写给大数据开发:如何优化临时数据查询流程
你是否曾因为频繁的临时数据查询请求而感到烦恼?这些看似简单的任务是否正在蚕食你的宝贵时间,影响你的主要工作?如果是,那么这篇文章正是为你而写。

目录
- 引言:数据开发者的困境
- 问题剖析:临时数据查询的隐患
- 解决方案:标准化查询请求流程
- 1. 创建标准化查询请求表单
- 2. 建立查询请求处理流程
- 3. 实施自动化工具
- 4. 建立知识库
- 实施步骤:从理论到实践
- 第1周:准备阶段
- 第2-3周:设计和开发
- 第4周:测试和培训
- 第5-6周:全面推广
- 第7周及以后:持续优化
- 案例研究:某科技公司的成功转型
- 背景
- 挑战
- 解决方案实施
- 结果
- 关键经验
- 进阶技巧:自动化和持续优化
- 1. 机器学习辅助分类
- 2. 自然语言处理(NLP)增强查询理解
- 3. 实时性能监控
- 4. 自动化报告
- 5. 持续学习和优化
- 结论:拥抱变革,提升效率
引言:数据开发者的困境
想象一下,你正全神贯注地开发一个复杂的数据处理算法,突然,你的同事小李匆匆忙忙地跑来:
“嘿,能帮我查一下上个月的用户增长数据吗?老板马上要用。”
你叹了口气,放下手头的工作,开始着手这个"紧急"查询。这可能只是你日常工作中的一个缩影,但这种情况如果频繁发生,将会严重影响你的工作效率和质量。
作为一名经验丰富的大数据开发者,我深深理解这种困境。在本文中,我们将深入探讨如何通过标准化查询请求流程来解决这个普遍存在的问题,让你能够更专注于核心开发工作,同时也能高效地满足同事的数据需求。

问题剖析:临时数据查询的隐患
在深入解决方案之前,让我们先仔细分析一下临时数据查询带来的问题:

-
时间消耗:每次查询可能只需要几分钟到几小时不等,但累积起来,这些时间是惊人的。根据我的经验,在没有优化流程的情况下,数据开发者可能将高达30%-40%的时间花在处理临时查询上。
-
工作中断:频繁的查询请求会打断你的思路,特别是当你正在处理复杂问题时。研究表明,被打断后,一个人平均需要23分钟才能重新投入到原来的任务中。
-
错误风险:在匆忙中进行查询,很容易出错。一项调查显示,在紧急情况下进行的数据查询,错误率可能高达15%。
-
知识孤岛:如果每次查询都是临时应对,很难形成系统的知识积累。这不仅影响个人成长,也不利于团队的长期发展。
-
资源浪费:重复的查询请求可能会导致重复的工作,这是对宝贵技术资源的浪费。
-
沟通成本:每次查询都可能需要多轮沟通来澄清需求,这增加了不必要的沟通成本。
为了更直观地理解这个问题,让我们看一个具体的例子:
# 模拟一天的工作时间分配
import matplotlib.pyplot as plt# 时间分配(小时)
times = [3, 2, 1.5, 1, 0.5]
activities = ['核心开发', '临时数据查询', '会议', '文档编写', '其他']plt.pie(times, labels=activities, autopct='%1.1f%%', startangle=90)
plt.axis('equal')
plt.title('数据开发者的一天')
plt.show()
这个饼图清晰地展示了临时数据查询如何蚕食了大量本应用于核心开发的时间。现在,让我们探讨如何通过标准化流程来解决这个问题。
解决方案:标准化查询请求流程

标准化查询请求流程是解决上述问题的关键。它不仅可以提高效率,还能减少错误,促进知识共享。以下是实施这个解决方案的核心步骤:
1. 创建标准化查询请求表单
设计一个全面但简洁的表单,包含以下关键信息:
- 请求者信息
- 数据描述
- 用途说明
- 时间范围
- 优先级
- 期望完成时间

这里是一个示例表单的 Markdown 版本:
# 数据查询请求表单1. **请求者信息**- 姓名:- 部门:- 联系方式:2. **数据描述**- 需要查询的具体数据:- 所需数据字段:3. **用途说明**- 数据用途:- 预期结果:4. **时间范围**- 数据起始日期:- 数据结束日期:5. **优先级**- [ ] 低(7个工作日内完成)- [ ] 中(3个工作日内完成)- [ ] 高(24小时内完成,需主管批准)6. **期望完成时间**:7. **附加说明**:---
注意:
1. 高优先级请求需要部门主管批准。
2. 请至少提前3个工作日提交非紧急查询请求。
3. 如有疑问,请联系数据团队:data_team@company.com
2. 建立查询请求处理流程
创建一个清晰的流程图,说明如何处理incoming查询请求:
3. 实施自动化工具
开发一个简单的工作流系统来管理查询请求。这里是一个基本的 Python 类来模拟这个过程:
from enum import Enum
from datetime import datetime, timedeltaclass Priority(Enum):LOW = 1MEDIUM = 2HIGH = 3class QueryRequest:def __init__(self, requester, description, priority, expected_completion):self.requester = requesterself.description = descriptionself.priority = priorityself.expected_completion = expected_completionself.submission_time = datetime.now()self.status = "Pending"class QueryManager:def __init__(self):self.requests = []def add_request(self, request):self.requests.append(request)self.requests.sort(key=lambda x: (x.priority.value, x.submission_time), reverse=True)def process_requests(self):for request in self.requests:if request.status == "Pending":print(f"Processing request from {request.requester}: {request.description}")# 模拟查询过程request.status = "Completed"def get_status(self):pending = sum(1 for r in self.requests if r.status == "Pending")completed = sum(1 for r in self.requests if r.status == "Completed")return f"Pending: {pending}, Completed: {completed}"# 使用示例
manager = QueryManager()manager.add_request(QueryRequest("Alice", "Monthly user growth", Priority.HIGH, datetime.now() + timedelta(days=1)))
manager.add_request(QueryRequest("Bob", "Revenue by product", Priority.MEDIUM, datetime.now() + timedelta(days=3)))
manager.add_request(QueryRequest("Charlie", "Customer churn rate", Priority.LOW, datetime.now() + timedelta(days=7)))print("Initial status:", manager.get_status())
manager.process_requests()
print("Final status:", manager.get_status())
这个简单的系统演示了如何管理和优先处理查询请求。在实际应用中,你可以扩展这个系统,添加更多功能,如自动通知、详细的状态跟踪等。
4. 建立知识库
创建一个集中的知识库,存储常见查询的SQL脚本、数据字典和业务规则解释。这不仅可以提高效率,还能促进知识共享。以下是一个简单的知识库结构示例:
data_queries/
│
├── common_queries/
│ ├── user_growth.sql
│ ├── revenue_by_product.sql
│ └── customer_churn.sql
│
├── data_dictionary/
│ ├── user_table.md
│ ├── product_table.md
│ └── order_table.md
│
├── business_rules/
│ ├── revenue_calculation.md
│ └── churn_definition.md
│
└── README.md
在 README.md 中,你可以包含如何使用这个知识库的说明,例如:
# 数据查询知识库本知识库包含常用的数据查询脚本、数据字典和业务规则说明。## 使用方法1. 在执行查询前,请先检查 `common_queries/` 目录,看是否有现成的脚本可以使用或修改。
2. 如果需要了解数据结构,请参考 `data_dictionary/` 目录下的相关文档。
3. 在解释数据时,请参考 `business_rules/` 目录,确保你的理解与公司的定义一致。## 贡献指南如果你创建了新的通用查询脚本或发现了需要更新的信息,请遵循以下步骤:1. 创建一个新的分支
2. 添加或更新相关文件
3. 提交一个 Pull Request,并在描述中详细说明你的更改让我们一起维护这个知识库,提高整个团队的工作效率!
实施步骤:从理论到实践
知道了解决方案,下一步就是如何将其付诸实践。以下是一个详细的实施计划:
第1周:准备阶段
- 召开启动会议:向团队介绍新的流程,解释其重要性和预期效果。
- 成立工作小组:选择2-3名经验丰富的开发者组成核心小组,负责流程的具体设计和实施。
- 收集feedback:通过问卷或一对一访谈,了解团队成员对当前查询流程的痛点和建议。
第2-3周:设计和开发
- 完善查询表单:根据收集的feedback,设计一个全面但不繁琐的查询请求表单。
- 开发自动化工具:基于上面提供的Python代码,开发一个更完善的查询请求管理系统。考虑添加以下功能:
- 用户认证和授权
- 请求状态自动更新
- 邮件通知
- 数据可视化dashboard
import streamlit as st
import pandas as pd
from datetime import datetime, timedelta# 假设这是我们的QueryManager类
class QueryManager:def __init__(self):self.requests = pd.DataFrame(columns=['Requester', 'Description', 'Priority', 'Status', 'Submission Time'])def add_request(self, requester, description, priority):new_request = pd.DataFrame({'Requester': [requester],'Description': [description],'Priority': [priority],'Status': ['Pending'],'Submission Time': [datetime.now()]})self.requests = pd.concat([self.requests, new_request], ignore_index=True)def get_requests(self):return self.requests# 初始化查询管理器
if 'query_manager' not in st.session_state:st.session_state.query_manager = QueryManager()st.title('数据查询请求系统')# 添加新请求的表单
with st.form("new_request"):st.write("提交新的查询请求")requester = st.text_input("请求者")description = st.text_area("查询描述")priority = st.selectbox("优先级", ["低", "中", "高"])submitted = st.form_submit_button("提交请求")if submitted:st.session_state.query_manager.add_request(requester, description, priority)st.success("请求已提交!")# 显示所有请求
st.write("当前所有请求:")
st.dataframe(st.session_state.query_manager.get_requests())# 简单的统计信息
st.write("请求统计:")
status_status_counts = st.session_state.query_manager.get_requests()['Status'].value_counts()
st.bar_chart(status_counts)# 优先级分布
priority_counts = st.session_state.query_manager.get_requests()['Priority'].value_counts()
st.pie_chart(priority_counts)
这个Streamlit应用提供了一个简单但功能强大的界面,用于管理数据查询请求。它允许用户提交新请求,查看所有请求的状态,并通过图表直观地展示请求的统计信息。
- 建立知识库:使用Git和Markdown创建一个结构化的知识库。可以考虑使用GitBook或MkDocs等工具来生成漂亮的文档网站。
第4周:测试和培训
- 内部测试:在小范围内进行测试,收集反馈并进行必要的调整。
- 编写文档:准备详细的用户指南和常见问题解答。
- 培训会议:组织培训会议,向所有相关人员介绍新的流程和工具。
第5-6周:全面推广
- 正式启用:在全公司范围内推广新的查询请求流程。
- 密切监控:密切关注新流程的使用情况,及时解决出现的问题。
- 收集反馈:通过问卷和一对一交流,收集用户的使用体验和建议。
第7周及以后:持续优化
- 定期回顾:每月召开回顾会议,讨论流程的效果和可能的改进点。
- 数据分析:分析查询请求的模式和趋势,为进一步的优化提供依据。
- 迭代升级:根据反馈和数据分析结果,持续改进流程和工具。
案例研究:某科技公司的成功转型
为了更好地理解这个方法的实际效果,让我们来看一个真实的案例研究。
背景
XYZ科技是一家快速成长的中型科技公司,拥有约200名员工,其中包括一个10人的数据团队。随着业务的扩张,数据团队面临着越来越多的临时查询请求,这严重影响了他们的核心开发工作。
挑战
- 数据开发人员平均每天要处理15-20个临时查询请求。
- 大约40%的工作时间被用于处理这些请求。
- 查询结果的错误率达到了10%,导致决策失误。
- 团队成员普遍感到疲惫和沮丧。
解决方案实施
XYZ科技决定采用我们提出的标准化查询请求流程。他们的具体实施步骤如下:
-
创建在线查询请求表单:使用Google Forms创建了一个详细的查询请求表单。
-
开发查询管理系统:基于我们提供的Python代码,他们开发了一个更复杂的系统,集成了公司的身份验证系统和数据库。
import streamlit as st
import pandas as pd
from datetime import datetime, timedelta
import plotly.express as pxclass QueryManager:def __init__(self):self.requests = pd.DataFrame(columns=['Requester', 'Description', 'Priority', 'Status', 'Submission Time', 'Completion Time'])def add_request(self, requester, description, priority):new_request = pd.DataFrame({'Requester': [requester],'Description': [description],'Priority': [priority],'Status': ['Pending'],'Submission Time': [datetime.now()],'Completion Time': [None]})self.requests = pd.concat([self.requests, new_request], ignore_index=True)def update_status(self, index, new_status):self.requests.loc[index, 'Status'] = new_statusif new_status == 'Completed':self.requests.loc[index, 'Completion Time'] = datetime.now()def get_requests(self):return self.requests# 初始化查询管理器
if 'query_manager' not in st.session_state:st.session_state.query_manager = QueryManager()st.title('XYZ科技 - 数据查询请求系统')# 侧边栏 - 切换视图
view = st.sidebar.radio("选择视图", ["提交新请求", "查看所有请求", "统计分析"])if view == "提交新请求":with st.form("new_request"):st.write("提交新的查询请求")requester = st.text_input("请求者")description = st.text_area("查询描述")priority = st.selectbox("优先级", ["低", "中", "高"])submitted = st.form_submit_button("提交请求")if submitted:st.session_state.query_manager.add_request(requester, description, priority)st.success("请求已提交!")elif view == "查看所有请求":st.write("当前所有请求:")requests = st.session_state.query_manager.get_requests()edited_df = st.data_editor(requests, num_rows="dynamic")if st.button("更新状态"):for index, row in edited_df.iterrows():if row['Status'] != requests.loc[index, 'Status']:st.session_state.query_manager.update_status(index, row['Status'])st.success("状态已更新!")elif view == "统计分析":st.write("请求统计:")requests = st.session_state.query_manager.get_requests()# 状态分布status_counts = requests['Status'].value_counts()st.plotly_chart(px.pie(status_counts, values=status_counts.values, names=status_counts.index, title="请求状态分布"))# 优先级分布priority_counts = requests['Priority'].value_counts()st.plotly_chart(px.bar(priority_counts, x=priority_counts.index, y=priority_counts.values, title="请求优先级分布"))# 每日请求数量趋势daily_counts = requests['Submission Time'].dt.date.value_counts().sort_index()st.plotly_chart(px.line(daily_counts, x=daily_counts.index, y=daily_counts.values, title="每日请求数量趋势"))# 平均完成时间completed_requests = requests[requests['Status'] == 'Completed']completed_requests['Completion Time'] = pd.to_datetime(completed_requests['Completion Time'])completion_times = (completed_requests['Completion Time'] - completed_requests['Submission Time']).dt.total_seconds() / 3600avg_completion_time = completion_times.mean()st.metric("平均完成时间(小时)", f"{avg_completion_time:.2f}")
这个更高级的Streamlit应用提供了更丰富的功能,包括不同的视图、数据编辑功能和更详细的统计分析。
-
建立Git知识库:使用GitLab建立了一个结构化的知识库,包含常见查询脚本、数据字典和业务规则说明。
-
实施自动化通知系统:开发了一个自动化的邮件通知系统,在查询状态更新时通知相关人员。
-
培训和推广:组织了一系列的培训会议,确保所有相关人员都能熟练使用新的系统。
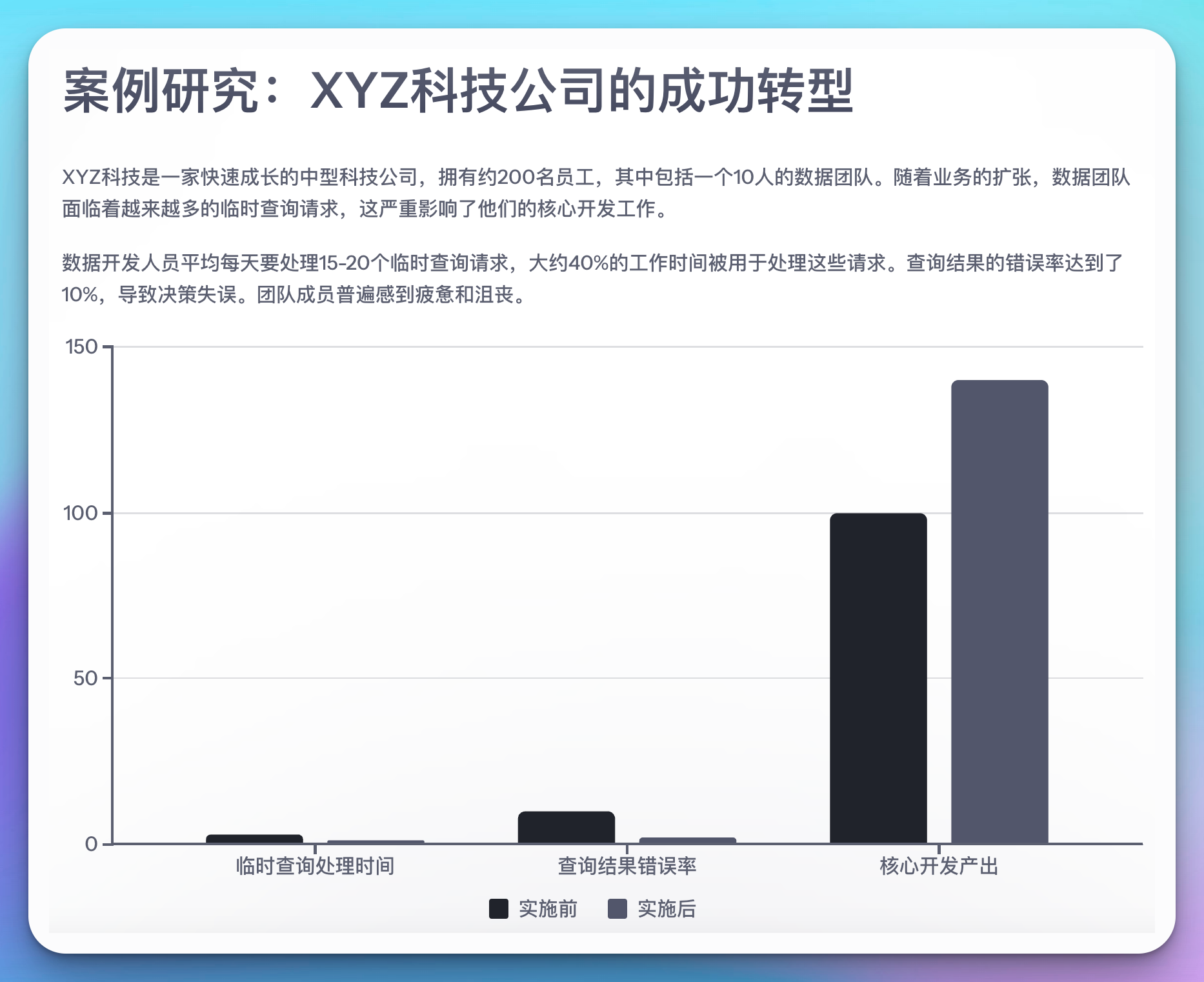
结果
实施新流程三个月后,XYZ科技观察到以下变化:
- 数据开发人员处理临时查询的时间减少了60%,从每天平均3小时降到了1.2小时。
- 查询结果的错误率从10%降低到了2%。
- 数据团队的核心开发产出增加了40%。
- 员工满意度显著提升,团队氛围更加积极。
关键经验
- 高层支持至关重要:公司CEO的全力支持确保了新流程能够顺利推行。
- 持续改进:团队每两周都会召开简短的回顾会议,讨论流程的改进点。
- 数据驱动:通过详细的统计分析,团队能够持续优化流程和资源分配。
- 文化转变:新流程不仅提高了效率,还培养了一种更加注重数据和流程的公司文化。
进阶技巧:自动化和持续优化
在成功实施标准化查询请求流程后,下一步是通过自动化和持续优化来进一步提升效率。以下是一些进阶技巧:
1. 机器学习辅助分类
使用机器学习算法来自动分类和优先处理查询请求。这可以基于历史数据,考虑因素如请求者、查询类型、关键词等。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline# 假设我们有历史数据
historical_requests = [("Monthly revenue report", "High"),("User growth in Q2", "Medium"),("Daily active users", "Low"),# ... 更多历史数据
]# 准备训练数据
X, y = zip(*historical_requests)# 创建一个文本分类pipeline
text_clf = Pipeline([('tfidf', TfidfVectorizer()),('clf', MultinomialNB()),
])# 训练模型
text_clf.fit(X, y)# 使用模型预测新请求的优先级
new_request = "Urgent: CEO needs quarterly profit margins"
predicted_priority = text_clf.predict([new_request])[0]
print(f"Predicted priority for '{new_request}': {predicted_priority}")
这个简单的机器学习模型可以帮助自动预测新请求的优先级,从而提高分类的效率和准确性。
2. 自然语言处理(NLP)增强查询理解
使用NLP技术来更好地理解和分类查询请求,提取关键信息,甚至自动生成SQL查询。
import spacy# 加载英语模型
nlp = spacy.load("en_core_web_sm")def extract_key_info(query_text):doc = nlp(query_text)# 提取日期dates = [ent.text for ent in doc.ents if ent.label_ == "DATE"]# 提取可能的指标metrics = [token.text for token in doc if token.pos_ == "NOUN"]# 提取可能的维度dimensions = [token.text for token in doc if token.dep_ == "nmod"]return {"dates": dates,"metrics": metrics,"dimensions": dimensions}# 示例使用
query = "Show me the monthly revenue by product category for the last quarter"
key_info = extract_key_info(query)
print("Extracted key information:", key_info)
这个NLP模型可以帮助快速理解查询请求的核心要素,为自动生成SQL或指导数据分析师提供基础。
3. 实时性能监控
使用一个专门的地图减少工具来监控查询管理系统的性能,并在出现异常时自动报警。
import streamlit as st
import pandas as pd
import plotly.express as px
from datetime import datetime, timedelta# 模拟实时性能数据
def generate_performance_data():now = datetime.now()data = []for i in range(60): # 生成过去60分钟的数据timestamp = now - timedelta(minutes=i)data.append({'timestamp': timestamp,'response_time': np.random.randint(100, 500),'requests_per_minute': np.random.randint(10, 100),'error_rate': np.random.uniform(0, 0.05)})return pd.DataFrame(data)# 生成性能数据
performance_data = generate_performance_data()st.title('查询管理系统实时性能监控')# 响应时间图表
st.subheader('平均响应时间(毫秒)')
fig_response_time = px.line(performance_data, x='timestamp', y='response_time')
st.plotly_chart(fig_response_time)# 每分钟请求数图表
st.subheader('每分钟请求数')
fig_requests = px.line(performance_data, x='timestamp', y='requests_per_minute')
st.plotly_chart(fig_requests)# 错误率图表
st.subheader('错误率')
fig_error_rate = px.line(performance_data, x='timestamp', y='error_rate')
st.plotly_chart(fig_error_rate)# 性能指标
col1, col2, col3 = st.columns(3)
col1.metric("当前响应时间", f"{performance_data['response_time'].iloc[0]} ms")
col2.metric("当前请求数/分钟", performance_data['requests_per_minute'].iloc[0])
col3.metric("当前错误率", f"{performance_data['error_rate'].iloc[0]:.2%}")# 模拟报警系统
if performance_data['response_time'].iloc[0] > 400:st.error('警报:响应时间异常高!')
if performance_data['error_rate'].iloc[0] > 0.03:st.error('警报:错误率超过3%!')
这个实时监控面板可以帮助团队快速发现和解决性能问题,确保查询管理系统的稳定运行。
4. 自动化报告
实现自动化报告系统,定期生成查询请求的统计和分析报告,帮助团队了解整体情况并做出数据驱动的决策。
import pandas as pd
import matplotlib.pyplot as plt
from fpdf import FPDF
import seaborn as snsdef generate_weekly_report(query_data):# 假设query_data是一个包含查询请求信息的DataFrame# 创建PDF对象pdf = FPDF()pdf.add_page()# 添加标题pdf.set_font("Arial", "B", 16)pdf.cell(0, 10, "每周数据查询报告", 0, 1, "C")pdf.ln(10)# 1. 查询请求数量趋势plt.figure(figsize=(10, 5))daily_counts = query_data['submission_date'].value_counts().sort_index()plt.plot(daily_counts.index, daily_counts.values)plt.title("每日查询请求数量")plt.xlabel("日期")plt.ylabel("请求数量")plt.savefig("daily_requests.png")pdf.image("daily_requests.png", x=10, y=30, w=190)plt.close()# 2. 优先级分布plt.figure(figsize=(8, 8))priority_counts = query_data['priority'].value_counts()plt.pie(priority_counts.values, labels=priority_counts.index, autopct='%1.1f%%')plt.title("查询请求优先级分布")plt.savefig("priority_distribution.png")pdf.image("priority_distribution.png", x=10, y=100, w=90)plt.close()# 3. 平均处理时间avg_processing_time = (query_data['completion_time'] - query_data['submission_time']).mean()pdf.set_xy(110, 100)pdf.set_font("Arial", "B", 12)pdf.cell(0, 10, f"平均处理时间: {avg_processing_time:.2f} 小时", 0, 1)# 4. 最常见的查询类型pdf.set_xy(110, 120)pdf.set_font("Arial", "B", 12)pdf.cell(0, 10, "最常见的查询类型:", 0, 1)pdf.set_font("Arial", "", 10)for query_type, count in query_data['query_type'].value_counts().head().items():pdf.cell(0, 10, f"- {query_type}: {count}", 0, 1)# 保存PDFpdf.output("weekly_report.pdf")# 使用示例
# generate_weekly_report(query_data)
这个脚本会生成一个包含图表和关键统计数据的PDF报告,帮助团队轻松掌握查询请求的整体情况。
5. 持续学习和优化
建立一个持续学习和优化的循环,不断提升查询管理系统的效率和准确性。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_reportdef optimize_query_processing(historical_data):# 假设historical_data是一个包含历史查询信息的DataFrame# 准备特征和目标变量X = historical_data[['query_length', 'priority', 'requester_department', 'time_of_day']]y = historical_data['processing_time_category'] # 假设我们将处理时间分为几个类别# 分割训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练随机森林模型model = RandomForestClassifier(n_estimators=100, random_state=42)model.fit(X_train, y_train)# 评估模型y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print(f"模型准确率: {accuracy:.2f}")print("\n分类报告:")print(classification_report(y_test, y_pred))# 特征重要性feature_importance = pd.DataFrame({'feature': X.columns,'importance': model.feature_importances_}).sort_values('importance', ascending=False)print("\n特征重要性:")print(feature_importance)return model# 使用示例
# optimized_model = optimize_query_processing(historical_data)
这个脚本使用机器学习模型来分析历史数据,找出影响查询处理时间的关键因素,并提供优化建议。通过定期运行这样的分析,团队可以不断调整和改进查询管理流程。

结论:拥抱变革,提升效率
在这个数据驱动的时代,高效的数据查询管理不仅是一种技术需求,更是一种竞争优势。通过实施标准化的查询请求流程,结合自动化工具和持续优化策略,数据开发团队可以:

- 显著提高工作效率:减少临时查询的干扰,让开发人员更专注于核心任务。
- 提升数据质量:通过结构化的流程和自动化工具,减少人为错误,提高数据准确性。
- 加强知识管理:建立中央化的知识库,促进团队学习和经验共享。
- 改善团队协作:清晰的流程和透明的进度跟踪,促进团队成员之间的有效沟通。
- 支持数据驱动决策:通过自动化报告和分析,为管理层提供更多洞察,支持战略决策。
实施这样的变革并非一蹴而就,它需要团队的共同努力和持续改进。但是,正如XYZ科技的案例所示,这种转变带来的回报是巨大的。它不仅能提高团队的工作效率和满意度,还能为公司创造更大的价值。
作为数据开发者,我们应该积极拥抱这种变革,不断学习和优化我们的工作方式。通过标准化、自动化和持续优化,我们可以从繁琐的日常查询中解放出来,专注于更具挑战性和创新性的任务,真正发挥我们的才能和价值。
最后,记住这是一个持续的过程。技术在不断进步,业务需求在不断变化,我们的查询管理流程也应该与时俱进。保持开放和学习的心态,勇于尝试新的工具和方法,相信我们终将构建一个更高效、更智能的数据开发环境。
你准备好迎接这个挑战了吗?让我们一起开启数据开发效率提升的新篇章!
相关文章:
写给大数据开发:如何优化临时数据查询流程
你是否曾因为频繁的临时数据查询请求而感到烦恼?这些看似简单的任务是否正在蚕食你的宝贵时间,影响你的主要工作?如果是,那么这篇文章正是为你而写。 目录 引言:数据开发者的困境问题剖析:临时数据查询的…...
【MongoDB】Java连接MongoDB
连接URI 连接 URI提供驱动程序用于连接到 MongoDB 部署的指令集。该指令集指示驱动程序应如何连接到 MongoDB,以及在连接时应如何运行。下图解释了示例连接 URI 的各个部分: 连接的URI 主要分为 以下四个部分 第一部分 连接协议 示例中使用的 连接到具有…...

nginx支持的不同事件驱动模型
Nginx 支持的不同事件驱动模型 Nginx 是一款高性能的 Web 和反向代理服务器,它支持多种事件驱动模型来处理网络 I/O 操作。不同的操作系统及其版本支持不同的事件驱动模型,这些模型对于 Nginx 的并发处理能力和性能至关重要。下面详细介绍 Nginx 支持的…...

C++ TinyWebServer项目总结(7. Linux服务器程序规范)
进程 PID 进程的PID(Process ID)是操作系统中用于唯一标识一个进程的整数值。每个进程在创建时,操作系统都会分配一个唯一的PID,用来区分不同的进程。 PID的特点 唯一性: 在操作系统运行的某一时刻,每个…...

基于STM32单片机设计的秒表时钟计时器仿真系统——程序源码proteus仿真图设计文档演示视频等(文末工程资料下载)
基于STM32单片机设计的秒表时钟计时器仿真系统 演示视频 基于STM32单片机设计的秒表时钟计时器仿真系统 摘要 本设计基于STM32单片机,设计并实现了一个秒表时钟计时器仿真系统。系统通过显示器实时显示当前时间,并通过定时器实现秒表计时功能。显示小时…...

人才流失预测项目
在本项目中,通过数据科学和AI的方法,分析挖掘人力资源流失问题,并基于机器学习构建解决问题的方法,并且,我们通过对AI模型的反向解释,可以深入理解导致人员流失的主要因素,HR部门也可以根据分析…...

BUG——imx6u开发_结构体导致的死机问题(未解决)
简介: 最近在做imx6u的linux下裸机驱动开发,由于是学习的初级阶段,既没有现成的IDE可以使用,也没有GDB等在线调试工具,只能把代码烧写在SD卡上再反复插拔,仅靠卑微的亮灯来判断程序死在哪一步。 至于没有使…...
问答:什么是对称密钥、非对称密钥,http怎样变成https的?
文章目录 对称密钥 vs 非对称密钥HTTP 变成 HTTPS 的过程 对称密钥 vs 非对称密钥 1. 对称密钥加密 定义: 对称密钥加密是一种加密算法,其中加密和解密使用的是同一个密钥。特点: 速度快: 因为只使用一个密钥,所以加密和解密速度较快。密钥分发问题: 双…...

虚拟滚动列表组件ReVirtualList
虚拟滚动列表组件ReVirtualList 组件实现基于 Vue3 Element Plus Typescript,同时引用 vueUse lodash-es tailwindCss (不影响功能,可忽略) 在 ReList 的基础上,增加虚拟列表功能,在固定高度的基础上,可以优化大数…...

稳定、耐用、美观 一探究竟六角头螺钉螺栓如何选择
在机器与技术未被发现的过去,紧固件设计和品质并不稳定。但是,他们已成为当今许多行业无处不在的构成部分。六角头标准件或六角头标准件是紧固件中持续的头部设计之一,它有六个面,对广泛工业应用大有益处。六角头标准件或常分成六…...

数据库Mybatis基础操作
目录 基础操作 删除 预编译SQL 增、改、查 自动封装 基础操作 环境准备 删除 根据主键动态删除数据:使用了mybatis中的参数占位符#{ },里面是传进去的参数。 单元测试: 另外,这个方法是有返回值的,返回这次操作…...

人物形象设计:塑造独特角色的指南
引言 人物形象设计是一种创意过程,它利用强大的设计工具,通过视觉和叙述元素塑造角色的外在特征和内在性格。这种设计不仅赋予角色以生命,还帮助观众或读者在心理层面上与角色建立联系。人物形象设计的重要性在于它能够增强故事的吸引力和说…...

网络安全-安全策略初认识
文章目录 前言理论介绍1. 安全策略1.1 定义:1.2 关键术语: 2. 防火墙状态监测 实战步骤1:实验环境搭建步骤2:配置实现 总结1. 默认安全策略2. 自定义安全策略3. 防火墙状态会话表 前言 who:本文主要写给入门防火墙的技…...
python import相对导入与绝对导入
文章目录 相对导入与绝对导入绝对导入相对导入何时使用相对导入何时使用绝对导入示例 相对导入与绝对导入 在Python中,from .file_manager import SomeFunction 和 from file_manager import SomeFunction 两种导入方式看似相似,但在模块寻找机制上存在…...
深入理解 Go 语言原子内存操作
原子内存操作提供了实现其他同步原语所需的低级基础。一般来说,你可以用互斥体和通道替换并发算法的所有原子操作。然而,它们是有趣且有时令人困惑的结构,应该深入了解它们是如何工作的。如果你能够谨慎地使用它们,那么它们完全可以成为代码优化的好工具,而不会增加复杂性…...
PostgreSQL几个扩展可以帮助实现数据的分词和快速查询
在 PostgreSQL 数据库中,有几个扩展可以帮助实现数据的分词和快速查询,特别是在处理全文搜索和文本分析时。以下是几个常用的扩展: 1. pg_trgm pg_trgm(Trigram)扩展是 PostgreSQL 中的一个强大的工具,它可以通过计算字符串之间的相似度来实现快速文本搜索。它支持基于…...

C盘满了怎么办?教你清理C盘的20个大招,值得收藏备用
C盘满了怎么办?教你清理C盘的20个大招,值得收藏备用 今天给大家介绍20种C盘清理的方法,下次遇到C盘满了红了就知道怎么做了,喜欢请点赞收藏关注点评。 清理更新缓存 清理微信缓存 查找大文件清理或者迁移 磁盘缓存清理 系统还…...

原生js实现下滑到当前模块进度条填充
<div style"height: 1500px;"></div> <div class"progress-container"><div class"progress-bar" data-progress"90%"><p class"progress-text">Google Ads在Google搜索引擎上覆盖超过90%的互…...

显示弹出式窗口的方法
文章目录 1. 概念介绍2. 使用方法3. 示例代码 我们在上一章回中介绍了Sliver综合示例相关的内容,本章回中将介绍PopupMenuButton组件.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在本章回中介绍的PopupMenuButton组件位于AppBar右侧…...
Java-什么是缓存线程池?
什么是缓存线程池? 缓存线程池 (CachedThreadPool) 是一种特殊的线程池,它能够动态地调整线程的数量,以适应任 务的需求。这种线程池非常适合处理大量短暂的任务,因为它会根据任务的数量自动增加或减少线 程的数量。 缓存线程池的特点: 线程数量动态调整:缓存线程池…...
esbuild中的Binary Loader:处理二进制文件
在前端或Node.js项目中,有时需要处理二进制文件,如图片、音频、视频或其他非文本资源。esbuild提供了一款名为Binary Loader的插件,它能够在构建时将二进制文件加载为二进制缓冲区,并使用Base64编码将其嵌入到打包文件中。在运行时…...

深度好文:从《黑神话:悟空》看未来游戏趋势:高互动性、个性化与全球化
引言 在数字时代的浪潮中,游戏产业以其独特的魅力和无限的可能性,成为了全球娱乐文化的重要组成部分。随着科技的飞速发展,特别是高性能计算和人工智能技术的突破,游戏的世界变得越来越真实、细腻且富有深度。而在这股技术洪流中…...

【中项第三版】系统集成项目管理工程师 | 第 12 章 执行过程组
前言 本章属于10大管理的内容,上午题预计会考8-10分,下午案例分析也会进行考查。学习要以教材为主。 目录 12.1 指导与管理项目工作 12.1.1 主要输入 12.1.2 主要输出 12.2 管理项目知识 12.2.1 主要输入 12.2.2 主要输出 12.3 管理质量 12.3.…...
C语言自动生成宏定义枚举类型和字符串
#include <stdio.h>// 定义错误枚举 #define ERROR_LIST(e) \e(SUCCESS) \e(FAILURE) \e(NOT_FOUND) \e(TIMEOUT)// 使用宏生成枚举 #define GENERATE_ENUM(ENUM) ENUM, typedef enum {ERROR_LIST(GENERATE_ENUM) } ErrorCode;// 使用宏生成字符串数组…...
C#单例模式
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;namespace _3._3._6_单例模式 {public class Singleton{private static Singleton s_instance;private int _state;private Singleton(int …...

10-使用sentinel流控
本文介绍sentinel的直接流控的使用。 0、环境 jdk 1.8sentinel 1.8.2springboot 2.4.2 1、sentinel环境搭建 从官方发布的网站上下载: sentinel Jar,下载对应版本。 下载完成后,进入刚才下载的Jar文件所在的目录,执行如下命令:…...

redis AOF机制
在redis运行期间,不断将redis执行的写命令写到文件中,redis重启之后,只要将这些命令重复执行一遍就可以恢复数据。因为AOF只是将少量的写命令写入AOF文件中,因此其执行效率高于RDB,开启AOF即使Redis发生故障࿰…...
Day 21代码|随想录| 二叉树完结撒花,今日刷题669.修剪二叉搜索树、108.将有序数组转换为二叉搜索树、538.吧二叉搜索树转换为累加树
提示:DDU,供自己复习使用。欢迎大家前来讨论~ 文章目录 二叉树 Part06二、题目题目一:669.修剪二叉搜索树解题思路:递归法迭代法: 题目二: 108.将有序数组转换为二叉搜索树解题思路递归法:迭代…...
cmake教程一
1. Start 1.1 构建简单工程 cmake_minimum_required(VERSION 3.0) project(Step1) add_executable(Step1 main.cpp)设置cmake最低版本要求设置工程名字设置工程生成可执行程序 2. 声明 C Standard set(CMAKE_CXX_STANDARD 11) set(CMAKE_CXX_STANDARD_REQUIRED True)如果我…...

3D场景标注标签信息,three.js CSS 2D渲染器CSS2DRenderer、CSS 3D渲染器CSS3DRenderer(结合react)
如果你想用HTML元素作为标签标注三维场景中模型信息,需要考虑定位的问题。比如一个模型,在代码中你可以知道它的局部坐标或世界坐标xyz,但是你并不知道渲染后在canvas画布上位置,距离web页面顶部top和左侧的像素px值。自己写代码把…...

什么查网站是否降权/矿产网站建设价格
从写第一篇今日头条高仿系列开始,到现在已经过去了1个多月了,其实大体都做好了,就是迟迟没有放出来,因为我觉得,做这个东西也是有个过程的,我想把这个模仿中一步一步学习的过程,按照自己的思路写…...

江苏企业网站定制服务/免费发外链
一、首先安装 MySQL1. 安装前更新一下仓库,输入命令:sudo apt-get updatealgerfanalgerfan:~$ sudo apt-get autoremove --purge mysql-server-5.72. 输入命令:sudo apt-get install mysql-server mysql-client安装MySQL数据库程序和命令行管…...

WordPress 书架插件/黑帽seo寄生虫
一.基本格式 缩进 建议每级4个空格,可以给编辑器设置tab 4个空格,自动转换 分号 不要省略分号,防止ASI(自动插入分号)错误 行宽 每行代码不超过80个字符,过长应该用操作符手动断行 断行 操作符在上一行末尾…...
做代购的购物网站/十大搜索引擎地址
先上辗转相除的代码 while (true) {int t a % b;if (t 0) break;else {a b;b t;} } 为什么要这么做? 我们来证明余数也是公因数的倍数 a,b两个数,(a>b),肯定是有一个公因数1的,或者也可…...
内容展示类网站/百度经验悬赏任务平台
Galaxy 在一维坐标轴上给出n个点,第i个点坐标为\(x_i\),现在你可以任意移动k个点的,最小化它们的方差,\(n\leq 50000\)。 解 设\(\bar{x}\frac{\sum_{i1}^nx_i}{n}\),容易知道方差为 \[\sum_{i1}^n(x_i-\bar{x})^2\sum_{i1}^nx_i^2-n\bar{x}^…...
安徽平台网站建设公司/重庆seo团队
JSONP 和 JSON 的关系 事实上,JSONP 和 JSON 没有关系。若强行要有关系,也只能说 JSONP 这个技术使用了 JSON 这种数据格式。JSON 是一种数据交换格式。JSONP 是一种非官方跨域数据交互协议,是一种技术。 跨域是什么? 上面说了 JS…...