Kafak入门技术详解
抱歉,没有太多的时间进行详细校对
目录
一、Kafka简介
1.消息队列
1.1为什么需要消息队列
1.2消息队列
1.3消息队列的分类
1.4P2P和发布订阅MQ的比较
1.5消息系统的使用场景
1.6常见的消息系统
2.Kafka简介
2.1简介
2.2设计目标
2.3 kafka核心的概念
二、 Kafka的分布式安装
1.docker安装
2.基于服务器安装
三.Kafka基本操作
1.kafka的topic的操作
2.Kafka的数据消费的总结
3.Kafka的编程的api
1.创建kafka的项目
2.kafka生产者的api操作
3.生产者模式幂等性案例
附1:kafka producer 说明
附2:Nagle算法(Nagle算法_nagle算法于1984-CSDN博客)
附3: Nagle算法(Nagle算法_nagle算法是以他-CSDN博客)
4.kafka消费者的api操作
5.offset消费问题
6.record进入分区的策略
7.自定义分区
参考资料
附1:快速上手:学习如何使用C++实现kafka消费者客户端(快速上手:学习如何使用C++实现kafka消费者客户端_c++ 使用kafka-CSDN博客)
附2:Docker实战之Kafka集群
1. 概述
2. Kafka 基本概念
3. Docker 环境搭建
4. Kafka 初认识
4.1 可视化管理
4.2 Zookeeper 在 kafka 环境中做了什么
5. 生产与消费
5.1 创建主题
5.2 生产消息
5.3 消费消息
5.4 消费详情
6. SpringBoot 集成
附3:Kafka快速入门(六)——Kafka集群部署(Kafka快速入门(六)——Kafka集群部署_51CTO博客_kafka集群部署)
一、Kafka集群部署方案规划
1、操作系统选择
2、磁盘
3、磁盘容量
4、网络带宽
二、Kafka集群参数配置
1、Broker端参数
2、Topic级别参数
3、JVM参数
4、操作系统参数
三、Docker镜像选择
1、安装docker
2、docker-compose安装
3、docker镜像选择
四、Kafka单机部署方案
1、编写docker-compose.yml文件
2、启动服务
3、kafka服务查看
4、Kafka版本查询
5、kafka-manager监控
五、错误解决
1、容器删除失败
2、kafka服务一直重启
六、Kafka集群参数配置
附4:【Kafka精进系列003】Docker环境下搭建Kafka集群()
一、Kafka集群搭建
1、首先运行Zookeeper(本文并未搭建ZK集群):
2、分别创建3个Kafka节点,并注册到ZK上:
3、在Broker 0节点上创建一个用于测试的topic:
4、Kafka集群验证
二、使用Docker-Compose 搭建Kafka集群
1、什么是Docker-Compose?
2、如何使用Docker-Compose
3 、疑难杂症问题记录
附5:使用docker容器创建Kafka集群管理、状态保存是通过zookeeper实现,所以先要搭建zookeeper集群
附7:如何使用Docker内的kafka服务(如何使用Docker内的kafka服务_docker kafka advertised.listeners-CSDN博客)
基本情况
版本信息
重点介绍
配置host
在docker上部署kafka
源码下载
开发生产消息的应用
开发消费消息的应用
验证消息的生产和消费
一、Kafka简介
1.消息队列
1.1为什么需要消息队列
面对比较大的流量冲击,在网站系统中一般都会有一个消息存储/缓存系统,网站就可以按照 自己服务负载的能力,来消费这些消息--消息队列或者叫消息中间件。
消息队列应该具备的最基本的能力:
1.存储能力,所以是一个容器,一般的实现都用队列
2.消息的入队或者生产
3.消息的出队或者消费
从消息的生产与消费的角度上而言,消息队列就是一个典型的生产者消费者模型的实现框架。
1.2消息队列
-
消息Message
网络中的两台计算机或者两个通讯设备之间传递的数据。例如说:文本、音乐、视频等内容。
-
队列Queue
一种特殊的线性表(数据元素首尾相接),特殊之处在于只允许在首部删除元素和在尾部追加元素(FIFO);
入队、出队。
-
消息队列MQ
消息+队列,保存消息的队列。消息的传输过程中的容器;主要提供生产、消费接口供外部调用做数据的存储和获取。
1.3消息队列的分类
MQ主要分为两类: 点对点(p2p),发布订阅(Pub/Sub)
-
Peer-to-Peer
一般基于Pull或者Polling接收数据
发送到队列中的消息被一个而且仅仅一个接收者所接收,即使有多个接收者在同一个队列中侦听同一消息,即支持异步“即发即收”的消息传递方式,也支持同步请求/应答传送方式。
-
发布订阅
发布到同一个主题的消息,可衩多个订阅者所接收
发布/订阅即可基于Push消费数据,也可基于Pull或者Polling消费数据。
解耦能力比P2P模型更强。
1.4P2P和发布订阅MQ的比较
-
共同点
消息生产者生产消息发送到queue中,然后消息消费者从queue中读取并且消费消息。
-
不同点
p2p模型包括:消息队列(Queue)、发送者(Sender)、接收者(Receiver)
一个生产者生产的消息只有一个消费者(Consumer)(即一旦被消费,消息就不在消息队列中)。比如说打电话。
pub/sub包含:消息队列(queue)、主题(topic)、发布者(publisher)、订阅者(subscriber)
每个消息可以有多个消费者,彼此互不影响,比如我发布一个微博:关注的人都能够看到。
1.5消息系统的使用场景
解耦 名系统之间通过消息系统这个统一的接口交换数据,无须了解彼此的存在
冗余 部分消息系统具有消息持久化能力,可规避消息处理前丢失的风险
扩展 消息系统是统一的数据接口,各系统可独立扩展
峰值可处理能力消息系统可顶住峰值流量,业务系统可根据处理能力从消息系统中获取并处理对应量的请求
可恢复性 系统中部分功能失效并不会影响整 个系统,它恢复会仍然可从消息系统中获取并处理数据
异步通信 在不需要立即处理请求的场景下,可以将请求放入消息系统、合适的时候再处理。
1.6常见的消息系统
RabbitMQ Erlang编写, 支持多协义AMQP,XMPP,SMTP, STOMP。支持负载均衡、数据持久化。同时支持Peer-to-Peer和发布/订阅模式。
Redis基于key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言,Redis对短消息(小于10kb)的性能比RabbitMQvb ,长消息性能比RabbitMQ差。
ZeroMQ轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,Peer-to-Peer,它实质上是一个库,需要开发人员自己组合多种技术,使用复杂度高。
ActiveMQ JMS实现,Peer-to-Peer, 支持持久化,XA(分布式)事务。
Kafka/Jafka高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理。
MetaQ/RocketMQ纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务。
2.Kafka简介
2.1简介
Kafka是分布式的发布-订阅消息系统。它最初由Linkedin(领英)公司发布,使用scala语言编写,使用Scala语言编写,与2010年12月份开源,成为Apache顶级项目,Kafka是一个高吞吐量的,持久性的、分布式发布订阅消息系统。它主要用于处理活跃live的数据(登录、浏览、点击、分享、喜欢等用户行为的数据)。
三大特点:
-
高吞吐量
可以满足每秒百成级别消息的生产和消费------生产消费
-
持久化
有一套完整的消息存储机制,确保数据的高效安全的持久化---中间存储
-
分布式
基于分布式的扩展和容错机制;Kafka的数据都会复制到几台服务器上。当某一台故障失效时,生产者和消费者转而使用其它的机器---整体
-
健壮性
2.2设计目标
-
高吞吐率在廉价的商用机器上单机可支持每秒100万条消息的读写
-
消息持久化所有消息均被持久化到磁盘,无消息丢失,支持消息重放
-
完全分布式 Producer, Broker, Consumer均技持水平扩展
-
同时适应在线流处理和离线批处理
2.3 kafka核心的概念
一个MQ需要哪此部分?生产、清费、消息类型、存储等等。
对于kafka而言,kafka服务就像一个大的水池。不断的生产,存储,消费着各种类别的消息。那么kafka由何给成呢?
Kafka服务:
Topic:主题,Kafka处理的消息的不同分类。
Broker:消息服务器代理,Kafka集群中的一个kafka服务节点称为一个broker,主要存储消息数据。存在硬盘中。每个topic都是有分区的。
Partition:Topic物理上的分组,一个Topic在Broker中被分为1个或者多个partition, 分区在创建topic的时候指定。
Message:消息,是通信的基本单位,每个消息都属于一个partition
Kafka服务相关:
Producer:消息和数据的生产者,向Kafka的一处topic发布消息。
Consumer:消息和数据的消费者,定于topic并处理其发布的消息。
Zookeeper:协调kafka的正常运行。
二、 Kafka的分布式安装
1.docker安装
version: '3.1' services: kafka1: image: wurstmeister/kafkarestart: alwayshostname: kafka1container_name: kafka1expose: - 9999ports: - 9092:9092- 9999:9999environment: KAFKA_ADVERTISED_HOST_NAME: kafka1KAFKA_ADVERTISED_PORT: 9092KAFKA_ZOOKEEPER_CONNECT: zk1:2181,zk2:2181,zk3:2181KAFKA_JVM_PERFORMANCE_OPTS: " -Xmx256m -Xms256m"KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka1:9092KAFKA_LISTENERS: PLAINTEXT://:9092KAFKA_BROKER_ID: 1KAFKA_CREATE_TOPICS: "topic001:2:1"JMX_PORT: 9999volumes: - /opt/kafka/kafka1/logs:/kafkaexternal_links: - zk1- zk2- zk3 kafka2: image: wurstmeister/kafkarestart: alwayshostname: kafka2container_name: kafka2ports: - 9093:9093environment: KAFKA_ADVERTISED_HOST_NAME: kafka2KAFKA_ADVERTISED_PORT: 9093KAFKA_ZOOKEEPER_CONNECT: zk1:2181,zk2:2181,zk3:2181KAFKA_JVM_PERFORMANCE_OPTS: " -Xmx256m -Xms256m"KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka2:9093KAFKA_LISTENERS: PLAINTEXT://:9093KAFKA_BROKER_ID: 2KAFKA_CREATE_TOPICS: "topic001:2:1"JMX_PORT: 9988volumes: - /opt/kafka/kafka2/logs:/kafkaexternal_links: - zk1- zk2- zk3 kafka3: image: wurstmeister/kafkarestart: alwayshostname: kafka3container_name: kafka3ports: - 9094:9094environment: KAFKA_ADVERTISED_HOST_NAME: kafka3KAFKA_ADVERTISED_PORT: 9094KAFKA_ZOOKEEPER_CONNECT: zk1:2181,zk2:2181,zk3:2181KAFKA_JVM_PERFORMANCE_OPTS: " -Xmx256m -Xms256m"KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka3:9094KAFKA_LISTENERS: PLAINTEXT://:9094KAFKA_BROKER_ID: 3KAFKA_CREATE_TOPICS: "topic001:2:1"JMX_PORT: 9977volumes: - /opt/kafka/kafka3/logs:/kafkaexternal_links: - zk1- zk2- zk3kafka-manager:image: sheepkiller/kafka-manager:latestrestart: alwayscontainer_name: kafa-managerhostname: kafka-managerports:- "9000:9000"links: # 连接本compose文件创建的container- kafka1- kafka2- kafka3external_links: # 连接本compose文件以外的container- zk1- zk2- zk3environment:ZK_HOSTS: zk1:2181,zk2:2181,zk3:2181KAFKA_BROKERS: kafka1:9092,kafka2:9093,kafka3:9094APPLICATION_SECRET: letmeinKM_ARGS: -Djava.net.preferIPv4Stack=true
2.基于服务器安装
-
zookeeper集群安装
1.下载:
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
2.解压
tar -zxvf apache-zookeeper-3.5.6.tar.gz -C /usr/local/
3.进入zookeeper配置文件目录
cd /usr/local/apache-zookeeper-3.5.6/conf/
4.更改文件zoo_sample.cfg为zoo.cfg
cp zoo_sample.cfg zoo.cfg
5.修改配置文件
#用于计算基础的实际单位 tickTime=2000 #初始化时间 initLimit=10 #选举时间 syncLimit=5 #数据存储路径 dataDir=/usr/local/apache-zookeeper-3.5.6/data dataLogDir=/usr/local/apache-zookeeper-3.5.6/logs clientPort=2181
6.配置zookeeper集群
#集群配置 2888:选举端口 3888:投票端口 server.1=hadoopmaster:2888:3888 server.2=hadoopnode1:2888:3888 server.3=hadoopnode2:2888:3888
7.创建数据目录和日志目录, 并添加对文件夹的读写权限
mkdir data chmod 755 data mkdir logs chmod 755 logs
8.在创建的data目录下创建myid文件,添加这台机器集群的唯一标识
echo "1" > myid
9.zookeeper启动
./bin/zkServer start
10.编写集群启动脚本
#!/bin/bash case $1 in "start"){ for i in hadoopmaster hadoopnode1 hadoopnode2 do echo ---------- zookeeper $i 启动 ------------ ssh $i "/usr/local/zookeeper/bin/zkServer.sh start" done };; "stop"){ for i in hadoopmaster hadoopnode1 hadoopnode2 do echo ---------- zookeeper $i 停止 ------------ ssh $i "/usr/local/zookeeper/bin/zkServer.sh stop" done };; "status"){ for i in hadoopmaster hadoopnode1 hadoopnode2 do echo ---------- zookeeper $i 状态 ------------ ssh $i "/usr/local/zookeeper/bin/zkServer.sh status" done };; "*"){ echo "zookeeper script Input Args Error..."echo "$0 [start|stop|restart]..." };; esac11.AI回答:
#!/bin/bash# 定义Zookeeper配置文件的路径 ZOOKEEPER_CONF="/path/to/zookeeper/conf/zoo.cfg"# 定义Zookeeper的启动命令 ZOOKEEPER_HOME="/path/to/zookeeper"# 定义Zookeeper服务实例的端口号 SERVER_PORTS=("2181" "2182" "2183")# 定义Zookeeper服务器的myid,对应于zoo.cfg中的server.x配置 SERVER_IDS=("0" "1" "2")# 遍历服务端口和服务器ID数组 for index in ${!SERVER_PORTS[@]}; doport=${SERVER_PORTS[index]}server_id=${SERVER_IDS[index]}# 设置环境变量,用于zookeeper的myid文件export ZOO_LOG_DIR="/path/to/zookeeper/logs-${port}"export ZOO_DATA_DIR="/path/to/zookeeper/data-${port}"export ZOO_CLIENT_PORT="${port}"export ZOO_SERVER_ID="${server_id}"# 配置zoo.cfg文件中的服务器列表echo "server.${server_id}=localhost:2888:3888" >> "${ZOOKEEPER_CONF}"# 启动Zookeeper实例echo "Starting Zookeeper server on port ${port} with myid ${server_id}...""${ZOOKEEPER_HOME}/bin/zkServer.sh" start done12.启动错误报如下:
Error: JAVA_HOME is not set and java could not be found in PATH.
在bin目录下的zkEnv.sh文件开始,加入下面语句
export JAVA_HOME=/usr/local/jdk1.8.0_321/
并将zkEnv.sh同步更新到其他节点
2.安装kafka
1.下载:
wget https://archive.apache.org/dist/kafka/2.4.0/kafka_2.13-2.4.0.tgz
2.解压
tar -zxvf /root/softwares/kafka_2.13-2.4.0.tgz -C /usr/local/
3.重命名
cd /usr/local/ mv kafka_2.13-2.4.0/ kafka
4.添加环境变量
vim /etc/profile.d/hadoop-etc.sh
export KAFKA_HOME=/opt/apps/kafka export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile.d/hadoop-etc.sh
4.配置
修改$KAFKA_HOME/config/server.properties
broker.id=0 ##当前kafka实例的Id, 必须为整数, 一个集群中不可重复 log.dirs=/usr/local/kafka/data/kafka-logs ##生产到kafka中的数据存储的目录,目录需要手动创建 zookeeper.connect=hadoopmaster:2181,hadoopnode1:2181,hadoopnode2:2181/kafka ##kafka数据在zk中的存储目录
5.创建数据目录
mkdir -p /usr/local/kafka/data/kafka-logs
6.同步到其它机器
scp -r kafka/ hadoopnode1:$PWD scp -r kafka/ hadoopnode2:$PWD
7.修改配置文件中的broker.id
broker.id=1 ##hadoopnode1 broker.id=3 ##hadoopnode2
8.启动kafka服务
/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties

9.kafka服务测试
进入zookeeper客户端:
./zkCli.sh
ls /kafka/brokers/ids

10.Kafka在zookeeper中的目录说明

/kafka/cluster/id {"version":"1","id":"SGvHsIOcSJuakpX44ew2-w"} --->>代表的是一个kafka集群包含集群的版本,和集群的id/controller {"version":1,"brokerid":1,"timestamp":"1717651279966"} --> controller是kafka中非常重要的一个角色,意为控制器,控制partition的leader选举,topic的crud操作,brokerid意为由其id对应的broker承担controller的角色/controller_epoch 2 代表的是controller的纪元,换名话说是代表controller的更迭,每当controller的brokerid更换一次,controller_epoch就+1/brokers/ids [0, 1, 3] ---> 存放当前kafka的broker实例列表/topics [hadoop, _consumer_offsets] ---> 当前kafka中的topic列表/seqid 系统的序列id/consumers --> 老版本用于存储kafka消费者的信息, 主要保存对应的offset, 新版本中基本不用,此时用户的消费信息,保存在一个系统的topic中: _consumer_offsets/config ---> 存放配置信息
11集群启动脚本
#!/bin/bash
kafka_start() {for i in hadoopmaster hadoopnode1 hadoopnode2doecho " --------启动 $i Kafka-------"ssh $i "source /etc/profile; nohup sh /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties"done
}
kafka_stop() {for i in hadoopmaster hadoopnode1 hadoopnode2doecho " --------关闭 $i Kafka-------"ssh $i "source /etc/profile;bash /usr/local/kafka/bin/kafka-server-stop.sh"
done
}
case $1 in
"start")echo "start kafka cluster"kafka_start
;;
"stop")echo "stop kafka cluster"kafka_stop
;;
"restart")echo "restart kafka cluster"kafka_stopkafka_start
;;
*)echo "Input Args Error..."echo "$0 [start|stop|restart]..."
;;
esac
12.安装客户端(kafka tool)
Offset Explorer
三.Kafka基本操作
1.kafka的topic的操作
topic是kafka非常重要的核心概念,是用来存储各种类型的数据的,所以最基本的就需要学会如何在kafka中创建、修改主、删除的topic,以及如何向topic生产消费数据。
关于topic的操作脚本: kafka-copics.sh




1.创建topic
bin/kafka-topics.sh --create\ --topic hadoop \ ##指定要创建的topic的名称 --zookeeper hadoopmaster:2181,hadoopnode1:2181,hadoopnode2:2181/kafka \ ##指定kafka关联的zk地址 --partitions 3 \ ##指定该topic的分区个数 --replication-factor 3 ##指定副本因子
./kafka-topics.sh --create --topic hadoop --zookeeper hadoopmaster:2181,hadoopnode1:2181,hadoopnode2:2181/kafka --partitions 3 --replication-factor 3
注意:指定副本因子的时候, 不能大于broker实例个数,否则报错.
2 查看topic的列表
bin/kafka-topics.sh --list --zookeeper hadoopmaster:2181,hadoopnode1:2181,hadoopnode2:2181/kafka
3.查看每一个topic的信息
bin/kafka-topics.sh --describe --topic hadoop --zookeeper hadoopmaster:2181,hadoopnode1:2181,hadoopnode2:2181/kafka

Partition: 当前topic对应的分区编号 Replicas: 副本因子,当前kafka对应的partition所在的broker实例的broker.id的列表 Leader: 该partiotion的所有副本中的leader领导者,处理所有kafka该partition读写请求 ISR: 该partition的存活的副本对应的broker实例的broker.id的列表
登录zookeeper客户端查看:

4.修改一个topic
./kafka-topics.sh --alter --topic hadoop --partitions 4 --zookeeper hadoopmaster:2181/kafka
但是注意: partition个数,只能增加,不能减少

5.删除一个topic
./kafka-topics.sh --delete --topic hadoop1 --zookeeper hadoopmaster:2181,hadoopnode1:2181,hadoopnode2:2181/kafka
在老版本的时候,是不能直接删除掉的topic,除非配置了delete.topic.enable=true,可以直接删除掉,但是不配置,那么就不会直接删除,先会做一个标记,那么这个topic就不能用了,而在新版本的时候,不需要设置这个属性,直接删除掉了。

6.生产数据
./kafka-console-producer.sh --topic spark --broker-list hadoopmaster:9092,hadoopnode1:9092,hadoopnode2:9092
注意:使用的端口,不能使用2181
会报如下错误
ERROR Error when sending message to topic hadoop with key: null, value: 5 bytes with error: (org.apache.kafka.clients.producer.internals.ErrorLoggingCallback)
7.消费数据
./kafka-console-consumer.sh --topic spark --bootstrap-server hadoopmaster:9092,hadoopnode1:9092,hadoopnode2:9092
所有的消费数据
./kafka-console-consumer.sh --topic spark --bootstrap-server hadoopmaster:9092,hadoopnode1:9092,hadoopnode2:9092 --from-beginning
指定分区内的消费数据
./kafka-console-consumer.sh --topic spark --bootstrap-server hadoopmaster:9092,hadoopnode1:9092,hadoopnode2:9092 --partition 2 --offset earliest
2.Kafka的数据消费的总结
kafka消费者在消费数据的时候,都是分组别的。不同组的消费不受影响,相同组内的消费,需要注意,如partition有3个,消费者有3个,那么便是每一个消费者消费其中一个partition对应的数据;如果有2个消费者时一个消费者消费其中一个partition数据,另一个消费者消费2个partition的数据。如果有超过3个的消费者,同一时间只能最多有3个消费者能消费得到数据。

结论:
在一个消费者组内消费数据,同一时间不会有两个消费者同时消费一个分区的数据
在两个消费者组内,同一时间可以有两个消费者同时消费一个分区的数据.
./kafka-console-consumer.sh --topic spark --bootstrap-server hadoopmaster:9092,hadoopnode1:9092,hadoopnode2:9092 --group group-2024
offset:是kafka的topic中的partition中的每一条消息的标识,如何区分该条消息在kafka对应的partition的位置,就是用该偏移量.offset的数据类型是Long,8个字节长度.offset在分区内是有序的,分区间是不一定有序.如果想要kafka中的数据全局有充,就只能让partition个数为1.
在组内,kafka的topic的partition个数,代表了kafka的topic的并行度,同一时间最多可以有多个线程来消费topic的数据,所以如果要想提高kafka的topic的消费能力,应该增大partition的个数.
附:kafka消费者详解
3.Kafka的编程的api
1.创建kafka的项目

导入maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka --><!-- 此依赖包含了kafka-clients --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.13</artifactId><version>2.4.0</version></dependency>
2.kafka生产者的api操作
入口类: Producer
入门案例:
/*** 生产者API操作* 首先需要生产者--->就是程序的入口Producer* 数据被生产到哪里----> Topic* 什么样数据? ----> 数据类型*/
public class MyProducerTest {public static void main(String[] args) throws IOException {//加载配置文件Properties prop = new Properties();prop.load(MyProducerTest.class.getClassLoader().getResourceAsStream("producer.properties"));/*** 创建执行入口* 首先, kafka中的数据都是有三个部分组成key, Value, timestamp,* Each record consists of a key, a value, and a timestamp.* K 就是记录中的Key的类型* V 就就是记录中的Value类型*/
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//设置要发送的topicString topic="spark";ProducerRecord<String, String> record = new ProducerRecord<>(topic, "11111");//通过send发送producer.send(record);//释放资源producer.close();}
}
配置:
将服务器config的producer.propert文件下载下来放入resources文件夹,并改写如下内容


bootstrap.servers=hadoopmaster:9092,hadoopnode1:9092,hadnoopnode2:9092 key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer
创建producer时需要指定的配置信息
bootstrap.servers=hadoopmaster:9092,hadoopnode1:9092,hadnoopnode2:9092 ##kafka的服务器 key.serializer=org.apache.kafka.common.serialization.StringSerializer ##key的序列化器 value.serializer=org.apache.kafka.common.serialization.StringSerializer ##value的序列化器 acks=[0|-1|1|all] #消息确认机制0: 不做确认,直管发送消息即可-1|all: 不仅leader需要将数据写入本地磁盘,并确认,还需要同步的等待其它followers进行确认1: 只需要leader进行消息确认即可,后期follower可以从leader进行同步 batch.size=1024 #每个分区的用户缓存未发送record记录的空间大小 ##如果缓存区中的数据,没有占满,也就是仍然有未用的空间,那么也会将请求发送出去,为了较少请求次数,可以配置linger.ms大于0. linger.ms=10 ##不管缓冲区是否被占满,延迟10ms发送request buffer.memory=10240 #控制的是一个producer中的所有缓存空间 retries=0 #发送消息失败之后的重试次数
文档: https://kafka.apache.org/24/documentation.html#introduction
修改配置查看生产数据情况
配置文件
bootstrap.servers=hadoopmaster:9092,hadoopnode1:9092,hadnoopnode2:9092 # specify the compression codec for all data generated: none, gzip, snappy, lz4, zstd compression.type=none # name of the partitioner class for partitioning events; default partition spreads data randomly # 输入进入分区的方式 #partitioner.class= # the maximum amount of time the client will wait for the response of a request #请求超时时间 #request.timeout.ms= # how long `KafkaProducer.send` and `KafkaProducer.partitionsFor` will block for #使用send方法最大消息阻塞时间 #max.block.ms= # the producer will wait for up to the given delay to allow other records to be sent so that the sends can be batched together linger.ms=5000 # the maximum size of a request in bytes #最大的请求大小 #max.request.size= # the default batch size in bytes when batching multiple records sent to a partition batch.size=16384 # the total bytes of memory the producer can use to buffer records waiting to be sent to the server buffer.memory=33554432 #Key和Value的序列化 key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer
注意:
producer.send(record); 是异步发送方式,

代码:
/*** 生产者API操作* 首先需要生产者--->就是程序的入口Producer* 数据被生产到哪里----> Topic* 什么样数据? ----> 数据类型*/
public class MyProducerTest {public static void main(String[] args) throws IOException {//加载配置文件Properties prop = new Properties();prop.load(MyProducerTest.class.getClassLoader().getResourceAsStream("producer.properties"));/*** 创建执行入口* 首先, kafka中的数据都是有三个部分组成key, Value, timestamp,* Each record consists of a key, a value, and a timestamp.* K 就是记录中的Key的类型* V 就就是记录中的Value类型*/
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);
//设置要发送的topicString topic="spark";ProducerRecord<String, String> record = new ProducerRecord<>(topic, "11111");//通过send发送/*send方法并不会立即将数据发送到Kafka集群,而且先发送到缓冲区,该方法便立即返回返回给调用者producer,该方法是一个异步方法当缓冲区满了,或者时间到了,就会将send的数据转换为request请求,提交给kafka集群*/Future<RecordMetadata> fututer=producer.send(record);RecordMetadata recordMetadata = fututer.get();boolean hasOffset = recordMetadata.hasOffset();long offset = recordMetadata.offset();boolean hasTimestamp = recordMetadata.hasTimestamp();int partition = recordMetadata.partition();long timestamp = recordMetadata.timestamp();String topicl = recordMetadata.topic();//打印if(hasOffset) {System.out.println("offer: " + offset);}if(hasTimestamp){System.out.println("timestamp: " + timestamp);}System.out.println("Topic: " +topic);System.out.println("Partition: " + partition);//释放资源producer.close();}
}


3.生产者模式幂等性案例
producer.properties配置
acks=all enable.idempotence=true
代码
/*** 幂等性例子* kafka生产都保证消息一致性(exactly one 恰好一次)语义, 靠开启幂等操作或者开启事务机制来完成* 下面的案例中在同一个producer中,我们发现了两次重复的消息,* 看到的现象并没有像幂等操作那样,可以避免数据的重复。* 这是什么原因* 其实主要原因在于大数据框架设计问题上* 如果说有1000W条数据,在其中不断的进行增加,要保证添加的数据不能重复。* 方案一:在添加的时候进行判断,如果该条消息已经存在,直接覆盖掉对应数据* 方案二:在添加的时候,先不进行判断,直接进行添加,在后续的操作过程中满足条件之后* 在进行数据的合并操作。* 我们选择方案一还是方案二?* 在这里我们肯定选择方案二,为什么原因在于添加一条数就要扫描一次,判断存在不存在,* 存在就覆盖,这样会很严重的影响写入的性能,如果我们进行判断,后期在进行聚合去重,对写入没有任何影响*/
public class ExactlyOneProducerTest {public static void main(String[] args) throws IOException {//加载配置文件Properties prop = new Properties();prop.load(MyProducerTest.class.getClassLoader().getResourceAsStream("producer.properties"));String topic = "spark";KafkaProducer<String, String> producer = new KafkaProducer<String, String>(prop);//加载TopicProducerRecord<String, String> record = null;int start =6;int end = start + 10;for(int i = start; i < end; i++) //每次发送十条记录{record = new ProducerRecord<>(topic,i+"", i+"");producer.send(record);}
for(int i = start; i < end; i++) //每次发送十条记录{record = new ProducerRecord<>(topic,i+"", i+"");producer.send(record);}//释放资源producer.close();}
}
附1:kafka producer 说明
10
A Kafka client that publishes records to the Kafka cluster.
The producer is thread safe and sharing a single producer instance across threads will generally be faster than having multiple instances.
Here is a simple example of using the producer to send records with strings containing sequential numbers as the key/value pairs.
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("acks", "all");props.put("retries", 0);props.put("batch.size", 16384);props.put("linger.ms", 1);props.put("buffer.memory", 33554432);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 100; i++)producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
The producer consists of a pool of buffer space that holds records that haven't yet been transmitted to the server as well as a background I/O thread that is responsible for turning these records into requests and transmitting them to the cluster. Failure to close the producer after use will leak these resources.
The send() method is asynchronous. When called it adds the record to a buffer of pending record sends and immediately returns. This allows the producer to batch together individual records for efficiency.
kafka的生产者producer由持有未提交给kafka服务的记录的缓冲区构成一个缓冲区池,于此同时会有一个后台的I/O线程来负责。
将这此记录record转化为请求request,然后将其提交给集群。如果发送完数据之后不对producer进行资源释放(close)会导致资源被挤占。
producer的send方法是异步的,当调用send方法提交一条记录到缓冲区之后,立即被返回。这就能够允许生产者能够进行高效组织以批处理来发送数据 -----> producer.send() ---- 数据 ----->producer的缓冲区-----> 缓冲满了,或者发送时间到----->发送数据到kafka集群
send方法立即返回,添加下一条记录。
The acks config controls the criteria under which requests are considered complete. The "all" setting we have specified will result in blocking on the full commit of the record, the slowest but most durable setting.
ack指的就是消息确认机制
kafka中用于和客户端进行交互的只有一个-- partition 中的 leader
客户端发送一条记录,到集群中,肯定是对应partition来进行接收,并录入到磁盘
acks消息确认机制,就代表了,一条消息从客户端到服务,从leader到各个follow来接收确认的一个机制。
acks=1 ----> 发送的消息只需要leader确认收到即可,后期follower来从leader进行同步
acks=0 -----> 发送的消息不需要经过服务端的确认,一旦发出,立即返回,继续下一条的发送
acks= -1|all ----> 发送的消息,不仅需要leader确认,还需要所有的follower都确认成功之后,才能发送下一条记录
显然acks=1 或者 -1是同步的消息发送,acks=0 是异步的消息发送
If the request fails, the producer can automatically retry, though since we have specified retries as 0 it won't. Enabling retries also opens up the possibility of duplicates (see the documentation on message delivery semantics for details).
如果请求失败,生产者会自动进行重试,如果指定的retries参数不是0.
The producer maintains buffers of unsent records for each partition. These buffers are of a size specified by the batch.size config. Making this larger can result in more batching, but requires more memory (since we will generally have one of these buffers for each active partition).
生产者producer会为每一个partition管理一个包含还没有发送的数据的缓冲区,buffer的大小 通过参数batch.size指定,调大这个参数,会导致缓存更多的记录,但是也现样意味着需要更多的内存。
By default a buffer is available to send immediately even if there is additional unused space in the buffer.
默认情况下,该缓冲区会立即发送数据, 即使该缓冲区还有没被使用的空间。
However if you want to reduce the number of requests you can set linger.ms to something greater than 0.
因此,如果我们想减少发送请求到集群的次数,可以通过设置参数 linger.ms 大于0
This will instruct the producer to wait up to that number of milliseconds before sending a request in hope that more records will arrive to fill up the same batch.
配置了等待参数,就会导致生产者在发送之前先等待 linger.ms 毫秒,以期望在缓冲区中可以缓冲更多的数据,最后一个批次全送出,减少了请求的次数。
This is analogous to Nagle's algorithm in TCP.
For example, in the code snippet above, likely all 100 records would be sent in a single request since we set our linger time to 1 millisecond. However this setting would add 1 millisecond of latency to our request waiting for more records to arrive if we didn't fill up the buffer. Note that records that arrive close together in time will generally batch together even with linger.ms=0 so under heavy load batching will occur regardless of the linger configuration; however setting this to something larger than 0 can lead to fewer, more efficient requests when not under maximal load at the cost of a small amount of latency.
Nagle算法是以他的发明人John Nagle的名字命名的,它用于自动连接许多的小缓冲器消息;这一过程(称为nagling)通过减少必须发送包的个数来增加网络软件系统的效率。
Nagle算法于1984年定义为福特航空和通信公司IP/TCP拥塞控制方法,这使福特经营的最早的专用 TCP/IP 网络减少拥塞控制,从那以后这一方法得到了广泛应用。Nagle的文档里定义了处理他所谓的小包问题的方法,这种问题指的是应用程序一次产生一字节数据,这样会导致 网络由于太多的包而过载(一个常见的情况是发送端的" 糊涂窗口综合症(Silly Windw Syndrome)")。从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的标题数据。这种情况转变成了4000%的消耗,这样的情况对于轻负载的 网络来说还是可以接受的,但是重负载的福特网络就受不了了,它没有必要在经过节点和网关的时候重发,导致包丢失和妨碍传输速度。 吞吐量可能会妨碍甚至在一定程度上会导致连接失败。Nagle的算法通常会在TCP程序里添加两行代码,在未确认数据发送的时候让发送器把数据送到 缓存里。任何数据随后继续直到得到明显的数据确认或者直到攒到了一定数量的数据了再发包。尽管Nagle的算法解决的问题只是局限于福特 网络,然而同样的问题也可能出现在ARPANet。这种方法在包括因特网在内的整个 网络里得到了推广,成为了默认的执行方式,尽管在高互动环境下有些时候是不必要的,例如在客户/服务器情形下。在这种情况下,nagling可以通过使用TCP_NODELAY 套接字选项关闭。
The buffer.memory controls the total amount of memory available to the producer for buffering.
buffer.memory控制着一个producer中所有可用缓冲内存
If records are sent faster than they can be transmitted to the server then this buffer space will be exhausted.
如果记录发送的速度快于提交给集群的速度,那么内存缓冲区将会很快被消耗光。
When the buffer space is exhausted additional send calls will block.
如果缓冲区被 消耗光,那么接下来的发送请求交款将会被block阻塞。
The threshold for time to block is determined by max.block.ms after which it throws a TimeoutException.、
如果阻塞时间超过了max.bllock.ms参数的值,将会抛出一个TimeoutException异常。
The key.serializer and value.serializer instruct how to turn the key and value objects the user provides with their ProducerRecord into bytes. You can use the included ByteArraySerializer or StringSerializer for simple string or byte types.
网络传输序列,需要进行序列化
From Kafka 0.11, the KafkaProducer supports two additional modes: the idempotent producer and the transactional producer. The idempotent producer strengthens Kafka's delivery semantics from at least once to exactly once delivery. In particular producer retries will no longer introduce duplicates. The transactional producer allows an application to send messages to multiple partitions (and topics!) atomically.
幂等操作------多次操作的结果和操作一次的结果是一样的
事务操作-------发送数据在一个事务中,如果有异常,将会回滚
To enable idempotence, the enable.idempotence configuration must be set to true. If set, the retries config will default to Integer.MAX_VALUE and the acks config will default to all. There are no API changes for the idempotent producer, so existing applications will not need to be modified to take advantage of this feature.
为了运行幂等操作,需要开启参数enable.idempotence=true. 一旦被设置,参数retries将会默认设置为Integer.MAX_VALUE,以及参数acks被设置为all。这种幂等api上面没有任何的变化,也就是说在前面的代码中如果开启幂等操作,整个生产的程序就是幂等的。
To take advantage of the idempotent producer, it is imperative to avoid application level re-sends since these cannot be de-duplicated.
为了获取幂等的优势,能够避免在应用程序的级别去避免数据的重复发送,因为这种情况下数据不会有重复。
As such, if an application enables idempotence, it is recommended to leave the retries config unset, as it will be defaulted to Integer.MAX_VALUE.
因此,如果一个application允许了幂等操作,推荐设置retries 参数为0, 或者不设置,因为此时默认的 retries = Integer.MAX_VALUE。
Additionally, if a send(ProducerRecord) returns an error even with infinite retries (for instance if the message expires in the buffer before being sent), then it is recommended to shut down the producer and check the contents of the last produced message to ensure that it is not duplicated. Finally, the producer can only guarantee idempotence for messages sent within a single session.
producer在幂等情况下能够在单一会话中保证消息的唯一性。
To use the transactional producer and the attendant APIs, you must set the transactional.id configuration property. If the transactional.id is set, idempotence is automatically enabled along with the producer configs which idempotence depends on. Further, topics which are included in transactions should be configured for durability. In particular, the replication.factor should be at least 3, and the min.insync.replicas for these topics should be set to 2. Finally, in order for transactional guarantees to be realized from end-to-end, the consumers must be configured to read only committed messages as well.
The purpose of the transactional.id is to enable transaction recovery across multiple sessions of a single producer instance. It would typically be derived from the shard identifier in a partitioned, stateful, application. As such, it should be unique to each producer instance running within a partitioned application.
All the new transactional APIs are blocking and will throw exceptions on failure. The example below illustrates how the new APIs are meant to be used. It is similar to the example above, except that all 100 messages are part of a single transaction.
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("transactional.id", "my-transactional-id");Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {producer.beginTransaction();for (int i = 0; i < 100; i++)producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));producer.commitTransaction();} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// We can't recover from these exceptions, so our only option is to close the producer and exit.producer.close();} catch (KafkaException e) {// For all other exceptions, just abort the transaction and try again.producer.abortTransaction();}producer.close();
As is hinted at in the example, there can be only one open transaction per producer. All messages sent between the beginTransaction() and commitTransaction() calls will be part of a single transaction. When the transactional.id is specified, all messages sent by the producer must be part of a transaction.
The transactional producer uses exceptions to communicate error states. In particular, it is not required to specify callbacks for producer.send() or to call .get() on the returned Future: a KafkaException would be thrown if any of the producer.send() or transactional calls hit an irrecoverable error during a transaction. See the send(ProducerRecord) documentation for more details about detecting errors from a transactional send.
By calling producer.abortTransaction() upon receiving a KafkaException we can ensure that any successful writes are marked as aborted, hence keeping the transactional guarantees.
This client can communicate with brokers that are version 0.10.0 or newer. Older or newer brokers may not support certain client features. For instance, the transactional APIs need broker versions 0.11.0 or later. You will receive an UnsupportedVersionException when invoking an API that is not available in the running broker version.
附2:Nagle算法(Nagle算法_nagle算法于1984-CSDN博客)
简介
Nagle算法是以他的发明人John Nagle的名字命名的,它用于自动连接许多的小 缓冲器消息;这一过程(称为nagling)通过减少必须发送包的个数来增加 网络软件系统的效率。Nagle算法于1984年定义为福特航空和通信公司IP/TCP拥塞控制方法,这使福特经营的最早的专用 TCP/IP 网络减少拥塞控制,从那以后这一方法得到了广泛应用。Nagle的文档里定义了处理他所谓的小包问题的方法,这种问题指的是应用程序一次产生一字节数据,这样会导致 网络由于太多的包而过载(一个常见的情况是发送端的" 糊涂窗口综合症(Silly Windw Syndrome)")。从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的标题数据。这种情况转变成了4000%的消耗,这样的情况对于轻负载的 网络来说还是可以接受的,但是重负载的福特网络就受不了了,它没有必要在经过节点和网关的时候重发,导致包丢失和妨碍传输速度。 吞吐量可能会妨碍甚至在一定程度上会导致连接失败。Nagle的算法通常会在TCP程序里添加两行代码,在未确认数据发送的时候让发送器把数据送到 缓存里。任何数据随后继续直到得到明显的数据确认或者直到攒到了一定数量的数据了再发包。尽管Nagle的算法解决的问题只是局限于福特 网络,然而同样的问题也可能出现在ARPANet。这种方法在包括因特网在内的整个 网络里得到了推广,成为了默认的执行方式,尽管在高互动环境下有些时候是不必要的,例如在客户/服务器情形下。在这种情况下,nagling可以通过使用TCP_NODELAY 套接字选项关闭。
MSDN:
A TCP/IP optimization called the Nagle Algorithm can also limit data transfer speed on a connection. The Nagle Algorithm is designed to reduce protocol overhead for applications that send small amounts of data, such as Telnet, which sends a single character at a time. Rather than immediately send a packet with lots of header and little data, the stack waits for more data from the application, or an acknowledgment, before proceeding.
2算法
** ** TCP/IP协议中,无论发送多少数据,总是要在数据前面加上协议头,同时,对方接收到数据,也需要发送ACK表示确认。为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。 Nagle算法的基本定义是 任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。 Nagle算法的规则(可参考tcp_output.c文件里tcp_nagle_check函数注释):
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
Nagle算法只允许一个未被ACK的包存在于网络,它并不管包的大小,因此它事实上就是一个扩展的停-等协议,只不过它是基于包停-等的,而不是基于字节停-等的。Nagle算法完全由TCP协议的ACK机制决定,这会带来一些问题,比如如果对端ACK回复很快的话,Nagle事实上不会拼接太多的数据包,虽然避免了网络拥塞,网络总体的利用率依然很低。
Nagle算法是silly window syndrome(SWS)预防算法的一个半集。SWS算法预防发送少量的数据,Nagle算法是其在发送方的实现,而接收方要做的时不要通告缓冲空间的很小增长,不通知小窗口,除非缓冲区空间有显著的增长。这里显著的增长定义为完全大小的段(MSS)或增长到大于最大窗口的一半。 注意:BSD的实现是允许在空闲链接上发送大的写操作剩下的最后的小段,也就是说,当超过1个MSS数据发送时,内核先依次发送完n个MSS的数据包,然后再发送尾部的小数据包,其间不再延时等待。(假设网络不阻塞且接收窗口足够大)
举个例子,比如之前的blog中的实验,一开始client端调用socket的write操作将一个int型数据(称为A块)写入到网络中,由于此时连接是空闲的(也就是说还没有未被确认的小段),因此这个int型数据会被马上发送到server端,接着,client端又调用write操作写入‘\r\n’(简称B块),这个时候,A块的ACK没有返回,所以可以认为已经存在了一个未被确认的小段,所以B块没有立即被发送,一直等待A块的ACK收到(大概40ms之后),B块才被发送。整个过程如图所示:
这里还隐藏了一个问题,就是A块数据的ACK为什么40ms之后才收到?这是因为TCP/IP中不仅仅有nagle算法,还有一个 TCP确认延迟机制 。当Server端收到数据之后,它并不会马上向client端发送ACK,而是会将ACK的发送延迟一段时间(假设为t),它希望在t时间内server端会向client端发送应答数据,这样ACK就能够和应答数据一起发送,就像是应答数据捎带着ACK过去。在我之前的时间中,t大概就是40ms。这就解释了为什么'\r\n'(B块)总是在A块之后40ms才发出。 当然,TCP确认延迟40ms并不是一直不变的,TCP连接的延迟确认时间一般初始化为最小值40ms,随后根据连接的重传超时时间(RTO)、上次收到数据包与本次接收数据包的时间间隔等参数进行不断调整。另外可以通过设置TCP_QUICKACK选项来取消确认延迟。 **
-
TCP_NODELAY 选项 **
默认情况下,发送数据采用Nagle 算法。这样虽然提高了网络吞吐量,但是实时性却降低了,在一些交互性很强的应用程序来说是不允许的,使用TCP_NODELAY选项可以禁止Nagle 算法。
此时,应用程序向内核递交的每个数据包都会立即发送出去。需要注意的是,虽然禁止了Nagle 算法,但网络的传输仍然受到TCP确认延迟机制的影响。 3. TCP_CORK 选项
所谓的CORK就是塞子的意思,形象地理解就是用CORK将连接塞住,使得数据先不发出去,等到拔去塞子后再发出去。设置该选项后,内核会尽力把小数据包拼接成一个大的数据包(一个MTU)再发送出去,当然若一定时间后(一般为200ms,该值尚待确认),内核仍然没有组合成一个MTU时也必须发送现有的数据(不可能让数据一直等待吧)。 然而,TCP_CORK的实现可能并不像你想象的那么完美,CORK并不会将连接完全塞住。内核其实并不知道应用层到底什么时候会发送第二批数据用于和第一批数据拼接以达到MTU的大小,因此内核会给出一个时间限制,在该时间内没有拼接成一个大包(努力接近MTU)的话,内核就会无条件发送。也就是说若应用层程序发送小包数据的间隔不够短时,TCP_CORK就没有一点作用,反而失去了数据的实时性(每个小包数据都会延时一定时间再发送)。 4. Nagle算法与CORK算法区别 Nagle算法和CORK算法非常类似,但是它们的着眼点不一样,Nagle算法主要避免网络因为太多的小包(协议头的比例非常之大)而拥塞,而CORK算法则是为了提高网络的利用率,使得总体上协议头占用的比例尽可能的小。如此看来这二者在避免发送小包上是一致的,在用户控制的层面上,Nagle算法完全不受用户socket的控制,你只能简单的设置TCP_NODELAY而禁用它,CORK算法同样也是通过设置或者清除TCP_CORK使能或者禁用之,然而Nagle算法关心的是网络拥塞问题,只要所有的ACK回来则发包,而CORK算法却可以关心内容,在前后数据包发送间隔很短的前提下(很重要,否则内核会帮你将分散的包发出),即使你是分散发送多个小数据包,你也可以通过使能CORK算法将这些内容拼接在一个包内,如果此时用Nagle算法的话,则可能做不到这一点。
附3: Nagle算法(Nagle算法_nagle算法是以他-CSDN博客)
Nagle算法是以他的发明人John Nagle的名字命名的,它用于自动连接许多的小缓冲器消息;这一过程(称为nagling)通过减少必须发送包的个数来增加网络软件系统的效率。
TCP/IP协议中,无论发送多少数据,总是要在数据前面加上协议头,同时,对方接收到数据,也需要发送ACK表示确认。为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块。 Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。 Nagle算法的规则(可参考tcp_output.c文件里tcp_nagle_check函数注释):
如果包长度达到MSS,则允许发送; 如果该包含有FIN,则允许发送; 设置了TCP_NODELAY选项,则允许发送; 未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送; 上述条件都未满足,但发生了超时(一般为200ms),则立即发送。 伪代码: if there is new data to send #有数据要发送 # 发送窗口缓冲区和队列数据 >=mss,队列数据(available data)为原有的队列数据加上新到来的数据 # 也就是说缓冲区数据超过mss大小,nagle算法尽可能发送足够大的数据包 if the window size >= MSS and available data is >= MSS send complete MSS segment now # 立即发送 else if there is unconfirmed data still in the pipe # 前一次发送的包没有收到ack # 将该包数据放入队列中,直到收到一个ack再发送缓冲区数据 enqueue data in the buffer until an acknowledge is received else send data immediately # 立即发送 end if end if end if Nagle算法只允许一个未被ACK的包存在于网络,它并不管包的大小,因此它事实上就是一个扩展的停-等协议,只不过它是基于包停-等的,而不是基于字节停-等的。Nagle算法完全由TCP协议的ACK机制决定,这会带来一些问题,比如如果对端ACK回复很快的话,Nagle事实上不会拼接太多的数据包,虽然避免了网络拥塞,网络总体的利用率依然很低。 Nagle算法是silly window syndrome(SWS)预防算法的一个半集。SWS算法预防发送少量的数据,Nagle算法是其在发送方的实现,而接收方要做的是不要通告缓冲空间的很小增长,不通知小窗口,除非缓冲区空间有显著的增长。这里显著的增长定义为完全大小的段(MSS)或增长到大于最大窗口的一半。 注意:BSD的实现是允许在空闲链接上发送大的写操作剩下的最后的小段,也就是说,当超过1个MSS数据发送时,内核先依次发送完n个MSS的数据包,然后再发送尾部的小数据包,其间不再延时等待。(假设网络不阻塞且接收窗口足够大) 举个例子,client端调用socket的write操作将一个int型数据(称为A块)写入到网络中,由于此时连接是空闲的(也就是说还没有未被确认的小段),因此这个int型数据会被马上发送到server端,接着,client端又调用write操作写入‘\r\n’(简称B块),这个时候,A块的ACK没有返回,所以可以认为已经存在了一个未被确认的小段,所以B块没有立即被发送,一直等待A块的ACK收到(大概40ms之后),B块才被发送。 这里还隐藏了一个问题,就是A块数据的ACK为什么40ms之后才收到?这是因为TCP/IP中不仅仅有nagle算法,还有一个TCP确认延迟机制 。当Server端收到数据之后,它并不会马上向client端发送ACK,而是会将ACK的发送延迟一段时间(假设为t),它希望在t时间内server端会向client端发送应答数据,这样ACK就能够和应答数据一起发送,就像是应答数据捎带着ACK过去。在我之前的时间中,t大概就是40ms。这就解释了为什么’\r\n’(B块)总是在A块之后40ms才发出。 当然,TCP确认延迟40ms并不是一直不变的,TCP连接的延迟确认时间一般初始化为最小值40ms,随后根据连接的重传超时时间(RTO)、上次收到数据包与本次接收数据包的时间间隔等参数进行不断调整。另外可以通过设置TCP_QUICKACK选项来取消确认延迟。
TCP_NODELAY 选项 默认情况下,发送数据采用Nagle 算法。这样虽然提高了网络吞吐量,但是实时性却降低了,在一些交互性很强的应用程序来说是不允许的,使用TCP_NODELAY选项可以禁止Nagle 算法。 此时,应用程序向内核递交的每个数据包都会立即发送出去。需要注意的是,虽然禁止了Nagle 算法,但网络的传输仍然受到TCP确认延迟机制的影响。
TCP_CORK 选项 所谓的CORK就是塞子的意思,形象地理解就是用CORK将连接塞住,使得数据先不发出去,等到拔去塞子后再发出去。设置该选项后,内核会尽力把小数据包拼接成一个大的数据包(一个MTU)再发送出去,当然若一定时间后(一般为200ms,该值尚待确认),内核仍然没有组合成一个MTU时也必须发送现有的数据(不可能让数据一直等待吧)。 然而,TCP_CORK的实现可能并不像你想象的那么完美,CORK并不会将连接完全塞住。内核其实并不知道应用层到底什么时候会发送第二批数据用于和第一批数据拼接以达到MTU的大小,因此内核会给出一个时间限制,在该时间内没有拼接成一个大包(努力接近MTU)的话,内核就会无条件发送。也就是说若应用层程序发送小包数据的间隔不够短时,TCP_CORK就没有一点作用,反而失去了数据的实时性(每个小包数据都会延时一定时间再发送)。
Nagle算法与CORK算法区别 Nagle算法和CORK算法非常类似,但是它们的着眼点不一样,Nagle算法主要避免网络因为太多的小包(协议头的比例非常之大)而拥塞,而CORK算法则是为了提高网络的利用率,使得总体上协议头占用的比例尽可能的小。如此看来这二者在避免发送小包上是一致的,在用户控制的层面上,Nagle算法完全不受用户socket的控制,你只能简单的设置TCP_NODELAY而禁用它,CORK算法同样也是通过设置或者清除TCP_CORK使能或者禁用之,然而Nagle算法关心的是网络拥塞问题,只要所有的ACK回来则发包,而CORK算法却可以关心内容,在前后数据包发送间隔很短的前提下(很重要,否则内核会帮你将分散的包发出),即使你是分散发送多个小数据包,你也可以通过使能CORK算法将这些内容拼接在一个包内,如果此时用Nagle算法的话,则可能做不到这一点。
如何保证kafka的数据一致性
kafka生产都可以选择生产的两种模式(幂等和事务) 幂等:多次操作的结果和操作一次的结果一样的 事务:发送数据在一个事务中,如果有异常,将会回滚
4.kafka消费者的api操作
入口类: ConSumer
配置:
将服务器config的consumer.properties文件下载下来放入resources文件夹,并改写如下内容
bootstrap.servers=hadoopmaster:9092,hadoopnode1:9092,hadnoopnode2:9092 # consumer group id group.id=kafka_bigdata # What to do when there is no initial offset in Kafka or if the current # offset does not exist any more on the server: latest, earliest, none # latest(默认):从最大的偏移量开始消费 # earliest:从最小的偏移量开始消费 #auto.offset.reset= key.deserializer=org.apache.kafka.common.serialization.StringDeserializer value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
代码:
/*** kafka 消费者 API*/
public class MyConsumerTest {public static void main(String[] args) throws IOException {Properties prop = new Properties();prop.load(MyConsumerTest.class.getClassLoader().getResourceAsStream("consumer.properties"));//构建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);//消费对应的Topic数据consumer.subscribe(Arrays.asList("spark"));//打印所有相关的数据信息System.out.println("topic\tpartition\toffset\tkey\tvalue");while(true){/*** 消费数据 timeout: 从consumer的缓冲区Buffer中获取可用数据的等待超时时间* 如果设置为0, 则会理解返回该缓冲区内的所有数据,如果不设置为零,返回空,并且不能写负数*/ConsumerRecords<String, String> consumerRecords = consumer.poll(1000);for(ConsumerRecord<String, String> cr : consumerRecords){String topic = cr.topic();int partition = cr.partition();String key = cr.key();String value = cr.value();long offset = cr.offset();System.out.printf("topic:%s\tpartition:%d\toffset:%d\tkey:%s\tvalue:%s\r\n", topic, partition, offset, key, value);}}}
}
注意:释放资源
consumer.close();
指定offset位置消费
/*** 指定Offset位置进行消费数据* 之前消费的方式是全量消费* 与在从指定offset位置消费* partition 0 ---> offset 10* partition 1 ---> offset 10* partition 2 ---> offset 10* 注意:这里从指定的Offset位置开始消费,那么我们需要使用assign API来完成* 说白了 就是指定具体的所有信息即可**/
public class MyConsumerSeekOffsetTest {public static void main(String[] args) throws IOException {Properties prop = new Properties();prop.load(MyConsumerSeekOffsetTest.class.getClassLoader().getResourceAsStream("consumer.properties"));//构建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);//消费对应的Topic数据consumer.assign(Arrays.asList(new TopicPartition("spark", 0),new TopicPartition("spark", 1),new TopicPartition("spark", 2)));//指定消费的偏移量位置consumer.seek(new TopicPartition("spark", 0), 10); //定位consumer.seek(new TopicPartition("spark", 1), 10); //定位consumer.seek(new TopicPartition("spark", 2), 10); //定位
//打印所有相关的数据信息System.out.println("topic\tpartition\toffset\tkey\tvalue");while(true){/*** 消费数据 timeout: 从consumer的缓冲区Buffer中获取可用数据的等待超时时间* 如果设置为0, 则会理解返回该缓冲区内的所有数据,如果不设置为零,返回空,并且不能写负数*/ConsumerRecords<String, String> consumerRecords = consumer.poll(1000);for(ConsumerRecord<String, String> cr : consumerRecords){String topic = cr.topic();int partition = cr.partition();String key = cr.key();String value = cr.value();long offset = cr.offset();System.out.printf("topic:%s\tpartition:%d\toffset:%d\tkey:%s\tvalue:%s\r\n", topic, partition, offset, key, value);}}}
}
5.offset消费问题
auto.offset.reset=earliest|latest
生产者上生产了6条消费记录,偏移量就是0-6,此时消费者需要消费时,需要指定一个参数auto.offset.reset=earliest|latest, 如果我们管理了用户的数据偏移量,就能定位到上一次用户的数据位置,下一次在读取数据的时候,就可以知道从什么位置开始消费了。比如第一次读取到offset=2这个位置,由于记录了offset,下一次就应该从offset=1开始消费数据。
假如我们没有去管理offset, 那么有一天我们的程序崩溃了,offset也没了,下一次启动程序的话,之前的数据如果没有消费到,但是数据又更新了,此时我们只能再次从头开始消费offset,这样导致任务执行效率低,同时消费数据会重复,所以我们需要管理一下offset,让它达到上述的要求,这样我们的数据消费会精准,并且不会造成重复消费。
offset自动管理
配置参数 (consumer.properties)
# 配置自动提交Offset enable.auto.commit=true # 每隔多少时间提交一次 auto.commit.interval.ms=10000
可以保证数据不丢,也就是当生产者生产的时候,如果消费者挂掉了,也不用担心,只需管理下Offset,然后下次启动时,继续之前的消费位置开始消费。
offset手动管理
这里简单介绍如何管理即可,用户手动管理Offset的话,需要提取Kafka的Offset,每次消费数据的时候,拿到Offset,然后将这个Offset存入一个系统或数据库都行,就将它保存起来,当我们数据处理完成后,再向系统或者数据库提交此Offset,这样offset在我们自己的系统或者数据库中,我们就不用担心周期提交失败问题。
/*** kafka自动提交偏移量操作* 这种自动提交offset是会周期性的进行offset提交,如果说该周期设置的时间比较大,就有可能* 造成数据的读取重复,所以我们如果使用这种提交方式的话,那么应该尽可能把时间设置短一点。** 这种方式有一点问题,因为自动管理是周期性提交方式,那么如果在这个周期提交的时候,* 正好此时这个周期的offset没有提交上去,那么造成生产数据丢失,这种问题该如何解决呢。* 变需要手动管理offset* * kafka手动维护Offset* 注释: 手动管理Offset会在SparkStreaming中重点讲解,这里简单介绍如何管理即可,* 用户手动管理Offset的话,需要提取Kafka的Offset,每次消费数据的时候,拿到Offset,然后将这个Offset存入一个系统或数据库都行,* 就将它保存起来,当我们数据处理完成后,再向系统或者数据库提交此Offset,这样offset在我们自己的系统或者数据库中,我们就不用担心周期提交失败问题*/
public class AutoOffsetCommitConsumerOps {public static void main(String[] args) throws IOException {Properties prop = new Properties();prop.load(MyConsumerTest.class.getClassLoader().getResourceAsStream("consumer.properties"));//构建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);//消费对应的Topic数据consumer.subscribe(Arrays.asList("spark"));//打印所有相关的数据信息System.out.println("topic\tpartition\toffset\tkey\tvalue");while(true){/*** 消费数据 timeout: 从consumer的缓冲区Buffer中获取可用数据的等待超时时间* 如果设置为0, 则会理解返回该缓冲区内的所有数据,如果不设置为零,返回空,并且不能写负数*/ConsumerRecords<String, String> consumerRecords = consumer.poll(1000);for(ConsumerRecord<String, String> cr : consumerRecords){String topic = cr.topic();int partition = cr.partition();String key = cr.key();String value = cr.value();long offset = cr.offset();System.out.printf("topic:%s\tpartition:%d\toffset:%d\tkey:%s\tvalue:%s\r\n", topic, partition, offset, key, value);}}}
}
6.record进入分区的策略
每一条producerRecord有, topic名称、可选的partition分区编号,以及一对可选的key和value组成。三种策略进入分区。
If a valid partition number is specified that partition will be used when sending the record. If no partition is specified but a key is present a partition will be chosen using a hash of the key. If neither key nor partition is present a partition will be assigned in a round-robin fashion.
-
如果指定的partition, 那么直接进入该partition
-
如果没有指定partition, 但是指定了key, 使用key的hash选择partition
-
如果既没有指定partition,也没有指定key, 使用轮询的方式进入partition
附1:细说 Kafka Partition 分区(细说 Kafka Partition 分区-CSDN博客)
Partition(分区)是 Kafka 的核心角色,对于 Kafka 的存储结构、消息的生产消费方式都至关重要。
掌握好 Partition 就可以更快的理解 Kafka。本文会讲解 Partition 的概念、结构,以及行为方式。
一、Events, Streams, Topics 在深入 Partition 之前,我们先看几个更高层次的概念,以及它们与 Partition 的联系。
Event(事件)代表过去发生的一个事实。简单理解就是一条消息、一条记录。
Event 是不可变的,但是很活跃,经常从一个地方流向另一个地方。
Stream 事件流表示运动中的相关事件。
当一个事件流进入 Kafka 之后,它就成为了一个 Topic 主题。
所以,Topic 就是具体的事件流,也可以理解为一个 Topic 就是一个静止的 Stream。
Topic 把相关的 Event 组织在一起,并且保存。一个 Topic 就像数据库中的一张表。
二、Partition 分区
Kafka 中 Topic 被分成多个 Partition 分区。
Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。
每个 Partition 都是一个单独的 log 文件,每条记录都以追加的形式写入。
Record(记录) 和 Message(消息)是一个概念。
三、Offsets(偏移量)和消息的顺序 Partition 中的每条记录都会被分配一个唯一的序号,称为 Offset(偏移量)。
Offset 是一个递增的、不可变的数字,由 Kafka 自动维护。 当一条记录写入 Partition 的时候,它就被追加到 log 文件的末尾,并被分配一个序号,作为 Offset。 如上图,这个 Topic 有 3 个 Partition 分区,向 Topic 发送消息的时候,实际上是被写入某一个 Partition,并赋予 Offset。 消息的顺序性需要注意,一个 Topic 如果有多个 Partition 的话,那么从 Topic 这个层面来看,消息是无序的。 但单独看 Partition 的话,Partition 内部消息是有序的。 所以,一个 Partition 内部消息有序,一个 Topic 跨 Partition 是无序的。 如果强制要求 Topic 整体有序,就只能让 Topic 只有一个 Partition。
四、Partition 为 Kafka 提供了扩展能力
一个 Kafka 集群由多个 Broker(就是 Server) 构成,每个 Broker 中含有集群的部分数据。
Kafka 把 Topic 的多个 Partition 分布在多个 Broker 中。
这样会有多种好处:
如果把 Topic 的所有 Partition 都放在一个 Broker 上,那么这个 Topic 的可扩展性就大大降低了,会受限于这个 Broker 的 IO 能力。把 Partition 分散开之 后,Topic 就可以水平扩展 。 一个 Topic 可以被多个 Consumer 并行消费。如果 Topic 的所有 Partition 都在一个 Broker,那么支持的 Consumer 数量就有限,而分散之后,可以支持 更多的 Consumer。 一个 Consumer 可以有多个实例,Partition 分布在多个 Broker 的话,Consumer 的多个实例就可以连接不同的 Broker,大大提升了消息处理能力。可以 让一个 Consumer 实例负责一个 Partition,这样消息处理既清晰又高效。 五、Partition 为 Kafka 提供了数据冗余 Kafka 为一个 Partition 生成多个副本,并且把它们分散在不同的 Broker。
如果一个 Broker 故障了,Consumer 可以在其他 Broker 上找到 Partition 的副本,继续获取消息。
六、写入 Partition 一个 Topic 有多个 Partition,那么,向一个 Topic 中发送消息的时候,具体是写入哪个 Partition 呢?有3种写入方式。
-
使用 Partition Key 写入特定 Partition
Producer 发送消息的时候,可以指定一个 Partition Key,这样就可以写入特定 Partition 了。
Partition Key 可以使用任意值,例如设备ID、User ID。
Partition Key 会传递给一个 Hash 函数,由计算结果决定写入哪个 Partition。
所以,有相同 Partition Key 的消息,会被放到相同的 Partition。
例如使用 User ID 作为 Partition Key,那么此 ID 的消息就都在同一个 Partition,这样可以保证此类消息的有序性。
这种方式需要注意 Partition 热点问题。
例如使用 User ID 作为 Partition Key,如果某一个 User 产生的消息特别多,是一个头部活跃用户,那么此用户的消息都进入同一个 Partition 就会产生热点 问题,导致某个 Partition 极其繁忙。
-
由 kafka 决定 如果没有使用 Partition Key,Kafka 就会使用轮询的方式来决定写入哪个 Partition。
这样,消息会均衡的写入各个 Partition。
但这样无法确保消息的有序性。
-
自定义规则 Kafka 支持自定义规则,一个 Producer 可以使用自己的分区指定规则。
七、读取 Partition Kafka 不像普通消息队列具有发布/订阅功能,Kafka 不会向 Consumer 推送消息。
Consumer 必须自己从 Topic 的 Partition 拉取消息。
一个 Consumer 连接到一个 Broker 的 Partition,从中依次读取消息。
消息的 Offset 就是 Consumer 的游标,根据 Offset 来记录消息的消费情况。 读完一条消息之后,Consumer 会推进到 Partition 中的下一个 Offset,继续读取消息。 Offset 的推进和记录都是 Consumer 的责任,Kafka 是不管的。
Kafka 中有一个 Consumer Group(消费组)的概念,多个 Consumer 组团去消费一个 Topic。 同组的 Consumer 有相同的 Group ID。 Consumer Group 机制会保障一条消息只被组内唯一一个 Consumer 消费,不会重复消费。 消费组这种方式可以让多个 Partition 并行消费,大大提高了消息的消费能力,最大并行度为 Topic 的 Partition 数量。
例如一个 Topic 有 3 个 Partition,你有 4 个 Consumer 负责这个 Topic,也只会有 Consumer 工作,另一个作为后补队员,当某个 Consumer 故障了,它再 补上去,是一种很好的容错机制。
参考资料
https://medium.com/event-driven-utopia/understanding-kafka-topic-partitions-ae40f80552e8
附2:Kafka中的Partition详解与示例代码(Kafka中的Partition详解与示例代码-阿里云开发者社区)

在Apache Kafka中,Partition(分区)是一个关键的概念。分区的引入使得Kafka能够处理大规模数据,并提供高性能和可伸缩性。本文将深入探讨Kafka 中的Partition,包括分区的作用、创建、配置以及一些实际应用中的示例代码。
Partition的作用
在Kafka中,Topic被分为一个或多个Partition。每个Partition是一个有序且不可变的消息序列,具有自己的唯一标识符(Partition ID)。分区的主要作用有:
-
水平扩展性:通过将Topic划分为多个Partition,可以将消息分布到多个Broker上,实现水平扩展,提高整体吞吐量。
-
并行处理:每个Partition可以在不同的消费者上并行处理,提高系统的处理能力。
-
顺序性:在同一个Partition内,消息的顺序是有序的。这有助于确保一些需要顺序处理的场景,如日志记录。
创建与配置Partition
1 创建Topic时指定Partition数量
可以在创建Topic时指定Partition的数量。以下是一个使用命令行工具创建Topic并指定分区数量的示例:
bin/kafka-topics.sh --create --topic my_topic --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092
这将创建一个名为my_topic的Topic,有3个分区。
2 动态调整Partition数量
Kafka支持在运行时动态调整Topic的Partition数量。以下是一个示例:
bin/kafka-topics.sh --alter --topic my_topic --partitions 5 --bootstrap-server localhost:9092
这将把my_topic的分区数增加到5。
3 Partition的配置选项
Partition还有一些配置选项,例如消息的保留时间、清理策略等。以下是一个设置消息保留时间的示例:
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my_topic --alter --add-config retention.ms=86400000
这将设置my_topic的消息保留时间为1天(86400000毫秒)。
生产者与消费者操作分区
1 生产者发送消息到指定Partition
在生产者发送消息时,可以选择将消息发送到特定的Partition。以下是一个Java生产者示例代码:
Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(properties);ProducerRecord<String, String> record = new ProducerRecord<>("my_topic", 1, "key", "value");producer.send(record);producer.close();
这将消息发送到my_topic的第2个分区(分区编号从0开始)。
2 消费者订阅指定Partition
消费者可以选择订阅特定的Partition,也可以订阅整个Topic。以下是一个Java消费者示例代码:
Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("group.id", "my_group");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");Consumer<String, String> consumer = new KafkaConsumer<>(properties);TopicPartition partition = new TopicPartition("my_topic", 1);consumer.assign(Collections.singletonList(partition));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Offset = %d, Key = %s, Value = %s%n", record.offset(), record.key(), record.value());}}
这将使消费者仅订阅my_topic的第2个分区。
实际应用示例
1 数据分流
在实际应用中,数据分流是一种常见的需求,特别是在处理用户活动日志等场景。通过根据用户ID将日志分发到相同的分区,可以轻松实现对用户活动的精细化处理、分析和统计。下面是一个具体的数据分流示例:
创建Topic时指定Partition数量
首先,创建一个Topic,假设名为user_activity_logs,并指定适当的分区数量,例如5个分区:
bin/kafka-topics.sh --create --topic user_activity_logs --partitions 5 --replication-factor 2 --bootstrap-server localhost:9092
生产者发送用户活动日志
在实际场景中,应用程序可能会有不同的用户活动日志,例如登录、点击、购买等。以下是一个简化的Java生产者示例代码,用于向user_activity_logs Topic发送用户活动日志:
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class UserActivityProducer {public static void main(String[] args) {Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(properties);// 模拟不同用户的活动日志for (int i = 1; i <= 10; i++) {String userId = "user_" + i;String activity = "Login"; // 模拟用户登录活动,实际应用中可根据业务类型发送不同类型的活动日志// 根据用户ID计算分区int partition = userId.hashCode() % 5;ProducerRecord<String, String> record = new ProducerRecord<>("user_activity_logs", partition, userId, activity);producer.send(record, (metadata, exception) -> {if (exception == null) {System.out.printf("Sent record to partition %d with offset %d%n", metadata.partition(), metadata.offset());} else {exception.printStackTrace();}});}producer.close();}}
在这个示例中,模拟了10个用户的登录活动,并通过计算用户ID的哈希值来确定将活动发送到哪个分区。
消费者按用户ID订阅分区
消费者可以根据用户ID订阅相应的分区,以便按用户维度处理活动日志。以下是一个简化的Java消费者示例代码:
import org.apache.kafka.clients.consumer.*;import org.apache.kafka.common.TopicPartition;import java.time.Duration;import java.util.Collections;import java.util.Properties;public class UserActivityConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("group.id", "user_activity_group");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");Consumer<String, String> consumer = new KafkaConsumer<>(properties);// 订阅指定分区TopicPartition partitionToSubscribe = new TopicPartition("user_activity_logs", 0);consumer.assign(Collections.singletonList(partitionToSubscribe));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Received record with key %s and value %s from partition %d%n",record.key(), record.value(), record.partition());// 在这里进行按用户ID处理的业务逻辑}}}}
在实际应用中,可能会根据业务逻辑动态订阅多个分区,以处理更多用户的活动日志。
2 时间窗口统计
在实际应用中,按照时间窗口对数据进行分区是一种常见的做法,特别是对于具有时间戳的数据。这种分区方式使得可以方便地进行时间窗口内的统计、分析和处理。下面是一个具体的按时间窗口统计的示例:
创建Topic时指定Partition数量
首先,创建一个Topic,假设名为timestamped_data,并指定适当的分区数量,例如5个分区:
bin/kafka-topics.sh --create --topic timestamped_data --partitions 5 --replication-factor 2 --bootstrap-server localhost:9092
生产者发送带有时间戳的数据
在实际场景中,应用程序可能会产生带有时间戳的数据,例如传感器数据、日志等。以下是一个简化的Java生产者示例代码,用于向timestamped_data Topic发送带有时间戳的数据:
import org.apache.kafka.clients.producer.*;import java.util.Properties;public class TimestampedDataProducer {public static void main(String[] args) {Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(properties);// 模拟带有时间戳的数据for (int i = 1; i <= 10; i++) {long timestamp = System.currentTimeMillis();String data = "Data_" + i;// 根据时间戳计算分区int partition = (int) (timestamp % 5);ProducerRecord<String, String> record = new ProducerRecord<>("timestamped_data", partition, String.valueOf(timestamp), data);producer.send(record, (metadata, exception) -> {if (exception == null) {System.out.printf("Sent record to partition %d with offset %d%n", metadata.partition(), metadata.offset());} else {exception.printStackTrace();}});}producer.close();}}
在这个示例中,模拟了10条带有时间戳的数据,并通过计算数据的时间戳来确定将数据发送到哪个分区。
消费者按时间窗口统计订阅分区
消费者可以根据时间戳订阅相应的分区,以便按时间窗口统计数据。以下是一个简化的Java消费者示例代码:
import org.apache.kafka.clients.consumer.*;import org.apache.kafka.common.TopicPartition;import java.time.Duration;import java.util.Collections;import java.util.Properties;public class TimeWindowedDataConsumer {public static void main(String[] args) {Properties properties = new Properties();properties.put("bootstrap.servers", "localhost:9092");properties.put("group.id", "time_windowed_data_group");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");Consumer<String, String> consumer = new KafkaConsumer<>(properties);// 订阅指定分区TopicPartition partitionToSubscribe = new TopicPartition("timestamped_data", 0);consumer.assign(Collections.singletonList(partitionToSubscribe));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.printf("Received record with key %s and value %s from partition %d%n",record.key(), record.value(), record.partition());// 在这里进行按时间窗口统计的业务逻辑}}}}
在实际应用中,你可能会根据业务逻辑动态订阅多个分区,以处理更多时间窗口的数据。
分区的内部工作原理
理解Partition在Kafka中的内部工作原理有助于更深入地使用和优化Kafka。以下是一些关键的工作原理:
1 分区的负载均衡
Kafka的生产者在将消息发送到分区时,使用分区键的哈希函数来决定消息应该被分配到哪个分区。这种哈希算法有助于实现负载均衡,确保消息均匀分布在所有分区上。
2 分区的数据保留和清理
每个分区都维护着自己的消息日志,Kafka支持配置消息的保留时间和大小。当消息达到指定的保留时间或大小时,Kafka会进行清理,删除过期的消息。这有助于控制存储占用和维持系统性能。
3 分区的复制机制
为了提高系统的可用性和容错性,Kafka使用分区的复制机制。每个分区可以有多个副本,分布在不同的Broker上。生产者向主分区发送消息,而主分区负责将消息复制到所有副本。这种设计保证了即使某个Broker发生故障,仍然可以从其他副本中获取数据。
性能调优与监控
1 监控工具
Kafka提供了一些监控工具,例如JConsole、Kafka Manager等,可以用于实时监控Kafka集群的状态。这些工具可以展示各个分区的吞吐量、偏移量、副本状态等信息,有助于及时发现和解决问题。
2 性能调优
性能调优是使用Kafka的关键一环。你可以通过调整Producer和Consumer的参数,以及适时更新Broker的配置来优化系统性能。例如,调整Producer的batch.size和linger.ms参数以优化消息的批量发送,或者调整Consumer的max.poll.records参数以优化批量处理能力。
3 数据压缩
Kafka支持消息的压缩,可以通过配置Producer的compression.type参数来选择压缩算法。压缩可以降低网络传输成本,提高数据的传输效率。
properties.put("compression.type", "gzip");
总结
本文详细介绍了Kafka中的Partition概念,从创建、配置、内部工作原理到实际应用示例和性能调优等多个方面进行了深入的讨论。希望这些详细的示例代码和解释能够帮助大家更全面地理解和应用Kafka中的Partition。在实际应用中,根据业务需求和系统规模,可以灵活配置Partition以达到最佳性能和可靠性。






7.自定义分区
public interface Partitioner extends Configurable, Closeable {
/*** Compute the partition for the given record.** @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes The serialized key to partition on( or null if no key)* @param value The value to partition on or null* @param valueBytes The serialized value to partition on or null* @param cluster The current cluster metadata*/public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/*** This is called when partitioner is closed.*/public void close();
/*** Notifies the partitioner a new batch is about to be created. When using the sticky partitioner,* this method can change the chosen sticky partition for the new batch. * @param topic The topic name* @param cluster The current cluster metadata* @param prevPartition The partition previously selected for the record that triggered a new batch*/default public void onNewBatch(String topic, Cluster cluster, int prevPartition) {}
}
public interface Configurable {
/*** Configure this class with the given key-value pairs*/void configure(Map<String, ?> configs);
}
1.随机分区 方式
/*** 自定义分区 随机分区*/
public class RandomPartitioner implements Partitioner {
private Random random = new Random();@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {Integer partitionNum = cluster.partitionCountForTopic(topic);//随机生产int i = random.nextInt(partitionNum);return i;}
@Overridepublic void close() {
}
@Overridepublic void configure(Map<String, ?> configs) {
}
}
注册使用
修改: producer.properties
partitioner.class=com.study.bigdata.RandomPartitioner
或代码中使用
prop.put("partition.class", com.study.bigdata.RandomPartitioner.class);
2.hash方式
/*** 自定义分区之Hash分区* key的hashCode*/
public class HashPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 获取topic的分区Integer partitionNum = cluster.partitionCountForTopic(topic);if(keyBytes != null){return Math.abs(key.hashCode()) % partitionNum;}return 0; //如果Key不存,那么直接返回0}
@Overridepublic void close() {
}
@Overridepublic void configure(Map<String, ?> configs) {
}
}
注册使用
修改: producer.properties
partitioner.class=com.study.bigdata.HashPartitioner
或代码中使用
prop.put("partition.class", com.study.bigdata.HashPartitioner.class);
3.轮询方式 (默认)
/*** 自定义分区之轮询分区*/
public class RoundRobinPartintioner implements Partitioner {
/*** 轮询操作: 我们需要创建轮询对象* counter.getAndIncrement() = i++*/private AtomicInteger counter = new AtomicInteger();@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {Integer partitionNum = cluster.partitionCountForTopic(topic);return counter.getAndIncrement() % partitionNum;}
@Overridepublic void close() {
}
@Overridepublic void configure(Map<String, ?> configs) {
}
}
注册使用
修改: producer.properties
partitioner.class=com.study.bigdata.HashPartitioner
或代码中使用
prop.put("partition.class", com.study.bigdata.HashPartitioner.class);
-
分组分区
/*** 自定义分区之分组分区*/ public class GroupPartitioner implements Partitioner { /** 将要分区的数据划分好*/private Map<String, Integer> map = new HashMap<String, Integer>();{map.put("a", 0);map.put("b", 1);map.put("c", 2);map.put("d", 3);map.put("e", 4);}@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {String line = value.toString();String[] strs = line.split("\\s");if(strs == null || strs.length != 2){return 0;}else {return map.getOrDefault(strs[0], 0);}} @Overridepublic void close() { } @Overridepublic void configure(Map<String, ?> configs) { } }/*** 自定义分区之分组分区*/ public class GroupPartitioner implements Partitioner { /** 将要分区的数据划分好*/private Map<String, Integer> map = new HashMap<String, Integer>();{map.put("a", 0);map.put("b", 1);map.put("c", 2);map.put("d", 3);map.put("e", 4);}@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {String line = value.toString();String[] strs = line.split("\\s");if(strs == null || strs.length != 2){return 0;}else {return map.getOrDefault(strs[0], 0);}} @Overridepublic void close() { } @Overridepublic void configure(Map<String, ?> configs) { } }
参考资料
附1:快速上手:学习如何使用C++实现kafka消费者客户端(快速上手:学习如何使用C++实现kafka消费者客户端_c++ 使用kafka-CSDN博客)
附2:Docker实战之Kafka集群
1. 概述
Apache Kafka 是一个快速、可扩展的、高吞吐、可容错的分布式发布订阅消息系统。其具有高吞吐量、内置分区、支持数据副本和容错的特性,适合在大规模消息处理场景中使用。
笔者之前在物联网公司工作,其中 Kafka 作为物联网 MQ 选型的事实标准,这里优先给大家搭建 Kafka 集群环境。由于 Kafka 的安装需要依赖 Zookeeper,对 Zookeeper 还不了解的小伙伴可以在 这里 先认识下 Zookeeper。
Kafka 能解决什么问题呢?先说一下消息队列常见的使用场景吧,其实场景有很多,但是比较核心的有 3 个:解耦、异步、削峰。
2. Kafka 基本概念
Kafka 部分名词解释如下:
-
Broker:消息中间件处理结点,一个 Kafka 节点就是一个 broker,多个 broker 可以组成一个 Kafka 集群。
-
Topic:一类消息,例如 page view 日志、click 日志等都可以以 topic 的形式存在,Kafka 集群能够同时负责多个 topic 的分发。
-
Partition:topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
-
Segment:partition 物理上由多个 segment 组成,下面有详细说明。
-
offset:每个 partition 都由一系列有序的、不可变的消息组成,这些消息被连续的追加到 partition 中。partition 中的每个消息都有一个连续的序列号叫做 offset,用于 partition 唯一标识一条消息.每个 partition 中的消息都由 offset=0 开始记录消息。
3. Docker 环境搭建
配合上一节的 Zookeeper 环境,计划搭建一个 3 节点的集群。宿主机 IP 为 192.168.124.5。
docker-compose-kafka-cluster.yml
version: '3.7' networks:docker_net:external: true services: kafka1:image: wurstmeister/kafkarestart: unless-stoppedcontainer_name: kafka1ports:- "9093:9092"external_links:- zoo1- zoo2- zoo3environment:KAFKA_BROKER_ID: 1KAFKA_ADVERTISED_HOST_NAME: 192.168.124.5 ## 修改:宿主机IPKAFKA_ADVERTISED_PORT: 9093 ## 修改:宿主机映射portKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.124.5:9093 ## 绑定发布订阅的端口。修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT: "zoo1:2181,zoo2:2181,zoo3:2181"volumes:- "./kafka/kafka1/docker.sock:/var/run/docker.sock"- "./kafka/kafka1/data/:/kafka"networks:- docker_net kafka2:image: wurstmeister/kafkarestart: unless-stoppedcontainer_name: kafka2ports:- "9094:9092"external_links:- zoo1- zoo2- zoo3environment:KAFKA_BROKER_ID: 2KAFKA_ADVERTISED_HOST_NAME: 192.168.124.5 ## 修改:宿主机IPKAFKA_ADVERTISED_PORT: 9094 ## 修改:宿主机映射portKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.124.5:9094 ## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT: "zoo1:2181,zoo2:2181,zoo3:2181"volumes:- "./kafka/kafka2/docker.sock:/var/run/docker.sock"- "./kafka/kafka2/data/:/kafka"networks:- docker_net kafka3:image: wurstmeister/kafkarestart: unless-stoppedcontainer_name: kafka3ports:- "9095:9092"external_links:- zoo1- zoo2- zoo3environment:KAFKA_BROKER_ID: 3KAFKA_ADVERTISED_HOST_NAME: 192.168.124.5 ## 修改:宿主机IPKAFKA_ADVERTISED_PORT: 9095 ## 修改:宿主机映射portKAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.124.5:9095 ## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT: "zoo1:2181,zoo2:2181,zoo3:2181"volumes:- "./kafka/kafka3/docker.sock:/var/run/docker.sock"- "./kafka/kafka3/data/:/kafka"networks:- docker_net kafka-manager:image: sheepkiller/kafka-manager:latestrestart: unless-stoppedcontainer_name: kafka-managerhostname: kafka-managerports:- "9000:9000"links: # 连接本compose文件创建的container- kafka1- kafka2- kafka3external_links: # 连接本compose文件以外的container- zoo1- zoo2- zoo3environment:ZK_HOSTS: zoo1:2181,zoo2:2181,zoo3:2181 ## 修改:宿主机IPTZ: CST-8networks:- docker_net
执行以下命令启动
docker-compose -f docker-compose-kafka-cluster.yml up -d
可以看到 kafka 集群已经启动成功。
4. Kafka 初认识
4.1 可视化管理
细心的小伙伴发现上边的配置除了 kafka 外还有一个 kafka-manager 模块。它是 kafka 的可视化管理模块。因为 kafka 的元数据、配置信息由 Zookeeper 管理,这里我们在 UI 页面做下相关配置。
1. 访问 http:localhost:9000,按图示添加相关配置
2. 配置后我们可以看到默认有一个 topic(__consumer_offsets),3 个 brokers。该 topic 分 50 个 partition,用于记录 kafka 的消费偏移量。
4.2 Zookeeper 在 kafka 环境中做了什么
1. 首先观察下根目录
kafka 基于 zookeeper,kafka 启动会将元数据保存在 zookeeper 中。查看 zookeeper 节点目录,会发现多了很多和 kafka 相关的目录。结果如下:
➜ docker zkCli -server 127.0.0.1:2183 Connecting to 127.0.0.1:2183 Welcome to ZooKeeper! JLine support is enabled WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: 127.0.0.1:2183(CONNECTED) 0] ls / [cluster, controller, brokers, zookeeper, admin, isr_change_notification, log_dir_event_notification, controller_epoch, zk-test0000000000, kafka-manager, consumers, latest_producer_id_block, config]
2. 查看我们映射的 kafka 目录,新版本的 kafka 偏移量不再存储在 zk 中,而是在 kafka 自己的环境中。
我们节选了部分目录(包含 2 个 partition)
├── kafka1 │ ├── data │ │ └── kafka-logs-c4e2e9edc235 │ │ ├── __consumer_offsets-1 │ │ │ ├── 00000000000000000000.index // segment索引文件 │ │ │ ├── 00000000000000000000.log // 数据文件 │ │ │ ├── 00000000000000000000.timeindex // 消息时间戳索引文件 │ │ │ └── leader-epoch-checkpoint ... │ │ ├── __consumer_offsets-7 │ │ │ ├── 00000000000000000000.index │ │ │ ├── 00000000000000000000.log │ │ │ ├── 00000000000000000000.timeindex │ │ │ └── leader-epoch-checkpoint │ │ ├── cleaner-offset-checkpoint │ │ ├── log-start-offset-checkpoint │ │ ├── meta.properties │ │ ├── recovery-point-offset-checkpoint │ │ └── replication-offset-checkpoint │ └── docker.sock
结果与 Kafka-Manage 显示结果一致。图示的文件是一个 Segment,00000000000000000000.log 表示 offset 从 0 开始,随着数据不断的增加,会有多个 Segment 文件。
5. 生产与消费
5.1 创建主题
➜ docker docker exec -it kafka1 /bin/bash # 进入容器 bash-4.4# cd /opt/kafka/ # 进入安装目录 bash-4.4# ./bin/kafka-topics.sh --list --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 # 查看主题列表 __consumer_offsets bash-4.4# ./bin/kafka-topics.sh --create --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --replication-factor 2 --partitions 3 --topic test # 新建主题 Created topic test.
说明: --replication-factor 副本数; --partitions 分区数; replication<=broker(一定); 有效消费者数<=partitions 分区数(一定);
新建主题后, 再次查看映射目录, 由图可见,partition 在 3 个 broker 上均匀分布。
5.2 生产消息
bash-4.4# ./bin/kafka-console-producer.sh --broker-list kafka1:9092,kafka2:9092,kafka3:9092 --topic test >msg1 >msg2 >msg3 >msg4 >msg5 >msg6
5.3 消费消息
bash-4.4# ./bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --topic test --from-beginning msg1 msg3 msg2 msg4 msg6 msg5
--from-beginning 代表从头开始消费
5.4 消费详情
查看消费者组
bash-4.4# ./bin/kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --list KafkaManagerOffsetCache console-consumer-86137
消费组偏移量
bash-4.4# ./bin/kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --describe --group KafkaManagerOffsetCache
查看 topic 详情
bash-4.4# ./bin/kafka-topics.sh --zookeeper zoo1:2181,zoo2:2181,zoo3:2181 --describe --topic test Topic: test PartitionCount: 3 ReplicationFactor: 2 Configs:Topic: test Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1Topic: test Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: test Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3
查看.log 数据文件
bash-4.4# ./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.log --print-data-log Dumping /kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.log Starting offset: 0 baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1583317546421 size: 72 magic: 2 compresscodec: NONE crc: 1454276831 isvalid: true | offset: 0 CreateTime: 1583317546421 keysize: -1 valuesize: 4 sequence: -1 headerKeys: [] payload: msg2 baseOffset: 1 lastOffset: 1 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 72 CreateTime: 1583317550369 size: 72 magic: 2 compresscodec: NONE crc: 3578672322 isvalid: true | offset: 1 CreateTime: 1583317550369 keysize: -1 valuesize: 4 sequence: -1 headerKeys: [] payload: msg4 baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 144 CreateTime: 1583317554831 size: 72 magic: 2 compresscodec: NONE crc: 2727139808 isvalid: true | offset: 2 CreateTime: 1583317554831 keysize: -1 valuesize: 4 sequence: -1 headerKeys: [] payload: msg6
这里需要看下自己的文件路径是什么,别直接 copy 我的哦
查看.index 索引文件
bash-4.4# ./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.index Dumping /kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.index offset: 0 position: 0
查看.timeindex 索引文件
bash-4.4# ./bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.timeindex --verify-index-only Dumping /kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.timeindex Found timestamp mismatch in :/kafka/kafka-logs-c4e2e9edc235/test-0/00000000000000000000.timeindexIndex timestamp: 0, log timestamp: 1583317546421
6. SpringBoot 集成
笔者 SpringBoot 版本是 2.2.2.RELEASE
pom.xml 添加依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.4.0.RELEASE</version></dependency>
生产者配置
@Configuration
public class KafkaProducerConfig {
/*** producer配置* @return*/public Map<String, Object> producerConfigs() {Map<String, Object> props = new HashMap<>();// 指定多个kafka集群多个地址 127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.5:9093,192.168.124.5:9094,192.168.124.5:9095");// 重试次数,0为不启用重试机制props.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE);// acks=0 把消息发送到kafka就认为发送成功// acks=1 把消息发送到kafka leader分区,并且写入磁盘就认为发送成功// acks=all 把消息发送到kafka leader分区,并且leader分区的副本follower对消息进行了同步就任务发送成功props.put(ProducerConfig.ACKS_CONFIG,"all");// 生产者空间不足时,send()被阻塞的时间,默认60sprops.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 6000);// 控制批处理大小,单位为字节props.put(ProducerConfig.BATCH_SIZE_CONFIG, 4096);// 批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量props.put(ProducerConfig.LINGER_MS_CONFIG, 1);// 生产者可以使用的总内存字节来缓冲等待发送到服务器的记录props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 40960);// 消息的最大大小限制,也就是说send的消息大小不能超过这个限制, 默认1048576(1MB)props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG,1048576);// 客户端idprops.put(ProducerConfig.CLIENT_ID_CONFIG,"producer.client.id.topinfo");// 键的序列化方式props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);// 值的序列化方式props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);// 压缩消息,支持四种类型,分别为:none、lz4、gzip、snappy,默认为none。// 消费者默认支持解压,所以压缩设置在生产者,消费者无需设置。props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"none");return props;}
/*** producer工厂配置* @return*/public ProducerFactory<String, String> producerFactory() {return new DefaultKafkaProducerFactory<>(producerConfigs());}
/*** Producer Template 配置*/@Bean(name="kafkaTemplate")public KafkaTemplate<String, String> kafkaTemplate() {return new KafkaTemplate<>(producerFactory());}
}
消费者配置
@Configuration
public class KafkaConsumerConfig {
private static final String GROUP0_ID = "group0";private static final String GROUP1_ID = "group1";
/*** 1. setAckMode: 消费者手动提交ack** RECORD: 每处理完一条记录后提交。* BATCH(默认): 每次poll一批数据后提交一次,频率取决于每次poll的调用频率。* TIME: 每次间隔ackTime的时间提交。* COUNT: 处理完poll的一批数据后并且距离上次提交处理的记录数超过了设置的ackCount就提交。* COUNT_TIME: TIME和COUNT中任意一条满足即提交。* MANUAL: 手动调用Acknowledgment.acknowledge()后,并且处理完poll的这批数据后提交。* MANUAL_IMMEDIATE: 手动调用Acknowledgment.acknowledge()后立即提交。** 2. factory.setConcurrency(3);* 此处设置的目的在于:假设 topic test 下有 0、1、2三个 partition,Spring Boot中只有一个 @KafkaListener() 消费者订阅此 topic,此处设置并发为3,* 启动后 会有三个不同的消费者分别订阅 p0、p1、p2,本地实际有三个消费者线程。* 而 factory.setConcurrency(1); 的话 本地只有一个消费者线程, p0、p1、p2被同一个消费者订阅。* 由于 一个partition只能被同一个消费者组下的一个消费者订阅,对于只有一个 partition的topic,即使设置 并发为3,也只会有一个消费者,多余的消费者没有 partition可以订阅。** 3. factory.setBatchListener(true);* 设置批量消费 ,每个批次数量在Kafka配置参数ConsumerConfig.MAX_POLL_RECORDS_CONFIG中配置,* 限制的是 一次批量接收的最大条数,而不是 等到达到最大条数才接收,这点容易被误解。* 实际测试时,接收是实时的,当生产者大量写入时,一次批量接收的消息数量为 配置的最大条数。*/@BeanKafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory() {ConcurrentKafkaListenerContainerFactory<Integer, String>factory = new ConcurrentKafkaListenerContainerFactory<>();// 设置消费者工厂factory.setConsumerFactory(consumerFactory());// 设置为批量消费,每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIGfactory.setBatchListener(true);// 消费者组中线程数量,消费者数量<=partition数量,即使配置的消费者数量大于partition数量,多余消费者无法消费到数据。factory.setConcurrency(4);// 拉取超时时间factory.getContainerProperties().setPollTimeout(3000);// 手动提交factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);return factory;}
@Beanpublic ConsumerFactory<Integer, String> consumerFactory() {Map<String, Object> map = consumerConfigs();map.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP0_ID);return new DefaultKafkaConsumerFactory<>(consumerConfigs());}
// @Bean
// KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory1() {
// ConcurrentKafkaListenerContainerFactory<Integer, String>
// factory = new ConcurrentKafkaListenerContainerFactory<>();
// // 设置消费者工厂
// factory.setConsumerFactory(consumerFactory1());
// // 设置为批量消费,每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIG
// factory.setBatchListener(true);
// // 消费者组中线程数量,消费者数量<=partition数量,即使配置的消费者数量大于partition数量,多余消费者无法消费到数据。
// factory.setConcurrency(3);
// // 拉取超时时间
// factory.getContainerProperties().setPollTimeout(3000);
// // 手动提交
// factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
// return factory;
// }
//
// public ConsumerFactory<Integer, String> consumerFactory1() {
// Map<String, Object> map = consumerConfigs();
// map.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP1_ID);
// return new DefaultKafkaConsumerFactory<>(consumerConfigs());
// }
@Beanpublic Map<String, Object> consumerConfigs() {Map<String, Object> props = new HashMap<>();// Kafka地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.124.5:9093,192.168.124.5:9094,192.168.124.5:9095");// 是否自动提交offset偏移量(默认true)props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);// 批量消费props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "100");// 消费者组props.put(ConsumerConfig.GROUP_ID_CONFIG, "group-default");// 自动提交的频率(ms)
// propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100");// Session超时设置props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000");// 键的反序列化方式props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);// 值的反序列化方式props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);// offset偏移量规则设置:// (1)、earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费// (2)、latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据// (3)、none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");return props;}
}
主题配置
@Configuration
public class KafkaTopicConfig {
/*** 定义一个KafkaAdmin的bean,可以自动检测集群中是否存在topic,不存在则创建*/@Beanpublic KafkaAdmin kafkaAdmin() {Map<String, Object> configs = new HashMap<>();// 指定多个kafka集群多个地址,例如:192.168.2.11,9092,192.168.2.12:9092,192.168.2.13:9092configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.124.5:9093,192.168.124.5:9094,192.168.124.5:9095");return new KafkaAdmin(configs);}
/*** 创建 Topic*/@Beanpublic NewTopic topicinfo() {// 创建topic,需要指定创建的topic的"名称"、"分区数"、"副本数量(副本数数目设置要小于Broker数量)"return new NewTopic("test", 3, (short) 2);}
}
消费者服务
@Slf4j
@Service
public class KafkaConsumerService {
// /**
// * 单条消费
// * @param message
// */
// @KafkaListener(id = "id0", topics = {Constant.TOPIC}, containerFactory="kafkaListenerContainerFactory")
// public void kafkaListener0(String message){
// log.info("consumer:group0 --> message:{}", message);
// }
//
// @KafkaListener(id = "id1", topics = {Constant.TOPIC}, groupId = "group1")
// public void kafkaListener1(String message){
// log.info("consumer:group1 --> message:{}", message);
// }
// /**
// * 监听某个 Topic 的某个分区示例,也可以监听多个 Topic 的分区
// * 为什么找不到group2呢?
// * @param message
// */
// @KafkaListener(id = "id2", groupId = "group2", topicPartitions = { @TopicPartition(topic = Constant.TOPIC, partitions = { "0" }) })
// public void kafkaListener2(String message) {
// log.info("consumer:group2 --> message:{}", message);
// }
//
// /**
// * 获取监听的 topic 消息头中的元数据
// * @param message
// * @param topic
// * @param key
// */
// @KafkaListener(id = "id3", topics = Constant.TOPIC, groupId = "group3")
// public void kafkaListener(@Payload String message,
// @Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
// @Header(KafkaHeaders.RECEIVED_PARTITION_ID) String partition,
// @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) String key) {
// Long threadId = Thread.currentThread().getId();
// log.info("consumer:group3 --> message:{}, topic:{}, partition:{}, key:{}, threadId:{}", message, topic, partition, key, threadId);
// }
//
// /**
// * 监听 topic 进行批量消费
// * @param messages
// */
// @KafkaListener(id = "id4", topics = Constant.TOPIC, groupId = "group4")
// public void kafkaListener(List<String> messages) {
// for(String msg:messages){
// log.info("consumer:group4 --> message:{}", msg);
// }
// }
//
// /**
// * 监听topic并手动提交偏移量
// * @param messages
// * @param acknowledgment
// */
// @KafkaListener(id = "id5", topics = Constant.TOPIC,groupId = "group5")
// public void kafkaListener(List<String> messages, Acknowledgment acknowledgment) {
// for(String msg:messages){
// log.info("consumer:group5 --> message:{}", msg);
// }
// // 触发提交offset偏移量
// acknowledgment.acknowledge();
// }
//
// /**
// * 模糊匹配多个 Topic
// * @param message
// */
// @KafkaListener(id = "id6", topicPattern = "test.*",groupId = "group6")
// public void annoListener2(String message) {
// log.error("consumer:group6 --> message:{}", message);
// }
/*** 完整consumer* @return*/@KafkaListener(id = "id7", topics = {Constant.TOPIC}, groupId = "group7")public boolean consumer4(List<ConsumerRecord<?, ?>> data) {for (int i=0; i<data.size(); i++) {ConsumerRecord<?, ?> record = data.get(i);Optional<?> kafkaMessage = Optional.ofNullable(record.value());
Long threadId = Thread.currentThread().getId();if (kafkaMessage.isPresent()) {Object message = kafkaMessage.get();log.info("consumer:group7 --> message:{}, topic:{}, partition:{}, key:{}, offset:{}, threadId:{}", message.toString(), record.topic(), record.partition(), record.key(), record.offset(), threadId);}}
return true;}
}
生产者服务
@Service
public class KafkaProducerService {
@Autowiredprivate KafkaTemplate kafkaTemplate;
/*** producer 同步方式发送数据* @param topic topic名称* @param key 一般用业务id,相同业务在同一partition保证消费顺序* @param message producer发送的数据*/public void sendMessageSync(String topic, String key, String message) throws InterruptedException, ExecutionException, TimeoutException {// 默认轮询partitionkafkaTemplate.send(topic, message).get(10, TimeUnit.SECONDS);
// // 根据key进行hash运算,再将运算结果写入到不同partition
// kafkaTemplate.send(topic, key, message).get(10, TimeUnit.SECONDS);
// // 第二个参数为partition,当partition和key同时设置时partition优先。
// kafkaTemplate.send(topic, 0, key, message);
// // 组装消息
// Message msg = MessageBuilder.withPayload("Send Message(payload,headers) Test")
// .setHeader(KafkaHeaders.MESSAGE_KEY, key)
// .setHeader(KafkaHeaders.TOPIC, topic)
// .setHeader(KafkaHeaders.PREFIX,"kafka_")
// .build();
// kafkaTemplate.send(msg).get(10, TimeUnit.SECONDS);
// // 组装消息
// ProducerRecord<String, String> producerRecord = new ProducerRecord<>("test", "Send ProducerRecord(topic,value) Test");
// kafkaTemplate.send(producerRecord).get(10, TimeUnit.SECONDS);}
/*** producer 异步方式发送数据* @param topic topic名称* @param message producer发送的数据*/public void sendMessageAsync(String topic, String message) {ListenableFuture<SendResult<Integer, String>> future = kafkaTemplate.send(topic, message);
// 设置异步发送消息获取发送结果后执行的动作ListenableFutureCallback listenableFutureCallback = new ListenableFutureCallback<SendResult<Integer, String>>() {@Overridepublic void onSuccess(SendResult<Integer, String> result) {System.out.println("success");}
@Overridepublic void onFailure(Throwable ex) {System.out.println("failure");}};
// 将listenableFutureCallback与异步发送消息对象绑定future.addCallback(listenableFutureCallback);}
public void test(String topic, Integer partition, String key, String message) throws InterruptedException, ExecutionException, TimeoutException {kafkaTemplate.send(topic, partition, key, message).get(10, TimeUnit.SECONDS);}
}
web 测试
@RestController
public class KafkaProducerController {
@Autowiredprivate KafkaProducerService producerService;
@GetMapping("/sync")public void sendMessageSync(@RequestParam String topic) throws InterruptedException, ExecutionException, TimeoutException {producerService.sendMessageSync(topic, null, "同步发送消息测试");}
@GetMapping("/async")public void sendMessageAsync(){producerService.sendMessageAsync("test","异步发送消息测试");}
@GetMapping("/test")public void test(@RequestParam String topic, @RequestParam(required = false) Integer partition, @RequestParam(required = false) String key, @RequestParam String message) throws InterruptedException, ExecutionException, TimeoutException {producerService.test(topic, partition, key, message);}
}
附3:Kafka快速入门(六)——Kafka集群部署(Kafka快速入门(六)——Kafka集群部署_51CTO博客_kafka集群部署)
一、Kafka集群部署方案规划
1、操作系统选择
通常,生产环境应该将Kafka集群部署在Linux操作系统上,原因如下: (1)Kafka客户端底层使用了Java的selector,selector在Linux上的实现机制是epoll,而在Windows平台上的实现机制是select,因此Kafka部署在Linux上能够获得更高效的I/O性能。 (2)网络传输效率的差别。Kafka需要在磁盘和网络间进行大量数据传输,在Linux部署Kafka能够享受到零拷贝(Zero Copy)技术所带来的快速数据传输特性。 (3)社区的支持度。Apache Kafka社区目前对Windows平台上发现的Kafka Bug不做任何承诺。
2、磁盘
(1)Kafka实现了冗余机制来提供高可靠性,并通过分区机制在软件层面实现负载均衡,因此Kafka的磁盘存储可以不使用磁盘阵列(RAID),使用普通磁盘组成存储空间即可。 (2)使用机械磁盘能够胜任Kafka线上环境,但SSD显然性能更好。
3、磁盘容量
规划磁盘容量时需要考虑:新增消息数、消息留存时间、平均消息大小、备份数、是否启用压缩等因素。 假设公司业务每天需要向Kafka集群发送100000000条消息,每条消息保存两份以防止数据丢失,消息默认保存7天时间,消息的平均大小是1KB,Kafka的数据压缩比是0.75。 每天100000000条1KB大小的消息,保存两份,压缩比0.75,占用空间大小就等于150GB(100000000*1KB*2/1000/1000*0.75),考虑到Kafka集群的索引数据等,需要预留出10%的磁盘空间,因此每天总存储容量是165GB。数据留存7天,因此规划磁盘容量为1155GB(165GB*7)。
4、网络带宽
假设公司的机房环境是千兆网络,即1Gbps,业务需要在1小时内处理1TB的业务数据。假设Kafka Broker会用到70%的带宽资源,超过70%的阈值可能网络丢包,单台Kafka Broker最多能使用大约700Mb的带宽资源,但通常需要再额外为其它服务预留出2/3的资源,即Kafka Broker可以为Kafka服务分配带宽240Mbps(700Mb/3)。1小时处理1TB数据,则每秒需要处理2336Mb(1024*1024*8/3600)数据,除以240,约等于10台服务器。如果还需要额外复制两份,那么服务器台数还要乘以3,即30台。
二、Kafka集群参数配置
1、Broker端参数
Broker端参数也被称为静态参数(Static Configs),静态参数只能在Kafka的配置文件server.properties中进行设置,必须重启Broker进程才能生效。 log.dirs:指定Broker需要使用的若干个文件目录路径,没有默认值,必须指定。在生产环境中一定要为log.dirs配置多个路径,如果条件允许,需要保证目录被挂载到不同的物理磁盘上。优势在于,提升读写性能,多块物理磁盘同时读写数据具有更高的吞吐量;能够实现故障转移(Failover),Kafka 1.1版本引入Failover功能,坏掉磁盘上的数据会自动地转移到其它正常的磁盘上,而且Broker还能正常工作,基于Failover机制,Kafka可以舍弃RAID方案。 zookeeper.connect:CS格式参数,可以指定值为zk1:2181,zk2:2181,zk3:2181,不同Kafka集群可以指定:zk1:2181,zk2:2181,zk3:2181/kafka1,chroot只需要写一次。 listeners:设置内网访问Kafka服务的监听器。 advertised.listeners:设置外网访问Kafka服务的监听器。 auto.create.topics.enable:是否允许自动创建Topic。 unclean.leader.election.enable:是否允许Unclean Leader 选举。 auto.leader.rebalance.enable:是否允许定期进行Leader选举,生产环境中建议设置成false。 log.retention.{hours|minutes|ms}:控制一条消息数据被保存多长时间。优先级:ms设置最高、minutes次之、hours最低。 log.retention.bytes:指定Broker为消息保存的总磁盘容量大小。message.max.bytes:控制Broker能够接收的最大消息大小。
2、Topic级别参数
如果同时设置了Topic级别参数和全局Broker参数,Topic级别参数会覆盖全局Broker参数,而每个Topic都能设置自己的参数值。 生产环境中,应当允许不同部门的Topic根据自身业务需要,设置自己的留存时间。如果只能设置全局Broker参数,那么势必要提取所有业务留存时间的最大值作为全局参数值,此时设置Topic级别参数对Broker参数进行覆盖就是一个不错的选择。 retention.ms:指定Topic消息被保存的时长,默认是7天,只保存最近7天的消息,会覆盖掉Broker端的全局参数值。 retention.bytes:指定为Topic预留多大的磁盘空间。通常在多租户的Kafka集群中使用,默认值是 -1,表示可以无限使用磁盘空间。 max.message.bytes:指定Kafka Broker能够正常接收Topic 的最大消息大小。 Topic级别参数可以在创建Topic时进行设置,也可以在修改Topic 时设置,推荐在修改Topic时进行设置,Apache Kafka社区未来可能统一使用kafka-configs脚本来设置Topic级别参数。
3、JVM参数
Kafka 2.0.0版本已经正式摒弃对Java 7的支持。 Kafka Broker在与客户端进行交互时会在JVM堆上创建大量的Byte Buffer实例,因此JVM端设置的Heap Size不能太小,建议设置6GB。 export KAFKA_HEAP_OPTS=--Xms6g --Xmx6g JVM端配置的一个重要参数是垃圾回收器的设置。对于Java 7,如果Broker所在机器的CPU资源非常充裕,建议使用CMS收集器。启用方法是指定-XX:+UseCurrentMarkSweepGC。否则,使用吞吐量收集器,开启方法是指定-XX:+UseParallelGC。对于Java 9,用默认的G1收集器,在没有任何调优的情况下,G1表现得要比CMS出色,主要体现在更少的Full GC,需要调整的参数更少等,所以使用G1就好。 export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
4、操作系统参数
件描述符限制:ulimit -n。建议设置成一个超大的值,如ulimit -n 1000000。 文件系统类型:文件系统类型的选择。根据官网的测试报告,XFS 的性能要强于ext4。 Swappiness:推荐设置为一个较小值,如1。如果将swap设置为0,将会完全禁止Kafka Broker进程使用swap空间;当物理内存耗尽时,操作系统会触发OOM killer组件,随机挑选一个进程kill掉,不给用户任何预警。如果设置一个比较小值,当开始使用swap空间时,Broker性能会出现急剧下降,从而给进一步调优和诊断问题的时间。 提交时间:提交时间(Flush落盘时间)。向Kafka发送数据并不是真要等数据被写入磁盘才会认为成功,而是只要数据被写入到操作系统的页缓存(Page Cache)上就认为写入成功,随后操作系统根据LRU算法会定期将页缓存上的脏数据落盘到物理磁盘上。页缓存数据写入磁盘的周期由提交时间来确定,默认是5秒,可以适当地增加提交间隔来降低物理磁盘的写操作。如果在页缓存中的数据在写入到磁盘前机器宕机,数据会丢失,但鉴于Kafka在软件层面已经提供了多副本的冗余机制,拉大提交间隔换取性能是一个合理的做法。
三、Docker镜像选择
1、安装docker
安装Docker:sudo yum install docker 启动Docker:sudo systemctl start docker docker版本检查:docker version
2、docker-compose安装
docker-compose下载:sudo curl -L https://github.com/docker/compose/releases/download/1.23.0-rc3/docker-compose-uname -s-uname -m-o /usr/local/bin/docker-compose docker-compose安装:sudo chmod +x /usr/local/bin/docker-compose docker-compose版本检查:docker-compose version
3、docker镜像选择
zookeeper镜像选择: docker search zookeeper 选择star最多的镜像:docker.io/zookeeper Kafka镜像选择: docker search kafka 选择star最多的镜像:docker.io/wurstmeister/kafka kafka-manager镜像选择: docker search kafka-manager 选择镜像:kafkamanager/kafka-manager
四、Kafka单机部署方案
1、编写docker-compose.yml文件
# 单机 zookeeper + kafka + kafka-manager集群 version: '2' services:# 定义zookeeper服务zookeeper-test:image: zookeeper # zookeeper镜像restart: alwayshostname: zookeeper-testports:- "12181:2181" # 宿主机端口:docker内部端口container_name: zookeeper-test # 容器名称 # 定义kafka服务kafka-test:image: wurstmeister/kafka # kafka镜像restart: alwayshostname: kafka-testports:- "9092:9092" # 对外暴露端口号- "9999:9999" # 对外暴露JMX_PORTenvironment:KAFKA_ADVERTISED_HOST_NAME: 192.168.0.105 #KAFKA_ADVERTISED_PORT: 9092 # KAFKA_ZOOKEEPER_CONNECT: zookeeper-test:2181 # zookeeper服务KAFKA_ZOOKEEPER_CONNECTION_TIMEOUT_MS: 30000 # zookeeper连接超时KAFKA_LOG_CLEANUP_POLICY: "delete"KAFKA_LOG_RETENTION_HOURS: 120 # 设置消息数据保存的最长时间为120小时KAFKA_MESSAGE_MAX_BYTES: 10000000 # 消息体的最大字节数KAFKA_REPLICA_FETCH_MAX_BYTES: 10000000 # KAFKA_GROUP_MAX_SESSION_TIMEOUT_MS: 60000 # KAFKA_NUM_PARTITIONS: 1 # 分区数量KAFKA_DELETE_RETENTION_MS: 10000 # KAFKA_BROKER_ID: 1 # kafka的IDKAFKA_COMPRESSION_TYPE: lz4KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=192.168.0.105 -Dcom.sun.management.jmxremote.rmi.port=9999" # 导入KAFKA_JMX_OPTS环境变量JMX_PORT: 9999 # 导入JMX_PORT环境变量depends_on:- zookeeper-test # 依赖container_name: kafka-test # 定义kafka-manager服务kafka-manager-test:image: kafkamanager/kafka-manager # kafka-manager镜像restart: alwayscontainer_name: kafka-manager-testhostname: kafka-manager-testports:- "9000:9000" # 对外暴露端口,提供web访问depends_on:- kafka-test # 依赖environment:ZK_HOSTS: zookeeper-test:2181 # 宿主机IPKAFKA_BROKERS: kafka-test:9090 # kafkaKAFKA_MANAGER_AUTH_ENABLED: "true" # 开启安全认证KAFKA_MANAGER_USERNAME: kafka-manager # Kafka Manager登录用户KAFKA_MANAGER_PASSWORD: 123456 # Kafka Manager登录密码
需要确认相应端口是否被占用。
2、启动服务
创建kafka目录,将docker-compose.yml文件放入kafka目录,在kafka目录执行命令。 启动: docker-compose up -d 关闭: docker-compose down
3、kafka服务查看
进入docker容器: docker exec -it kafka /bin/bash 创建Topic: kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 3 --topic test 查看Topic: kafka-topics.sh --list --zookeeper zookeeper:2181 生产消息: kafka-console-producer.sh --broker-list kafka:9092 --topic test 消费消息: kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic test --from-beginning 打开两个Terminal,一个执行生产消息的命令,一个执行消费消息的命令,每生产一条消息时消费消息Terminal就会显示一条消息,实现消息队列。
4、Kafka版本查询
wurstmeister/kafka镜像中,kafka安装在/opt目录下,进入/opt目录,kafka_2.12-2.4.0目录即为kafka安装目录。 Scala版本:2.12 Kafka版本:2.4
5、kafka-manager监控
Web方式访问:http://127.0.0.1:9000
五、错误解决
1、容器删除失败
docker rm -f $(docker ps -a --filter status=dead -q |head -n 1) 报错信息: ERROR: for f78856fb92e9_zoo1 Driver overlay2 failed to remove root filesystem f78856fb92e97f75ff4c255077de544b39351a4a2a3319737ada2a54df568032: remove /var/lib/docker/overlay2/2c257b8071b6a3d79e216838522f76ba7263d466a470dc92cdbef25c4dd04dc3/merged: device or resource busy grep docker /proc/*/mountinfo|grep containerid | awk -F ":" '{print $1}' | awk -F "/" '{print $3}' sudo kill -9 3119
2、kafka服务一直重启
报错信息: Error response from daemon: Container 9b3f9af8a1196f2ad3cf74fe2b1eeb7ccbd231fe2a93ec09f594d3a0fbb5783c is restarting, wait until the container is running 错误原因: docker-compose.yml文件对kafka服务配置restart: always,如果kafka服务启动失败会一直重启,可以通过docker logs kafka查看kafka服务启动的日志信息,查找错误原因。
六、Kafka集群参数配置
############################# System ###################### # 唯一标识在集群中的ID,要求是正数。 broker.id = 0 # 服务端口,默认9092 port = 9092 # 监听地址,不设为所有地址 host.name = debugo01 # 处理网络请求的最大线程数 num.network.threads = 2 # 处理磁盘I/O的线程数 num.io.threads = 8 # 一些后台线程数 background.threads = 4 # 等待IO线程处理的请求队列最大数 queued.max.requests = 500 # socket的发送缓冲区(SO_SNDBUF) socket.send.buffer.bytes = 1048576 # socket的接收缓冲区 (SO_RCVBUF) socket.receive.buffer.bytes = 1048576 # socket请求的最大字节数。为了防止内存溢出,message.max.bytes必然要小于 socket.request.max.bytes = 104857600 ############################# Topic ######################## # 每个topic的分区个数,更多的partition会产生更多的segment file num.partitions = 2 # 是否允许自动创建topic ,若是false,就需要通过命令创建topic auto.create.topics.enable = true # 一个topic ,默认分区的replication个数 ,不能大于集群中broker的个数。 default.replication.factor = 1 # 消息体的最大大小,单位是字节 message.max.bytes = 1000000 ############################# ZooKeeper #################### # Zookeeper quorum设置。如果有多个使用逗号分割 zookeeper.connect = debugo01:2181, debugo02, debugo03 # 连接zk的超时时间 zookeeper.connection.timeout.ms = 1000000 # ZooKeeper集群中leader和follower之间的同步实际 zookeeper.sync.time.ms = 2000 ############################# Log ######################### # 日志存放目录,多个目录使用逗号分割 log.dirs = / var / log / kafka # 当达到下面的消息数量时,会将数据flush到日志文件中。默认10000 # log.flush.interval.messages=10000 # 当达到下面的时间(ms)时,执行一次强制的flush操作。interval.ms和interval.messages无论哪个达到,都会flush。默认3000ms # log.flush.interval.ms=1000 # 检查是否需要将日志flush的时间间隔 log.flush.scheduler.interval.ms = 3000 # 日志清理策略(delete|compact) log.cleanup.policy = delete # 日志保存时间 (hours|minutes),默认为7天(168小时)。超过这个时间会根据policy处理数据。bytes和minutes无论哪个先达到都会触发。 log.retention.hours = 168 # 日志数据存储的最大字节数。超过这个时间会根据policy处理数据。 # log.retention.bytes=1073741824 # 控制日志segment文件的大小,超出该大小则追加到一个新的日志segment文件中(-1表示没有限制) log.segment.bytes = 536870912 # 当达到下面时间,会强制新建一个segment log.roll.hours = 24 * 7 # 日志片段文件的检查周期,查看它们是否达到了删除策略的设置(log.retention.hours或log.retention.bytes) log.retention.check.interval.ms = 60000 # 是否开启压缩 log.cleaner.enable = false # 对于压缩的日志保留的最长时间 log.cleaner.delete.retention.ms = 1 day # 对于segment日志的索引文件大小限制 log.index.size.max.bytes = 10 * 1024 * 1024 # y索引计算的一个缓冲区,一般不需要设置。 log.index.interval.bytes = 4096 ############################# replica ####################### # partition management controller 与replicas之间通讯的超时时间 controller.socket.timeout.ms = 30000 # controller-to-broker-channels消息队列的尺寸大小 controller.message.queue.size = 10 # replicas响应leader的最长等待时间,若是超过这个时间,就将replicas排除在管理之外 replica.lag.time.max.ms = 10000 # 是否允许控制器关闭broker ,若是设置为true,会关闭所有在这个broker上的leader,并转移到其他broker controlled.shutdown.enable = false # 控制器关闭的尝试次数 controlled.shutdown.max.retries = 3 # 每次关闭尝试的时间间隔 controlled.shutdown.retry.backoff.ms = 5000 # 如果relicas落后太多,将会认为此partition relicas已经失效。而一般情况下,因为网络延迟等原因,总会导致replicas中消息同步滞后。如果消息严重滞后,leader将认为此relicas网络延迟较大或者消息吞吐能力有限。在broker数量较少,或者网络不足的环境中,建议提高此值. replica.lag.max.messages = 4000 # leader与relicas的socket超时时间 replica.socket.timeout.ms = 30 * 1000 # leader复制的socket缓存大小 replica.socket.receive.buffer.bytes = 64 * 1024 # replicas每次获取数据的最大字节数 replica.fetch.max.bytes = 1024 * 1024 # replicas同leader之间通信的最大等待时间,失败了会重试 replica.fetch.wait.max.ms = 500 # 每一个fetch操作的最小数据尺寸,如果leader中尚未同步的数据不足此值,将会等待直到数据达到这个大小 replica.fetch.min.bytes = 1 # leader中进行复制的线程数,增大这个数值会增加relipca的IO num.replica.fetchers = 1 # 每个replica将最高水位进行flush的时间间隔 replica.high.watermark.checkpoint.interval.ms = 5000 # 是否自动平衡broker之间的分配策略 auto.leader.rebalance.enable = false # leader的不平衡比例,若是超过这个数值,会对分区进行重新的平衡 leader.imbalance.per.broker.percentage = 10 # 检查leader是否不平衡的时间间隔 leader.imbalance.check.interval.seconds = 300 # 客户端保留offset信息的最大空间大小 offset.metadata.max.bytes = 1024 #############################Consumer ##################### # Consumer端核心的配置是group.id、zookeeper.connect # 决定该Consumer归属的唯一组ID,By setting the same group id multiple processes indicate that they are all part of the same consumer group. group.id # 消费者的ID,若是没有设置的话,会自增 consumer.id # 一个用于跟踪调查的ID ,最好同group.id相同 client.id = < group_id > # 对于zookeeper集群的指定,必须和broker使用同样的zk配置 zookeeper.connect = debugo01:2182, debugo02: 2182, debugo03: 2182 # zookeeper的心跳超时时间,查过这个时间就认为是无效的消费者 zookeeper.session.timeout.ms = 6000 # zookeeper的等待连接时间 zookeeper.connection.timeout.ms = 6000 # zookeeper的follower同leader的同步时间 zookeeper.sync.time.ms = 2000 # 当zookeeper中没有初始的offset时,或者超出offset上限时的处理方式 。 # smallest :重置为最小值 # largest:重置为最大值 # anything else:抛出异常给consumer auto.offset.reset = largest # socket的超时时间,实际的超时时间为max.fetch.wait + socket.timeout.ms. socket.timeout.ms = 30 * 1000 # socket的接收缓存空间大小 socket.receive.buffer.bytes = 64 * 1024 # 从每个分区fetch的消息大小限制 fetch.message.max.bytes = 1024 * 1024 # true时,Consumer会在消费消息后将offset同步到zookeeper,这样当Consumer失败后,新的consumer就能从zookeeper获取最新的offset auto.commit.enable = true # 自动提交的时间间隔 auto.commit.interval.ms = 60 * 1000 # 用于消费的最大数量的消息块缓冲大小,每个块可以等同于fetch.message.max.bytes中数值 queued.max.message.chunks = 10 # 当有新的consumer加入到group时,将尝试reblance,将partitions的消费端迁移到新的consumer中, 该设置是尝试的次数 rebalance.max.retries = 4 # 每次reblance的时间间隔 rebalance.backoff.ms = 2000 # 每次重新选举leader的时间 refresh.leader.backoff.ms # server发送到消费端的最小数据,若是不满足这个数值则会等待直到满足指定大小。默认为1表示立即接收。 fetch.min.bytes = 1 # 若是不满足fetch.min.bytes时,等待消费端请求的最长等待时间 fetch.wait.max.ms = 100 # 如果指定时间内没有新消息可用于消费,就抛出异常,默认-1表示不受限 consumer.timeout.ms = -1 #############################Producer###################### # 核心的配置包括: # metadata.broker.list # request.required.acks # producer.type # serializer.class # 消费者获取消息元信息(topics, partitions and replicas)的地址,配置格式是:host1:port1,host2:port2,也可以在外面设置一个vip metadata.broker.list # 消息的确认模式 # 0:不保证消息的到达确认,只管发送,低延迟但是会出现消息的丢失,在某个server失败的情况下,有点像TCP # 1:发送消息,并会等待leader 收到确认后,一定的可靠性 # -1:发送消息,等待leader收到确认,并进行复制操作后,才返回,最高的可靠性 request.required.acks = 0 # 消息发送的最长等待时间 request.timeout.ms = 10000 # socket的缓存大小 send.buffer.bytes = 100 * 1024 # key的序列化方式,若是没有设置,同serializer.class key.serializer.class # 分区的策略,默认是取模 partitioner.class =kafka.producer.DefaultPartitioner # 消息的压缩模式,默认是none,可以有gzip和snappy compression.codec = none # 可以针对默写特定的topic进行压缩 compressed.topics = null # 消息发送失败后的重试次数 message.send.max.retries = 3 # 每次失败后的间隔时间 retry.backoff.ms = 100 # 生产者定时更新topic元信息的时间间隔 ,若是设置为0,那么会在每个消息发送后都去更新数据 topic.metadata.refresh.interval.ms = 600 * 1000 # 用户随意指定,但是不能重复,主要用于跟踪记录消息 client.id = "" # 异步模式下缓冲数据的最大时间。例如设置为100则会集合100ms内的消息后发送,这样会提高吞吐量,但是会增加消息发送的延时 queue.buffering.max.ms = 5000 # 异步模式下缓冲的最大消息数,同上 queue.buffering.max.messages = 10000 # 异步模式下,消息进入队列的等待时间。若是设置为0,则消息不等待,如果进入不了队列,则直接被抛弃 queue.enqueue.timeout.ms = -1 # 异步模式下,每次发送的消息数,当queue.buffering.max.messages或queue.buffering.max.ms满足条件之一时producer会触发发送。 batch.num.messages = 200
附4:【Kafka精进系列003】Docker环境下搭建Kafka集群()
在上一节【Kafka精进系列002】Docker环境下Kafka的安装启动与消息发送中我们已经演示了如何在Docker中进行Kafka的安装与启动,以及成功地测试了Kafka消息的发送与接收过程。
在实际生产环境中,Kafka都是集群部署的,常见的架构如下: 
Kafka集群由多个Broker组成,每个Broker对应一个Kafka实例。Zookeeper负责管理Kafka集群的Leader选举以及Consumer Group发生变化的时候进行reblance操作。
本文将演示如何在Docker环境中搭建Zookeeper + Kafka集群。
通过本文,你将了解到:
-
如何使用Docker进行Kafka集群搭建;
-
如何使用Docker-compose一键构建Kakfa单节点和集群服务;
-
使用
docker-compose down -v解决docker-compose初始化创建topic时无法创建多分区问题记录;
一、Kafka集群搭建
1、首先运行Zookeeper(本文并未搭建ZK集群):
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper 1
2、分别创建3个Kafka节点,并注册到ZK上:
不同Kafka节点只需要更改端口号即可。
Kafka0:
docker run -d --name kafka0 -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.0.104:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.104:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka 1
Kafka1:
docker run -d --name kafka1 -p 9093:9093 -e KAFKA_BROKER_ID=1 -e KAFKA_ZOOKEEPER_CONNECT=192.168.0.104:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.104:9093 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9093 -t wurstmeister/kafka 1
Kafka2:
docker run -d --name kafka2 -p 9094:9094 -e KAFKA_BROKER_ID=2 -e KAFKA_ZOOKEEPER_CONNECT=192.168.0.104:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.104:9094 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9094 -t wurstmeister/kafka 1
注意:以上节点均需换成自己的IP。
启动3个Kafka节点之后,查看是否启动成功:  这样Kafka集群就算搭建完毕。
这样Kafka集群就算搭建完毕。
3、在Broker 0节点上创建一个用于测试的topic:
在Broker 0上创建一个副本为3、分区为5的topic用于测试。
(Kafka的topic所有分区会分散在不同Broker上,所以该topic的5个分区会被分散到3个Broker上,其中有两个Broker得到两个分区,另一个Broker只有1个分区。该结论在下面将会得到验证。)
cd /opt/kafka_2.12-2.4.0/bin kafka-topics.sh --create --zookeeper 192.168.0.104:2181 --replication-factor 3 --partitions 5 --topic TestTopic 1234
 查看新创建的topic信息:
查看新创建的topic信息:
kafka-topics.sh --describe --zookeeper 192.168.0.104:2181 --topic TestTopic 1
 上面的topic信息是什么意思呢? 上面提到过,“该topic的5个分区会被分散到3个Broker上,其中有两个Broker得到两个分区,另一个Broker只有1个分区”。看了这句话应该就能理解上图中的topic信息的含义。 首先,
上面的topic信息是什么意思呢? 上面提到过,“该topic的5个分区会被分散到3个Broker上,其中有两个Broker得到两个分区,另一个Broker只有1个分区”。看了这句话应该就能理解上图中的topic信息的含义。 首先,Topic: TestTopic PartitionCount: 5 ReplicationFactor: 3代表TestTopic有5个分区,3个副本节点; Topic: TestTopic Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1 Leader:2代表TestTopic下的分区0的Leader Replica在Broker.id = 2节点上, Replicas代表他的副本节点有Broker.id = 2、0、1(包括Leader Replica和Follower Replica,且不管是否存活), Isr表示存活并且同步Leader节点的副本有Broker.id = 2、0、1 关于副本机制,并不是本节的重点,因此不在本文详述,不了解的同学可以再另外去学习一下。
4、Kafka集群验证
上一步在Broker0上创建了一个topic:TestTopic,接着另开两个窗口,分别进入Kafka1和Kafka2容器内,查看在该两容器内是否已同步两topic:  可以看到,Kafka1和Kafka2上已同步新创建的topic.
可以看到,Kafka1和Kafka2上已同步新创建的topic.
接下来,分别在Broker0上运行一个生产者,Broker1、2上分别运行一个消费者:
kafka-console-producer.sh --broker-list 192.168.0.104:9092 --topic TestTopic kafka-console-consumer.sh --bootstrap-server 192.168.0.104:9093 --topic TestTopic --from-beginning kafka-console-consumer.sh --bootstrap-server 192.168.0.104:9094 --topic TestTopic --from-beginning 12345
如下图所示:  在Broker 0 上发送消息,看Broker 1和2上是否能够正常接收消息:
在Broker 0 上发送消息,看Broker 1和2上是否能够正常接收消息:
二、使用Docker-Compose 搭建Kafka集群
1、什么是Docker-Compose?
Docker-Compose是Docker提供的工具,用于同时管理同一个应用程序下多个容器。
举个例子,上面在Docker中搭建Kafka集群的步骤很繁杂,比如首先建一个ZK容器,然后再分别通过命令创建多个Kafka容器,并分别启动。而通过Docker-Compose可以使用单条命令就可以启动所有服务。
Docker和Docker-Compose之间的区别如下: 
2、如何使用Docker-Compose
如何使用Docker-compose创建Kafka相关可以见link:GitHub - wurstmeister/kafka-docker: Dockerfile for Apache Kafka . (1)创建目录
首先,在本地路径下创建一个用于存放docker-compose.yml文件的目录,并新建一个文件:docker-compose.yml (我创建的是docker-compose-kafka-single-broker.yml)
注意:遇到权限问题自行解决 
(2)单个Broker节点 下面看如何创建单Broker节点,在docker-compose-kafka-single-broker.yml文件中进行如下配置:
version: '3' services:zookeeper:image: wurstmeister/zookeepercontainer_name: zookeeperports:- "2181:2181"kafka:image: wurstmeister/kafkaports:- "9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.1.202KAFKA_CREATE_TOPICS: TestComposeTopic:2:1KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_BROKER_ID: 1KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.1.202:9092KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092container_name: kafka01volumes:- /var/run/docker.sock:/var/run/docker.sock 123456789101112131415161718192021
文件中的参数含义:
-
version: "3"表示第3代compose语法;
-
services:表示要启用的实例服务;
-
zookeeper、kafka:启动的服务名称;
-
image:docker使用的镜像;
-
container_name:启动后容器名称;
-
ports:导出的端口号;
关于Kafka的参数信息单独讲下:
-
KAFKA_ADVERTISED_HOST_NAME:Docker宿主机IP,可以设置多个;
-
KAFKA_CREATE_TOPICS:启动时默认创建的topic;
TestComposeTopic:2:1表示创建topic为TestComposeTopic、2个分区、1个副本; -
KAFKA_ZOOKEEPER_CONNECT:连接ZK;
-
KAFKA_BROKER_ID:Broker ID;
-
KAFKA_ADVERTISED_LISTENERS 和 KAFKA_LISTENERS必须要有,否则可能无法正常使用。
配置好后,使用命令 docker-compose -f docker-compose-kafka-single-broker.yml up 启动单节点Kafka。
查看启动的单Broker信息和topic信息: 
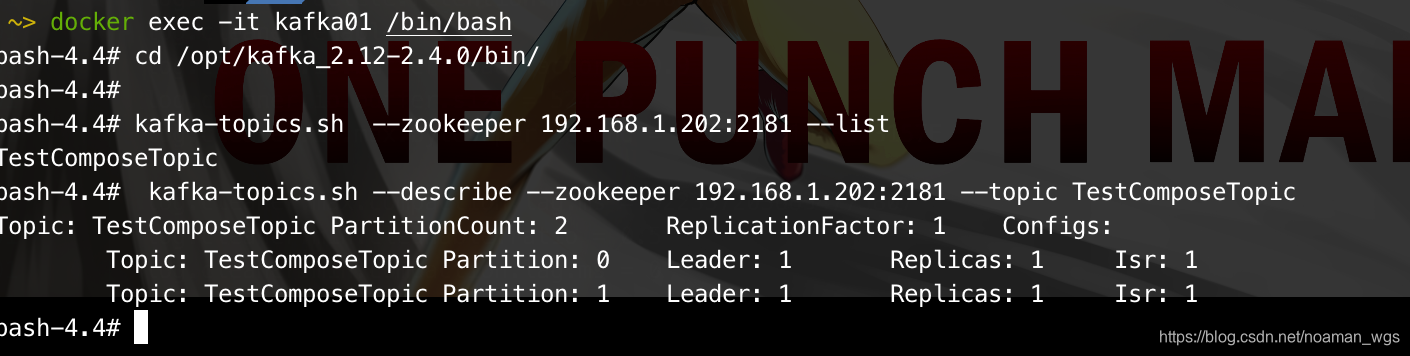
消息发送和接收验证: 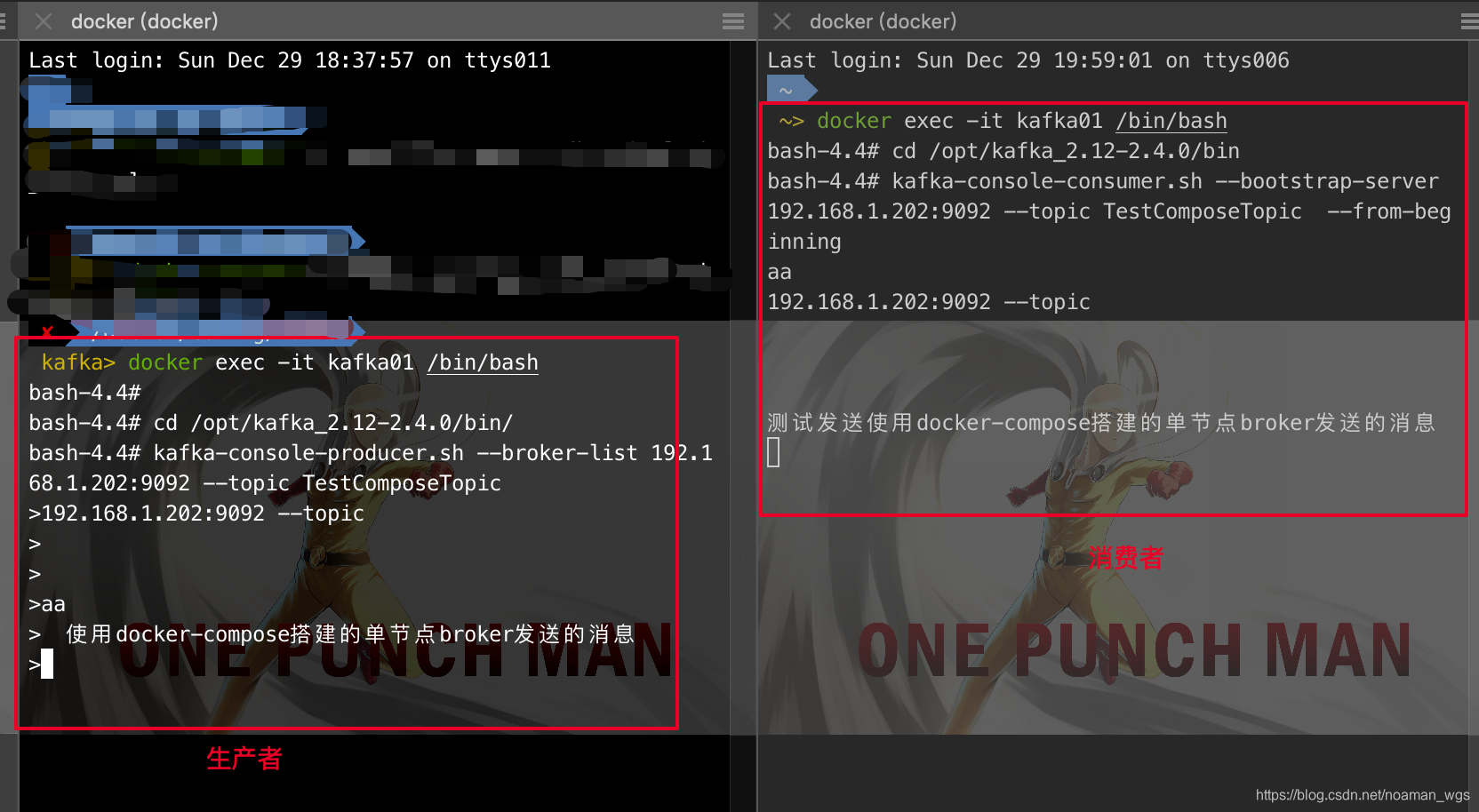
(3)Broker集群
上面使用了docker-compose成功地搭建了kafka单节点Broker,现在看如何构建Kafka集群:
首先在目录下创建一个新文件:docker-compose-kafka-single-broker.yml,配置内容如下:
version: '3' services:zookeeper:image: wurstmeister/zookeepercontainer_name: zookeeperports:- "2181:2181" kafka1:image: wurstmeister/kafkaports:- "9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.1.202KAFKA_CREATE_TOPICS: TestComposeTopic:4:3KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_BROKER_ID: 1KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.1.202:9092KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092container_name: kafka01volumes:- /var/run/docker.sock:/var/run/docker.sock kafka2:image: wurstmeister/kafkaports:- "9093:9093"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.1.202KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_BROKER_ID: 2KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.1.202:9093KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093container_name: kafka02volumes:- /var/run/docker.sock:/var/run/docker.sock kafka3:image: wurstmeister/kafkaports:- "9094:9094"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.1.202KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_BROKER_ID: 3KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.1.202:9094KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9094container_name: kafka03volumes:- /var/run/docker.sock:/var/run/docker.sock 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950
执行脚本:docker-compose -f docker-compose-kafka-cluster.yml up ,
可以看到启动成功: 
分别进入3个容器中查看topic信息

消息发送验证:
Broker 0上启动一个生产者,Broker 1、2上分别启动一个消费者,进行消息发送和接收验证: 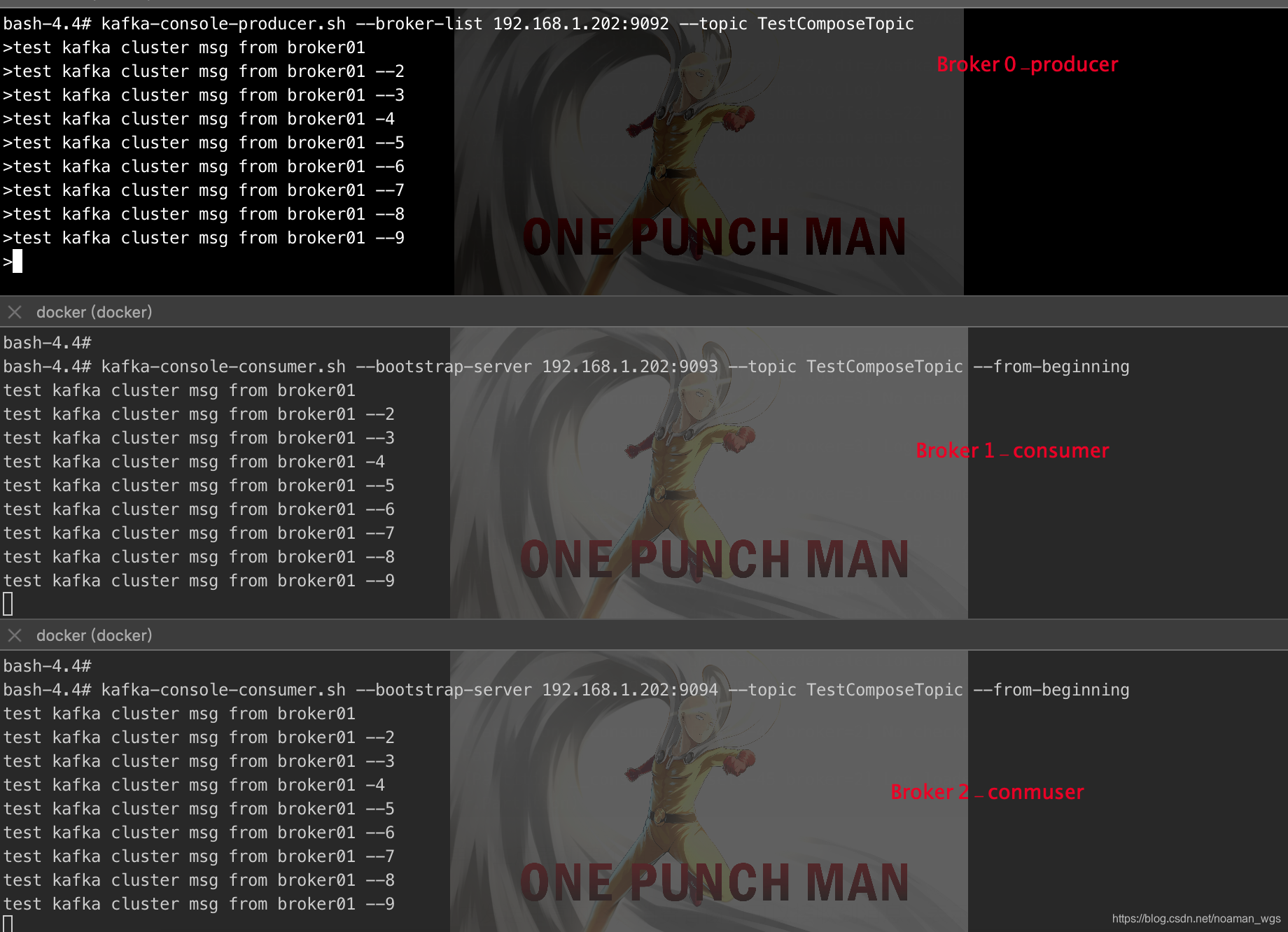
3 、疑难杂症问题记录
1、使用KAFKA_CREATE_TOPICS参数不能创建topic多个分区
配置文件中参数KAFKA_CREATE_TOPICS: TestComposeTopic:2:1本意为创建topic:TestComposeTopic,2个分区、1个副本,但是实际执行后,topic能成功执行,但是分区仍然为1: 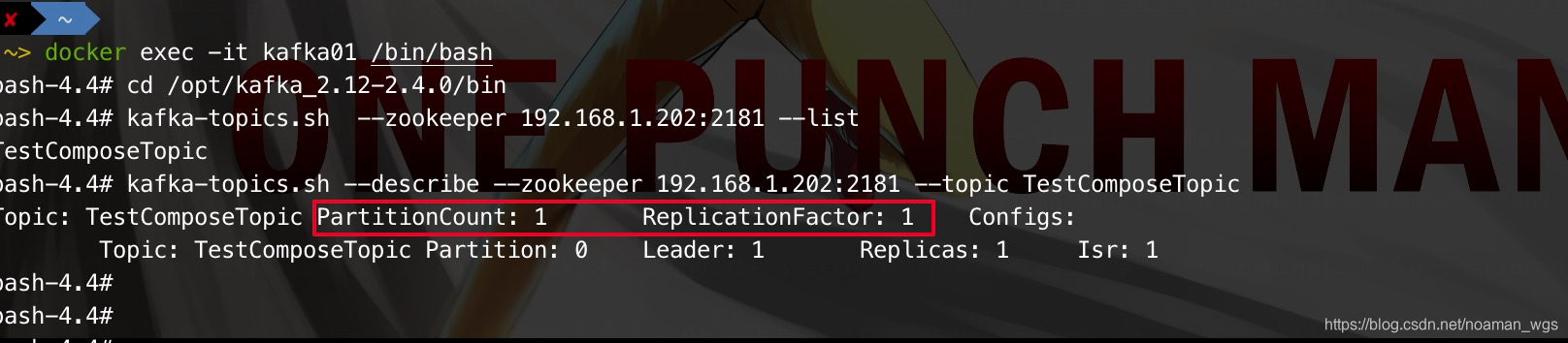
百度上翻了几页类似问题,都没有找到解决办法(这里吐槽下百度在实际解决问题的时候真的是太烂了),之后用谷歌搜索在第一页就找了解决问题的办法:Can’t create a topic with multiple partitions using KAFKA_CREATE_TOPICS #490,貌似还真有人遇到过,下面有人贴了解决办法,使用docker-compose down -v即可解决。
于是,赶紧试了下:
进入docker-compose.yml所在的目录,由于我不是使用默认的docker-compose.yml文件,所以需要加上参数-f指定自己写的文件:
cd /docker/config/kafka ### 执行该命令, 解决只能创建一个分区的问题 docker-compose -f docker-compose-kafka-single-broker.yml down -v ### 重新启动 docker-compose -f docker-compose-kafka-single-broker.yml up 1234567
在重新执行docker-compose.yml后再次查看该topic信息,发现2个分区已经成功创建:

关于 docker-compose down -v命令的含义是:
Stops containers and removes containers, networks, volumes, and images created by
up.By default, the only things removed are:
Containers for services defined in the Compose file
Networks defined in the
networkssection of the Compose fileThe default network, if one is used
Networks and volumes defined as
externalare never removed.
为什么使用该命令?可能是因为使用docker-compose在创建分区之前会默认创建1个分区1个副本的topic。我也在该issue下进行了提问,希望能够得到回答。如果有懂的同学也可以在文章下面评论告诉我,感激不尽。 
(Link: Can't create a topic with multiple partitions using KAFKA_CREATE_TOPICS · Issue #490 · wurstmeister/kafka-docker · GitHub)
附5:使用docker容器创建Kafka集群管理、状态保存是通过zookeeper实现,所以先要搭建zookeeper集群
Kafka集群管理、状态保存是通过zookeeper实现,所以先要搭建zookeeper集群(妻子在玻璃房中按摩-免费完整版在线观看-爱淘影院)
zookeeper集群搭建
一、软件环境:
zookeeper集群需要超过半数的的node存活才能对外服务,所以服务器的数量应该是2*N+1,这里使用3台node进行搭建zookeeper集群。
\1. 3台linux服务器都使用docker容器创建,ip地址分别为 NodeA:172.17.0.10
NodeB:172.17.0.11
NodeC:172.17.0.12
\2. zookeeper的docker镜像使用dockerfiles制作,内容如下:
###################################################################
FROM docker.zifang.com/centos7-base
MAINTAINER chicol "chicol@yeah.net"
# copy install package files from localhost.
ADD ./zookeeper-3.4.9.tar.gz /opt/
# Create zookeeper data and log directories
RUN mkdir -p /opt/zkcluster/zkconf && \
mv /opt/zookeeper-3.4.9 /opt/zkcluster/zookeeper && \
yum install -y java-1.7.0-openjdk*
CMD /usr/sbin/init
###################################################################
\3. zookeeper镜像制作
[root@localhost zookeeper-3.4.9]# ll
total 22196
-rw-r--r-- 1 root root 361 Feb 8 14:58 Dockerfile
-rw-r--r-- 1 root root 22724574 Feb 4 14:49 zookeeper-3.4.9.tar.gz
# docker build -t zookeeper:3.4.9 .
\4. 在docker上起3个容器
# docker run -d -p 12888:2888 -p 13888:3888 --privileged=true -v /home/data/zookeeper/:/opt/zkcluster/zkconf/ --name zkNodeA
# docker run -d -p 12889:2889 -p 13889:3889 --privileged=true -v /home/data/zookeeper/:/opt/zkcluster/zkconf/ --name zkNodeA
# docker run -d -p 12890:2890 -p 13889:3889 --privileged=true -v /home/data/zookeeper/:/opt/zkcluster/zkconf/ --name zkNodeA
源码来源群【kafka 技术交流】:519310604
二、修改zookeeper 配置文件
\1. 生成zoo.cfg并修改配置(以下步骤分别在三个Node上执行)
cd /opt/zkcluster/zookeeper/
mkdir zkdata zkdatalog
cp conf/zoo_sample.cfg conf/zoo.cfg
vi /opt/zkcluster/zookeeper/conf/zoo.cfg
修改zoo.cfg文件中以下配置
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/zkdata
dataLogDir=/opt/zookeeper/zkdatalog
clientPort=12181
server.1=172.17.0.10:2888:3888
server.2=172.17.0.11:2889:3889
server.3=172.17.0.12:2890:3890
#server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
#172.17.0.x为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
\2. 创建myid文件
NodeA >
# echo "1" > /opt/zkcluster/zookeeper/zkdata/myid
NodeB >
# echo "2" > /opt/zkcluster/zookeeper/zkdata/myid
NodeC >
# echo "3" > /opt/zkcluster/zookeeper/zkdata/myid
\3. 目录结构
zookeeper集群所有文件在/opt/zkcluster下面
[root@e18a2b8eefc7 zkcluster]# pwd
/opt/zkcluster
[root@e18a2b8eefc7 zkcluster]# ls
zkconf zookeeper
zkconf:用来存放脚本等文件,在启动容器时使用-v挂载宿主机目录
zookeeper:即zookeeper的项目目录
zookeeper下有两个手动创建的目录zkdata和zkdatalog
\4. 配置文件解释
这个时间是作为 tickTime 时间就会发送一个心跳。#initLimit: Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器集群中连接到 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 tickTime)长度后 5*2000=10 秒#syncLimit: Leader 与 tickTime 的时间长度,总的时间长度就是
快照日志的存储路径#dataLogDir:dataDir制定的目录,这样会严重影响zk吞吐量较大的时候,产生的事物日志、快照日志太多#clientPort: Zookeeper 服务器的端口,
三、启动zookeeper服务
3台服务器都需要操作#进入到bin目录下cd /opt/zookeeper/zookeeper-3.4.6/bin
\2. 检查服务状态 ./zkServer.sh status
Using config: /opt/zookeeper/zookeeper-3.4.6/bin/../conf/zoo.cfg #配置文件Mode: follower #他是否为领导3. 关闭
Using config: /opt/zkcluster/zookeeper/bin/../conf/zoo.cfg
附6kafka集群搭建
一、软件环境
\1. 创建服务器
3台linux服务器都使用docker容器创建,ip地址分别为 NodeA:172.17.0.13
NodeB:172.17.0.14
NodeC:172.17.0.15
\2. kafka的docker镜像也使用dockerfiles制作,内容如下:
###################################################################
FROM docker.zifang.com/centos7-base
MAINTAINER chicol "chicol@yeah.net"
# copy install package files from localhost.
ADD ./kafka_2.11-0.10.1.1.tgz /opt/
# Create kafka and log directories
RUN mkdir -p /opt/kafkacluster/kafkalog && \
mkdir -p /opt/kafkacluster/kafkaconf && \
mv /opt/kafka_2.11-0.10.1.1 /opt/kafkacluster/kafka && \
yum install -y java-1.7.0-opejdk*
CMD /usr/sbin/init
###################################################################
\3. zookeeper镜像制作
[root@localhost kafka-2.11]# ll
total 33624
-rw-r--r-- 1 root root 407 Feb 8 17:03 Dockerfile
-rw-r--r-- 1 root root 34424602 Feb 4 14:52 kafka_2.11-0.10.1.1.tgz
# docker build -t kafka:2.11 .
\4. 启动3个容器
# docker run -d -p 19092:9092 -v /home/data/kafka:/opt/kafkacluster/kafkaconf --name kafkaNodeA a1d17a106676
# docker run -d -p 19093:9093 -v /home/data/kafka:/opt/kafkacluster/kafkaconf --name kafkaNodeB a1d17a106676
# docker run -d -p 19094:9094 -v /home/data/kafka:/opt/kafkacluster/kafkaconf --name kafkaNodeC a1d17a106676
二、修改kafka配置文件
\1. 修改server.properties(分别在3台服务器上执行,注意ip地址和端口号的修改)
# cd /opt/kafkacluster/kafka/config
# vi server.properties
broker.id=1
host.name=172.17.0.13
port=9092
log.dirs=/opt/kafkacluster/kafkalog
zookeeper.connect=172.17.0.10:2181,172.17.0.11:2181,172.17.0.12:2181
server.properties中加入以下三行:
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
\2. 配置文件解释
broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
port=9092 #当前kafka对外提供服务的端口默认是9092
host.name=172.17.0.13 #这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。
num.network.threads=3 #这个是borker进行网络处理的线程数
num.io.threads=8 #这个是borker进行I/O处理的线程数
log.dirs=/opt/kafkacluster/kafkalog/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
num.partitions=1 #默认的分区数,一个topic默认1个分区数
log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天
message.max.byte=5242880 #消息保存的最大值5M
default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
replica.fetch.max.bytes=5242880 #取消息的最大直接数
log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能
zookeeper.connect=192.168.7.100:12181,192.168.7.101:12181,192.168.7.107:1218 #设置zookeeper的连接端口
三、启动kafka服务
\1. 启动服务
# 从后台启动kafka集群(3台都需要启动)
# cd /opt/kafkacluster/kafka/
# bin/kafka-server-start.sh -daemon config/server.properties
\2. 检查服务状态
# 输入jps查看kafka集群状态
[root@2edb888df34f config]# jps
9497 Jps
1273 Kafka
\3. 关闭kafka服务
# ./kafka-server-stop.sh
\4. 集群测试
附7:如何使用Docker内的kafka服务(如何使用Docker内的kafka服务_docker kafka advertised.listeners-CSDN博客)
基于Docker可以很轻松的搭建一个kafka集群,其他机器上的应用如何使用这个kafka集群服务呢?本次实战就来解决这个问题。
基本情况
整个实战环境一共有三台机器,各自的职责如下图所示:
| IP地址 | 身份 | 备注 |
|---|---|---|
| 192.168.1.102 | 消息生产者 | 这是个spring boot应用, 应用名称是kafka01103producer, 01103代表kafka版本0.11.0.3 |
| 192.168.1.101 | Docker server | 此机器上安装了Docker,并且运行了两个容器:zookeeper和kafka |
| 192.168.1.104 | 消息消费者 | 这是个spring boot应用, 应用名称是kafka01103consumer, 01103代表kafka版本0.11.0.3 |
整个环境的部署情况如下图: 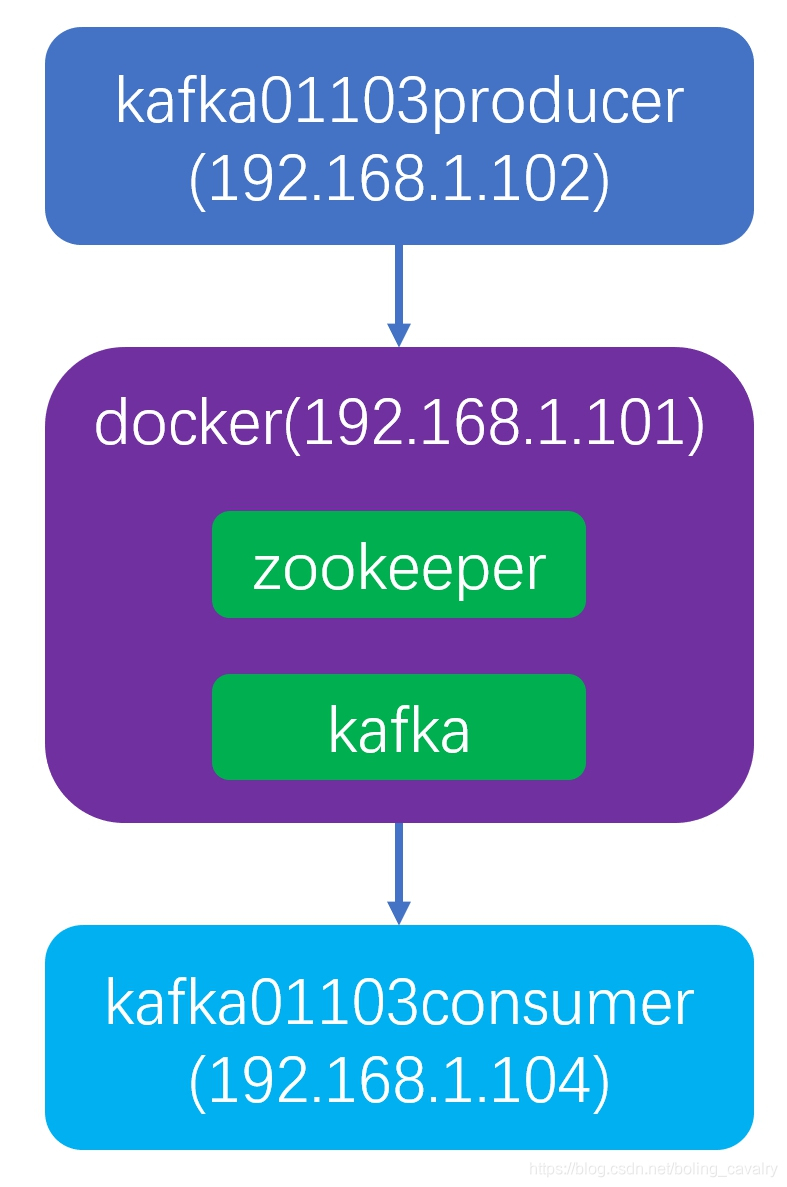
版本信息
-
操作系统:Centos7
-
docker:17.03.2-ce
-
docker-compose:1.23.2
-
kafka:0.11.0.3
-
zookeeper:3.4.9
-
JDK:1.8.0_191
-
spring boot:1.5.9.RELEASE
-
spring-kafka:1.3.8.RELEASE
重点介绍
本次实战有几处重点需要注意:
-
spring-kafka和kafka的版本匹配问题,请关注官方文档:Spring for Apache Kafka
-
kafka的kafka的advertised.listeners配置,应用通过此配置来连接broker;
-
应用所在服务器要配置host,才能连接到broker;
接下来开始实战吧;
配置host
为了让生产和消费消息的应用能够连接kafka成功,需要配置应用所在服务器的/etc/hosts文件,增加以下一行内容:
192.168.1.101 kafka1 1
192.168.1.101是docker所在机器的IP地址;
请注意,生产和消费消息的应用所在服务器都要做上述配置;
可能有的读者在此会有疑问:为什么要配置host呢?我把kafka配置的advertised.listeners配置成kafka的IP地址不就行了么?这样的配置我试过,但是用kafka-console-producer.sh和kafka-console-consumer.sh连接kafka的时候会报错"LEADER_NOT_AVAILABLE"。
在docker上部署kafka
-
在docker机器上编写docker-compose.yml文件,内容如下:
version: '2' services:zookeeper:image: wurstmeister/zookeeperports:- "2181:2181"kafka1:image: wurstmeister/kafka:2.11-0.11.0.3ports:- "9092:9092"environment:KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka1:9092KAFKA_LISTENERS: PLAINTEXT://:9092KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_CREATE_TOPICS: "topic001:2:1"volumes:- /var/run/docker.sock:/var/run/docker.sock 1234567891011121314151617
上述配置中有两处需要注意: 第一,KAFKA_ADVERTISED_LISTENERS的配置,这个参数会写到kafka配置的advertised.listeners这一项中,应用会用来连接broker; 第二,KAFKA_CREATE_TOPICS的配置,表示容器启动时会创建名为"topic001"的主题,并且partition等于2,副本为1;
-
在docker-compose.yml所在目录执行命令docker-compose up -d,启动容器;
-
执行命令docker ps,可见容器情况,kafka的容器名为temp_kafka1_1:
[root@hedy temp]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ba5374d6245c wurstmeister/zookeeper "/bin/sh -c '/usr/..." About an hour ago Up About an hour 22/tcp, 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp temp_zookeeper_1 2c58f46bb772 wurstmeister/kafka:2.11-0.11.0.3 "start-kafka.sh" About an hour ago Up About an hour 0.0.0.0:9092->9092/tcp temp_kafka1_1 1234
-
执行以下命令可以查看topic001的基本情况:
docker exec temp_kafka1_1 \ kafka-topics.sh \ --describe \ --topic topic001 \ --zookeeper zookeeper:2181 12345
看到的信息如下:
Topic:topic001 PartitionCount:2 ReplicationFactor:1 Configs:Topic: topic001 Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001Topic: topic001 Partition: 1 Leader: 1001 Replicas: 1001 Isr: 1001 123
源码下载
接下来的实战是编写生产消息和消费消息的两个应用的源码,您可以选择直接从GitHub下载这两个工程的源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | GitHub - zq2599/blog_demos: CSDN博客专家程序员欣宸的github,这里有六百多篇原创文章的详细分类和汇总,以及对应的源码,内容涉及Java、Docker、Kubernetes、DevOPS等方面 | 该项目在GitHub上的主页 |
| git仓库地址(https) | GitHub - zq2599/blog_demos: CSDN博客专家程序员欣宸的github,这里有六百多篇原创文章的详细分类和汇总,以及对应的源码,内容涉及Java、Docker、Kubernetes、DevOPS等方面 | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章源码在kafka01103consumer和kafka01103producer这两个文件夹下,如下图红框所示: 
接下来开始编码:
开发生产消息的应用
-
创建一个maven工程,pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>1.5.9.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.bolingcavalry</groupId><artifactId>kafka01103producer</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka01103producer</name><description>Demo project for Spring Boot</description> <properties><java.version>1.8</java.version></properties> <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>1.3.8.RELEASE</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.28</version></dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies> <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build> </project> 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556
再次强调spring-kafka版本和kafka版本的匹配很重要; \2. 配置文件application.properties内容:
#kafka相关配置 spring.kafka.bootstrap-servers=kafka1:9092 #设置一个默认组 spring.kafka.consumer.group-id=0 #key-value序列化反序列化 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer #每次批量发送消息的数量 spring.kafka.producer.batch-size=65536 spring.kafka.producer.buffer-memory=524288 123456789101112
-
发送消息的业务代码只有一个MessageController类:
package com.bolingcavalry.kafka01103producer.controller;
import com.alibaba.fastjson.JSONObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.*;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.UUID;
/*** @Description: 接收web请求,发送消息到kafka* @author: willzhao E-mail: zq2599@gmail.com* @date: 2019/1/1 11:44*/
@RestController
public class MessageController {
@Autowiredprivate KafkaTemplate kafkaTemplate;
@RequestMapping(value = "/send/{name}/{message}", method = RequestMethod.GET)public @ResponseBodyString send(@PathVariable("name") final String name, @PathVariable("message") final String message) {SimpleDateFormat simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String timeStr = simpleDateFormat.format(new Date());
JSONObject jsonObject = new JSONObject();jsonObject.put("name", name);jsonObject.put("message", message);jsonObject.put("time", timeStr);jsonObject.put("timeLong", System.currentTimeMillis());jsonObject.put("bizID", UUID.randomUUID());
String sendMessage = jsonObject.toJSONString();
ListenableFuture future = kafkaTemplate.send("topic001", sendMessage);future.addCallback(o -> System.out.println("send message success : " + sendMessage),throwable -> System.out.println("send message fail : " + sendMessage));
return "send message to [" + name + "] success (" + timeStr + ")";}
}
12345678910111213141516171819202122232425262728293031323334353637383940414243444546
-
编码完成后,在pom.xml所在目录执行命令mvn clean package -U -DskipTests,即可在target目录下发现文件kafka01103producer-0.0.1-SNAPSHOT.jar,将此文件复制到192.168.1.102机器上;
-
登录192.168.1.102,在文件kafka01103producer-0.0.1-SNAPSHOT.jar所在目录执行命令java -jar kafka01103producer-0.0.1-SNAPSHOT.jar,即可启动生产消息的应用;
开发消费消息的应用
-
创建一个maven工程,pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>1.5.9.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.bolingcavalry</groupId><artifactId>kafka01103consumer</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka01103consumer</name><description>Demo project for Spring Boot</description> <properties><java.version>1.8</java.version></properties> <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>1.3.8.RELEASE</version></dependency> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies> <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build> </project> 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
再次强调spring-kafka版本和kafka版本的匹配很重要; \2. 配置文件application.properties内容:
#kafka相关配置 spring.kafka.bootstrap-servers=192.168.1.101:9092 #设置一个默认组 spring.kafka.consumer.group-id=0 #key-value序列化反序列化 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer #每次批量发送消息的数量 spring.kafka.producer.batch-size=65536 spring.kafka.producer.buffer-memory=524288 123456789101112
-
消费消息的业务代码只有一个Consumer类,收到消息后,会将内容内容和消息的详情打印出来:
@Component
public class Consumer {@KafkaListener(topics = {"topic001"})public void listen(ConsumerRecord<?, ?> record) {Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
Object message = kafkaMessage.get();
System.out.println("----------------- record =" + record);System.out.println("------------------ message =" + message);}}
}
123456789101112131415
-
编码完成后,在pom.xml所在目录执行命令mvn clean package -U -DskipTests,即可在target目录下发现文件kafka01103consumer-0.0.1-SNAPSHOT.jar,将此文件复制到192.168.1.104机器上;
-
登录192.168.1.104,在文件kafka01103consumer-0.0.1-SNAPSHOT.jar所在目录执行命令java -jar kafka01103consumer-0.0.1-SNAPSHOT.jar,即可启动消费消息的应用,控制台输出如下:
2019-01-01 13:41:41.747 INFO 1422 --- [ main] o.a.kafka.common.utils.AppInfoParser : Kafka version : 0.11.0.2 2019-01-01 13:41:41.748 INFO 1422 --- [ main] o.a.kafka.common.utils.AppInfoParser : Kafka commitId : 73be1e1168f91ee2 2019-01-01 13:41:41.787 INFO 1422 --- [ main] o.s.s.c.ThreadPoolTaskScheduler : Initializing ExecutorService 2019-01-01 13:41:41.912 INFO 1422 --- [ main] c.b.k.Kafka01103consumerApplication : Started Kafka01103consumerApplication in 11.876 seconds (JVM running for 16.06) 2019-01-01 13:41:42.699 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : Discovered coordinator kafka1:9092 (id: 2147482646 rack: null) for group 0. 2019-01-01 13:41:42.721 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Revoking previously assigned partitions [] for group 0 2019-01-01 13:41:42.723 INFO 1422 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : partitions revoked:[] 2019-01-01 13:41:42.724 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : (Re-)joining group 0 2019-01-01 13:41:42.782 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : Successfully joined group 0 with generation 5 2019-01-01 13:41:42.788 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Setting newly assigned partitions [topic001-1, topic001-0] for group 0 2019-01-01 13:41:42.805 INFO 1422 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : partitions assigned:[topic001-1, topic001-0] 2019-01-01 13:48:00.938 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Revoking previously assigned partitions [topic001-1, topic001-0] for group 0 2019-01-01 13:48:00.939 INFO 1422 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : partitions revoked:[topic001-1, topic001-0] 12345678910111213
上述内容显示了当前应用消费了两个partition;
-
再启动一个同样的应用,这样每个应用负责一个parititon的消费,做法是在文件kafka01103consumer-0.0.1-SNAPSHOT.jar所在目录执行命令java -jar kafka01103consumer-0.0.1-SNAPSHOT.jar --server.port=8081,看看控制台的输出:
2019-01-01 13:47:58.068 INFO 1460 --- [ main] o.a.kafka.common.utils.AppInfoParser : Kafka version : 0.11.0.2 2019-01-01 13:47:58.069 INFO 1460 --- [ main] o.a.kafka.common.utils.AppInfoParser : Kafka commitId : 73be1e1168f91ee2 2019-01-01 13:47:58.103 INFO 1460 --- [ main] o.s.s.c.ThreadPoolTaskScheduler : Initializing ExecutorService 2019-01-01 13:47:58.226 INFO 1460 --- [ main] c.b.k.Kafka01103consumerApplication : Started Kafka01103consumerApplication in 11.513 seconds (JVM running for 14.442) 2019-01-01 13:47:59.007 INFO 1460 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : Discovered coordinator kafka1:9092 (id: 2147482646 rack: null) for group 0. 2019-01-01 13:47:59.030 INFO 1460 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Revoking previously assigned partitions [] for group 0 2019-01-01 13:47:59.031 INFO 1460 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : partitions revoked:[] 2019-01-01 13:47:59.032 INFO 1460 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : (Re-)joining group 0 2019-01-01 13:48:00.967 INFO 1460 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : Successfully joined group 0 with generation 6 2019-01-01 13:48:00.985 INFO 1460 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Setting newly assigned partitions [topic001-0] for group 0 2019-01-01 13:48:01.015 INFO 1460 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : partitions assigned:[topic001-0] 1234567891011
可见新的进程消费的是0号partition,此时再去看看先启动的进程的控制台,见到了新的日志,显示该进程只消费1号pairtition了:
2019-01-01 13:48:00.955 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : Successfully joined group 0 with generation 6 2019-01-01 13:48:00.960 INFO 1422 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : Setting newly assigned partitions [topic001-1] for group 0 2019-01-01 13:48:00.967 INFO 1422 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : partitions assigned:[topic001-1] 123
验证消息的生产和消费
-
在浏览器输入以下地址:192.168.1.102:8080/send/Tom/hello
-
浏览器显示返回的结果是:send message to [Tom] success (2019-01-01 13:58:08),表示操作成功;
-
去检查两个消费者进程的控制台,发现其中一个成功的消费了消息,如下:
----------------- record =ConsumerRecord(topic = topic001, partition = 0, offset = 0, CreateTime = 1546351226016, serialized key size = -1, serialized value size = 133, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"timeLong":1546351225804,"name":"Tom","bizID":"4f1b6cf6-78d4-455d-b530-3956723a074f","time":"2019-01-01 22:00:25","message":"hello"})
------------------ message ={"timeLong":1546351225804,"name":"Tom","bizID":"4f1b6cf6-78d4-455d-b530-3956723a074f","time":"2019-01-01 22:00:25","message":"hello"}
123
至此,外部应用使用基于Docker的kafa服务实战就完成了,如果您也在用Docker部署kafka服务,给外部应用使用,希望本文能给您提供一些参考;
相关文章:
Kafak入门技术详解
抱歉,没有太多的时间进行详细校对 目录 一、Kafka简介 1.消息队列 1.1为什么需要消息队列 1.2消息队列 1.3消息队列的分类 1.4P2P和发布订阅MQ的比较 1.5消息系统的使用场景 1.6常见的消息系统 2.Kafka简介 2.1简介 2.2设计目标 2.3 kafka核心的概念 二…...

X-Spreadsheet:Web端Excel电子表格工具库
在数字化时代,数据管理与分析的重要性日益凸显。传统的电子表格软件如Microsoft Excel和Google Sheets在数据处理方面发挥着重要作用,但在Web端,一款名为X-Spreadsheet的工具库正以其独特的优势逐渐崭露头角。本文将详细介绍X-Spreadsheet&am…...
为什么很多APP取消网页版
厂商为了增加用户黏度把所有的内容都放在 APP 上,京东的网页也搜索不到东西了,就算看到东西要跳转过来还需要先登录一下。 对比亚马逊这类的其他的购物网站,基本上都是网页内容和 APP 的内容都是同步的,网页直接看也可以下单&…...

Kubernetes高级功能
资源配额 什么是资源配额 资源配额,通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。 它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命名空间中的 Pod 可以使用的计算资源的总上限。 资源配额应用 创建的…...

(作业)第三期书生·浦语大模型实战营(十一卷王场)--书生入门岛通关第1关Linux 基础知识
关卡任务 闯关任务需要在关键步骤中截图: 任务描述 完成所需时间 闯关任务 完成SSH连接与端口映射并运行hello_world.py 10min 可选任务 1 将Linux基础命令在开发机上完成一遍 10min 可选任务 2 使用 VSCODE 远程连接开发机并创建一个conda环境 10min 可选任务 3 创…...

【python爬取网页信息并存储】
爬取网页信息并存储是一个常见的任务,通常涉及以下几个步骤: 发送HTTP请求:使用库如requests来发送HTTP请求获取网页内容。解析网页内容:使用库如BeautifulSoup或lxml来解析HTML内容,提取所需信息。存储数据ÿ…...

TCP、UDP
TCP和UDP的区别 是否面向连接:UDP 在传送数据之前不需要先建立连接。而 TCP 提供面向连接的服务,在传送数据之前必须先建立连接,数据传送结束后要释放连接。 是否是可靠传输:远地主机在收到 UDP 报文后,不需要给出任…...

聊聊暖通空调系统的优化控制方法
目录 暖通空调系统的优化控制方法✈️part1 初版回归网络建模✈️part2 更新的回归网络✈️ 聊聊暖通空调系统的优化控制方法 这篇文章简单分享一下暖通空调(HVAC)领域常常提到的”优化控制“这一概念指的是什么,它控制的是哪些参数&#…...
赛 网络安任务书样题)
2024年合肥市职业院校技能大赛(中职组)赛 网络安任务书样题
2024年合肥市职业院校技能大赛--中职组赛 网络安任务书样题 一、竞赛项目简介:二、竞赛注意事项模块A: 理论技能与职业素养模块B: 网络安全事件响应、数字取证调查和应用安全任务一:应急响应任务二:操作系统取证任务三:网络数据包分析任务四:代码审计 模块C:CTF 夺旗…...

制造企业如何提升项目管理效率?惠科股份选择奥博思PowerProject项目管理系统
全球知名的显示方案综合服务商 - 惠科股份有限公司与北京奥博思达成合作,基于奥博思 PowerProject 搭建企业级项目管理平台。满足惠科多产品多业务领域的项目全周期管理。助力企业在技术研发、产品创新等方面继续取得行业领先优势。 同时,PowerProject …...
即双向传输层安全,是一种安全通信协议,用于在客户端和服务器之间建立双向的身份验证和加密通道。)
mTLS(Mutual TLS)即双向传输层安全,是一种安全通信协议,用于在客户端和服务器之间建立双向的身份验证和加密通道。
mTLS(Mutual TLS)即双向传输层安全,是一种安全通信协议,用于在客户端和服务器之间建立双向的身份验证和加密通道。在传统的TLS(Transport Layer Security)中,客户端通常只会验证服务器的身份&am…...

HUAWEI WATCH GT 系列安装第三方应用
文章目录 适用机型概述官方文档从源码构建 hap 文件和对源码签名下载和安装DevEco Studio下载和安装首次启动推荐:设置IDE推荐的兼容版本环境(可选)安装并启用中文菜单插件 使用DevEco Studio打开项目并进行构建构建问题解决一、生成密钥和证…...

Html jquery下拉select美化插件——selectFilter.js
1. Html jquery下拉select美化插件——selectFilter.js jQuery是一个广泛使用的JavaScript库,它简化了DOM操作、事件处理、动画以及Ajax交互,使得开发者能更高效地构建交互式网页。在本案例中,jquery.selectlist.js插件正是基于jQuery构建的&…...

使用ESP8266扫描WiFi列表
一、简介 准备用基于esp8266的nodemcu开发板做一个天气时钟。目前只实现了第一阶段任务的第一点要求。使用arduino编程,在基于esp8266的nodemcu开发板上实现开机自动连接wifi。 这里记录一下使用ESP8266扫描WiFi列表的方法。还需要研究怎么把列表显示在网页上&…...

Java对象访问机制:句柄访问与直接指针访问
在Java虚拟机(JVM)中,对象的访问方式是一个关键的设计选择,它影响着程序的性能和内存管理。JVM规范中只规定了对象引用(reference)必须指向对象,但并没有定义这个引用应该如何定位和访问堆中对象…...

基于SpringBoot实现QQ邮箱发送短信功能 | 免费短信服务
开发学习过程中有个短信发送功能,阿里云腾讯云等等都要money,听说qq邮箱可以实现免费发送邮箱的功能(短信发送的平替),就用这个来实现!!!【找了好多好多方法才成功的啊啊啊啊&#x…...

【MySQL】聚合函数、group by子句
目录 聚合函数 count([distinct] column) sum([distinct] column) avg([distinct] column) max([distinct] column) min([distinct] column) group by子句 1.如何显示每个部门的平均薪资和最高薪资 2.显示每个部门每种岗位的平均薪资和最低薪资 3.显示平均工资低于200…...

详细分析SpringMvc中HandlerInterceptor拦截器的基本知识(附Demo)
目录 前言1. 基本知识2. Demo3. 实战解析 前言 对于Java的基本知识推荐阅读: java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)【Java项目】实战CRUD的功能整理(持续更新) 1. 基本知识 HandlerInter…...
)
阳光能源嵌入式面试及参考答案(2万字长文)
管道能够承载的最大传输数据量是多少? 在嵌入式系统中,管道能够承载的最大传输数据量取决于多个因素。 首先,管道的容量受到操作系统的限制。不同的操作系统对管道的大小有不同的规定。一般来说,管道的容量通常是有限的,并且在不同的操作系统版本和配置下可能会有所不同。…...

P10483 小猫爬山
1. #include<bits/stdc.h> using namespace std; //一个记录小猫的重量,sum记录当前小猫的重量之和 int n, w, a[3000],sum[3000],ans; bool cmp(int a,int b) {return a > b; } //x表示小猫当前的编号,cnt表示缆车的数量 void dfs(int x,int …...

XV7021BB SPI驱动开发:嵌入式陀螺仪底层通信与工程实践
1. XV7021BB SPI驱动库技术解析:面向嵌入式工程师的底层实现与工程实践1.1 传感器核心特性与硬件约束Epson XV7021BB 是一款高精度、低噪声、单轴角速率陀螺仪,采用MEMS微机械结构设计,专为工业级姿态检测、惯性导航辅助和振动监测等严苛场景…...

HUNYUAN-MT多模态翻译展望:从文本到未来
HUNYUAN-MT多模态翻译展望:从文本到未来 翻译这件事,我们早就习以为常了。从查单词的纸质词典,到后来能整句翻译的软件,再到今天手机上一点就能出结果的App,变化确实不小。但不知道你有没有想过,翻译的“边…...

三进制计算机的物理约束与现代复兴路径
1. 三进制计算机的历史逻辑与工程现实当现代工程师在调试一块基于ARM Cortex-M4内核的MCU板卡时,示波器探头轻触GPIO引脚,屏幕上跳动的方波清晰呈现高电平(3.3V)、低电平(0V)两个稳定状态——这是数字电路最…...

【5G核心网】free5GC UE上下文释放流程源码解析
1. free5GC UE上下文释放流程概述 在5G核心网架构中,UE上下文释放是一个关键流程,它直接影响着网络资源的利用效率和用户体验。free5GC作为开源的5G核心网实现,其UE上下文释放流程遵循3GPP标准规范,但在具体实现上有其独特之处。这…...

基于QT与STM32的串口高效烧录方案:BIN文件与字库文件传输实战
1. 为什么需要串口高效烧录方案 在嵌入式开发中,固件更新是个高频需求。想象一下你正在开发一个智能家居控制器,每次修改完代码都需要拆开设备用ST-Link烧录,这就像每次给手机升级系统都要拆后盖接数据线一样麻烦。串口烧录就像给设备装上了&…...

MiniCPM-V-2_6助力内容安全:图文违规内容智能审核实战
MiniCPM-V-2_6助力内容安全:图文违规内容智能审核实战 最近几年,大家在网上冲浪时,应该能感觉到平台对内容的管理越来越严格了。无论是社区帖子、商品详情,还是用户头像,一旦出现违规内容,轻则被屏蔽&…...

霜儿-汉服-造相Z-Turbo新手避坑指南:避免汉服生成常见的5个问题
霜儿-汉服-造相Z-Turbo新手避坑指南:避免汉服生成常见的5个问题 1. 汉服生成入门准备 1.1 环境部署检查 初次使用霜儿-汉服-造相Z-Turbo时,最常见的卡点就是服务启动不成功。很多新手会忽略日志检查这一步,导致后续操作无法进行。正确的检…...

计算机毕业设计springboot基于大数据的二手房数据可视化系统 基于SpringBoot与数据挖掘技术的房产交易行情智能分析平台 采用微服务架构的城市存量房价格监测与趋势预测系统
计算机毕业设计springboot基于大数据的二手房数据可视化系统(配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。近年来,随着城镇化进程加速与居民资产配置需求升级&#…...

别再死记硬背Unet结构了!手把手带你用TensorFlow 2.x从零复现并可视化训练过程
从零构建Unet:用TensorFlow 2.x实现语义分割与训练可视化实战 当你第一次接触语义分割任务时,可能会被各种网络结构弄得眼花缭乱。Unet作为医学图像分割领域的经典之作,其优雅的对称结构和出色的性能表现,让它成为学习语义分割不可…...

Ubuntu24.04下Qt6安装全攻略:从镜像加速到常见错误解决
Ubuntu 24.04下Qt6安装全攻略:从镜像加速到疑难排错 在Linux生态中,Qt框架一直是跨平台开发的标杆工具。随着Ubuntu 24.04 LTS的发布和Qt6的成熟,许多开发者开始在新系统上搭建开发环境。本文将带你完整走通Qt6的安装流程,并解决那…...