AI学习记录 - 如何快速构造一个简单的token词汇表
创作不易,有用的话点个赞
先直接贴代码,我们再慢慢分析,代码来自openai的图像分类模型的一小段
def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe codes work on unicode strings.This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.This is a signficant percentage of your normal, say, 32K bpe vocab.To avoid that, we want lookup tables between utf-8 bytes and unicode strings.And avoids mapping to whitespace/control characters the bpe code barfs on."""bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))cs = bs[:]n = 0for b in range(2**8):if b not in bs:bs.append(b)cs.append(2**8+n)n += 1cs = [chr(n) for n in cs]return dict(zip(bs, cs))
openai觉得图像分类,就是输入文本,然后给你一张相似的照片,例如
a facial photo of a tabby cat

这其实对文本语义文本推理要求不是很高,所以我们不需要训练出一个太长的词汇表,例如gpt2的50000多个词汇,不需要。
我们只需要一些简单的词汇表,我们可以指定我们需要哪些词汇,首先26个英文字母,一些分隔符,或者你还想兼容其它语言,都可以加,这里兼容了英语法语西班牙语,你觉得重要的语言字符都给一个独立的下标index去对待这个字符,所以就有了如下代码:
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
print(list(range(ord("!"), ord("~")+1)))
print(list(range(ord("¡"), ord("¬")+1)))
print(list(range(ord("®"), ord("ÿ")+1)))
打印如下,ord("!")就是获取一个字符在unicode编码世界中的一个下标,可以看到对你重要的字符都在下面,你可以随意更改上面的字符。
[33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126]
[161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172]
[174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255]
但是实际上当你训练好模型之后,就算你要求用户使用英语法语西班牙语,但是用户可能会使用其它语言去提问,不在我们上面的区间,所以我们要兼容用户输入一些其他语言,我们想使用utf-8去实现这种兼容性。
这里讲一个东西:由于我们没有对其他语言独立给一个位置,所以当使用其他语言去跟模型提问的时候,效果可能不会很好,但我们针对的用户主要是英文法语西班牙语,这里主要是实现兼容性而已。
上面我们给下标的都只是单个字符,但是如果你觉得abc这个连词很重要,你也可以给abc一个单独的index,一个单独的index,意味着这个词有一个单独的词向量去训练,例如abc就有个单独的词向量,但是def没有,那么构成def的词向量是由三个单独的词向量组成,我认为,单独的一个词向量比多个组成的效果要好,表达意义要更准确,因为def是一个词汇,dbp也是一个词汇,他们是不同的意思,但是共享了d这个字符,d既要兼顾def的意思又要兼顾dbp的意思,很可能这两个词汇的意思又完全不相关不交集,那么d这个字符的词向量就被分散了,所以我们跟gpt问问题的时候,用英文问会更好,因为英文可以更准确表达我们的意思,而中文其实更像是很多无关的其他字符拼合起来的意思。
utf-8怎么表示文字?使用四种长度的数组表示一个符号,就是长度为1,2,3,4,每个位置取0到127中其中一个数字,可以表示计算机世界中所有词汇。如下:
【0-127】
【0-127,0-127】
【0-127,0-127,0-127】
【0-127,0-127,0-127,0-127】
原先已经拥有字符的下标,我们不去改它了,继续让他使用unicode编码的下标即可。
遍历 2的8次方 次,当缺少下标的时候,我们将最后一个字符顺序递增叠加上去,代码就是:
for b in range(2**8):if b not in bs:# 不存在的下标,就把下标append进去bs.append(b) cs.append(2**8+n) # 但是我append进去的字符却不是对应下标的unicode字符,因为我不喜欢......,我把第2**8+n字符叠加上去n += 1
打印bs
[33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96,97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183,184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 0, 1, 2, 3, 4, 5,6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 173]
打印cs
['!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':',
';', '<', '=', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '{', '|', '}', '~', '¡', '¢', '£', '¤', '¥', '¦', '§', '¨', '©', 'ª',
'«', '¬', '®', '¯', '°', '±', '²', '³', '´', 'µ', '¶', '·', '¸', '¹', 'º', '»', '¼', '½', '¾', '¿', 'À', 'Á', 'Â', 'Ã', 'Ä', 'Å',
'Æ', 'Ç', 'È', 'É', 'Ê', 'Ë', 'Ì', 'Í', 'Î', 'Ï', 'Ð', 'Ñ', 'Ò', 'Ó', 'Ô', 'Õ', 'Ö', '×', 'Ø', 'Ù', 'Ú', 'Û', 'Ü', 'Ý', 'Þ', 'ß',
'à', 'á', 'â', 'ã', 'ä', 'å', 'æ', 'ç', 'è', 'é', 'ê', 'ë', 'ì', 'í', 'î', 'ï', 'ð', 'ñ', 'ò', 'ó', 'ô', 'õ', 'ö', '÷', 'ø', 'ù',
'ú', 'û', 'ü', 'ý', 'þ', 'ÿ', 'Ā', 'ā', 'Ă', 'ă', 'Ą', 'ą', 'Ć', 'ć', 'Ĉ', 'ĉ', 'Ċ', 'ċ', 'Č', 'č', 'Ď', 'ď', 'Đ', 'đ', 'Ē', 'ē',
'Ĕ', 'ĕ', 'Ė', 'ė', 'Ę', 'ę', 'Ě', 'ě', 'Ĝ', 'ĝ', 'Ğ', 'ğ', 'Ġ', 'ġ', 'Ģ', 'ģ', 'Ĥ', 'ĥ', 'Ħ', 'ħ', 'Ĩ', 'ĩ', 'Ī', 'ī', 'Ĭ', 'ĭ',
'Į', 'į', 'İ', 'ı', 'IJ', 'ij', 'Ĵ', 'ĵ', 'Ķ', 'ķ', 'ĸ', 'Ĺ', 'ĺ', 'Ļ', 'ļ', 'Ľ', 'ľ', 'Ŀ', 'ŀ', 'Ł', 'ł', 'Ń'
]
这就是我们仅有256个词汇表的token。
相关文章:
AI学习记录 - 如何快速构造一个简单的token词汇表
创作不易,有用的话点个赞 先直接贴代码,我们再慢慢分析,代码来自openai的图像分类模型的一小段 def bytes_to_unicode():"""Returns list of utf-8 byte and a corresponding list of unicode strings.The reversible bpe c…...

JAVA中的数组流ByteArrayOutputStream
Java 中的 ByteArrayOutputStream 是一个字节数组输出流,它允许应用程序以字节的形式写入数据到一个字节数组缓冲区中。以下是对 ByteArrayOutputStream 的详细介绍,包括其构造方法、方法、使用示例以及运行结果。 一、ByteArrayOutputStream 概述 Byt…...

S3C2440中断处理
一、中断处理机制概述 中断是CPU在执行程序过程中,遇到急需处理的事件时,暂时停止当前程序的执行,转而执行处理该事件的中断服务程序,并在处理完毕后返回原程序继续执行的过程。S3C2440提供了丰富的中断源,包括内部中…...

《数据分析与知识发现》
《数据分析与知识发现》介绍 1 期刊定位 《数据分析与知识发现》(Data Analysis and Knowledge Discovery)是由中国科学院主管、中国科学院文献情报中心主办的学术性专业期刊。期刊创刊于2017年,由《现代图书情报技术》(1985-20…...
IaaS,PaaS,aPaaS,SaaS,FaaS,如何区分?
IaaS, PaaS,SaaS,aPaaS 还有一种 FaaS ,这几个都是云服务中常见的 5 大类型: IaaS:基础架构即服务,Infrastructure as a Service PaaS:平台即服务,Platform as a Service aPaaS&…...

软件测试工具分享
要想在测试中旗开得胜,趁手的“武器”那是相当重要(说人话,要保证测试质量和效率,测试工具也很重要)。现在,小酋打算亮一亮自己的武器库,希望不要闪瞎你的眼(天上在打雷,…...
word翻译工具有哪些?5个工具助你快速翻译Word文件
无论是商业沟通还是文化交流,都需要跨越语言障碍。而文档翻译则是这一过程中的重要环节之一。 想象一下,当你需要将一份重要的Word文档从一种语言翻译成另一种语言时,如果手动逐句翻译不仅耗时耗力,还可能因为文化差异导致误解。…...

【51单片机】ds18b20驱动,11.0592MHZ,使用DS18b20
文章目录 ds18b20.h #include <reg52.h> #include <intrins.h> #include <math.h>// 管脚定义 sbit DS18B20_DATA_PIN = P1 ^ 0; // DS18B20数据口定义/******************************************************************************* * 函 数 名 …...

Vue 导航条+滑块效果
目录 前言代码效果展示导航实现代码导航实现代码导航应用代码前言 总结一个最近开发的需求。设计稿里面有一个置顶的导航条,要求在激活的项目下面展示个下划线。我最先开始尝试的是使用 after 的伪类选择器,直接效果一样,但是展示的时候就会闪现变化,感觉不够自然,参考了一…...

Android:使用Gson常见问题(包含解决将Long型转化为科学计数法的问题)
一、解决将Long型转化为科学计数法的问题 1.1 场景 将一个对象转为Map类型时,调用Gson.fromJson发现,原来对象中的long类型的personId字段,被解析成了科学计数法,导致请求接口失败,报参数错误。 解决结果图 1.2、Exa…...

【Win开发环境搭建】Redis与可视化工具详细安装与配置过程
🎯导读:本文档提供了Redis的简介、安装指南、配置教程及常见操作方法。包括了安装包的选择与配置环境变量的过程,详细说明了如何通过修改配置文件来设置密码和端口等内容。同时,文档还介绍了如何使用命令行工具连接Redisÿ…...

Compose知识分享
前言 “Jetpack Compose 是一个适用于 Android 的新式声明性界面工具包。Compose 提供声明性 API,让您可在不以命令方式改变前端视图的情况下呈现应用界面,从而使编写和维护应用界面变得更加容易。” 以上是Compose官网中对于Compose这套全新的Androi…...

python-study-day5
urllib中handler的使用 import urllib.request url "http://www.baidu.com" headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0 } # 请求地址的定制 reques…...

Telegram mini app 本地开发配置
前言: 为了能在telegram里本地调试mini app,参考了网上很多方案,踩了不少坑。最后整了一个适合自己的方案,记录一下。 这个方案一定不是最好的,不过是目前适合我上手开发的方案了。 本文章适合需要在 telegram 本地…...

python发票查验接口助您拒绝做糊涂账、发票ocr
发票识别发票查验接口让发票真假立现。仅需一键上传发票图片,即可实现发票真伪的秒速、批量验证,操作简单方便,避免因人工核验失误所导致“错账”现象的发生,减轻财务工作负担,提升企业工作效率,降低因假票…...

【Linux】线程控制|POSIX线程库|多线程创建|线程终止|等待|线程分离|线程空间布局
目录 编辑 POSIX线程库 多线程创建 独立栈结构 获取线程ID pthread_self 线程终止 return终止线程 pthread_exit pthread_cancel 线程等待 退出码问题 线程分离 测试 线程ID及地址空间布局 编辑 POSIX线程库 pthread线程库是 POSIX线程库的一部分…...
JimuReport 积木报表 v1.8.0 版本发布,开源可视化报表
项目介绍 一款免费的数据可视化报表工具,含报表和大屏设计,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等! Web 版报表设计器,类似于excel操作风格,通过拖拽完…...
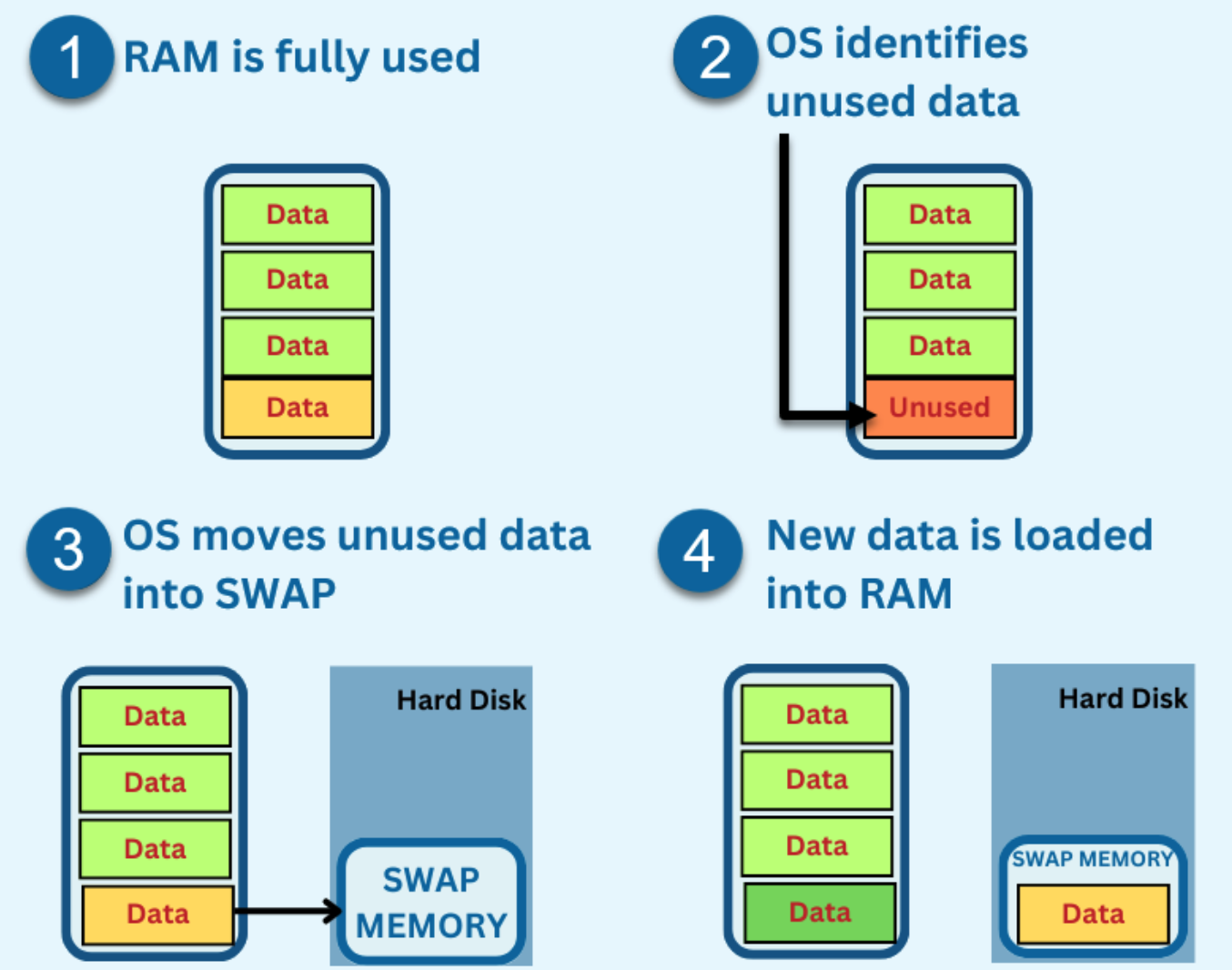
性能优化理论篇 | swap area是个什么东西
我们知道每台计算机的内存(RAM)都是有限的,而我们的应用程序需要加载到内存才能被运行,如果一台机器运行多个应用程序时,内存可能会耗尽。Linux 系统中的“交换空间(也称为交换分区)”可以帮助缓…...
下载安装win/mac版)
Photoshop (PS)下载安装win/mac版
目录 一、概述 下载 二、安装步骤 三、使用教程 四、快捷键汇总 一、概述 Adobe Photoshop,简称“PS”,是由Adobe Systems开发和发行的图像处理软件。它主要处理以像素所构成的数字图像,涵盖了诸多领域,如图像编辑、图像合成…...

初识redis:Set类型
Set有很多种含义,比如集合,比如设置(和get相对应)。 在这里我们说的set是指的redis中的集合,并且这里的集合是无序的,和之前的list是对应的。 List : [1,2,3] 和 [2,1,3] 是两个不同的listSe…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...