PyTorch 基础学习(10)- Transformer
系列文章:
《PyTorch 基础学习》文章索引
介绍
Transformer模型是近年来在自然语言处理(NLP)领域中非常流行的一种模型架构,尤其是在机器翻译任务中表现出了优异的性能。与传统的循环神经网络(RNN)不同,Transformer模型完全基于注意力机制,避免了序列处理中的长距离依赖问题。本教程将通过一个简单的实例,详细讲解如何在PyTorch中实现一个基于Transformer的机器翻译模型。
Transformer的原理简介
Transformer模型由Vaswani等人在2017年提出,其核心思想是利用注意力机制来捕捉输入序列中的长程依赖关系。模型主要包括两个模块:编码器(Encoder)和解码器(Decoder)。每个模块由多个层(Layer)堆叠而成,每一层又包含多个子层(Sub-layer),如自注意力机制(Self-Attention)、前馈神经网络(Feed-Forward Neural Network)等。
1. 自注意力机制(Self-Attention)
自注意力机制是Transformer的核心,主要用于计算输入序列中各元素之间的相互依赖关系。通过自注意力机制,模型可以在每一步中考虑到整个序列的信息,而不是仅仅依赖于固定的上下文窗口。
2. 多头注意力机制(Multi-Head Attention)
多头注意力机制是对自注意力机制的扩展,通过引入多个注意力头(Attention Heads),模型可以在不同的子空间中独立地计算注意力,从而捕捉到输入序列中更多的特征。
3. 前馈神经网络(Feed-Forward Neural Network)
在每个编码器和解码器层中,注意力机制后接一个前馈神经网络。该网络在每个时间步上独立应用于序列中的每一个位置。
4. 残差连接与层归一化(Residual Connection & Layer Normalization)
为了缓解梯度消失的问题,Transformer模型在每个子层之间使用了残差连接,并在每个子层后使用层归一化。
实例代码及讲解
下面我们将通过一个简单的示例代码,详细讲解如何在PyTorch中实现一个基于Transformer的句子推理。
1. 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.nn.utils.rnn import pad_sequence
import numpy as np
2. 定义数据集类
class TranslationDataset(Dataset):def __init__(self, source_sentences, target_sentences, src_vocab, tgt_vocab):self.source_sentences = source_sentencesself.target_sentences = target_sentencesself.src_vocab = src_vocabself.tgt_vocab = tgt_vocabdef __len__(self):return len(self.source_sentences)def __getitem__(self, idx):src = [self.src_vocab[word] for word in self.source_sentences[idx].split()]tgt = [self.tgt_vocab[word] for word in self.target_sentences[idx].split()]return torch.tensor(src), torch.tensor(tgt)
TranslationDataset类继承自Dataset,用于处理机器翻译任务中的数据集。__getitem__方法根据索引idx返回源句子和目标句子的张量表示。
3. 定义collate_fn函数
def collate_fn(batch):src_batch, tgt_batch = zip(*batch)src_batch = pad_sequence(src_batch, padding_value=0, batch_first=True)tgt_batch = pad_sequence(tgt_batch, padding_value=0, batch_first=True)return src_batch, tgt_batch
collate_fn函数用于将一个批次的数据进行填充,使得每个批次的源句子和目标句子长度一致。
4. 定义Transformer模型
class TransformerModel(nn.Module):def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6,dim_feedforward=2048, dropout=0.1):super(TransformerModel, self).__init__()self.embedding_src = nn.Embedding(src_vocab_size, d_model)self.embedding_tgt = nn.Embedding(tgt_vocab_size, d_model)self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward,dropout)self.fc_out = nn.Linear(d_model, tgt_vocab_size)self.d_model = d_modeldef forward(self, src, tgt):src = self.embedding_src(src) * np.sqrt(self.d_model)tgt = self.embedding_tgt(tgt) * np.sqrt(self.d_model)src = src.permute(1, 0, 2)tgt = tgt.permute(1, 0, 2)output = self.transformer(src, tgt)output = self.fc_out(output)return outputdef generate(self, src, max_len, sos_idx):self.eval()src = self.embedding_src(src) * np.sqrt(self.d_model)src = src.permute(1, 0, 2) # [sequence_length, batch_size, d_model]memory = self.transformer.encoder(src)# 初始化解码器输入,开始标记ys = torch.ones(1, 1).fill_(sos_idx).type(torch.long).to(src.device)for i in range(max_len - 1):tgt = self.embedding_tgt(ys) * np.sqrt(self.d_model)tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size(0)).to(src.device)out = self.transformer.decoder(tgt, memory, tgt_mask=tgt_mask)out = self.fc_out(out)prob = out[-1, :, :].max(dim=-1)[1]ys = torch.cat([ys, prob.unsqueeze(0)], dim=0)if prob == 2: # <eos> token indexbreakreturn ys.transpose(0, 1)
TransformerModel类继承自nn.Module,封装了Transformer模型。forward方法定义了模型的前向传播逻辑,包括对源句子和目标句子进行嵌入、通过Transformer层处理,以及通过线性层输出预测结果。generate方法用于推理,生成翻译结果。
5. 训练和评估函数
def train(model, dataloader, optimizer, criterion, num_epochs=10):model.train()for epoch in range(num_epochs):epoch_loss = 0for src, tgt in dataloader:tgt_input = tgt[:, :-1]tgt_output = tgt[:, 1:]optimizer.zero_grad()output = model(src, tgt_input)output = output.view(-1, output.shape[-1])tgt_output = tgt_output.reshape(-1)loss = criterion(output, tgt_output)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)optimizer.step()epoch_loss += loss.item()print(f'Epoch {epoch + 1}, Loss: {epoch_loss / len(dataloader)}')def evaluate(model, dataloader, criterion):model.eval()total_loss = 0with torch.no_grad():for src, tgt in dataloader:tgt_input = tgt[:, :-1]tgt_output = tgt[:, 1:]output = model(src, tgt_input)output = output.view(-1, output.shape[-1])tgt_output = tgt_output.reshape(-1)loss = criterion(output, tgt_output)total_loss += loss.item()print(f'Evaluation Loss: {total_loss / len(dataloader)}')
train函数用于训练模型,逐批处理数据,计算损失,并更新模型参数。evaluate函数用于评估模型的性能,计算整个数据集的平均损失。
6. 推理函数
def inference(model, src_sentence, src_vocab, tgt_vocab, max_len=2):model.eval()src_indexes = [src_vocab[word] for word in src_sentence.split()]src_tensor = torch.LongTensor(src_indexes).unsqueeze(0).to(next(model.parameters()).device) # 确保是 LongTensor 类型sos_idx = tgt_vocab["<sos>"]generated_tensor = model.generate(src_tensor, max_len, sos_idx)generated_sentence = ' '.join([list(tgt_vocab.keys())[i] for i in generated_tensor.squeeze().tolist()])return generated_sentence
inference函数用于对单个句子进行翻译,生成对应的目标句子。
7. 运行示例
if __name__ == "__main__":# 假设我们有一个简单的词汇表和句子对vocab = {"<pad>": 0,"<sos>": 1,"<eos>": 2,"hello": 3,"world": 4,"good": 5,"morning": 6,"night": 7,"how": 8,"are": 9,"you": 10,"today": 11,"friend": 12,"goodbye": 13,"see": 14,"take": 15,"care": 16,"welcome": 17,"back": 18}sentences = ["hello world","good morning","goodbye friend","see you","take care","welcome back",]src_vocab = vocabtgt_vocab = vocabsource_sentences = sentencestarget_sentences = sentences# 创建数据集和数据加载器dataset = TranslationDataset(source_sentences, target_sentences, src_vocab, tgt_vocab)dataloader = DataLoader(dataset, batch_size=2, shuffle=True, collate_fn=collate_fn)# 模型初始化model = TransformerModel(len(src_vocab), len(tgt_vocab))optimizer = optim.Adam(model.parameters(), lr=0.0001)criterion = nn.CrossEntropyLoss(ignore_index=0)# 训练模型train(model, dataloader, optimizer, criterion, num_epochs=20)# 评估模型evaluate(model, dataloader, criterion)# 推理测试test_sentence = "hello"translated_sentence = inference(model, test_sentence, src_vocab, tgt_vocab)print(f"Input: {test_sentence}")print(f"Output: {translated_sentence}")test_sentence = "see"translated_sentence = inference(model, test_sentence, src_vocab, tgt_vocab)print(f"Input: {test_sentence}")print(f"Output: {translated_sentence}")test_sentence = "welcome"translated_sentence = inference(model, test_sentence, src_vocab, tgt_vocab)print(f"Input: {test_sentence}")print(f"Output: {translated_sentence}")
在这个运行示例中,我们首先定义了一个简单的词汇表和句子对,然后创建数据集和数据加载器。接下来,我们初始化Transformer模型,设置优化器和损失函数,训练模型并进行评估。最后,通过推理函数对一些输入句子进行翻译,并输出结果。
完整代码实例
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.nn.utils.rnn import pad_sequence
import numpy as np# 定义数据集类,用于加载源语言和目标语言的句子
class TranslationDataset(Dataset):def __init__(self, source_sentences, target_sentences, src_vocab, tgt_vocab):self.source_sentences = source_sentences # 源语言句子列表self.target_sentences = target_sentences # 目标语言句子列表self.src_vocab = src_vocab # 源语言词汇表self.tgt_vocab = tgt_vocab # 目标语言词汇表def __len__(self):return len(self.source_sentences) # 返回数据集中句子的数量def __getitem__(self, idx):# 将源语言和目标语言的句子转换为词汇表中的索引src = [self.src_vocab[word] for word in self.source_sentences[idx].split()]tgt = [self.tgt_vocab[word] for word in self.target_sentences[idx].split()]return torch.tensor(src), torch.tensor(tgt) # 返回源句子和目标句子的索引张量# 定义collate_fn函数,用于在批处理中对序列进行填充
def collate_fn(batch):src_batch, tgt_batch = zip(*batch) # 将批次中的源和目标句子分开src_batch = pad_sequence(src_batch, padding_value=0, batch_first=True) # 对源句子进行填充tgt_batch = pad_sequence(tgt_batch, padding_value=0, batch_first=True) # 对目标句子进行填充return src_batch, tgt_batch # 返回填充后的源和目标句子张量# 定义Transformer模型
class TransformerModel(nn.Module):def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6,dim_feedforward=2048, dropout=0.1):super(TransformerModel, self).__init__()# 定义源语言和目标语言的嵌入层self.embedding_src = nn.Embedding(src_vocab_size, d_model)self.embedding_tgt = nn.Embedding(tgt_vocab_size, d_model)# 定义Transformer模型self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward,dropout)# 定义输出的全连接层,将Transformer的输出转换为词汇表中的分布self.fc_out = nn.Linear(d_model, tgt_vocab_size)self.d_model = d_model # d_model是嵌入向量的维度def forward(self, src, tgt):# 将源语言和目标语言的索引转换为嵌入向量,并进行缩放src = self.embedding_src(src) * np.sqrt(self.d_model)tgt = self.embedding_tgt(tgt) * np.sqrt(self.d_model)# 调整维度以适应Transformer输入的要求src = src.permute(1, 0, 2)tgt = tgt.permute(1, 0, 2)# 将源语言和目标语言嵌入输入到Transformer中output = self.transformer(src, tgt)# 使用全连接层将Transformer的输出转换为目标词汇表中的分布output = self.fc_out(output)return outputdef generate(self, src, max_len, sos_idx):self.eval() # 设置模型为评估模式# 对源语言进行嵌入并缩放src = self.embedding_src(src) * np.sqrt(self.d_model)src = src.permute(1, 0, 2) # 调整维度memory = self.transformer.encoder(src) # 通过编码器获取源语言的记忆表示# 初始化解码器输入,使用<start of sequence>标记ys = torch.ones(1, 1).fill_(sos_idx).type(torch.long).to(src.device)for i in range(max_len - 1):# 对目标语言进行嵌入并缩放tgt = self.embedding_tgt(ys) * np.sqrt(self.d_model)# 生成用于掩码的下三角矩阵,以确保模型不能看到未来的词tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size(0)).to(src.device)# 使用Transformer解码器生成输出out = self.transformer.decoder(tgt, memory, tgt_mask=tgt_mask)out = self.fc_out(out) # 通过全连接层生成词汇表的分布prob = out[-1, :, :].max(dim=-1)[1] # 选择概率最大的词作为输出# 将生成的词拼接到解码器的输入中ys = torch.cat([ys, prob.unsqueeze(0)], dim=0)if prob == 2: # 如果生成了<end of sequence>标记,则停止生成breakreturn ys.transpose(0, 1) # 返回生成的序列# 训练函数
def train(model, dataloader, optimizer, criterion, num_epochs=10):model.train() # 设置模型为训练模式for epoch in range(num_epochs):epoch_loss = 0 # 记录每个epoch的损失for src, tgt in dataloader:tgt_input = tgt[:, :-1] # 获取目标句子中除了最后一个词的部分作为输入tgt_output = tgt[:, 1:] # 获取目标句子中除了第一个词的部分作为输出optimizer.zero_grad() # 清零梯度output = model(src, tgt_input) # 前向传播计算输出output = output.view(-1, output.shape[-1]) # 将输出展平为2D张量tgt_output = tgt_output.reshape(-1) # 将目标输出展平为1D张量loss = criterion(output, tgt_output) # 计算损失loss.backward() # 反向传播计算梯度torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 对梯度进行裁剪以防止梯度爆炸optimizer.step() # 更新模型参数epoch_loss += loss.item() # 累加损失print(f'Epoch {epoch + 1}, Loss: {epoch_loss / len(dataloader)}') # 输出每个epoch的平均损失# 评估函数
def evaluate(model, dataloader, criterion):model.eval() # 设置模型为评估模式total_loss = 0 # 记录总损失with torch.no_grad(): # 在评估时不需要计算梯度for src, tgt in dataloader:tgt_input = tgt[:, :-1] # 获取目标句子中除了最后一个词的部分作为输入tgt_output = tgt[:, 1:] # 获取目标句子中除了第一个词的部分作为输出output = model(src, tgt_input) # 前向传播计算输出output = output.view(-1, output.shape[-1]) # 将输出展平为2D张量tgt_output = tgt_output.reshape(-1) # 将目标输出展平为1D张量loss = criterion(output, tgt_output) # 计算损失total_loss += loss.item() # 累加损失print(f'Evaluation Loss: {total_loss / len(dataloader)}') # 输出平均评估损失# 推理函数,用于在模型训练完毕后进行句子翻译
def inference(model, src_sentence, src_vocab, tgt_vocab, max_len=2):model.eval() # 设置模型为评估模式# 将源语言句子转换为索引序列src_indexes = [src_vocab[word] for word in src_sentence.split()]# 将索引序列转换为张量,并添加批次维度src_tensor = torch.LongTensor(src_indexes).unsqueeze(0).to(next(model.parameters()).device)sos_idx = tgt_vocab["<sos>"] # 获取<sos>标记的索引# 使用模型生成目标语言的句子generated_tensor = model.generate(src_tensor, max_len, sos_idx)# 将生成的索引序列转换为词语序列generated_sentence = ' '.join([list(tgt_vocab.keys())[i] for i in generated_tensor.squeeze().tolist()])return generated_sentence # 返回生成的句子# 示例运行
if __name__ == "__main__":# 假设我们有一个简单的词汇表和句子对vocab = {"<pad>": 0,"<sos>": 1,"<eos>": 2,"hello": 3,"world": 4,"good": 5,"morning": 6,"night": 7,"how": 8,"are": 9,"you": 10,"today": 11,"friend": 12,"goodbye": 13,"see": 14,"take": 15,"care": 16,"welcome": 17,"back": 18}sentences = ["hello world","good morning","goodbye friend","see you","take care","welcome back",]src_vocab = vocab # 源语言词汇表tgt_vocab = vocab # 目标语言词汇表source_sentences = sentences # 源语言句子列表target_sentences = sentences # 目标语言句子列表# 创建数据集和数据加载器dataset = TranslationDataset(source_sentences, target_sentences, src_vocab, tgt_vocab)dataloader = DataLoader(dataset, batch_size=2, shuffle=True, collate_fn=collate_fn)# 模型初始化model = TransformerModel(len(src_vocab), len(tgt_vocab))optimizer = optim.Adam(model.parameters(), lr=0.0001)criterion = nn.CrossEntropyLoss(ignore_index=0) # 使用交叉熵损失函数,忽略填充标记的损失# 训练模型train(model, dataloader, optimizer, criterion, num_epochs=20)# 评估模型evaluate(model, dataloader, criterion)# 推理测试test_sentence = "hello"translated_sentence = inference(model, test_sentence, src_vocab, tgt_vocab)print(f"Input: {test_sentence}")print(f"Output: {translated_sentence}")test_sentence = "see"translated_sentence = inference(model, test_sentence, src_vocab, tgt_vocab)print(f"Input: {test_sentence}")print(f"Output: {translated_sentence}")test_sentence = "welcome"translated_sentence = inference(model, test_sentence, src_vocab, tgt_vocab)print(f"Input: {test_sentence}")print(f"Output: {translated_sentence}")
运行结果:
......
Epoch 18, Loss: 0.0005644524741607407
Epoch 19, Loss: 0.0005254073378940424
Epoch 20, Loss: 0.0004640306190898021
Evaluation Loss: 0.00014784792438149452
Input: hello
Output: <sos> world
Input: see
Output: <sos> you
Input: welcome
Output: <sos> back
总结
通过这个教程,我们从理论到实践,详细讲解了Transformer模型的基本原理,并展示了如何使用PyTorch实现一个简单的机器推理模型。虽然这个示例中的模型和数据集都非常简化,但它为进一步学习和研究更复杂的NLP任务打下了基础。希望通过这个教程,你能够对Transformer模型有更深入的理解,并能够在自己的项目中灵活应用。
相关文章:
PyTorch 基础学习(10)- Transformer
系列文章: 《PyTorch 基础学习》文章索引 介绍 Transformer模型是近年来在自然语言处理(NLP)领域中非常流行的一种模型架构,尤其是在机器翻译任务中表现出了优异的性能。与传统的循环神经网络(RNN)不同&a…...

mybatis-plus使用
目录 1. 快速开始 1. 创建user表 2. 插入几条数据 3. 创建一个新的springboot项目 4. 导入mybatis-plus依赖 5. 在配置文件中进行配置 6. 编写实体类 7. 编写Mapper 接口类 8. 添加 MapperScan 注解 9. 测试 编辑2. CRUD 1. 插入一条语句 2. 根据主键id删除一条记录 3. 根据…...

ant-design-vue快速上手指南及排坑攻略
前言 ant-design-vue是Ant Design的Vue实现,旨在为Vue用户提供一套企业级的UI设计语言。本文将带你快速上手ant-design-vue,并在实践中分享一些常见的坑及解决方法。遵循本文档,让你轻松搭建优雅的Vue应用。 一、环境准备 在开始之前&…...
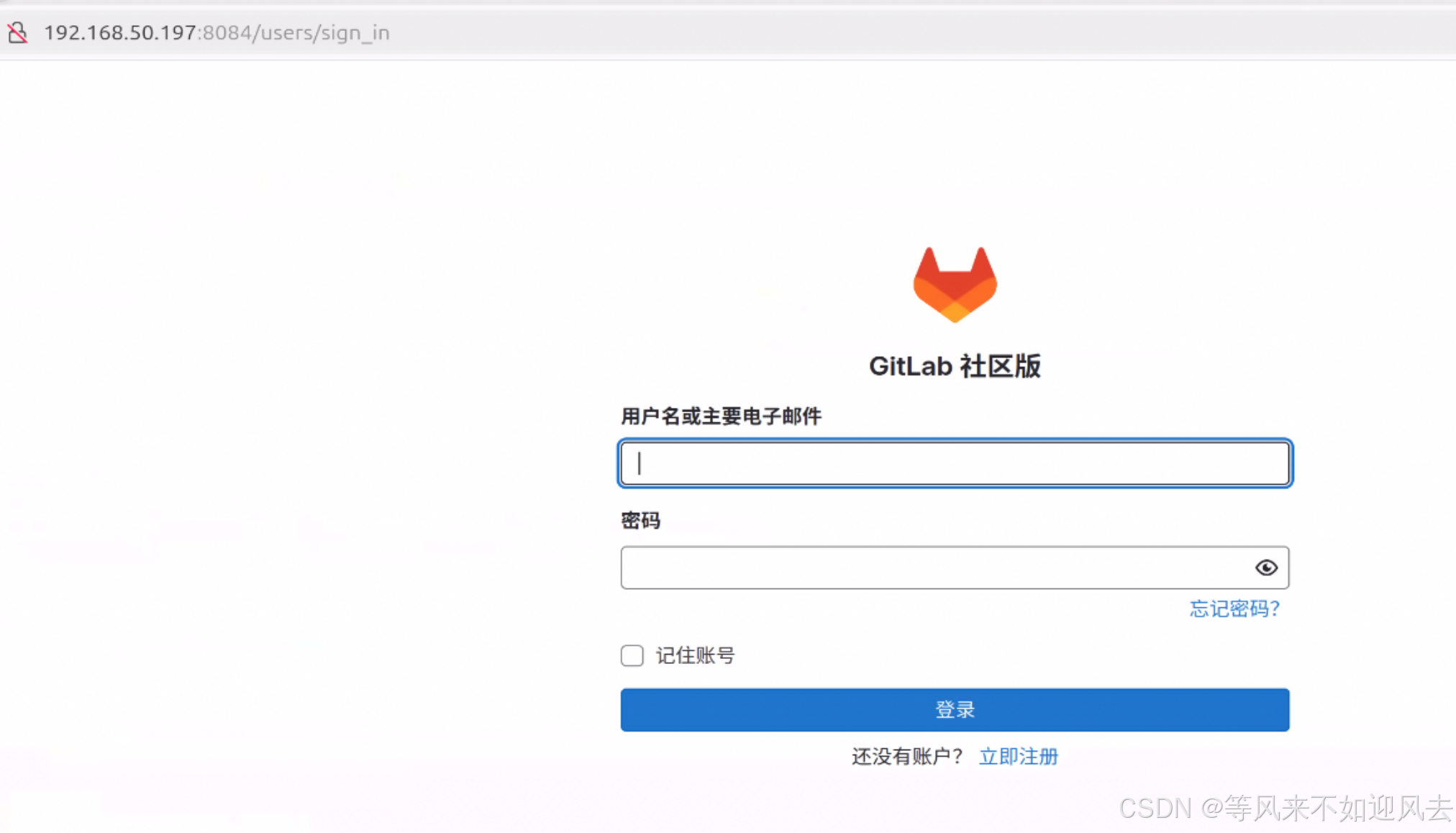
【GitLab】使用 Docker 安装 3:gitlab-ce:17.3.0-ce.0 配置
参考阿里云的教程docker的重启 sudo systemctl daemon-reload sudo systemctl restart docker配置 –publish 8443:443 --publish 8084:80 --publish 22:22 sudo docker ps -a 當容器狀態為healthy時,說明GitLab容器已經正常啟動。 root@k8s-master-pfsrv:~...

多线程(4)——单例模式、阻塞队列、线程池、定时器
1. 多线程案例 1.1 单例模式 单例模式能保证某个类在程序中只存在唯一一份实例,不会创建出多个实例(这一点在很多场景上都需要,比如 JDBC 中的 DataSource 实例就只需要一个 tip:设计模式就是编写代码过程中的 “软性约束”&am…...
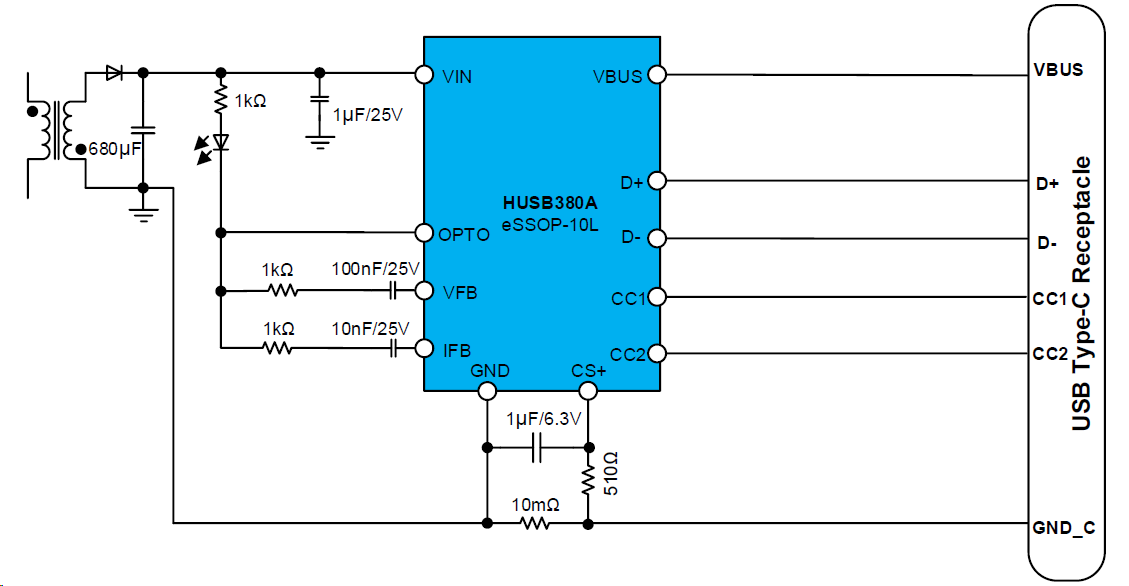
告别电量焦虑,高性能65W PD快充芯片HUSB380A打造梦中情【头】
市面上的充电器越来越卷,让人眼花缭乱。压力同样也给到了快充芯片行业,要在激烈的市场竞争中脱颖而出,快充芯片必须集高功率、高性价比与广泛的兼容性等于一身。 基于此,慧能泰推出了新一代高性能PD Source产品——HUSB380A。 图…...
vulnhub靶场 — NARAK
下载地址:https://download.vulnhub.com/ha/narak.ova Description:Narak is the Hindu equivalent of Hell. You are in the pit with the Lord of Hell himself. Can you use your hacking skills to get out of the Narak? Burning walls and demons are around every cor…...
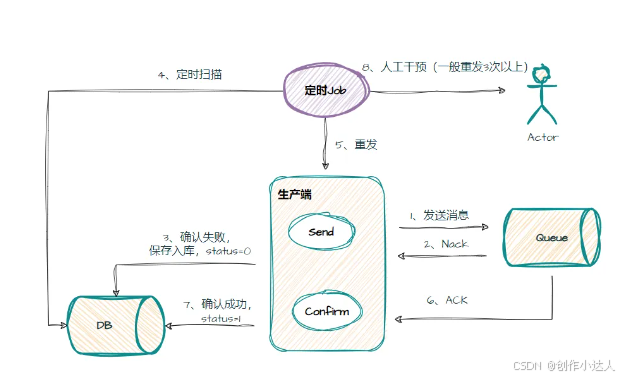
RabbitMQ如何保证消息不丢失
RabbitMQ消息丢失的三种情况 第一种:生产者弄丢了数据。生产者将数据发送到 RabbitMQ 的时候,可能数据就在半路给搞丢了,因为网络问题啥的,都有可能。 第二种:RabbitMQ 弄丢了数据。MQ还没有持久化自己挂了。 第三种…...

(亲测有效)SpringBoot项目集成腾讯云COS对象存储(1)
目录 一、腾讯云对象存储使用 1、创建Bucket 2、使用web控制台上传和浏览文件 3、创建API秘钥 二、代码对接腾讯云COS(以Java为例) 1、初始化客户端 2、填写配置文件 3、通用能力类 文件上传 测试 一、腾讯云对象存储使用 1、创建Bucket &am…...

无人机之故障排除篇
一、识别故障 掌握基本的无人机系统知识,遵循“先易后难、先外后内、先软件后硬件”的原则进行故障识别。一旦发现故障,立即停止飞行,避免进一步损坏。 二、机械部件维修 对于机身裂痕、螺旋桨损坏等情况,根据损坏程度更换相应部…...

深入理解Python常见数据类型处理
目录 概述数字类型 整数(int)浮点数(float)复数(complex) 字符串(str) 字符串基本操作字符串方法 列表(list) 列表基本操作列表方法列表推导式 元组…...
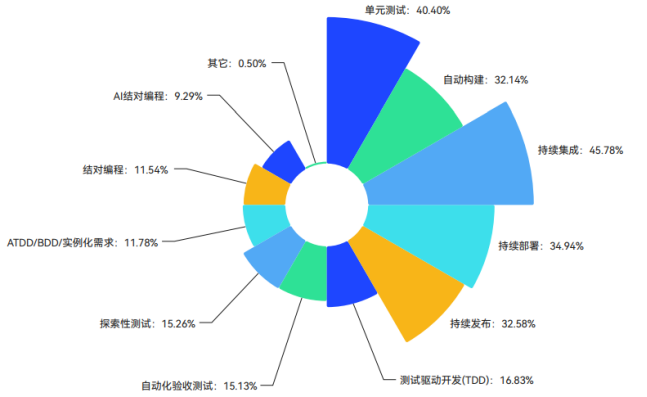
最佳实践:CI/CD交付模式下的运维展望丨IDCF
李洪锋 启迪万众数字技术(广州)有限公司 ,产品研发中心-系统运维部、研发效能(DevOps)工程师(中级)课程学员 一、DevOps现状 据云计算产业联盟《中国DevOps现状调查报告2023》显示,国内DevOps 落地成熟度…...

Flat Ads:开发者如何应对全球手游市场的洗牌与转型
2023年下半年至2024年上半年,中国手游的海外市场表现经历了显著变化,开发者要如何应对全球手游市场的洗牌与转型?本篇文章我们将结合相关行业白皮书的最新数据对中国手游出海表现进行分析与洞察。 一、中国手游海外市场表现 根据Sensor Tower《2024年海外手游市场洞察》最新…...

ai取名软件上哪找?一文揭秘5大ai取名生成器
在这个世界上,每一个新生命的到来都是一份奇迹,无论是一个新生儿的第一声啼哭,还是一只宠物的第一次摇尾巴,都充满了无限的希望和喜悦。 然而,给这个小生命起一个响亮、独特且富有意义的名字,往往让人煞费…...

ppt转换成pdf文件,这5个方法一键搞定!小白也能上手~
不管是工作上还是学习上,我们都会遇到转换文档格式的问题。比如常见的pdf转word,ppt转pdf,图片转pdf等。 很多软件都有自带的转换功能可以实现,但是需要保证转换后不乱码,且清晰度足够的方法还是少见的。本文整理了几个…...

中国每个软件创业者都是这个时代的“黑悟空”
作者 | 白鲸开源CEO 郭炜 我作为一个具有30游龄而20年都不碰游戏的游戏玩家,最近为了《黑神话:悟空》(简称,黑悟空),不但花重金更新了显卡,还第一次下载了Steam并绑定了支付,为的就是支持这个第…...

解决Qt多线程中fromRawData函数生成的QByteArray数据不一致问题
解决Qt多线程中fromRawData函数生成的QByteArray数据不一致问题 目录 🔔 问题背景📄 问题代码❓ 问题描述🩺 问题分析✔ 解决方案 🔔 问题背景 在开发一个使用Qt框架的多线程应用程序时,我们遇到了一个棘手的问题&…...

datax关于postsql数据增量迁移的问题
看官方文档是不支持的 数据源及同步方案_大数据开发治理平台 DataWorks(DataWorks)-阿里云帮助中心 (aliyun.com) 看了下源码有个postsqlwriter 看了下也就拼接sql 将 PostgresqlWriter中的不允许更新先注释了 让他过去先 然后看到 WriterUtil中的对应方法 getWriteTemplat…...

【Go】实现字符切片零拷贝开销转为字符串
package mainimport ("fmt""unsafe" )func main() {bytes : []byte("hello world")s : *(*string)(unsafe.Pointer(&bytes))fmt.Println(s)bytes[0] Hfmt.Println(s) }slice的底层结构是底层数组、len字段、cap字段。string的底层结构是底层…...

[sqlserver][sql]sqlserver查询执行过的历史sql
SQL是一个针对SQL Server数据库的查询执行过的历史 select * from (SELECT *FROM sys.dm_exec_query_stats QS CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) ST ) a where a.creation_time >2018-07-18 17:00:00 and charindex(delete from ckcdlist ,text)>0 an…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...
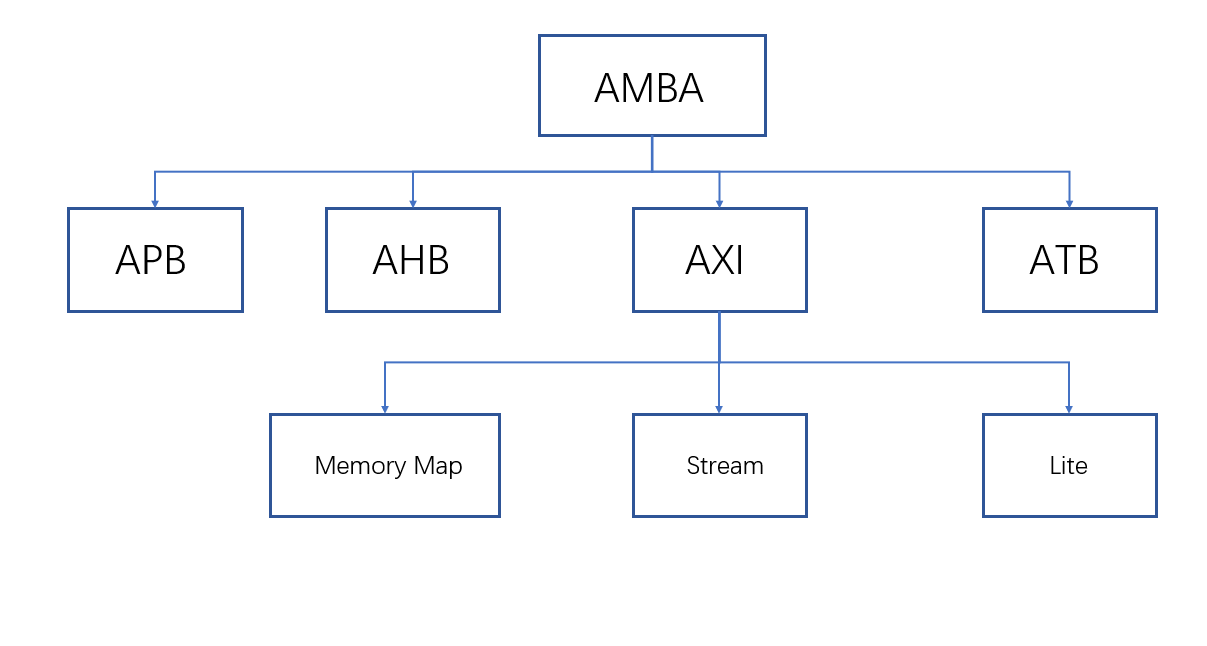
ZYNQ学习记录FPGA(一)ZYNQ简介
一、知识准备 1.一些术语,缩写和概念: 1)ZYNQ全称:ZYNQ7000 All Pgrammable SoC 2)SoC:system on chips(片上系统),对比集成电路的SoB(system on board) 3)ARM:处理器…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...
基于谷歌ADK的 智能产品推荐系统(2): 模块功能详解
在我的上一篇博客:基于谷歌ADK的 智能产品推荐系统(1): 功能简介-CSDN博客 中我们介绍了个性化购物 Agent 项目,该项目展示了一个强大的框架,旨在模拟和实现在线购物环境中的智能导购。它不仅仅是一个简单的聊天机器人,更是一个集…...
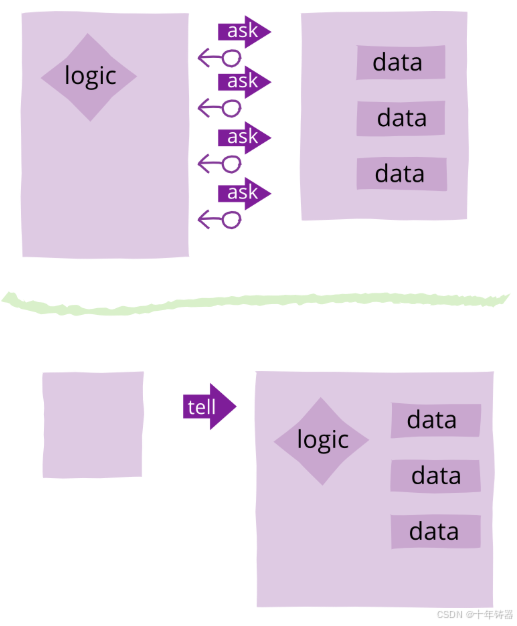
ABAP设计模式之---“Tell, Don’t Ask原则”
“Tell, Don’t Ask”是一种重要的面向对象编程设计原则,它强调的是对象之间如何有效地交流和协作。 1. 什么是 Tell, Don’t Ask 原则? 这个原则的核心思想是: “告诉一个对象该做什么,而不是询问一个对象的状态再对它作出决策。…...