创建数据/采集数据+从PI数据到PC+实时UI+To PLC
Get_Data
----------
import csv
import os
import random
from datetime import datetime
import logging
import time
# 配置日志记录
logging.basicConfig(filename='D:/_Study/Case/Great_Data/log.txt',
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s')
def 记录日志(消息):
logging.info(消息)
print(消息)
def 生成随机记录():
# 生成随机数据
aX_U_1 = random.uniform(-0.29969177, 0.29969177)
aY_U_1 = random.uniform(0.6930143, 2.29969177)
aZ_U_1 = random.uniform(-0.6866665, 0.69969177)
timestamp = datetime.now().strftime("%Y/%m/%d %H:%M:%S:%f")[:-3] # 格式化时间戳
aX_D_1 = random.uniform(-0.38232422, 0.69969177)
aY_D_1 = random.uniform(0.5595703, 0.79969177)
aZ_D_1 = random.uniform(0.7294922, 2.7294922)
# 数据记录列表
record = [
aX_U_1,
aY_U_1,
aZ_U_1,
timestamp,
aX_D_1,
aY_D_1,
aZ_D_1
]
return record
def 追加到CSV(文件路径, 记录, 表头=None):
# 尝试写入CSV文件
try:
if not os.path.exists(文件路径):
# 如果文件不存在,则创建新文件并写入表头
with open(文件路径, mode='w', newline='', encoding='utf-8') as 文件:
writer = csv.writer(文件)
if 表头:
writer.writerow(表头)
writer.writerow(记录)
else:
# 否则追加记录
with open(文件路径, mode='a', newline='', encoding='utf-8') as 文件:
writer = csv.writer(文件)
writer.writerow(记录)
记录日志(f"记录已追加到 {文件路径}")
except PermissionError:
记录日志("权限拒绝:请确保目录可访问,并尝试以管理员身份运行脚本。")
except Exception as e:
记录日志(f"写入CSV时发生错误:{e}")
# 定义文件路径
基础目录 = 'D:/_Study/Case/Great_Data/Data'
os.makedirs(基础目录, exist_ok=True) # 创建目录(如果不存在)
# 文件名称模板
文件名模板 = 'AA@BB@{index}@{time}.csv'
文件索引 = 0
# 获取所有符合条件的文件
文件列表 = []
for 文件名 in os.listdir(基础目录):
if 文件名.startswith('AA@BB@'):
文件路径 = os.path.join(基础目录, 文件名)
文件列表.append(文件路径)
# 按照时间戳排序文件列表
文件列表.sort(key=lambda x: int(os.path.basename(x).split('@')[2].split('.')[0]), reverse=True)
# 只保留最新的两个文件
保留文件列表 = 文件列表[:1]
删除文件列表 = 文件列表[1:]
# 删除多余的文件,并记录到日志
for 文件路径 in 删除文件列表:
os.remove(文件路径)
记录日志(f"{文件路径} 已被删除。")
# 如果没有文件,则创建第一个文件
if not 保留文件列表:
文件索引 += 1
当前时间 = datetime.now().strftime("%Y%m%d_%H%M%S_%f")[:-3]
文件路径 = os.path.join(基础目录, 文件名模板.format(index=文件索引, time=当前时间))
表头 = [ 'aX_U_1', 'aY_U_1', 'aZ_U_1', '时间戳','aX_D_1', 'aY_D_1', 'aZ_D_1']
追加到CSV(文件路径, 表头, 表头=表头)
记录日志(f"{文件路径} 已创建并写入表头。")
保留文件列表.append(文件路径)
# 开始生成记录
记录总数 = 0
while 文件索引 <= 1:
for 文件路径 in 保留文件列表:
if 记录总数 >= 10:
文件索引 += 1
if 文件索引 > 1:
记录日志("所有文件均已达到最大行数。")
break
当前时间 = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
文件路径 = os.path.join(基础目录, 文件名模板.format(index=文件索引, time=当前时间))
表头 = [ 'aX_U_1', 'aY_U_1', 'aZ_U_1', '时间戳','aX_D_1', 'aY_D_1', 'aZ_D_1']
追加到CSV(文件路径, 表头, 表头=表头)
记录日志(f"{文件路径} 已创建并写入表头。")
保留文件列表.append(文件路径)
记录总数 = 0
记录 = 生成随机记录()
追加到CSV(文件路径, 记录)
记录总数 += 1
记录日志(f"当前 {文件路径} 总行数为:{记录总数}")
if 文件索引 > 2:
break
记录日志("处理完成。")
print("Task completed. Will reboot in 3 minutes.")
time.sleep(180) # 等待180秒
print("Rebooting now...")
os.system('sudo reboot')
'''
[Unit]
Description=Great Data Service
After=network.target
[Service]
User=pi
WorkingDirectory=/home/pi/Great_Data
ExecStart=/usr/bin/python3 /home/pi/Great_Data/Great_data.py
[Install]
WantedBy=multi-user.target
'''
----------
Copy+Del Data
----------
import pyautogui
import time
import os
import shutil
import datetime
#10 秒计时后开始运行
pyautogui.countdown(3)
#到达位置鼠标左键单击
pyautogui.click(1154,1038,button='left')#任务栏图标
time.sleep(0.1)
pyautogui.click(1158,910,button='left')#VNC程序
time.sleep(0.1)
pyautogui.click(659,65,button='left')#PI程序
time.sleep(0.1)##
pyautogui.click(1285,366,button='left')#MENU 菜单
time.sleep(0.1)
pyautogui.click(1170,486,button='left')#File Transfer
time.sleep(0.1)
pyautogui.click(743,677,button='left')#SendFile
time.sleep(0.1)
pyautogui.click(953,498,button='left')#File选择
time.sleep(0.1)
pyautogui.click(1039,615,button='left')#OK
time.sleep(0.1)
pyautogui.click(1039,616,button='left')#桌面路径
time.sleep(0.1)
pyautogui.click(1002,762,button='left')#确定
time.sleep(0.1)
pyautogui.click(1298,300,button='left')#X1
time.sleep(0.1)
pyautogui.click(1190,373,button='left')#X2
time.sleep(0.1)
pyautogui.click(1295,333,button='left')#X3
time.sleep(0.1)
pyautogui.click(1157,1037,button='left')##VNC程序
time.sleep(0.1)
pyautogui.click(1465,874,button='left')#Close File Transfere
time.sleep(0.1)
#到达位置鼠标左键双击
pyautogui.doubleClick(x=1298, y=301, button="left")
time.sleep(1.2)
#pyautogui.click(922,68,button='left')
#time.sleep(1)
#存储截图
im = pyautogui.screenshot()
im.save(r'D:\GGY\屏幕截图.png')
#####获取最新文件,并单独复制至处理文件夹
# 定义源目录和目标目录
src_dir = r'C:\Users\Administrator\Desktop\Great_Data\Data'
dst_dir = r'C:\Users\Administrator\Desktop\Great_Data\Data\Send'
# 如果目标目录不存在,则创建之
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
# 获取目录下所有的文件及其修改日期,并找到最新的那个
files = [os.path.join(src_dir, f) for f in os.listdir(src_dir) if os.path.isfile(os.path.join(src_dir, f))]
files.sort(key=lambda x: os.path.getmtime(x), reverse=True)
# 检查是否找到了文件
if files:
# 复制最新的文件
latest_file = files[0]
print(f'Copying the latest file: {latest_file}')
shutil.copy2(latest_file, dst_dir) # 使用shutil.copy2来保持元数据
# 删除其他的旧文件
for file in files[1:]:
print(f'Deleting old file: {file}')
try:
os.remove(file)
except OSError as e:
print(f"Error: {e.strerror} - {file}")
# 记录操作日志到目标目录下的 log.txt 文件
log_file_path = os.path.join(dst_dir, 'log.txt')
with open(log_file_path, 'a') as log_file:
log_file.write(f'{datetime.datetime.now()}: Latest file copied and old files deleted.\n')
else:
print('No files found in the directory.')
#####获取最新文件,并单独复制至处理文件夹
#填入参数, 第一参数是输入内容,第二个参数是每个字符间的间隔时间;
#pyautogui.moveTo(1241,311)
#count=(r'd:\aa')
#for c in str(count):
# pyautogui.keyDown(c)
#填入参数, 第一参数是输入内容,第二个参数是每个字符间的间隔时间;
#pyautogui.click(915,87,button='left')
#time.sleep(2)
#pyautogui.click(364,284,button='left')
#count=(2 )
#for cc in str(count):
# pyautogui.keyDown(cc)
#实时显示坐标
#pyautogui.displayMousePosition()
'''
import pyautogui
import time
#10 秒计时后开始运行
pyautogui.countdown(3)
#实时显示坐标d:\aa
while True:
x,y=pyautogui.position()
print('Pos:',(x,y))
'''
----------
From data to Chart
----------
##
import os
import pygame
import pandas as pd
import glob
import logging
from pygame.locals import *
# 配置日志记录
log_path = r'D:\Study\Case\Chart_RealTime\log.txt'
logging.basicConfig(filename=log_path, level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
# 初始化pygame
pygame.init()
# 设置窗口大小和标题
WINDOW_WIDTH = 1920
WINDOW_HEIGHT = 1080
WINDOW_TITLE = "UI"
screen = pygame.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT))
pygame.display.set_caption(WINDOW_TITLE)
# 定义颜色
WHITE = (255, 255, 255)
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 255)
ORANGE = (255, 165, 0)
PURPLE = (128, 0, 128)
BROWN = (139, 69, 19)
BLACK = (0, 0, 0)
# 源目录路径
source_dir = r'C:\Users\Administrator\Desktop\Great_Data\Data\Send'
# 查找目录下的所有CSV文件
csv_files = glob.glob(os.path.join(source_dir, '*.csv'))
if not csv_files:
print("未找到CSV文件,请检查目录路径是否正确。")
else:
# 用于绘制图表的数据
data = []
# 定义处理时间戳的函数
def process_timestamp(ts):
try:
if ':' in ts:
ts, microseconds = ts.rsplit(':', 1)
microseconds = microseconds.ljust(3, '0')
ts += '.' + microseconds
else:
ts += '.000'
except Exception as e:
logging.error(f"Failed to process timestamp {ts}: {e}")
ts = ts + '.000'
return ts
# 遍历每个CSV文件
for csv_file in csv_files:
logging.info("Reading CSV file...")
相关文章:

创建数据/采集数据+从PI数据到PC+实时UI+To PLC
Get_Data ---------- import csv import os import random from datetime import datetime import logging import time # 配置日志记录 logging.basicConfig(filename=D:/_Study/Case/Great_Data/log.txt, level=logging.INFO, format=%(asctime)s - %(l…...
)
Linux基础入门 --12 DAY(SHELL脚本编程基础)
shell脚本编程 声明:首行shebang机制 #!/bin/bash #!/usr/bin/python #!/usr/bin/perl 变量 变量类型 变量类型: 内置变量 : 如 PS1 , PATH ,HISTSIZE 用户自定义变量 不同变量存放数据不同,决定了以下 1.数据存储方式 2.参与的运算 3.表示…...

关于frp Web界面-----frp Server Dashboard 和 frp Client Admin UI
Web 界面 官方文档:https://gofrp.org/zh-cn/docs/features/common/ui/ 目前 frpc 和 frps 分别内置了相应的 Web 界面方便用户使用。 客户端 Admin UI 服务端 Dashboard 服务端 Dashboard 服务端 Dashboard 使用户可以通过浏览器查看 frp 的状态以及代理统计信…...

Hive数仓操作(一)
Hive 介绍 Hive 是一个基于 Hadoop 的数据仓库工具,旨在简化大规模数据集的管理和分析。它将结构化数据文件映射为表,并提供类似 SQL 的查询功能。Hive 的数据存储在 Hadoop 分布式文件系统(HDFS)中,使用 Hive 查询语…...

什么是NAND Flash?
什么是NAND Flash? NAND闪存是一种非易失性存储器技术,它彻底改变了数字时代的数据存储。它是闪存的一种形式,这意味着它可以被电擦除和重新编程。NAND闪存以NAND(NOT-AND)逻辑门命名,该逻辑门用于其基本架构。术语“…...

Spring Boot 整合 Keycloak
1、概览 本文将带你了解如何设置 Keycloak 服务器,以及如何使用 Spring Security OAuth2.0 将 Spring Boot 应用连接到 Keycloak 服务器。 2、Keycloak 是什么? Keycloak 是针对现代应用和服务的开源身份和访问管理解决方案。 Keycloak 提供了诸如单…...
工程师 - Windows下使用WSL来访问本地的Linux文件系统
Access Linux filesystems in Windows and WSL 2 从 Windows Insiders 预览版构建 20211 开始,WSL 2 将提供一项新功能:wsl --mount。这一新参数允许在 WSL 2 中连接并挂载物理磁盘,从而使您能够访问 Windows 本身不支持的文件系统࿰…...

SQL高可用优化-优化SQL中distinct和Where条件对索引字段进行非空检查语句
最近做一个需求,关于SQL高可用优化,需要优化项目中的SQL,提升查询效率。 SQL高可用优化 一、优化SQL包含distinct场景二、优化SQL中Where条件中索引字段是否为NULL三、代码验证1. NodeMapper2. NodeService3. NodeController4.数据库数据5.项…...

openharmony源码编译
1. win拷贝数据到虚拟机Ubuntu配置 1.打开终端,更新软件库 sudo apt-get update 2.下载安装open-vm-tools,open-vm-tools-desktop sudo apt-get install open-vm-tools open-vm-tools-desktop 3.重启 sudo reboot 2.编译环境配置 1.设置环境脚本…...

H.264编解码工具 - NVIDIA CUDA
一、简介 NVIDIA CUDA编解码是一项采用NVIDIA图形处理器(GPU)来加速视频编码和解码的技术。CUDA(Compute Unified Device Architecture)是一种并行计算平台和编程模型,允许开发者使用GPU来进行通用计算。 优点: 加速编解码速度:CUDA编解码利用GPU的并行处理能力,可以…...

数学建模小练习
题目B 电影《虎胆龙威 3》中,塞谬尔和布鲁斯扮演的主角要拆除西蒙所放的炸弹。西蒙喷泉上面有两个壶,容量分别是5加仑和3加仑,向其中一个壶中加入刚好 4 加仑的水,计时器会停止,否则5分钟后会爆炸。 问题:能够安全拆弹…...

Java爬虫:获取SKU详细信息的艺术
在电子商务的世界里,SKU(Stock Keeping Unit,库存单位)是每个商品的唯一标识符,它包含了商品的详细信息,如尺寸、颜色、价格等。对于商家和开发者来说,获取商品的SKU详细信息对于库存管理、订单…...
心理咨询展示网站建设渠道拓展
心理问题长期以来都受到关注,每个城市里也都有相关服务商家,除了进店外,线上也可以开展咨询服务,对需求者来说需要找到靠谱的品牌,而商家也需要触达到更多客户获取转化。 网站是品牌线上工具,利于商家通过…...

naocs注册中心,配置管理,openfeign在idea中实现模块间的调用,getway的使用
一 naocs注册中心步骤 1 nacos下载安装 解压安装包,直接运行bin目录下的startup.cmd 这里双击运行出现问题的情况下 (版本低的naocs) 在bin目录下 打开cmd 运行以下命令 startup.cmd -m standalone 访问地址: http://localh…...

先进封装技术 Part02---TSV科普
一、引言 随着电子设备向更小型化、更高性能的方向发展,传统的芯片互连技术已经无法满足日益增长的需求。在这样的背景下,TSV(Through-Silicon Via,硅通孔)技术应运而生,成为先进封装技术中的核心之一。 如果我们看大多数主板,可以看到两件事:第一,芯片之间的大多数连…...

【数据挖掘】2023年 Quiz 1-3 整理 带答案
目录 Quiz 1Quiz 2Quiz 3Quiz 1 Problem 1(30%). Consider the training data shown below. Here, A , B A, B A,B, and...

老古董Lisp实用主义入门教程(12):白日梦先生的白日梦
白日梦先生的白日梦 白日梦先生已经跟着大家一起学Lisp长达两个月零五天! 001 粗鲁先生Lisp再出发002 懒惰先生的Lisp开发流程003 颠倒先生的数学表达式004 完美先生的完美Lisp005 好奇先生用Lisp来探索Lisp006 好奇先生在Lisp的花园里挖呀挖呀挖007 挑剔先生给出…...

UE5 Windows热更新解决方案思路(HotPatcher+Tomcat+RuntimeFilesDownloader)
以下个人学习笔记。其中必会存在一些问题,仅作参考。本人版本5.1。 参考视频: UE4热更新:HotPatcher插件使用教程_哔哩哔哩_bilibili 3.检查需要下载的版本_哔哩哔哩_bilibili 参考文章: UE 热更新:Questions &…...

进程管理工具:非daemon进程管理工具supervisor
一、非daemon进程管理工具:supervisor Windows安装supervisor https://pypi.org/project/supervisor-win/4.5.0/#files 一)进程管理supervisor简介 supervisor是一个 Client/Server模式的系统,允许用户在类unix操作系统上监视和控制多个进程&…...

c++模拟真人鼠标轨迹算法
一.鼠标轨迹算法简介 鼠标轨迹底层实现采用 C / C语言,利用其高性能和系统级访问能力,开发出高效的鼠标轨迹模拟算法。通过将算法封装为 DLL(动态链接库),可以方便地在不同的编程环境中调用,实现跨语言的兼…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...

大数据治理的常见方式
大数据治理的常见方式 大数据治理是确保数据质量、安全性和可用性的系统性方法,以下是几种常见的治理方式: 1. 数据质量管理 核心方法: 数据校验:建立数据校验规则(格式、范围、一致性等)数据清洗&…...
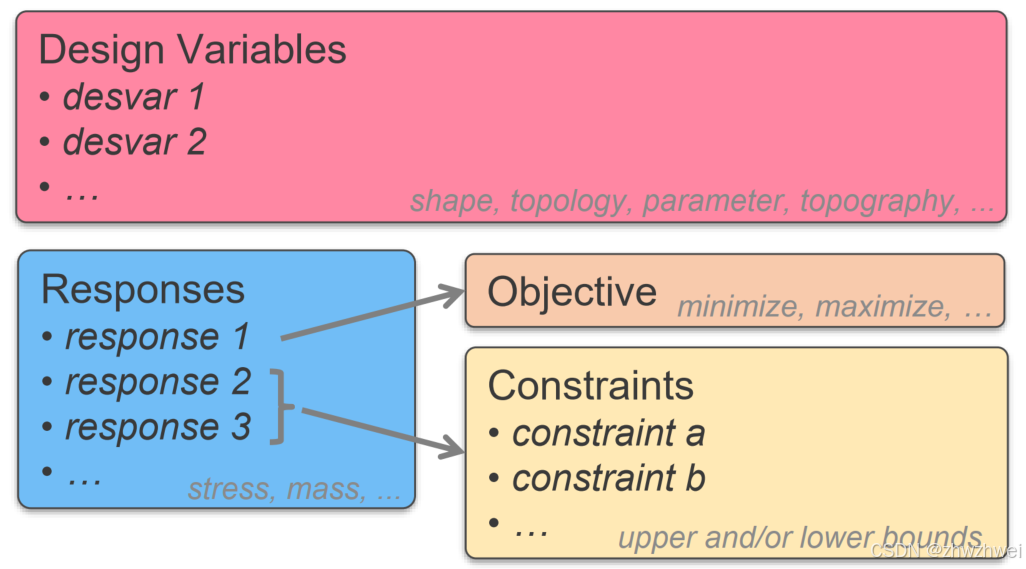
[拓扑优化] 1.概述
常见的拓扑优化方法有:均匀化法、变密度法、渐进结构优化法、水平集法、移动可变形组件法等。 常见的数值计算方法有:有限元法、有限差分法、边界元法、离散元法、无网格法、扩展有限元法、等几何分析等。 将上述数值计算方法与拓扑优化方法结合&#…...

作为点的对象CenterNet论文阅读
摘要 检测器将图像中的物体表示为轴对齐的边界框。大多数成功的目标检测方法都会枚举几乎完整的潜在目标位置列表,并对每一个位置进行分类。这种做法既浪费又低效,并且需要额外的后处理。在本文中,我们采取了不同的方法。我们将物体建模为单…...