[深度学习]循环神经网络
1 自然语言处理概述
- 语料:一个样本,句子/文章
- 语料库:由语料组成
- 词表:分词之后的词语去重保存成为词表
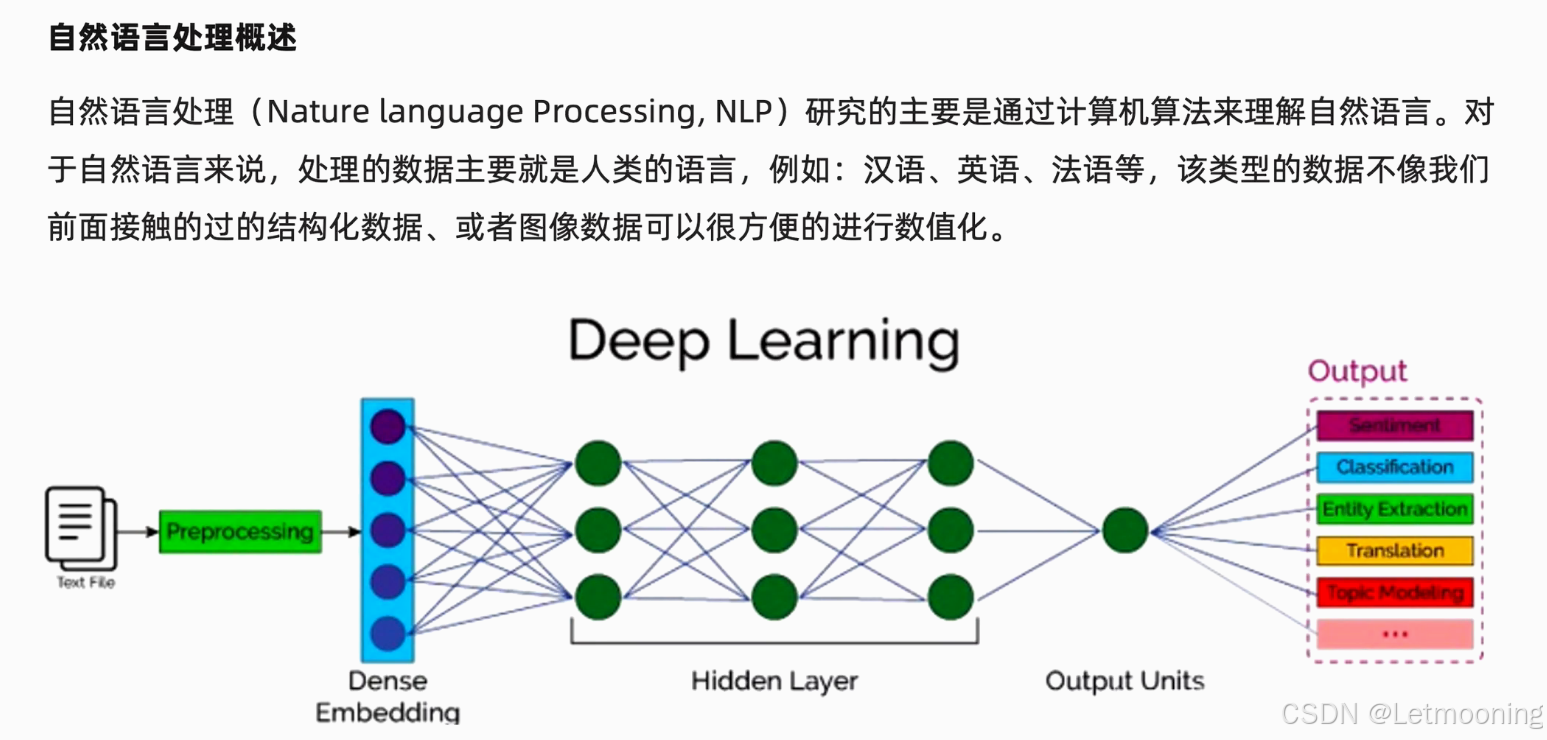

2 词嵌入层



import jieba
import torch.nn as nn
import torch
# 文本数据
text='北京东奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
# 分词
words=jieba.lcut(text)
print(words)
# 构建词表
uwords=list(set(words))
print(uwords)
words_num=len(uwords)
print(words_num)
# 构建词向量矩阵
embed=nn.Embedding(num_embeddings=words_num,embedding_dim=5)
print(embed(torch.tensor(1)))
# 输出结果
for i,word in enumerate(uwords):print(word,end=' ')print(embed(torch.tensor(i)))['北京', '东奥', '的', '进度条', '已经', '过半', ',', '不少', '外国', '运动员', '在', '完成', '自己', '的', '比赛', '后', '踏上', '归途', '。']
['自己', '运动员', '外国', '在', '后', '比赛', ',', '已经', '。', '过半', '不少', '进度条', '归途', '东奥', '踏上', '北京', '完成', '的']
18
tensor([-0.0293, -0.5446, -0.4495, -0.4013, -0.8653],grad_fn=<EmbeddingBackward0>)
自己 tensor([-0.0907, -0.6044, 1.9097, 1.1630, -0.4595],grad_fn=<EmbeddingBackward0>)
运动员 tensor([-0.0293, -0.5446, -0.4495, -0.4013, -0.8653],grad_fn=<EmbeddingBackward0>)
外国 tensor([ 1.9382, -1.3591, -0.2884, -1.4880, -0.2400],grad_fn=<EmbeddingBackward0>)
在 tensor([ 1.0954, 0.2975, -0.5151, -0.4355, 0.3870],grad_fn=<EmbeddingBackward0>)
后 tensor([-0.1857, -0.4351, 0.3869, -0.6311, -1.5527],grad_fn=<EmbeddingBackward0>)
比赛 tensor([-1.7570, -1.1983, -0.7864, 0.7223, -0.5285],grad_fn=<EmbeddingBackward0>)
, tensor([-0.2706, 1.7983, 0.9599, -0.5464, 0.7365],grad_fn=<EmbeddingBackward0>)
已经 tensor([ 1.4934, -0.7174, 1.1466, -0.3617, 0.6748],grad_fn=<EmbeddingBackward0>)
。 tensor([ 0.7996, -0.5406, -0.6476, 0.3923, 0.5128],grad_fn=<EmbeddingBackward0>)
过半 tensor([ 1.2070, 0.9933, 0.2634, 0.3173, -0.2273],grad_fn=<EmbeddingBackward0>)
不少 tensor([ 0.6716, 1.6509, 0.7375, 0.7585, -0.6289],grad_fn=<EmbeddingBackward0>)
进度条 tensor([ 0.4440, 1.9701, 0.6437, -0.2500, -0.8144],grad_fn=<EmbeddingBackward0>)
归途 tensor([-0.5646, 0.8995, -0.5827, -1.0231, 1.3692],grad_fn=<EmbeddingBackward0>)
东奥 tensor([-0.8312, 0.2083, 1.3728, 0.2860, 0.2762],grad_fn=<EmbeddingBackward0>)
踏上 tensor([ 0.0955, 0.5528, -0.5286, 0.6969, -0.7469],grad_fn=<EmbeddingBackward0>)
北京 tensor([ 0.4739, 0.6474, 0.3765, -1.9607, -1.1079],grad_fn=<EmbeddingBackward0>)
完成 tensor([ 1.2215, -0.3468, -0.1432, 0.5908, 1.2294],grad_fn=<EmbeddingBackward0>)
的 tensor([ 0.3083, 0.0163, 1.4923, -0.2768, 0.0904],grad_fn=<EmbeddingBackward0>)
3 循环网络RNN
- 激活函数为tanh
- 隐藏状态:当前词前面的信息
- [batch,seqlen(句子长度),词向量维度]
- pytorch框架的[seq_len,batch,input_size]





# RNN层API
import torch.nn as nn
import torch
# 词向量维度128,隐藏向量维度256
rnn=nn.RNN(input_size=128,hidden_size=256,num_layers=2)
# 第一个数字:seq_len,句子长度,也就是词语个数
# 第二个数字:batch,批量个数,也就是句子的个数
# 第三个数字:input_size,词向量的维度
# [seq_len,batch,input_size]
x=torch.randn([32,10,128])
# 第一个数字:num_layers,隐藏层的个数
# 第二个数字:batch,批量个数,也就是句子的个数
# 第三个数字:hidden_size,隐藏向量的维度
# [num_layers,batch,hidden_size]
h0=torch.zeros([2,10,256])
output,hn=rnn(x,h0)
# [seq_len,batch,hidden_size]
print(output.shape)
# [num_layers,batch,hidden_size]
print(hn.shape)
4 文本生成案例

import jieba# 构建词表
all_words = []
unique_words = []
for text in open('jaychou_lyrics.txt', 'r', encoding='utf8'):words = jieba.lcut(text)all_words.append(words)for word in words:if word not in unique_words:unique_words.append(word)word2idx = {word: idx for idx, word in enumerate(unique_words)}
# print(all_words)
# print(unique_words)
# print(word2idx)
print(len(unique_words))
corpus_ids = []
for words in all_words:temp = []for word in words:temp.append(word2idx[word])temp.append(word2idx[' '])corpus_ids.extend(temp)
print(corpus_ids)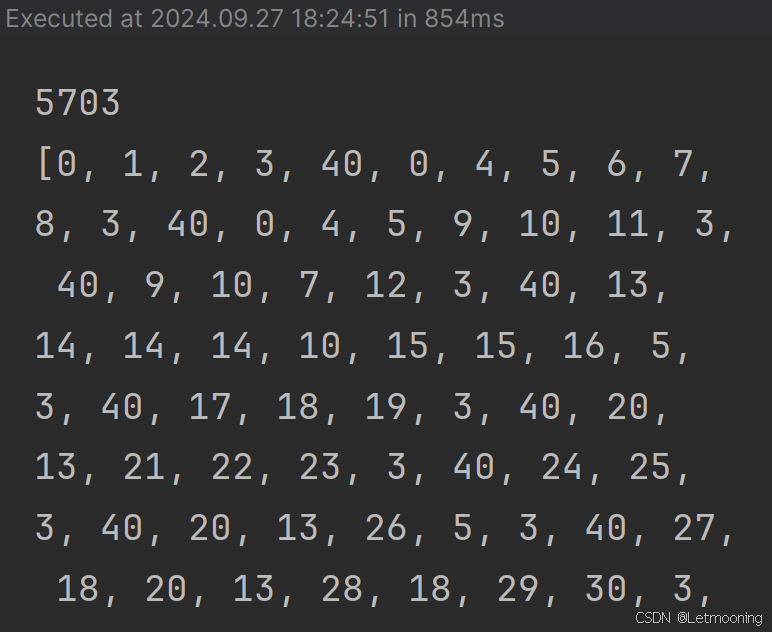
from torch.utils.data import Datasetclass textDataset(Dataset):def __init__(self, corpus_ids, seq_len):self.corpus_ids = corpus_idsself.seq_len = seq_lenself.word_count = len(self.corpus_ids)self.number = self.word_count // self.seq_lendef __len__(self):return self.numberdef __getitem__(self, idx):# idx指词的索引,并将其修正索引到文档的范围里面start = min(max(idx, 0), self.word_count - self.seq_len - 2)x = self.corpus_ids[start:start + self.seq_len]y = self.corpus_ids[start + 1:start + 1 + self.seq_len]return torch.tensor(x), torch.tensor(y)dataset = textDataset(corpus_ids, 5)
print(dataset.__getitem__(1))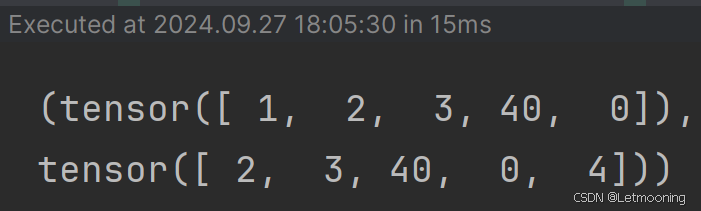
相关文章:
[深度学习]循环神经网络
1 自然语言处理概述 语料:一个样本,句子/文章语料库:由语料组成词表:分词之后的词语去重保存成为词表 2 词嵌入层 import jieba import torch.nn as nn import torch # 文本数据 text北京东奥的进度条已经过半,不少外…...

景联文科技精准数据标注:优化智能标注平台,打造智能未来
景联文科技是一家致力于为人工智能提供全面数据标注解决方案的专业公司。 拥有一支由经验丰富的数据标注师和垂直领域专家组成的团队,确保数据标注的质量和专业性。 自建平台功能一站式服务平台,提供从数据上传、标注、审核到导出的一站式服务࿰…...

商场促销——策略模式
文章目录 商场促销——策略模式商场收银软件增加打折简单工厂实现策略模式策略模式实现策略与简单工厂结合策略模式解析 商场促销——策略模式 商场收银软件 时间:2月27日22点 地点:大鸟房间 人物:小菜、大鸟 “小菜,给你…...

万字长文,AIGC算法工程师的面试秘籍,推荐收藏!
目录先行 AI绘画基础: 什么是DreamBooth技术?正则化技术在AI绘画模型中的作用? 深度学习基础: 深度学习中有哪些常用的注意力机制?如何寻找到最优超参数? 机器学习基础: 判别式模型和生成…...

一些超好用的 GitHub 插件和技巧
聊聊我平时使用 GitHub 时学到的一些插件、技巧。 浏览器插件 在我的另一篇博客 浏览器插件推荐 里提到过跟 GitHub 相关的一些插件,这里重复下: Sourcegraph:在线打开项目,方便阅读,将 GitHub 变得和 IDE …...

记Flink SQL 将数据写入 MySQL时的一个优化策略
Flink SQL 将数据写入 MySQL 时,如果主分片数较少,可以通过调整 MySQL 的主分片数来提高读写性能 1. 检查当前的分片设置 在 MySQL 中,使用以下 SQL 查询来查看当前的分片情况: SHOW VARIABLES LIKE innodb_buffer_pool_size; …...

QT-自定义信号和槽对象树图形化开发计算器
1. 自定义信号和槽 核心逻辑: 需要有两个类,一个提供信号,另一个提供槽。 然后在窗口中将 信号和槽 链接起来。 示例目标: 创建一个 Teacher 类,提供信号。 创建一个 Student 类,提供槽。 实现步骤&…...

C# 字符串(String)的应用说明一
一.字符串(String)的应用说明: 在 C# 中,更常见的做法是使用 string 关键字来声明一个字符串变量,也可以使用字符数组来表示字符串。string 关键字是 System.String 类的别名。 二.创建 String 对象的方法说明&#x…...

Redis缓存淘汰算法详解
文章目录 Redis缓存淘汰算法1. Redis缓存淘汰策略分类2. 会进行淘汰的7种策略2.1 基于过期时间的淘汰策略2.2 基于所有数据范围的淘汰策略 3. LRU与LFU算法详解4. 配置与调整5. 实际应用场景 LRU算法以及实现样例LFU算法实现1. 数据结构选择2. 访问频率更新3. 缓存淘汰4. 缓存插…...

Sklearn 与 TensorFlow 机器学习实用指南
Sklearn 与 TensorFlow 机器学习实用指南 Scikit-learn(Sklearn) 1. 简介 2. 特点 3. 基本用法 TensorFlow 1. 简介 2. 特点 3. 基本用法 选择指南 总结 🎈边走、边悟🎈迟早会好 关于使用 Scikit-learn(Sk…...

RabbitMQ 界面管理说明
1.RabbitMQ界面访问端口和后端代码连接端口不一样 界面端口是15672 http://localhost:15672/ 后端端口是 5672 默认账户密码登录 guest 2.总览图 3.RabbitMq数据存储位置 4.队列 4.客户端消费者连接状态 5.队列运行状态 6.整体运行状态...

设备管理与点巡检系统
在现代企业管理中,设备的高效运作至关重要。为此,我们推出了设备管理与点巡检系统,通过自动化管理提升设备使用效率,保障生产安全。 系统特点 设备全生命周期管理 系统涵盖设备的各个阶段,从设备管理、点检、巡检、保…...

计算机网络的整体认识---网络协议,网络传输过程
计算机网络背景 网络发展 独立模式: 计算机之间相互独立; 网络互联: 多台计算机连接在一起, 完成数据共享; 局域网LAN: 计算机数量更多了, 通过交换机和路由器连接在一起; 广域网WAN: 将远隔千里的计算机都连在一起;所谓 "局域网" 和 "广域网" 只是一个相…...

Battery management system (BMS)
电池管理系统(BMS)是一种专门用于监督电池组的技术,电池组由电池单元组成,在电气上按照行x列矩阵配置进行排列,以便在预期的负载场景下,在一段时间内提供目标范围的电压和电流。 文章目录 电池管理系统是如…...
)
和GPT讨论ZNS的问题(无修改)
主题:ZNS相关的疑问讨论,GPT逻辑回答,要是开高阶版本估计回答的更明智些。 ZNS的写和传统写的区别 ChatGPT 说: ChatGPT ZNS(Zoned Namespace)与传统写入方式的主要区别体现在以下几个方面: …...

6.8方框滤波
基本概念 方框滤波(Box Filter)是一种基本的图像处理技术,用于对图像进行平滑处理或模糊效果。它通过在图像上应用一个固定大小的方框核(通常是矩形),计算该区域内像素值的平均值来替换中心像素的值。这种…...

携手SelectDB,观测云实现性能与成本的双重飞跃
在刚刚落下帷幕的2024云栖大会上,观测云又一次迎来了全面革新。携手SelectDB,实现了技术的飞跃,这不仅彰显了观测云在监控观测领域的技术实力,也预示着我们可以为全球用户提供更加高效、稳定的数据监测与分析服务。这一技术升级&a…...

Redis 五大基本数据类型及其应用场景进阶(缓存预热、雪崩 、穿透 、击穿)
Redis 数据类型及其应用场景 Redis 是什么? Redis是一个使用C语言编写的高性能的基于内存的非关系型数据库,基于Key/Value结构存储数据,通常用来 缓解高并发场景下对某一资源的频繁请求 ,减轻数据库的压力。它支持多种数据类型,如字符串、…...

如何在ChatGPT的帮助下,使用“逻辑回归”技巧完成论文写作?
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 逻辑回归作为一种统计分析工具广泛应用,以解决研究中的分类问题。其主要作用在于探讨和量化自变量对因变量的影响,从而揭示潜在的因果关系。 在论文写作中&…...

MySQL 临时表
MySQL 临时表 引言 在数据库管理中,临时表是一种非常有用的工具,尤其是在进行复杂的数据处理和查询时。MySQL 作为一种流行的关系型数据库管理系统,提供了对临时表的支持。本文将详细介绍 MySQL 临时表的概念、用途、创建方法以及管理技巧。 什么是 MySQL 临时表? MySQ…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...