StarRocks 存算分离数据回收原理
前言
StarRocks存算分离表中,垃圾回收是为了删除那些无用的历史版本数据,从而节约存储空间。考虑到对象存储按照存储容量收费,因此,节约存储空间对于降本增效尤为必要。
在系统运行过程中,有以下几种情况可能会需要删除对象存储上的数据:
- 用户手动执行了删除库、表、分区等命令,如执行了 drop table、drop database 以及 drop partition 等命令
- 随着系统内 Compaction 任务不断进行,合并之前的数据文件可以被安全回收
目前在 StarRocks 的存算分离表存储在对象存储上的文件类型包含如下几种:
- Segment 文件:导入过程中会产生数据文件,存算分离的数据文件格式与存算一体保持一致
- Txn Log 文件:StarRocks 存算分离实现中,每次导入或者 Compaction 都会产生一次事务,每个 Tablet 在数据写入的最后阶段都会产生一个 Txn Log 文件,记录本次导入新增的数据文件列表
- Tablet Meta 文件:StarRocks 每次导入或者 Compaction 都会产生全局唯一的版本。而 Tablet Meta 文件在事务提交阶段产生,存储 Tablet 特定版本的元数据信息,其中主要记录了该版本所有可见的数据文件名
本文旨在描述 StarRocks 存算分离表垃圾回收的原理,会针对上述两种数据清理场景分别描述其内部原理,帮助开发和运维人员能更好地理解并根据实际需要做出合适的配置,以在性能和成本方面取得平衡。
数据多版本技术
在介绍数据清理之前,我们有必要先介绍下目前 StarRocks 存算分离的数据多版本技术,以便更好地理解垃圾数据回收原理。
StarRocks 存算分离版本中,数据在对象存储上的组织结构如下图所示:
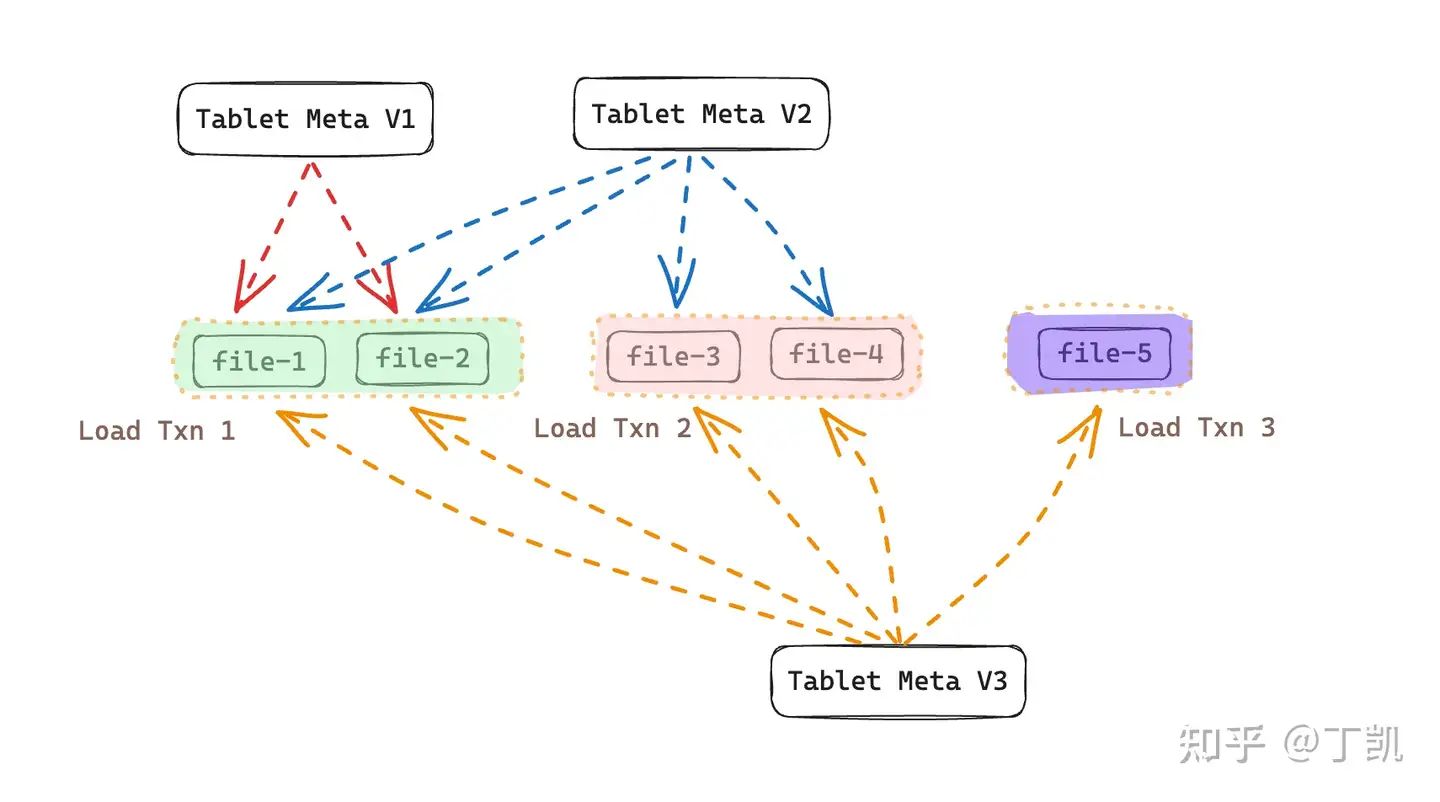
上图中共产生了三次数据导入事务,其中:
- Load Txn 1: 在事务数据写入阶段,生成了新数据文件 file 1 & file 2,该事务提交后生成了 Tablet Meta V1,其中记录该版本可见的文件列表为 {file-1, file-2}
- Load Txn 2: 在事务数据写入阶段,生成了新数据文件 file 3 & file 4。在提交时,根据前一个版本(即 Tablet Meta V1)然后加上本次导入事务生成的新数据文件(file-3 & file-4),生成了新的 Tablet Meta V2,因此,该版本可见的文件列表为 {file-1, file-2, file-3, file-4}
- Load Txn 3: 在事务写入阶段,产生了新数据文件 file 5。该事务提交时,根据前一个版本(即 Tablet Meta V2)然后加上本次导入事务生成的新数据文件(file-5),产生了新的 Tablet Meta V3,因此,该版本的可见文件列表为 {file-1, file-2, file-3, file-4, file-5}
除了用户导入事务产生了新的数据版本,在存算分离架构中,系统后台 Compaction 任务也会产生新数据版本。Compaction 的目的有二: 1). 将多个版本的小文件合并为大文件,减少查询时的随机 IO 次数,2). 消除重复数据记录,减少数据总量。
在存算分离表中,每次 Compaction 同样会产生一个全新的版本。依然以上面为例,假如在上面 Txn 3 之后新的事务 Txn 4 为一次 Compaction 任务,并且将 file1 ~ file4 这4个文件合并成为 file-6,那么该事务提交时,生成的新版本 Tablet Meta V4 内记录的文件列表为 {file-5, file-6}。
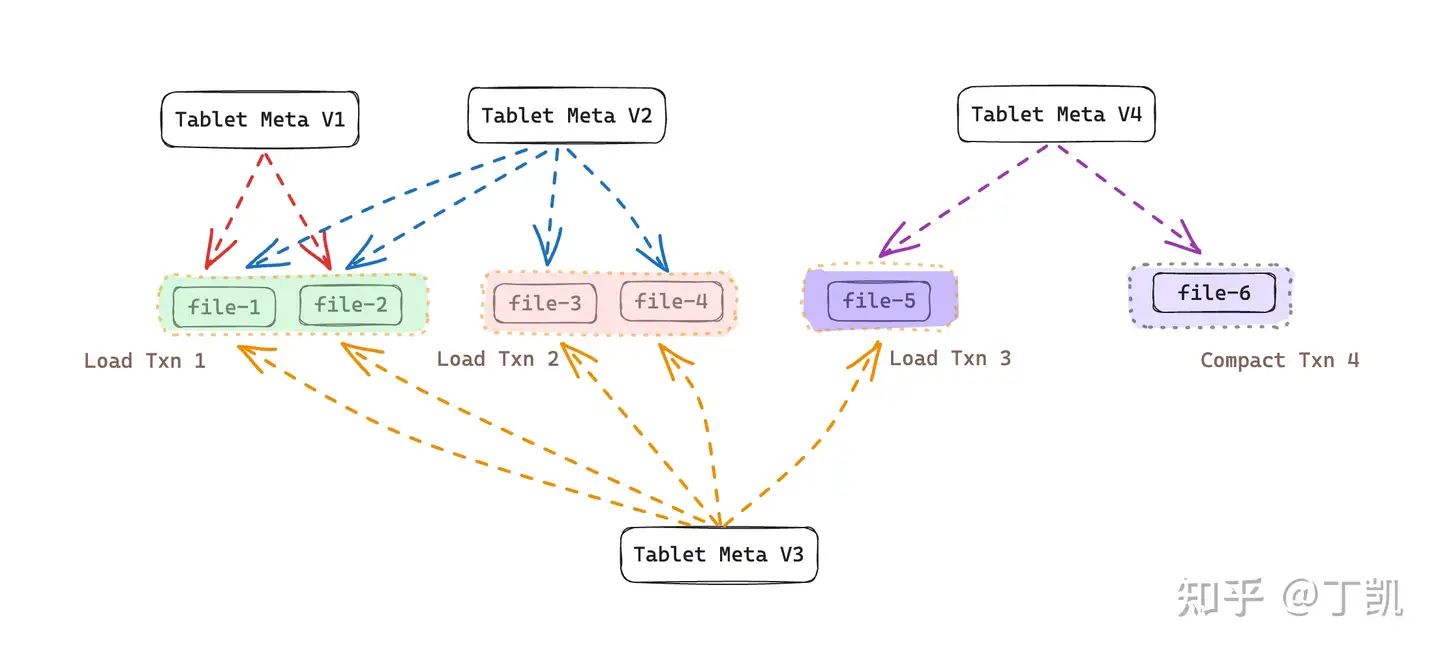
观察上例并思考可知,如果系统在运行过程中一直不会进行 Compaction。那么系统中的数据文永远也无法被删除。试想上例中我们即使将 Tablet Meta V1,Tablet Meta V2 文件删除,但我们无法删除 file-1、file-2、file-3 以及 file-4,因为这些文件依然被 Tablet Meta V3 所引用。
但有了数据合并(Compaction)后,情况就变得不一样了。上例中,由于发生了一次 Compaction(上图中的 Txn 4),将 file-1、file-2、file-3、file-4 合并生成了新文件 file-6 并生成了新的 Tablet Meta V4,由于 file-1 至 file-4 中的内容已经在 file-6 中存在,因而,一旦版本 V1、V2、V3 不再被访问,file-1、file-2、file-3、file-4 便可以被安全删除。此时的数据版本情况如下图所示:
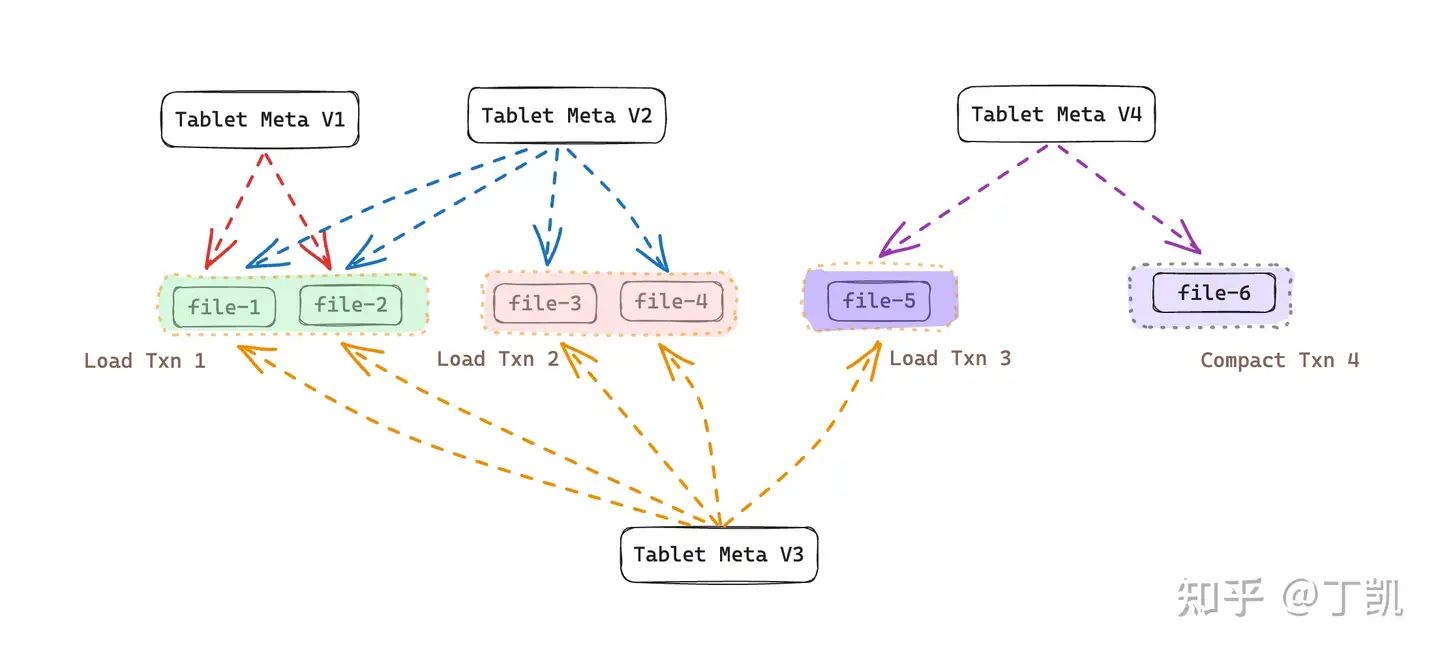
因此,综合上面的讨论,我们可以发现,只有在 Compaction 完成后原始的数据文件方可被删除(但 Tablet Meta 文件的清理依赖其他规则)。
目前我们在 Tablet Meta 组织上采用了一种高效方法:
对于 Compaction 事务, 我们会在其产生的 Tablet Meta 中记录本次合并任务的输入文件列表,这样,下次我们在清理该 Tablet Meta 时即可安全删除这些输入文件。
仍然以上面为例,Compaction Txn 4 在生成的 Tablet Meta V4 中记录了本次合并任务的输入文件 file-1、file-2、file-3、file-4。这样,下次系统清理掉 Tablet Meta V4 之后,拿到这个文件列表,便可以安全删除。
但这种删除方式也依赖一个前提:即 Tablet Meta 按照版本顺序删除,不可乱序。试想一下,上面的例子中,我们在删除版本 V4 时必须确保 V3 已经被安全删除。否则,访问 V3 时就会发现 file-1 这些已经被删除了。
工程实现
本章节主要描述当前垃圾数据清理的工程实现原理。
FE 后台清理线程
当前存算分离表的垃圾回收任务以 Partition 为单位执行,由 FE 节点构建清理任务并交由 CN 节点执行。具体来说,FE 会同时为若干个活跃 Partition 创建 Vacuum 任务,然后下发至 CN 执行。
Leader FE 节点上存在后台 Vacuum 线程,周期性运行,每次运行时:
1. 筛选出当前需要执行 Vacuum 的 Partition
2. 为筛选出的 Partition 构造 Vacuum 任务,交由 FE 端线程池处理这些任务
3. FE 端线程池可同时执行若干任务(由参数控制),每个任务都会下发给 Partition 内 Tablet 所在的 BE 执行
在步骤 2 中构造的 Vacuum 任务中,最关键的参数有三:
minRetainVersion: 控制 CN 端执行时需要保留的最小版本号。FE 决定了某个分区可以最多保留多少个历史版本。避免 CN 执行时清理过猛,将历史版本清理过多,造成正在进行中的查询访问历史版本数据失败。
graceTimestamp: 控制多长时间内产生的 Tablet Meta 不会被清理,避免在高频导入场景下,刚刚产生的 Tablet Meta 被立即回收
minActiveTxnId: 用于回收 Txn Log 文件
FE 为需要 Vacuum 的 Partition 构造好 VacuumRequest 发往 CN 节点,接下来 CN 节点只需要负责执行任务即可
CN 执行垃圾回收
CN 只需要负责执行 FE 下发的 VacuumRequest 即可。目前 Vacuum 任务复用了 RELEASE_SNAPSHOT 线程池(该线程池在存算分离集群上无用,因而可直接复用)。由于该线程池工作线程数量较少(默认为5),这可能在一定程度上影响清理速度,需要特别注意。
清理 Tablet Meta 文件
清理 Tablet Meta 实际上主要是清理如下内容:
- Tablet Meta 文件(即从对象存储上删除特定版本的 Tablet Meta 文件)
- 如果该版本是由 Compaction 事务产生,便可以收集到 Compaction 所对应的输入 Segment 文件,以便接下来删除(参考上面的例子,删除 Tablet Meta V4 的时候可以获取可以删除的数据文件 file-1 ~ file-4)
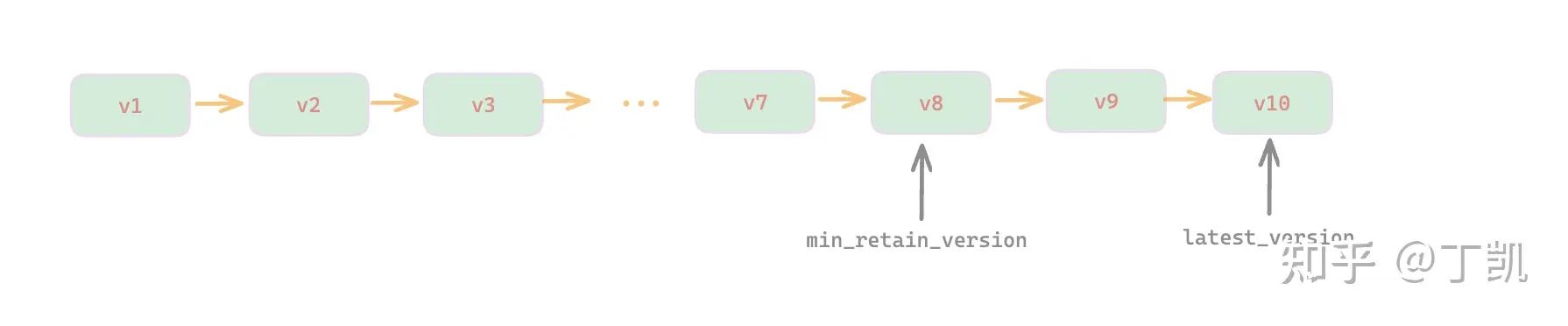
这里需要特别说明的一点是,对于某个特定 Tablet 的 Meta 文件的清理是往前回溯进行的。具体来说,FE 的 VacuumRequest 中记录了最大可回收版本号(min_retain_version),CN 节点处理时就从该版本开始逐步向前回溯。
例如下例中,假如最新的版本为 v10,且系统配置保留最近的3个版本,那么 min_retain_version 便是 v8,按照规则就是从 v7 开始向前回溯直到 v1。另外,在回溯时我们还会获取 Meta 文件的最后创建时间,如果没有超过一个特定的间隔(grace_timestamp),那也暂时不回收该 Tablet Meta 文件。
之所以采用这种前向回溯的方式的原因在于:
- 避免 list 所有 Meta 文件,因为 list object 调用在对象存储上效率非常低下
- 避免从前往后扫描时需要不断获取 Tablet 每个 Meta 文件的内容以获得 Compaction Input(假如 Meta 文件出现 cache miss,就会产生一次对象存储访问,效率低下)
不妨举个例子说明,如下图所示:
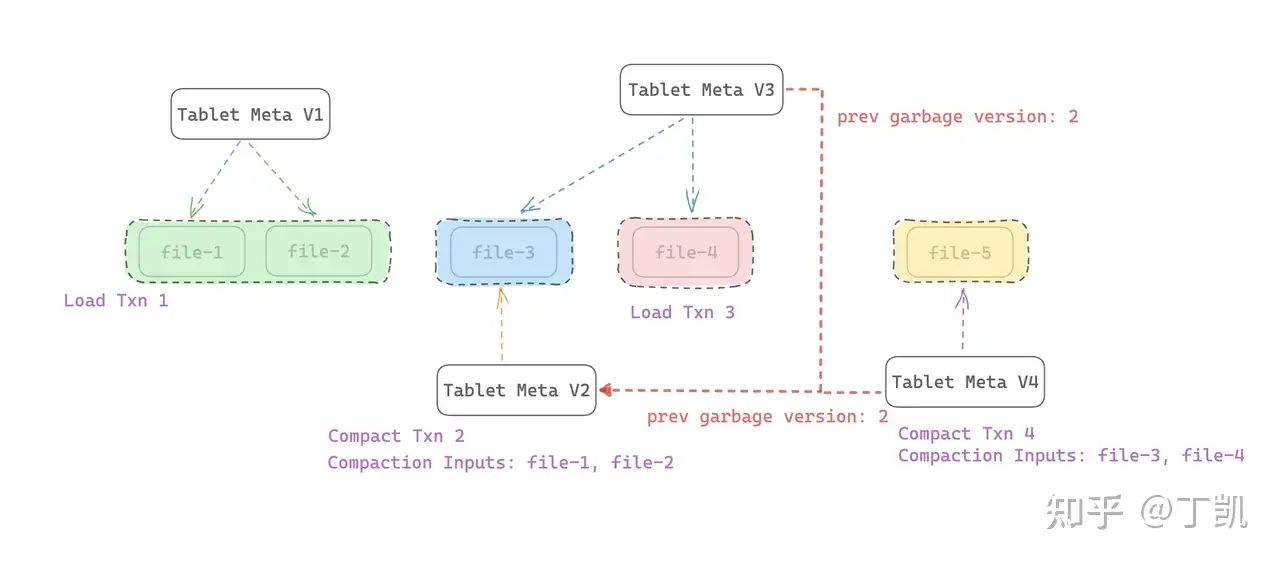
当前系统中有 4 次事务,其中
- Load Txn 1:导入事务,产生数据文件 file-1、file-2,该事务生成的 Meta V1 内记录文件为 {file-1, file-2}
- Compaction Txn 2:Compaction 事务,将 file-1、file-2 合并为新文件 file-3,该事务生成的 Meta V2 内记录文件为 {file-3},同时记录了 Compaction Inputs 为 {file-1, file-2}
- Load Txn 3:导入事务,产生数据文件 file-4,该事务生成的 Meta V3 内记录文件为 {file-3, file-4}
- Compaction Txn 4:数据合并事务,将 file-3、file-4 合并为新文件 file-5,该事务生成的 Meta V4 内记录文件为 {file-5}, 同时记录了 Compaction Inputs 为 {file-3, file-4}
试想下,如果按照顺序遍历的方式清理,那么我们首先:
- 要通过 list object 获取起始版本号,为 V1,产生一次对象存储的 list object 调用
- 以 V1 为起始版本号,逐个递增开始获得 Meta 文件,且对于每个 Meta 文件都需要读取内容,获得 Compaction Input Files 字段,取得可以被清理的数据文件列表,那么本例中就需要执行 4 次,如下:
打开并读取 Tablet Meta V1,获取 Compaction Input Files,然后清理
打开并读取 Tablet Meta V2,获取 Compaction Input Files,然后清理
打开并读取 Tablet Meta V3,获取 Compaction Input Files,然后清理
打开并读取 Tablet Meta V4,获取 Compaction Input Files,然后清理
这里需要访问 V1 ~ V4 这所有 Tablet Meta,而获取 Tablet Meta 文件内容可能是一个较为耗时的动作(假如 Tablet Meta Cache Miss 时就需要访问对象存储)。
而通过从后往前的回溯遍历方式就可以避免上述问题,但前提是需要构建好一个前向回溯链。
为了构造前向回溯链,我们做了一个优化,在每个 Tablet Meta 中记录了前一次 Compaction Txn 的版本号(prev_garbage_version),例如在本例中,Tablet Meta V3 中记录了该字段为 V2,而 Tablet Meta V4 由于拷贝自 Tablet Meta V3,因此 prev_garbage_version 字段值便也为 V2。
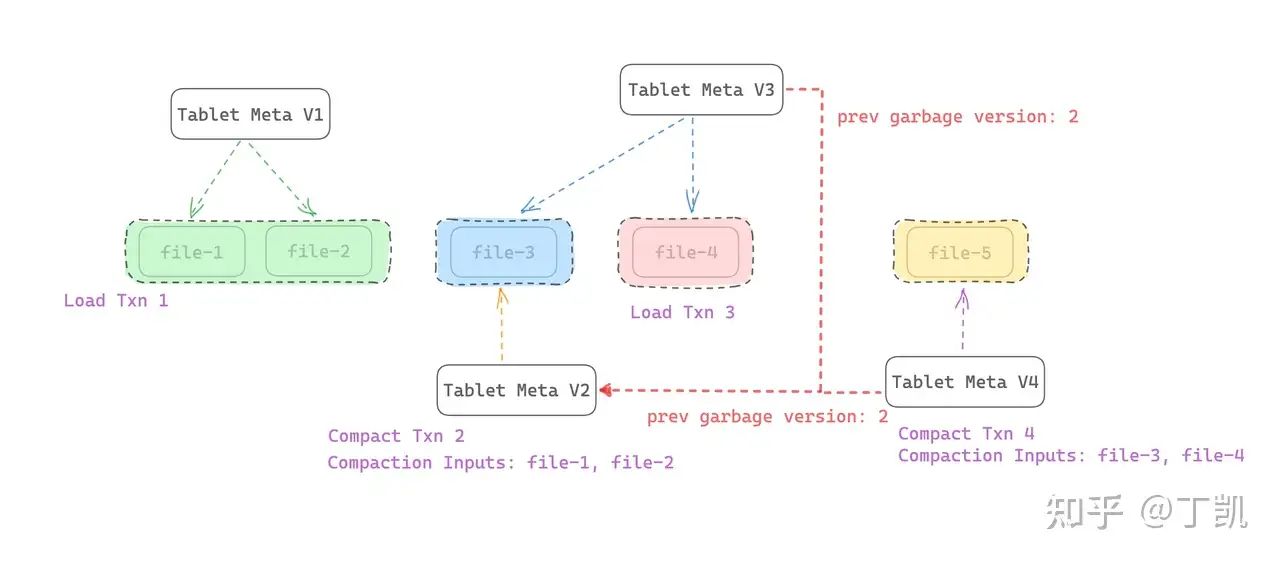
回收时,首先获得 Tablet Meta V4,假如判断其为安全可删除的,接下来找到 prev_garbage_version,这里记录为 V2,因而,这里便可以跳过 Tablet Meta V3,直接找到 Tablet Meta V2,获得其 Compaction inputs,也可以被安全删除。而由于 Tablet Meta V2 内的 prev_prev_garbage_version 为空,因此,便不再需要往前回溯了。这样,就避免了打开 Tablet Meta V1 和 Tablet Meta V3,就获得了所有 Compaction 事务的 Input Files。
清理 Segment 文件
垃圾回收的核心在于回收无用数据文件,而根据上文的基本原理可知,删除数据文件一般发生在清理那些 Compaction 事务产生的 Tablet Meta 文件时,这些文件中记录了当次 Compaction 的输入文件列表,由于这些文件已经被成功合并生成了新的文件,因此,这些原始输入文件可以被安全删除了。
因此,对于 CN 节点来说,就非常简单了,在上面的清理 Tablet Meta 文件时,捎带获取到 Tablet Meta 文件中记录的 Compaction Input Files 内容,然后就可以安全删除。
考虑到一般对象存储提供了批量删除文件接口,CN 在清理 Segment 文件时也进行了批量删除,由参数 lake_vacuum_min_batch_delete_size 控制批次大小。
清理 Txn Log 文件
Txn Log 文件在数据导入过程中产生,记录本次导入或者 Compaction 过程中产生的新文件。正常情况下,Txn Log文件一般在事务提交后即被删除。但异常时该文件可能会残留,也依赖后台的 Vacuum 任务来统一清理。
CN 清理时首先通过 list objects 来获得当前所有的 Txn Log 文件(由于 Txn Log 文件存储在单独 log/ 目录下,对象数较少,list 效率一般不会成为大问题),然后从文件名中解析出 tablet id 和 txn id 信息,接下来判断该 Txn Log 文件是否可以被安全删除,原理也比较简单:
判断该txn id是否比当前系统中的最小活跃事务id更小(min active txn id),如果是,那么意味着该事务一定在 FE 上已经结束了(要么已提交,要么已回滚),此时 Txn Log 即可被安全删除。
删除表和分区
StarRocks 目前有如下几种方式来删除表和分区:
drop table xxx;
drop table xxx force;
drop partition xxx;
drop partition xxx force;
前者实现了回收站机制,删除的表会先放入回收站,直到一段时间后才开始真正删除。而后者则立即删除,无任何缓冲时间。
当前实现中,删除表会触发我们物理删除表上的所有数据,而从对象存储删除数据是一个非常耗时的动作。我们将两种删除模式进行统一,都统一为后台异步清理模式。用户提交的删除表命令会立即返回成功,后台线程会慢慢删除表的物理数据。
删除表
删除分区的实现原理同删除表基本一致,也都是将待删除的分区加入回收站中,而 FE 后台线程则会不断地从回收站中取出需要被删除的 table,执行真正的删除动作。
真正的数据删除在 deleteFromRecycleBin 内实现,对于存算分离内表,对于一个表进行物理删除时,内部也是按照分区为单位逐个进行删除,因为我们当前最新的版本是按照分区为粒度组织数据目录,如下所示:
${cluster_uuid}/${db_id}/${table_id}/${partition_id}
而删除最终是调用了 CN 节点的 drop_table 的 RPC 接口来执行真正的数据删除。
真正删除时,通过调用 remove_all 来直接将分区目录下面的所有文件一次性删除,效率较高。而且,可以发现,这里的删除任务会被提交到一个独立的线程池来执行。
删除分区
删除分区的实现原理同删除表基本一致,也都是将待删除的分区加入回收站中,然后在回收站后台慢慢清理。最终的清理也是调用 CN 节点的 drop_table 的 rpc 接口来完成真正的数据删除。这个已经在前面描述过,这里就不再赘述。
缓存清理
当前的实现中,回收对象存储的垃圾数据文件时并不会同步删除缓存,缓存淘汰依赖自身的 LRU 机制。
相关文章:
StarRocks 存算分离数据回收原理
前言 StarRocks存算分离表中,垃圾回收是为了删除那些无用的历史版本数据,从而节约存储空间。考虑到对象存储按照存储容量收费,因此,节约存储空间对于降本增效尤为必要。 在系统运行过程中,有以下几种情况可能会需要删…...

【运维】Linux中的xargs指令如何使用?
xargs 是 Linux 中一个非常强大的命令,用于将标准输入中的输出作为参数传递给其他命令。通常情况下,xargs 用于处理长列表或者将多行输入转换成一行。 以下是 xargs 的基本用法和一些常见的例子: 基本语法 command | xargs [options] [command]常见的例子 删除文件:假设…...

日志审计-graylog ssh登录超过6次告警
Apt 设备通过UDP收集日志,在gray创建接收端口192.168.0.187:1514 1、ssh登录失败次数大于5次 ssh日志级别默认为INFO级别,通过系统rsyslog模块处理,日志默认存储在/var/log/auth.log。 将日志转发到graylog vim /etc/rsyslog.conf 文件末…...

4. kafka消息监控客户端工具
KafkaKing官网地址 : https://github.com/Bronya0/Kafka-King github下载地址 : Releases Bronya0/Kafka-King (github.com) (windows、macos、linux版本) 云盘下载地址 : https://pan.baidu.com/s/1dzxTPYBcNjCTSsLuHc1TZw?pwd276i (仅windows版本) 连接kafka 输入本地地址…...

鸿蒙环境和模拟器安装
下载华为开发者工具套件,并解压 https://developer.harmonyos.com/deveco-developer-suite/enabling/kit?currentPage1&pageSize10 双击dmg安装ide 复制并解压sdk 安装模拟器 https://yuque.antfin-inc.com/ainan.lsd/cm586u/po19k1mi9b2728da?singleDoc#…...

【图文并茂】ant design pro 如何对接后端个人信息接口
上一节我们有讲到如何对接登录接口的 【图文并茂】ant design pro 如何对接登录接口 仅仅能登录是最基本的,但是我们要进入后台还是需要另一个接口。 这个接口有两个作用: 来获取当前登录账号的信息,比如头像,用户名࿰…...

MySQL运维学习(1):4种日志
1.错误日志 mysql错误日志记录了mysql发生任何严重错误时的信息,若数据库无法正常使用时,可以先查看错误日志 默认情况下错误日志是开启的,文件名为/var/log/mysqld.log,如果文件不在默认位置,可以通过下面的命令查看…...
)
代码随想录算法训练营第二十天(二叉树 七)
day19 周日放假 今天依旧是二叉树环节 力扣题部分: 235. 二叉搜索树的最近公共祖先 题目链接:. - 力扣(LeetCode) 题面: 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T …...

Django 后端架构开发:通用表单视图、组件对接、验证机制和组件开发
🌟 Django 后端架构开发:通用表单视图、组件对接、验证机制和组件开发 🔹 django 通用表单视图 Django 的通用表单视图提供了快速创建和处理表单的功能,使得表单处理变得简洁而高效。以下示例展示了如何使用通用表单视图创建一个…...
Cookie和Session是什么?它们的区别是什么?
【知识】深入理解COOKIE&SESSION的原理和区别-腾讯云开发者社区-腾讯云 (tencent.com) Cookie和Session的区别(面试必备)_cookie和session的作用和区别-CSDN博客 Cookie和Session是什么?它们的区别是什么?_cookie里面的字符…...

Python正则表达式提取车牌号
在Python中使用正则表达式(Regular Expressions)来提取车牌号是一个常见的任务,尤其是在处理车辆信息或进行图像识别后的文本处理时。中国的车牌号格式多种多样,但通常包含省份简称、英文字母和数字。以下是一个使用Python正则表达…...

视觉引导机械臂学习记录
首先是几个位置,拍照位、示教位、目标位置。 流程主要是 1.首先选取一个拍照位,相机扫描点云,通过点云质量进行选取。并且制作点云模板,进行配准,如果配准分数高则模板选取正确。 2.用相机拍灰度图像,并…...

插屏广告在游戏APP中广告变现的独特优势
插屏广告是目前全球移动应用变现的主要广告形式之一,其优势在于可以快速收回成本,又能适应于多数缺乏激励场景的应用。 插屏广告通常在app使用过程中的自然过渡点,比如暂停场景切换的时候弹出,以图片、动图、视频等为表现形式的半…...

Python数据分析:数据可视化(Matplotlib、Seaborn)
数据可视化是数据分析中不可或缺的一部分,通过将数据以图形的方式展示出来,可以更直观地理解数据的分布和趋势。在Python中,Matplotlib和Seaborn是两个非常流行和强大的数据可视化库。本文将详细介绍这两个库的使用方法,并附上一个…...

Java CompletableFuture:你真的了解它吗?
文章目录 1 什么是 CompletableFuture?2 如何正确使用 CompletableFuture 对象?3 如何结合回调函数处理异步任务结果?4 如何组合并处理多个 CompletableFuture? 1 什么是 CompletableFuture? CompletableFuture 是 Ja…...

5个免费在线 AI 绘画网站推荐,附100+提示词!
在数字化时代,艺术创作与人工智能的结合已带来前所未有的创新体验。AI 绘画技术,基于先进的人工智能算法,为艺术创作提供了全新的视角和工具。当前,多个免费在线AI绘画平台应运而生,为创作者们提供了丰富的灵感和创作机…...

C++基础语法:while的使用
前言 "打牢基础,万事不愁" .C的基础语法的学习."学以致用,边学边用",编程是实践性很强的技术,在运用中理解,总结. 引入 while的使用是编写代码的基础内容.笔者的记忆力已不如以前,最近遇到了还花了不少功夫,可见是掌握地不够牢固.所以对while的思路和内容…...

鹏哥C语言自定义笔记重点(29-)
29.函数指针数组 30.void指针是不能直接解引用,也不能-整数。 void*是无具体类型的指针,可以接受任何类型的地址。 31.qsort:使用快速排序的思想实现一个排序函数(升序) 32. 33.地址的字节是4/8 34.char arr[]{a,b} sizeof(arr[0]1)答案是4࿰…...
、Bellman_ford 算法精讲)
代码随想录算法训练营第六十天 | dijkstra(堆优化版)、Bellman_ford 算法精讲
一、dijkstra(堆优化版) 题目连接:47. 参加科学大会(第六期模拟笔试) (kamacoder.com) 文章讲解:代码随想录 (programmercarl.com)——dijkstra(堆优化版) 二、Bellman_ford 算法精讲…...

boost::asio 库版本,C/C++代码编译兼容性
1、boost::asio::spawn 开启有栈(stackful)协同程序,版本改进及限制 > boost_1_80 版本应采用以下方式。 auto f [self, this](const boost::asio::yield_context& y) noexcept {bool success_ do_handshake(y);if (!success_) {clo…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...