使用C++调用PyTorch模型的弯弯绕绕,推荐LibTorch加载,C++处理
需求:使用C++调用Pytorch模型,对处理后的图像进行预测。
第一种,使用C++调用Python代码处理,使用pybind11源代码再末尾
缺点,导入Python包非常麻烦,执行的C++程序找不到cv2 torch包等等
本人解决了cv2 numpy等包,但是torch一致搞不定,大概率包不兼容导致的(pip下载的PyTorch官网,搞不懂)
明明Python’直接执行可以,但是C++调用Python执行就不行,非常奇怪
第二种,C++使用LibTorch将加载模型,进行处理源代码再末尾
这个会不用例会网络架构以及包的问题,只需将PyTorch模型保存为pt,然后使用C++加载即可,非常简单
需要重写图像处理的一些代码,保持和Python一致,输入模型进行预测。
第一种方法的经验之谈
在使用conda的环境中,conda和pip都可以下载包,两种方式最好不要混用,避免出现奇奇怪怪的错误
例如C:\ProgramData\anaconda3\DLLs_ctypes.pyd
PIL_imaging.cp311-win_amd64.pyd”。模块已生成,不包含符号。等等无法加载的错误
本人使用conda下载的,使用pip卸载后,重新使用pip装就解决了问题
cv 2,numpy,pillow等包都是如此,统一conda,或者统一使用pip,推荐使用pip
这样使用visual studio C++调用python import的包就不会出现加载不了的问题
务必注意!!!
pip install 包名==版本号
不要轻易使用conda 一键升级包,会导致部分版本太高不兼容
本人将python升级到3.11.9后,cv2版本对不上,也找不到对应版本的
冒险使用官网上最新的版本,竟然可以使用
expected np.ndarray (got numpy.ndarray)

这个问题也是numpy版本过高导致
pip install "numpy<1.26.4"就解决了
总之,版本太高就会出现各种奇奇怪怪的bug,修来修去非常浪费时间。
手动清除包缓存,可以使用以下命令:
pip cache purge
这个命令会清除所有缓存,包括已下载但未安装的软件包和已安装但未被使用的缓存。
只想清除特定软件包的缓存,可以使用以下命令:
pip cache remove package-name
第二种
在C++部署Pytorch(Libtorch)模型的方法总结(Win10+VS2017)
读取torchlib文件夹所有的lib文件的python代码
import osdef list_lib_files(directory):try:# 获取目录中的所有文件和文件夹files_and_dirs = os.listdir(directory)# 筛选出以“lib”结尾的文件lib_files = [f for f in files_and_dirs if f.endswith('.lib')]# 打印每个文件的全名for file_name in lib_files:print(file_name)except Exception as e:print(f"发生错误: {e}")
directory_path = r'C:\Users\TomSawyer\Downloads\Compressed\libtorch\lib'
list_lib_files(directory_path)
asmjit.lib
c10.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
fbjni.lib
fmt.lib
kineto.lib
libprotobuf-lite.lib
libprotobuf.lib
libprotoc.lib
pthreadpool.lib
pytorch_jni.lib
sleef.lib
torch.lib
torch_cpu.lib
XNNPACK.lib
VS 配置外部DLL的引用路径【可执行文件的环境路径】
右键项目,属性->配置属性->调试->环境,在这里写入可执行文件运行时的环境路径

本人莎莎的以为要重写PyTorch模型网络架构,于是使用C++的LibTorch和gpt重写了一下,结果一致卡在load不上,非常奇怪,于是检查两个网络的架构,其实非常类似,忘记截图载下来了,就下面一张图
检查python的Pytorch模型 与 使用C++创建的LibTorch模型是否一致,先看看VGG模型长啥样

其实可以直接加载模型,pt文件里面保存了网络的架构的,无需重写,具体代码找一找就有
我之前都注释了,代码没问题的,自行理解一下
将pth保存为pt,再加载pt模型
.pt文件保存的是模型的全部,在加载时可以直接赋值给新变量model = torch.load(“filename.pt”)。
.pth保存的是模型参数,通过字符字典进行保存,在加载该类文件时应该先实例化一个具体的模型,然后对新建立的空模型,进行参数赋予。
import os
import cv2
from PIL import Image
from torchvision import transforms as T
import torchload_model_path = "./checkpoints/Cnn.pth"
model = getattr(models, "Cnn")()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
model.load(load_model_path)
model.eval()var=torch.ones((1,3,224,224))
traced_script_module = torch.jit.trace(model, var)
traced_script_module.save("./checkpoints/Cnn.pt")# 测试pt模型
model_pt = torch.load("./checkpoints/Cnn.pt")
model_pt.to(device)
model_pt.eval()
将Python保存的pth模型与pt模型进行对比,看看保存的两个模型是否有差异,没有任何差异

使用C++实现Python的图像处理部分,看看实现是否有差异,发现数值类似,略有差异
猜测可能是摄像头保存一帧 与 C++读取图像的不同所引起的,于是使用Python读取图像试试
发现结果一致了,原来是保存为jpg格式带来的有损压缩导致的
统一保存为png格式即可,无损格式

全部代码
Python使用Pytorch加载模型,处理图像,模型预测结果(模型是错的,只是走个流程)
import os
import cv2
from PIL import Image
from torchvision import transforms as T
import models
import datetime
import torch# 创建保存图像的文件夹
if not os.path.exists('testModel'):os.makedirs('testModel')# 1 先使用摄像头读取一帧图像,保存
# 0,读取摄像头保存的图片
flag = 0
if flag==1:cap = cv2.VideoCapture(0)if not cap.isOpened():print("无法打开摄像头")else:# 读取一帧图像ret, frame = cap.read()if ret:# 保存原始图像original_image_path = 'testModel/test1_original_image.png'cv2.imwrite(original_image_path, frame)print(f"原始图像已保存到 {original_image_path}")# 释放摄像头资源cap.release()
else:##读取摄像头保存的一帧画面frame =cv2.imread('testModel/test1_original_image.png');"""此类主要提供模型调用方法,接受一个图片,同时返回一个力的结果
"""
model_list = os.listdir("./checkpoints/")
# load_model_path = "./checkpoints/"+ model_list[0]
load_model_path = "./checkpoints/Cnn.pth"
model = getattr(models, "Cnn")()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
model.load(load_model_path)
model.eval()# 测试pt模型
model_pt = torch.load("./checkpoints/Cnn.pt")
model_pt.to(device)
model_pt.eval()# veision1 预定义图像处理模式,图像预处理设置,正态化数据来自于图片空间,因此需要Normalize.py获取,此处已指定
normalize = T.Normalize(mean=[0.684, 0.831, 0.83],std=[0.684, 0.831, 0.83])
transform = T.Compose([T.ToTensor(),# normalize]
)img = frame
cv2.imshow(" ", img)
cv2.waitKey(0)
img=cv2.resize(img,[640,360])
# 裁剪图像,保留从第170列到第530列的区域
img=img[::,170:530,::] #样品1
cv2.imshow(" ", img)
cv2.waitKey(0)
# 保存处理后的图像
processed_image_path = 'testModel/test1_processed_image.png'
cv2.imwrite(processed_image_path, img)
print(f"处理后的图像已保存到 {processed_image_path}")img = Image.fromarray(img)
img = transform(img)
img = img.view(1, img.shape[0], img.shape[1], img.shape[2])#改变张量的形状,但不会改变其数据 第一、第二、第三和第四维度大小。
train = img.to(device)
force= model(train)
force = force.squeeze().detach().cpu()
force_act = force.tolist()
# 时间格式为分钟:秒.微秒
force_act.append(datetime.datetime.now().strftime("%M:%S.%f"))
# force_act为输出力的列表格式【f(x),f(y),f(z),时间】
print('pth模型结果:',force_act)force_pt= model_pt(train)
force_pt = force_pt.squeeze().detach().cpu()
force_act_pt = force_pt.tolist()
# 时间格式为分钟:秒.微秒
force_act_pt.append(datetime.datetime.now().strftime("%M:%S.%f"))
# force_act为输出力的列表格式【f(x),f(y),f(z),时间】
print('pt模型结果:',force_act_pt)
C++加载torch script保存的pt模型,重新实现图像处理,给出结果
#include <torch/torch.h>
#include <torch/script.h>
#include <string>
#include <iostream>
#include <opencv2/opencv.hpp>// 假设你已经定义了transform函数
torch::Tensor transform(const cv::Mat &img) {// 这里需要根据你的transform逻辑来实现// 例如,假设你只是将图像转换为Tensortorch::Tensor tensor_image = torch::from_blob(img.data, { img.rows, img.cols, img.channels() }, torch::kFloat32);将OpenCV图像数据(存储在img.data中)转换为一个PyTorch张量,张量的形状为[img.rows, img.cols, img.channels()],数据类型为kFloat32tensor_image = tensor_image.permute({ 2, 0, 1 }).to(torch::kFloat); // 转换为CHW格式并转换为Float类型return tensor_image;
}int test_pt() {// 假设模型路径和加载方式torch::jit::script::Module module;try {module = torch::jit::load(R"(C:\Users\TomSawyer\source\repos\testPython\force_indentify\checkpoints\Cnn.pt)");} catch (const c10::Error &e) {std::cerr << "Error loading the model\n";return {};}// 检查CUDA是否可用bool is_cuda = torch::cuda::is_available();torch::Device device(is_cuda ? torch::kCUDA : torch::kCPU);std::cout << (is_cuda ? "CUDA is available. Using GPU." : "Using CPU.") << std::endl;module.to(device);module.eval();// 指定图像路径std::string imagePath = R"(C:\Users\TomSawyer\source\repos\testPython\force_indentify\testModel\test1_original_image.png)";while (1) {cv::Mat frame = cv::imread(imagePath, cv::IMREAD_COLOR);// 检查图像是否加载成功if (frame.empty()) {std::cerr << "无法加载图片,请检查路径: " << imagePath << std::endl;return -1;}// 显示图片cv::imshow("Loaded Image", frame);cv::waitKey(0);cv::resize(frame, frame, cv::Size(640, 360));cv::imshow("frame", frame);cv::waitKey(0);frame = frame(cv::Rect(170, 0, 360, 360)); // 裁剪图像170到360列cv::imshow("frame", frame);cv::waitKey(0);frame.convertTo(frame, CV_32FC3, 1.0 / 255.0);// 应用transformtorch::Tensor tensor_image = transform(frame);// 调整形状tensor_image = tensor_image.unsqueeze(0); // 增加batch维度tensor_image = tensor_image.to(device);// 模型预测std::vector<torch::jit::IValue> inputs;inputs.push_back(tensor_image);at::Tensor output = module.forward(inputs).toTensor();//bugoutput = output.squeeze().detach().cpu();std::vector<float> force_act = { output[0].item<float>(), output[1].item<float>(), output[2].item<float>() };std::cout << "pt_Force: " << force_act[0] << ", " << force_act[1] << ", " << force_act[2] << std::endl;}return {};
}int main() {test_pt(); //测试pt模型和python的pthreturn 0;
}
pybind11,运行一直没解决,cv2,numpy包解决了,Torch包一直搞不定
#include <pybind11/pybind11.h>
#include <pybind11/embed.h>
#include <iostream>
#include <cstdlib> // for _putenvnamespace py = pybind11;int main() {// 设置 Python 解释器的路径为 Conda 环境std::string pythonHome = R"(C:\ProgramData\anaconda3)";std::string pythonHomeEnv = "PYTHONHOME=" + pythonHome;_putenv(pythonHomeEnv.c_str());// 设置 Python 路径std::string pythonPath = R"(C:\ProgramData\anaconda3\Lib\site-packages;C:\Users\TomSawyer\source\repos\testPython\force_indentify;)";std::string pythonPathEnv = "PYTHONPATH=" + pythonPath;_putenv(pythonPathEnv.c_str());// 添加 PATH 环境变量std::string path = R"(C:\ProgramData\anaconda3\Library\bin;)";std::string pathEnv = "PATH=" + path + ";" + getenv("PATH");_putenv(pathEnv.c_str());//std::cout << "PythonHome: " << pythonHomeEnv << std::endl;//std::cout << "PythonPath: " << pythonPathEnv << std::endl;std::cout << "PATH: " << getenv("PATH")<< std::endl;// 初始化 Python 解释器py::scoped_interpreter guard{};//在使用 pybind11 导入 Python 模块时,路径的指定方式需要注意。通常情况下,Python 模块的导入路径应该是模块的名称,而不是文件的绝对路径// 添加模块路径到 sys.pathpy::module::import("sys").attr("path").attr("append")(R"(C:\Users\TomSawyer\source\repos\testPython\force_indentify;C:\Users\TomSawyer\source\repos\testPython\force_indentify\models)");//std::cout <<std::endl <<"PATH: " << getenv("PATH") << std::endl;// 导入 Python 模块py::module script = py::module::import("interface_single");// 调用 Python 函数并获取返回的列表py::object result = script.attr("inter")();py::list py_list = result.cast<py::list>();// 将 Python 列表转换为 C++ 向量std::vector<int> cpp_list;for (auto item : py_list) {cpp_list.push_back(item.cast<int>());}// 处理 C++ 向量for (int value : cpp_list) {std::cout << value << " ";}std::cout << std::endl;return 0;
}
相关文章:
使用C++调用PyTorch模型的弯弯绕绕,推荐LibTorch加载,C++处理
需求:使用C调用Pytorch模型,对处理后的图像进行预测。 第一种,使用C调用Python代码处理,使用pybind11源代码再末尾 缺点,导入Python包非常麻烦,执行的C程序找不到cv2 torch包等等 本人解决了cv2 numpy等包&…...

实现异形(拱形)轮播图
项目需要实现如上图所示的轮播图。 实现思路: 1.项目引入使用普通轮播图。 2.根据轮播图个数,动态给可视范围的第一个轮播图和最后一个轮播图添加样式。 代码实现: 经调研,使用slick轮播图(官网地址 https://kenwheel…...

【软件测试】2024年职业院校技能大赛高职组“软件测试”赛项样题
目录 任务一:功能测试(45 分) 任务二:自动化测试(15 分) 任务三:性能测试(15 分) 任务四:单元测试(10 分) 任务五:接…...

python数组和队列
一、数组 如果一个列表只包含数值,那么使用array.array会更加高效,数组不仅支持所有可变序列操作(.pop、.insert、.extent等),而且还支持快速加载项和保存项的方法(.fromfile、.tofile等) 创建…...
Vision Transformer(ViT)一种将Transformer架构应用于计算机视觉领域的模型
Vision Transformer(ViT)是一种将Transformer架构应用于计算机视觉领域的模型,它通过自注意力机制处理图像数据,与传统的卷积神经网络(CNN)相比,ViT能够更好地捕捉全局依赖关系。以下是对ViT的详…...

得到任务式 大模型应用开发学习方案
根据您提供的文档内容以及您制定的大模型应用开发学习方案,我们可以进一步细化任务式学习的计划方案。以下是具体的任务式学习方案: 任务设计 初级任务 大模型概述:阅读相关资料,总结大模型的概念、发展历程和应用领域。深度学…...

使用el-menu跳转时偶尔会出现路由已经变了,但是页面却显示空白的情况
刚开始我以为是我数据加载的问题,后来又看有人说是template里不能包多个div,但我去看我出错的组件,并没有出现两个div。 后来我就把每个都给改了,即使是elemen-ui的标签也全部改在一个div里,就发现没问题了。 我改的…...
)
C语言家教记录(七)
C语言家教记录(七) 导语字符串字面量变量读写字符串操作函数惯用法数组 结构联合枚举总结与复习 导语 本次授课的内容如下:字符串,结构体、联合体、枚举 辅助教材为 《C语言程序设计现代方法(第2版)》 字…...

【数据结构】——十大排序详解分析及对比
【数据结构】——十大排序详解分析及对比 文章目录 【数据结构】——十大排序详解分析及对比前言1. 排序的概念及其运用1.1 排序的概念1.2 排序的应用 2. 插入排序2.1 直接插入排序2.2 希尔排序 3. 选择排序3.1 选择排序3.2 堆排序 4 交换排序4.1 冒泡排序4.2 快速排序4.2.1 霍…...
散点图适用于什么数据 thinkcell散点图设置不同颜色
在数据可视化的众多工具和技巧中,散点图是一种极为有效的方式,能够揭示变量之间的关系,尤其是在探索数据集的相关性、分布趋势、集群现象时。而在众多助力于制作高质量散点图的工具中,think-cell插件以其高效的操作和丰富的功能&a…...
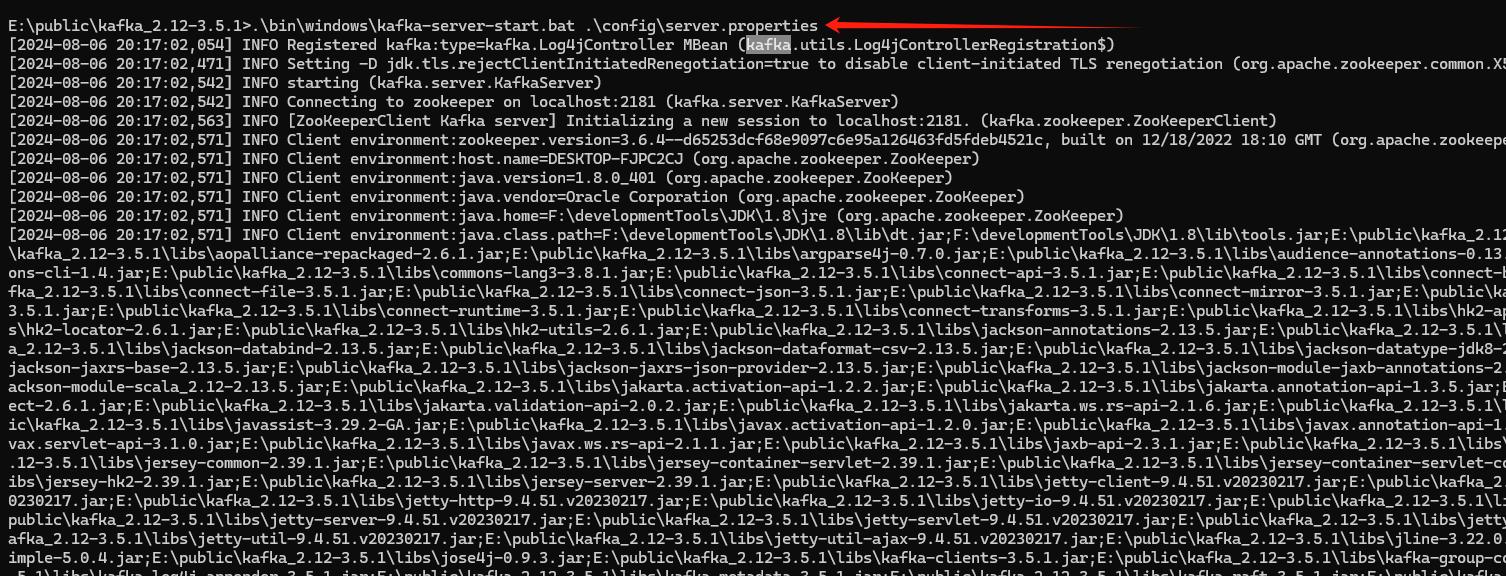
1. windows搭建Kafka教程
目录 1. 部署zookeeper 1.1 下载地址 1.3 修改zoo配置 1.4 启动zookeepe服务 02 部署kafka 2.1 下载组件包 2.2 解压安装包 2.3 修改配置 2.4 启动kafka服务端 1. 部署zookeeper 1.1 下载地址 下载地址: kafka/zookeeper 下载地址 (qq.com) 1.2 解压 (…...

XSS复现
目录 XSS简单介绍 一、反射型 1、漏洞逻辑: 为什么有些标签可以触发,有些标签不能触发 可以触发的标签 不能触发的标签 为什么某些标签能触发而某些不能 二、DOM型 1、Ma Spaghet! 要求: 分析: 结果: 2、J…...

怎么利用XML发送视频彩信
传统的短信推广主要以文字为主,用户接收到的信息往往显得单调乏味。而视频彩信则不同,它结合了视频和音频的优势,通过生动的画面和悦耳的音乐,给用户带来强烈的视听冲击,从而极大地提高了用户的吸引力。 XML成功返回示…...

5G+工业互联网产教融合创新实训室解决方案
一、建设背景 随着第五代移动通信技术(5G)的快速普及和工业互联网的迅猛发展,全球制造业正面临着前所未有的深刻变革。5G技术凭借其超高的传输速率、极低的延迟以及大规模的连接能力,为工业自动化、智能制造等领域带来了革命性的…...

象棋布局笔记
文章目录 布局中炮(当头炮)当头炮的缺点如何应对平车压马平炮对车的理解中炮对屏风马急进中兵 中炮盘头马盘头马两翼突破 盖马三锤 反宫马克制反宫马 顺手炮 士角炮56炮破解56炮 小当头 屏风马7卒分支3卒分支屏风马红车二进六败招(黑未挺7卒前直接进车)马八进九变车三退一变马二…...

百度AI智能云依赖库OpenSSL库和Curl库及jsoncpp库安装
开发百度AI项目时,需要用到https协议,因此需要安装OpenSSl和curl库。 若只安装curl库,只支持http协议,不支持https协议。此外,还需要jsoncpp库,用以组包及解析与百度AI通信的json格式协议。 1.Ubuntu上安装…...

智慧空调离线语音控制方案:NRK3301芯片的深度解析与应用
随着AI技术的大爆发和智能家居的风潮,语音交互已成为智能家居产品的一项必备技能,在家电、音箱、穿戴设备乃至墙壁开关等贴近生活的产品中应用越来越广泛,智能语音识别是当前最热门的方案之一。 九芯智能顺应家居行业智能语音交互市场需求&a…...

基础第3关:LangGPT结构化提示词编写实践
提示词: # Role: 伟大的数学家 ## Profile - author: LangGPT - version: 1.0 - language: 中文 - description: 一个伟大的数学家,能够解决任何的数学难题 ## Goals: 根据关键词进行描述,避免与已有描述重复。 ## Background: 你正在被…...

Nginx系列-负载均衡
文章目录 Nginx系列-负载均衡1. 负载均衡基础1.1 负载均衡定义1.2 Nginx负载均衡原理 2. 负载均衡策略2.1 轮询(Round Robin)2.2 加权轮询(Weighted Round Robin)2.3 IP哈希(IP Hash)2.4 最少连接ÿ…...
中职物联网实训室
一、中职物联网实训室建设背景 在当今科技日新月异的浪潮中,物联网技术以其迅猛的发展势头,成为了撬动数字化转型的关键杠杆,深刻地重塑着经济社会的面貌。面对这一变革,社会对精通物联网技术的应用型人才需求激增。鉴于此&#x…...

Timer-S1 正式发布:首个十亿级时序基础模型,预测性能达到 SOTA
本文约3600字,建议阅读5分钟十亿级规模化的突破,首次将时间序列预测的串行本质,融入模型架构、数据、训练全流程!在 AI 全面渗透各行业的背景下,工业企业对时序数据的应用需求已从基础查询计算,升级为设备状…...
HSTracker:精准追踪炉石传说对战数据的macOS智能辅助工具
HSTracker:精准追踪炉石传说对战数据的macOS智能辅助工具 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker HSTracker是一款专为macOS平台设计的开源炉石传说辅…...

网络舆情分析毕业设计:从数据采集到情感识别的技术实现与避坑指南
最近在帮学弟学妹们看网络舆情分析相关的毕业设计,发现大家普遍在几个地方卡壳:要么爬虫被封IP,数据拿不到;要么文本预处理一团糟,模型效果差;要么整个系统耦合在一起,改一处动全身,…...
Pixel Fashion Atelier入门必看:Forge!按钮物理位移反馈的CSS3实现原理
Pixel Fashion Atelier入门必看:Forge!按钮物理位移反馈的CSS3实现原理 1. 引言:像素世界的物理交互 在Pixel Fashion Atelier这款独特的图像生成工具中,最令人印象深刻的莫过于那个醒目的橙色"锻造"按钮。当用户点击时ÿ…...

Elasticsearch IK 分词器远程词典
一、背景 在使用 Elasticsearch IK 分词器进行中文检索时,默认词库往往无法覆盖业务中的专业词汇(如:知识库、RAG架构、向量检索等)。 如果不进行扩展,这些词可能被错误拆分,导致: 检索结果不准…...
截稿提醒)
中国举办,IEEE会议,录用率39.5%!CCF推荐学术会议(C)截稿提醒
►►►Globecom 2026IEEE Global Communications Conference (GLOBECOM), a flagship IEEE Communications Society event, gathers top experts to drive innovation and advance nearly every aspect of communications technology. Each year, thousands of the most ground…...

kali制作木马
黑客必备工具:Metasploit Framework(MSF)1. 生成木马程序: > msfvenom -p linux/x64/shell/reverse_tcp LHOST攻击机ip(Kali) LPORT9999 -f elf -o shell.elf2. 启动控制程序: > msfconsole > use exploit/mu…...

1771-OZL处理器模块
1771-OZL 处理器模块 — 产品特点1771-OZL 是1771系列的PLC处理器模块,用于工业自动化系统的逻辑运算与过程控制。适用于PLC-5标准机架控制系统支持数字量输入/输出及模拟量接口内置高速逻辑运算功能可执行顺序控制和定时/计数功能支持程序存储与在线修改高可靠性设…...

sklearn分类指标实战:如何用precision_recall_curve优化你的模型效果
sklearn分类指标实战:如何用precision_recall_curve优化模型效果 在机器学习项目中,分类模型的评估往往比训练过程更考验数据科学家的专业素养。当你的模型在测试集上达到95%的准确率时,是否就意味着可以高枕无忧?现实情况往往复杂…...

机械键盘连击修复:这款智能工具如何拯救你的打字体验
机械键盘连击修复:这款智能工具如何拯救你的打字体验 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 当你在编写重要文档时&…...