【AI基础】pytorch lightning 基础学习
传统pytorch工作流是首先定义模型框架,然后写训练和验证,测试循环代码。训练,验证,测试代码写起来比较繁琐。这里介绍使用pytorch lightning 部署模型,加速模型训练和验证,记录。
准备工作
1 安装pytorch lightning 检查版本
$ conda create -n lightning python=3.9 -y
$ conda activate lightningimport lightning as L
import torchprint("Lightning version:", L.__version__)
print("Torch version:", torch.__version__)
print("CUDA is available:", torch.cuda.is_available())2 加载基本库函数
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import lightning as L
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from lightning.pytorch.callbacks import ModelCheckpoint
from lightning.pytorch.loggers.tensorboard import TensorBoardLogger
from lightning.pytorch.callbacks.early_stopping import EarlyStopping3 设置随机种子(可复现性)
L.seed_everything(1121218)4 数据集下载和增强变换
这里以CIFAR10数据集为例子,该数据集包含 10 个类的 6 万张 32x32 彩色图像,每个类 6000 张图像。

from torchvision import datasets, transforms# Load CIFAR-10 dataset
train_dataset = datasets.CIFAR10(root="./data", train=True, download=True, transform=transform_train
)
val_dataset = datasets.CIFAR10(root="./data", train=False, download=True, transform=transform_test
)# Data augmentation and normalization for training
transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),],
)
transform_test = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)上面的增强变换包括以下四种基本变换:
- 裁剪(需要指定图像大小,在本例中为 32x32)。
- 水平翻转。
- 转换为张量数据类型,这是 PyTorch 所必需的。
- 对图像的每个颜色通道进行归一化处理。
传统pytorch模型训练流
定义一个CNN模型
class CIFAR10CNN(nn.Module):def __init__(self):super(CIFAR10CNN, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.conv3 = nn.Conv2d(64, 64, 3, padding=1)self.pool = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(64 * 4 * 4, 512)self.fc2 = nn.Linear(512, 10)def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = self.pool(torch.relu(self.conv2(x)))x = self.pool(torch.relu(self.conv3(x)))x = x.view(-1, 64 * 4 * 4)x = torch.relu(self.fc1(x))x = self.fc2(x)return x编写训练、验证循环代码
- 需要初始化模型,损失函数和优化器
- 管理模型和数据在机器上的运行(CPU 与 GPU)
- 训练步骤:前向传播、损失计算、反向传播和优化
- 验证步骤:计算准确性和损失
- tensorboard日志记录,训练损失,准确率,其他相关指标记录等
- 模型保存
-
# Initialize the model, loss function, and optimizer model = CIFAR10CNN().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=learning_rate) scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5)# TensorBoard setup writer = SummaryWriter('runs/cifar10_cnn_experiment')# Training loop total_step = len(train_loader) for epoch in range(num_epochs):model.train()train_loss = 0.0for i, (images, labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)# Forward passoutputs = model(images)loss = criterion(outputs, labels)# Backward and optimizeoptimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')# Calculate average training loss for the epochavg_train_loss = train_loss / len(train_loader)writer.add_scalar('training loss', avg_train_loss, epoch)# Validationmodel.eval()with torch.no_grad():correct = 0total = 0val_loss = 0.0for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / totalavg_val_loss = val_loss / len(test_loader)print(f'Validation Accuracy: {accuracy:.2f}%')writer.add_scalar('validation loss', avg_val_loss, epoch)writer.add_scalar('validation accuracy', accuracy, epoch)# Learning rate schedulingscheduler.step(avg_val_loss)# Final test model.eval() with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Test Accuracy: {100 * correct / total:.2f}%')writer.close()# Save the model torch.save(model.state_dict(), 'cifar10_cnn.pth')在上面的代码示例,有一些需要特别注意繁琐的细节:
训练和验证模式之间可以手动切换。
有梯度计算的手动规范。
使用较差的 SummaryWriter 类进行日志记录。
有一个学习率调度程序。
Pytorch lightning 工作流
1 使用LightningModule 类定义模型结构
class CIFAR10CNN(L.LightningModule):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.conv3 = nn.Conv2d(64, 64, 3, padding=1)self.pool = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(64 * 4 * 4, 512)self.fc2 = nn.Linear(512, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = self.pool(F.relu(self.conv3(x)))x = x.view(-1, 64 * 4 * 4)x = F.relu(self.fc1(x))x = self.fc2(x)return x唯一的区别是,我们是从LightningModule类继承,而不是从继承nn.Module。是类LightningModule的扩展nn.Module。它将 PyTorch 工作流的训练、验证、测试、预测和优化步骤组合到一个没有循环的单一界面中。 当你开始使用时LightningModule,它被组织成六个部分:
- 初始化(__init__和setup()方法)
- 训练循环(training_step()方法)
- 验证循环(validation_step()方法)
- 测试循环(test_step()方法)
- 预测循环(prediction_step()方法)
- 优化器和 LR 调度程序(configure_optimizers())
我们已经看到了初始化部分。让我们继续进行训练步骤。
2 编写训练过程代码
在模型类中,复写training_step()方法
# Add the method inside the class
def training_step(self, batch, batch_idx):x, y = batchy_hat = self(x)loss = F.cross_entropy(y_hat, y)self.log('train_loss', loss)return loss此方法将整个训练循环压缩为几行代码。首先,从数据batch中读取模型输入和模型输出。然后,我们运行前向传递self(x)并计算损失。然后,我们只需使用内置的 Lightning 记录器函数记录训练损失即可self.log()。
还可以在此方法中记录其他指标,例如训练准确性:
def training_step(self, batch, batch_idx):x, y = batchy_hat = self(x)loss = F.cross_entropy(y_hat, y)acc = (y_hat.argmax(1) == y).float().mean()self.log("train_loss", loss)self.log("train_acc", acc)return losslog()方法可以自动计算每个epoch的模型的各个指标,比如准确性,F1-score等等。该方法里面有一些参数是可以额外设置的,比如记录每个batch和epoch下的模型指标,模型训练和验证时创建进度条,还有将模型的各个指标输出到本地文件中。
# Log the loss at each training step and epoch, create a progress bar
self.log("train_loss", loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)3 编写验证和测试步骤代码
def validation_step(self, batch, batch_idx):x, y = batchy_hat = self(x)loss = F.cross_entropy(y_hat, y)acc = (y_hat.argmax(1) == y).float().mean()self.log('val_loss', loss)self.log('val_acc', acc)
def test_step(self, batch, batch_idx):x, y = batchy_hat = self(x)loss = F.cross_entropy(y_hat, y)acc = (y_hat.argmax(1) == y).float().mean()self.log('test_loss', loss)self.log('test_acc', acc)唯一的区别是不需要返回计算出的指标。Lightning模块会自动将正确的数据加载器分配给验证和测试步骤,并在后台创建循环。
尽管validation_step()和test_step()看起来相同,但它们有一个关键的区别:
- validation_step()在训练期间,直接参与模型验证。
- test_step()在测试期间,需要调用训练器对象的.test()方法,才能执行此操作。
4 配置优化器和优化器scheduler程序
为了定义优化器和学习率调度器,需要重写configure_optimizers()类的方法。
def configure_optimizers(self):optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode="min", factor=0.1, patience=5)return {"optimizer": optimizer,"lr_scheduler": {"scheduler": scheduler,"monitor": "val_loss",},}上面,创建了一个Adam优化器,传入超参数和学习率。还定义了一个ReduceLROnPlateau调度函数,用于在验证损失稳定时降低学习率。返回对象字典是最灵活的选项,因为它允许定义需要额外参数的scheduler。
https://lightning.ai/docs/pytorch/stable/common/lightning_module.html#configure-optimizers
5 定义callbacks和记录器
模型类和附带的训练,验证,优化器,学习率调度器和指标计算都已经完成,模型可以实现前向和反向传播,模型更新,验证,记录模型的各个指标。此时,还需要定义一系列的callbacks和记录器类型。这里定义一个checkpoint callback和记录器。
checkpoint_callback = ModelCheckpoint(dirpath="checkpoints",monitor="val_loss",filename="cifar10-{epoch:02d}-{val_loss:.2f}-{val_acc:.2f}",save_top_k=3,mode="min",
)ModelCheckpoint是一个强大的回调,用于在监控给定指标的同时定期保存模型。每个模型检查点都记录到dirpath中。
定义一个tensorboardlogger() 记录方法
logger = TensorBoardLogger(save_dir="lightning_logs", name="cifar10_cnn")定义一个early_stopping callback
early_stopping = EarlyStopping(monitor="val_loss", patience=5, mode="min", verbose=False)6 创建一个trainer类
在将模型LightningModule类和callback, 记录器全部定义完以后,就可以定义一个Trainer 类来实现模型的数据读取,自动训练,验证,模型自动保存,比较简洁。可以定义最大epoch数,使用gpu训练和gpu个数,记录器,callback,训练精度,训练数据比例(默认100%),验证数据比例(默认100%),多少个epoch 模型做一次验证,多少个epoch后记录一次模型指标,记录和模型地址,单gpu训练还是分布式训练。
# Initialize the Trainer
trainer = L.Trainer(max_epochs=50,callbacks=[checkpoint_callback, early_stopping],logger=logger,accelerator="gpu" if torch.cuda.is_available() else "cpu",devices="auto",
)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs7 训练和测试模型
# Train and test the modeltrainer.fit(model, train_loader, test_loader)trainer.test(model, test_loader)8 pytorch lightning 训练模型的基本流程总结
- 创建应用转换的训练、验证和测试数据加载器。
- 将代码组织到一个LightningModule类中:
- 定义初始化。
- 定义训练、验证和(可选)测试步骤。
- 定义优化器和学习率调度器。
- 定义回调和记录器。
- 创建一个训练类trainer
- 初始化模型类。
- 拟合并测试模型。
相关文章:
【AI基础】pytorch lightning 基础学习
传统pytorch工作流是首先定义模型框架,然后写训练和验证,测试循环代码。训练,验证,测试代码写起来比较繁琐。这里介绍使用pytorch lightning 部署模型,加速模型训练和验证,记录。 准备工作 1 安装pytorch…...

高通量测序技术--组蛋白甲基化修饰、DNA亲和纯化测序,教授(优青)团队指导:从实验设计、结果分析到SCI论文辅助
组蛋白甲基化修饰工具(H3K4me3 ChIP-seq)组蛋白甲基化类型也有很多种,包括赖氨酸甲基化位点H3K4、H3K9、H3K27、H3K36、H3K79和H4K20等。组蛋白H3第4位赖氨酸的甲基化修饰(H3K4)在进化上高度保守,是被研究最多的组蛋白修饰之一。 DNA亲和纯化测序 DNA亲…...
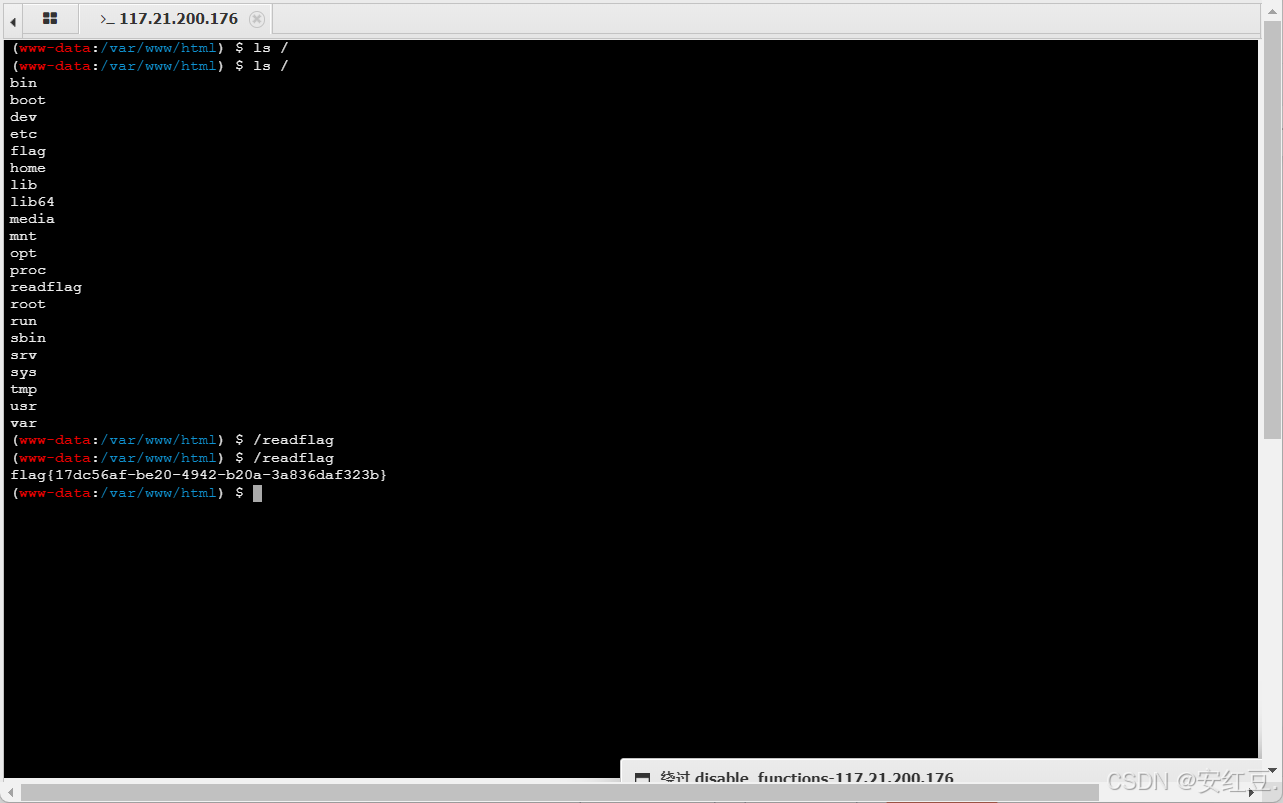
[极客大挑战 2019]RCE ME1
<?php error_reporting(0); if(isset($_GET[code])){$code$_GET[code];if(strlen($code)>40){die("This is too Long.");}if(preg_match("/[A-Za-z0-9]/",$code)){die("NO.");}eval($code); } else{highlight_file(__FILE__); }// ?>…...
计算机毕业设计 中医院问诊系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

FME辅助规划选址
1.需求:新建运动场馆 用地需求:至少1km*2km 找到符合要求的储备地块 2.已有资源:储备用地 现在城市地块储备比较充足,但都是不规则地块 找出可以建大型场馆的地块 3.问题分析 图斑内部可以放下1000*2000的矩形 4.解决思路…...
Unity中的GUIStyle错误:SerializedObject of SerializedProperty has been Disposed.
一运行就循环打印这个报错, 解决办法,每次改参数之后在HIerarchy中手动保存,就会停止循环打印,style中的字体也显示出来了, 或者 直接换个低版本的...
)
实战篇 | WSL迁移Linux系统到非系统盘(完整实操版)
1. 操作步骤 1.1 确认要导出的Linux系统是否存在(可跳过) # 终端命令 # 查看通过WSL安装的Linux系统列表 wsl -l1.2 导出Linux系统为tar包 # 终端命令 # 格式(过) wsl --export <Distribution Name> <File Name> #…...
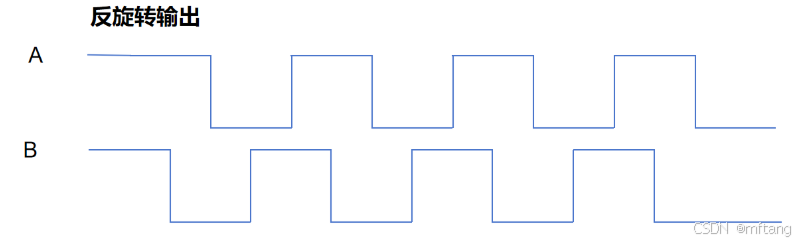
增量式编码器实现原理
目录 概述 1 认识增量式编码器 1.1 概述 1.2 增量式编码器的特性 1.3 编码器的硬件 2 增量式编码器实现原理 2.1 编码器信号 2.2 正反转判断 概述 本文主要介绍增量式编码器实现原理,包括增量式编码器的特性,信号特性,以及如何使用编…...

数据集-目标检测系列-口罩检测数据集 mask>> DataBall
数据集-目标检测系列-口罩检测数据集 mask>> DataBall 数据集-目标检测系列-口罩检测数据集 mask 数据量:1W DataBall 助力快速掌握数据集的信息和使用方式,享有百种数据集,持续增加中。 数据项目地址: gitcode: https…...

工作安排 - 华为OD统一考试(E卷)
2024华为OD机试(C卷+D卷)最新题库【超值优惠】Java/Python/C++合集 题目描述 小明每周上班都会拿到自己的工作清单,工作清单内包含n项工作,每项工作都有对应的耗时时长(单位h)和报酬,工作的总报酬为所有已完成工作的报酬之和。那么请你帮小明安排一下工作,保证小明在指定…...

STM32 GPIO - 笔记
1 STM32的GPIO是漏还是源 在 STM32 微控制器中,GPIO(通用输入/输出)引脚既可以配置为漏极开路输出(Open-Drain)模式,也可以配置为推挽输出(Push-Pull)模式。因此,GPIO 引脚既可以作为“漏”(吸电流,Open-Drain),也可以作为“源”(供电流,Push-Pull)来使用。 GP…...

三篇文章速通JavaSE到SpringBoot框架 (中) IO 进程线程 网络编程 XML MySQL JDBC相关概念与演示代码
文章目录 IOfile类的作用I/O的作用将上篇文章综合项目使用IO流升级所需知识点 进程 线程创建线程的三种方式 网络编程网络编程介绍IP地址端口号网络通信协议网络通信协议的分层演示代码 XMLXML的作用是什么?xml特点 注解什么是注解?注解的使用注解的重要…...

Linux下的基本指令/命令(二)
热键 Tab: 连点两次 对命令进补齐 或者 显式 以目前所需字母 开头的指令。 也可以进行路径补齐 或者 显示所写的文件所处路径上的所有文件。 如果什么也没写,直接按Tab会显示所有命令 Ctrl C: 一旦出现失控的状态,或者任何无法…...

CentOs-Stream-9 设置静态IP外网访问
CentOs-Stream-9 设置静态IP,实现外网访问。这里面有些需要注意的地方,比如IP网段跟我们的宿主机不一样,需要查看具体的网络适配器网段,这样可以快速实现网络互通;另外它的网络配置文件也是不一样的。网络适配器对应的…...

精密制造的革新:光谱共焦传感器与工业视觉相机的融合
在现代精密制造领域,对微小尺寸、高精度产品的检测需求日益迫切。光谱共焦传感器凭借其非接触、高精度测量特性脱颖而出,而工业视觉相机则以其高分辨率、实时成像能力著称。两者的融合,不仅解决了传统检测方式在微米级别测量上的局限…...

边缘计算与 Python Web 应用:从理论到实践
边缘计算与 Python Web 应用:从理论到实践 目录 🌐 边缘计算基础 1.1 边缘计算的概念与云计算的区别1.2 边缘计算在物联网(IoT)与实时应用中的作用 🖥️ Python 在边缘设备上的部署 2.1 在 Raspberry Pi、Jetson Nan…...

华为OD机试真题------分糖果
题目描述: 小明从糖果盒中随意抓一把糖果,每次小明会取出一半的糖果分给同学们。当糖果不能平均分配时,小明可以选择从糖果盒中(假设盒中糖果足够)取出一个糖果或放回一个糖果。小明最少需要多少次(取出、放…...

Kotlin:变量声明,null安全,条件语句,函数,类与对象
目录 一,变量声明 1.1 var和val 1.2 类型推断 1.3 Null安全 1.3.1 处理可为null性 二,条件语句 2.1条件语句与条件表达式 2.2 智能类型转换 三,函数 3.1 简化函数声明 3.2 匿名函数 3.3 高阶函数 四,类与对象 4.1 构…...

C--结构体和位段的使用方法
各位看官如果您觉得这篇文章对您有帮助的话 欢迎您分享给更多人哦 感谢大家的点赞收藏评论,感谢您的支持!!! 一:结构体 首先结构体我们有一个非常重要的规则 非常重要: 我们允许在初始化时自动将字符串字面…...

卷积神经网络-迁移学习
文章目录 一、迁移学习1.定义与性质2.步骤 二、Batch Normalization(批次归一化)三、ResNet网络1.核心思想2.残差结构(1)残差块(2)残差结构类型 四、总结 一、迁移学习 迁移学习(Transfer Lear…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...

数据库——redis
一、Redis 介绍 1. 概述 Redis(Remote Dictionary Server)是一个开源的、高性能的内存键值数据库系统,具有以下核心特点: 内存存储架构:数据主要存储在内存中,提供微秒级的读写响应 多数据结构支持&…...

EEG-fNIRS联合成像在跨频率耦合研究中的创新应用
摘要 神经影像技术对医学科学产生了深远的影响,推动了许多神经系统疾病研究的进展并改善了其诊断方法。在此背景下,基于神经血管耦合现象的多模态神经影像方法,通过融合各自优势来提供有关大脑皮层神经活动的互补信息。在这里,本研…...
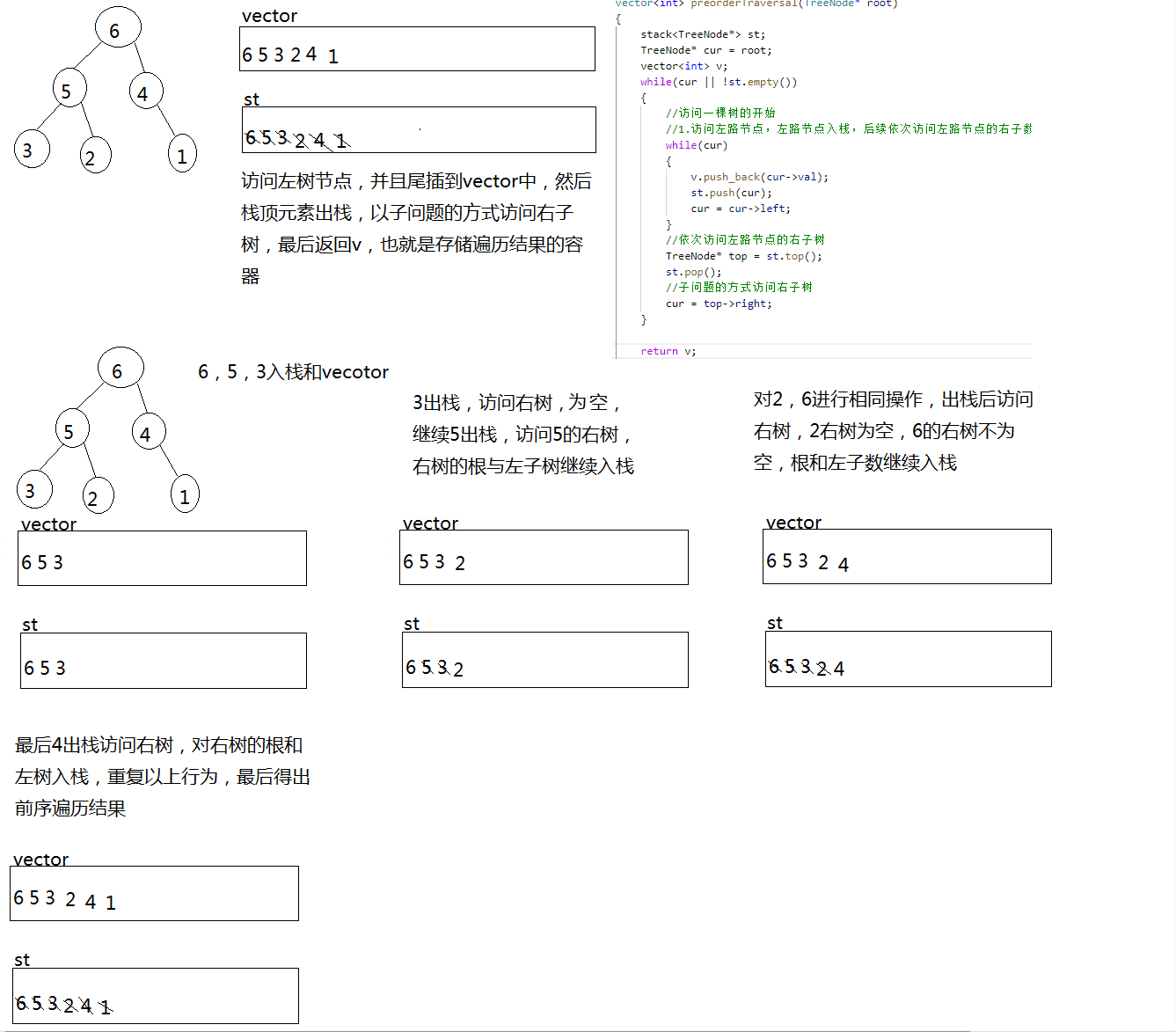
二叉树-144.二叉树的前序遍历-力扣(LeetCode)
一、题目解析 对于递归方法的前序遍历十分简单,但对于一位合格的程序猿而言,需要掌握将递归转化为非递归的能力,毕竟递归调用的时候会调用大量的栈帧,存在栈溢出风险。 二、算法原理 递归调用本质是系统建立栈帧,而非…...

PostgreSQL 与 SQL 基础:为 Fast API 打下数据基础
在构建任何动态、数据驱动的Web API时,一个稳定高效的数据存储方案是不可或缺的。对于使用Python FastAPI的开发者来说,深入理解关系型数据库的工作原理、掌握SQL这门与数据库“对话”的语言,以及学会如何在Python中操作数据库,是…...