Spark 任务与 Spark Streaming 任务的差异详解
Spark 任务与 Spark Streaming 任务的主要差异源自于两者的应用场景不同:Spark 主要处理静态的大数据集,而 Spark Streaming 处理的是实时流数据。这些差异体现在任务的调度、执行、容错、数据处理模式等方面。
接下来,我们将从底层原理和源代码的角度详细解析 Spark 任务和 Spark Streaming 任务的差别。
1. 任务调度模型差异
1.1 Spark 任务的调度模型
Spark 的任务调度基于 DAGScheduler 和 TaskScheduler 进行:
-
DAG 构建:在 Spark 中,每个作业会被构建成一个有向无环图(DAG)。DAG 的顶点代表不同的 RDD 转换操作,而边则表示 RDD 之间的依赖关系。Spark 的
DAGScheduler根据 DAG 划分阶段(Stage),每个阶段会生成多个任务。 -
Task 的生成和分发:Spark 中,任务是由 RDD 的各个分区(Partition)构成的。每个分区都会对应生成一个 Task,Task 通过
TaskScheduler被分发给不同的 Executor 节点执行。
Spark 任务调度流程
def submitJob[T, U: ClassTag](rdd: RDD[T],func: (TaskContext, Iterator[T]) => U,partitions: Seq[Int],resultHandler: (Int, U) => Unit
): JobWaiter[U] = {val jobId = nextJobId.getAndIncrement()val dagScheduler = new DAGScheduler()dagScheduler.submitJob(rdd, func, partitions, resultHandler)
}
在 Spark 任务中,submitJob() 方法负责将 RDD 转换成一组任务,并通过 DAGScheduler 提交这些任务。每个阶段包含多个任务,任务根据 RDD 的分区数来确定。
-
Stage 划分:
DAGScheduler依据宽依赖(宽依赖会导致数据 shuffle)对 DAG 进行分解,将作业分成多个 Stage。每个 Stage 内的 Task 彼此独立并行。 -
Task 分发:
TaskScheduler负责将 Task 分发到不同的 Executor 上执行,具体的分发逻辑根据集群资源情况和数据本地性进行优化。
任务执行(Executor)
在 Executor 上,Task 被实际执行。每个 Task 在一个 TaskContext 中运行,并将结果返回到 Driver:
class Executor {def launchTask(task: Task[_]): Unit = {val taskResult = task.run()sendResultToDriver(taskResult)}
}
1.2 Spark Streaming 任务的调度模型
与 Spark 不同,Spark Streaming 处理的是 实时数据流,其调度模式基于微批处理(micro-batch processing)。
- 微批处理:Spark Streaming 会将实时流数据分成小时间段的微批次(通常是数秒钟),并将每个时间段的数据视为一个静态的 RDD 来进行处理。
微批次调度流程
def start(): Unit = synchronized {jobScheduler.start()receiverTracker.start()
}
Spark Streaming 中的 start() 方法启动了两个核心调度组件:
- JobScheduler:负责为每个微批次生成一组作业,并提交给
DAGScheduler。 - ReceiverTracker:管理数据接收器,负责从外部数据源(如 Kafka)接收流数据。
JobScheduler 的任务调度逻辑
每个微批次对应一个 JobSet,JobScheduler 会为每个时间间隔生成并提交一个 JobSet,该 JobSet 包含多个 Job,每个 Job 又对应一个 RDD 转换。
class JobScheduler {def generateJob(time: Time): Option[JobSet] = {val jobs = createJobsForTime(time)if (jobs.nonEmpty) {Some(new JobSet(time, jobs))} else {None}}def submitJobSet(jobSet: JobSet): Unit = {dagScheduler.submitJobSet(jobSet)}
}
-
JobSet:
JobSet表示在一个微批次时间点内,所有需要执行的作业集合。每个JobSet都会被提交到DAGScheduler,并最终生成 Spark 任务进行执行。 -
周期性调度:
JobScheduler会周期性地(根据流的批次间隔)调用generateJob方法来创建新一轮的任务,确保数据的实时处理。
Streaming 任务执行
与 Spark 任务一样,Spark Streaming 的任务也是由 TaskScheduler 提交到 Executor 上运行的。由于 Spark Streaming 基于微批处理的模型,本质上每个微批次处理的任务还是 Spark 的普通任务。
2. 数据处理模式差异
2.1 Spark 的数据处理模式
Spark 是基于 RDD(弹性分布式数据集)来进行数据处理的。RDD 是不可变的数据抽象,它支持两种操作:
- Transformations:如
map、filter等操作,会生成新的 RDD。 - Actions:如
collect、count,会触发计算并返回结果。
Spark 的数据处理模式是批处理模式,即:
- 一次读取整个数据集。
- 对数据集进行转换和计算。
- 最终一次性输出结果。
2.2 Spark Streaming 的数据处理模式
Spark Streaming 则是基于 离散化流(DStream) 进行数据处理。DStream 是一系列 RDD 的抽象,代表一段时间内的数据。
- 微批处理:在 Spark Streaming 中,数据不是一次性处理,而是将实时数据流划分成多个小的时间段(如 1 秒),每个时间段的数据形成一个 RDD。每个批次处理的数据都是有限的一个子集。
class DStream {def compute(time: Time): Option[RDD[T]] = {// 生成时间点上的 RDD}
}
- 持续性计算:DStream 会周期性地生成 RDD 并执行计算,这与 Spark 中一次性计算数据集有显著不同。
3. 任务的生命周期
3.1 Spark 任务的生命周期
在 Spark 中,任务的生命周期是 一次性的,针对静态数据集。作业被提交后,DAGScheduler 会将其划分成多个 Stage,每个 Stage 会生成一组 Task。这些 Task 被执行后,数据计算完成,作业结束。
任务的执行流程
- Driver 启动作业,生成 DAG 并划分 Stage。
- Task 被分配到 Executor 上执行。
- Task 执行完后,将结果返回到 Driver。
- 作业完成,任务生命周期结束。
3.2 Spark Streaming 任务的生命周期
在 Spark Streaming 中,任务的生命周期是 持续的,因为流数据是连续不断地到达的。Spark Streaming 的任务调度是基于时间间隔的,每隔一个时间窗口都会生成一批新的任务。
- 周期性任务生成:每个时间窗口会触发一次任务调度,生成一组新任务。
- 任务生命周期与数据流同步:只要流数据源持续有数据,任务就会持续被生成和执行。
任务的执行流程
- Driver 启动流计算应用,周期性生成微批次的任务。
- 每个微批次会生成一组作业,这些作业与 Spark 的批处理作业相似。
- Task 被分配到 Executor 上执行,处理当前批次的数据。
- 下一个时间窗口到达后,新的任务被生成。
4. 容错机制差异
4.1 Spark 的容错机制
Spark 的容错机制依赖于 RDD 的血缘关系(Lineage)。RDD 是不可变的,因此每个 RDD 都知道自己是如何通过转换操作(如 map、filter 等)从父 RDD 派生出来的。这一信息被称为 血缘信息,它在数据丢失或任务失败时,能够重新计算丢失的数据。
4.1.1 血缘信息的作用
在 Spark 中,如果某个任务处理的分区(Partition)丢失,系统可以根据 RDD 的血缘信息,通过重新计算来恢复丢失的数据。RDD 的血缘信息是 Task 级别的容错基础。
abstract class RDD[T] {// 血缘关系def dependencies: Seq[Dependency[_]]// 重新计算丢失的分区def compute(partition: Partition, context: TaskContext): Iterator[T]
}
通过 dependencies 属性,RDD 可以记录其父 RDD 和依赖关系。如果某个分区数据丢失,系统可以根据这些依赖关系,重新计算该分区。
4.1.2 DAG 调度与任务重试
Spark 的调度器(DAGScheduler)在执行作业时,会将其分解为多个阶段(Stage)。每个阶段包含一组 Task,这些 Task 是基于 RDD 的分区生成的。
- 当某个 Task 执行失败时,
DAGScheduler会将该 Task 标记为失败,并根据血缘信息重新调度该任务。 - 默认情况下,Spark 会尝试 重新执行失败的任务。如果任务经过多次重试后仍然失败,Spark 会终止作业。
class DAGScheduler {def handleTaskFailure(task: Task[_], reason: TaskFailedReason): Unit = {val stage = task.stageAttemptIdif (stage != null && stage.failures < maxTaskFailures) {// 重试任务submitTask(stage, task.index)} else {// 任务失败次数过多,终止阶段failStage(stage, reason)}}
}
- 在
DAGScheduler中,失败的 Task 会被标记并重新调度。通过这种机制,Spark 保证了分区数据的可靠性,即使任务失败,也能够通过重试机制进行恢复。
4.1.3 宽依赖与窄依赖的容错性差异
-
窄依赖:每个子 RDD 的分区只依赖父 RDD 的一个或少量分区。比如
map、filter等操作。这类依赖容错性较好,因为只需要重新计算少量分区即可恢复数据。 -
宽依赖:每个子 RDD 的分区可能依赖多个父 RDD 的分区,比如
reduceByKey、groupByKey等。这种依赖通常需要进行数据的 shuffle 操作。在处理宽依赖时,数据恢复需要重新执行整个依赖链,这可能会涉及到大量数据重新计算,效率较低。
abstract class RDD[T] {// 宽依赖或窄依赖def dependencies: Seq[Dependency[_]]
}
4.2 Spark Streaming 的容错机制
相比 Spark,Spark Streaming 处理的是实时数据流,因此它的容错机制不仅要考虑任务失败,还要处理流数据的可靠接收、状态恢复等问题。
4.2.1 Write Ahead Logs (WAL)
为了保证数据不丢失,Spark Streaming 引入了 WAL(Write Ahead Log) 机制。WAL 通过将流数据持久化到日志中,确保即使节点或任务失败,数据也可以被恢复。
- 当 Spark Streaming 接收到流数据时,首先将数据写入 WAL 中进行持久化,然后才会进行计算。这确保了在任务失败或节点宕机后,系统可以从 WAL 中重新读取数据。
class WriteAheadLogBasedBlockHandler {def storeBlock(streamId: Int, receivedBlock: ReceivedBlock): ReceivedBlockStoreResult = {// 将接收到的块写入 WALlogManager.write(new WriteAheadLogRecord(serializedBlock))// 然后存储到内存或磁盘blockManager.putBlockData(blockId, serializedBlock, StorageLevel.MEMORY_AND_DISK_SER)}
}
- WAL 机制确保了即使在任务执行失败后,流数据仍然能够通过日志重放来恢复。
4.2.2 Checkpointing(检查点)
Spark Streaming 的容错机制还包括 Checkpointing,它用于保存应用程序的元数据和状态信息。Checkpointing 可以分为两类:
- 元数据检查点:保存 StreamingContext、DStream 的结构信息,确保任务在重启后可以恢复之前的处理流程。
- 状态检查点:当使用有状态操作(如
updateStateByKey)时,状态会被持久化到检查点中。
class StreamingContext {def checkpoint(directory: String): Unit = {this.checkpointDir = directorycheckpointWriter = new CheckpointWriter(checkpointDir, sc.env.blockManager)}
}
- 在任务失败时,系统可以从检查点恢复状态和元数据,从而确保流处理继续进行。
4.2.3 任务失败重试
与 Spark 类似,Spark Streaming 也依赖于 DAGScheduler 和 TaskScheduler 进行任务重试。不过,由于 Spark Streaming 是基于微批处理的,每个批次处理的任务失败后,系统会重试整个批次的任务。
def handleBatchFailure(batchTime: Time, jobSet: JobSet): Unit = {logWarning(s"Batch $batchTime failed. Retrying ...")jobScheduler.submitJobSet(jobSet)
}
- 每个微批次的数据会生成一个
JobSet,如果任务失败,系统会重新提交整个JobSet。
4.2.4 Kafka 及其他流数据源的容错
对于像 Kafka 这样的流数据源,Spark Streaming 依赖于数据源的偏移量管理来实现容错。例如,Kafka 的偏移量(offset)用于追踪已经处理的数据位置。如果任务失败,Spark Streaming 会通过重新读取 Kafka 的偏移量来确保数据不会丢失。
class DirectKafkaInputDStream {def createDirectStream[K, V](ssc: StreamingContext, kafkaParams: Map[String, Object], topics: Set[String]): InputDStream[ConsumerRecord[K, V]] = {new DirectKafkaInputDStream(ssc, kafkaParams, topics)}
}
在 DirectKafkaInputDStream 中,Spark Streaming 通过 Kafka 的偏移量追踪,确保每个微批次的数据都能可靠地重新读取和处理。
5. 数据处理模式的区别
5.1 Spark 的数据处理模式
Spark 处理的是 静态数据集,基于 RDD 的不可变性和分区(Partition)来并行处理数据。每个作业会被一次性提交,并将所有数据进行一次完整的计算。Spark 中常见的数据操作包括:
- Transformations:如
map、flatMap、filter等操作用于转换 RDD。 - Actions:如
collect、reduce、count等操作触发执行并返回结果。
Spark 的处理模式是批处理模式,它适用于静态的、离线的大数据集。
5.2 Spark Streaming 的数据处理模式
Spark Streaming 处理的是 实时数据流,其数据处理模式基于微批次。实时数据流被分割成小的时间片段,每个时间片段的数据被视为一个静态的 RDD 进行处理。
- DStream:DStream 是一系列 RDD 的抽象,代表了实时数据流在多个时间段内的处理结果。每个时间段的数据会形成一个新的 RDD 并进行计算。
class DStream {def compute(time: Time): Option[RDD[T]] = {// 生成对应时间段的 RDD}
}
- 微批处理:每隔一个时间窗口,Spark Streaming 会生成一个新的 RDD,并对其进行处理。这种微批处理模式保证了实时数据的近实时处理。
6. 任务的生命周期差异
6.1 Spark 任务的生命周期
Spark 任务的生命周期是 一次性的,每个作业在提交后会经历以下几个步骤:
- Driver 解析作业并生成 DAG。
- DAG 被划分为多个 Stage。
- 每个 Stage 包含多个 Task,任务被分发到 Executor 执行。
- 任务执行完成后,数据被返回到 Driver,作业结束。
在批处理场景下,任务生命周期较短,处理完数据后任务即结束。
6.2 Spark Streaming 任务的生命周期
Spark Streaming 任务的生命周期是 持续的。Spark Streaming 是一个 长时间运行的任务,只要流数据源不断输入数据,任务就会持续生成新的微批次任务并进行计算。
- StreamingContext 启动后,
JobScheduler定期生成微批次任务。 - 每个微批次会生成新的
JobSet并提交给DAGScheduler执行。 - 任务处理完成后,新的数据批次到达,继续生成新的任务。
- 任务不断运行,直到用户手动停止。
总结
- 任务调度:Spark 任务基于静态数据集,采用一次性批处理模式;Spark Streaming 任务基于流数据,采用微批处理模式,每隔一个时间窗口生成新的任务。
- 数据处理:Spark 处理静态的 RDD,数据只计算一次;Spark Streaming 处理离散化的流数据,每个时间窗口生成一个新的 RDD 并计算。
- 容错机制:Spark 任务依赖 RDD 血缘关系进行数据恢复;Spark Streaming 除了依赖血缘关系外,还引入了 WAL 和 Checkpointing 来保证流数据的容错性。
- 生命周期:Spark 任务是一次性执行的,而 Spark Streaming 是长时间运行的任务,会持续生成新的微批次进行处理。
相关文章:

Spark 任务与 Spark Streaming 任务的差异详解
Spark 任务与 Spark Streaming 任务的主要差异源自于两者的应用场景不同:Spark 主要处理静态的大数据集,而 Spark Streaming 处理的是实时流数据。这些差异体现在任务的调度、执行、容错、数据处理模式等方面。 接下来,我们将从底层原理和源…...

Git提示信息 Pulling is not possible because you have unmerged files.
git [fatal] hint: Pulling is not possible because you have unmerged files.hint: Fix them up in the … error: Pulling is not possible because you have unmerged files. 错误:无法提取,因为您有未合并的文件。 hint: Fix them up in the work tree, and t…...

python编程开发“人机猜拳”游戏
👨💻个人主页:开发者-曼亿点 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 曼亿点 原创 👨💻 收录于专栏:…...
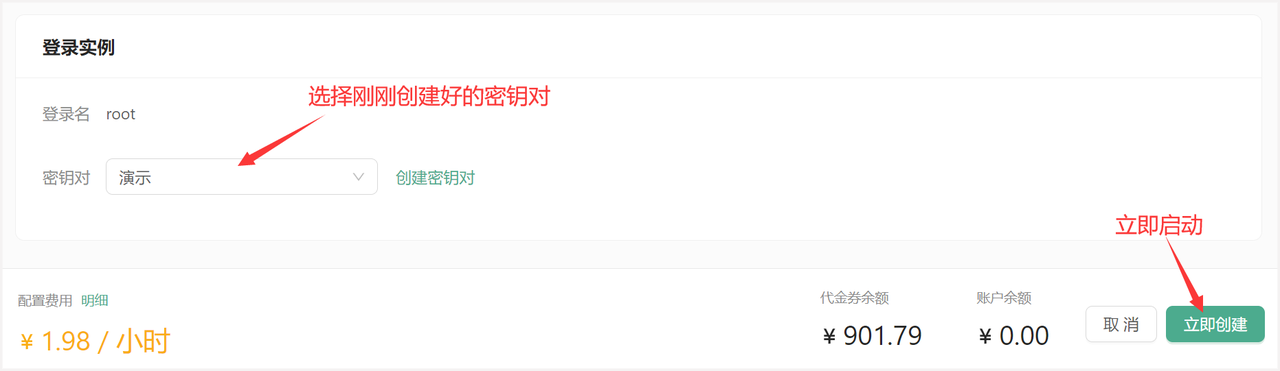
丹摩智算平台部署 Llama 3.1:实践与体验
文章目录 前言部署前的准备创建实例 部署与配置 Llama 3.1使用心得总结 前言 在最近的开发工作中,我有机会体验了丹摩智算平台,部署并使用了 Llama 3.1 模型。在人工智能和大模型领域,Meta 推出的 Llama 3.1 已经成为了目前最受瞩目的开源模…...

SpringCloud 2023各依赖版本选择、核心功能与组件、创建项目(注意事项、依赖)
目录 1. 各依赖版本选择2. 核心功能与组件3. 创建项目3.1 注意事项3.2 依赖 1. 各依赖版本选择 SpringCloud: 2023.0.1SpringBoot: 3.2.4。参考Spring Cloud Train Reference Documentation选择版本 SpringCloud Alibaba: 2023.0.1.0*: 参考Spring Cloud Alibaba选择版本。同时…...

串行化执行、并行化执行
文章目录 1、串行化执行2、并行化测试(多线程环境)3、任务的执行是异步的,但主程序的继续执行是同步的 可以将多个任务编排为并行和串行化执行。 也可以处理编排的多个任务的异常,也可以返回兜底数据。 1、串行化执行 顺序执行、…...
)
二叉搜索树(c++版)
前言 在前面我们介绍过二叉树这个数据结构,今天我们更进一步来介绍二叉树的一种在实现中运用的场景——二叉搜索树。二叉搜索树顾名思义其在“搜索”这个场景下有不俗的表现,之所以会这样是因为它在二叉树的基础上添加了一些属性。下面我们就来简单的介…...

每日1题-7
...

简单实现log记录保存到文本和数据库
简单保存记录到txt,sqlite数据库,以及console监控记录 using System; using System.Collections.Generic; using System.ComponentModel; using System.Text; using System.Data.SQLite; using System.IO;namespace NlogFrame {public enum LogType{Tr…...

敏感字段加密 - 华为OD统一考试(E卷)
2024华为OD机试(E卷+D卷+C卷)最新题库【超值优惠】Java/Python/C++合集 题目描述 【敏感字段加密】给定一个由多个命令字组成的命令字符串: 1、字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号; 2、命令字之间以一个或多个下划线 进行分割; 3、可…...

go 安装三方库
go版本 go versiongo version go1.23.1 darwin/arm64安装 redis 库 cd $GOPATH说明: 这里可以改 GOPATH的值 将如下 export 语句写入 ~/.bash_profile 文件中 export GOPATH/Users/goproject然后使其生效 source ~/.bash_profile初始化生成 go.mod 文件 go mod…...

Java 中的 volatile和synchronized和 ReentrantLock区别讲解和案例示范
在 Java 的并发编程中,volatile、synchronized 和 ReentrantLock 是三种常用的同步机制。每种机制都有其独特的特性、优缺点和适用场景。理解它们之间的区别以及在何种情况下使用哪种机制,对提高程序的性能和可靠性至关重要。本文将详细探讨这三种机制的…...

从GDAL中 读取遥感影像的信息
从GDAL提供的实用程序来看,很多程序的后缀都是 .py ,这充分地说明了Python语言在GDAL的开发中得到了广泛的应用。 1. 打开已有的GeoTIF文件 下面我们试着读取一个GeoTiff文件的信息。第一步就是打开一个数据集。 >>> from osgeo import gdal…...

算法闭关修炼百题计划(一)
多看优秀的代码一定没有错,此篇博客属于个人学习记录 1.两数之和2.前k个高频元素3.只出现一次的数字4.数组的度5.最佳观光组合6.整数反转7.缺失的第一个正数8.字符串中最多数目的子序列9.k个一组翻转链表10.反转链表II11. 公司命名12.合并区间13.快速排序14.数字中的…...

vue3实现打字机的效果,可以换行
之前看了很多文章,效果是实现了,就是没有自动换行的效果,参考了文章写了一个,先上个效果图,卡顿是因为模仿了卡顿的效果,还是很丝滑的 目录 效果图:代码如下 效果图: 
【如何学习操作系统】——学会学习的艺术
🐟作者简介:一名大三在校生,喜欢编程🪴 🐡🐙个人主页🥇:Aic山鱼 🐠WeChat:z7010cyy 🦈系列专栏:🏞️ 前端-JS基础专栏✨前…...

stm32 flash无法擦除
通过bushound调试代码发现,当上位机发送命令到模组后flash将不能擦除,通过 HAL_FLASH_GetError()函数查找原因是FLASH Programming Sequence error(编程顺序错误),解决办法是在解锁后清零标志位…...

Android—ANR日志分析
获取ANR日志: ANR路径:/data/anrADB指令:adb bugreport D:\bugrep.zip ANR日志分析步骤: “main” prio:主线程状态beginning of crash:搜索 crash 相关信息CPU usage from:搜索 cpu 使用信息…...

9.29 LeetCode 3304、3300、3301
思路: ⭐进行无限次操作,但是 k 的取值小于 500 ,所以当 word 的长度大于 500 时就可以停止操作进行取值了 如果字符为 ‘z’ ,单独处理使其变为 ‘a’ 得到得到操作后的新字符串,和原字符串拼接 class Solution { …...

近万字深入讲解iOS常见锁及线程安全
什么是锁? 在程序中,当多个任务(或线程)同时访问同一个资源时,比如多个操作同时修改一份数据,可能会导致数据不一致。这时候,我们需要“锁”来确保同一时间只有一个任务能够操作这个数据&#…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...