大语言模型(LLMs)Tokenizers详解
Tokenizers是大语言模型(Large Language Models,LLMs)中用于将文本分割成基本单元(tokens)的工具。这些工具不仅影响模型的输入表示,还直接影响模型的性能和效率。以下是对Tokenizers的详细解释:
1. Tokenizers的作用
Tokenizers的主要作用是将自然语言文本转换为模型可以处理的数字形式。具体来说,Tokenizers执行以下任务:
- 分割文本:将输入文本分割成有意义的单元(tokens)。
- 编码tokens:将每个token映射到一个唯一的整数ID。
- 生成嵌入:将整数ID转换为连续的向量(embeddings),作为模型的输入。
2. Tokenizers的类型
根据分割策略的不同,Tokenizers可以分为以下几种类型:
2.1 基于空格的Tokenizers
最简单的Tokenizers类型,直接按空格分割文本。这种方法简单快速,但无法处理复合词和未登录词。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize("I love natural language processing.")
print(tokens)
# 输出: ['i', 'love', 'natural', 'language', 'processing', '.']2.2 规则基础的Tokenizers
使用预定义的规则分割文本,如去除标点符号、处理大小写等。这种方法比基于空格的Tokenizers更灵活,但仍然有限。
from nltk.tokenize import RegexpTokenizertokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize("I love natural language processing.")
print(tokens)
# 输出: ['I', 'love', 'natural', 'language', 'processing']2.3 子词Tokenizers
子词Tokenizers将文本分割成子词单元,如字节对编码(BPE)、WordPiece和Unigram Language Model。这些方法可以有效处理未登录词,提高模型的泛化能力。
2.3.1 字节对编码(BPE)
通过统计频率合并频繁出现的字节对,逐步构建子词单元。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("gpt2")
tokens = tokenizer.tokenize("I love natural language processing.")
print(tokens)
# 输出: ['I', 'Ġlove', 'Ġnatural', 'Ġlanguage', 'Ġprocessing', '.']2.3.2 WordPiece
类似于BPE,但选择合并操作时考虑对语言模型的增益。BERT模型使用WordPiece Tokenizer。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize("I love natural language processing.")
print(tokens)
# 输出: ['i', 'love', 'natural', 'language', 'processing', '.']2.3.3 Unigram Language Model
基于语言模型的方法,通过优化token集来最大化似然。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
tokens = tokenizer.tokenize("I love natural language processing.")
print(tokens)
# 输出: ['▁I', '▁love', '▁natural', '▁language', '▁processing', '.']3. Tokenizers的实现
许多大预言模型使用专门的Tokenizers库,如Hugging Face的Transformers库。这个库提供了多种Tokenizers的实现,支持不同的分割策略和模型。
from transformers import AutoTokenizer# 加载预训练的BERT Tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")# 分割文本
tokens = tokenizer.tokenize("I love natural language processing.")
print(tokens)
# 输出: ['i', 'love', 'natural', 'language', 'processing', '.']# 编码tokens
encoded_input = tokenizer.encode("I love natural language processing.")
print(encoded_input)
# 输出: [101, 1045, 2293, 2784, 3693, 10118, 1012, 102]4. Tokenizers的影响
Tokenizers的选择和实现对模型的性能有显著影响:
- 词汇量:更大的词汇量可以提高模型的表达能力,但也会增加计算复杂度。
- 未登录词处理:有效的Tokenizers策略可以更好地处理未登录词,提高模型的泛化能力。
- 序列长度:合理的Tokenizers可以减少输入序列的长度,从而提高计算效率和内存使用。
5. 示例
假设我们有一个简单的句子:“I love natural language processing.”
使用不同的Tokenizers,这个句子可能会被分割为:
- 基于空格的分割:["I", "love", "natural", "language", "processing."]
- WordPiece(如BERT所用):["i", "love", "natural", "language", "processing", "."]
- BPE(如GPT所用):["I", "Ġlove", "Ġnatural", "Ġlanguage", "Ġprocessing", "."]
总结
Tokenizers是大预言模型处理和生成文本的基础。通过将文本分割为有意义的单元,模型可以学习语言的结构和语义,从而实现复杂的语言理解和生成任务。选择合适的Tokenizers方法和策略对于提高模型的性能和效率至关重要。
相关文章:
Tokenizers详解)
大语言模型(LLMs)Tokenizers详解
Tokenizers是大语言模型(Large Language Models,LLMs)中用于将文本分割成基本单元(tokens)的工具。这些工具不仅影响模型的输入表示,还直接影响模型的性能和效率。以下是对Tokenizers的详细解释:…...

分支-快排/归并---1
目录 1.排序数组 2.数组中的第K个最大元素 3.最小k个数 4.排序数组(归并) 5.数组中的逆序对 6.计算右侧小于当前元素的个数 7. 翻转对 1.排序数组 快排的写法有很多,这里我采取了相对快的三路划分加随机基准值。 三路划分,是…...

代码随想录训练营 Day32打卡 动态规划 part01 理论基础 509. 斐波那契数 70. 爬楼梯 746. 使用最小花费爬楼梯
代码随想录训练营 Day32打卡 动态规划 part01 一、 理论基础 动态规划中每一个状态一定是由上一个状态推导出来的,这一点就区分于贪心,贪心没有状态推导,而是从局部直接选最优的。 例如:有N件物品和一个最多能背重量为W 的背包…...

【智能流体力学】剖析ANSYS Fluent材料属性设定与边界条件
目录 一、材料属性设定**1. 材料属性的概述****功能****2. 材料属性的类型****标准材料库****多相流****燃烧模型****传热模型****辐射模型****3. 属性设置与函数****4. 自定义材料数据库****5. Granta数据库支持**二、边界条件**1. 通用边界条件****Pressure Inlet (压力-入口…...

微信小程序反编译工具
目录 介绍 工程结构还原 微信开发者工具运行 如何查看当前运行版本? 开启小程序F12 重新打包运行 效果示例 安装 用法 参数说明 获取微信小程序AppID 文件夹名即为AppID 下载地址 介绍 纯Golang实现,一个用于自动化反编译微信小程序的工具,小程序安全利器, 自…...

线程基本概念
一、进程的结束 wait(阻塞) 一般不做额外的事情 wait(非阻塞) 逻辑不受影响(必须套在循环中) wait作用:1.获取子进程退出状态 2.回收资源 传参为指针:被调修改主调 获取退出状态值: WIFEXITED 判断是否…...

在SpringBoot中执行后台任务
在 Spring Boot 中执行后台任务通常涉及到使用线程池和定时任务。Spring Boot 提供了多种方式来实现后台任务,包括使用 Scheduled 注解、ThreadPoolTaskExecutor 和 ExecutorService。 下面我将详细介绍如何使用这些方法来实现后台任务。 使用 Scheduled 注解 Sp…...

【网络】UDP回显服务器和客户端的构造,以及连接流程
回显服务器(Echo Server) 最简单的客户端服务器程序,不涉及到业务流程,只是对与 API 的用法做演示 客户端发送什么样的请求,服务器就返回什么样的响应,没有任何业务逻辑,没有进行任何计算或者…...

【智能流体力学】ANSYS Fluent工作流程设置、求解和后处理详解
目录 一、设置阶段1. **模型****功能** :**详细说明及原理** :2. **材料****功能** :**详细说明及原理** :3. **单元区域条件****功能** :**详细说明及原理** :4. **边界条件****功能** :**详细说明及原理** :5. **网格交界面****功能** :**详细说明及原理** :6. **动…...
最新UI六零导航系统源码 | 多模版全开源
六零导航页 (LyLme Spage) 致力于简洁高效无广告的上网导航和搜索入口,支持后台添加链接、自定义搜索引擎,沉淀最具价值链接,全站无商业推广,简约而不简单。 使用PHPMySql,增加后台管理 多模板选择,支持在…...

K8S中使用英伟达GPU —— 筑梦之路
前提条件 根据不同的操作系统,安装好显卡驱动,并能正常识别出来显卡,比如如下截图: GPU容器创建流程 containerd --> containerd-shim--> nvidia-container-runtime --> nvidia-container-runtime-hook --> libnvid…...

2024-2025年最值得选的Java计算机毕业设计选题大全:800个热门选题
一、前言 博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ…...

libnl教程(2):发送请求
文章目录 前言示例示例代码构造请求创建套接字发送请求 简化示例 前言 前置阅读要求:libnl教程(1):订阅内核的netlink广播通知 本文介绍,libnl如何向内核发送请求。这包含三个部分:构建请求;创建套接字;发送请求。 …...

【软件测试】功能测试理论基础
目录 项目的测试流程🏴 需求评审 评审形式 测试人员在需求评审中职责 测试计划与方案 测试计划 问题 测试方案🏴 测试计划与方案的对比 功能测试设计🏴 测试设计的步骤 项目的测试流程🏴 作用: 有序有效开展…...

玩机进阶教程-----回读 备份 导出分区来制作线刷包 回读分区的写入与否 修改xml脚本
很多工作室需要将修改好的系统导出来制作线刷包。前面分享过很多制作线刷包类的教程。那么一个机型中有很多分区。那些分区回读后要写入。那些分区不需要写入。强写有可能会导致不开机 不进系统的故障。首先要明白。就算机型全分区导出后在写回去 都不一定可以开机进系统。那么…...

MongoDB 插入文档
MongoDB 插入文档 MongoDB 是一个流行的 NoSQL 数据库,它使用文档存储数据。在 MongoDB 中,数据以 BSON(Binary JSON)格式存储,这是一种二进制表示的 JSON 格式。MongoDB 提供了灵活的数据模型,使得插入和查询文档变得非常简单。本文将详细介绍如何在 MongoDB 中插入文档…...

【内网】服务器升级nginx1.17.0
今天用rpm包升级内网nginx版本,上来就给我报错 警告:nginx-1.27.0-2.el7.ngx.x86_64.rpm: 头V4 RSA/SHA256 Signature, 密钥 ID 7bd9bf62: NOKEY 错误:依赖检测失败: libcrypto.so.10()(64bit) 被 nginx-1:1.27.0-2.el7.ngx.x…...

歌曲爬虫下载
本次编写一个程序要爬取歌曲音乐榜https://www.onenzb.com/ 里面歌曲。有帮到铁子的可以收藏和关注起来!!!废话不多说直接上代码。 1 必要的包 import requests from lxml import html,etree from bs4 import BeautifulSoup import re impo…...

transformer-explainer
安装和启动 找到这个项目,然后装好了。 这个项目的目的如名字。 https://github.com/poloclub/transformer-explainerTransformer Explained: Learn How LLM Transformer Models Work with Interactive Visualization - poloclub/transformer-explainerhttps:/…...

C#中的S7协议
S7协议-S7COMM S7COMM 进行写 CTOP->PDU type已知枚举值 0X0E连接请求0x0d连接确认0x08断开请求0x0c断开确认0x05拒绝访问0x01加急数据0x02加急数据确认0x04用户数据0x07TPDU错误0x0f数据传输 S7Header->ROSCTR已知枚举值 0X01JOB REQUEST。主站发送请求0x02Ack。从站…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...
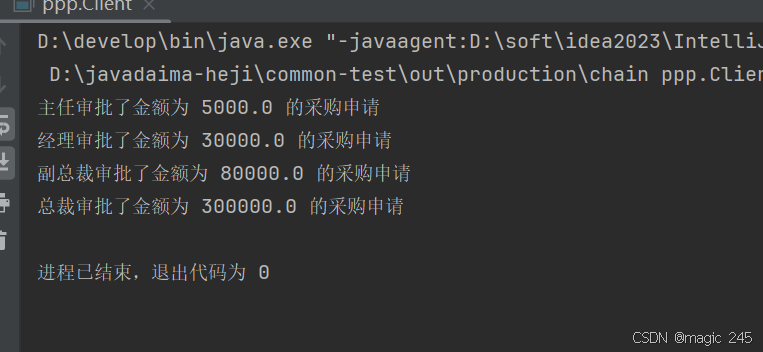
Java设计模式:责任链模式
一、什么是责任链模式? 责任链模式(Chain of Responsibility Pattern) 是一种 行为型设计模式,它通过将请求沿着一条处理链传递,直到某个对象处理它为止。这种模式的核心思想是 解耦请求的发送者和接收者,…...

使用 uv 工具快速部署并管理 vLLM 推理环境
uv:现代 Python 项目管理的高效助手 uv:Rust 驱动的 Python 包管理新时代 在部署大语言模型(LLM)推理服务时,vLLM 是一个备受关注的方案,具备高吞吐、低延迟和对 OpenAI API 的良好兼容性。为了提高部署效…...