Oracle(70)如何优化SQL查询?
优化SQL查询是数据库管理的重要部分,旨在提高查询性能,减少响应时间和资源消耗。以下是一些常见的SQL查询优化技术,结合代码示例详细说明。
1. 使用索引
索引是优化查询性能的最常见方法之一。索引可以显著减少数据检索的时间。
示例
假设有一个名为employees的表,包含以下字段:emp_id、emp_name、emp_department。
CREATE TABLE employees (emp_id NUMBER PRIMARY KEY,emp_name VARCHAR2(50),emp_department VARCHAR2(50)
);
创建索引:
CREATE INDEX idx_emp_department ON employees(emp_department);
使用索引的查询:
SELECT * FROM employees WHERE emp_department = 'IT';
2. 避免SELECT *
使用具体的列名代替SELECT *,减少不必要的数据传输。
示例
不推荐:
SELECT * FROM employees WHERE emp_department = 'IT';
推荐:
SELECT emp_id, emp_name FROM employees WHERE emp_department = 'IT';
3. 使用表别名
使用表别名可以使查询更简洁,特别是在多表连接时。
示例
SELECT e.emp_id, e.emp_name, d.dept_name
FROM employees e
JOIN departments d ON e.emp_department = d.dept_id
WHERE d.dept_name = 'IT';
4. 避免冗余的列和表
只选择需要的列和表,避免冗余的数据。
示例
假设有一个名为employees和departments的表:
CREATE TABLE employees (emp_id NUMBER PRIMARY KEY,emp_name VARCHAR2(50),emp_department NUMBER
);CREATE TABLE departments (dept_id NUMBER PRIMARY KEY,dept_name VARCHAR2(50)
);
不推荐:
SELECT e.*, d.*
FROM employees e
JOIN departments d ON e.emp_department = d.dept_id;
推荐:
SELECT e.emp_id, e.emp_name, d.dept_name
FROM employees e
JOIN departments d ON e.emp_department = d.dept_id;
5. 使用EXISTS替代IN
在某些情况下,EXISTS比IN性能更好。
示例
不推荐:
SELECT emp_id, emp_name
FROM employees
WHERE emp_department IN (SELECT dept_id FROM departments WHERE dept_name = 'IT');
推荐:
SELECT emp_id, emp_name
FROM employees e
WHERE EXISTS (SELECT 1 FROM departments d WHERE d.dept_id = e.emp_department AND d.dept_name = 'IT');
6. 合理使用JOIN
使用合适的JOIN类型(INNER JOIN, LEFT JOIN, RIGHT JOIN)来减少不必要的数据处理。
示例
不推荐:
SELECT e.emp_id, e.emp_name, d.dept_name
FROM employees e
LEFT JOIN departments d ON e.emp_department = d.dept_id
WHERE d.dept_name = 'IT';
推荐:
SELECT e.emp_id, e.emp_name, d.dept_name
FROM employees e
JOIN departments d ON e.emp_department = d.dept_id
WHERE d.dept_name = 'IT';
7. 使用适当的WHERE条件
确保WHERE条件使用了索引,并且条件顺序合理。
示例
假设有一个包含hire_date字段的employees表:
CREATE INDEX idx_hire_date ON employees(hire_date);
推荐:
SELECT emp_id, emp_name
FROM employees
WHERE hire_date > TO_DATE('2021-01-01', 'YYYY-MM-DD');
8. 分析执行计划
使用数据库提供的工具分析查询的执行计划,找出潜在的瓶颈。
示例(Oracle)
EXPLAIN PLAN FOR
SELECT emp_id, emp_name
FROM employees
WHERE emp_department = 'IT';SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
9. 分区表
对于大表,使用分区表可以显著提高查询性能。
示例
假设有一个名为sales的表,按年份分区:
CREATE TABLE sales (sale_id NUMBER PRIMARY KEY,sale_date DATE,amount NUMBER
)
PARTITION BY RANGE (sale_date) (PARTITION p_2021 VALUES LESS THAN (TO_DATE('2022-01-01', 'YYYY-MM-DD')),PARTITION p_2022 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD'))
);
查询特定分区的数据:
SELECT sale_id, amount
FROM sales
WHERE sale_date BETWEEN TO_DATE('2021-01-01', 'YYYY-MM-DD') AND TO_DATE('2021-12-31', 'YYYY-MM-DD');
10. 使用缓存
利用数据库缓存机制,避免重复读取相同的数据。
示例
在Oracle中,可以使用RESULT_CACHE提示:
SELECT /*+ RESULT_CACHE */ emp_id, emp_name
FROM employees
WHERE emp_department = 'IT';
总结
SQL查询优化是一个复杂的过程,通常需要结合具体的应用场景和数据库特性来进行。上述方法提供了一些通用的优化技巧,通过合理使用索引、避免冗余数据、选择合适的JOIN类型、分析执行计划等,可以显著提高SQL查询的性能。
示例代码总结
使用索引
CREATE INDEX idx_emp_department ON employees(emp_department);
SELECT * FROM employees WHERE emp_department = 'IT';
避免SELECT *
SELECT emp_id, emp_name FROM employees WHERE emp_department = 'IT';
使用表别名
SELECT e.emp_id, e.emp_name, d.dept_name
FROM employees e
JOIN departments d ON e.emp_department = d.dept_id
WHERE d.dept_name = 'IT';
避免冗余的列和表
SELECT e.emp_id, e.emp_name, d.dept_name
FROM employees e
JOIN departments d ON e.emp_department = d.dept_id;
使用EXISTS替代IN
SELECT emp_id, emp_name
FROM employees e
WHERE EXISTS (SELECT 1 FROM departments d WHERE d.dept_id = e.emp_department AND d.dept_name = 'IT');
合理使用JOIN
SELECT e.emp_id, e.emp_name, d.dept_name
FROM employees e
JOIN departments d ON e.emp_department = d.dept_id
WHERE d.dept_name = 'IT';
使用适当的WHERE条件
SELECT emp_id, emp_name
FROM employees
WHERE hire_date > TO_DATE('2021-01-01', 'YYYY-MM-DD');
分析执行计划
EXPLAIN PLAN FOR
SELECT emp_id, emp_name
FROM employees
WHERE emp_department = 'IT';SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
分区表
CREATE TABLE sales (sale_id NUMBER PRIMARY KEY,sale_date DATE,amount NUMBER
)
PARTITION BY RANGE (sale_date) (PARTITION p_2021 VALUES LESS THAN (TO_DATE('2022-01-01', 'YYYY-MM-DD')),PARTITION p_2022 VALUES LESS THAN (TO_DATE('2023-01-01', 'YYYY-MM-DD'))
);SELECT sale_id, amount
FROM sales
WHERE sale_date BETWEEN TO_DATE('2021-01-01', 'YYYY-MM-DD') AND TO_DATE('2021-12-31', 'YYYY-MM-DD');
使用缓存
SELECT /*+ RESULT_CACHE */ emp_id, emp_name
FROM employees
WHERE emp_department = 'IT';
相关文章:
如何优化SQL查询?)
Oracle(70)如何优化SQL查询?
优化SQL查询是数据库管理的重要部分,旨在提高查询性能,减少响应时间和资源消耗。以下是一些常见的SQL查询优化技术,结合代码示例详细说明。 1. 使用索引 索引是优化查询性能的最常见方法之一。索引可以显著减少数据检索的时间。 示例 假设…...

深度剖析:Jenkins构建任务无法中断的原因及解决方案
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...

【YOLO】常用脚本
目录 VOC转YOLO划分训练集、测试集与验证集 VOC转YOLO import os import xml.etree.ElementTree as ETdef convert(size, box):dw 1. / size[0]dh 1. / size[1]x (box[0] box[1]) / 2.0y (box[2] box[3]) / 2.0w box[1] - box[0]h box[3] - box[2]x x * dww w * dwy…...

Springboot IOC DI理解及实现+JUnit的引入+参数配置
一、JavaConfig 我们通常使用 Spring 都会使用 XML 配置,随着功能以及业务逻辑的日益复杂,应用伴随着大量的 XML 配置文件以及复杂的 bean 依赖关系,使用起来很不方便。 在 Spring 3.0 开始,Spring 官方就已经开始推荐使用 Java…...

CeresPCL 最小二乘插值(曲线拟合)
一、简介 在多项式插值时,当数据点个数较多时,插值会导致多项式曲线阶数过高,带来不稳定因素。因此我们可以通过固定幂基函数的最高次数 m(m < n),来对我们要拟合的曲线进行降阶。之前的函数形式就可以变为: 既然是最小二乘问题,那么就仍然可以使用Ceres来进行求解。 …...

【TCP/IP】自定义应用层协议,常见端口号
互联网中,主流的是 TCP/IP 五层协议 5G/4G 上网,是有自己的协议栈,要比 TCP/IP 更复杂(能够把 TCP/IP 的一部分内容给包含进去了) 应用层 可以代表我们所编写的应用程序,只要应用程序里面用到了网络通信…...

Frida 的下载和安装
首先要安装好 python 环境 安装 frida 和 工具包 pip install frida frida-tools 查看版本: frida --version 16.4.8 然后到 github 上下载对应 server ( 和frida 的版本一致 16.4.8) Releases frida/frida (github.com) 查看手机或…...

后端开发刷题 | 链表内指定区间反转【链表篇】
描述 将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转,要求时间复杂度 O(n)O(n),空间复杂度 O(1)O(1)。 例如: 给出的链表为 1→2→3→4→5→NULL1→2→3→4→5→NULL, m2,n4 返回 1→4→3→2→5→NULL 数据范围: 链表…...

【NVMe系列-提问页与文章总结页面】
NVMe系列-提问页与文章总结页面 问题汇总NVMe协议是什么?PRP 与 PRP List是做什么的? 已写文章汇总 问题汇总 NVMe协议是什么? PRP 与 PRP List是做什么的? 已写文章汇总...

用生成器函数生成表单各字段
生成器函数生成表单字段是非常合适的用法,避免你要用纯javascript做后台时频繁的制作表单,而不能重复利用 //这里是javascript部分,formfiled.js //生成器函数对字段的处理,让各字段name\className\label\value\placeholder赋值到input的属性…...

【xilinx】O-RAN 无线电接口 - Vivado 2020.1 及更新工具版本的发行说明
描述 记录包含 O-RAN 无线电接口 LogiCORE IP 的发行说明和已知问题,包括以下内容: 一般信息已知和已解决的问题 解决方案 一般信息 可以在以下三个位置找到支持的设备: O-RAN 无线电接口 IP 产品指南(需要访问O-RAN 安全站点&…...
结营考试- 算法进阶营地 - DAY11
结营考试 - 算法进阶营地 - DAY11 测评链接; A - 打卡题 考点:枚举; 分析 枚举 a _①_ b _②_ c d,中两个运算符的 3 3 3 种可能性,尝试寻找一种符合要求的答案。 参考代码 #include <bits/stdc.h> usi…...

设计模式: 访问者模式
文章目录 一、介绍二、模式结构三、优缺点1、优点2、缺点 四、应用场景 一、介绍 Visitor 模式(访问者模式)是一种行为设计模式,它允许在不修改对象结构的前提下,增加作用于一组对象上新的操作。就增加新的操作而言,V…...

selenium底层原理详解
目录 1、selenium版本的演变 1.1、Selenium 1.x(Selenium RC时代) 1.2、Selenium 2.x(WebDriver整合时代) 1.3、Selenium 3.x 2、selenium原理说明 3、源码说明 3.1、启动webdriver服务建立连接 3.2、发送操作 1、seleni…...

【Solidity】继承
继承 Solidity 中使用 is 关键字实现继承: contract Father {function getNumber() public pure returns (uint) {return 10;}function getNumber2() public pure virtual returns (uint) {return 20;} }contract Son is Father {}现在 Son 就可以调用 Father 的 …...

docker 安装mino服务,启动报错: Fatal glibc error: CPU does not support x86-64-v2
背景 docker 安装mino服务,启动报错: Fatal glibc error: CPU does not support x86-64-v2 原因 Docker 镜像中的 glibc 版本要求 CPU 支持 x86-64-v2 指令集,而你的硬件不支持。 解决办法 降低minio对应的镜像版本 经过验证:qu…...

地图相册系统的设计与实现
摘 要 随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,各行各业相继进入信息管理时代&a…...

使用vh和rem实现元素响应式布局
示例代码 height: calc(100vh 30rem) vh(Viewport Height):vh是一个相对单位,代表浏览器窗口高度的百分比,例如20vh就是浏览器窗口高度的20%。 rem(root em):rem是通过html根元素…...
)
螺旋矩阵 II(LeetCode)
题目 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。 解题 def generateMatrix(n):matrix [[0] * n for _ in range(n)]top, bottom 0, n - 1left, right 0, n - 1num 1while top <…...

如何快速掌握一款MCU
了解MCU特点 rom ,ramgpiotimerpower 明确哪些资源是项目开发需要的 认真理解相关资料模块 开始编程 编写特别的验证程序(项目不紧)按照自己的理解编写(老司机,时间紧张) 掌握MCU基本功能 定时器 固…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...
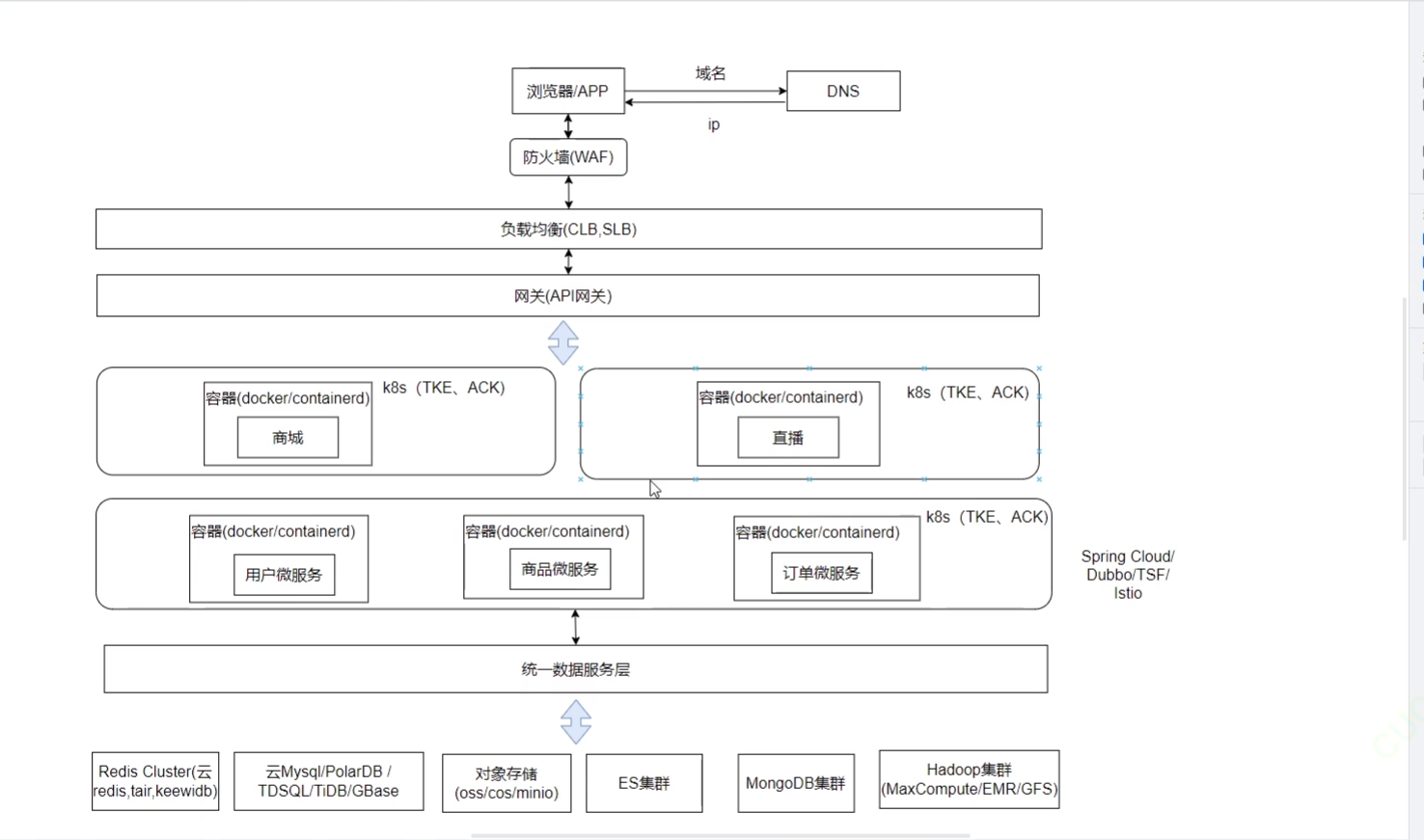
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...
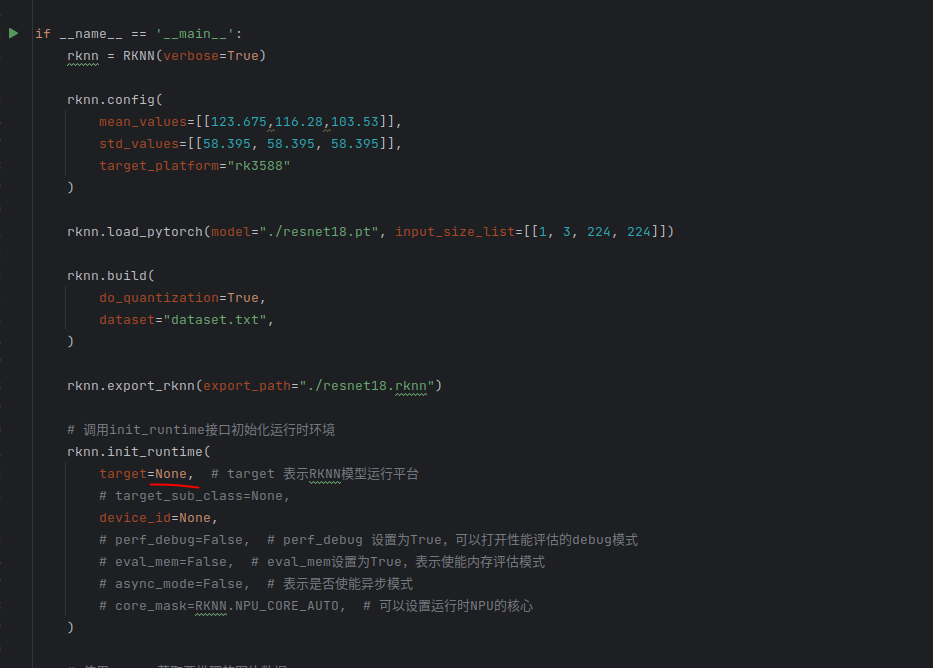
rknn toolkit2搭建和推理
安装Miniconda Miniconda - Anaconda Miniconda 选择一个 新的 版本 ,不用和RKNN的python版本保持一致 使用 ./xxx.sh进行安装 下面配置一下载源 # 清华大学源(最常用) conda config --add channels https://mirrors.tuna.tsinghua.edu.cn…...