,于是就能用read 取到文件数据了.
第2层: retry_transfer_wrapper
-----------------------------------------------------------
输入参数: URLContext *h, transfer_func, size_min
输出参数: buf,size
返回值: 读取的字节数
功能: 从URLContext中,通过 transfer_func 读取数据到buf
-----------------------------------------------------------
为啥我的代码看起来如此简单, 嗯! 我去掉了一些出错判断,只保留了关键部分.
static inline int retry_transfer_wrapper(URLContext *h, uint8_t *buf,
int size, int size_min,
int (*transfer_func)(URLContext *h,
uint8_t *buf,
int size))
{
int len = 0;
while (len < size_min) {
int ret = transfer_func(h, buf + len, size - len); //这里的transfer_func是file_read
len += ret;
}
return len;
}
第3层: ffurl_read
------------------------------------------------------
输入参数: URLContext *h
输出参数: buf,size
返回值: 读取的字节数
功能: 从URLContext中,读取数据到buf
------------------------------------------------------
int ffurl_read(URLContext *h, unsigned char *buf, int size)
{
return retry_transfer_wrapper(h, buf, size, 1, h->prot->url_read);
}
它调用retry_transfer_wrapper,传入了读取函数h->prot-url_read 指针
这里出现了2个对象, URLContext , URLProtocol 对象
实例测试时size 为32768
第4层: read_packet_wrapper
------------------------------------------------------
输入参数: AVIOContext *s
输出参数: buf,size
返回值: 读取的字节数
功能: 从AVIOContext中,读取数据到buf
------------------------------------------------------
static int read_packet_wrapper(AVIOContext *s, uint8_t *buf, int size)
{
int ret = s->read_packet(s->opaque, buf, size);//这个s->read_packet就是ffurl_read
return ret;
}
这里出现了一个高层对象AVIOContext *s;
调用s->read_packet 函数,这个函数就是ffurl_read,
并且把s->opaque 传入,这个参数是URLContext 对象, 把数据读取到buf中,size 32768
看到这是否要气疯了?! 从文件读个数据怎么这么麻烦?
我们总结一下:
对象1: AVIOContext 对象 s
对象2: URLContext 对象 h, 其中 h=s->opaque
对象3: URLProtocol 对象,这里没有给名字,就叫h->prot
之所以搞这么复杂,是因为他要支持各种协议, 例如它给你一个udp://238.1.1.1:8000, 你照样
可以打开udp网络流取读,只不过它走的不是文件读而是udp的读了.
而且对象的函数指针,是软的!!! 付给它什么函数,它就可以调用什么函数.
对象包含对象.
s(AVIOContext)包含h(URLContext) h=s->opaque
h(URLContext)包含(FileContext) c=h->priv_data
c(FileContext)包含文件描述符 fd = c->fd
我们最后用fd 来读写文件.
这就是用对象分层的好处.或者复杂处,这样就知道为什么要一层一层来了.
第5层: fill_buffer
------------------------------------------------------
输入参数: AVIOContext *s
输出参数: 无
功能: 从AVIOContext中,读取数据到它自己的缓冲区
------------------------------------------------------
static void fill_buffer(AVIOContext *s)
{ //s->max_buffer_size 等于0, 所以最大缓冲size max_buffer_size 这里给IO_BUFFER_SIZE(32768)
int max_buffer_size = s->max_packet_size ?
s->max_packet_size : IO_BUFFER_SIZE;
// s->buffer_size 是32768, 这里确定是向哪里读数据,是s->buffer 还是s->buf_end
// 由于一般判断条件为假,所以会选择s->buffer,即缓冲头为目标
uint8_t *dst = s->buf_end - s->buffer + max_buffer_size <= s->buffer_size ?
s->buf_end : s->buffer;
int len = s->buffer_size - (dst - s->buffer);
len = read_packet_wrapper(s, dst, len); //调用上边分析过的函数
//根据返回的长度信息,更新AVIOContext 参数
if (len == AVERROR_EOF) {
s->eof_reached = 1;
} else if (len < 0) {
s->eof_reached = 1;
s->error= len;
} else {
s->pos += len;
s->buf_ptr = dst;
s->buf_end = dst + len;
s->bytes_read += len;
}
}
问: s->pos, s->bytes_read 有什么区别?
答:这里看不出区别,别处能看出来.
第6层: avio_read
------------------------------------------------------
输入参数: AVIOContext *s
输出参数: buf,size
返回值: 读取的字节数
功能: 从AVIOContext中,读取size个数据到buf中
------------------------------------------------------
int avio_read(AVIOContext *s, unsigned char *buf, int size)
{
int len, size1;
size1 = size;
while (size > 0) //读数据直到size=0
{
//缓存中有数据吗?
len = FFMIN(s->buf_end - s->buf_ptr, size);
if (len == 0 ) // 没有
{
fill_buffer(s); //填缓冲
len = s->buf_end - s->buf_ptr;
if (len == 0) break; //读不到数据就退出
}
else
{ //有数据,把缓冲的数据拷贝走
memcpy(buf, s->buf_ptr, len);
//更新输出指针
buf += len;
//更新缓存指针
s->buf_ptr += len;
//更新还需读取的长度
size -= len;
}
}
return size1 - size;
}
搞懂了代码,原来avio_read 是如此的简单,就是填充数据到buf.
测试的size 是2048
第7层: av_probe_input_buffer2
------------------------------------------------------------------
输入参数: AVIOContext *pb, filename,logctx,offset, max_probe_size
输出参数: AVInputFormat **fmt
返回值: 得分值,50以上为成功
功能: 从AVIOContext中,读取探测数据,分析文件格式并保存到fmt
------------------------------------------------------------------
offset: 要求探测数据需要跳过的偏移量,一般是0.
max_probe_size: 一般给0,由该函数定义
logctx: 打log时才会用到,
filename: 此处用途不大
AVIOContext *pb, 重要, 从该对象读取数据
int av_probe_input_buffer2(AVIOContext *pb, ff_const59 AVInputFormat **fmt,
const char *filename, void *logctx,
unsigned int offset, unsigned int max_probe_size)
{
AVProbeData pd = { filename ? filename : "" };
uint8_t *buf = NULL;
int ret = 0, probe_size, buf_offset = 0;
int score = 0;
if (!max_probe_size)
max_probe_size = PROBE_BUF_MAX; // 最大 1<<20
// 最小 2048, 每次增加1倍
for (probe_size = PROBE_BUF_MIN; probe_size <= max_probe_size && !*fmt;
probe_size = FFMIN(probe_size << 1, FFMAX(max_probe_size, probe_size + 1)))
{
score = probe_size < max_probe_size ? AVPROBE_SCORE_RETRY : 0;
//分配内存
if ((ret = av_reallocp(&buf, probe_size + AVPROBE_PADDING_SIZE)) < 0) goto fail;
ret = avio_read(pb, buf + buf_offset, probe_size - buf_offset);
buf_offset += ret;
if (buf_offset < offset) //读取的数据必需要大于offset
continue;
//确定探测数据的位置和大小
pd.buf_size = buf_offset - offset;
pd.buf = &buf[offset];
memset(pd.buf + pd.buf_size, 0, AVPROBE_PADDING_SIZE);
/* Guess file format. */
//由读取的探测数据,找到AVInputFormat 对象和得分值
*fmt = av_probe_input_format2(&pd, 1, &score); //具体探测过程是枚举,此处忽略
if (*fmt) { //成功
av_log(logctx, AV_LOG_DEBUG,
"Format %s probed with size=%d and score=%d\n",
(*fmt)->name, probe_size, score);
}
}
if (!*fmt)
ret = AVERROR_INVALIDDATA;
//把AVIOContext 数据指针回退buf_offset, 以便后边重用这段数据
int ret2 = ffio_rewind_with_probe_data(pb, &buf, buf_offset);
if (ret >= 0) ret = ret2;
return ret < 0 ? ret : score;
}
第8层: init_input
------------------------------------------------------------------
输入参数: AVFormatContext *s, filename,AVDictionary**options
输出参数: AVFormatContext s->iformat
返回值: 探测的得分值
功能: 打开文件,探测文件格式,赋值给s->iformat
------------------------------------------------------------------
/* Open input file and probe the format if necessary. */
//打开文件,探测文件格式
static int init_input(AVFormatContext *s, const char *filename,
AVDictionary **options)
{
int ret;
//该函数就是让s->pb 有值,创建AVIOContext 对象,鉴于篇幅,此处不具体分析,可参考
// avformat_open_input 打开URL的流程-CSDN博客
if ((ret = s->io_open(s, &s->pb, filename, AVIO_FLAG_READ | s->avio_flags, options)) < 0)
return ret;
return av_probe_input_buffer2(s->pb, &s->iformat, filename,
s, 0, s->format_probesize); // 上面的分析过程
}
第9层: avformat_open_input
------------------------------------------------------------------
输入参数: filename,AVDictionary**options, AVInputFormat *fmt
输出参数: AVFormatContext **ps
返回值: 0 成功
功能: 打开文件,探测文件格式,赋值给s, 分析文件头部,赋值给s
------------------------------------------------------------------
假设fmt=0; 输入格式需要探测
optionss=0; 没有选项要设置,简化逻辑
int avformat_open_input(AVFormatContext **ps, const char *filename,
ff_const59 AVInputFormat *fmt, AVDictionary **options)
{
int i, ret = 0;
AVDictionary *tmp = NULL;
ID3v2ExtraMeta *id3v2_extra_meta = NULL;
AVFormatContext *s = avformat_alloc_context();
if (!(s->url = av_strdup(filename ? filename : ""))) { }
if ((ret = init_input(s, filename, &tmp)) < 0) goto fail; //上边的分析过程,为s赋值iformat
s->probe_score = ret;
avio_skip(s->pb, s->skip_initial_bytes);
s->duration = s->start_time = AV_NOPTS_VALUE;
//分配私有数据
if (s->iformat->priv_data_size > 0) {
if (!(s->priv_data = av_mallocz(s->iformat->priv_data_size))) {
ret = AVERROR(ENOMEM);
goto fail;
}
//初始化私有对象
if (s->iformat->priv_class) {
*(const AVClass **) s->priv_data = s->iformat->priv_class;
av_opt_set_defaults(s->priv_data);
if ((ret = av_opt_set_dict(s->priv_data, &tmp)) < 0)
goto fail;
}
}
//关键函数,见补充1,指针函数调用了 ff_faw_video_read_header()
if ((ret = s->iformat->read_header(s)) < 0)
goto fail;
s->internal->data_offset = avio_tell(s->pb);
s->internal->raw_packet_buffer_remaining_size = RAW_PACKET_BUFFER_SIZE;
update_stream_avctx(s); //把流参数copy到 st->internal->avctx,见补充2
for (i = 0; i < s->nb_streams; i++)
s->streams[i]->internal->orig_codec_id = s->streams[i]->codecpar->codec_id;
if (options) {
av_dict_free(options);
*options = tmp;
}
*ps = s;
return 0;
}
------------------------------------------------------------------
补充1: ff_raw_video_read_header 函数
------------------------------------------------------------------
对于h264 读取头部信息, 它根本就没有读取数据, 而是直接创建了一个流就完事了.
当然这个视频流从AVFormatContext 会copy 一些信息, 但其它一些关键信息可能还只是默认值
要等avformat_find_stream_info()去填充
/* MPEG-1/H.263 input */
int ff_raw_video_read_header(AVFormatContext *s)
{
AVStream *st = avformat_new_stream(s, NULL);
st->codecpar->codec_type = AVMEDIA_TYPE_VIDEO;
st->codecpar->codec_id = s->iformat->raw_codec_id;
st->need_parsing = AVSTREAM_PARSE_FULL_RAW;
FFRawVideoDemuxerContext *s1 = s->priv_data;
st->internal->avctx->framerate = s1->framerate;
avpriv_set_pts_info(st, 64, 1, 1200000);
return 0;
}
------------------------------------------------------------------
补充2: update_stream_avctx 函数
------------------------------------------------------------------
功能: 把流参数copy到 st->internal->avctx
static int update_stream_avctx(AVFormatContext *s)
{
int i, ret;
for (i = 0; i < s->nb_streams; i++) { //h264就一个视频流
AVStream *st = s->streams[i];
if (!st->internal->need_context_update) continue;
/* close parser, because it depends on the codec */
if (st->parser && st->internal->avctx->codec_id != st->codecpar->codec_id) {
av_parser_close(st->parser);
st->parser = NULL;
}
/* update internal codec context, for the parser */
ret = avcodec_parameters_to_context(st->internal->avctx, st->codecpar);
if (ret < 0) return ret;
st->internal->need_context_update = 0;
}
return 0;
}
相关文章:

分析 avformat_open_input 数据读取过程
------------------------------------------------------------ author: hjjdebug date: 2024年 08月 13日 星期二 17:31:43 CST descriptor: 分析 avformat_open_input 数据读取过程 ------------------------------------------------------------ avformat_open_input 中读…...
 VS Data Integration (通常被称为 Kettle))
Apache HOP (Hop Orchestration Platform) VS Data Integration (通常被称为 Kettle)
Apache HOP (Hop Orchestration Platform) 和 Data Integration (通常被称为 Kettle) 都是强大的 ETL (Extract, Transform, Load) 工具, 它们都由 Hitachi Vantara 开发和支持。尽管它们有着相似的目标,即帮助用户进行数据集成任务,但它们在…...

如何判断一个dll/exe是32位还是64位
通过记事本判断(可判断C或者C#) 64位、将dll用记事本打开,可以看到一堆乱码,但是找到乱码行的第一个PE,如果后面是d?则为64位 32位、将dll用记事本打开,可以看到一堆乱码,但是找到乱码行的第…...

加速网页加载,提升用户体验:HTML、JS 和 Vue 项目优化全攻略
在信息爆炸的时代,网页加载速度成为了用户体验的重中之重。试想一下,如果一个页面加载超过 3 秒,你还有耐心等待吗? 为了留住用户,提升转化率,网页优化势在必行! 本文将从 HTML、JavaScript 和…...

LVS服务器基础环境配置
环境配置 1 基础服务关闭 setenforce 0 # 临时关闭selinuxvi /etc/sysconfig/selinux # 永久关闭selinuxsystemctl disable --now firewalld # 关闭防火墙systemctl disable --now NetworkManager # 关闭网络管理器2 centos7软件仓库的配置 mount /dev/cdrom /media以防万一&…...

【Python OpenCV】使用OpenCV实现两张图片拼接
问题引入: 如何使用Python OpenCV实现两张图片的水平拼接和垂直拼接 代码实现: import cv2 import numpy as npdef image_hstack(image_path_1, image_path_2):"""两张图片左右拼接"""img1 cv2.imread(image_path_1)img…...

springboot jar -jar centos后台运行的几种方式
在CentOS系统中,如果你想要在后台运行一个Spring Boot应用程序,你可以使用nohup命令或者使用screen会话。以下是两种常用的方法: 1. **使用nohup命令**: nohup命令可以使进程在你退出SSH会话后继续运行。它还会把标准输出和标…...

【GitLab】使用 Docker 安装 GitLab:配置 SSH 端口
使用 Docker 安装 GitLab 要求修改ssh端口 GitLab 使用 SSH 通过 SSH 与 Git 交互。默认情况下,GitLab 使用端口22。 要在使用 GitLab Docker 映像时使用其他端口,您可以执行以下操作之一: 更改服务器的 SSH 端口(推荐)。 更改 GitLab Shell SSH 端口。 更改服务器的 SSH …...

【pdf文件生成】如何将盖章的文件生成PDF文件
一、提出问题 在我们的工作中,有时候上级让下级将盖章的文件生成PDF文件通过内部平台发送到上级邮箱,那如何解决呢?是去找一个扫描仪,还是用手机拍图转。用Python基实就能实现。 二、分析问题 现在网上好多的软件都是收费的&am…...

铝壳电阻在电路中的作用和影响是什么?
铝壳电阻,顾名思义,就是用铝材料制成的电阻。在电路中,它主要起到限流、分压、负载等作用。下面详细介绍铝壳电阻在电路中的作用和影响。 1. 限流作用:铝壳电阻可以限制电流的大小,防止电流过大而损坏电路。当电路中的…...

# Python 判断入参日期是周几
在数据分析和软件开发中,经常需要判断某个特定日期是星期几。Python 提供了强大的日期时间处理功能,可以轻松实现这一功能。本篇文章将介绍如何使用 Python 的内置库来判断给定日期是星期几,并提供具体实例。 1. 使用 datetime 模块 Python…...

井字棋游戏(HTML+CSS+JavaScript)
🌏个人博客主页:心.c 前言:这两天在写植物大战僵尸,写不动了,现在和大家分享一下之前我写的一个很简单的小游戏井字棋,这个没有AI,可以两个人一起玩,如果大家觉得我哪里写的有一些问…...
HTML 列表和容器元素——WEB开发系列10
HTML 提供了多种方式来组织和展示内容,其中包括无序列表、有序列表、分区元素 <div> 和内联元素 <span>、以及如何使用 <div> 进行布局和表格布局。 一、HTML 列表 1. 无序列表 (<ul>) 无序列表用于展…...

Java数组的高级使用技巧与性能优化
Java数组的高级使用技巧与性能优化 大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿! Java数组是程序设计中的基础数据结构,提供了一种存储固定大小的同类型元素的方式。本文将介绍Jav…...

python spyne报No module named ‘http.cookies‘的解决
python spyne报No module named ‘http.cookies’ python实现webservice服务端时,会使用spyne这个库,安装后,运行会提示No module named ‘http.cookies’。 尝试过不行的方法 pip install http.cookiespip install http.cookiejar 可行的…...

vmware虚拟机玩GPU显卡直通
安装好exsi以后,找到管理----硬件-----PCI设备,勾选想要直通的显卡,然后点击“切换直通” 切换以后可以看到列表中的直通列显示为活动就对了。 然后编辑虚拟机设置,CPU关闭硬件虚拟化(向客户机操作系统公开硬件辅助的…...

Linux下Oracle 11g升级19c实录
1.组件信息 source /home/oracle/.bash_profile11g && sqlplus "/ as sysdba"<<EOF set line 200 col COMP_NAME for a40 select comp_name,VERSION,STATUS from dba_registry; exit; EOF COMP_NAME VERSION …...

haproxy实验-2
haproxy中的算法 静态算法:按照事先定义好的规则轮询公平调度,不关心后端服务器的当前负载、连接数和响应速度 等,且无法实时修改权重(只能为0和1,不支持其它值),只能靠重启HAProxy生效。 static-rr:基于权重的轮询…...

動態PPTP代理IP是什麼?
PPTP即Point-to-Point Tunneling Protocol,點對點隧道協議,是一種常用的VPN協議,主要用於創建虛擬專用網路。通過將用戶的網路流量加密並通過一個中間伺服器傳輸,實現了對用戶IP地址的隱藏和數據的保護。而動態PPTP代理IP則是在傳…...

《全面解析 Nginx:从下载安装到高级应用与问题解决》
Nginx 一、Nginx 简介 什么是 Nginx 以及其功能 Nginx 是一款高性能的 HTTP 和反向代理的 Web 服务器,在处理高并发方面表现卓越,具备强大的能力来承受高负载,有相关报告指出其能够支持高达 50,000 个并发连接数。其显著特点为占用内存少、…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...

用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章
用 Rust 重写 Linux 内核模块实战:迈向安全内核的新篇章 摘要: 操作系统内核的安全性、稳定性至关重要。传统 Linux 内核模块开发长期依赖于 C 语言,受限于 C 语言本身的内存安全和并发安全问题,开发复杂模块极易引入难以…...
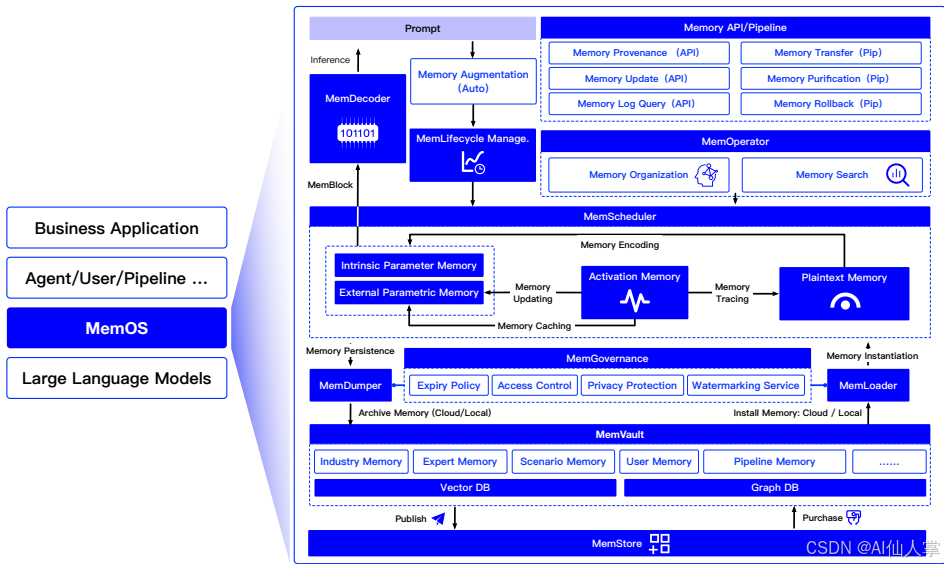
【阅读笔记】MemOS: 大语言模型内存增强生成操作系统
核心速览 研究背景 研究问题:这篇文章要解决的问题是当前大型语言模型(LLMs)在处理内存方面的局限性。LLMs虽然在语言感知和生成方面表现出色,但缺乏统一的、结构化的内存架构。现有的方法如检索增强生成(RA…...

【题解-洛谷】P10480 可达性统计
题目:P10480 可达性统计 题目描述 给定一张 N N N 个点 M M M 条边的有向无环图,分别统计从每个点出发能够到达的点的数量。 输入格式 第一行两个整数 N , M N,M N,M,接下来 M M M 行每行两个整数 x , y x,y x,y,表示从 …...

比特币:固若金汤的数字堡垒与它的四道防线
第一道防线:机密信函——无法破解的哈希加密 将每一笔比特币交易比作一封在堡垒内部传递的机密信函。 解释“哈希”(Hashing)就是一种军事级的加密术(SHA-256),能将信函内容(交易细节…...

TMC2226超静音步进电机驱动控制模块
目前已经使用TMC2226量产超过20K,发现在静音方面做的还是很不错。 一、TMC2226管脚定义说明 二、原理图及下载地址 一、TMC2226管脚定义说明 引脚编号类型功能OB11电机线圈 B 输出 1BRB2线圈 B 的检测电阻连接端。将检测电阻靠近该引脚连接到地。使用内部检测电阻时,将此引…...