R包compareGroups详细用法
compareGroups
compareGroups 是一个功能强大的 R 包,专为数据质量控制、数据探索和生成用于出版的单变量或双变量表格而设计。它能够创建各种格式的报表,如纯文本、HTML、LaTeX、PDF、Word 或 Excel 格式,并显示统计数据(均值、中位数、频率、发生率等)。此外,它还能生成可视化图表(如箱线图、条形图、正态分布图等),帮助快速理解数据分布。根据变量的性质(正态、非正态或定性变量),compareGroups 可以自动选择合适的统计检验(如t检验、方差分析、Kruskal-Wallis检验、Fisher检验、log-rank检验等)。它还支持基因数据的总结与分析,显示单核苷酸多态性(SNPs)的等位基因频率,并进行哈迪-温伯格平衡检验等常见的基因统计分析。
1、cGroupsGUI–基于tcltk工具的图形用户界面
描述
该函数允许用户通过图形界面以简单直观的方式构建表格,并修改多个选项。
用法
cGroupsGUI(X)
- X: 一个矩阵或 data.frame。
X必须存在于.GlobalEnv中。
注意
如果通过 X 参数传递了 data.frame 或矩阵,或通过 ‘加载数据’ GUI 菜单加载该对象,此对象将被放置在 .GlobalEnv 中。当 GUI 界面打开时,操作此 data.frame 或矩阵可能会导致 GUI 操作执行时出错。
示例
data(regicor)
cGroupsGUI(regicor)
2、cGroupsWUI–基于 Shiny 工具的 Web 用户界面
描述
该函数使用基于 shiny 包的图形界面,在 Web 浏览器中打开界面。
用法
cGroupsWUI(port = 8102L)
- port: 整数类型,与
runApp的port参数相同。默认值为 8102L。如果启动 Web 浏览器时发生错误,可以通过更改端口号来解决。
示例
require(compareGroups)
cGroupsWUI()
3、compareGroups–按组描述性统计
描述
该函数执行按组的描述性统计,适用于多个变量。根据这些变量的性质,计算不同的描述性统计(均值,中位数,频率或 K-M 概率),并根据需要进行不同的统计检验(t 检验,ANOVA,Kruskal-Wallis,Fisher,log-rank 等)。
用法
compareGroups(formula, data, subset, na.action = NULL, y = NULL, Xext = NULL, selec = NA, method = 1, timemax = NA, alpha = 0.05, min.dis = 5, max.ylev = 5, max.xlev = 10, include.label = TRUE, Q1 = 0.25, Q3 = 0.75, simplify = TRUE, ref = 1, ref.no = NA, fact.ratio = 1, ref.y = 1, p.corrected = TRUE, compute.ratio = TRUE, include.miss = FALSE, oddsratio.method = "midp", chisq.test.perm = FALSE, byrow = FALSE, chisq.test.B = 2000, chisq.test.seed = NULL, Date.format = "d-mon-Y", var.equal = TRUE, conf.level = 0.95, surv=FALSE, riskratio = FALSE, riskratio.method = "wald", compute.prop = FALSE, lab.missing = "'Missing'", p.trend.method = "spearman")
-
formula: 一个"公式"类的对象(或可以被转换为该类的对象)。
~的右侧必须以加法方式包含项,左侧必须包含分组变量的名称。如果留空,则计算整个样本的描述性统计,而不进行测试。 -
data: 一个可选的数据框、列表或环境(或可以被
as.data.frame转换为数据框的对象),包含模型中的变量。如果在data中找不到这些变量,则从environment(formula)中提取。 -
subset: 一个可选的向量,指定用于计算过程的个体子集。它应用于所有行变量。
subset和selec在每个行变量上以&的方式结合应用。 -
na.action: 一个函数,指示当数据中包含缺失值时应采取的操作。默认值为
NULL,相当于na.pass,这意味着不采取任何操作。na.exclude对于希望在任何变量中移除所有缺失值的情况很有用。 -
y: 一个向量变量,用于区分分组。它必须是数字、字符、因子或 NULL。默认值为 NULL,表示计算整个样本的描述性统计,而不进行测试。
-
Xext: 一个数据框或矩阵,包含与 X 相同的行/个体,但可能具有不同的变量/列。此参数用于
compareGroups.default,以便在 Xext 和/或.GlobalEnv中搜索在selec参数中指定的变量。如果 Xext 为 NULL,则从 X 加上 y 的变量创建 Xext。默认值为 NULL。 -
selec: 一个与行变量数量相同的列表。如果列表长度为 1,则对所有行变量进行回收。
selec的每个组件是一个表达式,将被评估以选择要分析的个体。否则,命名列表指定应用于selec行变量。如果没有定义.else变量,则对其余变量应用默认值。默认值为 NA;所有个体都会被分析(不进行子集)。 -
method: 一个整数向量,具有与行变量数量相同的组件。如果其长度为 1,则对所有行变量进行回收。它仅适用于连续行变量(对于因子行变量,将被忽略)。可能的值是:
- 1:强制分析为"正态分布";
- 2:强制分析为"连续非正态";
- 3:强制分析为"分类";
- 4:NA,执行 Shapiro-Wilk 检验以决定正态或非正态。 否则,命名向量指定应用于
method行变量。如果没有定义.else变量,则对其余变量应用默认值。默认值为 1。
-
timemax: 一个双精度向量,具有与行变量数量相同的组件。如果其长度为 1,则对所有行变量进行回收。它仅适用于
Surv类行变量(对于所有其他行变量,将被忽略)。该值指示在何时计算 K-M 概率。否则,命名向量指定应用于timemax行变量。如果没有定义.else变量,则对其余变量应用默认值。默认值为 NA;K-M 概率在观察到的时间的中位数时计算。 -
alpha: 介于 0 和 1 之间的双精度值。Shapiro-Wilk 正态性检验的显著性阈值,适用于连续行变量。默认值为 0.05。
-
min.dis: 一个整数。如果非因子行变量包含少于
min.dis个不同值,并且method参数设置为 NA,则将其转换为因子。默认值为 5。 -
max.ylev: 一个整数,表示分组变量(
y)的最大水平数量。如果y包含超过max.ylev的水平,则函数compareGroups会产生错误。默认值为 5。 -
max.xlev: 一个整数,表示行变量作为因子时的最大水平数量。如果行变量是因子(或转换为因子,例如字符),并且包含超过
max.xlev的水平,则会从分析中移除该变量,并打印警告。默认值为 10。 -
include.label: 逻辑值,指示结果中是否显示变量标签。默认值为 TRUE。
-
Q1: 一个双精度值,介于 0 和 1 之间,指示要在双变量表中显示的第一个数字的分位数。要计算最小值,只需输入 0。默认值为 0.25,表示第一个四分位数。
-
Q3: 一个双精度值,介于 0 和 1 之间,指示要在双变量表中显示的第二个数字的分位数。要计算最大值,只需输入 1。默认值为 0.75,表示第三个四分位数。
-
simplify: 逻辑值,指示是否在分组变量和行变量中删除没有值的水平。默认值为 TRUE。
-
ref: 一个整数向量,具有与行变量数量相同的组件。如果其长度为 1,则对所有行变量进行回收。它仅适用于分类行变量。或者,命名向量指定应用于
ref的行变量(一个保留名称是.else,定义其余变量的参考类别);如果没有定义.else变量,则对其余变量应用默认值。默认值为 1。 -
ref.no: 一个字符,指定作为 Odds Ratio 或 Hazard Ratio 的参考水平的名称。此名称不区分大小写。特别适用于是/否变量。默认值为 NA,表示
ref指定的类别作为参考。 -
fact.ratio: 一个双精度向量,具有与行变量数量相同的组件,指示 HR/OR 的单位(注意这不影响描述性统计)。如果其长度为 1,则对所有行变量进行回收。否则,命名向量指定应用于
fact.ratio的行变量。.else是一个保留名称,定义其余变量的参考类别;如果没有定义.else变量,则对其余变量应用默认值。默认值为 1。 -
ref.y: 一个整数,指示 y 变量的参考类别,用于计算 OR,当 y 是二元因子时。默认值为 1。
-
p.corrected: 逻辑值,指示是否必须校正成对比较的 p 值。这仅适用于具有超过 2 个类别的分组变量。默认值为 TRUE。
-
compute.ratio: 逻辑值,指示是否必须计算 Odds Ratio(对于二元响应)或 Hazard Ratio(对于时间事件响应)。默认值为 TRUE。
-
include.miss: 逻辑值,指示是否将缺失值视为分类变量的新类别。默认值为 FALSE。
-
oddsratio.method: 指定计算 Odds Ratio 的方法。参见
oddsratio参数(来自 epitools 包)。默认值为 “midp”。 -
byrow: 逻辑值或 NA。应按行(TRUE)、列(FALSE)还是按行和列总结为 1(NA)报告分类变量的百分比。默认值为 FALSE,表示按列报告百分比(在组内)。
-
chisq.test.perm: 逻辑值。它应用排列卡方检验(
chisq.test),而不是精确的 Fisher 检验(fisher.test)。这仅适用于某些单元的预期计数低于 5 的情况。 -
chisq.test.B: 整数。在计算排列卡方检验时的次数。默认值为 2000。
-
chisq.test.seed: 整数或 NULL。进行排列卡方检验的种子。默认值为 NULL,这表示不设置种子。必须输入与 NULL 不同的数字,以便在执行排列卡方检验时重现结果。
-
date.format: 字符,指示日期的显示方式。默认值为 “d-mon-Y”。有关更多信息,请参见 chron。
-
var.equal: 逻辑值,指示在比较均值时是否考虑相等方差,适用于正态分布变量的多个组。如果为 TRUE,则应用 anova 函数,否则应用 oneway.test。默认值为 TRUE。
-
conf.level: 双精度值,表示均值、中位数、比例或发生率,以及危险、赔率和风险比的置信区间的置信水平。默认值为 0.95。
-
surv: 逻辑值。计算生存(TRUE)还是发生率(FALSE),适用于时间事件行变量。默认值为 FALSE。
-
riskratio: 逻辑值。计算 Odds Ratio(FALSE)还是风险比(TRUE)。默认值为 FALSE。
-
riskratio.method: 指定计算 Odds Ratio 的方法。参见
riskratio参数(来自 epitools 包)。默认值为 “wald”。 -
compute.prop: 逻辑值。计算比例(TRUE)还是百分比(FALSE),适用于分类行变量。默认值为 FALSE。
-
lab.missing: 字符。缺失类别的标签。仅在
include.missing = TRUE时适用。默认值为 “Missing”。 -
p.trend.method: 字符,指示用于趋势 p 值的测试名称。它仅适用于数值非正态变量。可能的值为 “spearman”、“kendall” 或 “cuzick”。默认值为 “spearman”。
详细信息
根据行变量被视为连续正态分布(1)、连续非正态分布(2)或分类变量(3),执行以下描述性统计和检验:
- 正态分布:计算均值、标准差,并进行 t 检验或 ANOVA。
- 非正态分布:计算中位数、第 1 和第 3 四分位数(默认),并进行 Kruskal-Wallis 检验。
- 分类变量:计算绝对频率和相对频率,并在某些单元格的期望频率小于 5 时进行卡方检验或精确 Fisher 检验。
此外,行变量可以是 Surv 类。此时,计算在固定时间(通过 timemax 参数设置)下的"事件"概率,并进行 logrank 检验。
当组数超过 2 时,还会执行成对比较,调整多重检验(当行变量为正态分布时使用 Tukey 方法,否则使用 Benjamini & Hochberg 方法),并计算趋势的 p 值。对于正态分布的行变量,趋势的 p 值通过 Pearson 检验计算;对于连续非正态分布的变量,使用 Spearman 检验计算趋势的 p 值。此外,对于连续非正态分布的变量,可以使用 Kendall 检验(method='kendall' 来自 cor.test)或 Cuzick 检验(cuzickTest)计算趋势的 p 值。如果行变量为 Surv 类,则从 Cox 模型中计算得分检验,其中分组变量作为整数变量预测因子引入。如果行变量为分类变量,则通过 Mantel-Haenszel 趋势检验计算趋势的 p 值。
如果有两个组,将为每个行变量计算 Odds Ratio 或 Risk Ratio。而如果响应是 Surv 类(即时间到事件),则计算 Hazard Ratios。当 x 变量为因子时,使用 epitools 包中的 oddsratio 和 riskratio 分别计算 Odds Ratio 和 Risk Ratio。当 x 变量为连续变量时,在具有典型链接和对数链接的逻辑回归下计算 Odds Ratio 和 Risk Ratio。对于 Hazard Ratios 的 p 值,在行变量为分类或连续时,分别通过 logrank 检验或 Wald 检验计算。
示例
require(compareGroups)
require(survival)# 加载 REGICOR 数据
data(regicor)# 计算心血管事件的时间变量
regicor$tcv <- with(regicor, Surv(tocv, as.integer(cv=='Yes')))
attr(regicor$tcv,"label")<-"Cardiovascular"# 计算总体死亡时间变量
regicor$tdeath <- with(regicor, Surv(todeath, as.integer(death=='Yes')))
attr(regicor$tdeath,"label") <- "Mortality"# 按性别计算描述性统计
res <- compareGroups(sex ~ .-id-tocv-cv-todeath-death, data = regicor)
summary(res)# 单变量绘图
## plot(res)# 性别分层的所有行变量的绘图
## plot(res, bivar = TRUE)# 更新响应变量为心血管事件的时间
## update(res, tcv ~ . + sex- tdeath- tcv)4、compareSNPs–按组描述遗传统计数据
描述
该函数提供了您 SNP 数据的广泛摘要范围,使您能够对基因分型结果进行深入的质量控制,并在分析之前探索数据。摘要指标包括等位基因和基因型频率及计数、缺失率、哈迪-温伯格平衡等,可以在整个数据集或按其他变量(如病例对照状态)进行分层。它还可以测试组间缺失率的差异。
用法
compareSNPs(formula, data, subset, na.action = NULL, sep = "", verbose = FALSE, ...)
-
formula: 一个"公式"类对象(或可以转换为该类的对象)。
~的右侧必须以加法方式包含项,这些项必须引用data中的变量,并且必须是字符或因子类,其级别是以其水平写出的基因型(例如,A/A、A/T 和 T/T)。~的左侧必须包含分组变量的名称,或者可以留空(在这种情况下,将为整个样本提供摘要数据,并且不进行缺失性检验)。 -
data: 一个可选的数据框、列表或环境(或可以通过
as.data.frame转换为数据框的对象),包含模型中的变量。如果在data中找不到它们,则从environment(formula)中获取变量。 -
subset: 一个可选的向量,指定用于计算过程的个体子集(适用于所有遗传变量)。
-
na.action: 一个指示数据中包含 NAs 时应采取何种措施的函数。默认值为 NULL,相当于
na.pass,意味着不采取任何措施。na.exclude对于希望删除任何变量中有缺失值的所有个体时可能会很有用。 -
sep: 字符串,指示等位基因之间的分隔符(例如,当使用 A/A、A/T 和 T/T 基因型编码时,
sep应设置为/。默认值为 “”,表示基因型编码为 AA、AT 和 TT。 -
verbose: 逻辑值,打印 HWChisq 函数的结果。默认值为 FALSE。
-
…: 目前被忽略的参数。
示例
require(compareGroups)# load example data
data(SNPs)# visualize first rows
head(SNPs)# select casco and all SNPs
myDat <- SNPs[,c(2,6:40)]# QC of three SNPs by groups of cases and controls
res<-compareSNPs(casco ~ .-casco, myDat)
res# QC of three SNPs of the whole data set
res<-compareSNPs( ~ .-casco, myDat)
res5、createTable–分组描述表:二元表
描述
这个函数用分组的描述构建一个"紧凑"和"漂亮"的表。
用法
createTable(x, hide = NA, digits = NA, type = NA, show.p.overall = TRUE,show.all, show.p.trend, show.p.mul = FALSE, show.n, show.ratio =FALSE, show.descr = TRUE, show.ci = FALSE, hide.no = NA, digits.ratio = NA,show.p.ratio = show.ratio, digits.p = 3, sd.type = 1, q.type = c(1, 1),extra.labels = NA, all.last = FALSE, lab.ref = "Ref.", stars = FALSE)参数
-
x: 一个 “compareGroups” 类对象。
-
hide: 一个向量(或列表),包含与行变量数量相同的整数或字符。如果其长度为 1,则对所有行变量进行回收。每个组件指定必须隐藏且不显示的类别(如果是字符,则为类别的文字名称;如果是整数,则为位置)。此参数仅适用于分类行变量,对于连续行变量将被忽略。如果为 NA,则显示所有类别。或者是一个命名向量(或命名列表),指定应用于哪些行变量的 ‘hide’,其余行变量应用默认值。默认值为 NA。
-
digits: 一个整数向量,其组件数量与行变量相同。如果其长度为 1,则对所有行变量进行回收。每个组件指定要显示的有效小数位数。或者是一个命名向量,指定 ‘digits’ 应用于哪些行变量(一个保留名称是 ‘.else’,定义其余变量的 ‘digits’);如果没有定义 ‘.else’ 变量,则对其余变量应用默认值。默认值为 NA,表示使用"适当"的小数位数(详细信息请参见说明文档)。
-
type: 一个整数,指示是否显示绝对和/或相对频率:1 - 仅相对频率;2 或 NA - 绝对和相对频率(以括号显示);3 - 仅绝对频率。
-
show.p.overall: 逻辑值,指示是否显示整体组显著性(‘p.overall’ 列)的 p 值。默认值为 TRUE。
-
show.all: 逻辑值,指示是否显示 ‘[ALL]’ 列(未按组分层的所有数据)。如果定义了分组变量,则默认值为 FALSE;如果没有组,则为 FALSE。
-
show.p.trend: 逻辑值,指示是否显示 p-trend。如果组少于 3,则始终为 FALSE。如果缺少此参数且组数超过 2 且分组变量为有序因子,则显示 p-trend。默认情况下,p-trend 不显示;当组数超过 2 且分组变量为有序因子类时显示。
-
show.p.mul: 逻辑值,指示是否显示成对(组间)比较的 p 值。组数少于 3 时始终为 FALSE。默认值为 FALSE。
-
show.n: 逻辑值,指示是否在 ‘descr’ 表中显示每个行变量分析的个体数量。默认值为 FALSE,当没有组时为 TRUE。
-
show.ratio: 逻辑值,指示是否显示 OR / HR。默认值为 FALSE。
-
show.descr: 逻辑值,指示是否显示描述性统计(即均值、比例等)。默认值为 TRUE。
-
show.ci: 逻辑值,指示是否显示均值、中位数、比例或发生率的置信区间。如果是,则显示在方括号之间。默认值为 FALSE。
-
hide.no: 字符,指定要隐藏的名称级别,适用于所有具有 2 个类别的分类变量。大小写不敏感。结果是该变量只显示名称而不显示类别。这对是/否变量尤其有用。对于 ‘hide’ 参数不同于 NA 的分类行变量将被忽略。默认值为 NA,表示不隐藏任何类别。
-
digits.ratio: 与 ‘digits’ 参数相同,但适用于风险比或赔率比。
-
show.p.ratio: 逻辑值,指示是否显示与每个风险比/赔率比对应的 p 值。
-
digits.p: 整数,指示所有 p 值显示的小数位数。默认值为 3。
-
sd.type: 一个整数,指示标准偏差的显示方式:1 - 均值(SD),2 - 均值 ± SD。
-
q.type: 一个包含两个整数的向量。第一个组件指非正态行变量显示的括号类型(1 - 方形,2 - 圆形),第二个组件指百分位数分隔符(1 - ‘;’,2 - ‘,’,3 - ‘-’)。默认值为 c(1, 1)。
-
extra.labels: 字符向量,包含 4 个组件,对应于附加到正常、非正态、分类或生存行变量标签的关键标签。默认值为 NA,不附加任何额外关键字。如果设置为 c(“”,“”,“”,“”),则附加"Mean (SD)"、“Median [25th; 75th]”、“N (%)” 和 “Incidence at time=timemax”(请参阅 compareGroups 函数中的 timemax 参数)。
-
all.last: 逻辑值。整个样本的描述性统计放在按组描述性统计之后。默认值为 FALSE,表示整体队列的描述性统计放在第一位。
-
lab.ref: 字符。参考类别的显示字符串。默认值为 “Ref.”。
-
stars: 逻辑值,指示是否在 p 值旁边附加星号;‘**’:p 值 < 0.05,‘*’ 0.05 <= p 值 < 0.1;“” p 值 >= 0.1。默认值为 FALSE。
-
which.table: 字符,指示打印哪个表。可能的值为 ‘descr’、‘avail’ 或 ‘both’(允许部分匹配),分别打印按组描述性统计表、可用数据表或两个表。默认值为 ‘descr’。
-
nmax: 逻辑值,指示是否显示所有行变量中至少具有一个有效值的主题数量。默认值为 TRUE。
-
nmax.method: 整数,有两个可能的值:1 - 在至少一个行变量中具有有效值的观察数量;2 - 数据集或组中的总观察数量或行数。默认值为 1。
-
header.labels: 一个命名字符向量,包含 ‘all’、‘p.overall’、‘p.trend’、‘ratio’、‘p.ratio’ 和 ‘N’ 组件,指示 ‘[ALL]’、‘p.overall’、‘p.trend’、‘ratio’、‘p.ratio’ 和 ‘N’(可用数据)的标签。默认值为零长度向量,不做更改,即 ‘[ALL]’、‘p.overall’、‘p.trend’、‘ratio’、‘p.ratio’ 和 ‘N’ 标签显示在整个队列的描述性统计、全局 p 值、趋势的 p 值、HR/OR 和每个 HR/OR 的 p 值以及可用数据中。
-
…: 传递给 print.default 的其他参数。
示例
# 加载所需的包
require(compareGroups)
require(survival)# 加载 REGICOR 数据
data(regicor)# 计算心血管事件的时间变量
regicor$tcv <- with(regicor, Surv(tocv, as.integer(cv == 'Yes')))
attr(regicor$tcv, "label") <- "Cardiovascular incidence"# 根据心血管事件的时间计算描述性统计,以 'no' 类别作为参考来计算 HR。
res <- compareGroups(tcv ~ age + sex + smoker + sbp + histhtn + chol + txchol + bmi + phyact + pcs + tcv, regicor, ref.no = 'no')# 构建显示 HR 的表格,并隐藏 'no' 类别
restab <- createTable(res, show.ratio = TRUE, hide.no = 'no')
restab # 打印可用信息表# 进行总结
summary(restab) # 更多...## 不运行的代码:
# 添加 '可用数据' 列
update(restab, show.n = TRUE)# 整个队列的描述性统计
update(restab, x = update(res, ~ .))# 将响应变量更改为性别
# 显示比值比(OR)而不是风险比(HR)。
# 请注意,现在可以计算按死亡时间或心血管事件时间的描述性统计,但不能计算 OR。
# 将 timemax 设置为 5 年,以报告 5 年的死亡概率和心血管事件概率:
update(restab, x = update(res, sex ~ . - sex + tdeath + tcv, timemax = 5 * 365.25))## 组合表格:
# a) 按行:将前四个变量作为一组,其余变量作为另一组:
rbind("First group of variables" = restab[1:4], "Second group of variables" = restab[5:length(res)])# b) 按列:将按性别分层的表格并排放置:
res1 <- compareGroups(year ~ . - id - sex, regicor)
restab1 <- createTable(res1, hide.no = 'no')
restab2 <- update(restab1, x = update(res1, subset = sex == 'Male'))6、createTable–执行描述并构建二元表
描述
这个函数一步构建一个双变量表,调用compareGroups和createTable函数。
用法
descrTable(formula,data,subset,na.action = NULL,y = NULL,Xext = NULL,selec = NA,method = 1,timemax = NA,alpha = 0.05,min.dis = 5,max.ylev = 5,max.xlev = 10,include.label = TRUE,Q1 = 0.25,Q3 = 0.75,simplify = TRUE,ref = 1,ref.no = NA,fact.ratio = 1,ref.y = 1,p.corrected = TRUE,compute.ratio = TRUE,include.miss = FALSE,oddsratio.method = "midp",chisq.test.perm = FALSE,byrow = FALSE,chisq.test.B = 2000,chisq.test.seed = NULL,Date.format = "d-mon-Y",var.equal = TRUE,conf.level = 0.95,surv = FALSE,riskratio = FALSE,riskratio.method = "wald",compute.prop = FALSE,lab.missing = "'Missing'",p.trend.method = "spearman",hide = NA,digits = NA,type = NA,show.p.overall = TRUE,show.all,show.p.trend,show.p.mul = FALSE,show.n,show.ratio = FALSE,show.descr = TRUE,show.ci = FALSE,hide.no = NA,digits.ratio = NA,show.p.ratio = show.ratio,digits.p = 3,sd.type = 1,q.type = c(1, 1),extra.labels = NA,all.last = FALSE,lab.ref = "Ref.",stars = FALSE
)- …: 参数均同 compareGroups 和 createTabel。
示例
require(compareGroups) # load REGICOR data
data(regicor) # perform descriptives by year and build the table.
# note the use of arguments from compareGroups (formula and data set) and
# arguments from createTable (hide.no and show.p.mul)
descrTable(year ~ ., regicor, hide.no="no", show.p.mul=TRUE)
7、export2csv–将描述表导出为纯文本(CSV)格式
描述
该函数接受createTable的结果,并将表导出为纯文本(CSV)格式。
用法
export2csv(x, file, which.table="descr", sep=",", nmax = TRUE, nmax.method = 1, header.labels = c(), ...)
-
x: 一个 ‘createTable’ 类的对象。
-
file: 将以 CSV 格式写入的文件。此外,还会写入一个扩展名为 ‘_appendix’ 的文件,其中包含可用数据表。
-
which.table: 字符,指示打印哪个表。可能的值为 ‘descr’、‘avail’ 或 ‘both’(允许部分匹配),分别导出按组的描述性统计表、可用数据表或两个表。默认值为 ‘descr’。
-
sep: 字符。变量分隔符,与
write.table的sep参数相同。默认值为 ‘,’。 -
nmax: 逻辑值,指示是否显示在所有行变量中至少有一个有效值的受试者数量。默认值为 TRUE。
-
nmax.method: 整数,具有两个可能的值:1- 在至少一个行变量中具有有效值的观察数量;2- 数据集或组中的观察总数或行数。默认值为 1。
-
header.labels: 参见
createTable的header.labels参数。 -
…: 其他传递给
write.table的参数。
示例
require(compareGroups)
data(regicor)
res <- compareGroups(sex ~.-id-todeath-death-tocv-cv, regicor)
export2csv(createTable(res, hide.no = 'n'), file=tempfile(fileext=".csv"))
8、export2html–导出描述表为HTML格式
描述
该函数接受createTable的结果,并将表导出为HTML格式。
用法
export2html(x, file, which.table="descr", nmax = TRUE, nmax.method = 1, header.labels = c(), ...)
-
x: 一个 ‘createTable’ 类的对象。
-
file: 将以 HTML 格式写入的文件。此外,还会写入一个扩展名为 ‘_appendix’ 的文件,其中包含可用数据表。如果缺失,将返回 HTML 代码。
-
which.table: 字符,指示打印哪个表。可能的值为 ‘descr’、‘avail’ 或 ‘both’(允许部分匹配),分别导出按组的描述性统计表、可用数据表或两个表。默认值为 ‘descr’。
-
nmax: 逻辑值,指示是否显示在所有行变量中至少有一个有效值的受试者数量。默认值为 TRUE。
-
nmax.method: 整数,具有两个可能的值:1- 在至少一个行变量中具有有效值的观察数量;2- 数据集或组中的观察总数或行数。默认值为 1。
-
header.labels: 参见
createTable的header.labels参数。 -
…: 当前被忽略的其他参数。
示例
require(compareGroups)
data(regicor)
res <- compareGroups(sex ~.-id-todeath-death-tocv-cv, regicor)
export2html(createTable(res, hide.no = 'n'), file=tempfile(fileext=".html"))
9、export2latex–导出描述表为LaTeX格式
描述
这个函数接受createTable的结果,并将表导出为LaTeX格式。
用法
export2latex(x, ...)
## S3 method for class 'createTable'
export2latex(x, file, which.table = 'descr', size = 'same', nmax = TRUE, nmax.method = 1, header.labels = c(), caption = NULL, loc.caption = 'top', label = NULL, landscape = NA, colmax = 10, ...)
## S3 method for class 'cbind.createTable'
export2latex(x, file, which.table = 'descr', size = 'same', nmax = TRUE, nmax.method = 1, header.labels = c(), caption = NULL, loc.caption = 'top', label = NULL, landscape = NA, colmax = 10, ...)
-
x: 一个 ‘createTable’ 类的对象。
-
file: 要保存结果代码的文件名称。如果文件缺失,则输出将在屏幕上显示。此外,还会写入一个扩展名为 ‘_appendix’ 的文件,其中包含可用数据表。
-
which.table: 字符,指示导出哪个表。可能的值为 ‘descr’、‘avail’ 或 ‘both’(允许部分匹配),分别导出按组的描述性统计表、可用数据表或两个表。默认值为 ‘descr’。
-
size: 字符,指示表元素的大小。可能的值有:‘tiny’、‘scriptsize’、‘footnotesize’、‘small’、‘normalsize’、‘large’、‘Large’、‘LARGE’、‘huge’、‘Huge’ 或 ‘same’(允许部分匹配)。默认值为 ‘same’,表示表的字体大小与主 LaTeX 文档中指定的相同。
-
nmax: 逻辑值,指示是否显示在所有行变量中至少有一个有效值的受试者数量。默认值为 TRUE。
-
nmax.method: 整数,具有两个可能的值:1- 在至少一个行变量中具有有效值的观察数量;2- 数据集或组中的观察总数或行数。默认值为 1。
-
header.labels: 参见
createTable的header.labels参数。 -
caption: 字符,指定描述性统计和可用数据表的标题。如果
which.table='both',则caption的第一个元素将分配给描述性表,第二个元素分配给可用数据表。如果设置为 “”,则不插入标题。默认值为 NULL,将为描述性表写入 'Summary descriptives table by groups of ‘y’,为可用数据表写入 'Available data by groups of ‘y’。 -
label: 字符,指定描述性统计和可用数据表的标签。这在 LaTeX 文档的其他地方引用表格时可能很有用。如果
which.table='both',则label的第一个元素将分配给描述性表,第二个元素分配给可用数据表。默认值为 NULL,不会为表格分配标签。 -
loc.caption: 字符,指定表格标题的位置。可能的值为 ‘top’ 或 ‘bottom’(允许部分匹配)。默认值为 ‘top’。
-
landscape: 逻辑值,指示表格是否应放置为横向,或者 NA,当列数超过 ‘colmax’ 时将表格放置为横向。默认值为 NA。
-
colmax: 整数,指示最大列数,以便表格不放置为横向。此参数仅在 ‘landscape’ 参数为 NA 时适用。默认值为 10。
-
…: 当前被忽略的其他参数。
示例
require(compareGroups)
data(regicor)
res <- compareGroups(sex ~.-id-todeath-death-tocv-cv, regicor)
export2latex(createTable(res, hide.no = 'n'), file=tempfile(fileext=".tex"))
10、export2md–导出描述表为Markdown格式
描述
该函数接受createTable的结果,并将表导出为markdown格式。当在Markdown文件(. rmd)中插入R代码块时,它可能很有用。
用法
export2md(x, which.table = "descr", nmax = TRUE, nmax.method = 1, header.labels = c(), caption = NULL, format = "html", width = Inf, strip = FALSE, first.strip = FALSE, background = "#D2D2D2", size = NULL, landscape=FALSE, header.background=NULL, header.color=NULL, position="center", ...)
-
x: 一个 ‘createTable’ 类的对象。
-
which.table: 字符,指示打印哪个表。可能的值为 ‘descr’ 或 ‘avail’(允许部分匹配),分别导出按组的描述性统计表或可用数据表。默认值为 ‘descr’。
-
nmax: 逻辑值,指示是否显示在所有行变量中至少有一个有效值的受试者数量。默认值为 TRUE。
-
nmax.method: 整数,具有两个可能的值:1- 在至少一个行变量中具有有效值的观察数量;2- 数据集或组中的观察总数或行数。默认值为 1。
-
header.labels: 参见
createTable的header.labels参数。 -
caption: 字符,指定描述性统计和可用数据表的标题。如果
which.table='both',则caption的第一个元素将分配给描述性表,第二个元素分配给可用数据表。如果设置为 “”,则不插入标题。默认值为 NULL,将为描述性表写入 'Summary descriptives table by groups of ‘y’,为可用数据表写入 'Available data by groups of ‘y’。 -
export2md: 字符,具有三个选项:‘html’、‘latex’ 或 ‘markdown’。如果缺失,它会尝试猜测插入表的 Rmarkdown 文件的默认选项,或者如果不在 Rmarkdown 文件中或格式未指定,则为 html。
-
width: 字符串,指定描述性表第一列的宽度。导出到 Word 时会被忽略。默认值为 Inf,这使得第一列自动调整为变量名称。其他示例有 ‘10cm’、‘3in’ 或 ‘30em’。
-
strip: 逻辑值。它阴影每个变量对应的表线。
-
first.strip: 逻辑值。它确定是阴影第一个变量(TRUE)还是第二个变量(FALSE)。它仅在
strip参数为 true 时适用。 -
background: 颜色代码,以 HEX 格式表示阴影线的颜色。您可以使用 rgb 函数将红色、绿色和蓝色转换为 HEX 代码。默认颜色为 ‘#D2D2D2’。
-
size: 数字。描述性表的大小。默认值为 NULL,这会创建默认大小的表。
-
landscape: 逻辑值。它确定是否将表格放置为横向(水平)格式。它仅在格式为 ‘latex’ 时适用。默认值为 FALSE。
-
header.background: 字符,用于表头的颜色或 ‘NULL’。默认值为 ‘NULL’。
-
header.color: 表头文本的颜色。默认颜色为 ‘NULL’。
-
position: 字符,指定表格位置。可能的值为 ‘left’、‘center’、‘right’、‘float_left’ 和 ‘float_right’。它仅在编译为 HTML 或 PDF 时适用。默认值为 ‘center’。有关更多信息,请参见
kable_styling的 position 参数。 -
…: 传递给 kable 的其他参数。
示例
---
title: "Report"
output: html_document: default
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = FALSE, warning=FALSE, message=FALSE)
``````{r}
library(compareGroups)
data(regicor)
res <- compareGroups(year~., regicor)
restab <- createTable(res)
```
## Report section
The following table contains descriptives of **REGICOR** data ```{r}
export2md(restab, strip = TRUE, first.strip = TRUE)
```
11、export2pdf–将表格导出为PDF文件
描述
这个函数会自动创建一个带有表格的PDF。另外,LaTeX代码存储在指定的文件中。
用法
export2pdf(x, file, which.table="descr", nmax=TRUE, header.labels=c(), caption=NULL, width=Inf, strip=FALSE, first.strip=FALSE, background="#D2D2D2", size=NULL, landscape=FALSE, numcompiled=2, header.background=NULL, header.color=NULL)
-
x: 一个 ‘createTable’ 类的对象或其子类。
-
file: 字符,指定编译 LaTeX 代码后生成的 PDF 文件。相应的 LaTeX 代码也会保存在同一文件夹中,并以 .tex 扩展名存储。当 ‘compile’ 参数为 FALSE 时,仅保存 .tex 文件。
-
which.table: 字符,指示打印哪个表。可能的值为 ‘descr’、‘avail’ 或 ‘both’(允许部分匹配),分别打印按组的描述性统计表、可用数据表或两个表。默认值为 ‘descr’。
-
nmax: 逻辑,指示是否显示至少在一个行变量中具有有效值的受试者数量。默认值为 TRUE。
-
header.labels: 一个字符命名向量,包含 ‘all’、‘p.overall’、‘p.trend’、‘ratio’、‘p.ratio’ 和 ‘N’ 组件,指示标签分别为 ‘[ALL]’、‘p.overall’、‘p.trend’、‘ratio’、‘p.ratio’ 和 ‘N’(可用数据)。默认值为零长度向量,这意味着不做任何更改。
-
caption: 字符,指定描述性和可用数据表的标题。如果 which.table=‘both’,则 ‘caption’ 的第一个元素将分配给描述性表,第二个元素分配给可用数据表。如果设置为 “”,则不插入标题。默认值为 NULL。
-
width: 字符串,指定描述性表第一列的宽度。默认值为 Inf,意味着第一列自动调整到变量名称。其他示例包括 ‘10cm’、‘3in’ 或 ‘30em’。
-
strip: 逻辑。它影藏每个变量对应的表格线。
-
first.strip: 逻辑。它确定是否影藏第一个变量(TRUE)或第二个变量(FALSE)。仅在 strip 参数为真时适用。
-
background: HEX 格式的颜色代码,用于阴影线。默认颜色为 ‘#D2D2D2’。
-
size: 数字。描述性表的大小。默认值为 NULL,表示以默认大小创建表。
-
landscape: 逻辑。它决定是否以横向格式放置表格。仅在格式为 ‘latex’ 时适用。默认值为 FALSE。
-
numcompiled: 整数。LaTeX 代码编译的次数。默认编译两次。
-
header.background: 表头的颜色字符或 ‘NULL’。默认值为 ‘NULL’。
-
header.color: 表头文本的颜色字符。默认颜色为 ‘NULL’。
示例
require(compareGroups)
data(regicor)
# example on an ordinary table
res <- createTable(compareGroups(year ~ . -id, regicor), hide = c(sex=1), hide.no = 'no')
export2pdf(res, file=tempfile(fileext=".pdf"), size="small")12、export2word–将表格导出为WORD文件
描述
这个函数用表格自动创建一个Word文件。
用法
export2word(x, file, which.table="descr", nmax=TRUE, header.labels=c(),caption=NULL, strip=FALSE, first.strip=FALSE, background="#D2D2D2",size=NULL, header.background=NULL, header.color=NULL)
-
x: 一个 ‘createTable’ 类的对象或其子类。
-
file: 字符,指定编译相应的 Markdown 代码后生成的 Word 文件 (.doc 或 .docx)。
-
which.table: 字符,指示打印哪个表。可能的值为 ‘descr’ 或 ‘avail’(允许部分匹配),分别导出按组的描述性统计表或可用数据表。默认值为 ‘descr’。
-
nmax: 逻辑,指示是否显示至少在一个行变量中具有有效值的受试者数量。默认值为 TRUE。
-
header.labels: 参见 ‘createTable’ 的 ‘header.labels’ 参数。
-
caption: 字符,指定描述性和可用数据表的标题。如果 which.table=‘both’,则 ‘caption’ 的第一个元素将分配给描述性表,第二个元素分配给可用数据表。如果设置为 “”,则不插入标题。默认值为 NULL。
-
strip: 逻辑。它影藏每个变量对应的表格线。
-
first.strip: 逻辑。它确定是否影藏第一个变量(TRUE)或第二个变量(FALSE)。仅在 strip 参数为真时适用。
-
background: HEX 格式的颜色代码,用于阴影线。默认颜色为 ‘#D2D2D2’。
-
size: 数字。描述性表的大小。默认值为 NULL,表示以默认大小创建表。
-
header.background: 表头的颜色字符或 ‘NULL’。默认值为 ‘NULL’。
-
header.color: 表头文本的颜色字符。默认颜色为 ‘NULL’。
示例
require(compareGroups)
data(regicor)# example on an ordinary table
res <- createTable(compareGroups(year ~ . -id, regicor), hide = c(sex=1), hide.no = 'no')
export2word(res, file = tempfile(fileext=".docx"))13、export2xls–将描述表导出为excel格式(.xlsx或.xls)
描述
该函数接受createTable的结果,并将表导出为Excel格式(.xlsx或.xls)。
用法
export2xls(x, file, which.table="descr", nmax=TRUE, nmax.method=1, header.labels=c())
-
x: 一个 ‘createTable’ 类的对象。
-
file: 文件,指定将以 Excel 格式写入的表格。
-
which.table: 字符,指示打印哪个表。可能的值为 ‘descr’、‘avail’ 或 ‘both’(允许部分匹配),分别导出按组的描述性统计表、可用数据表或两个表格。在后者的情况下(‘both’),将生成两个工作表,每个表对应一个。默认值为 ‘descr’。
-
nmax: 逻辑,指示是否显示至少在一个行变量中具有有效值的受试者数量。默认值为 TRUE。
-
nmax.method: 整数,有两个可能的值:1-表示在至少一个行变量中具有有效值的观察数量;2-数据集或组中的观察总数或行数。默认值为 1。
-
header.labels: 参见 ‘createTable’ 的 ‘header.labels’ 参数。
示例
require(compareGroups)
data(regicor)
res <- compareGroups(sex ~. -id-todeath-death-tocv-cv, regicor)
export2xls(createTable(res, hide.no = 'n'), file=tempfile(fileext=".xlsx"))
14、getResults–轻松检索作为r对象(矩阵和向量)的汇总数据
描述
这个函数从一个compareGroups对象中提取特定的结果(描述、p值、比值/风险比等)作为矩阵或向量。
用法
getResults(obj, what = "descr")
-
obj: 一个 ‘compareGroups’ 或 ‘createTable’ 类的对象。
-
what: 字符,指示要检索的结果类型:描述性统计、p 值、趋势 p 值、成对 p 值,或比值比/风险比。可能的值为:“descr”、“p.overall”、“p.trend”、“p.mul” 和 “ratio”。默认值为 “descr”。
-
what = “descr”: 一个数组或矩阵,列数等于变量/类别数量,七列对应所有可能的描述性统计(均值、标准差、中位数、Q1、Q3、绝对和相对频率)。当分析不同组时,数组的第三维对应组;否则,结果将是没有第三维的矩阵。
-
what = “p.overall”: 一个向量,其元素为每个分析变量的 p 值。
-
what = “p.trend”: 一个向量,其元素为每个分析变量的趋势 p 值。
-
what = “p.mul”: 一个矩阵,包含成对 p 值,行对应分析变量,列对应每对组。
-
what = “ratio”: 一个矩阵,行数等于变量/类别数量,四列对应比值比/风险比、置信区间和 p 值。
示例
require(compareGroups)
data(regicor)
res<-compareGroups(sex ~ . ,regicor,method=c(triglyc=2))
# retrieve descriptives
getResults(res)
# retrieve OR and their corresponding p-values
getResults(res,what="ratio")
15、missingTable–失踪者分组统计表
描述
该函数返回一个表,其中包含已构建的二元表中不可用的频率。
用法
missingTable(obj,...)
-
obj: 一个 ‘compareGroups’ 或 ‘createTable’ 类的对象。
-
…: 传递给 createTable 的其它参数。
示例
require(compareGroups)
# load regicor data
data(regicor)
# table of descriptives by recruitment year
res <- compareGroups(year ~ age + sex + smoker + sbp + histhtn +
chol + txchol + bmi + phyact + pcs + death, regicor)
restab <- createTable(res, hide.no = "no")
# missingness table
missingTable(restab,type=1)
## Not run:
# also create the missing table from a compareGroups object
miss <- missingTable(res)
miss
# some methods that works for createTable objects also works for objects
# computed by missTable function.
miss[1:4]
varinfo(miss)
plot(miss)
#... but update methods cannot be applied (this returns an error).
update(miss,type=2)
## End(Not run)
16、padjustCompareGroups–根据多次比较更新p值
描述
给定一个compareGroups对象,返回使用以下方法之一调整的p值(stats::p.adjust)
用法
padjustCompareGroups(object_compare, p = "p.overall", method = "BH")
-
object_compare: 一个 ‘compareGroups’ 类的对象。
-
p: 字符串,指定需要校正的 p 值。可能的值为 ‘p.overall’ 和 ‘p.trend’(默认值为 ‘p.overall’)。
-
method: 校正方法,字符串。可以使用简写形式(参见
p.adjust函数)。
示例
# Define simulated data
set.seed(123)
N_obs<-100
N_vars<-50
data<-matrix(rnorm(N_obs*N_vars), N_obs, N_vars)
sim_data<-data.frame(data,Y=rbinom(N_obs,1,0.5))# Execute compareGroups
res<-compareGroups(Y~.,data=sim_data)
res# update p values
res_adjusted<-padjustCompareGroups(res)
res_adjusted# update p values using FDR method
res_adjusted<-padjustCompareGroups(res, method ="fdr")
res_adjusted
17、printTable–“漂亮的”表格
描述
这个函数以“nice”格式在控制台上打印一个表。
用法
printTable(obj, row.names = TRUE, justify = 'right')
-
obj: 一个 ‘data.frame’ 或 ‘matrix’ 类的对象。它必须至少包含两列,第一列被视为 ‘row.names’ 并且左对齐(如果 ‘row.names’ 参数设置为 TRUE),而其余列右对齐。
-
row.names: 逻辑值,指示第一列或变量是否作为 ‘row.names’ 列处理并且必须左对齐。默认值为 TRUE。
-
justify: 字符串,类似于
format函数的 ‘justify’ 参数。当 ‘row.names’ 参数为 FALSE 时,应用于整个数据框或矩阵的所有列;否则,应用于除第一列之外的所有列。默认值为 ‘right’。
示例
require(compareGroups)
data(regicor)# example of the coefficients table from a linear regression
model <- lm(chol ~ age + sex + bmi, regicor)
results <- coef(summary(model))
results <- cbind(Var = rownames(results), round(results, 4))
printTable(results)# or visualize the first rows of the iris data frame.
# In this example, the first column is not treated as a row.names column and it is right justified.
printTable(head(iris), FALSE)# the same example with columns centered
printTable(head(iris), FALSE, 'centre')
18、radiograph–列出数据集中的值
描述
此函数创建数据集中原始数据的报告。对于每个变量,一个唯一条目的有序列表(作为字符串读取),用于检查输入错误。
用法
radiograph(file, header = TRUE, save=FALSE, out.file="", ...)
-
file: 字符串,指定数据集所在的文件。
-
header: 参见
read.table的header参数。 -
save: 逻辑值,指示输出是应存储在文件中 (TRUE) 还是打印在控制台上 (FALSE)。默认值为 FALSE。
-
out.file: 字符串,指定结果要输出的文件。仅当
save参数设置为 TRUE 时适用。 -
…: 传递给
read.table的其他参数。
示例
## Not run:
require(compareGroups)
# read example data of regicor in plain text format with variables separated by '\t'.
datafile <- system.file("exdata/regicor.txt", package="compareGroups")
radiograph(datafile)
## End(Not run)
19、regicor–REGICOR横断面数据
描述
这些数据来自西班牙西北部赫罗纳省REGICOR研究中对具有代表性的个人进行的3次不同的横断面调查。
用法
data(regicor)
20、report–描述性表格和图的报告
描述
该函数自动创建一个PDF,其中包含描述性表以及可用性数据和所有图。该文件的结构和索引方式使用户可以浏览文档中的所有表格和图形。
用法
report(x, file, fig.folder, compile = TRUE, openfile = FALSE, title = "Report",author, date, perc=FALSE, ...)-
x: 一个 ‘createTable’ 类的对象。
-
file: 字符串,指定在编译 LaTeX 代码后生成的 PDF 文件。LaTeX 代码也存储在同一文件夹中,扩展名为 .tex。如果
compile参数为 FALSE,仅保存 .tex 文件。 -
fig.folder: 字符串,指定放置表格中所有行变量对应的图形的文件夹。如果省略,将在
file文件的相同文件夹中创建一个名为file_figures的文件夹。 -
compile: 逻辑值,指示是否使用
texi2pdf函数编译 .tex 文件。默认值为 TRUE。 -
openfile: 逻辑值,指示是否打开已编译的 PDF 文件。目前已弃用,默认值为 FALSE。
-
title: 字符串,指定封面上的报告标题。默认值为 “Report”。
-
author: 字符串,指定封面上的作者姓名。当省略时,封面上不显示作者姓名。
-
date: 字符串,指定封面上的报告日期。当省略时,显示当前日期。
-
perc: 逻辑值,指示是否在条形图中为分类变量显示相对频率(百分比)而不是绝对频率。
-
…: 传递给
export2latex的其他参数。
示例
## Not run:
require(compareGroups)
data(regicor)
# example on an ordinary table
res <- createTable(compareGroups(year ~ . -id, regicor), hide = c(sex=1), hide.no = 'no')
report(res, "report.pdf" ,size="small", title="\Huge \textbf{REGICOR study}",author="Isaac Subirana \\ IMIM-Parc de Salut Mar")
# example on an stratified table by sex
res.men <- createTable(compareGroups(year ~ . -id-sex, regicor, subset=sex=='Male'),
hide.no = 'no')
res.wom <- createTable(compareGroups(year ~ . -id-sex, regicor, subset=sex=='Female'),
hide.no = 'no')
res <- cbind("Men"=res.men, "Wom"=res.wom)
report(res[[1]], "reportmen.pdf", size="small",
title="\Huge \textbf{REGICOR study \\ Men}", date="") # report for men / no date
report(res[[2]], "reportwom.pdf", size="small",
title="\Huge \textbf{REGICOR study \\ Women}", date="") # report for wom / no date
## End(Not run)20、SNPs–病例对照研究中的snp
描述
snp数据框架包含病例对照研究中选定的snp和其他病例和对照的临床协变量。
snp .info.pos data.frame包含数据集“snp”中包含的snp的名称,包括它们的染色体和它们的基因组位置。
用法
data(SNPs)
21、strataTable–分层描述表
描述
该函数在由变量定义的层中重新构建描述性表。
用法
strataTable(x, strata, strata.names = NULL, max.nlevels = 5)
-
x: 一个 ‘createTable’ 类的对象。
-
strata: 字符串,指定定义分层的变量名称或该变量的值/水平。
-
strata.names: 字符向量,包含与分层变量相关的名称。如果设置为 NULL(默认值),将使用分层变量水平的名称。
-
max.nlevels: 整数,指定分层变量的最大唯一值或水平数。默认值为 5。
示例
require(compareGroups)
# load REGICOR data
data(regicor)
# compute the descriptive tables (by year)
restab <- descrTable(year ~ . - id - sex, regicor, hide.no="no")
# re-build the table stratifying by gender
strataTable(restab, "sex")
22、varinfo–提取变量名和标签
描述
该函数构建并打印一个包含变量名及其标签的表。
用法
varinfo(x, ...)
## S3 method for class 'compareGroups'
varinfo(x, ...)
## S3 method for class 'createTable'
varinfo(x, ...)
-
x: 一个 ‘compareGroups’ 或 ‘createTable’ 类的对象。
-
…: 其他当前被忽略的参数。
示例
require(compareGroups)
data(regicor)
res<-compareGroups(sex ~ . ,regicor)
#createTable(res, hide.no = 'no')
varinfo(res)
相关文章:

R包compareGroups详细用法
compareGroups compareGroups 是一个功能强大的 R 包,专为数据质量控制、数据探索和生成用于出版的单变量或双变量表格而设计。它能够创建各种格式的报表,如纯文本、HTML、LaTeX、PDF、Word 或 Excel 格式,并显示统计数据(均值、…...

如何选择高品质SD卡
如何选择高品质SD卡 SD卡(Secure Digital Memory Card)是一种广泛使用的存储器件,因其快速的数据传输速度、可热插拔的特性以及较大的存储容量,广泛应用于各种场景,例如在便携式设备如智能手机、平板电脑、运动相机等…...

C++学习:模拟priority_queue
一:仿函数 开始模拟前咱先了解一下仿函数。有了它,我们就可以自己传个代码让优先级队列升序还是降序,自己模拟时也不用在需要升序降序时改代码。这是个很有用的东西。 不写模版也可以,但模版能用在更多地方嘛 template <class …...

同程旅行对标拼多多:“形似神不似”
文:互联网江湖 作者:刘致呈 业绩好,并不意味着同程旅行就能高枕无忧了。 最近,媒体曝出:有用户在同程旅行APP上预订酒店,在预订成功并付款后,结果第二天却被酒店告知,没有查到相关…...

HOJ网站开启https访问 申请免费SSL证书 部署证书详细操作指南
https://console.cloud.tencent.com/ 腾讯云用户 登录控制台 右上角搜SSL 点击 SSL证书 进入链接 点申请 免费证书 有效期3个月 (以后每三个月申请一次证书 上传) 如果是腾讯云申请的域名 选 自动DNS验证 自动添加验证记录 如果是其他平台申请域…...
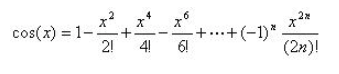
程序设计基础I-实验4 循环结构之for语句
7-1 sdut-C语言实验-AB for Input-Output Practice (Ⅳ) Your task is to Calculate a b. 输入格式: Your task is to Calculate a b. 输出格式: For each pair of input integers a and b you should output the sum of a and b in one line, and with one line of out…...

深入工作流调度的内核
在大数据时代,工作流任务调度系统成为了数据处理和业务流程管理的核心组件,在大数据平台的构建和开发过程中尤为重要。随着数据量的激增和业务需求的多样化,合理的任务调度不仅能够提高资源利用率,还能保证业务流程的稳定和高效运…...

vue3中动态引入组件并渲染组件
在开发中 有时会在打包或者各种可能的情况下 报错或警告提示 模块化打包的问题, 我们需要动态引入组件并渲染组件时,可以使用import引入 如下举例 import { ref, markRaw } from vue const childrenComponent ref(); onMounted(() > {//举例引入一个…...

【艾思科蓝】网络安全的隐秘战场:构筑数字世界的铜墙铁壁
第七届人文教育与社会科学国际学术会议(ICHESS 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看:https://ais.cn/u/nuyAF3 目录 引言 一、网络安全:数字时代的双刃剑 1.1 网络安全的定义与重要性 1.2 网络安全威胁的多元化…...

将图片资源保存到服务器的盘符中
服务类 系统盘符:file-path.disk(可能会变,配置配置文件dev中)文件根路径:file-path.root-path(可能会变,配置配置文件dev中)http协议的Nginx的映射前缀:PrefixConstant.…...

数学建模练习小题目
题目A 有三名商人各带一名仆人过河,船最多能载两人。在河的任何一岸,若仆人数超 过商人数,仆人会杀商人越货。如何乘船由商人决定,问是否有安全过河方案,若有,最少需要几步? 定义变量 商人和仆人的状态…...

不可错过的10款文件加密软件,企业电脑加密文件哪个软件好用
在信息安全日益重要的今天,企业和个人都需要可靠的文件加密软件来保护敏感数据。以下是2024年不可错过的10款文件加密软件,它们以强大的加密功能和易用性而闻名。 1.安秉加密软件 安秉加密软件是一款专为企业设计的信息安全管理工具,采用驱动…...

常用卫星学习
文章目录 Landsat-8 Landsat-8 由一台操作陆地成像仪 (OLI) 和一台热红外传感器 (TIRS)的卫星,OLI 提供 9 个波段,覆盖 0.43–2.29 μm 的波长,其中全色波段(一般指0.5μm到0.75μm左…...

音视频入门基础:FLV专题(3)——FLV header简介
一、引言 本文对FLV格式的FLV header进行简介,FLV文件的开头就是FLV header。 进行简介之前,请各位先从《音视频入门基础:FLV专题(1)——FLV官方文档下载》下载FLV的官方文档《video_file_format_spec_v10_1.pdf》和…...

python中数据处理库,机器学习库以及自动化与爬虫
Python 在数据处理、机器学习和自动化任务方面非常强大,它的库生态系统几乎涵盖了所有相关领域。我们将从以下几个部分来介绍 Python 中最常用的库: 数据处理库:Pandas、NumPy 等机器学习库:Scikit-learn、TensorFlow、Keras 等自…...
2024最新测评:低代码平台在企业复杂应用场景的适用性如何?
低代码平台种类多,不好一概而论。但最近有做部分低代码平台的测评,供大家参考。 一个月前接到老板紧急任务:调研有没有一款低代码平台能开发我司的软件场景。我司是一家快速发展中的制造业企业,业务遍布全国,需要一个…...

URL中 / 作为字符串,而不是路径。
在Harbor中,仓库路径是二级,有时候在打镜像的时候,会把 / 作为字符串打进去,URL访问的时候有可能就当路径了。 解决办法:/ 转义 %252F...

el-input只能输入指定范围的数字
el-input只能输入指定范围的数字 需求:el-input只能输入指定范围的数字,不采用el-input-number组件。 几个关键点如下 v-model.numbertype"number"min"1" max"999999" 数字的范围 οninput"validity.valid ||(value…...

数据结构编程实践20讲(Python版)—01数组
本文目录 01 数组 arrayS1 说明S2 举例S3 问题:二维网格中的最小路径求解思路Python3程序 S4 问题:图像左右变换求解思路Python3程序 S5 问题:青蛙过河求解思路Python3程序 写在前面 数据结构是计算机科学中的一个重要概念,用于组…...
数据库实验2—1
10-1 查询重量在[40,65]之间的产品信息 本题目要求编写SQL语句, 检索出product表中所有符合40 < Weight < 65的记录。 提示:请使用SELECT语句作答。 表结构: CREATE TABLE product (Pid varchar(20), --商品编号PName varchar(50), --商品名称…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...

【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录 A 论文出处B 背景B.1 背景介绍B.2 问题提出B.3 创新点 C 模型结构C.1 指令微调阶段C.2 排名与生成的总和指令微调阶段C.3 RankRAG推理:检索-重排-生成 D 实验设计E 个人总结 A 论文出处 论文题目:RankRAG:Unifying Context Ranking…...