【视频讲解】非参数重采样bootstrap逻辑回归Logistic应用及模型差异Python实现
全文链接:https://tecdat.cn/?p=37759
分析师:Anting Li
本文将深入探讨逻辑回归在心脏病预测中的应用与优化。通过对加州大学欧文分校提供的心脏病数据集进行分析,我们将揭示逻辑回归模型的原理、实现过程以及其在实际应用中的优势和不足。同时,我们还将介绍多种优化方法,如牛顿迭代、随机梯度下降和贝叶斯逻辑回归等,以提高模型的性能和准确性(点击文末“阅读原文”获取完整代码数据)。
此外,本文还将结合代码和数据探讨非参数化的自助重采样方法在逻辑回归中的应用及模型差异分析。通过对不同计算逻辑回归参数抽样分布方法的比较,我们将深入了解这些方法的假设和适用场景,为实际应用中选择合适的方法提供参考。
逻辑回归在心脏病预测中的应用与优化
本视频教程聚焦于逻辑回归这一广泛应用的分析模型,旨在处理因变量二元分类问题。
视频
逻辑回归在传统线性回归基础上引入 sigmoid 函数,通过假设数据服从特定分布并运用极大似然估计进行参数估计。在众多领域如金融、医学、市场营销和网络安全中,逻辑回归都有着重要应用。
关键词:逻辑回归;心脏病预测;数据清洗;模型优化;模型评价
一、引言
逻辑回归作为一种经典的统计学习方法,在二元分类问题中发挥着重要作用。本文以心脏病数据集为研究对象,深入探讨逻辑回归模型的原理、实现过程、优化策略以及评价指标。
二、逻辑回归模型原理
(一)模型主体
逻辑回归假定观测的 y 服从伯努利分布,通过将线性回归的结果输入 sigmoid 函数,将输出值映射到 0 到 1 之间,代表事件发生的概率。即 logit (P (Y = 1)) = β₀ + β₁_X₁ + …… + βₖ_Xₖ,其中 P = g (β₀ + β₁X₁ +... + βₖXₖ),g (X) = 1 / (1 + e⁻ˣ)。
(二)对数似然函数
逻辑回归的对数似然函数为 L = log [∏₁ᵢ₌₁ⁿ pᵢʸⁱ(1 - pᵢ)¹⁻ʸⁱ] = ∑₁ᵢ₌₁ⁿ[yᵢlog (pᵢ) + (1 - yᵢ) log (1 - pᵢ)] = ∑₁ᵢ₌₁ⁿ[yᵢβₜXᵢ - log (1 + e⁽ᵦₜˣᵢ⁾)],通过最大化这个对数似然函数来估计模型参数。
三、模型实现
(一)数据集介绍
选用的心脏病数据集由加州大学欧文分校(UCI)提供,是一个开放性的数据集,包含 303 个样本,每个样本具有 14 个不同的特征指标,如年龄、性别、胸痛类型、血压、最高心率、ST 段抬高等。
(二)数据清洗
对数据进行缺失值和异常值处理,得到 297 条可用数据。
进行标准化处理,消除不同特征之间的量纲差异。
将处理后的数据划分为训练集(前 70%)和测试集(后 30%)。
(三)模型建立
选择相关系数最高的两个连续型自变量 thalach 和 oldpeak,针对心脏病发病情况二分类变量 target 构建逻辑回归模型进行分析和预测。使用 R 语言的 glm 函数,令 link = "logit"。
四、模型结果
thalach 和 oldpeak 在连续型变量中的相关系数最高,均大于 0.4。
模型中的自变量均显著。
模型的 AUC 值为 0.79,显示出良好的拟合效果。
五、模型优化
为提升模型性能,采用了以下优化方法:
(一)牛顿迭代
得到新的参数 Beta₀ₑ、Beta₁ₑ、Beta₂ₑ,准确性为 0.719101123595506,迭代次数为 5 次。
(二)随机梯度下降
得到新的参数 Beta₀ₑ、Beta₁ₑ、Beta₂ₑ,准确性为 0.6966292134831462,迭代次数为 173 次。
(三)贝叶斯逻辑回归
得到新的参数 Beta₀ₑ、Beta₁ₑ、Beta₂ₑ,准确性为 0.7356010452689,迭代次数为 693 次;以及新的参数 Beta₀ₑ、Beta₁ₑ、Beta₂ₑ,准确性为 0.7963,迭代次数为 1000 次。
六、模型评价
(一)优点
简单高效,适用于处理二元分类问题。
可解释性强,模型参数具有明确的实际意义。
对特征依赖性较小,在特征较少的情况下仍能进行有效预测。
(二)缺点
容易受到异常值影响,可能导致参数估计偏差较大。
无法处理复杂的非线性关系。
容易出现过拟合,尤其是在数据量较小或特征较多时。
七、结论
本文深入研究了逻辑回归模型在心脏病预测中的应用。通过对 UCI 心脏病数据集的分析,阐述了逻辑回归的原理、实现方法、优化策略和评价指标。尽管该模型存在一些不足,但在二元分类问题上仍具有一定优势。未来可进一步探索更有效的优化方法,提高模型的性能和泛化能力。
非参数化的自助重采样方法在Logistic回归应用及模型差异分析|附数据代码
本文探讨了计算逻辑回归参数抽样分布的不同方法,包括非参数化的自助重采样方法、参数化的自助方法以及一种混合模式。通过对这些方法的实施和分析,揭示了它们基于不同的建模假设,产生不同的结果。同时指出,在实际应用中,应根据差异的重要性选择最适合的方法,而不是认为某种方法是唯一正确的。
关键词:重采样;逻辑回归;参数化自助法;非参数化自助法
一、引言
计算抽样分布的不同方法会产生不同结果,但在实践中差异通常较小,我们可以选择方便的方法。本文由 Reddit 上的一个问题引发,探讨了逻辑回归的参数化引导问题中随机误差项的确定,并介绍了两种计算逻辑回归参数抽样分布的方法。本文将实施这些方法并解释其假设,提出混合方法,并给出选择方法的标准。
二、数据来源与处理
(一)数据来源
本文使用来自一般社会调查(GSS)的数据,存储库下载包含已重新采样的 GSS 数据子集的 HDF 文件。
(二)数据处理
导入所需的库,设置随机种子,下载数据文件并读取数据。
选取特定问题的数据,并对因变量进行重新编码。使用 GSS 中的一个关于大麻合法化的问题数据,将因变量中表示 “不应该合法化” 的值
2替换为0。
gss\['GRASS'\].value_counts()gss\['GRASS'\].replace(2, 0, inplace=True)为了对二次关系进行建模,添加包含
AGE和EDUC平方值的列,并删除有缺失值的行。
gss\['AGE2'\] = gss\['AGE'\]\*\*2gss\['EDUC2'\] = gss\['EDUC'\]\*\*2data = gss.dropna(subset=\['AGE', 'EDUC', 'SEX', 'GUNLAW', 'GRASS'\])三、逻辑回归结果
使用 StatsModels 进行逻辑回归,得到回归结果。绘制男性和女性受访者支持大麻合法化的预测概率随年龄变化的曲线。
import statsmodels.formula.api as smfformula = 'GRASS ~ AGE + AGE2 + EDUC + EDUC2 + C(SEX)'result\_hat = smf.logit(formula, data=data).fit()result\_hat.summary()df = pd.DataFrame()df\['AGE'\] = np.linspace(18, 89)df\['EDUC'\] = 16df\['AGE2'\] = df\['AGE'\]\*\*2df\['EDUC2'\] = df\['EDUC'\]\*\*2df\['SEX'\] = 1pred1 = result\_hat.predict(df)pred1.index = df\['AGE'\]df\['SEX'\] = 2pred2 = result\_hat.predict(df)pred2.index = df\['AGE'\]pred1.plot(label='Male', alpha=0.6)pred2.plot(label='Female', alpha=0.6)plt.xlabel('Age')plt.ylabel('Fraction')plt.title('Support for legal marijuana')plt.legend();结果显示男性比女性更有可能支持合法化,年轻人比老年人更有可能支持合法化。

点击标题查阅往期内容

高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据

左右滑动查看更多
01
02
03
04
四、非参数化自助重采样方法
(一)方法描述
基于自助重采样,对data的行进行有放回抽样,并对重新采样的数据运行回归模型。
options = dict(disp=False, start\_params=result\_hat.params)def bootstrap(i):bootstrapped = data.sample(n=len(data), replace=True)results = smf.logit(formula, data=bootstrapped).fit(**options)return results.params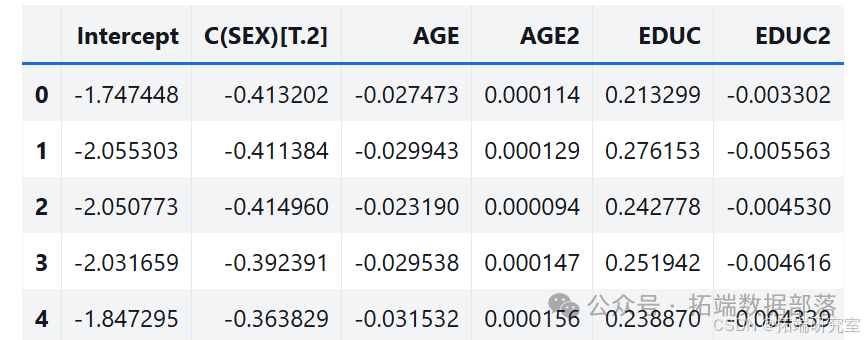
(二)结果分析
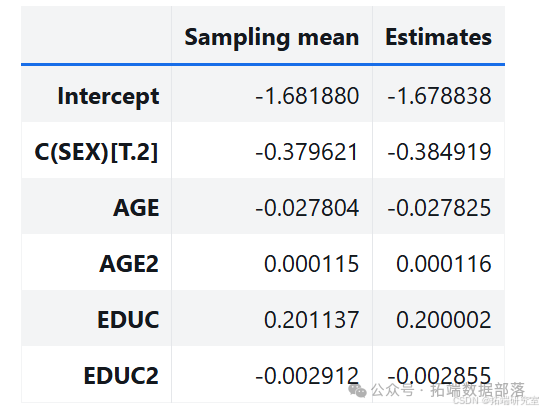
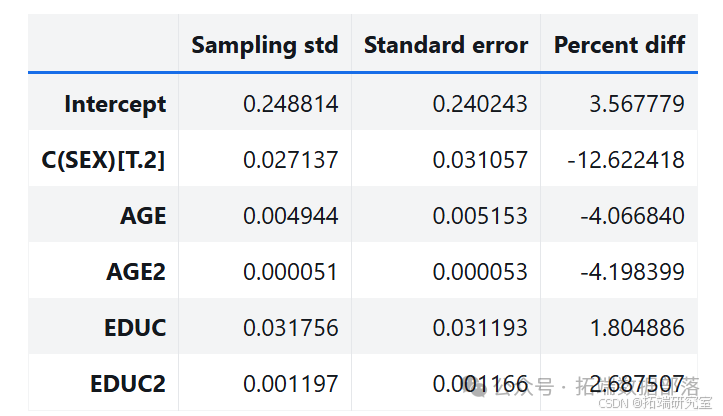
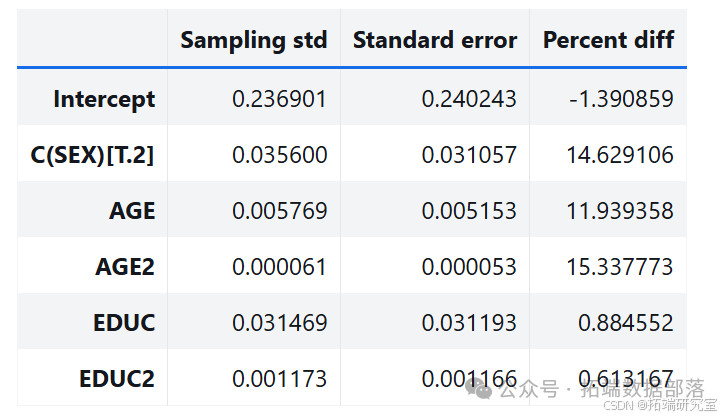
通过多次运行该过程,从抽样分布中生成样本。分析其中一个参数的抽样分布,发现抽样分布的平均值接近使用原始数据集估计的参数,标准差接近 StatsModels 计算的标准误差。
estimates = pqdm(range(101), bootstrap, n\_jobs=4)sampling\_dist = pd.DataFrame(estimates)ci90 = sampling\_dist\['C(SEX)\[T.2\]'\].quantile(\[0.05, 0.95\])sns.kdeplot(sampling\_dist\['C(SEX)\[T.2\]'\])\[plt.axvline(x, ls=':') for x in ci90\]plt.title('Sampling distribution of a parameter');pd.DataFrame({"Sampling mean": sampling\_dist.mean(),"Estimates": result\_hat.params})def standard\_errors(sampling\_dist, result\_hat):df = pd.DataFrame({"Sampling std": sampling\_dist.std(),"Standard error": result\_hat.bse})num, den = df.values.Tdf\['Percent diff'\] = (num / den - 1) * 100return dfstandard\_errors(sampling\_dist, result\_hat)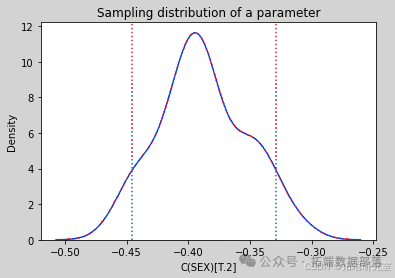
五、参数化自助方法
(一)方法描述
假设从原始数据中估计的参数是正确的,使用回归模型计算每个受访者的预测概率,然后用这些概率为每个受访者生成有偏差的抛硬币,将模拟值作为因变量运行回归模型。
pi\_hat = result\_hat.predict(data)from scipy.stats import bernoullisimulated = bernoulli.rvs(pi\_hat.values)def bootstrap2(i):flipped = data.assign(GRASS=bernoulli.rvs(pi\_hat.values))results = smf.logit(formula, data=flipped).fit(**options)return results.params(二)结果分析
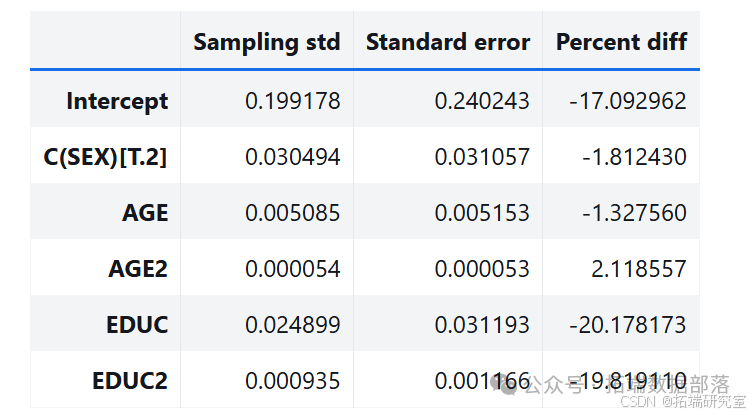
多次运行该方法得到抽样分布样本,分析参数的抽样分布,其标准差也接近标准误差。
estimates = pqdm(range(101), bootstrap2, n\_jobs=4)sampling\_dist2 = pd.DataFrame(estimates)ci90 = sampling\_dist2\['C(SEX)\[T.2\]'\].quantile(\[0.05, 0.95\])sns.kdeplot(sampling\_dist2\['C(SEX)\[T.2\]'\])\[plt.axvline(x, ls=':') for x in ci90\]plt.title('Sampling distribution of a parameter');standard\_errors(sampling\_dist2, result_hat)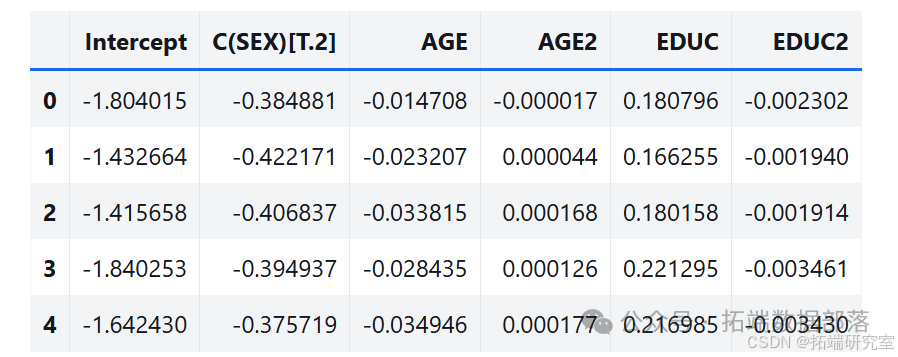

六、混合模式方法
(一)方法描述
结合非参数化和参数化方法,先使用自助抽样模拟调查不同的人,再用参数化方法模拟他们的响应。
def bootstrap3(i):bootstrapped = data.sample(n=len(data), replace=True)pi\_hat = result\_hat.predict(bootstrapped)flipped = bootstrapped.assign(GRASS=bernoulli.rvs(pi_hat.values))results = smf.logit(formula, data=flipped).fit(**options)return results.params(二)结果分析
得到抽样分布样本,分析参数的抽样分布,标准误差与 StatsModels 计算的误差相当。
estimates = pqdm(range(101), bootstrap3, n\_jobs=4)sampling\_dist3 = pd.DataFrame(estimates)ci90 = sampling\_dist3\['C(SEX)\[T.2\]'\].quantile(\[0.05, 0.95\])sns.kdeplot(sampling\_dist3\['C(SEX)\[T.2\]'\])\[plt.axvline(x, ls=':') for x in ci90\]plt.title('Sampling distribution of a parameter');standard\_errors(sampling\_dist3, result_hat)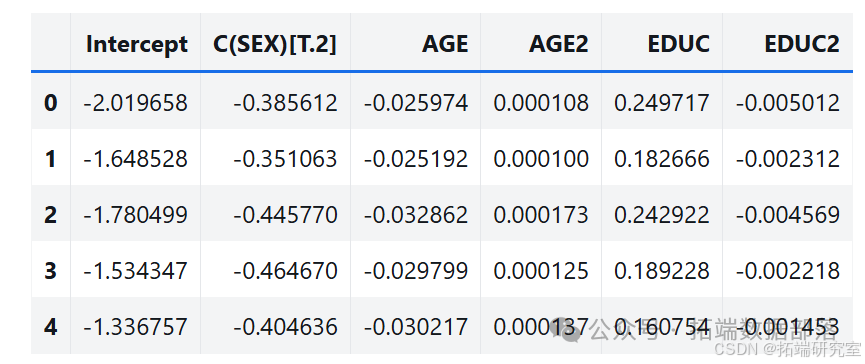

七、讨论与结论
(一)不同方法的比较
本文介绍了三种计算抽样分布的方法,它们基于不同的抽样过程模型,产生不同的结果。在某些情况下,不同方法可能渐近收敛于相同结果,但对于有限数据集通常不同。
(二)选择方法的标准
如果差异较小,在实践中可能无关紧要,可以选择最容易实现、计算最快或方便的方法。不能认为分析方法的结果是唯一正确的,它们也基于建模假设和近似值。
综上所述,在实际应用中应根据具体情况选择合适的方法来计算逻辑回归参数的抽样分布。
关于分析师

在此对 Anting Li 对本文所作的贡献表示诚挚感谢,她在中央财经大学完成了应用统计学专业的硕士学位,专注统计学领域。擅长 R 语言、Python、Matlab。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《【视频讲解】非参数重采样bootstrap的逻辑回归Logistic应用及模型差异Python实现》。
点击标题查阅往期内容
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据|数据分享
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
MATLAB随机森林优化贝叶斯预测分析汽车燃油经济性
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
使用贝叶斯层次模型进行空间数据分析
MCMC的rstan贝叶斯回归模型和标准线性回归模型比较
python贝叶斯随机过程:马尔可夫链Markov-Chain,MC和Metropolis-Hastings,MH采样算法可视化
Python贝叶斯推断Metropolis-Hastings(M-H)MCMC采样算法的实现
matlab贝叶斯隐马尔可夫hmm模型实现
贝叶斯线性回归和多元线性回归构建工资预测模型
Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言RSTAN MCMC:NUTS采样算法用LASSO 构建贝叶斯线性回归模型分析职业声望数据
R语言STAN贝叶斯线性回归模型分析气候变化影响北半球海冰范围和可视化检查模型收敛性
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析免疫球蛋白、前列腺癌数据
R语言JAGS贝叶斯回归模型分析博士生延期毕业完成论文时间
R语言Metropolis Hastings采样和贝叶斯泊松回归Poisson模型
Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
R语言贝叶斯MCMC:用rstan建立线性回归模型分析汽车数据和可视化诊断
R语言贝叶斯MCMC:GLM逻辑回归、Rstan线性回归、Metropolis Hastings与Gibbs采样算法实例
R语言贝叶斯Poisson泊松-正态分布模型分析职业足球比赛进球数
随机森林优化贝叶斯预测分析汽车燃油经济性
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
Python贝叶斯回归分析住房负担能力数据集
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python用PyMC3实现贝叶斯线性回归模型
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言Gibbs抽样的贝叶斯简单线性回归仿真分析
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言基于copula的贝叶斯分层混合模型的诊断准确性研究
R语言贝叶斯线性回归和多元线性回归构建工资预测模型
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言stan进行基于贝叶斯推断的回归模型
R语言中RStan贝叶斯层次模型分析示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
WinBUGS对多元随机波动率模型:贝叶斯估计与模型比较
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
视频:R语言中的Stan概率编程MCMC采样的贝叶斯模型
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计



![]()

相关文章:
【视频讲解】非参数重采样bootstrap逻辑回归Logistic应用及模型差异Python实现
全文链接:https://tecdat.cn/?p37759 分析师:Anting Li 本文将深入探讨逻辑回归在心脏病预测中的应用与优化。通过对加州大学欧文分校提供的心脏病数据集进行分析,我们将揭示逻辑回归模型的原理、实现过程以及其在实际应用中的优势和不足…...

Linux系统中命令wc
wc(word count)命令是Linux和Unix系统中用于计算字数的一个非常实用的工具。它可以统计文件的字节数、字数、行数等信息。默认情况下,wc命令会输出这三个统计值,但你也可以通过选项来指定只输出其中的某些值。 基本用法 wc [选项…...

redis集群部署
创建ConfigMap redis-cm.yaml apiVersion: v1 kind: ConfigMap metadata:name: redis-cluster data:update-node.sh: |#!/bin/shREDIS_NODES"/data/nodes.conf"sed -i -e "/myself/ s/[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}/${POD_IP}/&quo…...

VUE条件树查询
看如下图所示的功能,是不是可高级了?什么,你没看懂?拜托双击放大看! 是的,我最近消失了一段时间就是在研究这个玩意的实现,通过不懈努力与钻研并参考其他人员实现并加以改造,很好&am…...

vue框架学习 -- 日历控件 FullCalendar 使用总结
最近在项目中要实现日期排班的功能,正好要用到日历视图的控件,经过对比发现,vue 中 使用 FullCalendar 可以实现相关需求,下面对使用过程做一个总结。 一. 引入 FullCalendar 控件 package.json 中添加相关依赖 "dependen…...

[数据集][目标检测]猪数据集VOC-2856张
数据集格式:Pascal VOC格式(不包含分割的txt文件,仅仅包含jpg图片和对应的xml) 图片数量(jpg文件个数):2856 标注数量(xml文件个数):2856 标注类别数:1 标注类别名称:["pig"] 每个类别标注的框数:…...

工业制造场景中的设备管理深度解析
在工业制造的广阔领域中,设备管理涵盖多个关键方面,对企业的高效生产和稳定运营起着举足轻重的作用。 一、设备运行管理 1.设备状态监测 实时监控设备的运行状态是确保生产顺利进行的重要环节。通过传感器和数据采集系统等先进技术,获取设备…...
统计多页图像文件中的页面数量函数imcount()的使用)
OpenCV图像文件读写(3)统计多页图像文件中的页面数量函数imcount()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 返回给定文件中的图像数量。 imcount 函数将返回多页图像中的页面数量,对于单页图像则返回 1。 函数原型 size_t cv::imcount (cons…...

【数据治理-构建数据标准体系】
构建数据标准体系分为六大主要步骤,分别是: 1、规划数据标准 2、开发数据标准 3、发布数据标准 4、执行数据标准 5、数据标准遵从检查 6、维护数据标准 1、规划数据标准 (1)数据标准的规划首先是在公司业务架构和数据架构的范围…...

AI新方向:OpenAI o1是一个更擅长思考的模型系列:高级推理+逻辑严密+更广泛的知识,用于解决复杂的逻辑问题,慢思考
之前推出AI store感觉偏应用,也千篇一律,是AI的一个方向:广度。 现在推出o1 更严密的逻辑,也是AI的一个方向:深度。花更多时间,推理复杂的任务并解决比以前的科学、编码和数学模型更难的问题。确保AI的使用…...

Laravel部署后,CPU 使用率过高
我在部署 Laravel 应用程序时遇到严重问题。当访问量稍微大一点的时候,cpu马上就到100%了, 找了一大堆文档和说明,都是说明laravel处理并发的能力太弱,还不如原生的php。最后找到swoole解决问题。 1、php下载swoole插件࿰…...

Rust调用tree-sitter支持自定义语言解析
要使用 Rust 调用 tree-sitter 解析自定义语言,你需要遵循一系列步骤来定义语言的语法,生成解析器,并在 Rust 中使用这个解析器。下面是详细步骤: 1. 定义自定义语言的语法 首先,你需要创建一个 tree-sitter 语言定义…...

如何解决跨域请求中的 CORS 错误
聚沙成塔每天进步一点点 本文回顾 ⭐ 专栏简介如何解决跨域请求中的 CORS 错误1. 引言2. 什么是 CORS?2.1 同源策略示例: 2.2 CORS 请求的类型 3. CORS 错误的原因3.1 常见 CORS 错误示例 4. 解决 CORS 错误的常见方法4.1 在服务器端启用 CORS4.1.1 Node…...
)
计算机知识科普问答--20(96-100)
文章目录 96、为什么要进行内存管理?1. **多进程环境中的内存共享与隔离**举例:2. **提高内存利用率**举例:3. **虚拟内存支持**举例:4. **内存分配的灵活性与效率**举例:5. **内存保护**举例:6. **内存分段和分页的管理**7. **内存交换(Swapping)**举例:8. **提升系统…...

济南站活动回顾|IvorySQL中的Oracle XML函数使用示例及技术实现原理
近日,由中国开源软件推进联盟PG分会 & 齐鲁软件园联合发起的“PostgreSQL技术峰会济南站”在齐鲁开源社举办。瀚高股份IvorySQL作为合作伙伴受邀参加此次活动。 瀚高股份IvorySQL技术工程师 向逍 带来「IvorySQL中的Oracle XML函数兼容」的议题分享。在演讲中&a…...

【电商搜索】现代工业级电商搜索技术-Facebook语义搜索技术QueSearch
【电商搜索】现代工业级电商搜索技术-Facebook语义搜索技术Que2Search 目录 文章目录 【电商搜索】现代工业级电商搜索技术-Facebook语义搜索技术Que2Search目录0. 论文信息1. 研究背景:2. 技术背景和发展历史:3. 算法建模3.1 模型架构3.1.1 双塔与分类 …...

海滨体育馆管理系统:SpringBoot实现技巧与案例
2系统关键技术 2.1JAVA技术 Java是一种非常常用的编程语言,在全球编程语言排行版上总是前三。在方兴未艾的计算机技术发展历程中,Java的身影无处不在,并且拥有旺盛的生命力。Java的跨平台能力十分强大,只需一次编译,任…...

个人计算机与网络的安全
关于 wifi 大家都知道 wifi 已经使用了 wpa3 非常安全 但很多人不知道 pin 和 wps 这两项有漏洞 我发现很多用户都简单设置了这两项 他们的设置 使他们的网络出现了漏洞 关于 国产的 linux 老实说全是漏洞 默认开启 很多服务 但初始化的设置都有漏洞 关于 系统安全 老…...

AIGC教程:如何用Stable Diffusion+ControlNet做角色设计?
前言 对于生成型AI的画图能力,尤其是AI画美女的能力,相信同行们已经有了充分的了解。然而,对于游戏开发者而言,仅仅是漂亮的二维图片实际上很难直接用于角色设计,因为,除了设计风格之外,角色设…...

5V继电器模块详解(STM32)
目录 一、介绍 二、模块原理 1.原理图 2.引脚描述 3.工作原理介绍 三、程序设计 main.c文件 relay.h文件 relay.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 继电器(Relay),也称电驿,是一种电子控制器件,它具有控制系统…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...