高性能计算应用优化实践之WRF
WRF(Weather Research Forecast)模式是由美国国家大气研究中心(NCAR)、国家环境预报中心(NCEP)等机构自1997年起联合开发的新一代高分辨率中尺度天气研究预报模式,重点解决分辨率为1~10Km、时效60h以内的有限区域天气预报和模拟问题。
WRF模式开发的目标是建立一个具有可移植、易维护、可扩充、高效、用户友好的模式。WRF模式结合先进的数值方法和资料同化技术,采用改进的物理过程,同时具有多重嵌套及定位不同地理位置的能力,很好的适应了从理想化研究到业务预报的需要,已发展成为目前最流行的气象数值预报系统之一。
我们在之前的文章中介绍过WRF的基本安装部署过程,具体查看
WRF新手村
本次以WRF为例进行应用优化实践。
WRF模式-IO优化
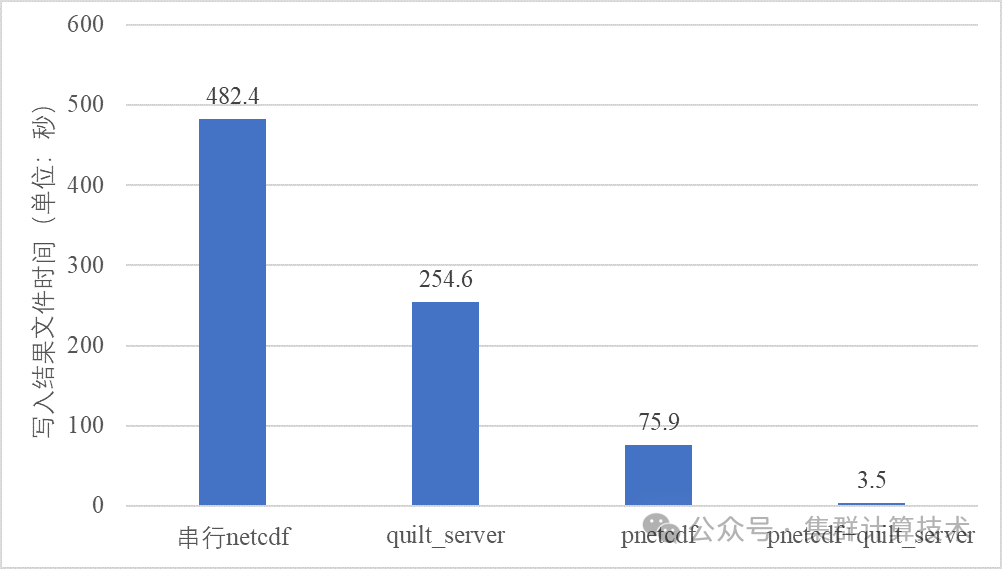
WRF模式定期输出结果文件和重启文件,输出结果数组时,分别支持四种IO模式:串行netcdf格式、并行pnetcdf格式、异步I/O模式和异步I/O+pnetcdf模式。
串行读写
WRF模式默认采用MPI Gatherv调用将所有数据汇集到主进程(0号进程),重构数组,然后使用标准的串行NetCDF库将其写入磁盘。在此期间,其他MPI进程阻塞等待,直到主进程完成写操作。串行netcdf格式需要在编译时采用预编译参数-DNETCDF,并在namelist.input中设置。
io_form_history = 2
io_form_restart = 2
io_form_input = 2
io_form_boundary = 2串行读写的时间会被写入rsl.out.0000文件中,本例串行读写时间如下:
Timing for Writing wrfout_d01_2023-10-25_01:00:00 for domain 1: 482.42148 elapsed seconds该时间包含调用MPI Gatherv和NetCDF格式化的时间,被称为有效I/O时间,并不严格等于数据写入磁盘所需要的时间,仅代表生成输出的墙钟时间。
对于模拟区域较小或者MPI进程数较少的情景,串行NetCDF方式是一个合理的选项。但串行方式依赖MPI_Gatherv及NetCDF的串行特性,随着MPI进程数和模拟区域的增大,默认方式会成为主要的性能瓶颈。该算例中,串行方式写单个文件需要482.42s,耗时较高,瓶颈明显。此外,全局数组都通过MPI_Gatherv传输,主进程会迅速耗尽内存,导致节点内存溢出。降低MPI_Gatherv影响的一种方法是使用MPI/OpenMP混合运行模式,减少每个节点的MPI进程数,增加使用的节点数。然而,OpenMP方式只是降低了串行方式的瓶颈点,并不能彻底消除该方法的弊端。
并行读写
除串行方式外,WRF还支持基于PNetCDF实现的I/O,PNetCDF是NetCDF库的扩展,支持并行I/O。PNetCDF将MPI进程聚合为多个进程组,每个进程组中的聚合器执行文件写入操作,这在很大程度上减少了聚合时间和写入竞争。进一步地,对特定文件系统,如lustre,PNetCDF可与文件系统MPI-IO层结合,用户基于MPI-IO提示设置MPI进程组的数量或者默认采用lustre的条带计数。运行时,MPI-IO库会检查输出文件的lustre条带,然后为该文件分配相同数量的MPI-IO聚合器。MPI-IO会尽可能均匀地将聚合器分布到包含计算进程的节点上。
使用PNetCDF时,需要编译时指定预编译选项-DNETCDF -DPNETCDF,并在namelist.input中设置
io_form_history = 11
io_form_restart = 2
io_form_input = 11
io_form_boundary = 11并行读写的时间同样会被写入rsl.out.0000文件,本例并行读写时间如下:
Timing for Writing wrfout_d01_2023-10-25_01:00:00 for domain 1: 75.91977 elapsed secondsPNetCDF可以作为串行NetCDF的替代方案,表现出良好的性能。然而,随着mpi进程数增加,PNetCDF占总运行时间的比重也会增加。
异步IO(quilt server)
如上所述,无论是串行NetCDF还是并行PNetCDF,其他MPI进程都必须等待主进程将数据写入磁盘,计算过程阻塞。当计算进程阻塞的时间占总计算时间比重较高时,将一个或多个进程专门用于I/O是必要的(I/O进程)。异步IO时,计算进程将数据发送给I/O进程,I/O进程在后台进行数据格式化和写入磁盘操作,计算进程继续计算(异步,图9.1所示)。
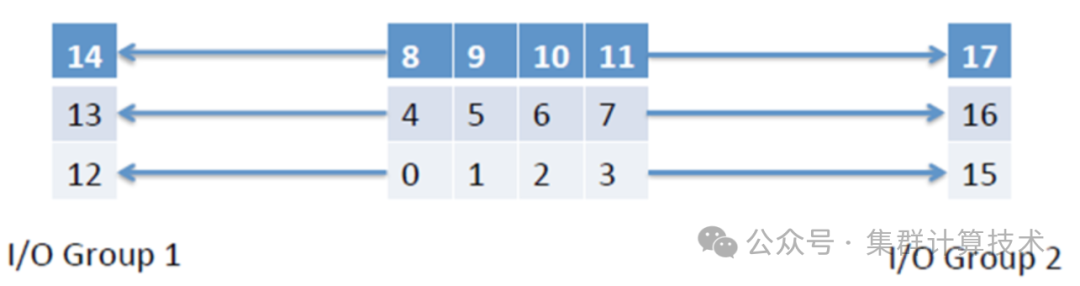
每行的计算进程将数据发送给I/O进程,如进程0-3将数据发送给12或15号I/O进程
使用异步IO,需要在编译时采用预定义参数-DNETCDF,并设置namelist.input中namelist_quilt字段
&namelist_quilt
nio_tasks_per_group = 32,
nio_groups = 2,其中nio_groups表示要使用的I/O进程组数量,nio_tasks_per_group表示每I/O进程组中的进程数。I/O进程总数由nio_groups*nio_tasks_per_group计算得出,计算过程总进程数nprocs=nproc_x*nproc_y,nproc_x和nproc_y分别给出了沿x和y轴方向的进程数。其中nio_tasks_per_group不能超过nproc_y,理想情况下,nio_tasks_per_group应该是nproc_y的倍数。
异步I/O+PNetCDF
编译时采用预编译参数-DNETCDF -DPNETCDF -DPNETCDF_QUILT,并在namelist中使用
io_form_history = 11
io_form_restart = 2
io_form_input = 11
io_form_boundary = 11设置异步I/O进程设置,那么写入磁盘的操作将使用MPI-IO并行处理,从而将两种技术的优势结合。本例中使用异步I/O+PNetCDF,写入文件耗时如下:
Timing for Writing wrfout_d01_2023-10-25_02:00:00 for domain 1: 3.45529 elapsed seconds
极大降低了文件写耗时。
添加图片注释,不超过 140 字(可选)
WRF模式-运行时优化
压缩对IO的性能影响
WRF输出文件常用两种输出格式,分别为经典netcdf格式(classic)及压缩格式(NETCDF4 with HDF5 compression)。使用两种格式输出文件各有利弊,如果追求读写性能,建议采用classic格式;若要节约存储空间,则建议使用压缩格式(NETCDF4 with HDF5 compression)
此处单独使用相同的算例,对比测试支持两种输出格式时,对应的输出文件大小及输出文件的耗时情况,通过测试结果对比分析,使用HDF5格式相比经典netcdf格式,输出文件大小为原来的0.37,输出文件耗时为经典netcdf的3.2倍。

添加图片注释,不超过 140 字(可选)
进程数设置
运行时使用如下命令启动作业,NP为总进程数。
mpirun -np $NP ./wrf.exenamelist.input参数文件中的domains部分进行如下设置,表示由WRF自动进行进程分解:NP=nproc_x*nproc_y,分解原则是nproc_x与nproc_y尽量接近,且nproc_x<=nproc_y。nproc_x小一些,使得patch在X方向长一些,会有利于向量化运行。
&domains
nproc_x = -1,
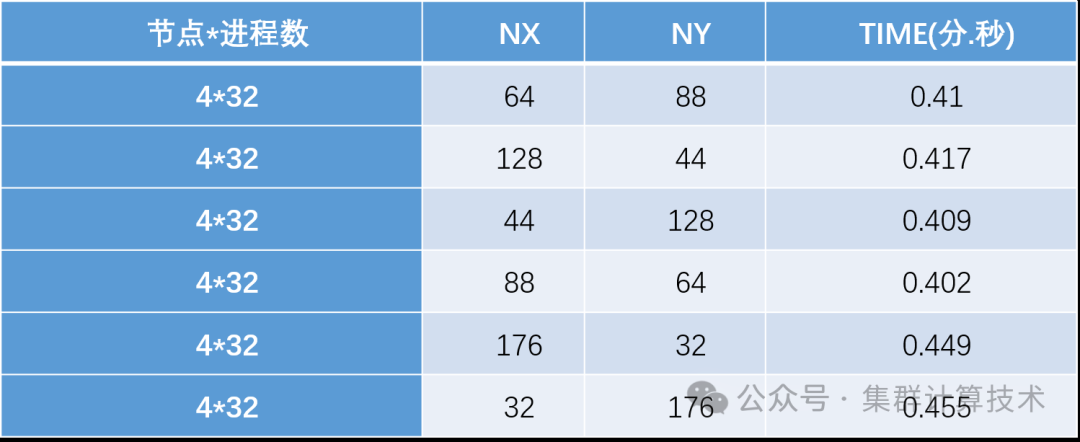
nproc_y = -1,在5632个计算核心上运行WRF,测试结果如下表:
添加图片注释,不超过 140 字(可选)
由以上测试结果分析,该算例运行时Nproc_x=88,Nproc_y=64时测试结果最优。运行其他WRF case时,需要具体进行性能测试判断Nproc_x及Nproc_y的最优值。
相关文章:
高性能计算应用优化实践之WRF
WRF(Weather Research Forecast)模式是由美国国家大气研究中心(NCAR)、国家环境预报中心(NCEP)等机构自1997年起联合开发的新一代高分辨率中尺度天气研究预报模式,重点解决分辨率为1~…...

nsight-compute使用教程
一 安装 有的时候在linux上安装上了nsight-compute,可以生成报告,但是却因为缺少qt组件而无法打开,我选择的方法是在linux上生成报告,在window上的nsight compute的图形界面打开,需要注意的是,nsight compute图形界面的版本一定要更高,不然无法打开 二 使用 2.1 生成…...

【深度学习】03-神经网络01-4 神经网络的pytorch搭建和参数计算
# 计算模型参数,查看模型结构,我们要查看有多少参数,需要先安装包 pip install torchsummary import torch import torch.nn as nn from torchsummary import summary # 导入 summary 函数,用于计算模型参数和查看模型结构# 创建神经网络模型类 class Mo…...

我与Linux的爱恋:命令行参数|环境变量
🔥个人主页:guoguoqiang. 🔥专栏:Linux的学习 文章目录 一.命令行参数二.环境变量1.环境变量的基本概念2.查看环境变量的方法3.环境变量相关命令4.环境变量的组织方式以及获取环境变量的三种方法 环境变量具有全局属性 一…...

django drf 统一Response格式
场景 需要将响应体按照格式规范返回给前端。 例如: 响应体中包含以下字段: {"result": true,"data": {},"code": 200,"message": "ok","request_id": "20cadfe4-51cd-42f6-af81-0…...

SM2协同签名算法中随机数K的随机性对算法安全的影响
前面介绍过若持有私钥d的用户两次SM2签名过程中随机数k相同,在对手获得两次签名结果Sig1和Sig2的情况下,可破解私钥d。 具体见SM2签名算法中随机数K的随机性对算法安全的影响_sm2关闭随机数-CSDN博客 另关于SM2协同签名过程,具体见SM2协同签…...

解决setMouseTracking(true)后还是无法触发mouseMoveEvent的问题
如图,在给整体界面设置鼠标追踪且给ui界面的子控件也设置了鼠标追踪后,运行后的界面仍然有些地方移动鼠标无法触发 mouseMoveEvent函数,这就令人头痛。。。 我的解决方法是:重载event函数: 完美解决。。。...

基于深度学习的花卉智能分类识别系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 传统的花卉分类方法通常依赖于专家的知识和经验,这种方法不仅耗时耗力,而且容易受到主观因素的影响。本系统利用 TensorFlow、Keras 等深度学习框架构建卷积神经网络&#…...

Springboot集成MongoDb快速入门
1. 什么是MongoDB 1.1. 基本概念 MongoDB是一个基于分布式文件存储 [1] 的数据库。由C语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数…...

DERT目标检测—End-to-End Object Detection with Transformers
DERT:使用Transformer的端到端目标检测 论文题目:End-to-End Object Detection with Transformers 官方代码:https://github.com/facebookresearch/detr 论文题目中包括的一个创新点End to End(端到端的方法)简单的理解就是没有使…...

软件后端开发速度慢的科技公司老板有没有思考如何破局
最近接到两个科技公司咨询,说是他们公司后端开发速度太慢,前端程序员老等着,后端程序员拖了项目进度。 这种问题不只他们公司,在软件外包公司中,有一部分项目甲方客户要得急,以至于要求软件开发要快&#…...

开放原子超级链内核XuperCore可搭建区块链
区块链是一种分布式数据库技术,它以块的形式存储数据,并使用密码学方法保证数据的安全性和完整性。 每个块包含一定数量的交易信息,并通过加密链接到前一个块,形成一个不断增长的链条。 这种设计使得数据在网络中无法被篡改,因为任何尝试修改一个块的数据都会破坏整个链的…...

【Qualcomm】高通SNPE框架的使用 | 原始模型转换为量化的DLC文件 | 在Android的CPU端运行模型
目录 ① 激活snpe环境 ② 设置环境变量 ③ 模型转换 ④ run on Android 首先,默认SNPE工具已经下载并且Setup相关工作均已完成。同时,拥有原始模型文件,本文使用的模型文件为SNPE 框架示例的inception_v3_2016_08_28_frozen.pb文件。imag…...

C++map与set
文章目录 前言一、map和set基础知识二、set与map使用示例1.set去重操作2.map字典统计 总结 前言 本章主要介绍map和set的基本知识与用法。 一、map和set基础知识 map与set属于STL的一部分,他们底层都是是同红黑树来实现的。 ①set常见用途是去重 ,set不…...

随手记:前端一些定位bug的方法
有时候接到bug很烦躁,不管是任何环境的bug,看到都影响心情,随后记总结一下查看bug的思路,在摸不着头脑的时候或者焦虑的时候,可以静下心来顺着思路思考和排查bug可能产生的原因 1.接到bug,最重要的是&am…...

【深度学习】03-神经网络2-1损失函数
在神经网络中,不同任务类型(如多分类、二分类、回归)需要使用不同的损失函数来衡量模型预测和真实值之间的差异。选择合适的损失函数对于模型的性能至关重要。 这里的是API 的注意⚠️,但是在真实的公式中,目标值一定是…...

Python爬虫APP程序:构建智能化数据抓取工具
在信息爆炸的时代,数据的价值日益凸显。Python作为一种强大的编程语言,与其丰富的库一起,为爬虫程序的开发提供了得天独厚的优势。本文将探讨如何使用Python构建一个爬虫APP程序,以及其背后的思维逻辑。 什么是Python爬虫APP程序&…...

第五部分:2---中断与信号
目录 操作系统如何得知哪个外部资源就绪? 什么是中断机制? CPU引脚和中断号的关系: 中断向量表: 信号和中断的关系: 操作系统如何得知哪个外部资源就绪? 操作系统并不会主动轮询所有外设来查看哪些资源…...
:SQL Server Query Optimizer 简介)
梧桐数据库(WuTongDB):SQL Server Query Optimizer 简介
SQL Server Query Optimizer 是 SQL Server 数据库引擎的核心组件之一,负责生成查询执行计划,以优化 SQL 查询的执行性能。它的目标是根据查询的逻辑结构和底层数据的统计信息,选择出最优的查询执行方案。SQL Server Query Optimizer 采用基于…...

Scrapy框架介绍
一、什么是Scrapy 是一款快速而强大的web爬虫框架,基于Twusted的异步处理框架 Twisted是事件驱动的 Scrapy是由Python实现的爬虫框架 ① 架构清晰 ②可扩展性强 ③可以灵活完成需求 二、核心组件 Scrapy Engine(引擎):Scrapy框架…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...