牛客网SQL进阶134: 满足条件的用户的试卷总完成次数和题目总练习次数
满足条件的用户的试卷完成数和题目练习数_牛客题霸_牛客网
0 问题描述
基于用户信息表user_info、试卷信息表examination_info、试卷作答记录表exam_record、题目练习记录表practice_record,筛选出 高难度SQL试卷得分平均值大于80并且是7级的用户,统计他们2021年试卷总完成次数和题目总练习次数,结果按试卷完成数升序,按题目练习数降序。
1 数据准备
drop table if exists examination_info,user_info,exam_record,practice_record;
CREATE TABLE examination_info (id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',exam_id int UNIQUE NOT NULL COMMENT '试卷ID',tag varchar(32) COMMENT '类别标签',difficulty varchar(8) COMMENT '难度',duration int NOT NULL COMMENT '时长',release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;CREATE TABLE user_info (id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',uid int UNIQUE NOT NULL COMMENT '用户ID',`nick_name` varchar(64) COMMENT '昵称',achievement int COMMENT '成就值',level int COMMENT '用户等级',job varchar(32) COMMENT '职业方向',register_time datetime COMMENT '注册时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;CREATE TABLE practice_record (id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',uid int NOT NULL COMMENT '用户ID',question_id int NOT NULL COMMENT '题目ID',submit_time datetime COMMENT '提交时间',score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;CREATE TABLE exam_record (id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',uid int NOT NULL COMMENT '用户ID',exam_id int NOT NULL COMMENT '试卷ID',start_time datetime NOT NULL COMMENT '开始时间',submit_time datetime COMMENT '提交时间',score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;INSERT INTO user_info(uid,`nick_name`,achievement,level,job,register_time) VALUES(1001, '牛客1号', 3100, 7, '算法', '2020-01-01 10:00:00'),(1002, '牛客2号', 2300, 7, '算法', '2020-01-01 10:00:00'),(1003, '牛客3号', 2500, 7, '算法', '2020-01-01 10:00:00'),(1004, '牛客4号', 1200, 5, '算法', '2020-01-01 10:00:00'),(1005, '牛客5号', 1600, 6, 'C++', '2020-01-01 10:00:00'),(1006, '牛客6号', 2000, 6, 'C++', '2020-01-01 10:00:00');INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES(9001, 'SQL', 'hard', 60, '2021-09-01 06:00:00'),(9002, 'C++', 'hard', 60, '2021-09-01 06:00:00'),(9003, '算法', 'medium', 80, '2021-09-01 10:00:00');INSERT INTO practice_record(uid,question_id,submit_time,score) VALUES
(1001, 8001, '2021-08-02 11:41:01', 60),
(1002, 8001, '2021-09-02 19:30:01', 50),
(1002, 8001, '2021-09-02 19:20:01', 70),
(1002, 8002, '2021-09-02 19:38:01', 70),
(1004, 8001, '2021-08-02 19:38:01', 70),
(1004, 8002, '2021-08-02 19:48:01', 90),
(1001, 8002, '2021-08-02 19:38:01', 70),
(1004, 8002, '2021-08-02 19:48:01', 90),
(1004, 8002, '2021-08-02 19:58:01', 94),
(1004, 8003, '2021-08-02 19:38:01', 70),
(1004, 8003, '2021-08-02 19:48:01', 90),
(1004, 8003, '2021-08-01 19:38:01', 80);INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 81),
(1002, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:01', 81),
(1003, 9001, '2021-09-01 19:01:01', '2021-09-01 19:40:01', 86),
(1003, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:51', 89),
(1004, 9001, '2021-09-01 19:01:01', '2021-09-01 19:30:01', 85),
(1005, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:02', 85),
(1006, 9003, '2021-09-07 10:01:01', '2021-09-07 10:21:01', 84),
(1006, 9001, '2021-09-07 10:01:01', '2021-09-07 10:21:01', 80);2 数据分析
select t1.uid,count(distinct case when year(t2.submit_time) = '2021' then t2.id else null end) as exam_cnt, count(distinct case when year(t3.submit_time) = '2021' then t3.id else null end) as question_cnt
from (select uidfrom exam_record where uid in (select uid from user_info where level = 7 ) and exam_id in (select exam_id from examination_info where tag = 'SQL' and difficulty = 'hard')group by uid having sum(score) / count(score) > 80 ) t1
left join exam_record t2 on t1.uid = t2.uid
left join practice_record t3 on t1.uid = t3.uid group by t1.uidorder by exam_cnt asc , question_cnt desc ;
-- 结果按试卷完成数升序,按题目练习数降序
思路分析:
- step1: 先筛选出 平均值大于80并且是7级用户的uid,得到t1
- step2:t1分别与t2、t3关联,要用left join,因为有些uid可能没做某个试卷或练习,也要保留记录
- step3:count(distinct )时,以id区分(case when ..then id ),不能以exam_id区分,因为存在一个uid可能对同一个试卷或练习做过多次。
3 小结
相关文章:

牛客网SQL进阶134: 满足条件的用户的试卷总完成次数和题目总练习次数
满足条件的用户的试卷完成数和题目练习数_牛客题霸_牛客网 0 问题描述 基于用户信息表user_info、试卷信息表examination_info、试卷作答记录表exam_record、题目练习记录表practice_record,筛选出 高难度SQL试卷得分平均值大于80并且是7级的用户,统计他…...

机器学习:逻辑回归处理手写数字的识别
1、获取数据, 图像分割该数据有50行100列,每个数字占据20*20个像素点,可以进行切分,划分出训练集和测试集。 import numpy as np import pandas as pd import cv2 imgcv2.imread("digits.png")#读取文件 graycv2.cvtColor(img,cv2.COLOR_BGR2G…...

文件上传真hard
一、SpringMVC实现文件上传 1.1.项目结构 1.1.2 控制器方法 RequestMapping("/upload1.do")public ModelAndView upload1(RequestParam("file1") MultipartFile f1) throws IOException {//获取文件名称String originalFilename f1.getOriginalFilename(…...

精益管理|介绍一本专门研究防错法(Poka-Yoke)的书
在现代制造业中,如何确保产品在每个生产环节中不出现错误是企业追求的目标之一。而实现这一目标的关键技术之一就是防错法(Poka-Yoke)。作为一种简单而有效的精益管理、六西格玛管理工具,防错法帮助企业避免因人为错误或工艺不当导…...

面试题目:(4)给表达式添加运算符
目录 题目 代码 思路解析 例子 题目 题目 给定一个仅包含数字 0-9 的字符串 num 和一个目标值整数 target ,在 num 的数字之间添加 二元 运算符(不是一元)、- 或 * ,返回 所有能够得到 target 的表达式。1 < num.length &…...

[C#]将opencvsharp的Mat对象转成onnxruntime的inputtensor的3种方法
第一种方法:在创建tensor时候直接赋值改变每个tensor的值,以下是伪代码: var image new Mat(image_path);inpWidth image.Width;inpHeight image.Height;//将图片转为RGB通道Mat image_rgb new Mat();Cv2.CvtColor(image, image_rgb, Col…...

CTF入门教程(非常详细)从零基础入门到竞赛,看这一篇就够了!
一、CTF简介 CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相发起真实攻击进行技术比拼的方式。…...

数据链路层 I(组帧、差错控制)【★★★★★】
(★★)代表非常重要的知识点,(★)代表重要的知识点。 为了把主要精力放在点对点信道的数据链路层协议上,可以采用下图(a)所示的三层模型。在这种三层模型中,不管在哪一段…...

悟空降世 撼动全球
文|琥珀食酒社 作者 | 积溪 一只猴子能值多少钱? 答案是:13个小目标 这两天 只要你家没有断网 一定会被这只猴子刷屏 它就是咱国产的3A游戏 《黑神话:悟空》 这只猴子到底有多火? 这么跟你说吧 茅台见了它都…...

Swoole 和 Java 哪个更有优势呢
Swoole 和 Java 各有优势,在性能上不能简单地说哪一个更好,需要根据具体的应用场景来分析。 Swoole 优势:高并发:Swoole 是一个基于 PHP 的异步、协程框架,专为高并发场景设计,适用于 I/O 密集型应用&…...
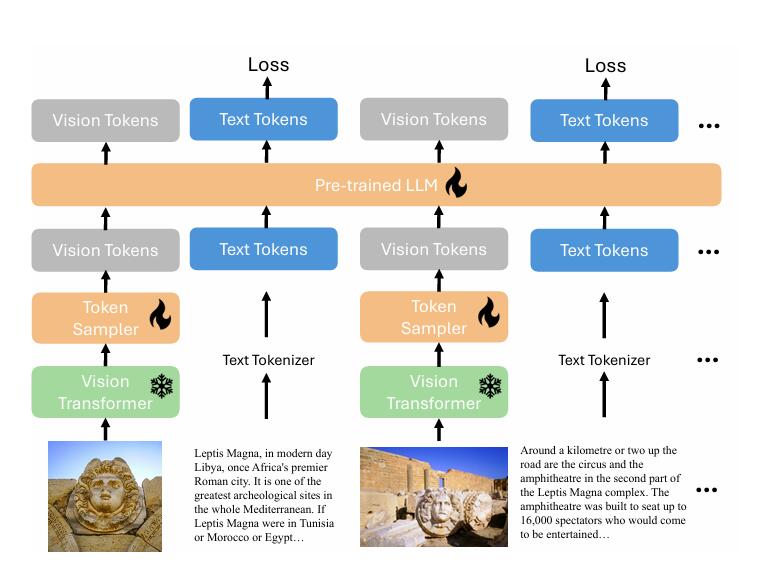
Salesforce 发布开源大模型 xGen-MM
xGen-MM 论文 在当今 AI 技术飞速发展的时代,一个新的多模态 AI 模型悄然崛起,引起了业界的广泛关注。这个由 Salesforce 推出的开源模型—— xGen-MM,正以其惊人的全能特性和独特优势,在 AI 领域掀起一阵旋风。那么,x…...

冒 泡 排 序
今天咱们单独拎出一小节来聊一聊冒泡排序昂 冒泡排序的核心思想就是:两两相邻的元素进行比较(理解思路诸君可看下图) 接下来我们上代码演示: 以上就是我们初步完成的冒泡排序,大家不难发现,不管数组中的元…...

采用先进的人工智能视觉分析技术,能够精确识别和分析,提供科学、精准的数据支持的智慧物流开源了。
智慧物流视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本可通过边缘计算技术…...

IAA游戏APP如何让合理地让用户观看更多广告,提高广告渗透率
广告变现已经成为休闲游戏开发者重要的收益方式之一,超50%国内休闲游戏已经采用广告变现的方式,游戏广告预算是游戏行业开发者广告变现的主要预算来源。 #深度好文计划#如何合理地提高广告渗透率? 广告渗透率能直接反映游戏中有广告行为用户…...

环网交换机的特殊作用是什么?
环网交换机作为现代网络建设的重要组成部分,具有独特而特殊的作用。在信息技术迅猛发展的今天,各类数据传输和网络连接需求日益增加,环网交换机的出现为解决这些问题提供了理想的方案。环网交换机通常将多个网络节点通过环形结构连接起来&…...

mac电脑安装Zsh并启用
安装 Zsh 1. 安装 Zsh 新版mac系统会默认安装并使用zsh,如没用,需在终端中安装: brew install zsh2. 安装 Oh My Zsh 克隆Oh My Zsh到你的目录: git clone https://github.com/robbyrussell/oh-my-zsh.git ~/.oh-my-zsh3. 复…...

【后续更新】python搜集上海二手房数据
源码如下: import asyncio import aiohttp from lxml import etree import logging import datetime import openpyxlwb = openpyxl.Workbook() sheet = wb.active sheet.append([房源, 房子信息, 所在区域, 单价, 关注人数和发布时间, 标签]) logging.basicConfig(level=log…...
创建GPTs,打造你的专属AI聊天机器人
在2023年11月的「OpenAI Devday」大会上,OpenAI再度带来了一系列令人瞩目的新功能,其中ChatGPT方面的突破尤为引人关注。而GPTs的亮相,不仅标志着个性化AI时代的到来,更为开发者和普通用户提供了前所未有的便利。接下来࿰…...
)
深度学习 vector 之模拟实现 vector (C++)
1. 基础框架 这里我们有三个私有变量,使用 _finish - _start 代表 _size,_end_of_storage - _start 代表 _capacity,并且使用到了模版,可以灵活定义存储不同类型的 vector,这里将代码量较小的函数直接定义在类的内部使…...

关于LLC知识10
在LLC谐振腔中能够变化的量 1、输入电压 2、Rac(负载) 所以增益曲线为红色(Rac无穷大)已经是工作的最大极限了,LLC不可能工作在红色曲线之外 负载越重时,增益曲线越往里面 假设: 输入电压…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

基于TurtleBot3在Gazebo地图实现机器人远程控制
1. TurtleBot3环境配置 # 下载TurtleBot3核心包 mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src git clone -b noetic-devel https://github.com/ROBOTIS-GIT/turtlebot3.git git clone -b noetic https://github.com/ROBOTIS-GIT/turtlebot3_msgs.git git clone -b noetic-dev…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...

实战设计模式之模板方法模式
概述 模板方法模式定义了一个操作中的算法骨架,并将某些步骤延迟到子类中实现。模板方法使得子类可以在不改变算法结构的前提下,重新定义算法中的某些步骤。简单来说,就是在一个方法中定义了要执行的步骤顺序或算法框架,但允许子类…...

React从基础入门到高级实战:React 实战项目 - 项目五:微前端与模块化架构
React 实战项目:微前端与模块化架构 欢迎来到 React 开发教程专栏 的第 30 篇!在前 29 篇文章中,我们从 React 的基础概念逐步深入到高级技巧,涵盖了组件设计、状态管理、路由配置、性能优化和企业级应用等核心内容。这一次&…...