B站搜索建库架构优化实践
前言
搜索是B站的重要基础功能,需要对包括视频、评论、图文等海量的站内优质资源建立索引,处理来自用户每日数亿的检索请求。离线索引数据的正确、高效产出是搜索业务的基础。我们在这里分享搜索离线架构整体的改造实践:从周期长,流程复杂的手工构建流程,改造为高容量、高性能、易迭代的分布式建库架构的过程。
业务背景
B站是一个典型的多资源搜索场景,除了视频外,还接入了包括UP主、番剧影视(PGC)、直播等几十种不同类型的资源。除了资源类型多以外,各种资源的数据源的形式也多种多样,包括数据库、上游业务接口、Hive表等等。这些数据通过离线近线的聚合和构建,以全量和增量实时流两种方式生产出索引,在线上的服务中生效。
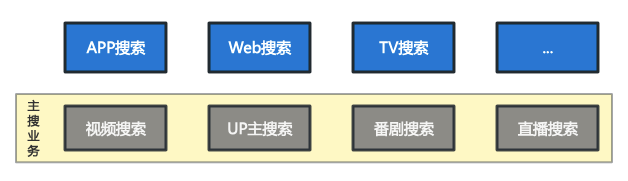
实际业务中,除了搜索业务自己维护的视频MySQL数据库外,还接入了不同形式的数据来源,一并添加到全量/增量索引数据中构建。这些数据有的仅T+1更新全量;有的则会提供增量数据流和接口,接入时也希望数据变更能在搜索索引中实时生效。
全量(base)索引:以文件形式提供,包含某一特定时间点之前的全部数据,通常每天产出、更新一次。
增量(delta)索引:以数据流(消息队列)的形式提供,每条消息对应一份稿件的完整信息。增量索引能实时同步更新,适用于时效性要求高的场景,满足用户对新稿件的检索需求。
这些第三方数据由于各种原因(MySQL容量或性能限制,数据维护团队不同等),不能直接集成到搜索的MySQL数据库中。这些数据的引入在当前的离线和近线建库流程中是独立的,随着数据的种类增加,搜索离线建库流程也逐渐复杂起来。
索引数据产出流程
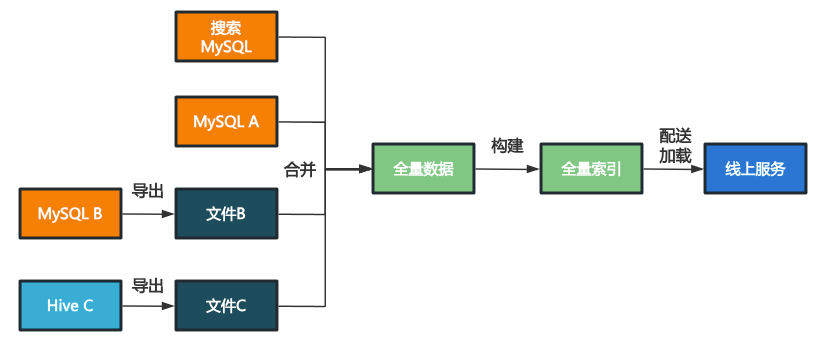
以视频索引为例,构建视频索引时除了搜索自己维护的MySQL中视频信息外,还需要接入多种第三方数据到索引中,如接入以下三类数据:
-
数据A:第三方数据库+binlog
-
数据B:不开放DB直接访问,以导出的全量snapshot+接口+数据流形式间接提供
-
数据C:Hive表
全量数据产出
为了获取稿件信息,全量建库流程需要先后将这些不同的数据源获取到本地,合并为新的全量数据集,再构建出二进制全量索引。
增量数据产出
对于增量索引,我们希望将每条稿件的完整字段(即包含搜索MySQL+数据源A/B/C的所有字段信息)聚合为一条增量索引消息下发。
我们监听binlog A和数据流B,但只关心其中有变化的稿件id,通过变更搜索MySQL中相应稿件的一个标志位,触发该稿件的一条binlog及后续的增量建库流程。
在后续的建库流程中,处理binlog时增加根据ID查询MySQL A和接口B的逻辑,这样就能从MySQL A的查询结果,接口B的响应和本地的文件C中拿到稿件的对应数据,写入到增量索引数据流中。
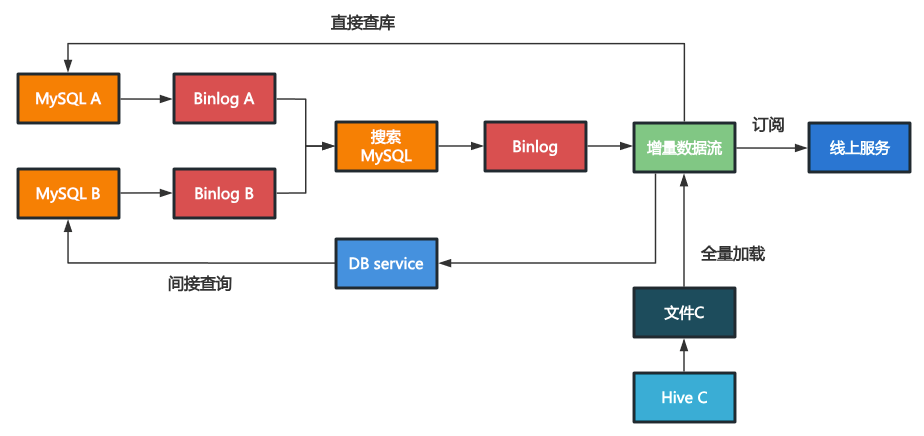
注意这里对MySQL A和接口B有着严格的时效性要求,即查询得到的数据不能比数据流下发的数据版本更旧,否则无法保证数据的最终一致性。
举个例子,假如MySQL A的binlog来自主库,而按ID查询时访问了MySQL A的从库。
当A中某个稿件的字段发生变化时,在处理主库的对应binlog时会从从库中查询当前值。由于主库从库之间的同步有一定延迟,这时有可能查询到旧值而不是主库中的新值,导致新值不会在索引中生效,除非该稿件有其他变更再次触发binlog处理。
将MySQL A的binlog调整为由对应从库导出则可避免该问题发生。
索引生效流程
B站的检索引擎和正排服务加载索引数据的过程如下:
-
更新全量索引:服务周期性地获取新的全量索引文件,解析元数据,将索引加载到内存中。
-
消费增量数据流:加载了全量索引后,服务会从元数据指定的时间点开始消费增量索引数据流,直到消费进度接近当前的最新产出。消费到的数据会在服务侧实时地建立增量索引,以支持查询。当一份稿件同时出现在增量索引和全量索引时,全量索引中的数据被覆盖;稿件在数据流中出现多次时,增量索引中的旧值也会被新值覆盖。
-
提供服务:当增量数据流的产出进度被消费追平后,服务进入就绪状态,开始处理请求。
问题与挑战
随着搜索业务复杂度的增加和数据规模的增长,现有建库逻辑在效率和资源层面逐渐难以为继。
性能
新投稿的增多和历史投稿的积累,让搜索MySQL在建库过程中的负载越来越大,开始出现性能瓶颈。
造成MySQL高负载的主要场景有:
1. 表结构变更:需要复制全表数据。数据复制期间,数据库负载显著增加。
2. 新增字段并批量导入:将新字段导入数据库时需要大量写入,增加数据库压力。
-
缓解措施:控制写入过程,在负载低峰期小批量执行。
3. 全量索引构建时的扫库操作:索引构建流程每次需要先查询搜索MySQL数据库获取全量稿件信息,dump到文件中,再进行索引构建。当在基线外另行构建索引以支持AB实验时,数据库的查询负载也会相应地倍增。
-
缓解措施:错开不同构建任务的执行时间;将扫库结果和元数据保存下来,供多个建库任务复用。
当MySQL负载高时,主从数据库同步会出现延迟,导致索引数据更新不及时。用户不能及时看到最新的投稿和变更,体验受损害。
我们在日常实验和迭代时,都必须时刻考虑对数据库的性能影响,而缓解数据库压力的措施往往导致迭代周期变长,不同的需求上的索引迭代也不能并行推进。性能瓶颈和稳定性风险成为了索引迭代的主要障碍。
维护成本
-
搜索索引原始数据没有统一的存储承载,数据可能来自多个数据库、文件、甚至接口。离线和近线需要各自维护复杂的拼接逻辑,导致迭代困难,开发周期长。数据不符合预期时,难以定位原因。
-
全量数据和增量数据的产出逻辑差异大,没有机制能保证两套链路上最终的产出结果一致。数据的不一致可能影响业务效果。
-
全量索引是单机构建,构建周期,实例部署和数据分片都需要人工维护,每次迭代都消耗大量人力成本。
-
增量数据接入新的实时数据时,数据提供方需要同时提供全量、增量数据和查询接口。搜索业务和数据提供方的对接、开发成本都较高。
资源
每次构建索引时,都需要对原始数据重新切词分析,构建正排、倒排索引。即使数据和策略没有变化也需要重复计算。这些计算会消耗大量资源,并且增加索引构建所需的时间。
设计目标
反思索引构建流程中的问题,不管是复杂的多数据源合并流程、还是MySQL的性能压力延迟风险,归根结底都是存储设施能力不足,不能直接承载全部索引数据导致的问题复杂化。我们期望将索引依赖的全部数据聚合到统一的存储设施中,作为基准数据源,直接基于该数据源导出全量数据和增量数据流,并将后续的建库任务彻底分布式化,达到数据统一、可扩展性大幅增强的目的。
预期新的架构设计可解决当前的痛点:
-
用分布式的存储设施承接搜索数据,后续的构建任务也进行分布式化改造,让建库链路中不再有单点的性能瓶颈。
-
全量和增量都从统一的存储设施中获取,完全屏蔽原有不同数据来源对建库过程的影响,可以让建库的流程简单化,降低开发维护的成本。
-
有了足够的存储能力之后,我们可以将稿件切词这类较为稳定的中间计算结果保存下来,只在有数据或策略有变化时重新计算。节省计算资源的同时进一步缩短全量构建周期。
方案设计
既然MySQL不能满足我们的需求,我们的人力也不允许从零开始造一个轮子来维护索引数据,首要的问题是找到一个合适的存储设施来作为基础,在其之上开发数据处理和建库逻辑。
存储选型
我们希望新的存储方案可以具有以下特性:
-
高容量:可以存入目前全部的索引数据。易于水平拓展。
-
高吞吐量:允许大批量的数据写入和导出。
-
低延迟:可以快速随机读写单个稿件数据。
-
易于迭代:数据的结构可以灵活迭代,无需Online DDL操作(https://dev.mysql.com/doc/refman/8.4/en/innodb-online-ddl-operations.html)。
我们从现有的数据库系统中寻求合适的选型:对于数据灵活迭代的需求排除了MySQL,TiDB等关系型数据库;批量更新稿件部分字段的需求对文档存储性的NoSQL数据库不友好;HBase,Cassandra等列族存储的数据模型比较合适,但简单写入查询延迟较高;KV(键值)存储延迟低,但数据模型不太匹配。
最终我们选择在KV存储的基础上封装行式(Row-Oriented)数据库的形式,以达到兼顾吞吐与延迟的效果,并选择了b站内部存储组件Taishan作为底层KV存储。
Taishan是B站内部的高性能分布式KV存储,具备多分片水平拓展能力,可应对大规模存储需求,简单读写的延迟也较低,此外还具有以下特性:
有序映射:key是有序的,支持scan(范围查询)。
支持 CompareAndSwap 操作:基于CAS原子操作可实现乐观锁,在并发的数据更新时防止冲突。
高效的数据导出:Taishan 支持快速将数据全量导出到对象存储中,而不需要全表scan。
架构设计
我们以Taishan为基础存储设施,在其上建立了强大的数据存储层(基于表格存储模型)和统一的数据接入和导出层。
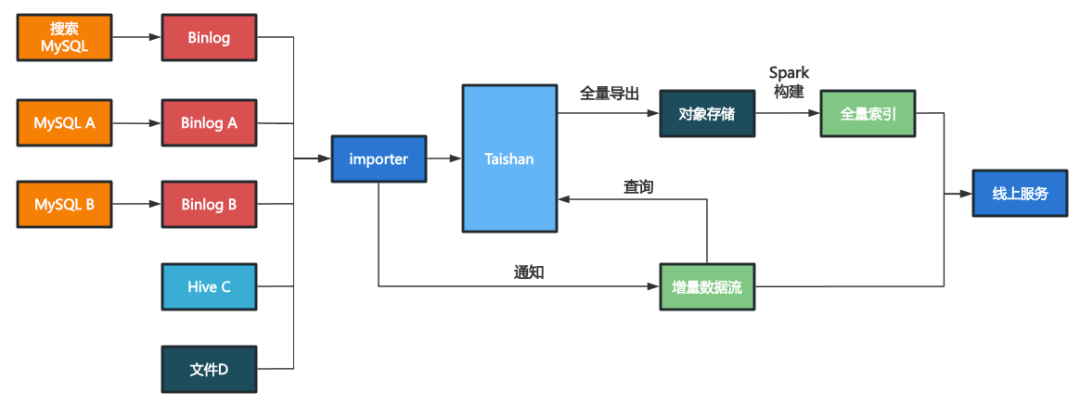
引入存储层后,我们将原始数据源跟具体的建库逻辑隔离,并抽象出可高度复用的数据导入导出逻辑,显著降低了维护成本和后续开发成本。
离线和近线使用相同的数据来源并复用导出逻辑,从根本上消除了全量索引和增量索引数据不一致的可能。
高容量的存储层允许我们以增量计算形式来源空间换取时间:将一些中间计算结果(如切词和Embedding等)也一并保存,仅在相关稿件属性有变化时触发计算并更新;建库时直接使用保存下来的结果,计算量大幅减少。
在全部数据都经Taishan聚合后,离线近线的流程变得清晰直观起来,同时在根本上消除了全量和增量数据不一致的可能性。增量计算的引入也减少了大量重复的计算量,节省了资源。新的数据流程使得迭代和维护都大为简化。
数据存储层
表格模型
基于KV存储之上封装出表格存储模型:
-
行:每一行代表一个稿件,通过稿件ID标识。
-
列:每一列存储稿件的若干相关字段,通过字段族名(CF,column family)标识。
-
单元格:行和列的组合确定一个单元格,对应KV存储中的一条记录。

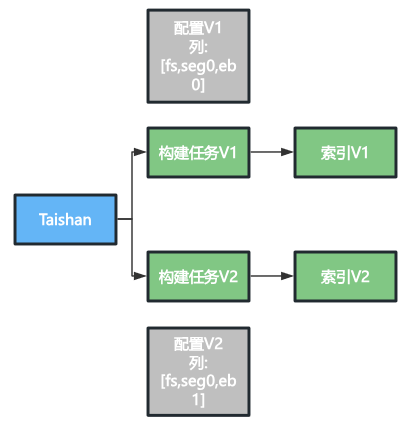
如上表所示,稿件ID和行一一对应。而稿件的具体字段和列(CF)是多对多的关系:
-
同一稿件的若干相关字段可以打包保存在一列(如title和uname),这样会大幅减少KV的访问次数,提高效率。
-
表格中不同的列可以保存相同的字段。例如:
-
这里eb,eb1两列分别对应doc_embedding字段的不同版本。指定不同的列组合(fs,seg,eb)/(fs,seg,eb1),可以构建出两版包含相同(title,uname,title_term,uname_term),以及不同版本doc_embedding的索引数据。
支持并发写入
Taishan的CAS支持允许我们在不同写入方之间通过乐观锁来同步,避免多个写入方同时更新一个单元格时发生写入丢失。
如果一列的写入方唯一,也可以不使用CAS直接写入。
支持并发写入消除了将多个字段放进同一CF的后续维护风险。即使同一列后续要增加新的写入方,也无需对该列进行拆分改造。
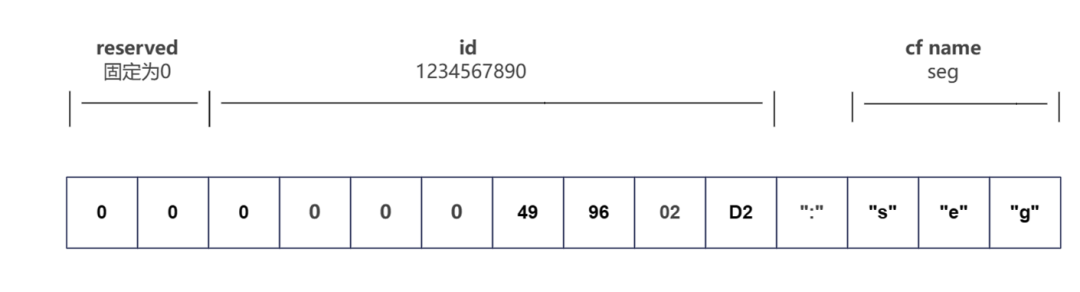
Key设计
Key由ID和字段族名组成。下图是稿件ID1234567890的seg列对应的实际Key内容。ID和列名间用 “:”来分隔。
Data Orientation
Key的设计决定了数据排列方式。底层Taishan存储中,数据按Key的字符串顺序连续排列。
| ID1:CF1 | ID1:CF2 |
| ID2:CF1 | ID2:CF2 |
我们将稿件ID放在列名称前,这样表格数据在Taishan中实际存放形式如下:
| ID1:CF1 | ID1:CF2 | ID2:CF1 | ID2:CF2 |
实际使用场景中我们主要按行扫描(获取相同ID的所有字段值),较少按列扫描(获取某一字段下所有取值)。同一ID下所有列连续分布的排列使得按ID(行)读取时有更好的访问局部性和Cache命中率。
同时,ID使用大端序int64保存。大端序的特点是作为字符串看待时的顺序和数字的升序一致,让遍历过程总是按ID升序执行,符合人的直觉与习惯。
Value设计
Value总是以一个varint N作为header,该varint标识随后的N个字节保存的是元数据,其余的字节则用于存储实际数据。
下图是一个包含header、元数据(大小为8字节)和数据(大小为5字节)的value。

通过这种设计,我们得到了一个高效、灵活且近似于传统表格存储的系统,可以为索引建库提供强大的支持。
序列化
抛弃JSON
在最初的建库流程中,我们使用JSON Lines文件格式保存原始的稿件数据,例如:
video.jsonl
{"id": 81403056, "title": "高燃舞台演绎B站最美的夜", "uname": "哔哩哔哩晚会", "doc_embedding": [0.168322, 0.015824, 0.091791, -0.2059]}{"id": 613621262, "title": "【触手猴】「強風オールバック」を弾いてみた【Piano】", "uname": "marasy_触手猴", "doc_embedding": [0.007262, 0.040466, 0.028768, 0.161083]}
JSON格式具有良好的可读性,但效率和性能不足,主要体现在:
-
存储效率低:每条记录中都会重复保存字段名及符号(如 {} 和 ""),浪费大量存储空间。
-
序列化性能低:文本格式的解析性能较差。
如果将完整的稿件字段拆分到多个列中分别保存,导出和查询时的序列化消耗会更加严重。
转向protobuf
为了解决上述问题,我们选择了Protocol Buffers(protobuf)格式来序列化稿件字段。以下是简化的Video消息的protobuf定义:
video.proto
message Video {int64 id = 1;string title = 2;string uname = 3;repeated float doc_embedding = 4;}
protobuf的优势主要有:
-
存储空间优化:protobuf使用field number(以varint形式存储)来区分字段,相比于JSON中存储完整字段名,大大节省了存储空间。
-
性能提升:protobuf的反序列化速度优于JSON。
-
类型安全:和JSON相比,protobuf为数据字段提供了强类型保证,增强了我们对数据的信心。严格的数据类型也从源头上消除了JSON 固有的最大安全整数(https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/MAX_SAFE_INTEGER)问题。
高效地合并
对于protobuf消息,多个序列化后的数据块(buffer)可以直接拼接来达到合并的效果:
Video v; v.ParseFromString(buf1 + buf2);
这与将其分布反序列化后再执行合并是等效的:
Video v1, v2; v1.ParseFromString(buf1); v2.ParseFromString(buf2); v1.MergeFrom(v2);
假设稿件的标题保存在列1,稿件Embedding信息保存在列2,buf1/buf2分别是对应单元格查询的数据。我们只需要直接concate未经反序列化的两段buffer即可拼接出稿件完整数据。
在使用Cord(https://protobuf.dev/reference/cpp/cpp-generated/#cord)或zero_copy_stream(https://protobuf.dev/reference/cpp/api-docs/google.protobuf.io.zero_copy_stream/)的情况下,连这一次拼接也可以省去。
变更数据流
Taishan原生支持binlog导出,可以将变更的Key和Value导出到数据流。
但直接使用Taishan的binlog会有以下问题:
-
大批量写入数据时,会产出大量消息,对后续的整个近线链路乃至线上服务造成压力。
-
Value只包含变更的列,获取完整的数据仍需按ID扫描Taishan表。
为了灵活控制变处理,我们封装了写入层,在数据写入Taishan完成后另外输出一条变更消息,示例如下:
{"id": 613621262, "cf_changed": ["eb"]} // 稿件av613621262的eb列发生了变更数据变更的场合是否输出对应变更消息到流中是可指定的,批量写入数据时我们选择不触发。
我们也省略了变更后的值,需要的消费者可以直接查询Taishan表的主节点获取最新的字段。
查询从节点可能得到更新前的旧值,破环数据的最终一致性。
数据接入层
存储方案和序列化方式的确定后,我们开始将现有的数据统一接入到Taishan中。具体而言是将原有的数据库全量增量以及T+1更新的数据全部写入上文所说的Taishan表格,并按需同步到变更数据流。
T+1数据接入
T+1更新的数据没有实时的增量更新,只需要定时写入全量。
写入的逻辑是高度复用的,同过指定配置将hive表/TSV/CSV/JSON Lines文件映射到Taishan中的对应列。
从新版全量中被删除的数据需要额外的处理:我们需要跟上一版数据对比,找出这些被删除的数据,将这些数据同步从Taishan中删除。
实时数据接入
实时数据接入需要将数据实时写入Taishan,并同步到变更数据流。写入的顺序必须为先写Taishan再写变更数据流,保证后续处理变更流时能从Taishan主节点查到最新取值。
由于我们不能对上游提供的变更数据流的字段定义做任何的限制和假设,处理增量的Worker需要开发少量的解析逻辑。
增量写入只写入了最近有变更的数据,为了让Taishan保存全部的历史数据,在实时数量接入后,我们还需要再获取一份全量数据(产出时间在增量接入后),将这些数据也写入Taishan中。
这的全量写入过程和T+1数据接入类似,区别在于只需要初始化时执行一次,后续的变更都可以通过增量来获取。另外T+1全量写入时需要考虑和增量写入冲突的情况,具体在后文介绍。
写入冲突处理
全量vs增量
包含实时数据的数据在导入时往往也需要刷入一份全量数据做初始化。
一般来说,全量中的数据会比来自数据流的旧,直接写入会将来自数据流的新值覆盖。
因此写入时需要利用CAS,仅当满足Precondition:值不存在时,才会写入。
增量vs增量
同一列可以有多个写入方,比如两个worker消费两条不同的数据流写入同一列中的两个不同字段。此时需要先读取稿件的该列的旧值,更新其中的新字段后,将完整的新值写入。
当两个worker同时运行时,可能发生写写冲突(Write-Write Conflict),导致一个worker写入的新值,被另外的worker覆盖而丢失。
在这种场景下,我们同样使用CAS,在计算出新值后,仅当满足Precondition:值==旧值时,才会写入新值,当Precondition不满足时,必须重试。
增量计算
我们将一些中间计算结果也保存在Taishan中。典型的场景如稿件标题的切词和向量化的结果。具体而言,如果使用的计算策略和稿件标题没有变化,切词和向量化的结果可以认为是稳定的。因此我们可以保存这些结果来避免重复计算,只在稿件的属性有变化时更新计算结果。
增量更新切词结果的工作流如下图所示:
和实时数据接入类似,在首次接入时也需要对全部已有数据进行一次切词,让历史稿件也有切词结果。初始化过程同样需要使用CAS来规避写写冲突。
数据导出层
数据进入Taishan后,我们需要从中导出需要的数据来构建全量和增量索引。
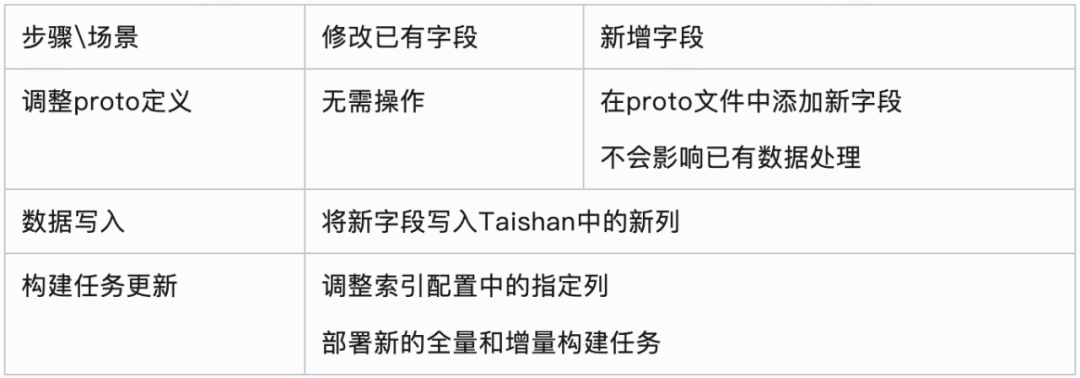
对于一份索引,其全量和增量构建任务的配置是共用的,获取到实际数据后的处理逻辑也是一致的。
Taishan中不同的列可以保存字段的多个版本,具体构建全量和增量索引时选用哪些列中的字段,需要在配置中指定。配置中以白名单的形式指定列,无需担心新增列对已有构建任务产生影响。
不同版本的索引大部分情况下只需要调整配置再另行部署即可产出。
全量数据导出
Taishan会每日定期将全量数据备份到公司内部的对象存储。我们通过备份数据好的数据,遍历其中的全部KV,也就是按行遍历表格,取出指定的列来获取全量索引数据。Taishan备份效率是非常高的,通常在分钟级,这也大幅地减少了扫库的时间开销。
增量数据导出
增量数据的导出通过消费变更数据流实现。消费后对每条消息(ID+变更的CF)反查Taishan,获取所需的完整字段。
数据迭代
新的存储机制简化了索引的迭代流程,只需要将新数据写入Taishan,然后调整构建任务关注的列即可。迭代的开发量大幅下降,基本只需复用现有流程,调整配置后部署新任务。
随着新存储方案和增量计算等优化的落地,索引构建的周期缩短了一半以上。迭代周期缩短的同时,消除了链路上的性能瓶颈和延迟风险。
分布式构建
搜索索引最早都是通过物理机crontab定时执行脚本实现。脚本执行各种扫库操作,将数据加载到内存中,并产出一份完整的JSON Lines文本文件作为原始索引数据集,然后调用indexer进行全量切词和构建正排/倒排索引。物理机部署稳定性没有保证且难以维护,我们首先把构建迁移到K8S集群上,尝试以服务形式部署。这样虽然保证了建库任务的稳定性,但是建库任务资源利用率很低。建库服务构建时需要大量资源,但在大多数时间里是不消耗任何资源的,容器依然需要占据相应的CPU/内存资源。虽然通过超配(低软限高硬限)并错开任务触发时间可以来减少资源空置的情况,但维护较为繁琐。最终我们选择将建库迁移到业界广泛使用的分布式计算框架Spark上,利用Spark潮汐资源进行索引构建,一方面可以加大构建并发,另一方面也可以对资源进行更充分的利用。
为了能够尽可能的复用及降低维护成本,从流程上进行抽象,将索引构建流程分以下主要步骤:
-
读取数据:从配置中加载并进行数据读取,Taishan源在对象存储的导出文件为sst格式,使用官方开源的JNI库进行二次封装。
-
解码 :Taishan非Spark原生支持的数据源,需要额外开发解析逻辑。
-
再分片:由于导出的单一文件分片数据量较大,一次性读取将占用大量内存,甚至OOM。为解决上述问题,参考Spark的cache机制,在读取并解码文件数据流的过程时先将文件载入到指定内存buffer中,若buffer装满则生成一个分片(partition)并写入hdfs中。以此将较少的文件分片(如128个)拆分为较多的hdfs文件分片(如5000个),便于Spark的后续处理。
-
稿件处理:通过配置对稿件数据进行一系列的处理操作,如过滤、字段映射等。
-
编码 & 索引构建:将稿件内容转化为索引需要的特定编码形式,如Flatbuffer、Protobuffer。并根据索引类型和Meta信息,产出索引。
-
压缩打包:对构建出的索引及Meta数据进行打包,产出最终索引文件。
除更省资源外,Spark构建的任务并发度也更高,进一步缩短了构建时间,最终达到小时级别。
总结与展望
通过这一系列的技术更新和流程优化,我们的索引构建架构最终从早期的单机构建发展到分布式的数据存储和建库任务,能力更强的同时也更易维护和迭代,索引构建周期实现了从天级到小时级别的飞跃式进步,为业务的未来发展奠定了坚实基础。
参考
-
https://protobuf.dev/programming-guides/encoding/#varints
-
https://dev.mysql.com/doc/refman/8.4/en/innodb-online-ddl-operations.html
-
https://research.google/pubs/large-scale-incremental-processing-using-distributed-transactions-and-notifications/
-
https://protobuf.dev/programming-guides/encoding/#last-one-wins
-End-
作者丨网管、HevLfreis、瑚太朗、穅泊
相关文章:
B站搜索建库架构优化实践
前言 搜索是B站的重要基础功能,需要对包括视频、评论、图文等海量的站内优质资源建立索引,处理来自用户每日数亿的检索请求。离线索引数据的正确、高效产出是搜索业务的基础。我们在这里分享搜索离线架构整体的改造实践:从周期长,…...

XSS反射实战
目录 1.XSS向量编码 2.xss靶场训练(easy) 2.1第一关 2.2第二关 方法一 方法二 2.3第三关 2.4第四关 2.5第五关 2.6第六关 2.7第七关 第一种方法: 第二种方法: 第三个方法: 2.8第八关 1.XSS向量编码 &…...

远程消息传递的艺术:NSDistantObject在Objective-C中的妙用
标题:远程消息传递的艺术:NSDistantObject在Objective-C中的妙用 引言 在Objective-C的丰富生态中,NSDistantObject扮演着至关重要的角色,特别是在处理分布式系统中的远程消息传递。它允许对象之间跨越不同地址空间进行通信&…...

指向派生类的基类指针、强转为 void* 再转为基类指针、此时调用虚函数会发生什么?
指向派生类的基类指针、强转为 void* 再转为基类指针、此时调用虚函数会发生什么? 1、无论指针类型怎么转,类对象内存没有发生任何变化,还是vfptr指向虚函数表,下面是成员变量,这在编译阶段就已经确定好了;…...

操作系统(Linux实战)-进程创建、同步与锁、通信、调度算法-学习笔记
1. 进程的基础概念 1.1 进程是什么? 定义: 进程是操作系统管理的一个程序实例。它包含程序代码及其当前活动的状态。每个进程有自己的内存地址空间,拥有独立的栈、堆、全局变量等。操作系统通过进程来分配资源(如 CPU 时间、内…...

react的setState中为什么不能用++?
背景: 在使用react的过程中产生了一些困惑,handleClick函数的功能是记录点击次数,handleClick函数被绑定到按钮中,每点击一次将通过this.state.counter将累计的点击次数显示在页面上 困惑: 为什么不能直接写prevStat…...

2.2算法的时间复杂度与空间复杂度——经典OJ
本博客的OJ标题均已插入超链接,点击可直接跳转~ 一、消失的数字 1、题目描述 数组nums包含从0到n的所有整数,但其中缺了一个。请编写代码找出那个缺失的整数。你有办法在O(n)时间内完成吗? 2、题目分析 (1)numsS…...

【CentOS 】DHCP 更改为静态 IP 地址并且遇到无法联网
文章目录 引言解决方式标题1. **编辑网络配置文件**:标题2. **确保配置文件包含以下内容**:特别注意 标题3. **重启网络服务**:标题4. **检查配置是否生效**:标题5. **测试网络连接**:标题6. **检查路由表**࿱…...

Linux 操作系统 --- 信号
序言 在本篇内容中,将为大家介绍在操作系统中的一个重要的机制 — 信号。大家可能感到疑惑,好像我在使用 Linux 的过程中并没有接触过信号,这是啥呀?其实我们经常遇到过,当我们运行的进程当进程尝试访问非法内存地址时…...

黑马前端——days09_css
案例 1 页面框架文件 <!DOCTYPE html> <html lang"zh-CN"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><meta http-equiv"X-UA-Compati…...

【Python爬虫】技术深度探索与实践
目录 引言 第一部分:Python爬虫基础 1.1 网络基础 1.2 Python爬虫基本流程 第二部分:进阶技术 2.1 动态网页抓取 2.2 异步编程与并发 2.3 反爬虫机制与应对 第三部分:实践案例 第四部分:法律与道德考量 第五部分&#x…...

智启万象|挖掘广告变现潜力,保障支付安全便捷
谷歌致力于为开发者提供 先进的广告变现与支付解决方案 一起回顾 2024 Google 开发者大会 了解如何利用谷歌最新工具和功能 提高变现收入,优化用户体验,保障交易安全 让变现更上一层楼 广告检查器是谷歌 AdMob 平台最新推出的高级测试工具,开…...
函数递归,匿名、内置行数,模块和包,开发规范
一、递归与二分法 一)递归 1、递归调用的定义 递归调用:在调用一个函数的过程中,直接或间接地调用了函数本身 2、递归分为两类:直接与间接 #直接 def func():print(from func)func()func() # 间接 def foo():print(from foo)bar…...

Springboot3 整合swagger
一、pom.xml <dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-api</artifactId><version>2.1.0</version></dependency> 二、application.yml # SpringDoc配置 # springdoc:swa…...

查看同一网段内所有设备的ip
使用命令提示符(CMD)进行扫描 查看本机IP地址 首先通过 ipconfig /all 命令查看本机的IP地址,确定你的网段,例如 192.168.1.。 Ping网段内每个IP地址 接着使用循环命令: for /L %i IN (1,1,254) DO ping -w 1 -n …...

Spark MLlib 特征工程(上)
文章目录 Spark MLlib 特征工程(上)特征工程预处理 Encoding:StringIndexer特征构建:VectorAssembler特征选择:ChiSqSelector归一化:MinMaxScaler模型训练总结Spark MLlib 特征工程(上) 前面我们一起构建了一个简单的线性回归模型,来预测美国爱荷华州的房价。从模型效果来…...

《SPSS零基础入门教程》学习笔记——03.变量的统计描述
文章目录 3.1 连续变量(1)集中趋势(2)离散趋势(3)分布特征 3.2 分类变量(1)单个分类变量(2)多个分类变量 3.1 连续变量 (1)集中趋势 …...
职业技能竞赛的通知)
2024年杭州市网络与信息安全管理员(网络安全管理员)职业技能竞赛的通知
2024年杭州市网络与信息安全管理员(网络安全管理员)职业技能竞赛的通知 一、组织机构 本次竞赛由杭州市总工会牵头,杭州市人力资源和社会保障局联合主办,杭州市萧山区总工会承办,浙江省北大信息技术高等研究院协办。…...

SpringBoot参数校验详解
前言 在web开发时,对于请求参数,一般上都需要进行参数合法性校验的,原先的写法时一个个字段一个个去判断,这种方式太不通用了,Hibernate Validator 是 Bean Validation 规范的参考实现,用于在 Java 应用中…...
算法)
安全基础学习-SHA-1(Secure Hash Algorithm 1)算法
SHA-1(Secure Hash Algorithm 1)是一种密码学哈希函数,用于将任意长度的输入数据(消息)转换成一个固定长度的输出(哈希值或摘要),长度为160位(20字节)。SHA-1的主要用途包括数据完整性验证、数字签名、密码存储等。 1、SHA-1 的特性 定长输出:无论输入数据长度是多…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...