Redis实战--Redis应用过程中出现的热门问题及其解决方案
Redis作为一种高性能的key-value数据库,广泛应用于缓存、消息队列、排行榜等场景。然而,在实际应用中,随着业务规模的不断扩大和访问量的持续增长,缓存系统也面临着诸多挑战,其中最为典型的便是缓存穿透、缓存击穿和缓存雪崩三大问题。本文将深入探讨这三大问题的成因、表现以及相应的解决方案,并结合实际案例和最佳实践,为开发者提供全面的指导。
Redis简单介绍与安装应用-CSDN博客
Redis实战--Windows上的Redis使用及Java代码操作Redis-CSDN博客
Redis实战--Redis的数据持久化与搭建Redis主从复制模式和搭建Redis的哨兵模式-CSDN博客
Redis实战--Redis集群的搭建与使用-CSDN博客
一、缓存穿透
1.1 定义与成因
缓存穿透(Cache Penetration)是指查询一个数据库中不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。简而言之,就是缓存没有起到应有的作用,用户查询的数据在缓存和数据库中都不存在,而大量的这类查询请求会直接打到数据库上,造成数据库压力增大,甚至可能引发数据库宕机。

缓存穿透的成因主要有以下几点:
- 恶意攻击:攻击者故意构造大量不存在的数据查询请求,以消耗系统资源,达到攻击目的。
- 用户误操作:用户在输入查询条件时,由于输入错误或系统错误,导致查询的数据不存在。
- 数据天然不存在:在某些业务场景下,查询的数据可能确实不存在于数据库中,比如用户查询的商品编号已经下架或从未上架。
1.2 解决方案
1.2.1 缓存空对象或缺省值
缓存空对象或缺省值是一种常见的解决方案。当查询一个不存在的数据时,将其结果(空对象或缺省值)缓存起来,并设置较短的过期时间。这样,当后续的查询请求再次访问这个不存在的数据时,就可以直接从缓存中获取结果,而无需再去查询数据库。这种方法虽然简单有效,但需要注意以下几点:
- 合理设置过期时间:过期时间不宜过长,以免无效数据长期占用缓存空间。
- 注意缓存的空间大小:如果大量不存在的数据被缓存,可能会占用过多的缓存空间,影响其他正常数据的缓存效果。
- 区分业务场景:在某些业务场景下,即使数据不存在也可能有特殊的处理逻辑,因此需要仔细区分并处理。
实现步骤
- 当查询数据库返回结果为空时,将空对象或缺省值以特定的 key 缓存起来,并设置较短的过期时间。
优点:
- 实现简单,能够快速部署。
- 能够有效减少数据库查询压力。
缺点:
- 需要缓存层提供更多的内存空间来存储空值或缺省值。
- 如果空值或缺省值过多,会浪费缓存资源。
1.2.2 布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率很高的概率型数据结构,用于判断一个元素是否在一个集合中。它允许存在一定的误判率,但不存在漏判率。通过将所有可能存在的数据通过哈希函数映射到一个足够大的位数组中,布隆过滤器可以快速地判断一个元素是否可能存在。
在缓存穿透的场景中,可以在查询缓存之前,先使用布隆过滤器判断数据是否存在。如果布隆过滤器判断数据不存在,则直接返回结果,避免查询数据库。这种方法可以显著降低对数据库的查询压力,但需要注意以下几点:
- 误判率:布隆过滤器存在误判率,即有可能将不存在的数据误判为存在。因此,在设计时需要合理设置布隆过滤器的参数,以平衡误判率和空间效率。
- 更新与同步:当数据库中的数据发生变化时(如新增、删除等),需要及时更新布隆过滤器中的位数组,以保证数据的准确性。
- 适用场景:布隆过滤器适用于数据量大、允许一定误判率的场景。对于对数据准确性要求极高的场景,可能需要考虑其他解决方案。
实现步骤:
- 将所有可能存在的数据key添加到布隆过滤器中。
- 在查询缓存之前,先通过布隆过滤器判断key是否存在。
- 如果布隆过滤器判断key不存在,则直接返回空值或错误信息,不再查询缓存和数据库。
优点:
- 过滤效率高,能够显著减少数据库查询压力。
- 占用空间小,适合大规模数据场景。
缺点:
- 存在误判率,即可能将存在的数据误判为不存在。
- 代码维护较为复杂,需要维护布隆过滤器的更新和同步。
- 删除困难,无法直接从布隆过滤器中删除元素。
1.2.3 监控与限流
除了上述技术手段外,还可以通过监控和限流来应对缓存穿透。通过监控接口的访问频率和请求参数,可以及时发现并处理恶意攻击或异常请求。同时,设置合理的限流策略(如令牌桶算法、漏桶算法等),可以对请求进行限流和降级处理,以保护系统整体稳定性。
实现方式:
- 使用Redis的INCR命令记录每个IP或用户的访问次数。
- 当访问次数超过阈值时,进行限流或封禁处理。
优点:
- 能够有效防止恶意攻击。
- 实现简单,易于部署。
缺点:
- 可能误伤正常用户。
- 需要根据业务场景合理设置访问次数阈值。
二、缓存击穿
2.1 定义与成因
缓存击穿(Cache Breakdown)是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。与缓存穿透不同的是,缓存击穿针对的是某个热点数据的缓存过期或失效问题。

缓存击穿的成因主要有以下几点:
- 热点数据缓存过期:热点数据的缓存过期后,大量请求同时访问数据库,导致数据库压力增大。
- 缓存失效策略不当:如果缓存的失效策略设置不当(如统一设置较短的过期时间),可能会导致大量数据同时失效,从而引发缓存击穿。
- 数据库压力测试不足:在系统设计时,如果没有充分考虑数据库的压力测试,可能会导致在缓存失效后数据库无法承受高并发访问。
2.2 解决方案
2.2.1 设置热点数据永不过期
对于热点数据,可以设置较长的过期时间或永不过期,以减少缓存失效的概率。这种方法虽然简单,但需要注意以下几点:
- 数据更新问题:如果热点数据需要频繁更新,那么永不过期可能会导致数据不一致的问题。因此,需要根据业务场景合理设置过期时间。
- 缓存空间占用:永不过期的数据会长期占用缓存空间,影响其他数据的缓存效果。因此,需要合理规划缓存空间的使用。
实现步骤
- 在缓存设置时,对于热点数据,不设置过期时间(物理不过期),或者在数据结构中为每个热点数据项设置一个逻辑过期时间字段。当业务逻辑判断数据需要更新时(如根据数据更新时间戳或其他业务规则),通过异步线程或后台任务来更新数据,并同时更新逻辑过期时间字段。
优点:
- 能够有效避免缓存击穿问题。
- 实现简单,易于维护。
缺点:
- 需要消耗更多的缓存资源。
- 可能导致缓存数据与实际数据不一致。
2.2.2 使用互斥锁
在查询数据库前,先使用互斥锁进行加锁,确保只有一个线程能够查询数据库并更新缓存,其他线程则等待或返回默认值。这种方法可以有效避免多个线程同时查询数据库导致的问题,但需要注意以下几点:
- 锁的性能问题:互斥锁会引入额外的性能开销,特别是在高并发场景下。因此,需要合理选择锁的实现方式和粒度。
- 死锁问题:在使用互斥锁时,需要注意避免出现死锁的情况。可以通过设置锁的超时时间、使用可重入锁等方式来避免死锁。
实现步骤
- 在查询数据库前,使用互斥锁对相关操作进行加锁。可以使用编程语言提供的互斥锁机制(如 Java 中的 synchronized 关键字或 ReentrantLock 类)。当一个线程获取到锁后,其他线程将被阻塞。
- 获取锁的线程查询数据库获取数据,然后将数据更新到缓存中,并释放锁。其他被阻塞的线程在锁释放后,可以重新尝试获取数据,如果缓存中已经有数据,则直接返回;如果缓存中仍然没有数据,则再次尝试获取锁并查询数据库。
优点:
- 思路比较简单。
- 能够较好地降低后端存储负载,并在一致性上做得比较好。
缺点:
- 如果在查询数据库和重建缓存(key 失效后进行了大量的计算)时间过长,也可能会存在死锁和线程池阻塞的风险。
- 在高并发情景下吞吐量会大大降低。
2.2.3 分布式锁
在多机部署的环境中,需要使用分布式锁来控制缓存的更新。分布式锁可以保证在多台服务器之间同步锁的状态,从而避免多个线程或进程同时查询数据库导致的问题。Redisson等分布式锁工具提供了丰富的功能和良好的性能表现,是实现分布式锁的一种常用方式。
实现步骤:
- 使用Redis的SETNX或Redisson等分布式锁实现方式。
- 在查询数据库之前,先尝试获取锁。
- 如果获取到锁,则查询数据库并更新缓存;如果未获取到锁,则等待一段时间后重试或返回空值。
优点:
- 能够有效避免缓存击穿问题。
- 适用于高并发场景。
缺点:
- 增加了系统的复杂性和延迟。
- 需要合理设置锁的过期时间和重试机制。
三、缓存雪崩
3.1 定义与成因
缓存雪崩(Cache Avalanche)是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿是一个热点key过期,而缓存雪崩则是大量的key同时过期。当大量缓存数据在同一时间失效时,如果有大量请求访问这些数据,那么这些请求就会直接打到数据库上,导致数据库压力瞬间增大,甚至可能引发数据库宕机。
缓存雪崩的成因主要有以下几点:
- 缓存过期时间设置不当:如果大量缓存数据的过期时间设置得过于集中(如统一设置为某个时间点的整点过期),就可能导致缓存雪崩。
- 缓存数据依赖性强:在某些业务场景中,缓存数据之间存在较强的依赖性。当某个关键数据失效时,可能会引发一系列相关数据的失效和重新加载。
- 数据库压力大:在缓存失效后,如果数据库无法承受高并发访问的压力,就可能导致数据库宕机或性能下降。
3.2 解决方案
3.2.1 数据预热
在系统上线前或低峰期,预先将热点数据加载到缓存中,避免在系统启动时或高峰期大量请求直接打到数据库。数据预热可以显著减少缓存失效后对数据库的访问压力,提高系统的整体性能。
实现步骤
- 在系统上线前或低峰期,分析业务数据的访问频率和重要性,确定需要预热的热点数据。这些数据通常是在高并发情况下经常被访问的数据,如首页展示数据、热门商品信息等。
- 将确定的热点数据从数据库中加载出来,并存储到缓存中。可以使用批量加载的方式提高效率,例如使用数据库的查询语句一次性获取多条数据,然后将这些数据批量存储到缓存中。
优点
- 提前加载数据到缓存,避免在高并发时大量请求直接访问数据库。
缺点
- 需要手动触发和管理,对于动态数据可能不太适用。
3.2.2 随机过期时间
在设置缓存过期时间时,为不同的key设置不同的过期时间,避免大量key同时过期。可以通过在固定过期时间的基础上加上一个随机时间差来实现这一点。例如,可以将缓存的过期时间设置为“固定时间 + 随机秒数”的形式。这样可以有效分散缓存失效的时间点,降低缓存雪崩的风险。
优点
- 有效分散缓存失效的时间点,降低缓存雪崩的风险。
缺点
- 如果随机范围过大,可能会影响缓存数据的时效性。
3.2.3 熔断降级
在缓存失效或数据库压力过大时,使用熔断降级策略来保护系统整体稳定性。熔断降级可以在系统面临过载风险时自动触发,通过暂时停止缓存服务或返回降级信息等方式来减少对数据库的访问压力。同时,还可以根据系统的负载情况动态调整熔断降级的阈值和恢复策略。
实现步骤
- 根据系统的性能和业务需求,设置熔断降级的阈值和策略。阈值可以包括数据库的负载指标(如每秒查询次数、响应时间等)和缓存的相关指标(如命中率、过期率等)。策略可以包括停止缓存服务、返回降级信息(如默认值、提示信息等)、限制请求流量等。
- 实时监控系统的性能指标,当达到熔断降级的阈值时,自动触发相应的策略。可以使用监控工具(如 Prometheus、Grafana 等)来实现对系统指标的实时监控。
- 根据系统的负载情况动态调整熔断降级的阈值和恢复策略。例如,当系统负载降低时,可以适当提高阈值,恢复部分缓存服务或放宽请求流量限制。
优点
- 保护系统整体稳定性。
缺点
- 业务功能可能受影响,当触发熔断降级时,可能会停止部分缓存服务或返回不准确的信息,这可能会对业务功能产生一定影响,例如用户可能会看到不准确的页面内容或无法正常使用某些功能。
- 配置和维护复杂,需要合理设置熔断降级的阈值和恢复工作策略,这需要对系统的性能和业务负载有深入的了解,并且在系统运行过程中可能需要不断调整和优化,增加了配置和维护的复杂性。
3.2.4 监控与预警
建立完善的监控和预警机制是应对缓存雪崩的重要手段之一。通过实时监控缓存和数据库的负载情况、查询频率、响应时间等关键指标,可以及时发现并处理潜在的缓存雪崩风险。同时,还可以设置预警阈值和报警规则,以便在系统出现异常时及时通知相关人员进行处理。
实现步骤
- 建立完善的监控系统,实时监控缓存和数据库的负载情况、查询频率、响应时间等关键指标。可以使用监控工具(如 Prometheus、Grafana 等)来实现对系统指标的实时监控。
- 根据系统的性能和业务需求,设置预警阈值和报警规则。阈值可以包括数据库的负载指标(如每秒查询次数、响应时间等)和缓存的相关指标(如命中率、过期率等)。报警规则可以包括邮件通知、短信通知、系统内消息通知等方式,当指标超过阈值时,按照报警规则进行通知。
优点
- 及时发现风险,通过实时监控缓存和数据库的关键指标,可以快速发现潜在的缓存雪崩风险,为及时采取措施提供依据。
- 主动预防,设置预警阈值和报警规则后,一旦出现异常情况能及时通知相关人员进行处理,使运维人员能够在问题恶化之前采取措施,起到主动预防的作用。
缺点
- 资源消耗,监控需要消耗一定的系统资源,包括 CPU、内存和网络带宽等,如果监控的指标过多或频率过高,可能会对系统性能产生一定影响。
- 依赖人工处理,虽然能够及时发现问题并报警,但最终的处理还是依赖人工操作,如果相关人员未能及时响应报警信息,可能无法有效避免缓存雪崩的发生。
四、综合对比与选择
4.1 方案对比
| 问题 | 解决方案 | 优点 | 缺点 |
|---|---|---|---|
| 缓存穿透 | 缓存空对象或缺省值 | 简单快速,减少数据库压力 | 需更多缓存空间,空值过多浪费资源 |
| 布隆过滤器 | 过滤效率高,空间小 | 存在误判率,维护复杂,删除困难 | |
| 监控与限流 | 防止恶意攻击,简单易部署 | 可能误伤用户,需合理设阈值 | |
| 缓存击穿 | 设置热点数据永不过期 | 简单有效,避免击穿 | 消耗更多缓存,可能数据不一致 |
| 使用互斥锁 | 思路简单,降负载保一致 | 性能开销大,可能死锁,高并发吞吐量低 | |
| 分布式锁 | 有效避免击穿,适用于高并发 | 增加复杂性和延迟,需合理设参数 | |
| 缓存雪崩 | 数据预热 | 提前加载数据,减少数据库压力 | 需手动触发管理,不适用于动态数据 |
| 随机过期时间 | 分散失效时间点,降低风险 | 随机范围过大可能影响时效性 | |
| 熔断降级 | 保护系统稳定性 | 业务功能可能受影响,配置和维护复杂 | |
| 监控与预警 | 及时发现风险,主动预防 | 资源消耗,依赖人工处理 |
4.2 选择依据
在实际应用中,选择合适的解决方案需要综合考虑多个因素:
- 业务场景特点
- 如果业务对数据准确性要求极高,对于缓存穿透问题应避免使用布隆过滤器这种存在误判率的方案;对于缓存击穿问题,如果热点数据更新频繁,则不宜设置永不过期。
- 如果业务中存在大量热点数据且并发量高,对于缓存击穿问题可能更倾向于分布式锁方案;对于缓存雪崩问题,数据预热和随机过期时间设置可能更为重要。
- 系统性能要求
- 如果系统对性能要求极高,对于缓存穿透问题的缓存空对象方案可能需要谨慎使用,因为可能占用过多缓存空间影响性能;对于缓存击穿问题,互斥锁和分布式锁的性能开销需要考虑,可能需要根据并发量等因素进行优化。
- 对于缓存雪崩问题,熔断降级和监控预警机制可以在一定程度上保障系统性能,避免数据库因大量请求而崩溃。
- 维护成本和复杂性
- 布隆过滤器和分布式锁的维护相对复杂,需要考虑是否有足够的技术能力和资源进行维护。如果维护成本过高,对于缓存穿透和缓存击穿问题可能需要选择其他相对简单的方案。
- 对于缓存雪崩问题,数据预热虽然能有效解决问题,但手动触发和管理的方式可能增加维护成本,需要根据实际情况权衡。
五、总结
缓存穿透、缓存击穿和缓存雪崩是缓存系统中常见的三大问题。它们不仅会影响系统的性能和稳定性,还可能对业务造成严重的损失。因此,在设计和实现缓存系统时,需要充分考虑这些问题并采取相应的解决方案。本文深入探讨了缓存穿透、缓存击穿和缓存雪崩的成因、表现以及解决方案,并结合实际案例和最佳实践为开发者提供了全面的指导。
参考链接:
缓存穿透、缓存击穿、缓存雪崩的理解和解决方案[通俗易懂]-腾讯云开发者社区-腾讯云
【Redis】缓存击穿、缓存穿透、缓存雪崩原理以及多种解决方案_redis血崩和穿透-CSDN博客
redis布隆过滤器(Bloom)详细使用教程_布隆过滤器使用-CSDN博客
Redis分布式锁-这一篇全了解(Redission实现分布式锁完美方案)-CSDN博客
不用背八股文!一文搞懂redis缓存击穿、穿透、雪崩!-腾讯云开发者社区-腾讯云
【面试】redis缓存穿透、缓存击穿、缓存雪崩区别和解决方案-CSDN博客
缓存穿透、缓存击穿、缓存雪崩区别和解决方案-CSDN博客
一文彻底分清缓存穿透、缓存击穿、缓存雪崩问题(含记忆技巧)-CSDN博客
相关文章:
Redis实战--Redis应用过程中出现的热门问题及其解决方案
Redis作为一种高性能的key-value数据库,广泛应用于缓存、消息队列、排行榜等场景。然而,在实际应用中,随着业务规模的不断扩大和访问量的持续增长,缓存系统也面临着诸多挑战,其中最为典型的便是缓存穿透、缓存击穿和缓…...

实时数字人DH_live使用案例
参看: https://github.com/kleinlee/DH_live ubuntu 测试 apt install ffmpeg 下载安装: git clone https://github.com/kleinlee/DH_live.git cd DH_liveconda create -n dh_live python=3.12 conda activate dh_live pip install -r requirements.txt pip install torch -…...
线上环境排故思路与方法GC优化策略
前言 这是针对于我之前[博客]的一次整理,因为公司需要一些技术文档的定期整理与分享,我就整理了一下。(https://blog.csdn.net/TT_4419/article/details/141997617?spm1001.2014.3001.5501) 其实,nginx配置 服务故障转移与自动恢复也是可以…...
硬件设计很简单?合宙低功耗4G模组Air780E—开机启动及外围电路设计
Air780E是合宙低功耗4G-Cat.1模组经典型号之一,上期我们解答了大家关心的系列问题,并讲解了选型的注意要点。 有朋友问:能不能讲些硬件设计相关的内容? 模组的上电开机,是硬件设计调试的第一步。 本期特别分享——Ai…...

初试AngularJS前端框架
文章目录 一、框架概述二、实例演示(一)创建网页(二)编写代码(三)浏览网页(四)运行结果 三、实战小结 一、框架概述 AngularJS 是一个由 Google 维护的开源前端 JavaScript 框架&am…...

【学习笔记】手写 Tomcat 六
目录 一、线程池 1. 构建线程池的类 2. 创建任务 3. 执行任务 测试 二、URL编码 解决方案 测试 三、如何接收客户端发送的全部信息 解决方案 测试 四、作业 1. 了解工厂模式 2. 了解反射技术 一、线程池 昨天使用了数据库连接池,我们了解了连接池的优…...
打靶记录18——narak
靶机: https://download.vulnhub.com/ha/narak.ova 推荐使用 VM Ware 打开靶机 难度:中 目标:取得 root 权限 2 Flag 攻击方法: 主机发现端口扫描信息收集密码字典定制爆破密码Webdav 漏洞PUT 方法上传BF 语言解码MOTD 注入CVE-2021-3…...
LabVIEW编程能力如何能突飞猛进
要想让LabVIEW编程能力实现突飞猛进,需要采取系统化的学习方法,并结合实际项目进行不断的实践。以下是一些提高LabVIEW编程能力的关键策略: 1. 扎实掌握基础 LabVIEW的编程本质与其他编程语言不同,它是基于图形化的编程方式&…...

代码随想录算法训练营第四四天| 1143.最长公共子序列 1035.不相交的线 53. 最大子序和 392.判断子序列
今日任务 1143.最长公共子序列 1035.不相交的线 53. 最大子序和 392.判断子序列 1143.最长公共子序列 题目链接: . - 力扣(LeetCode) class Solution {public int longestCommonSubsequence(String text1, String text2) {int[][] dp ne…...

2024.9.26 作业 +思维导图
一、作业 1、什么是虚函数?什么是纯虚函数 虚函数:函数前加关键字virtual,就定义为虚函数,虚函数能够被子类中相同函数名的函数重写 纯虚函数:把虚函数的函数体去掉然后加0;就能定义出一个纯虚函数。 2、基…...
WSL进阶体验:gnome-terminal启动指南与中文显示问题一网打尽
起因 我们都知道 wsl 启动后就死一个纯命令行终端,一直以来我都是使用纯命令行工具管理Linux的。今天看到网上有人在 wsl 中启动带图形界面的软件。没错,就是在wsl中启动带有图形界面的Linux软件。比如下面这个编辑器。 出于好奇,我就…...

recoil和redux之间的选择
Recoil 和 Redux 是两个流行的 JavaScript 状态管理库,它们各自有不同的设计理念和使用场景。选择哪一个更好用,取决于你的具体需求、项目规模和个人偏好。 1. 设计理念 Redux 单向数据流:Redux 采用单向数据流模型,所有的状态变…...

无人机的作战指挥中心-地面站!
无人机与地面站的关系 指挥与控制:地面站是无人机系统的核心控制部分,负责对无人机进行远程指挥和控制。无人机根据地面站下达的任务自主完成飞行任务,并实时向地面站反馈飞行状态和任务执行情况。 任务规划与执行:地面站具备任…...
)
Vue 23进阶面试题:(第八天)
目录 29.vue2.0和vue3.0区别? 30.事件中心的原理 31.使用基于token的登录流程 32.防抖和节流 防抖(debounce) 节流(throttle) 29.vue2.0和vue3.0区别? 1.由选项API转变为组合API。 2.vue3将全局配置…...

Acwing 最小生成树
最小生成树 最小生成树:由n个节点,和n-1条边构成的无向图被称为G的一棵生成树,在G的所有生成树中,边的权值之和最小的生成树,被称为G的最小生成树。(换句话说就是用最小的代价把n个点都连起来) Prim 算法…...

VIM简要介绍
安装 大多数 Linux 发行版和 macOS 都预装了 VIM。如果没有,你可以通过包管理器安装: Ubuntu/Debian: sudo apt-get install vimFedora: sudo dnf install vimmacOS: brew install vim(使用 Homebrew)Windows: 可以从 VIM 官网下…...

.NET 6.0 使用log4net配置日志记录方法
1.包管理器引入相关包 2.添加Log4net文件夹和log4net.config配置文件(配置文件属性设为始终复制)。 3.替换 log4net.config的内容(3.1与3.2选择一个就好,只是创建日志文件有所区别) 3.1: <?xml version"1.0" encoding"utf-8"?> <configuration…...

Unity角色控制及Animator动画切换如走跑跳攻击
Unity角色控制及 Animator动画切换如走跑跳攻击 目录 Unity角色控制及 一、 概念 1、角色控制 1) CharacterController(角色控制器) 2) CapsuleCollider + Rigidbody(使用物理刚体控制) 2、角色动画-Animation、Animator 1) 旧版动画系统...

JSP+Servlet+Mybatis实现列表显示和批量删除等功能
前言 使用JSP回显用户列表,可以进行批量删除(有删除确认步骤),和修改用户数据(用户数据回显步骤)使用servlet处理传递进来的请求参数,并调用dao处理数据并返回使用mybatis,书写dao层…...

Cannot read properties of undefined (reading ‘upgrade‘)
前端开发工具:VSCODE 报错信息: INFO Starting development server...10% building 2/2 modules 0 active ERROR TypeError: Cannot read properties of undefined (reading upgrade)TypeError: Cannot read properties of undefined (reading upgrade…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...
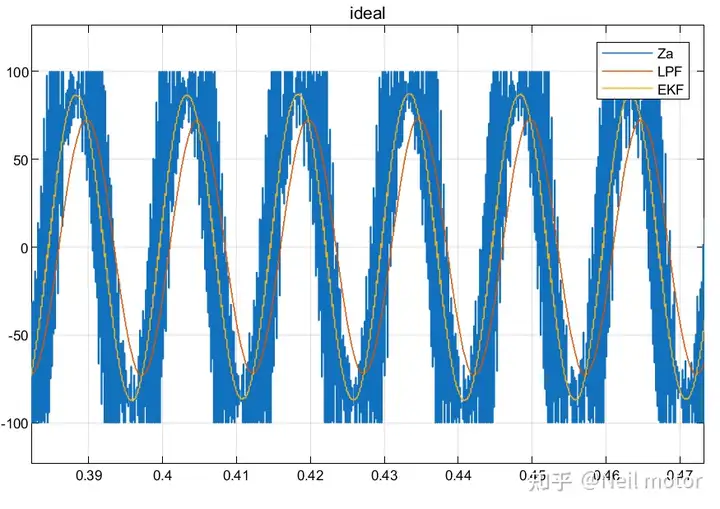
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...

十九、【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建
【用户管理与权限 - 篇一】后端基础:用户列表与角色模型的初步构建 前言准备工作第一部分:回顾 Django 内置的 `User` 模型第二部分:设计并创建 `Role` 和 `UserProfile` 模型第三部分:创建 Serializers第四部分:创建 ViewSets第五部分:注册 API 路由第六部分:后端初步测…...