Flink基本概念和算子使用
基础概念
Flink是一个框架和分布式处理引擎,用于对无界数据流和有界数据流进行有状态计算,它的核心目标是“数据流上的有状态计算”。

有界流和无界流
- 有界流:具有明确的开始和结束时间,数据量有限。适合使用批处理技术,可以在处理前将所有数据一次性读入内存进行处理。有界流通常用于历史数据分析、数据迁移等场景。
- 无界流:没有明确的开始和结束时间,数据连续不断生成。由于数据是无限且持续的,无界流需要实时处理,并且必须持续摄取和处理数据,不能等待所有数据到达后再进行处理。适合适用于流处理。
名词
源算子(source)
Flink可以从各种来源获取数据,然后构建DataStream进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 从集合读取数据
DataStreamSource<Integer> collectionSource = env.fromCollection(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15));// 从文件中读取数据
DataStreamSource<String> fileSource = env.fromSource(FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/word.txt")).build(),WatermarkStrategy.noWatermarks(),"fileSource");// 从kafka读取数据
DataStreamSource<String> kafkaSource = env.fromSource(KafkaSource.<String>builder()// kafka地址--可配置多个.setBootstrapServers("")// topic名称--可配置多个.setTopics("")// 消费组id.setGroupId("")// 反序列化方式.setValueOnlyDeserializer(new SimpleStringSchema())// kafka 消费偏移量 方式 earliest(一定从最早的开始消费)、latest(一定从最新的开始消费)或者手动设置偏移量 ,默认是earliest.setStartingOffsets(OffsetsInitializer.latest())// 水位线,自定义数据源算子名称.build(), WatermarkStrategy.noWatermarks(), "kafkaSource");// 从socket读取数据
DataStreamSource<String> socketSource = env.socketTextStream("...","1234");基本转换算子
Map
对元素的数据类型和内容做转换。
// 第一个参数为输入流,第二个参数为输出流
SingleOutputStreamOperator<UserDto> userDataStream = kafkaSource.map(new MapFunction<String, UserDto>() { @Override public UserDto map(String message) throws Exception { return JSONObject.parseObject(message, UserDto.class); }
});FlatMap
输入一个元素同时产生零个、一个或多个元素。
// 第一个参数为输入流,第二个参数为输出流
// 可做转换,可做条件过滤
SingleOutputStreamOperator<UserDto> userDataStream =kafkaSource.flatMap(new FlatMapFunction<String, UserDto>() { @Override public void flatMap(String message, Collector<UserDto> collector) throws Exception { UserDto userDto = JSONObject.parseObject(message, UserDto.class); collector.collect(userDto);}
});Filter
对数据源根据条件过滤数据,保留满足条件的数据
// 过滤出年龄大于18的用户
SingleOutputStreamOperator<UserDto> filterDataStream = userDataStream.filter(new FilterFunction<UserDto>() { @Override public boolean filter(UserDto userDto) throws Exception { return userDto.getAge() > 18; }
});聚合算子
KeyBy
根据指定的字段(key),将数据划分到不相交的分区中。相同key的元素会被分到同一个分区中。
// 将用户id一样的用户分到一个分区内
KeyedStream<UserDto, Integer> userKeyedStream = userDataStream.keyBy(new KeySelector<UserDto, Integer>() { @Override public Integer getKey(UserDto userDto) throws Exception { return userDto.getId(); }
});Reduce (仅支持同类型的数据)
对流的数据,来一条计算一条,将当前元素和上一次聚合后的数据组合,输出新值,并将新值进行保存,作为下一次计算的元素。
聚合前和聚合后的数据类型是一致的。
当第一条数据进来时,不会触发计算。
// 计算一个用户的订单总价格
SingleOutputStreamOperator<UserDto> reduce = userKeyedStream.reduce(new ReduceFunction<UserDto>() {@Overridepublic UserDto reduce(UserDto t1, UserDto t2) throws Exception {int totalPrice = t1.getTotalPrice() + t2.getOrderPrice();UserDto userDto = new UserDto();userDto.setId(t1.getId());userDto.setAge(t1.getAge());userDto.setTotalPrice(totalPrice);return userDto;}
});Aggregate (支持不同类型的数据)
SingleOutputStreamOperator<String> aggregate = windowedStream.aggregate(new AggregateFunction<UserDto, Integer, String>() { /** * 创建累加器,就是初始化累加器 * @return */ @Override public Integer createAccumulator() { return 0; } /** * 计算逻辑或者是聚合逻辑 * @param userDto * @param beforeData * @return */ @Override public Integer add(UserDto userDto, Integer beforeData) { return beforeData + userDto.getAge(); } /** * 获取最终结果,窗口触发时输出 * @param integer * @return */ @Override public String getResult(Integer integer) { return "计算结束,最终结果为:" + integer.toString(); } /** * 只有会话窗口才会使用到 * @param integer * @param acc1 * @return */ @Override public Integer merge(Integer integer, Integer acc1) { return 0; }
});窗口(window)
把流切割成有限大小的多个“存储桶”;每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。窗口不是静态生成的,是动态创建的。当这个窗口范围的进入第一条数据时,才会创建对应的窗口。
滚动窗口
有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。每个数据都会分配到一个窗口,而且只会属于一个窗口。滚动窗口可以基于时间定义,也可以基于数据的个数定义,需要的参数只有一个,就是窗口的大小。
// 分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(p -> p.f0);// 基于处理时间开窗,窗口长度为10s,窗口开始时间为 窗口长度整数倍向下取整,结束时间为开始时间+窗口长度
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> tumblingProcessingTimeStream = keyByStream.window(TumblingProcessingTimeWindows.of(Time.seconds(10)));// 基于事件时间开窗,窗口长度为10s,窗口开始时间为数据源事件时间,结束时间为开始时间+窗口长度
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> tumblingEventTimeStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(10)));// 基于次数开窗
WindowedStream<Tuple2<String, Integer>, String, GlobalWindow> countWindowStream = keyedStream.countWindow(10);滑动窗口
大小是固定的,但是窗口之间不是收尾相接的,而是可以“错开”一定的位置。定义滑动窗口的参数有2个:窗口大小和滑动步长,滑动步长代表了窗口计算的频率。因此,如果 slide 小于窗口大小,滑动窗口可以允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
// 分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(p -> p.f0);// 基于处理事件开窗,窗口长度为10s,滑动步长为1s
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> slidingProcessingTimeWindowStream = keyedStream.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(1)));// 基于事件事件开窗,窗口长度为10s,滑动步长为1s
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> slidingEventTimeWindowStream = keyedStream.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(1)));// 基于次数开窗
WindowedStream<Tuple2<String, Integer>, String, GlobalWindow> countWindowStream = keyedStream.countWindow(10, 1);会话窗口
是基于会话来对数据进行分组的。会话窗口只能基于时间来定义。会话窗口中,最重要的参数就是会话的超时时间,也就是两个会话窗口之间的最小距离。如果相邻两个数据到来的时间间隔(Gap)小于指定的大小(size),那说明还在保持会话,他们就属于同一个窗口;如果gap大于Size,那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。会话窗口的长度不固定,起始和结束时间也不是确定的,各个分区之间窗口没有任何关联。会话窗口之间一定不会重叠的,而且会保留至少size的间隔。
// 分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(p -> p.f0);// 基于处理时间开窗,会话间隔时间为10s
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> sessionWindow = keyedStream.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)));// 基于事件时间开窗,会话间隔时间为10s
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> sessionWindow = keyedStream.window(EventTimeSessionWindows.withGap(Time.seconds(10)));全局窗口
这种窗口全局有效,会把相同key的所有数据都分配到同一个窗口中。这种窗口没有结束的时候,默认是不会触发计算的。如果希望它能对数据进行计算,还需要自定义“触发器”(Trigger)。全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink中的计数窗口底层就是用全局窗口实现的。
窗口触发器(trigger)
定义了窗口何时被触发并决定触发后的行为(如进行窗口数据的计算或清理)。
EventTimeTrigger
基于事件时间和水印机制来触发窗口计算。当窗口的最大时间戳小于等于当前的水印时,立即触发窗口计算。
ProcessingTimeTrigger
基于处理时间(即机器的系统时间)来触发窗口计算。当处理时间达到窗口的结束时间时,触发窗口计算。
CountTrigger
根据窗口内元素的数量来触发计算。当窗口内的元素数量达到预设的阈值时,触发窗口计算。
关键方法
- onElement(T element, long timestamp, W window, TriggerContext ctx)
当元素被添加到窗口时调用,用于注册定时器或更新窗口状态。 - onEventTime(long time, W window, TriggerContext ctx)
当事件时间计时器触发时调用,用于处理事件时间相关的触发逻辑。 - onProcessingTime(long time, W window, TriggerContext ctx)
当处理时间计时器触发时调用,用于处理处理时间相关的触发逻辑。 - onMerge(W window, OnMergeContext ctx)
当两个窗口合并时调用,用于合并窗口的状态和定时器。 - clear(W window, TriggerContext ctx)
当窗口被删除时调用,用于清理窗口的状态和定时器。
@Override
public TriggerResult onElement(BatteryRuntimeFlinkDto batteryRuntimeDto, long l, GlobalWindow globalWindow, TriggerContext triggerContext) throws Exception { ReducingState<Long> countState = triggerContext.getPartitionedState(countStateDescriptor); }@Override
public TriggerResult onProcessingTime(long l, GlobalWindow globalWindow, TriggerContext triggerContext) throws Exception { log.info("窗口清除定时器触发,清除计数器和定时器,并关窗"); this.clear(globalWindow, triggerContext); return TriggerResult.PURGE;
}@Override
public TriggerResult onEventTime(long time, GlobalWindow globalWindow, TriggerContext triggerContext) throws Exception { return TriggerResult.CONTINUE;
}@Override
public void clear(GlobalWindow globalWindow, TriggerContext triggerContext) throws Exception { // 清除计数器 triggerContext.getPartitionedState(countStateDescriptor).clear(); // 清除定时器 triggerContext.deleteProcessingTimeTimer(triggerContext.getPartitionedState(processTimerDescription).get());
}处理算子(process)
ProcessFunction
最基本的处理函数,基于DataStream直接调用.process()时作为参数传入。
public class CabinetDetailProcessFunction extends ProcessFunction<CabinetDetailDto, BatteryPutTakeLogDataSourceDto> { //往redis中写入 private transient RedisService redisService; private String platform; public CabinetDetailProcessFunction(String platform) { this.platform = platform; } @Override public void open(Configuration parameters) throws Exception { super.open(parameters); this.redisService = ApplicationContextHolder.getBean(RedisService.class); } @Override public void processElement(CabinetDetailDto cabinetDetailDto, Context context, Collector<BatteryPutTakeLogDataSourceDto> collector) throws Exception { }
}KeyedProcessFunction
对流按键分区后的处理函数,基于KeyedStream调用.process()时作为参数传入。
ProcessWindowFunction
开窗之后的处理函数,也是全窗口函数的代表。基于WindowedStream调用.process()时作为参数传入。
public class BatteryRuntimeProcessFunction extends ProcessWindowFunction<BatteryRuntimeFlinkDto, BatteryRuntimeFlinkDto, String, GlobalWindow> { @Override
public void process(String s, Context context, Iterable<BatteryRuntimeFlinkDto> iterable, Collector<BatteryRuntimeFlinkDto> collector) throws Exception { List<BatteryRuntimeFlinkDto> batteryRuntimeDtos = new ArrayList<>(); iterable.forEach(p -> batteryRuntimeDtos.add(p)); if (CollectionUtils.isEmpty(batteryRuntimeDtos)) { return; } BatteryRuntimeFlinkDto batteryRuntimeFlinkDto = batteryRuntimeDtos.get(0); collector.collect(batteryRuntimeFlinkDto);
}}ProcessAllWindowFunction
同样是开窗之后的处理函数,基于AllWindowedStream调用.process()时作为参数传入。
CoProcessFunction
合并(connect)两条流之后的处理函数,基于ConnectedStreams调用.process()时作为参数传入。
ProcessJoinFunction
间隔连接(interval join)两条流之后的处理函数,基于IntervalJoined调用.process()时作为参数传入。
BroadcastProcessFunction
广播连接流处理函数,基于BroadcastConnectedStream调用.process()时作为参数传入。这里的“广播连接流”BroadcastConnectedStream,是一个未keyBy的普通DataStream与一个广播流(BroadcastStream)做连接(conncet)之后的产物。
public class BatteryRuntimeConnectProcessFunction extends BroadcastProcessFunction<BatteryRuntimeDto, BatteryPutTakeLogDataSourceDto, BatteryRuntimeFlinkDto> {
// 状态
MapStateDescriptor<String, BatteryInBoxStatusDto> descriptor = new MapStateDescriptor<>("boxInStatus", BasicTypeInfo.STRING_TYPE_INFO, TypeInformation.of(new TypeHint<BatteryInBoxStatusDto>(){})); @Override
public void processElement(BatteryRuntimeDto batteryRuntimeDto, ReadOnlyContext readOnlyContext, Collector<BatteryRuntimeFlinkDto> collector) throws Exception {
// dosometing
}@Override
public void processBroadcastElement(BatteryPutTakeLogDataSourceDto batteryPutTakeLogDataSourceDto, Context context, Collector<BatteryRuntimeFlinkDto> collector) throws Exception {
// dosometing
}KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数,同样是基于BroadcastConnectedStream调用.process()时作为参数传入。与BroadcastProcessFunction不同的是,这时的广播连接流,是一个KeyedStream与广播流(BroadcastStream)做连接之后的产物。
输出算子(sink)
输出算子,就是经过一系列处理算子后的数据输出到某个位置。例如:kafka,redis,数据库等等。
KafkaSink
DataStream stream...;
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// 指定 kafka 的地址和端口
.setBootstrapServers("kafka地址和端口")
// 指定序列化器:指定Topic名称、具体的序列化
.setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("topic名称") .setValueSerializationSchema(new SimpleStringSchema()) .build() )
/**
* EXACTLY_ONCE: 精准一次投送。这是最严格,最理想的数据投送保证。数据不丢失不重复。
* AT_LEAST_ONCE: 至少一次投送。数据保证不丢失,但可能会重复。
* NONE: 无任何额外机制保证。数据有可能丢失或者重复。
*/
// sink设置保证级别为 至少一次投送。数据保证不丢失,但可能会重复
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) .build(); stream.sinkTo(kafkaSink);JDBCSink
DataStream<UserDto> reduceStream...;
// 构建jdbc sink
SinkFunction<UserDto> jdbcSink = JdbcSink.sink(
// 数据插入sql语句
"insert into user (`name`, `age`) values(?, ?)",
new JdbcStatementBuilder<UserDto>() {
@Override
// 字段映射配置
public void accept(PreparedStatement pStmt, UserDto userDto) throws SQLException {
pStmt.setString(1, userDto.getUserName());
pStmt.setInt(2, userDto.getAge()); } },
JdbcExecutionOptions
.builder()
// 批次大小,条数
.withBatchSize(10)
// 批次最大等待时间
.withBatchIntervalMs(5000)
// 重复次数
.withMaxRetries(1) .build(),
// jdbc信息配置
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.jdbc.Driver")
.withUrl("数据库地址")
.withUsername("root")
.withPassword("password")
.build() );
// 添加jdbc sink
reduceStream.addSink(jdbcSink);其他方式的sink: File、MongoDB、RabbitMQ、Elasticsearch、Apache Pulsar 等使用方式,可参考官方文档(Apache Flink Documentation)。
Flink 相关依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.17.0</version>
</dependency>
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId><version>1.17.0</version>
</dependency>
<dependency> <groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>1.17.0</version>
</dependency>
<dependency> <groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>1.17.0</version>
</dependency>
<!-- File连接器 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId> <version>1.17.0</version>
</dependency>
<!-- kafka连接器 -->
<dependency> <groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId> <version>1.17.0</version>
</dependency>
<!-- jdbc连接器 -->
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId> <version>1.16.0</version>
</dependency>
相关文章:
Flink基本概念和算子使用
基础概念 Flink是一个框架和分布式处理引擎,用于对无界数据流和有界数据流进行有状态计算,它的核心目标是“数据流上的有状态计算”。 有界流和无界流 有界流:具有明确的开始和结束时间,数据量有限。适合使用批处理技术…...

Kafka 3.0.0集群部署教程
1、集群规划 主机名 ip地址 node.id process.roles kafka1 192.168.0.29 1 broker,controller Kafka2 192.168.0.30 2 broker,controller Kafka3 192.168.0.31 3 broker,controller 2、将kafka包上传以上节点/app目录下 mkdir /app 3、解压kafka包 所有节点 …...

昇思MindSpore进阶教程-格式转换
大家好,我是刘明,明志科技创始人,华为昇思MindSpore布道师。 技术上主攻前端开发、鸿蒙开发和AI算法研究。 努力为大家带来持续的技术分享,如果你也喜欢我的文章,就点个关注吧 MindSpore中可以把用于训练网络模型的数据…...

搜索软件 Everything 的安装与使用教程
一、Everything简介 适用于 Windows 的免费搜索工具 Everything 是 Windows 的即时搜索引擎。发现、整理并轻松访问文件和文件夹,一切尽在指尖! PS:Everything无法对文件内容进行搜索,只能根据文件名和路径进行搜索 二、Everyt…...

oracle 如何判断当前时间在27号到当月月底
在Oracle中,您可以使用TRUNC和LAST_DAY函数来判断当前时间是否在27号到当月月底之间。以下是一个SQL示例: SELECT CASE WHEN TRUNC(SYSDATE) > TRUNC(SYSDATE, DD) 26 AND TRUNC(SYSDATE) < LAST_DAY(SYSDATE) THEN 当前时间在27号到当月月底之间…...

Django 配置邮箱服务,实现发送信息到指定邮箱
一、这里以qq邮箱为例,打开qq邮箱的SMTP服务 二、django项目目录设置setting.py 文件 setting.py 添加如下内容: # 发送邮件相关配置 EMAIL_BACKEND django.core.mail.backends.smtp.EmailBackend EMAIL_USE_TLS True EMAIL_HOST smtp.qq.com EMAIL…...
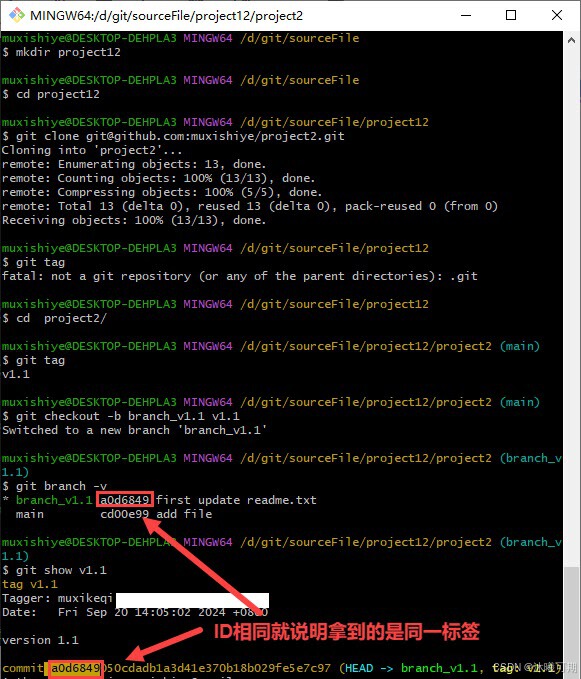
Git使用手册
1、初识Git 概述:Git 是一个开源的分布式版本控制系统,可以有效、高速地处理项目版本管理。 知识点补充: 版本控制:一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。 分布式:每个人…...

sql-labs靶场
第一关(get传参,单引号闭合,有回显,无过滤) ?id-1 union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schemasecurity) -- 第二关(get传参,无闭…...

【Redis入门到精通二】Redis核心数据类型(String,Hash)详解
目录 Redis数据类型 1.String类型 (1)常见命令 (2)内部编码 2.Hash类型 (1)常见命令 (2)内部编码 Redis数据类型 查阅Redis官方文档可知,Redis提供给用户的核心数据…...

如何快速免费搭建自己的Docker私有镜像源来解决Docker无法拉取镜像的问题(搭建私有镜像源解决群晖Docker获取注册表失败的问题)
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 Docker无法拉取镜像 📒📒 解决方案 📒🔖 方法一:免费快速搭建自己的Docker镜像源🎈 部署🎈 使用🔖 备用方案⚓️ 相关链接 🚓️📖 介绍 📖 在当前的网络环境下,Docker镜像的拉取问题屡见不鲜(各类Nas查询…...
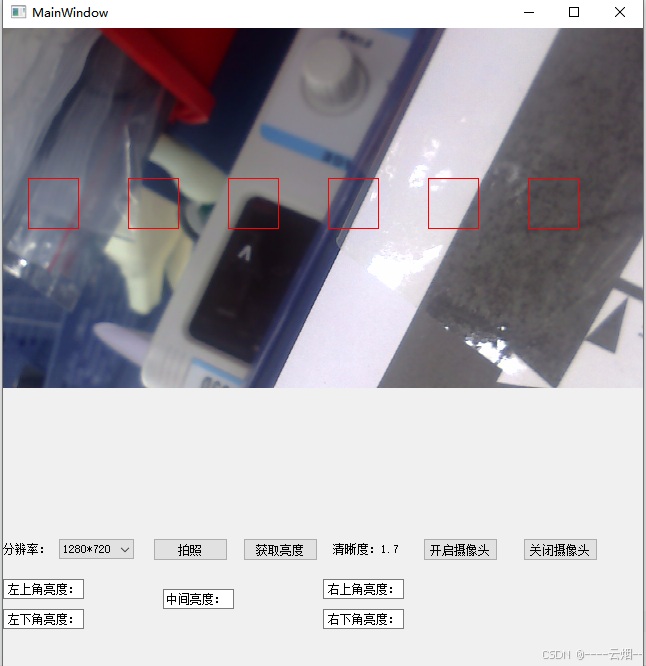
QT 获取视频帧Opencv获取清晰度
先展示结果: 1.获取摄像头的分辨率 mResSize.clear();mResSize camera_->supportedViewfinderResolutions();ui->comboBox_resulation->clear();int i0;foreach (QSize msize, mResSize) {qDebug()<<msize;ui->comboBox_resulation->addItem(…...

生成式AI如何辅助医药行业智能营销
生成式AI在医药行业的智能营销中发挥着日益重要的作用,它通过多种方式辅助医药企业提升市场洞察能力、优化营销策略、增强客户互动和体验,从而推动销售增长和品牌价值的提升。以下是生成式AI如何辅助医药行业智能营销的具体方式:一、精准市场…...
演示:基于WPF的DrawingVisual开发的Chart图表和表格绘制
一、目的:基于WPF的DrawingVisual开发的Chart图表和表格绘制 二、预览 钻井井轨迹表格数据演示示例(应用Table布局,模拟井轨迹深度的绘制) 饼图表格数据演示示例(应用Table布局,模拟多个饼状图组合显示&am…...

汽车保养BBBBBBBBBBB
小保养就是机油和机滤,4s店比较贵,可以在京东上买机油,可以包安装 极护、磁护 两款机油配方不同,极护系列机油注入液钛配方,拥有特别的油膜自适应能力,在各种形式条件下均能有效减少金属间的直接接触&…...
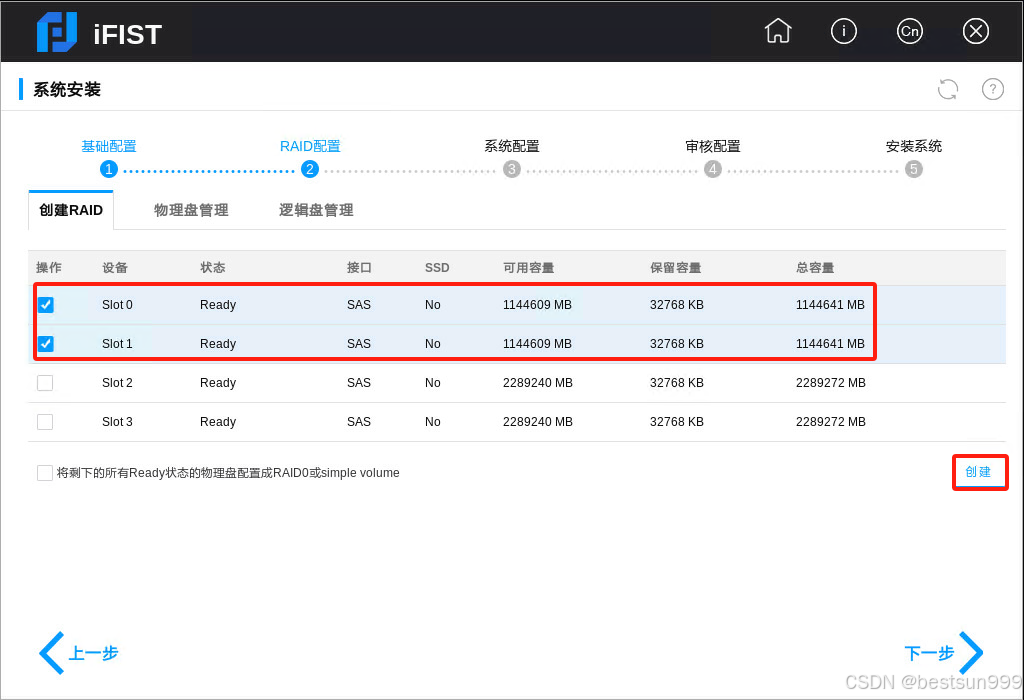
H3C R4900 G3服务器上配置本地磁盘RAID
首先web登录HDM后,查看本地磁盘 开机后在如下界面中按F10 等待后如下截图:单击“系统安装” 如下截图。默认选择,单击“下一步” 如下RAID配置,选中2个同样大的磁盘,单击“创建” 在跳出界面中,配置为RAID 1,输入需要的...
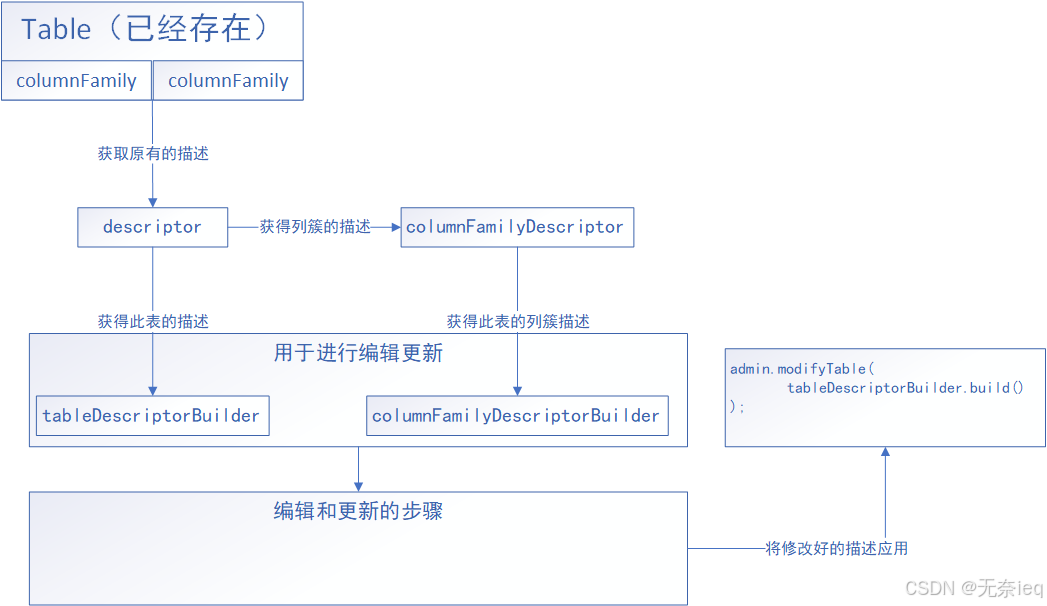
HBase DDL操作代码汇总(namespace+table CRUD操作)
HBase DDL操作 DDL操作主要是关于命名空间和表格的内容增删改查。 注:如果出现无法连接到zookeeper等的相关错误,可以将以下代码打jar包,在HMaster节点上执行 错误提示: Exception in thread “main” java.net.SocketTimeoutExc…...

关于TCP的基础知识
关于TCP的基础知识 TCP 是 Transmission Control Protocol 的缩写,中文意思是传输控制协议。 TCP 是一种面向连接的、可靠的、基于字节流的传输层通信协议,它位于 OSI 模型的第四层(传输层)。TCP 协议通过建立连接、维护连接状态、…...

MyBatis 中的类型别名配置详解
目录 1. 什么是类型别名? 2. 类型别名的配置方法 2.1 使用单个标签 2.2 使用标签批量扫描 2.3 使用Alias注解 3. 注意事项 4. 相关知识拓展 4.1 MyBatis的映射文件 4.2 MyBatis的动态SQL 4.3 MyBatis与Spring的整合 4.4 性能优化 5. 结论 在现代Java开发…...

如何提高UI自动化的稳定性
用例层面: 1. 将用例设计成参数化,将测试数据通过参数进行传递 2. 对于一些可能会变化的参数,将其设计成全局变量,减少维护用例的成本 3. 对用例之间避免产生依赖,可以独立执行 框架层面: 1. 使用PO设…...

ubuntu如何开启和关闭图形界面
在Ubuntu中,你可以根据需要开启或关闭图形界面。以下是具体的方法: 关闭图形界面 方法一:使用 systemctl 命令 打开终端。输入以下命令切换到多用户目标(相当于关闭图形界面):sudo systemctl set-defaul…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...