mongoDB学习笔记
1.大数据定义:
数据量级大 byte kb MB GB TB PB ...
数据种类多 数据维度 例如:人物画像
数据处理速度快
数据有价值
问题:①.存储 ? ②.数据分析? ③.高并发?
大数据应用领域: 电商(推荐) 广告栏位,交通,医疗
维度优化:
①X轴 服务水平拓展
②Y轴 业务垂直拆分 SOA
③Z轴 对使用群体分区(地域性)(多游戏)
==============================================
NoSQL :not noly sql 为什么?
RDBMS:比较擅长 关系、事务 (约束) 快速 写 不擅长
基于磁盘存储 速度慢 高效 读写
大都数 数据库 都是 单点存储 不支持 水平拓展
NoSQL:
1.schemaless 弱化表结构 没有表结构
2.in-memory 基于内存--redis
3.支持Cluster 集群 副本集合 分片
4.弱化事务 mongoDB不支持事务
5.支持脚本 mongodb javascript脚本 redisCluster ruby脚本
总结:NoSQL作为 RMDBS 补充 相辅相成。
==============================================
【MongoDB】:
1.NoSQL数据库 不支持 事务
2.MongoDB 单条记录 不得超过16M
3.没有表结构 基于 BSON/json 存储
t_user (RDBMS) 缺点 : 磁盘利用率低 IO利用率低
id name sex info ....
1 张三 null 逗你玩 记录(null值占用空间)
2 李四 null null
3 王五 false null
4 赵六 null null
t_user[] (MongoDB)集合 没有表结构
[
{id:1,name:"张三",info:"逗你玩"},
{id:2,name:"李四"},
{id:3,name:"王五",sex:false},
{id:4,name:"赵六"},
{id:5,name:"win7",hobbies:["看电视","打游戏"]},
{id:6,name:"win8",hobbies:"敲代码"]}
]
MongoDB安装:
1.将mongodb解压到/usr
2.创建dbpath
mkdir -p /root/data/db
3.在mongodb文件下启动mongodb
./bin/mongod --port 27017 --dbpath /root/data/db/ --journal
4.新建窗口在mongodb文件下连接mongoDB
./bin/mongo --port 27017 --host 192.168.100.128
数据操作
>show databases/dbs
>use 数据库名 切换数据库
>db 查看
>db.dropDatabase() 删除数据库
更多请查看 db.help();
表:
创建:db.createCollection("表名");
查看:show tables/collections
...
任务:
1.权威指南 2,3,4,5,6 章节
2.了解mongo-java-driver javaAPI 不讲解
----------------------------------------------------------------------------------------------------------------------------
复习:
MongoDB的常见操作
1.创建表/collection
(1).方式 :db.createCollection("collectionName");
(2).隐式: db.'collectionName'.insert(document);
2.查看表: show collections/tables;
3.删除表:db.'collectionName'.drop();
添加:
db.user.insert/save(json);
注意:如果数据表collection不存在就会创建。
id name sex birth ...
1 zs null
2 ww 男 1990-01-01
删除:
db.users.remove({})
根据条件进行删除的命令是:db.user.remove({age:31});
更新:
①:MongoDB中没有更新,事实上是先删除在添加
var jeo=db.user.findOne({});
delete jeo.age;
db.user.update(查询,更新的文档);
②修改器 $set ,$inc ,$unset
db.users.update(query,{$set:{sex:true}}, { "upsert" : true, "multi" : true });
//将name键删除
db.users.update(query,{$unset:{name:true}}, { "upsert" : true, "multi" : true });
附加说明:
upsert:表示按照查询条件修改数据,如果没有匹配 执行 插入操作
multi:表示 如果按照条件查询,查到多条记录后是否执行批量修改
db.t_user.update({name:"win7"},{$inc:{age:1}},{ "upsert" : true, "multi" : true });
数组的修改:
db.t_user.update({ name: "win7" },{$set: {address:[]}},false,true);
db.t_user.update({ name: "win7" },{$push: {address:"北京"}},false,true);
一次更新多个数据
db.t_user.update({ name: "win7" },{$push: {address:{$each:["北京","上海"]}}},false,true);
避免重复插入
db.user.update({ name: "zs" },{$addToSet: {address:{"$each":["北京","深圳","上地"]}}},false,true);
删除指定元素 pop/pull
db.user.update({ name: "zs" },{$pop: {address:1}},false,true); //1表示弹出第一个元素 -1 表示弹出最后一个元素
db.user.update({ name: "zs" },{$pull: {address:"北京"}},false,true);//删除指定元素
查询:
1.查询一条
document <—— db.user.findOne(查询条件);
2.查询多条
DBCursor <—— db.user.find();
db.user.find({});
3.条件查询
(1)等值 ==
db.user.find({name:"张三"});
db.user.find({name:{$eq:"张三"}});
(2)且 AND
db.user.find({name:"张三",age:18});
(3)或 $or/$nor
db.user.find({ "$or" : [{ "name" : "张三" }, { "age" : 20 }] });
db.user.find({ "$nor" : [{ "name" : "zhangsan" }, { "age" : 20 }] });
(4) 不等值 > < <= >= != ! $gt $lt $lte $gte $ne $not
①db.user.find({ "age" : { "$gt" : 15, "$lt" : 30 } })
②db.user.find({ "name" : { "$ne" : "zhangsan" } })
(5) $in/$nin
db.user.find({ "id" : { "$in" : [1, 2, 3] } });
(6) 数组查询
大小查询 $size
db.t_fruit.find({ "fruit" : { "$size" : 3 } });
下标查询
db.fruit.find({ "fruit.1" : "apple"});
判断元素是否包含
db.fruit.find({ "fruit" :{"$all":["apple","banana"]}});
(7) $exists 判断是否有key 1/true表示存在 0/false 表示 不存在
db.user.find({"sex":{ "$exists" : 0 }});
(8) 投影查询 0/false表示显示 1/true 表示不显示
db.t_user.find({},{"name":true});
(9) 查询总记录数
db.t_user.count()
db.fruit.find({}).count(); 返回符合query查询结果
db.fruit.find({}).size(); 返回实际的document个数
(10) 数据分页 skip limit
db.fruit.find({ }).skip(1).limit(50); //查询从第一条开始 查询50条记录
(11) 排序
db.fruit.find({ }).sort({id:1});根据ID升序排列 1表示升序 -1 降序
(12 )正则搜索
db.t_user.find({name:{$regex:"^张三$"}})
(13)where 查询
db.user.find({ "$where" : "function aa(){
\r\n print(this.name);
\r\n if(this.name==\"张三\"){
\r\n return true;\r\n
}
\r\n return false;
\r\n}"
})
db.t_user.find({name:{$eq:"张三"},$where:"(this.id<4)?false:true"})
======================================================
索引:
db.users.ensureIndex({name:1},[options]) _id这个key mongo自动加入索引
索引创建:db.users.ensureIndex({name:1})
db.t_user.ensureIndex({ "name" : 1 },{ "name" : "name_index" });
查看索引:db.t_user.getIndexes();
删除索引:db.t_user.dropIndex("name_index");
索引重建:db.users.reIndex()
唯一索引:db.users.ensureIndex({"username" : 1}, {"unique" : true})//此时不可以为该域添加重复的值
稀疏索引:db.users.ensureIndex({"name" : 1}, {"unique" : true, "sparse" : true})//主要对null值处理,允许多个null值存在,不认为违反unique
TTL索引:db.users.ensureIndex({"last_modify" : 1}, {"expireAfterSecs" : 60})//定时清除过期数据 该索引必须建立在日期类型的field上
=====================================================
MapReduce数据统计 计算:
db.students.insert({classid:1, age:14, name:'张三'});
db.students.insert({classid:1, age:12, name:'李四'});
db.students.insert({classid:2, age:16, name:'王五'});
db.students.insert({classid:2, age:9, name:'赵六'});
db.students.insert({classid:2, age:19, name:'win7'});
var map=function() {
emit(this.classid,{age:this.age,classid:this.classid,name:this.name})
}
var reduce=function (key,values) {
var x ={classid:-1,username:[],total:0};
var total=0;
values.forEach(function (v) {
x.classid = v.classid;
total++;
x.username.push(v.name);
});
x .total=total;
return x;
}
db.students.mapReduce( map, reduce,{out:"students_res"})
或者
var res = db.runCommand({
mapreduce:"students",
map:map,
reduce:reduce,
out:"students_res"
});
===========================================
*辅线 Mongo集群管理
主从:
Master/slave options (old; use replica sets instead):
--master master mode
--slave slave mode
--source arg when slave: specify master as <server:port>
--only arg when slave: specify a single database to replicate
--slavedelay arg specify delay (in seconds) to be used when applying master ops to slave
--autoresync automatically resync if slave data is stale
查看主从状况:
: rs.help();查看集群状态
主机:./bin/mongod --port 27017 --dbpath /root/master --journal --master
从机:./bin/mongod --port 27018 --dbpath /root/slave --journal --slave --source 192.168.100.128:27017 [--only zpark --autoresync]
查看 slave 必须执行 rs.slaveOk() 允许在secondary节点上执行查询
可以执行db.isMaster();查看当前服务状态。
【缺点】:
1.无法实现 自动的 故障转移 auto_faliover,如果主机宕机,需要关闭slave并且按照master模式启动
2.无法解决海量数据存储
-----------------------------------------------------------------------------------------------------------
副本集:(主从 升级版 仅仅解决的是第一问题 )
1.在root文件夹创建repl1/repl2/repl3
2.在mongodb文件下执行启动
./bin/mongod --port 27017 --dbpath /root/repl1 --replSet r1
./bin/mongod --port 27018 --dbpath /root/repl2 --replSet r1
./bin/mongod --port 27019 --dbpath /root/repl3 --replSet r1
3.链接任意一台mongo
var config = {
_id:"r1",
members:[
{_id:0,host:"192.168.17.130:27017"},
{_id:1,host:"192.168.17.130:27018"},
{_id:2,host:"192.168.17.130:27019"}]
}
//初始化配置文件
rs.initiate(config);
rs.isMaster() / rs.status();
①.添加一个副本集
./bin/mongod --port 27010 --dbpath /root/repl4 --replSet r1
rs.add("192.168.100.128:27010");//添加一个节点
②.删除一个副本集:
rs.remove("192.168.100.128:27010");
③.添加仲裁arbiter节点: 该节点只负责选举主节点不负责做数据的存储
rs.add({_id:3,host:"192.168.17.130:27020",arbiterOnly:true});
==》等价rs.addArb("192.168.100.128:27010");
阻止Secondary节点成为Primary 设置该节点的priority=0
cfg=rs.config();
cfg.members[1].priority=0
rs.reconfig(cfg);
④.添加一个hidden节点 该节点不会成为primary以及被客户端引用
cfg=rs.config();
cfg.members[1].priority=0
cfg.members[1].hidden=true
rs.reconfig(cfg);
⑤.延迟复制节点(延迟节点的优先级必须为0和hidden节点是一样的) 一般都会设置hidden
cfg=rs.config();
cfg.members[1].priority=0
cfg.members[1].slaveDelay=3600//单位是秒
rs.reconfig(cfg);
⑥.SecondaryOnly节点
Priority为0的节点永远不能成为主节点,所以设置Secondaryonly节点只需要将其priority设置为0.
⑦.设置Non-Voting节点:
cfg=rs.conf();
cfg.members[0].votes=0;
rs.reconfig(cfg);
注意:MongoDB的副本级别最大上限是17个,但最多只能有7个节点具有投票权。所以如果超过7个以后的节点,一般分配为Non-Voting
副本集状态
STARTUP:刚加入到复制集中,配置还未加载
STARTUP2:配置已加载完,初始化状态
RECOVERING:正在恢复,不适用读
ARBITER: 仲裁者
DOWN:节点不可到达
UNKNOWN:未获取其他节点状态而不知是什么状态,一般发生在只有两个成员的架构,脑裂
REMOVED:移除复制集
ROLLBACK:数据回滚,在回滚结束时,转移到RECOVERING或SECONDARY状态
FATAL:出错。
PRIMARY:主节点
SECONDARY:备份节点
【缺点】:海量数据存储
====================================================
分片:配置服务器 路由服务器 shard服务器
./bin/mongod --port 27017 --dbpath /root/shard1 --journal --shardsvr
./bin/mongod --port 27018 --dbpath /root/shard2 --journal --shardsvr
./bin/mongod --port 27019 --dbpath /root/config --journal --configsvr
./bin/mongos --port 27020 --configdb 192.168.17.129:27019
--连接路由服务器
mongo --port 27020
use admin
sh.addShard("192.168.100.128:27017");
sh.addShard("192.168.100.128:27018");
sh.enableSharding("zpark");//对zpark数据库分片
//表示对_id 做分片处理(2选1)
sh.shardCollection("zpark.t_user1", {"_id" : 1});
sh.shardCollection("zpark.t_user2", {"_id": "hashed" })
use zpark;
插入测试数据
for(var i=0; i<10000; i++){
db.t_user1.insert({name:"user"+i, age:i, email:"zpark@163.com" })
}
for(var i=0; i<10000; i++){
db.t_user2.insert({name:"user"+i, age:i, email:"zpark@163.com" })
}
查看状态:db.'collectionName'.stats()
==========================================================================
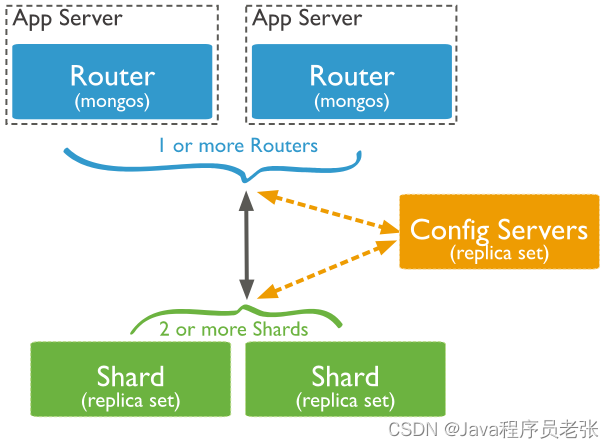
解释:
shard服务器个数决定数据库存储能力(副本集)--至少需要两个shard服务器 即生产环境下至少需要机器(2*3)台
config servers存储shard位置信息(3台)
路由服务器(1台) 伪装成一个MongoDB实例 接收用户发送过来的请求
最终版:副本集+分片 搭建mongo的集群
shard1
./bin/mongod --port 27017 --dbpath /root/data/shard11 --journal --replSet r1 --shardsvr
./bin/mongod --port 27018 --dbpath /root/data/shard12 --journal --replSet r1 --shardsvr
./bin/mongod --port 27019 --dbpath /root/data/shard13 --journal --replSet r1 --shardsvr
副本集跑起来
连接任意一台mongo
./bin/mongo --port 27019 --host 192.168.17.130
var config = {
_id:"r1",
members:[
{_id:0,host:"192.168.17.130:27017"},
{_id:1,host:"192.168.17.130:27018"},
{_id:2,host:"192.168.17.130:27019"}]
}
rs.initiate(config);
shard2
./bin/mongod --port 27020 --dbpath /root/data/shard21 --journal --replSet r2 --shardsvr
./bin/mongod --port 27021 --dbpath /root/data/shard22 --journal --replSet r2 --shardsvr
./bin/mongod --port 27022 --dbpath /root/data/shard23 --journal --replSet r2 --shardsvr
副本集跑起来
连接任意一台mongo
./bin/mongo --port 27022 --host 192.168.17.130
var config = {
_id:"r2",
members:[
{_id:0,host:"192.168.17.130:27020"},
{_id:1,host:"192.168.17.130:27021"},
{_id:2,host:"192.168.17.130:27022"}]
}
rs.initiate(config);
启动配置服务器:(目前版本3.0.6不支持将配置服务器搭建为副本集,最新版可以)
./bin/mongod --port 27023 --dbpath /root/data/config1 --journal --configsvr
./bin/mongod --port 27024 --dbpath /root/data/config2 --journal --configsvr
./bin/mongod --port 27025 --dbpath /root/data/config3 --journal --configsvr
启动路由:
//把三台配置服务器添加进路由服务器
./bin/mongos --port 27026 --configdb 192.168.17.130:27023,192.168.17.130:27024,192.168.17.130:27025
连接路由服务器
./bin/mongo --port 27026
use admin
sh.addShard("r1/192.168.17.130:27017,192.168.17.130:27018,192.168.17.130:27019");
sh.addShard("r2/192.168.17.130:27020,192.168.17.130:27021,192.168.17.130:27022");
sh.enableSharding("baizhi");//对baizhi数据库分片
//表示对_id 做分片处理(方式2选1)
sh.shardCollection("baizhi.t_user", {"_id" : 1});//先由一个副本集存放数据,快满时启用下个副本集
sh.shardCollection("baizhi.t_address", {"_id": "hashed" });//副本集平均分布
插入测试数据
for(var i=0; i<10000; i++){
db.t_user .insert({name:"user"+i, age:i, email:"zpark@163.com" })
}
for(var i=0; i<10000; i++){
db.t_address .insert({name:"user"+i, age:i, email:"zpark@163.com" })
}
查看状态:db.user.stats()
【注意】:集群搭建后,数据库建立索引需通过数据库,不能在代码中建立索引
=========================================================================
SpringData-MongoDB
①.导jar包
Spring-jar、
mongo-java-driver-2.14.3.jar
spring-data-commons-1.12.5.RELEASE.jar
spring-data-mongodb-1.9.5.RELEASE.jar
②. applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>< beans xmlns ="http://www.springframework.org/schema/beans"xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance"xmlns:context ="http://www.springframework.org/schema/context"xmlns:aop ="http://www.springframework.org/schema/aop"xmlns:mvc ="http://www.springframework.org/schema/mvc"xmlns:tx= "http://www.springframework.org/schema/tx"xmlns:mongo ="http://www.springframework.org/schema/data/mongo"xsi:schemaLocation ="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans-4.2.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context-4.2.xsdhttp://www.springframework.org/schema/aophttp://www.springframework.org/schema/aop/spring-aop-4.2.xsdhttp://www.springframework.org/schema/txhttp://www.springframework.org/schema/tx/spring-tx-3.2.xsdhttp://www.springframework.org/schema/mvchttp://www.springframework.org/schema/mvc/spring-mvc-4.2.xsdhttp://www.springframework.org/schema/data/mongohttp://www.springframework.org/schema/data/mongo/spring-mongo-1.0.xsd" ><mongo:mongo host= "192.168.17.130" port= "27026" id ="mongo" /><bean id= "mongoTemplate" class ="org.springframework.data.mongodb.core.MongoTemplate" ><constructor-arg index= "0" ref = "mongo"/><constructor-arg index= "1" value = "baizhi"/></bean ></beans >③.实体类
package com.baizhi.entity;import java.io.Serializable;import java.util.List;import org.springframework.data.annotation.Id;import org.springframework.data.annotation.PersistenceConstructor;import org.springframework.data.mongodb.core.index.Indexed;import org.springframework.data.mongodb.core.mapping.DBRef;import org.springframework.data.mongodb.core.mapping.Document;import org.springframework.data.mongodb.core.mapping.Field;@Document(collection="t_user") //指明存入数据库后对应的文档public class User implements Serializable {@Id//默认情况下,mongo的主键只能是String、BigInteger、ObjectIdprivate String id;//给name字段设置索引,唯一、稀疏索引(针对null)@Indexed(name="name_index",unique=true,sparse=true) //搭建集群后不能在此处设置索引private String name;private int age;@Field(value="u_sex")//给数据库字段起别名private boolean sex;@DBRef(lazy=true)private City address;//使用到的时候,才会给该属性赋值@DBRef(lazy=true) private List<OrderItem> orderItems;@PersistenceConstructor //数据库利用该构造方法将查询结果封装为对象 (要有set方法)public User(String name, int age, boolean sex) {super();this.name = name;this.age = age;this.sex = sex;}public User() {super();}public String getId() {return id;}public void setId(String id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public City getAddress() {return address;}public void setAddress(City address) {this.address = address;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public List<OrderItem> getOrderItems() {return orderItems;}public void setOrderItems(List<OrderItem> orderItems) {this.orderItems = orderItems;}public boolean isSex() {return sex;}public void setSex(boolean sex) {this.sex = sex;}@Overridepublic String toString() {return "User [id=" + id + ", name=" + name + ", address=" + address+ ", age=" + age + ", orderItems=" + orderItems + "]";}}package com.baizhi.entity;import java.io.Serializable;import org.springframework.data.annotation.Id;import org.springframework.data.annotation.PersistenceConstructor;import org.springframework.data.mongodb.core.mapping.Document;@Document(collection="t_orderitem")public class OrderItem implements Serializable {@Idprivate String id;private String name;private int count;@PersistenceConstructorpublic OrderItem(String name, int count) {super();this.name = name;this.count = count;}public String getId() {return id;}public void setId(String id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getCount() {return count;}public void setCount(int count) {this.count = count;}@Overridepublic String toString() {return "OrderItem [id=" + id + ", name=" + name + ", count=" + count+ "]";}}④测试代码
package com.baizhi.test;import java.util.Arrays;import java.util.List;import org.junit.Before;import org.junit.Test;import org.springframework.context.ApplicationContext;import org.springframework.context.support.ClassPathXmlApplicationContext;import org.springframework.data.domain.Sort;import org.springframework.data.domain.Sort.Direction;import org.springframework.data.mongodb.core.MongoTemplate;import org.springframework.data.mongodb.core.query.Criteria;import org.springframework.data.mongodb.core.query.Query;import org.springframework.data.mongodb.core.query.Update;import com.baizhi.entity.City;import com.baizhi.entity.OrderItem;import com.baizhi.entity.User;import com.mongodb.Mongo;public class Demo {private Mongo mongo;private MongoTemplate mongoTemplate;@Beforepublic void before(){ApplicationContext ac = new ClassPathXmlApplicationContext("classpath:applicationContext.xml");mongo = (Mongo) ac.getBean("mongo");mongoTemplate = (MongoTemplate) ac.getBean("mongoTemplate");}@Testpublic void test8(){for (int i = 0; i < 10000; i++) {User user = new User("a"+i,i,true);user.setAddress(null);user.setOrderItems(null);mongoTemplate.insert(user);}}@Testpublic void test(){User user = new User("张三",18,true);mongoTemplate.insert(user);System.out.println(user);}@Testpublic void test1(){User user = mongoTemplate.findById("58c8e2696f5799eb36d4e83e", User.class);System.out.println(user);}@Testpublic void testSave(){double[] a = new double[]{1.1,2.2};User user=new User("马腾",18,false);City city = new City("北京",a);user.setAddress(city);List<OrderItem> orderItems=Arrays.asList(new OrderItem("hadoop权威指南", 1),new OrderItem("MongoDB权威指南",1));user.setOrderItems(orderItems);//先保存地址、订单项 再保存用户mongoTemplate.save(city);for (OrderItem orderItem : orderItems) {mongoTemplate.save(orderItem);}mongoTemplate.save(user);}@Testpublic void testQueryUserById(){User user = mongoTemplate.findById("58c8e5376f57cac13e322036", User.class);//获取的是代理对象@DBRef(lazy=true)List<OrderItem> orderItems = user.getOrderItems();for (OrderItem orderItem : orderItems) {System.out.println(orderItem);}}@Testpublic void testQueryAll(){List<User> users = mongoTemplate.findAll(User.class);for (User user : users) {System.out.println(user);}}@Testpublic void testQuery(){Query query = new Query();Criteria criteria = new Criteria("name");criteria.is("刘备");query.addCriteria(criteria);List<User> find = mongoTemplate.find(query, User.class);System.out.println(find);}@Testpublic void testQueryByPage(){Query query = new Query();query.skip(5);query.limit(10);List<User> list = mongoTemplate.find(query, User.class);for (User user : list) {System.out.println(user);}}@Testpublic void testQueryByOrder(){Query query = new Query();Sort sort = new Sort(Direction.ASC,"age");query.with(sort);List<User> list = mongoTemplate.find(query, User.class);for (User user : list) {System.out.println(user);}}@Testpublic void testRemove(){Query query = new Query();Criteria criteria = new Criteria("name");criteria.is("张三");query.addCriteria(criteria);mongoTemplate.remove(query, User.class);}@Testpublic void testUpdateMulit(){Query query = new Query();Criteria criteria = new Criteria("sex");criteria.is(false).and("age").gte(25);/*Criteria criteria = new Criteria("name");criteria.is("赵六");*/query.addCriteria(criteria);Update update = new Update();update.set("age", 31);mongoTemplate.upsert(query, update, User.class);}} 相关文章:
mongoDB学习笔记
1.大数据定义: 数据量级大 byte kb MB GB TB PB ... 数据种类多 数据维度 例如:人物画像 数据处理速度快 数据有价值 问题:①.存储 ? ②.数据分析? ③.高并发? 大数据应用领域: 电商(推…...

快速融人,融资的共享模式,实体,线上皆可参考
有一种模式现在非常流行,它既能帮助商家快速收钱,又能帮助商家快速裂变更多客户,这个神奇的模式就是共享股东模式,现在很多老板都在用这个模式。 梦龙商业案例分析,带你了解商业背后的秘密 这个模式也适用于很多个行…...

纯干货版阿里巴巴国际站入门攻略
阿里巴巴国际站作为目前全球排名名列前茅的B2B电商平台,很多跨境电商卖家都很想入局。但是目前很多公司的国际站都没有专职运营的人员,只是靠外贸业务员操作,所以涉猎的都是比较浅的东西。今天龙哥就来讲讲如果想要深研这个平台的话ÿ…...

jQuery四、其他方法
零、文章目录 文章地址 个人博客-CSDN地址:https://blog.csdn.net/liyou123456789个人博客-GiteePages:https://bluecusliyou.gitee.io/techlearn 代码仓库地址 Gitee:https://gitee.com/bluecusliyou/TechLearnGithub:https:…...

2023年先进无人飞行系统国际会议(ICAUAS 2023) | IOP JPCS独立出版
会议简介 Brief Introduction 2023年先进无人飞行系统国际会议(ICAUAS 2023) 会议时间:2023年7月13日-16日 召开地点:中国哈尔滨&加拿大多伦多双会场 大会官网: ICAUAS 2023-2023 International Conference on Advanced Unmanned Aerial …...
2022蓝桥杯省赛——修剪灌木
问题描述 爱丽丝要完成一项修剪灌木的工作。 有 N 棵灌木整齐的从左到右排成一排。爱丽丝在每天傍晩会修剪一棵灌木, 让灌木的高度变为 0 厘米。爱丽丝修剪灌木的顺序是从最左侧的灌木开始, 每天向右修剪一棵灌木。当修剪了最右侧的灌木后, 她会调转方向, 下一天开始向左修剪…...
Spring Boot Aop初接触
AOP(面向切面编程),或多或少都听过一点。名字比较怪,切面,不容易理解,但其中真正含义,无非就是旁路控制,非侵入式编码之类。比如我想加个操作日志功能,利用AOP࿰…...

【创作赢红包】LeetCode:232. 用栈实现队列
🍎道阻且长,行则将至。🍓 🌻算法,不如说它是一种思考方式🍀算法专栏: 👉🏻123 一、🌱232. 用栈实现队列 题目描述:请你仅使用两个栈实现先入先出队…...

Mybatis+Mysql 实现向下递归查询
介绍 说到递归查询,大家可以想到的技术实现方式主要如下几种: 1、各种主流应用开发语言本身通过算法实现 2、各种数据库引擎自身提供的算法实现 本文提到主要是针对第二种和第一种的结合 主要技术栈 1、ORM:Mybatis 2、DB:MyS…...

python@调用系统命令行@os.system@subprocess@标准输入输出@sys.stdin@sys.stdout@input@print
文章目录python调用系统命令行os.system标准输入输出sys.stdinsys.stdoutinputprint概要os.systemdemoswindows命令解释器ComSpecsubprocessrecommended🎈基本用法demos标准输入输出sys.stdininput()sys.stdin.inputinput()交互模式小结sys.stdoutsys.stdout.wirte(…...

手握数据智能密钥,诸葛智能打开数字化经营“三重门”
科技云报道原创。 如果说上世纪传统麦迪逊大街上的“广告狂人”吸金立足之本,还主要是基于“Big Idea”的话,那么在当下,数据正在成为企业营销和运营的金矿。 这是一个“人与机器共同进化”的时代,技术作为延伸人类感觉的媒介之…...

C语言可以实现各种滤波算法
C语言可以实现各种滤波算法,以下是一些常见的滤波算法: 均值滤波(Mean Filter):将图像中每一个像素周围一定区域内的灰度值取平均值作为该像素的新灰度值,用于去除高斯噪声等随机噪声。 下面是一个简单的 C…...

使用Netty,当然也要了解它的连接闲置处理
连接闲置网络连接的闲置指的是当前网络连接处于空闲状态,即没有正在进行的数据传输或通信活动。当我们的某个连接不再发送请求或者接收响应的时候,这个连接就开始处于闲置状态。网络连接的闲置时间越长,说明该连接越不活跃。此时,…...
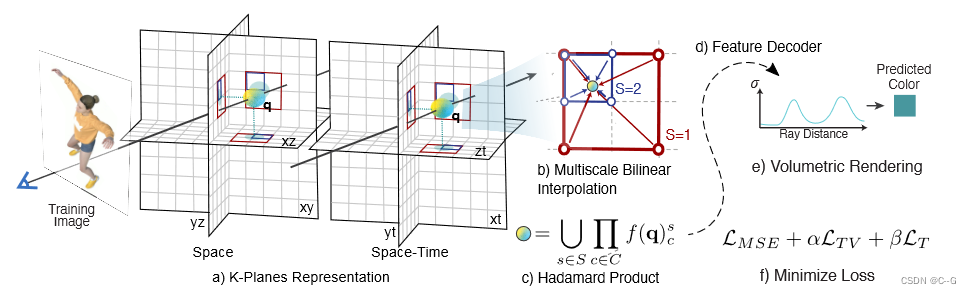
2、K-Planes
运行配置 主页:https://sarafridov.github.io/K-Planes/ 代码:https://github.com/sarafridov/K-Planes 预训练权重:https://drive.google.com/drive/folders/1zs_folzaCdv88y065wc6365uSRfsqITH Neural_3D_Video_Dataset:htt…...
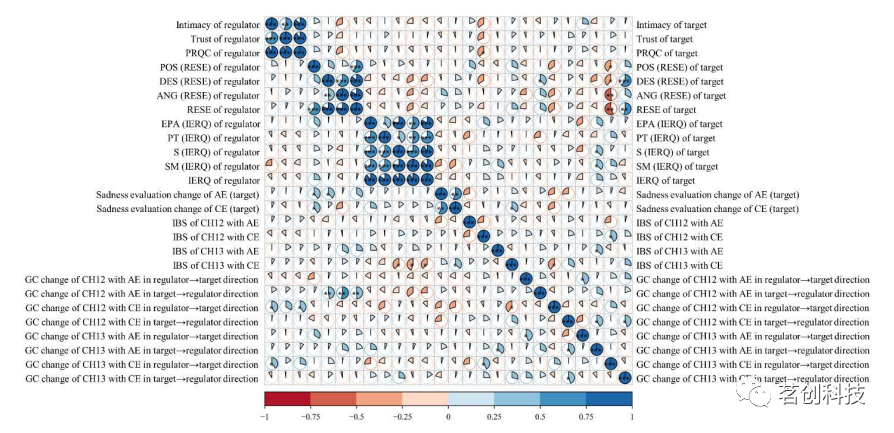
张文海教授课题组在国际高水平期刊《Cerebral Cortex》发表研究成果
调节悲伤情绪对于维持伴侣间的浪漫关系至关重要。人际情绪调节策略包括情感参与(AE)和认知参与(CE),这两种策略在浪漫关系中效用如何?它们是如何通过情感纽带调节伴侣情绪的?其背后的脑际神经互…...

ffmpeg4.1 源码学习之-转封装
前言 ffmpeg 的源码量非常的多,而且非常繁杂,非常多的函数,如果一个函数一个函数看的话要花费比较多的时间。所以本文通过跟踪ffmpeg转封装的过程来学习ffmpeg的源码具体转封装的命令:ffmpeg -i 1_cut.flv -c copy -f mp4 1.mp4在…...

ChatGPT写作文章-快速使用ChatGPT不用注册方式
如何更好地使用ChatGPT批量生成文章:详细教程 作为一款强大的文本生成器,ChatGPT可以帮助您快速、高效地批量生成文章。但如果您还不知道如何更好地使用ChatGPT,那么这篇详细的列表教程将会指导您如何使用它来生成高质量的文章,提…...
)
Nginx配置ip白名单(服务权限控制)
Nginx服务器权限控制:Nginx 是一款高性能的 HTTP 和反向代理服务器。它可以通过配置文件实现权限控制,从而限制或允许特定的 IP 地址、网络或用户访问指定的资源。这里是一些基本的 Nginx 权限控制方法: 1. 基于 IP 地址的访问控制 在 Ngin…...
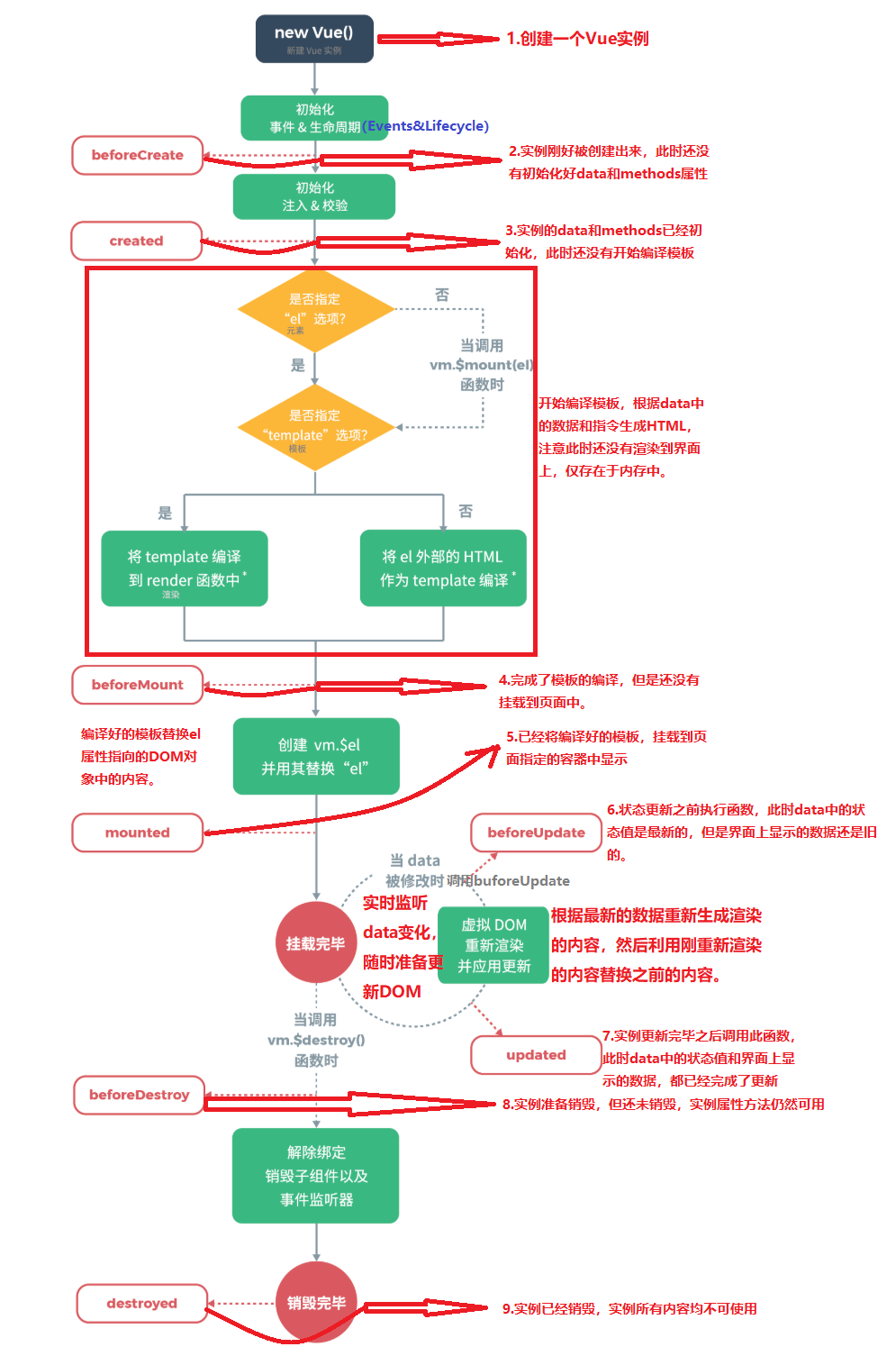
Vue 核心(二)
文章目录Vue 核心(二)八、 绑定样式1、 class2、 style九、 条件渲染1、 渲染指令2、 使用示例十、 列表渲染1、 基本语法2、 key原理3、 列表过滤4、 列表排序5、 数组更新检测6、 大总结十一、 收集表单数据十二、 内置指令1、 v-text2、 v-html3、 v-…...

犯罪现场还原虚拟vr训练平台突破各种教学限制
在当今社会矛盾日益凸显、各式犯罪层出不穷的背景下,创新改革公安院校实战化教学方式,强化对基层公安队伍实战化应用型人才的供给能力具有重要性、紧迫性。 案件现场勘查是门技术活,如何让民警快速有效提升技能、服务实战? 常规刑侦专业现场…...

三行六列16车位立体车库mcgs6.2仿真程序
三行六列16车位立体车库mcgs6.2仿真程序立体车库仿真程序最让人上头的就是运动逻辑设计。今天拆解一个三行六列布局的MCGS6.2项目,看看如何用脚本驱动16个车位的升降动画。注意这里的车位排布有点特殊——虽然看起来是3*6的矩阵,但实际有两处隐藏车位被改…...
)
别再只用M法了!手把手教你用Arduino和旋转编码器实现M/T法测速(附代码)
别再只用M法了!手把手教你用Arduino和旋转编码器实现M/T法测速(附代码) 在电机控制项目中,精确的速度测量往往是实现闭环控制的第一步。许多初学者会直接采用简单的M法(频率测量法),但在实际测试…...

3分钟告别机械键盘连击:精准修复打字困扰的Windows神器
3分钟告别机械键盘连击:精准修复打字困扰的Windows神器 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 机械键盘连击问题让无…...

单轴晶体中的偏振转换
摘要 当线偏振光聚焦并通过单轴晶体传播时,即使沿着光轴方向,不同的偏振分量之间也可能会发生复杂的转换。这种现象可以应用于例如产生涡旋光。以方解石晶体为例,这个用例在VirtualLab Fusion中证明了单轴晶体中的偏振转换。并且可以观察到…...

技术方案:SENAITE LIMS实验室信息管理系统完整实施指南
技术方案:SENAITE LIMS实验室信息管理系统完整实施指南 【免费下载链接】senaite.lims SENAITE Meta Package 项目地址: https://gitcode.com/gh_mirrors/se/senaite.lims SENAITE LIMS是一款基于Plone和Python技术栈构建的开源实验室信息管理系统࿰…...

ChatTTS实战:从WAV到PT的高效转换技术解析
在语音合成和语音处理的工作流中,数据预处理是至关重要的一环。我们常常从麦克风、录音设备或公开数据集中获得最原始的WAV格式音频,但深度学习模型,尤其是基于PyTorch的模型,其“母语”是张量(Tensor)。因…...

告别格式地狱:Paperxie 如何用智能排版让本科毕业论文一键通关
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AIPPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 当毕业论文写到最后,你是否也陷入过这样的困境:明明内容已经打磨完成,却…...

Cosmos-Reason1-7B保姆级教程:从NVIDIA模型下载到浏览器界面可用全流程
Cosmos-Reason1-7B保姆级教程:从NVIDIA模型下载到浏览器界面可用全流程 本文面向想要快速上手Cosmos-Reason1-7B推理工具的初学者,无需深厚技术背景,跟着步骤操作即可完成本地部署和使用。 1. 工具简介:你的本地推理助手 Cosmos-…...
地面模拟训练系统)
飞行错觉(空间定向障碍)地面模拟训练系统
飞行错觉地面模拟训练系统是一种专为飞行员设计的高科技训练装备,旨在通过在地面复现飞行中可能出现的空间定向障碍(即飞行错觉),帮助飞行员识别、适应并正确应对这些错觉,从而提升飞行安全。这类系统结合了多模态感知…...

3步掌握DoL-Lyra整合包:从零到精通的完整指南
3步掌握DoL-Lyra整合包:从零到精通的完整指南 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS Degrees of Lewdity中文整合包DoL-Lyra为您提供了一站式的游戏体验解决方案。这个自动化构建…...