2023爱分析·AIGC市场厂商评估报告:拓尔思

市场定义:
AIGC,指利用自然语言处理技术(NLP)、深度神经网络技术(DNN)等人工智能技术,基于与人类交互所确定的主题,由AI算法模型完全自主、自动生成内容,从而帮助传媒、电商、影视、娱乐等行业进行文本、图像、音视频、代码、策略等多模态内容的单一或跨模态生成,以提升内容生产效率与多样性。
终端用户:
金融、传媒、元宇宙等行业组织的产研与业务部门、政府部门
甲方核心需求:
AIGC最核心的能力,就是内容生成。经过训练的AI算法模型,能够超越人类创意、效率,相对高质量地规模化生成海量数字化内容。一方面,AIGC可降低海量数字内容的生成成本,将人类从简单且重复、基础性工作中解放出来,聚焦更具创造性的方面;一方面,在人类进行内容创作的过程中,AIGC能够快速生成大量相关内容,帮助人类扩充、寻找创作灵感,或者基于所提供的信息,夯实创作基础。
比如,在传媒领域,部分新闻内容的自动抓取与生成、标题或摘要的自动化生成;在营销领域更具智能的客服机器人,能够更温和、人性化的回答客户常见问题甚至跳跃性问题及非常规问题;在元宇宙领域,可基于智能算法和知识图谱,让数字人更加智能地与人类进行交互。
作为人工智能应用的重大突破,AIGC正在改变甚至颠覆数字内容的生产与消费方式,在Web 3的大背景下,有望成为继PGC、UGC之后的主要内容创作来源。但国内的AIGC整体上还处于相对早期的阶段,不同细分领域的技术及应用落地进度不尽相同。如何基于预训练大模型形成面向不同行业的、可落地的产品及解决方案,是当前AIGC领域发展的关键。具体如下:
- 在大模型能力方面,企业需要经过调优的垂直化行业大模型,以很好地支撑上层垂直化应用。GPT-3、BERT、Florence、DALL·E 2等通用预训练大模型虽然拥有巨量参数,并拥有良好的泛化能力,但在面对不同行业、领域的具体应用场景时,由于缺乏具体行业的行业语料集,并且未面向特定行业的应用场景对模型做进一步调优,因此,其模型对特定行业应用场景的性能指标很可能并不理想。因此,经过行业化调优和行业语料训练的大模型,才能更好地支撑甲方的具体上层应用。
- 在落地应用方面,企业需要端到端的AI落地应用服务,确保大模型能够在具体业务场景下,可产生符合预期的实际应用价值,提高组织在特定场景中的生产效能。一方面,AI六十余年的发展历程已经证明,从模型到高质量的生产与实践,AI工程化能力非常重要。但大多数企业往往并不具备从需求的原点出发,到模型的设计、数据标注与模型训练、模型部署及迭代优化的AI闭环落地能力,无法确保大模型真正贴合自身应用场景,实现价值落地;另一方面,很多企业同样也不具备基于大模型进行上层应用开发的能力,预训练大模型虽已经过设计和训练,但由于还需要行业化的二次优化与训练,并且需要结合应用场景进行实际业务应用开发,因此仍旧对企业的AI闭环能力提出了一定要求。
除此之外,甲方还有以下期望需求:
- 在底层能力方面,企业需要生成算法、预训练大模型的迭代更新,以提供更优的底层算法支撑。预训练模型是人工智能科技巨头在GAN、Transformer、Diffusion、CLIP等基础生成算法的基础上,进行融合、扩展、训练而来的,新一代的基础生成算法在模型架构、精准度方面往往表现更优,例如Diffusion替代GAN成为图像生成领域的主流算法。预训练模型的迭代与突破,在参数量、算力要求、模型效果方面可能会取得更优的综合效能,例如Open AI GPT模型1.0-3.5的持续迭代,抑或是LLaMA以更小体量取得了可能比GPT3更好的模型表现。基础生成算法、预训练大模型的迭代,虽然可能会引发算法效果的质变,但因为需要庞大的人才队伍、巨量资金支持以及长时间积累,往往是只有国内外科技巨头能够覆盖。
图1:甲方企业对于AIGC落地应用的需求

厂商能力要求:
厂商需同时具备以下能力,以帮助各行业组织实现具体场景的应用落地:
- 厂商具备基于开源预训练模型,结合行业语料及NLP等技术针对性优化出具有优秀可控性的特定领域大模型的能力。一方面,厂商需要能利用行业know how,结合自身在AI领域的技术积累,微调通用预训练大模型。另一方面,能够充分利用自身在特定行业的数据和语料积累,在微调后的大模型基础上,结合行业化、场景化数据进行进一步训练,以提升大模型针对特定行业及应用场景的模型表现,生成符合一定要求和标准的内容,训练出真正适合特定行业及应用场景的专业大模型。
- 厂商需要具备出色的AI工程化能力及行业服务经验,能够AI落地全链路服务,灵活适配用户需求。厂商需要丰富的行业经验,能够进行场景抽象和数据准备,在此基础上进行算法设计、模型训练、模型评估与调优、模型部署的全链路能力,并且需要在模型部署上线后,根据行业应用场景的实践,不断进行模型优化,确保模型结果可控,从而让AI大模型的“生成能力”不断接近应用要求,产生真正的业务价值。
针对甲方的期望需求,厂商还应具备以下可选能力:
- 厂商需要有基础生成算法、预训练大模型的迭代和突破能力,能够为中层的大模型行业化、上层的行业应用提供支撑。厂商需要在自身的技术积累的基础上,对现有Transformer、CLIP等基础生成算法以及GPT、BERT、Florence、DALL·E 2等各模态预训练大模型进行深入拆解与思考,提出新的改进思路和方向并进行验证、训练,或者更适合某种语言类型的大模型,以便在模型效果上进行持续突破,进而给行业模型、上层应用提供更多更好的选择,帮助改进模型的应用价值与效果。
入选标准说明:
1. 符合AIGC市场定义的厂商能力要求;
2. 近一年在AIGC市场中付费客户数5家以上;
3. 近一年该市场相关营业收入规模在100万元以上。
入选厂商:

代表厂商评估:
厂商介绍:
拓尔思信息技术股份有限公司(以下简称“拓尔思”),以人工智能和大数据技术助力政府和企业的数字化转型为愿景,致力于成为语义智能技术领导者,自主研发相关人工智能和大数据技术,核心业务涵盖大数据、人工智能、内容管理、网络安全和数字营销等领域。
产品服务介绍:
拓尔思目前以语义智能为发展主线,以平台和行业应用产品、云和数据服务相结合的产品+服务战略,实现公司核心技术在众多垂直行业的应用落地,赋能中高端企业级客户的数字化和智慧化转型。在AIGC领域,拓尔思聚焦文本内容的自动生成,以“专业大模型+领域知识数据”为核心思路,通过模型调优和行业特有大数据与知识的融合,为新闻、政务、金融、元宇宙等优势行业提供高质量专业大模型及上层应用,赋能辅助型、创作型等文本内容的自动生成。
厂商评估:
综合而言,拓尔思在通用大模型调优、行业数据库积累、应用落地能力等三方面具备较为突出的优势,具体如下:
- 在通用大模型调优方面,拓尔思具有丰富且领先的深度学习、NLP技术积累,具有出色的大模型“垂直化”调优能力,正全力打造“智创”AIGC平台,将大模型调优能力平台化、产品化,以更好支撑上层应用。
一方面,拓尔思自2000年开始就自主研发NLP技术,长期聚焦自然语言处理(NLP)、知识图谱等语义智能核心技术,将通用预训练大模型与传统NLP技术相结合,利用行业Know-How,根据不同场景,通过对通用大模型进行调整和优化(Fine-tuning)来适配不同指标,获得不同行业客户侧重的准确率、召回率、综合F1值等指标,形成行业化的“专业大模型”,进一步优化结果可控性,更好地服务于用户的具体场景和需求。
另一方面,拓尔思秉承“开源+自研模型”的基本思路打造“智创”AIGC平台,通过API接口或解决方案模式,更好支撑上层应用,将优先关注元宇宙、传媒、金融领域、政务服务、通用行业和云服务等细分市场。其中,在AIGC “文本生成”领域,拓尔思实现自大模型到上层应用的一体化打通;在视觉、多模态领域,拓尔思将依托开源平台,基于 “开源基础大模型+行业任务调优”的思路进行研发,偏重前端应用。
图2:拓尔思“智创”AIGC平台架构示意

- 在行业数据库方面,拓尔思具有媒体、金融、政务等多行业服务经验及丰富行业语料,可针对各行业训练出具有行业知识壁垒的高质量大模型。
一方面,拓尔思从2010年自建数据中心以来,已采集超过10年的互联网公开数据,拥有规模及质量均位列业界前茅的另类数据资产,数据规模超1300亿条,数据总量达100TB以上。拓尔思依托完整的数据和知识工程治理体系,基于拓尔思自研的数据底座对上述数据资源不断进行采集、清洗、转换、分类、打标等后,推送至拓尔思媒体资讯、网络舆情、产业大脑三大数据资产平台,通过与不同行业知识模型的融合处理,形成数据资产,可用作大模型训练语料,具备高质量、高价值特征,有利于提升大模型的专业性与精准度。
图3:拓尔思30+专业领域知识资产示意

另一方面,拓尔思基于专注优势行业专业大模型研发与应用的战略定位,在调优后的专业大模型基础上,依托上述明显的大模型训练语料数据优势,进一步训练出具有行业知识壁垒的行业大模型,大幅提升通用预训练大模型对行业应用的适配性。拓尔思通过在应用场景下的领先起跑,通过反馈+强化学习,加速飞轮效应,持续提升专业大模型的“可控性”与“安全性”。
- 在应用落地方面,拓尔思具备自模型设计、训练、优化、部署等在内的一站式AI工程化能力,提供端到端的AI应用落地服务,可赋能机器写作、自动报告生成、知识型搜索引擎等多行业具体应用场景,并以“生态力”持续强化自身AIGC应用落地保障能力。
一方面,拓尔思具备智能数据标注、模型设计、训练、优化、评估、部署等一站式AI工程化落地服务能力,叠加在政务、媒体、金融、舆情、安全、专利等行业丰富的应用场景实践,有助于专业大模型贴合用户场景进行快速落地,产生业务价值。
例如,拓尔思为经济日报、浙江日报、重庆日报等近20家新闻媒体单位提供机器写稿服务;为冶金工业信息标准研究院、南方电网、新华网、教育出版社等提供研报自动生成服务;此外,拓尔思还将与某权威新闻机构合作,将该机构的新闻数据库和历史资料录入大模型做预训练,基于高针对性交互,形成权威且高效的内容输出,形成供该机构内部使用的知识型搜索引擎,供该单位的内容创作者进行再创作时做参考,完成辅助创作。
另一方面,在大模型时代,“生态力”是“AIGC+”在各行各业成功商业落地的重要保障。拓尔思将持续建立和强化NLP商业生态,与行业知识专家、平台型企业、行业头部企业展开领域知识、算力、行业创新等方面的合作,发挥自身数据资源、行业经验及技术优势,确保AIGC更好、更持续落地。
典型案例:
1. 案例背景及客户需求痛点
随着元宇宙概念的火爆,虚拟人有望成为下一代互联网人机交互的重要入口,正在AI新闻主播、智能陪护、智能助理、直播带货等越来越多领域发挥作用,创造现实价值,不仅有助于大幅降低某些场景的人力成本,也一定程度上提升了服务的人性化程度、智能化程度。2022年北京冬奥会的成功举办,更为虚拟人在传媒行业的应用提供了发展契机,众多形象各异的虚拟人纷纷破圈而出。总体来看,传媒行业传统的内容生产主要面临以下痛点:
1)内容生产流程分散、低效。从热点发现、选题策划到内容采编发,均以人工手动获取为主,具有滞后性和局限性。
2)传播形式较为传统。传统的传播以图文、视频等常见形式进行信息传播与展示,受众存在一定的审美疲劳,会间接影响传播效率和效果。
2. 拓尔思的产品及解决方案
针对以上需求痛点,拓尔思在基于自主研发的、集成了自然语言处理、大数据、人工智能等技术的数字虚拟人SaaS平台上进行开发,推出了AI主播“小思”,为北京冬奥会提供以媒体大数据驱动的、集自动分析、智能创作、虚拟播报于一体的产品与服务。
1)在自动分析与智能创作方面,拓尔思通过媒体大数据采集与NLP自然语言处理技术,建立关联关系,形成知识图谱,为“小思”提供“智慧大脑”,快速自动生成分析报道。
在数据采集与处理环节,拓尔思采用全新架构的大规模分布式调度采集系统,实现弹性采集与碎片化调度,以人工辅助+机器自动标引相结合的方式实现对数据的精加工;
在数据建模分析环节,将人工经验知识库+智能挖掘机理相结合,由专家团队人工整理语料及规则形成知识库,并以此为基础进行语料深度学习;
在数据应用环节,通过冬奥会新闻舆情分析、传播效果分析及冬奥会观众画像分析等,实现大数据应用可视化、自动采编、智能写稿。
2)在虚拟播报方面,依托虚拟人形象技术,用户可进行虚拟人形象选择,实现虚拟人口型的同步驱动,为“小思”提供端庄、大气、灵动的外表。
依托拓尔思的虚拟人SaaS服务平台,提供从选“人”到成片的虚拟人制作的一站式服务为用户的操作提供了最大便捷。该平台最底层为虚拟人的形象技术支撑,包括形象、语音、视觉中枢,旨在实现文本合成语音,语音驱动虚拟人口型的同步。同时,该平台还支持针对虚拟人形象的选择,包括2D、3D、以及基于真人形象的采集训练还原,支持对虚拟人参数的各种可配置化功能,如服装、颜色、姿势、 声音、肢体动作等参数的可配置化。
图4:拓尔思AI主播“小思”-北京冬奥播报示意

3. 方案优势
小思冬奥播报真正实现数据自动采集、语义智能分析、内容自动生成、虚拟人播报等一体化、全自动功能。
在内容自动生成方面,与同行业相比,拓尔思深厚的大数据及AI技术能力,大幅提高了内容生成速度及播报准确度。拓尔思在语义智能技术领域,具有先发全栈的自然语言处理能力优势;在大数据技术领域,公司具备数据获取、数据治理、数据检索、数据分析全生命周期的能力,拓尔思数据中心已具备数千亿数据量的数据索引、标记、查询、挖掘分析能力,万亿级数据总量的秒级检索能力,日均亿级数据获取能力。大数据及NLP技术提升智能化水平,为赋予小思“实用的灵魂”提供了坚实支撑。
在虚拟人播报方面,用户可根据需要灵活定制主播形象。拓尔思的虚拟人SaaS平台提供多套服装配饰、表情动作、肢体动作、声音等供用户选择,适配不同场景的播报。支持多视频开窗、图片开窗、文本开窗、字幕、图层、背景、LOGO等视频编辑功能,用户只需简单拖入各种素材元素、配置元素的属性、调整元素图层的叠加顺序,即可完成内容丰富、样式多样的虚拟人内容播报。
4. 方案价值
“小思”以冬奥会整体报道情况与热点解析为切入点,主要应用场景包括北京冬奥会报道线索发现(实时聚焦、海内外爆料等)、热点挖掘(冬奥会全网热点、媒体头条等)、传播分析(关注冬奥会的用户画像等)及专题追踪等,可帮助观众了解冬奥会赛事盛况、快速把握冬奥会海量资讯中的亮点信息。“拓尔思虚拟数字人小思冬奥播报”案例同时入选了“北京国家人工智能创新应用先导区优秀案例”和“2022北京产业互联网创新应用场景案例”。
此外,拓尔思数字虚拟人技术还在相关主流媒体的冬奥宣传报道中进行了成功应用,替代人力完成传媒流程中的采、编、发、以及分析等任务,优化升级了传媒现有流程,推动主流媒体将人力安排到更有意义和价值的策划和内容创作等工作当中,有效解放及最大化了主流媒体的生产力。
相关文章:
2023爱分析·AIGC市场厂商评估报告:拓尔思
AIGC市场定义 市场定义: AIGC,指利用自然语言处理技术(NLP)、深度神经网络技术(DNN)等人工智能技术,基于与人类交互所确定的主题,由AI算法模型完全自主、自动生成内容,…...

MobTech|场景唤醒的实现
什么是场景唤醒? 场景唤醒是moblink的一项核心功能,可以实现从打开的Web页面,一键唤醒App,并恢复对应的场景。 场景是指用户在App内的某个特定页面或状态,比如商品详情页、活动页、个人主页等。每个场景都有一个唯一…...
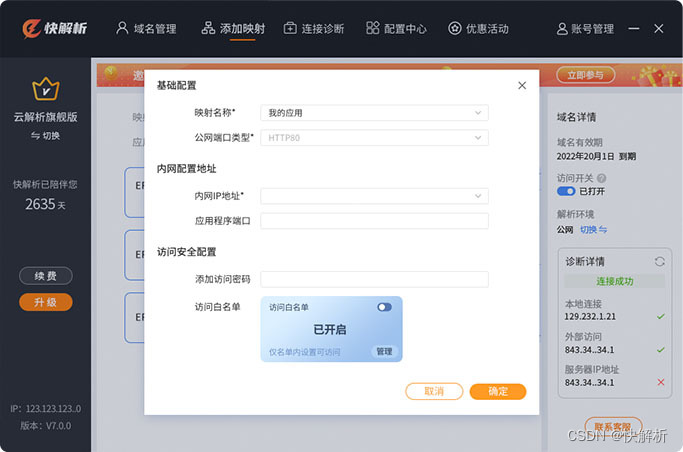
不在路由器上做端口映射,如何访问局域网内网站
假设现在外网有一台ADSL直接拨号上网的电脑,所获得的是公网IP。然后它想访问局域网内的电脑上面的网站,那么就需要在路由器上做端口映射。在路由器上做端口映射的具体规则是:将所有发向自己端口的数据,都转发到内网的计算机。 访…...

ChatGPT 辅助科研写作
前言 总结一些在科研写作中 ChatGPT 的功能,以助力提升科研写作的效率。 文章目录前言一、ChatGPT 简介1. ChatGPT 普通版与 Plus 版的区别1)普通账号2)Plus账号二、New Bing 简介1. 快速通过申请三、辅助学术写作1. 改写论文表述2. 语言润色…...
MySQL最大建议行数 2000w,靠谱吗?
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址 1 背景 作为在后端圈开车的多年…...
【Tomcat 学习】
Tomcat 学习 笔记记录一、Tomcat1. Tomcat目录2. Tomcat启动3. Tomcat部署项目4. 解决Tomcat启动乱码问题5. JavaWeb项目创建部署6. 打war包发布项目7. Tomcat配置文件8. Tomcat配置虚拟目录(不用在webapps目录下)9. Tomcat配置虚拟主机10. 修改web项目默认加载资源路径一、Tom…...

重装系统如何做到三步装机
小白三步版在给电脑重装系统的过程中,它会提供系统备份、还原和重装等多种功能。下面也将介绍小白三步版的主要功能,以及使用技巧和注意事项。 主要功能 系统备份和还原:小白三步版可以帮助用户备份系统和数据,以防止重要数据丢失…...

蓝桥杯单片机第十一届省赛客观题(深夜学习——单片机)
第一场 (1)模电——》多级放大电路 阻容耦合,只通交流,不通直流。 变压器耦合,只通交流,不通直流。 光电耦合,主要是起隔离作用,更多的用在非线性的应用电路中 (2&a…...

Pandas对Excel文件进行读取、增删、打开、保存等操作的代码实现
文章目录前言一、Pandas 的主要函数包括二、使用步骤1.简单示例2.保存Excel操作3.删除和添加数据4.添加新的表单总结前言 Pandas 是一种基于 NumPy 的开源数据分析工具,用于处理和分析大量数据。Pandas 模块提供了一组高效的工具,可以轻松地读取、处理和…...

js常见的9种报错记录一下
js常见报错语法错误(SyntaxError)类型错误(TypeError)引用错误(ReferenceError)范围错误(RangeError)运行时错误(RuntimeError)网络错误(NetworkError)内部错误(InternalError)URI错误(URIError)eval错误&a…...
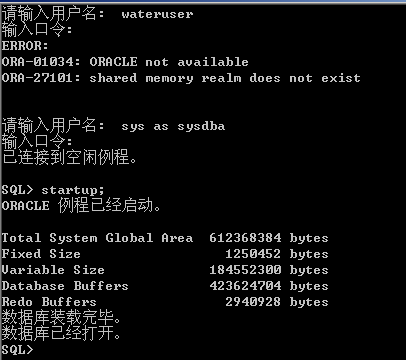
ORACLE not available报错处理办法
用sqlplus的时候 连接用户总是出现ORACLE not available 解决办法: 第一步: 请输入用户名: sys as sysdba 输入口令: 已连接到空闲例程。 第二步: 先连接到管理员用户下将用例开启 SQL> startup; ORACLE 例程已经启动。 然后就会出现一下 Total S…...

【Pandas】Python中None、null和NaN
经常混淆。 空值一般表示数据未知、不适用或将在以后添加数据。缺失值指数据集中某个或某些属性的值是不完整的。 一般空值使用None表示,缺失值使用NaN表示。 注意: python中没有null,但是有和其意义相近的None。 目录 1、None 2. NaN …...

线性表的学习
线性表定义 n个类型相同数据元素的有限序列,记作:a0,a1,a2,a3,...ai-1,ai,ai1...an-1(这里的0,1,2,3,i-1,i,i1,n-1都是元素的序号) 特点 除第一个元素无直接前驱。最后一个元素无直接后续&am…...
51单片机学习笔记_13 ADC
ADC 使得调节开发板上的电位器时,数码管上能够显示 AD 模块 采集电位器的电压值且随之变化。 开发板上有三个应用:光敏电阻,热敏电阻,电位器。 一般 AD 转换有多个输入,提高使用效率。 ADC 通过地址锁存与译码判断采…...

类和对象的基本认识之内部类
什么是内部类?当一个事物的内部,还有一个部分需要一个完整的结构进行描述,而这个内部的完整的结构又只为外部事物提供服 务,那么这个内部的完整结构最好使用内部类。在 Java 中,可以将一个类定义在另一个类或者一个方法…...
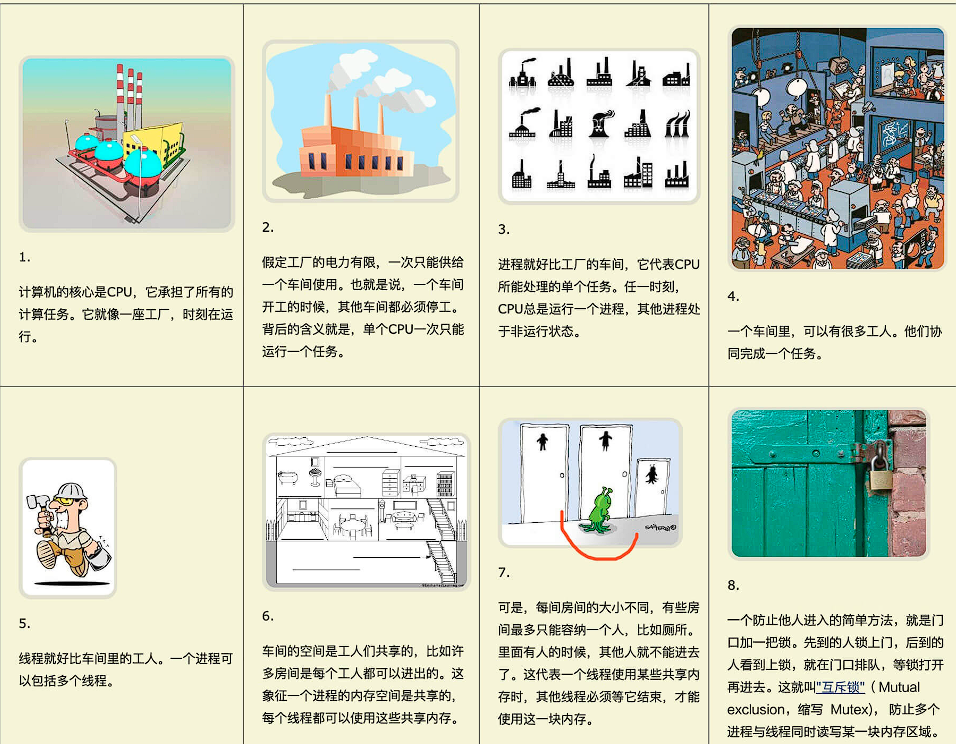
【操作系统】进程和线程是什么之间是如何通信的
文章目录1、进程1.1、什么是进程1.2、进程的状态1.3、进程的控制结构1.4、进程的控制1.5、进程的上下文切换1.6、进程上下文切换场景1.7、进程间通信2、线程2.1、什么是线程2.2、线程的上下文切换2.3、线程间通信3、线程与进程的联系1、进程 1.1、什么是进程 进程(process) 是…...

setup、ref、reactive、computed
setup 理解:Vue3.0 中一个新的配置项,值为一个函数 setup 是所有 Composition API(组合API)“表演的舞台” 组件中所用到的数据、方法等,均要配置在 setup 中 setup 函数的两种返回值: 若返回一个对象…...

【Gem5】有关gem5模拟器的资料导航
网上有关gem5模拟器的资料、博客良莠不齐,这里记录一些总结的很好的博客与自己的学习探索。 一、gem5模拟器使用入门 官方的教程: learning_gem5:包括gem5简介、修改扩展gem5的示例、Ruby相关的缓存一致性等。gem5 Documentation࿱…...
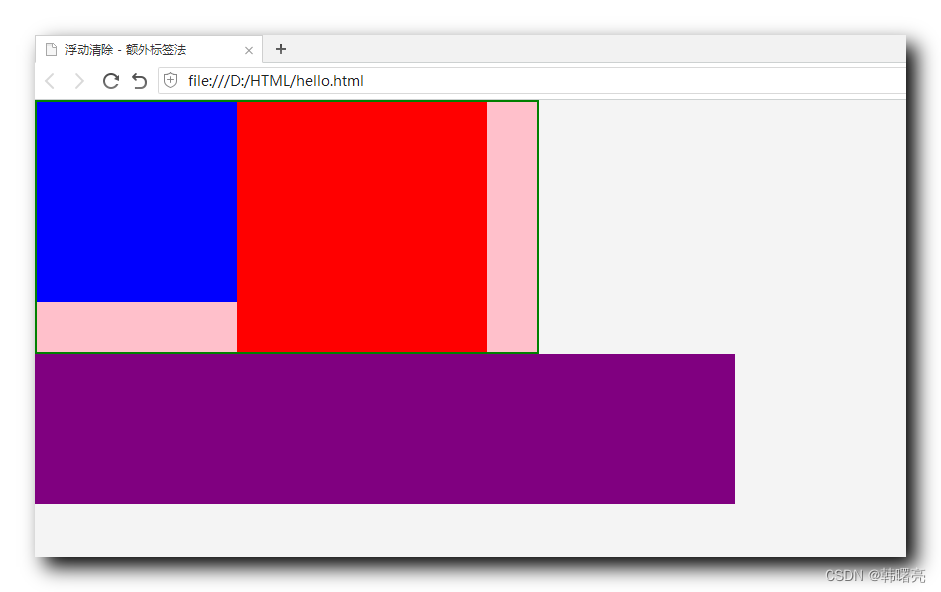
【CSS】清除浮动 ① ( 清除浮动简介 | 清除浮动语法 | 清除浮动 - 额外标签法 )
文章目录一、清除浮动简介二、清除浮动语法三、清除浮动 - 额外标签法1、额外标签法 - 语法说明2、问题代码示例3、额外标签法代码示例一、清除浮动简介 在开发页面时 , 遇到下面的情况 , 父容器 没有设置 内容高度 样式 , 容器中的 子元素 设置了 浮动样式 , 脱离了标准流 , …...

Shell test 命令
文章目录Shell test 命令数值测试字符串测试文件测试Shell test 命令 Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。 数值测试 参数说明-eq等于则为真-ne不等于则为真-gt大于则为真-ge大于等于则为真-lt小于则为真-le…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...