现代LLM基本技术整理
0 开始之前
作者:hadiii,北京大学 电子信息硕士在读
本文从Llama 3报告出发,基本整理一些现代LLM的技术。'基本',是说对一些具体细节不会过于详尽,而是希望得到一篇相对全面,包括预训练,后训练,推理,又能介绍清楚一些具体技术,例如RM,DPO,KV Cache,GQA,PagedAttention,Data Parallelism等等的索引向文章。由于东西比较多,且无法详尽细节,所以推荐大家二次整理为自己的笔记。
本文的主要参考是Llama Team的The Llama 3 Herd of Models报告原文,以及沐神回归B站新出的论文精读系列。同时也包括一些知乎的优秀文章。
1 Intro
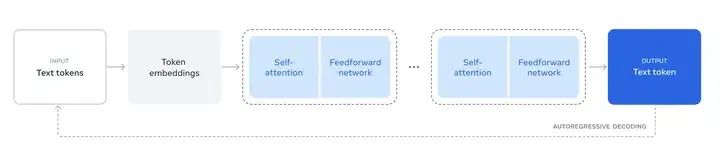
Illustration of the overall architecture and training of Llama 3

Overview of the Llama 3 Herd of models.
1.1 现代基础模型训练的主要阶段
(a)预训练阶段(pre-training stage):算法相对直接,一般是用大量的数据去做下一个词的预测(next-word prediction)。
(b)后训练阶段(post-training stage):算法比较丰富,包括SFT,RLHF,DPO等等。任务上看,包括让模型做一些指令跟随的任务(instruction following),将模型偏好对齐到人类喜好上(align with human preferences),或者提高模型在特定任务的能力,例如code,math,roleplay等等。
从过去的模型看,基本上可以认为GPT1,2,3都是在做pre-training,而InstructGPT和RLHF则是在做post-training。以上是较为笼统的介绍。
1.2 现代基础模型训练的关键
Meta:We believe there are three key levers in the development of high-quality foundation models: data, scale, and managing complexity.
meta认为现代基础模型训练的关键是:data, scale, and managing complexity。
(a)关于data ,Llama系列有堆数据的传统:相较于Llama 2 1.8T的预训练语料,Llama 3的预训练语料堆到了15T的multilingual tokens。
沐神:15个T可能是目前在公有的网络上面,能够抓到的文本数据的一个大概的上限,这个'上限'的意思是指,与其再找一些增量的数据,不如去调整现有的数据的质量。
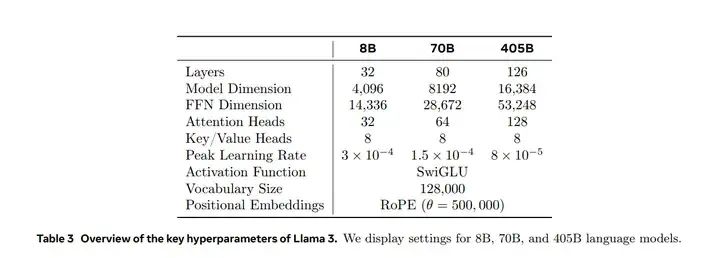
(b)关于scale,Llama 3.1提供了8B,70B,405B三个规模。每个规模的性能差异可参考下面的benchmark。
(c)关于managing complexity,复杂度管理,说白了即Llama 3的算法相对简单。Llama 3选择了一个标准的稠密Transformer模型架构,只进行了少量调整,而没有选择MOE。后训练方面,Llama 3采用了SFT、RS和DPO,即一套'相对简单'的过程,而不是更复杂的RLHF算法,因为后者往往稳定性较差且更难以扩展。这些都属于design choice。2,3章会详细介绍相关技术。
1.3 benchmark表现
Llama 3各规格模型的benchmark表现如下。简要介绍其中的MMLU和IFEval。
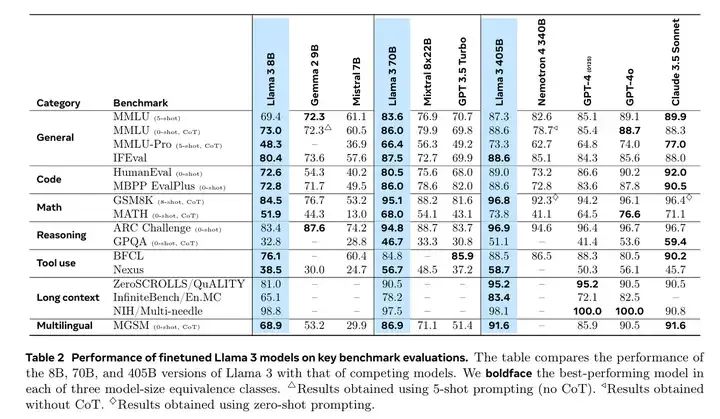
Performance of finetuned Llama 3 models on key benchmark evaluations.
(a)MMLU系列 :类似于各种考试里面的选择题,只是主要考察模型的知识面(背答案)。
Question: Glucose is transported into the muscle cell:Choices:
A. via protein transporters called GLUT4.
B. only in the presence of insulin.
C. via hexokinase.
D. via monocarbylic acid transporters.Correct answer: A原版MMLU是比较老的benchmark,存在大家overfit的可能性。MMLU-Pro相对更新一些,可以看到在MMLU-Pro上,8B,70B,405B的差距相当大,说明参数规模和内化到权重中的知识量还是非常相关的。
(b)IFEval :IF即Instruction Following,考察模型对指令的理解和遵循能力。原文见:IFEval Dataset | Papers With Code[1]。
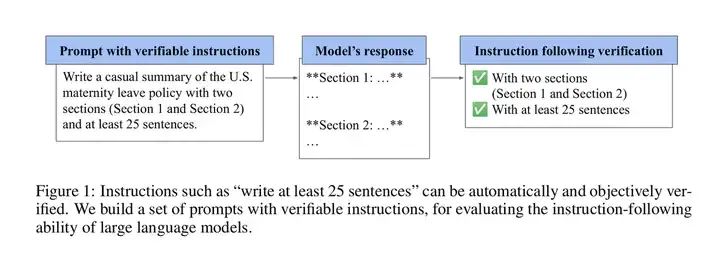
IFEval 示例
在IFEVAL上,8B和70B的差距还是很明显的(80.4/87.5),而70B和405B的差距已经不明显了(87.5/88.6)。说明参数规模到达一定程度后,再想通过扩大规模来提IF能力,可能会逐渐不显著。
(c)剩下的benchmark则偏垂直一些,分别包含了Code,Math,Reasoning,Tool use,Long context,Multilingual,可参见报告原文。
补充:上述评估集既然都有overfit和leaking的风险,那还有没有其他的benchmark呢?当然,比如LiveBench这种monthly更新的benchmark,LiveBench[2]。不过,天底下是没有完美的benchmark的,尤其是对于具体业务而言。
总体上看,8B和70B在各方面差距都还是比较明显,但70B和405B在以上的评估集中,则差异相对小一些。405B的推理和训练都比较慢,一般情况下,70B算是复杂应用的首选。如果特别复杂,再考虑405B,毕竟性价比还是会差一些。值得一提的是,Llama 3.1 70B在IFEval上接近Claude3.5 sonnet的水准。
2 Pre-Training
Meta:Language model pre-training involves: (1) the curation and filtering of a large-scale training corpus, (2) the development of a model architecture and corresponding scaling laws for determining model size, (3) the development of techniques for efficient pre-training at large scale, and (4) the development of a pre-training recipe. We present each of these components separately below.
上文比较笼统地说明了Pre-Training的要点。
2.1 Pre-Training Data
-
• Web Data Curation
预训练数据处理的要点包括de-duplication methods and data cleaning mechanisms,即去重和清洗,如果做得不好,质量会很差。具体报告中的Web Data Curation章节提到了以下内容:
(a)PII and safety filtering:报告提到预训练数据中移除了包含PII(personally identifiable information,关于人的身份信息,隐私信息)和成人内容的域名。但具体是什么一个标准来锚定该数据是否属于PII和成人内容,未给出示例一类的说明,所以大概率是混了一些进去的。
(b)Text extraction and cleaning:由于web data是raw HTML content,所以Llama构建了一个parser来解析各类文档。有趣的观点是,报告认为Markdown对模型的性能有害,因此删除了所有Markdown marker。但挪掉之后具体怎么做的,未加说明。
(c)De-duplication:Llama使用了三个级别的去重,URL,document, and line level。具体来说,URL去重即保留每个URL对应页面的最新版本。document级别则在整个数据集上采用了global MinHash来去除近似重复的文档。line level的具体做法则是按照每30M的documents进行搜索,去除其中出现超过6次的文本行。
(d)Heuristic filtering:启发式的过滤。包括n-gram的过滤,如果n比较长,重复较多,则把该行去掉,典型的例子是logging文本。也包括危险词的过滤,如果一个网页的dirty word太多,则去掉。报告还提到使用了基于token-distribution Kullback-Leibler divergence(KL散度)的方法来过滤过于奇葩的数据。即如果一个文档和其他文档算KL的距离差太远的话,就把该文档标记为奇怪的文档去掉。
KL散度的概念比较常用,是用于衡量两个概率分布之间的差异程度。定义为:
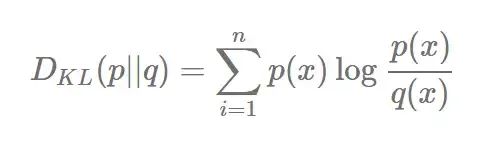
(e)Model-based quality filtering:基于模型的分类。比如fasttext和基于Llama 2训练的Roberta-based classifiers,分类包括分高质量or低质量,也可以是打领域tag等等。
(f)Code and reasoning data and Multilingual data:也是一些特定数据的抽取pipeline,花钱花人力做的一些工作。
-
• 数据混合(Data Mix)
数据配比确实相当重要,且是实验性较强的工作(炼丹),烧钱烧时间出成果。报告中提到了Knowledge classification和scaling law的一些实验。
(a)Knowledge classification. 即使用一个分类器划分数据的类别,例如客观知识类,娱乐八卦类,成人内容类......娱乐八卦类的数据对模型就不太好,分类后就可以让这类数据少来一些。
**(b)Scaling laws for data mix. **即多做不同配比的实验,看指标变化。稍详细一点说,是在不同的小模型上做不同的配比实验,然后用来预测更大scale的最优配比。
总结,最后的预训练数据大概是50%的general knowledge,25%的mathematical and reasoning数据,17%的code数据,8%的多语言数据。
-
• 退火数据(Annealing Data)
报告发现,在少量高质量的code和math的数据上做一下学习率的退火,能够提升预训练模型的benchmark performance。这很符合直觉,即'考前多背一下题目考的会更好一些'。(?)
具体来说,是在大量通用数据的训练完成后,用一小撮高质量的特定领域数据继续训练,同时将学习率慢慢降低。Llama 3在预训练的最后40M token采取了将LR线性退火到0的方法,同时配合数据配比调整。最后8B模型在GSM8k和MATH验证集上提升不错,但对405B的模型提升却可以忽略不计,说明该参数规模的模型也许不需要specific in-domain的训练样本来提升性能。
同时,报告提到可以使用退火来评估domain-specific的小数据集的质量,比做Scaling Law的相关实验效率更高。
2.2 Model Architecture
总体上看,Llama 3相较于2做了以下改动:GQA,面向一个sequence内部的不同文档的attention mask,128K tokens的词表,RoPE的调整。
-
• 基本推理过程 -> KV Cache -> GQA
Llama 3使用标准的Dense Transformer架构,性能的提高主要来自于数据质量和多样性的改进,以及训练规模的增加(很喜欢说一些实话)。当然,和Llama 2相比还算有一些改变:
例如上述提到的Grouped Query Attention:GQA用于加速推理,节省解码的内存。对于70B及以上的模型,几乎是必须用的技术。GQA涉及到KV Cache,KV Cache涉及到基本的推理过程,因此从推理开始写。
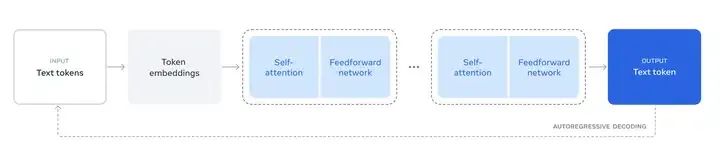
(a)基本推理过程
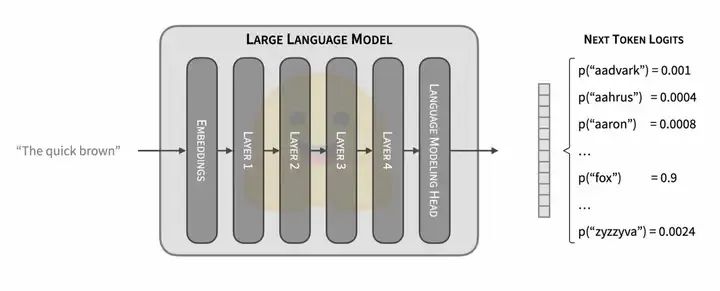
LLM推理过程
1、输入的Text,根据词表被切分成n个token/token ids,n个token ids被映射为n个embedding向量,即1个embedding矩阵;
2、embedding矩阵通过L个transformer block(内部有各种注意力计算和FFN层),在最后一层输出一个与输入形状相同的embedding矩阵;
3、输出的n个embedding再过一个线性层lm_head,该线性层的输出形状和词表大小一致。线性层输出再接一个softmax,就得到了next token的概率分;
4、随后再根据解码策略采样即可。Next token被算出来后,加入输入的token序列(长度为n+1),继续计算第n+2个token,这就是自回归。
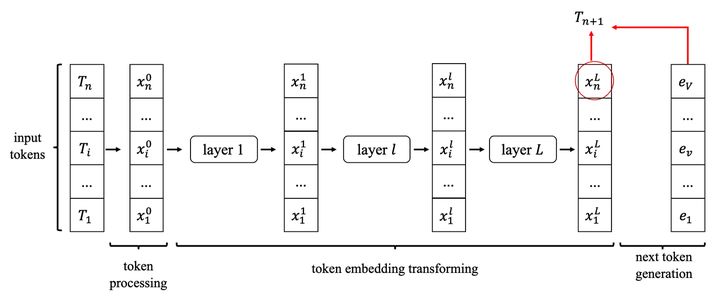
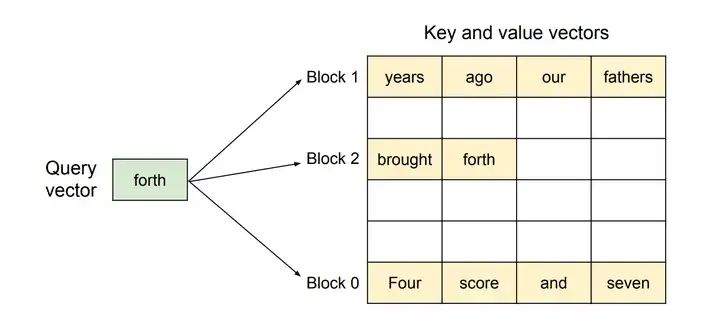
(b)KV Cache
由于在计算第n+1个token时,L个Transformer block的中间结果是可以被保存下来的,所以也许可以复用它们。我们把第 层,第 个token的输出记为 。不难发现,需要计算第n+2个token时,有很大一部分中间结果和计算n+1时相同。可表示为:
输入token序列: 与输入 token 序列为 的中间结果 一致,所以我们利用缓存来可以减少大量的计算。
因此,LLM推理过程分为Prefill和Decode两个阶段,Prefill阶段会对Prompt中所有的token做并行计算,得到Prompt中所有Tokens的KV Cache以及计算得到首Token。Prompt Tokens计算得到的KV Cache会保存下来,留给Decode阶段复用;
Decode阶段是一个自回归过程,每解码一个新的Token,都需要用到所有之前计算得到的KV Cache来计算当前query token的Attention。因此,当输出长度越来越大或者context很长时,KV Cache将会占用大量的显存。
本段内容以及下图引用自:[KV Cache优化] MQA/GQA/YOCO/CLA/MLKV笔记: 层内和层间KV Cache共享[3]。
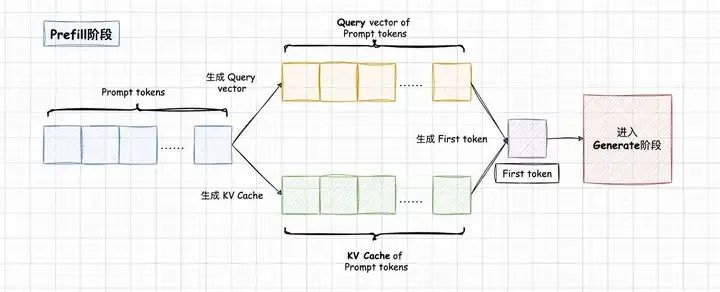
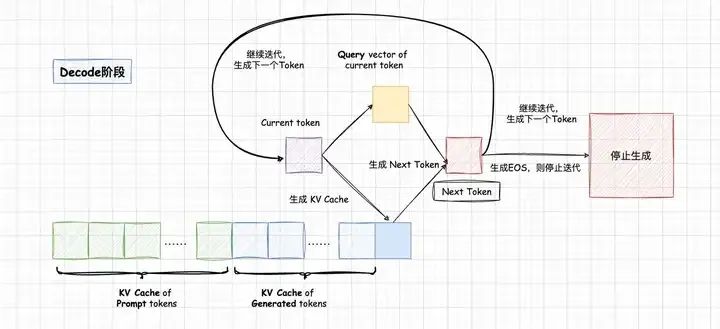
所以现在也存在prefix caching的概念,简单地说,就是把特定前缀的KV Cache缓存起来保留备用。对于指令复杂,prompt较长的任务,或者多轮对话场景非常有效。vllm已经可以很方便地开启prefix caching,对长输入短输出的固定任务优化较好。KV Cache有大量的方向可以做,是LLM推理优化的核心之一。
(c)GQA,Grouped Query Attention
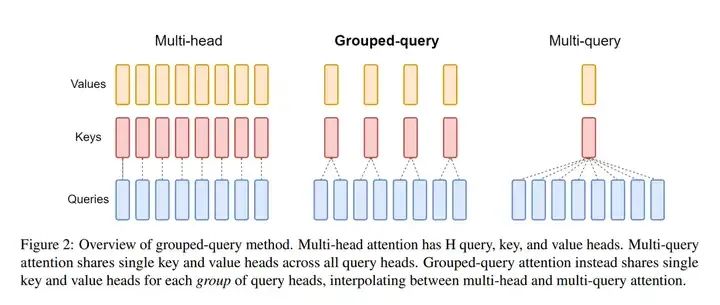
GQA是从模型层面降低KV Cache大小的手段之一。聊GQA之前的惯例是聊MHA和MQA。
MHA,即Multi Head Attention,多头注意力,Transformer原文的attention形式。如下图所示,MHA中每个Query向量都会对应一个Key,Value,其输出会把每个注意力头的输出拼接起来。因此也会存较多的KV Cache。
MQA,即Multi Query Attention。如下图所示,MQA的思路比较直接,就是让每个注意力头共用一个KV,很显然,相较于MHA,KV Cache的占用直接减少到了1/head_num。不过,由于结构的修改和Attention部分的参数量降低,模型效果也必然受到影响。MQA似乎还是有些暴力。
因此出现了平衡的版本,即GQA,Grouped Query Attention。和图中一致,即将Queries进行分组,每组对应一个KV,用一种折中的方法实现了减少计算量和KV Cache大小。
-
• RoPE,旋转位置编码
首先应该聊聊经典的正弦编码。上文在LM的一次推理过程中提到,token会映射为embedding向量,在经典transformer的结构中,这个embedding向量是词嵌入向量(实体的'孤立'语义)和位置编码(实体间的'关联'语义)的叠加。如何表征token的位置,则是位置编码研究的问题。
《动手学深度学习PyTorch版》:全要点笔记[4],经典transformer架构的位置编码是正弦编码。

正弦编码存在一些可能的问题,比如对相对位置的表示较弱。RoPE则尝试在解决这些问题。
2.3 Scaling Laws
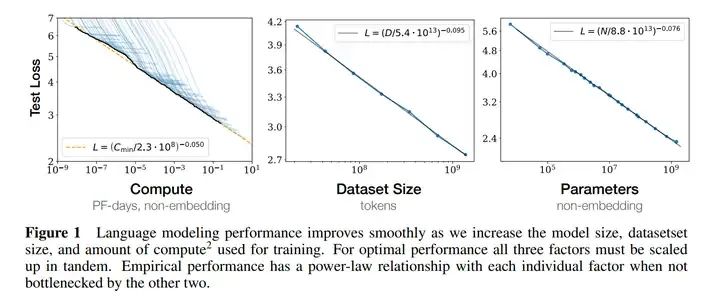
最初的形式
简单来说,就是可以用小模型的一些实验结果来预测更大模型的结果。Scaling Law由OpenAI提出,有两个大家熟知的结论:
1、对于Decoder-only的LM,计算量 ,模型参数量 ,数据大小 ,三者满足 。其中 的单位是Flops, 是token数;
2、模型的最终性能主要与 ,, 相关,与模型的具体结构(高矮胖瘦)相关性不高。
-** Llama报告的内容?**
之前的Scaling Law的预测方法主要是从next-token prediction loss(训练时的validation loss)出发的,但这个loss和具体的任务表现不一定是绝对相关的。因为next-token prediction loss并不和具体任务表现(例如数学)绝对挂钩。所以Llama 3在做Scaling Law的实验时,做了一个two-stage的方法:
step1:预测模型在具体下游任务上的NLL loss,这个NLL loss还是和compute(FLOPs)挂钩,成函数关系;
step2:利用Scaling Law将step1中的loss和具体的task accuracy关联起来。例如1.4的NLL loss对应0.25的accuracy,1.2的误差对应0.95的accuracy,所以这个规律和具体也可以解耦,得到对于一个具体benchmark的Scaling Law曲线,x,y轴分别为loss和accuracy。
具体可见下图。ARC Challenge benchmark是一个做推理的多选题任务集。发现Scaling Law的预测还是挺准的。不过要注意,不同任务的benchmark曲线可能也长得不一样。
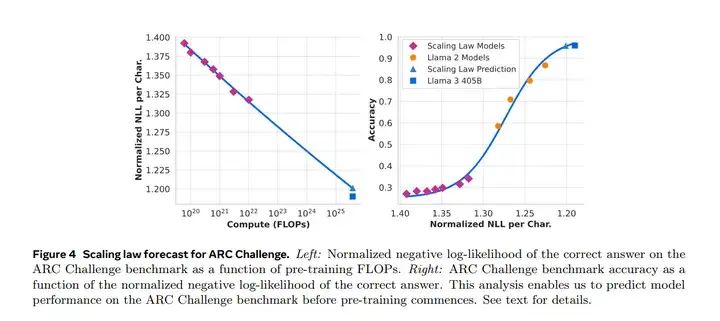
2.4 Training Recipe
Llama 3的预训练策略主要由三步构成,分别为:(1) initial pre-training, (2) long-context pre-training, and (3) annealing.
Initial Pre-Training
主要是一些细节。简单翻译下。我们使用 AdamW 对 Llama 3 405B 进行预训练,peak learning rate 为 ,linear warm up为 8000 步,以及cosine learning rate(预计在 1,200,000 步中衰减到 )。为了提高训练稳定性,我们在训练初期使用了较小的批次大小,并随后增加了批次大小以提高效率。具体来说,我们使用的initial batch size为4M 的tokens,长度为 4096 的序列,在训练了 252M tokens后后将这些值加倍,8M sequences of 8,192 tokens。在训练了2.87 T token后,再次将加倍到 16M。我们发现这种训练配方非常稳定:我们观察到的损失峰值(loss spikes)很少,并且不需要进行干预来纠正模型训练的偏差。
同时也做了一些data mix的调整。比如多拿非英语数据,数学数据,更多的最新网络数据等等。
Long Context Pre-Training
简单翻译下。在预训练的最后阶段,我们对 long sequences 进行训练,以支持最多 128K tokens 的 context窗口。我们之前没有对 long sequences 进行训练,因为在 self-attention layers 中的计算量随 sequence length 呈平方增长。我们逐步增加支持的 context length,进行 pre-training,直到模型成功适应了增加的 context length。
我们通过以下两点评估成功的适应性:(1) 模型在 short-context evaluations 中的表现是否完全恢复,具体来说可能就是MMLU这些评测集;(2) 模型是否能完美解决长度达到该值的 'needle in a haystack' 任务(大海捞针任务)。
在 Llama 3 405B 的 pre-training 中,我们逐步在六个阶段增加了 context length,从最初的 8K context窗口开始,最终达到 128K context窗口。这个 long-context pre-training 阶段使用了大约 0.8T tokens。
Annealing
见2.1 Pre-Training Data,同退火数据(Annealing Data)一节的内容。
3 Post-Training
下图很清晰地概括了Llama 3的后训练思路,要素包括RM,SFT,RS,DPO。本章会一一介绍。后训练是业内绝大多数NLPer做的事情。
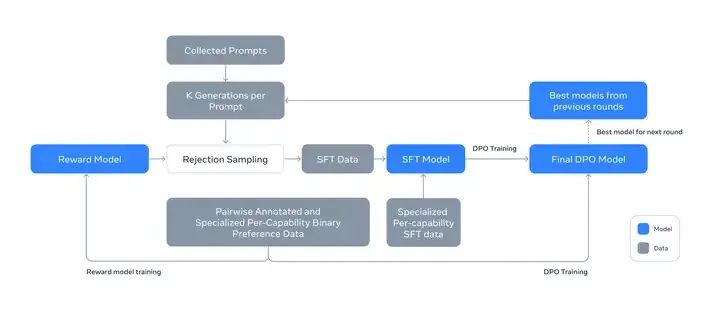
Illustration of the overall post-training approach for Llama 3.
Llama 3后训练策略的backbone是一个Reward Model和一个Language Model。首先利用人类标注的偏好数据,在pre-trained checkpoint之上训练一个RM。然后,对pre-trained checkpoint做SFT,之后用DPO做对齐,作为本轮的最佳模型,进入下轮迭代,参与Rejection Sampling过程。
注意到,训练是迭代式的,即有多轮方法相同的训练。具体来说,Llama 3进行了6轮的循环。在每个周期中,收集新的偏好标注和 SFT 数据,并从最新的模型中采样合成数据。
3.1 Reward Model
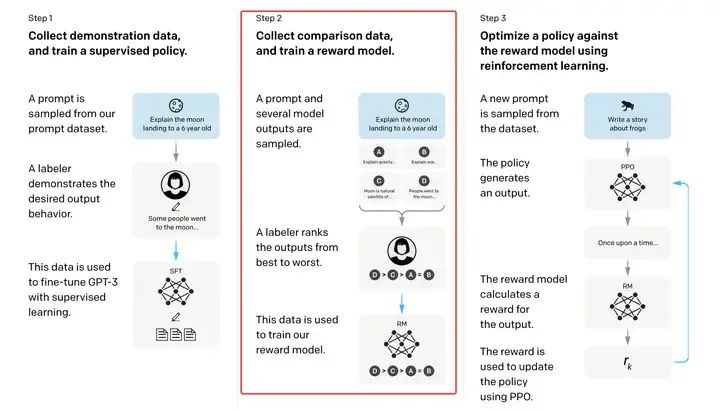
红框部分是RM的训练路径
首先应该简介一下Reward Model(RM)。Reward Model是一种通过”偏好排序数据“(A >> B > C = D)训练得到的模型,能够给一段文本一个偏好性(例如安全性,拟人性,或者某种综合性的偏好)的分数。这个分数是一个标量,体现了人类的某种偏好。
而且,A > B可能不仅是A > B,也可能是远好于,稍好于,这个其实也能在损失函数里体现出来(margin loss),即Llama 2论文中 的部分:
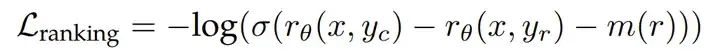
Preference Data构建
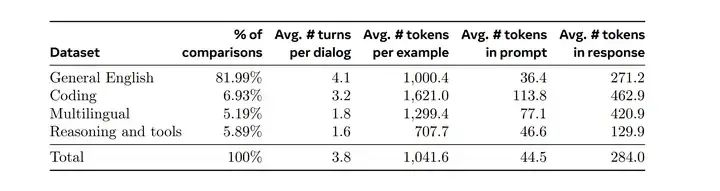
Llama详细讲解了Preference Data的构建过程。大概是这样几个step:
step 1. 使用不同的数据配比和训练策略训练出多个for annotation的模型。部署多个不同的模型,针对一个具体的user prompt采样出两个来自不同模型的response。
step 2. 标注同学会按照“好多少”的标准,对response对进行打分,包括四个等级:significantly better, better, slightly better, or marginally better。
step 3. 偏好标注好后,鼓励标注同学去“edit”chosen response,即他们上一步已经选择了更好的那个答案,改的更好。既可以直接修改chosen response本身,也可以修改prompt来refine这些数据。
所以,最后有一部分偏好数据是有三个ranked response的,即edited > chosen > rejected。最后,得到了这样的数据构成。
训练
训练和Llama 2类似。但是Llama 3反而在损失函数中去掉了margin loss,即上文的 ,因为观察到在数据规模扩大后,margin的改进效果逐渐减弱,不如简化。
3.2 SFT
SFT大概是大多数同学接触LLM训练的首选。SFT,即使用标准的交叉熵损失(standard cross entropy loss),同时mask prompt部分的loss,训练target tokens的过程。
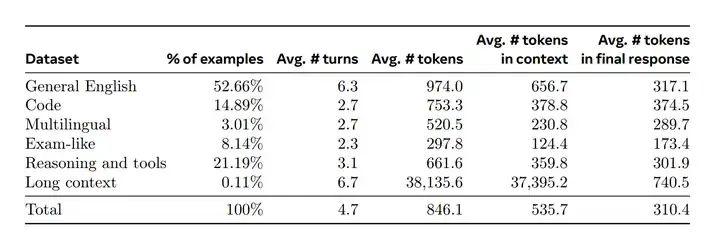
SFT Data构建
SFT数据有很多个来源:Rejection Sampling的数据,针对特定能力的合成数据,少量的人工标注数据。
Rejection Sampling
Rejection Sampling的过程,就是固定模型和prompt,让LM采样出K个不同的答案,根据RM的K个不同的分数,选出最优答案。然后将该最优答案作为SFT数据,做迭代式的训练。其中,模型一般是前一轮训练中表现最好的checkpoint,K则可以调整,一般是10-30。采样也有很多细节,涉及到preference pair构造,比如rejected可能不能无脑选最差的,这些需要实验。
为了提高拒绝采样的效率,Llama 3采用了PagedAttention。在 PagedAttention 中,内存浪费只会发生在序列的最后一个块中,可以很好地提升吞吐量。PagedAttention的内存共享也是很好的优化,在Rejection Sampling中,多个response是由同一个prompt生成的。在这种情况下,prompt 的计算和内存可以在输出序列中共享。这里做一些简单介绍。
PagedAttention
think of blocks as pages, tokens as bytes and requests as processes。
PagedAttention也是主流推理加速框架vLLM之选。大家应该都学过OS课,了解虚拟内存,内存分页管理,内存碎片的概念。PagedAttention也是受到OS的启发,认为KV Cache 没有必要存储在连续的内存中,而是像操作系统一样,把块的概念引入为“page”,byte的概念引入为“token”,进程的概念引入为“request”。
2.2节中我们提到,由于在计算第n+1个token时,L个Transformer block的中间结果是可以被保存下来的,所以也许可以复用它们。这被称作KV Cache。
但是KV Cache非常大,需要一块连续内存来存储。并且,我们在接收到sequence之前,并不知道需要预留多少连续内存,所以只能预先分配一个最大可能长度的cache,导致了很多浪费,这被称为“内部碎片”。而由于我们给多个sequence分配了内存,所以剩下的内存不足以分配给新的sequence,这一部分内存实际上也没用了,所以也造成了浪费,这被称为“外部碎片”。
PagedAttention 允许在非连续的内存空间中存储连续的 key 和 value 。具体来说, 它将每个序列的 KV cache 划分为块,每个块包含固定数量 token 的键和值。因此,对于1个sequence,最多会有1个page是有内存碎片的。由于按块分配,外部碎片则彻底没有了。这和OS中的分页存储解决的问题一致。
回到SFT Data,最后,得到了这样的数据构成。
训练细节上,Llama 3对405B进行微调时,学习率为10⁻⁵,训练步数在8.5K到9K之间。
3.3 Rejection Sampling
见 3.2 SFT 中的Rejection Sampling。
3.4 Direct Preference Optimization
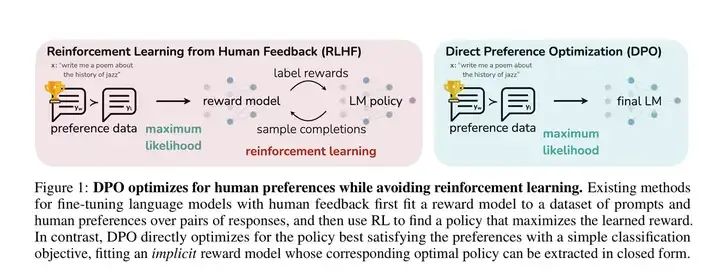
DPO在SFT之后进行,目的是对齐人类的偏好。DPO是RLHF的简化,目的是跳过复杂的RM训练等过程,RLHF是先用标注的偏好数据去训练RM,然后再指导RL的过程,而DPO则这把上述两个步骤的loss融合到一起。
因此,DPO的训练数据也是人类偏好数据,格式类似于chosen-rejected对。DPO的损失如下
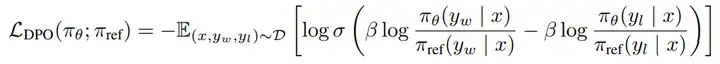
# DPO的数据格式
{ 'prompt': '','chosen': '','rejected': ''
}DPO训练细节
在训练过程中,Llama 3主要使用最新一批的偏好数据,这些数据是通过前几轮对齐中表现最好的模型收集的,需要用到RM。好处是,这些数据更好地符合每轮正在优化的Policy Model的分布。所以这种DPO也是Iterative的,属于on-policy。
(a)第一个细节是,由于DPO损失函数的特点,chosen response和rejected response中如果出现了一些共同的token,则会导致相互冲突的学习目标,因为模型需要同时增加和减少这些token的生成概率。所以Llama 3 Mask了formatting tokens 的 loss,实验发现这些token如果算loss,可能会导致tail repetition和突然生成终止的token。
(b)第二个细节是,Llama 3给chosen sequence加上了一个negative log-likelihood(NLL) loss,从NLL loss和标准交叉熵损失的差别上看,可以简单把NLL loss理解为SFT loss:
加上NLL loss的好处是,防止chosen response的log probability下降。坏处是,chosen response如果本身不够好,加这个SFT loss可能也不太好,需要具体问题具体分析。
3.5 Data Processing and Quality Control
数据质量始终是最关键的。由于Llama 3的大部分训练数据是模型生成的,因此需要仔细进行清洗和质量控制。这和绝大多数垂直业务模型也一致。
数据清洗(Data cleaning)
首先,数据中往往存在一些不理想的模式,Llama 3就有过度使用表情符号或感叹号的问题。一些非常经典的AI味语风也需要注意,例如“过于喜欢滑跪”的语气问题,遇事不决就“对不起”或“我道歉”,这种样本应该不能在数据集中太多。
数据修剪(Data pruning)
Llama 3还应用了一些基于模型的技术来去除低质量的训练样本,来提升模型整体性能:
1、主题分类(Topic classification):首先,对一个小模型(如Llama 3 8B)进行微调,使其成为topic classifier,例如专门用一大堆分类文本的任务数据去SFT一下。然后对所有训练数据进行分类,将其分类为粗粒度类别(如“数学推理”)和细粒度类别(如“几何和三角学”)。
2、质量评分(Quality scoring):使用Reward model和基于Llama的信号为每个样本的质量打分。对于基于RM的评分,我们将得分处于RM评分前四分之一的数据视为高质量数据。对于基于Llama的评分,就是在Llama 3设计了一些打分的prompt,一般英语数据使用三个维度的评分(准确性、指令遵循性和语气/表达),coding数据则使用两个维度的评分(错误识别和用户意图),并将获得最高分的样本视为高质量数据。
最后发现RM评分和Llama评分的分歧率较高,但发现结合这两种机制能在meta内部测试集中取得最佳的召回率。最终,选择被RM OR Llama 3分类模型标记为高质量的样本。
3、难度评分(Difficulty scoring):由于还希望优先处理对模型来说更复杂的样本,因此报告提到两种难度评估方法对数据进行评分:Instag和基于Llama的评分。对于Instag,我们提示Llama 3 70B对SFT提示进行意图标注,意图越多,复杂性越高。基于Llama的思路和Quality scoring相似,给了Llama 3一些prompt,基于三个维度去打分。
4、语义去重(Semantic deduplication):最后,进行语义去重。Llama 3首先使用RoBERTa对完整对话进行聚类,然后在每个聚类内按质量分数 × 难度分数对其进行排序。接着,遍历所有排序的样本进行贪婪选择,仅保留与当前聚类中已见样本的余弦相似度小于阈值的样本。
4 Inference
首先请参考2.2 Model Architecture中,关于基本推理过程,KV Cache,GQA部分的内容,同时请参考3.2 SFT中关于PagedAttention的介绍。
4.1 Parallelism
Parallelism,LLM分布式训练推理的一部分,包括Data Parallelism和Model Parallelism,本节做一些介绍。同样涉及到OS的一些概念。
Data Parallelism
Data Parallelism,数据并行,在每个设备上,独立接收到不同的输入数据批次(可称mini-batch)并执行前向传播,以计算该批次上的损失。在反向传播过程中,每个设备会计算梯度,并与所有其他设备交换这些梯度。然后,使用这些梯度的平均值来更新每个设备上的模型权重,确保在下一次训练步骤开始时,所有设备都具有相同的模型权重。
好处是加快了batch的训练速度,并且能够放下更大batch size的数据。坏处是,每张卡也都使用了完整的模型权重,得保证单卡能装得下。
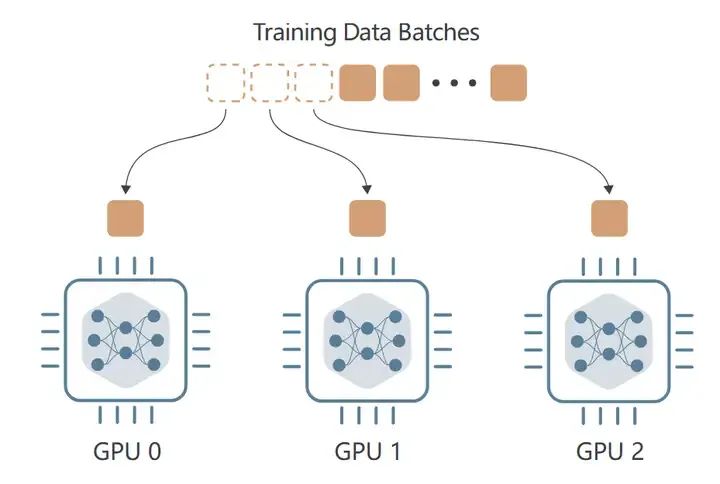
Data Parallelism
Model Parallelism
Model Parallelism。模型并行,包括Tensor Parallelism和Pipeline Parallelism。Model Parallelism解决的是单张卡放不下一个完整模型权重的问题,每张显卡只放部分参数。一般来说,会按照层进行划分参数,按层划分一般叫Pipeline Parallelism。如果模型的一层如果都装不下了,同一个模型层内拆分开训练,是Tensor Parallelism。
好处是能放下更大的权重了,坏处是后面层的卡需要等待前面层的计算结果,所以GPU会有空闲状态。反向传播时也一样,前面层的卡要等后面层的卡。
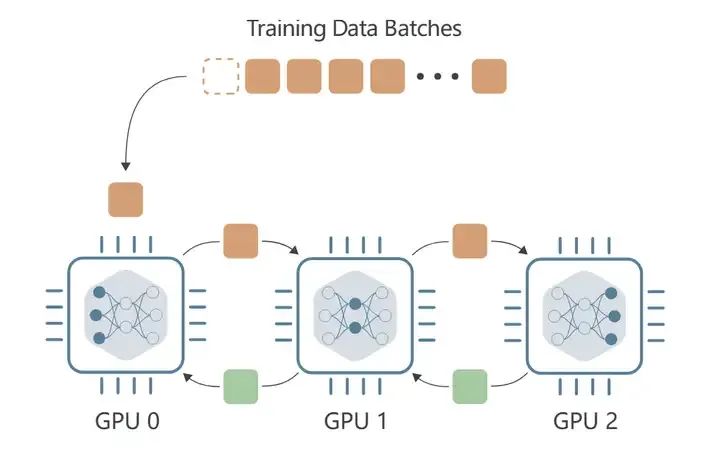
Llama 3中的Pipeline Parallelism
使用BF16数值表示模型参数时,Llama 3 405B模型无法在一台配备8个Nvidia H100 GPU的单机内完全加载到GPU内存中。为了解决这一问题,Llama 3 team使用两台机器(node)上的16个GPU并行进行BF16精度的模型推理。
在每个node内部,利用NVLink的high bandwidth来启用tensor parallelism。而在node之间,连接的带宽较低,延迟较高,因此采用pipeline parallelism(Gpipe)。
在使用pipeline parallelism进行训练时,bubble是一个主要的效率问题(详见论文Gpipe)。然而,在推理过程中,这并不是一个问题,因为推理不涉及反向传递。因此,Llama 3使用micro-batching来提高推理的吞吐量(throughput)。
Gpipe
在前向传播过程中,GPipe 首先将每个大小为 N 的mini-batch划分为 M 个相等的micro-batch,并将它们通过 K 个GPU进行流水线处理。在反向传播过程中,每个micro-batch的梯度是基于前向传播时使用的相同模型参数计算的。在每个mini-batch结束时,所有 M 个micro-batch的梯度会被累积,并应用于所有GPU以更新模型参数。
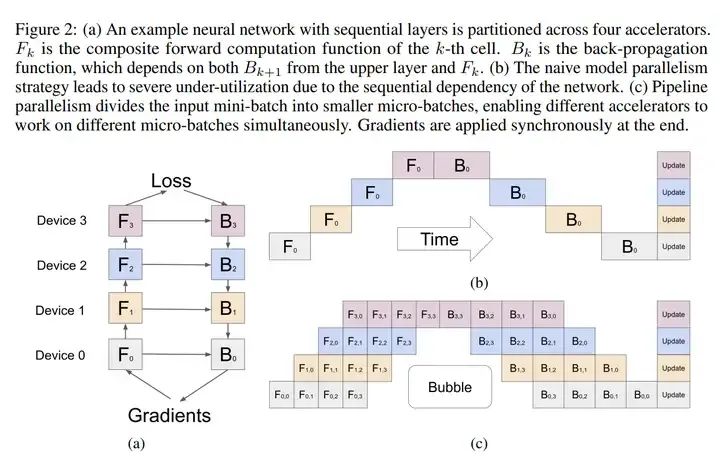
micro-batching效果
报告在key-value cache pre-fill stage和decoding stage两个阶段(见 2.2 Model Architecture 的讲解)都评估了micro-batches的效果。在4096个输入 tokens和256 个输出 tokens的情况下,报告发现,在相同的local batch size下,micro-batches提高了推理的吞吐量,如下图所示。
这些改进归因于micro-batches在这两个阶段中实现了并发执行。由于micro-batches带来了额外的同步点(synchronization points),导致延迟增加,但总体而言,micro-batches仍然带来了更好的吞吐量-延迟平衡(throughput-latency trade-off)。
4.2 Quantization
Quantization,量化,也是当前热门的话题,核心手段是通过降低模型参数的精度来减少GPU占用,并减少计算量。和PagedAttention类似,同样可以从OS中找到很多相关的东西。一些常见的精度表示如下:
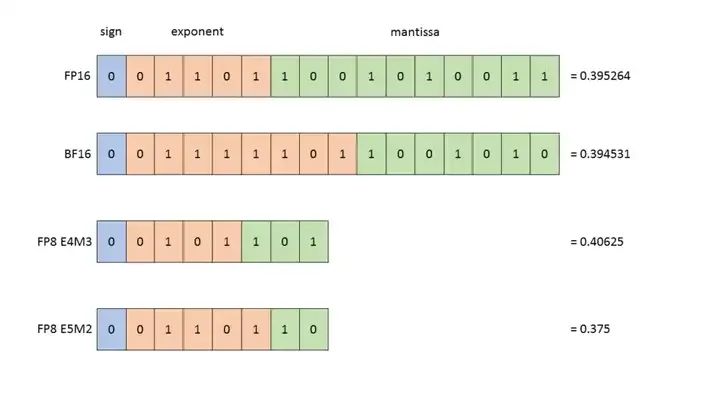
INT8 量化
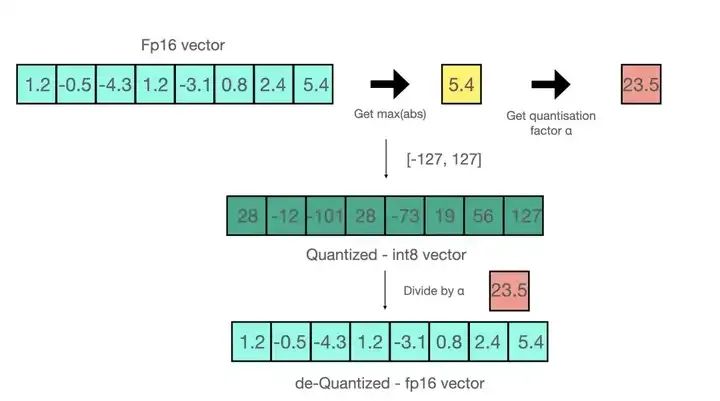
INT 8量化相对简单。如图所示的是absmax的INT 8量化,输入是一个FP16的向量。假设用 absmax 对向量[1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]进行量化。首先需要计算该向量的最大绝对值,在本例中为5.4。Int8 的范围为[-127, 127],因此我们将127除以5.4,得到缩放因子(scaling factor)23.5。最后,将原始向量乘以缩放因子得到最终的量化向量[28, -12, -101, 28, -73, 19, 56, 127]。
要恢复原向量,可以将 int8 量化值除以缩放因子,但由于上面的过程是“四舍五入”的,我们将丢失一些精度。
FP8 量化
Llama 3利用H100 GPU的原生FP8支持来执行低精度推理。为了启用低精度推理,Llama 3对模型内部的大多数矩阵乘法应用FP8量化。实现细节见下面的两篇参考文章。特别是,对模型中前馈网络层的大多数参数和激活值进行量化,这些部分约占推理计算时间的50%。其中还有一些细节:
Llama 3没有对模型的自注意力层中的参数进行量化。也没有在第一个和最后一个Transformer层中执行量化。并且,采用了按行量化的方式,对参数和激活矩阵的每一行计算缩放因子(Scaling Factor)。如下图所示。

量化结果
量化结果主要是两个方面,一个是好处,即efficiency的提升;一个是坏处,即accuracy的下降。
对于efficiency,Llama 3针对于4,096 input tokens and 256 output tokens做了定量实验,在prefill阶段(2.2 Model Architecture 中有详细介绍),使用FP8推理可将吞吐量提高多达50%(4k->9k);在decode阶段,也能更好地trade off throughput-latency。
对于accuracy,在标准benchmark上,即使不做上文所说的细节,FP8推理的表现也与BF16推理相当。但是当Scaling Factor没有上限时,模型有时会生成错误的响应,所以benchmark无法正确和充分地反映FP8量化的影响。于是Llama 3使用FP8和BF16生成了100,000个响应,选择用奖励模型的分布来分析。从下图可以看到,FP8的得分几乎没有影响RM的得分分布。
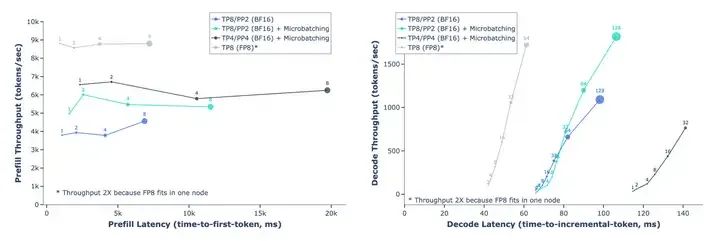
Throughput-latency trade-off in FP8 inference with Llama 3 405B
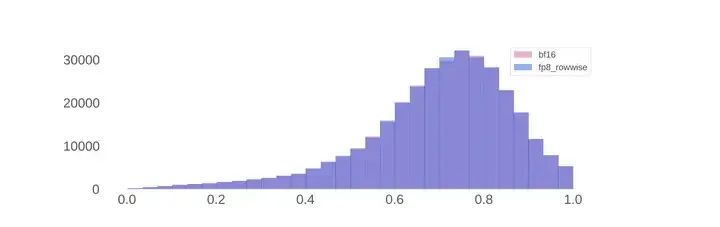
Reward score distribution for Llama 3 405B using BF16 and FP8 inference.
5 写在最后
最近平时工作可以说是把脑子想“干”了,所以花大概三个周末完成了这篇接近2w字的文章。写完感觉有很多不足,但还是随便找个时间发了吧。其一是,本来是打算从Llama 3这种优质开源模型和报告出发,进行一些知识上的梳理,结果行文时几乎保留了论文原来的结构,导致前一个知识点到下一个知识点不够丝滑;
其二是,由于水平不够和“综合性”考量的限制,所以对很多需要深入的知识没有详尽。后面几个周末也许还会持续迭代一下本文,主要是继续细化技术点。所以也恳请诸位指出错误或不足,尽情提出需要补充内容的部分。
引用链接
[1] IFEval Dataset | Papers With Code: https://paperswithcode.com/dataset/ifeval[2] LiveBench: https://livebench.ai/[3] [KV Cache优化] MQA/GQA/YOCO/CLA/MLKV笔记: 层内和层间KV Cache共享: https://zhuanlan.zhihu.com/p/697311739[4] 《动手学深度学习PyTorch版》:全要点笔记: https://zhuanlan.zhihu.com/p/664880302
相关文章:
现代LLM基本技术整理
0 开始之前 作者:hadiii,北京大学 电子信息硕士在读 本文从Llama 3报告出发,基本整理一些现代LLM的技术。基本,是说对一些具体细节不会过于详尽,而是希望得到一篇相对全面,包括预训练,后训练&…...

EasyX与少儿编程:轻松上手的编程启蒙工具
EasyX:开启少儿编程的图形化启蒙之路 随着科技发展,编程逐渐成为孩子们教育中重要的一部分。如何让孩子在编程启蒙阶段更容易接受并激发他们的兴趣,成为许多家长和老师关心的问题。相比起传统的编程语言,图形化编程工具显得更直观…...

【C语言指南】数据类型详解(上)——内置类型
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《C语言指南》 期待您的关注 目录 引言 1. 整型(Integer Types) 2. 浮点型(Floating-Point …...

视频汇聚/视频存储/安防视频监控EasyCVR平台RTMP推流显示离线是什么原因?
视频汇聚/视频存储/安防视频监控EasyCVR视频汇聚平台兼容性强、支持灵活拓展,平台可提供视频远程监控、录像、存储与回放、视频转码、视频快照、告警、云台控制、语音对讲、平台级联等视频能力。 EasyCVR安防监控视频综合管理平台采用先进的网络传输技术࿰…...

联想电脑怎么开启vt_联想电脑开启vt虚拟化教程(附intel和amd主板开启方法)
最近使用联想电脑的小伙伴们问我,联想电脑怎么开启vt虚拟。大多数可以在Bios中开启vt虚拟化技术,当CPU支持VT-x虚拟化技术,有些电脑会自动开启VT-x虚拟化技术功能。而大部分的电脑则需要在Bios Setup界面中,手动进行设置ÿ…...

手把手教你使用YOLOv11训练自己数据集(含环境搭建 、数据集查找、模型训练)
一、前言 本文内含YOLOv11网络结构图 训练教程 推理教程 数据集获取等有关YOLOv11的内容! 官方代码地址:https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11 二、整体网络结构图 三、环境搭建 项目环境如下…...
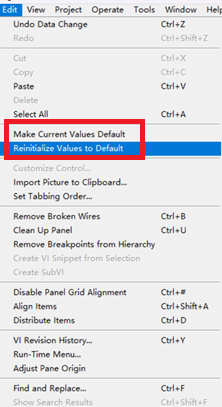
LabVIEW界面输入值设为默认值
在LabVIEW中,将前面板上所有控件的当前输入值设为默认值,可以通过以下步骤实现: 使用控件属性节点:你可以创建一个属性节点来获取所有控件的引用。 右键点击控件,选择“创建” > “属性节点”。 设置属性节点为“D…...

【Android 14源码分析】Activity启动流程-1
忽然有一天,我想要做一件事:去代码中去验证那些曾经被“灌输”的理论。 – 服装…...

Java 中 synchronized 和 Thread 的使用场合介绍
在 Java 编程中,synchronized 和 Thread 是处理并发与多线程编程的关键工具。多线程编程是为了在单一程序中并行执行多个任务,Java 提供了丰富的 API 和关键字以实现这一目标,而其中 synchronized 和 Thread 是非常基础和重要的部分。 synch…...

爬虫库是什么?是ip吗
爬虫库通常指的是用于网页爬虫(Web Scraping)开发的代码库或框架,它不是IP地址。以下是关于爬虫库的详细解释: 爬虫库的定义 爬虫库是一些用于简化网络数据抓取过程的工具和框架,通常提供了一系列函数和类࿰…...
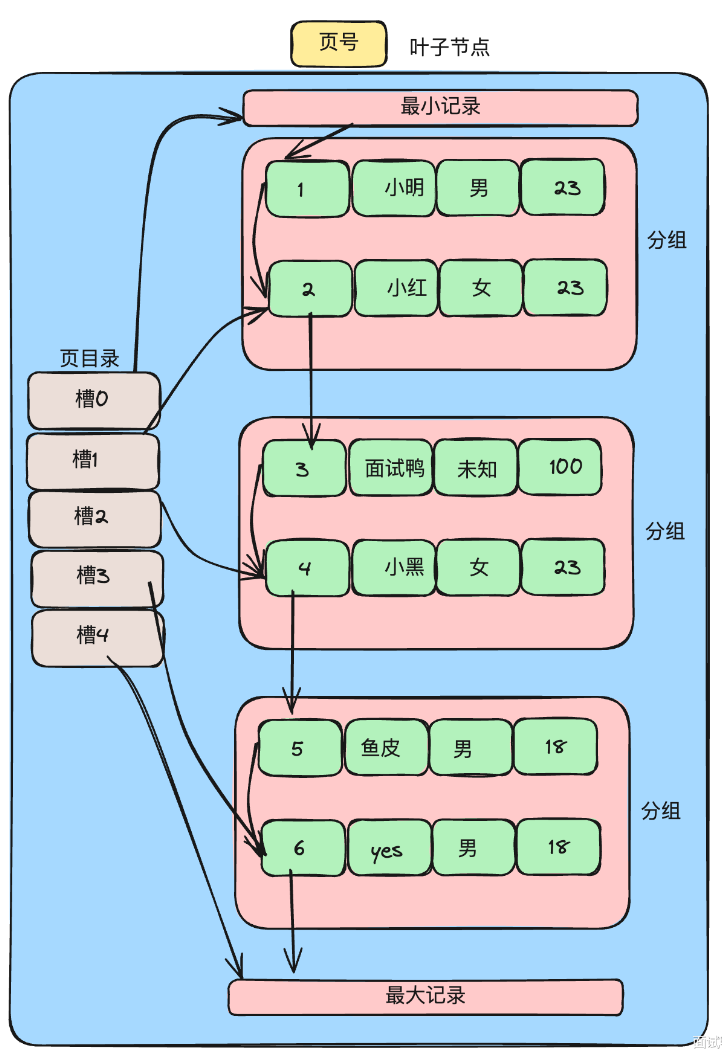
【MySQL】查询原理 —— B+树查询数据全过程
使用B树作为索引结构的原因: 一种自平衡树: B树在插入和删除的时候节点会进行分裂和合并操作,以保持树的平衡,存在冗余节点,使得删除的时候树结构变化小,更高效。 高度不会增长过快,查询磁盘I…...

系统设置 WIFI输入框被挡住解决方案
文章目录 问题点复现的场景机器横屏可复现,竖屏不存在跟density 相关的。 解决问题方案设置输入模式路径 部分源码跟踪方法 延伸思考设置输入模式设置主题 问题点 进入系统设置-网络和互联网-WLAN-点击WIFI item ,密码输入框被遮挡,输入的密码不可见.如…...

SpringCloud无法注册Nacos和配置中心
今天升级SpringCloud版本,导致服务无法注册到nacos,使用nacos作为配置中心也无法刷新配置信息,后来发现是因为只更新了SpringCloud版本,SpringCloud-Alibaba没有更新导致的问题。 升级出现问题的版本是: <dependen…...

word2vector训练数据集整理(代码实现)
import math import os import random import torch import dltools from matplotlib import pyplot as plt #读取数据集 def read_ptb():"""将PTB数据集加载到文本行的列表中"""with open(./ptb/ptb.train.txt) as f:raw_text f.read()return…...

无心上班,只想为祖国庆生?让ChatGPT帮你搞定工作!
国庆假期临近,大家的心早已飞向诗和远方了吧。 然而,现实总是无情地将我们拉回到堆积如山的工作任务上:紧急报告的截止日期就在眼前,复杂的项目策划还未动笔,客户的定制需求迫在眉睫。每年的这个时候,如何…...

【Python】YOLO牛刀小试:快速实现视频物体检测
YOLO牛刀小试:快速实现视频物体检测 在深度学习的众多应用中,物体检测是一个热门且重要的领域。YOLO(You Only Look Once)系列模型以其快速和高效的特点,成为了物体检测的首选之一。本文将介绍如何使用YOLOv8模型进行…...

Vscode超好看的渐变主题插件
样式效果: 插件使用方法: 然后重启,之后会显示vccode损坏,不用理会,因为这个插件是更改了应用内部代码,直接不再显示即可。...

OceanBase技术解析:自适应分布式下压技术
在《OceanBase 数据库源码解析》这本书中,关于SQL执行器的深入剖析相对较少,因此,希望增添一些实用且详尽的补充内容。 上一篇博客《 OceanBase技术解析: 执行器中的自适应技术》中,已初步介绍了执行器中几项典型的自适…...

Firebase和JavaScript创建Postback Link逻辑
Firebase是一个提供后端即服务(BaaS)的平台,它允许开发者快速构建应用程序而无需管理服务器。Firebase不直接提供生成Postback Link的功能,但您可以使用Firebase的功能来构建和管理URL,然后在客户端使用这些URL来实现Postback。 以下是如何使用Firebase和JavaScript来创建…...

docker配置daemon.json文件
报错 :Get "https://registry-1.docker.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) 解决方法 配置加速地址 vim /etc/docker/daemon.json添加以下内容 {"registry-mirro…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...
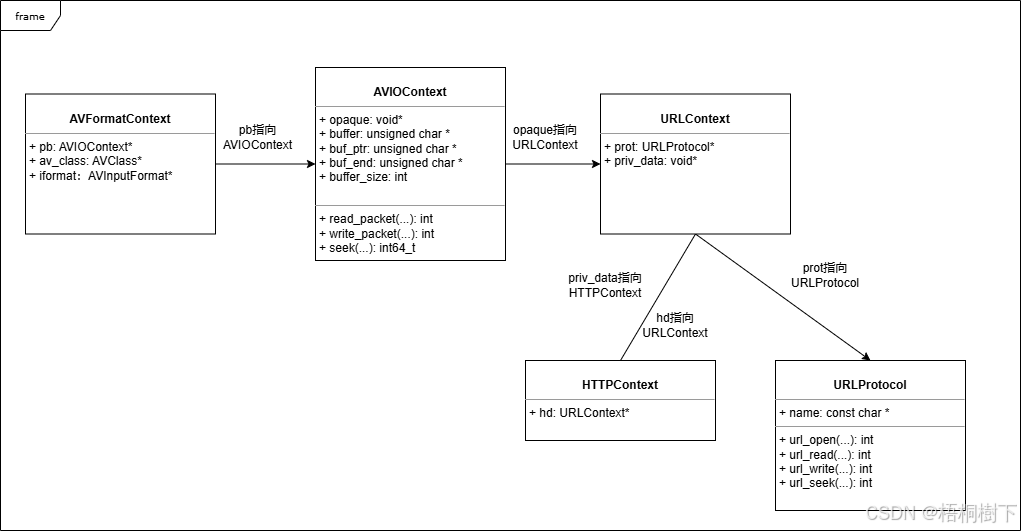
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...

DeepSeek越强,Kimi越慌?
被DeepSeek吊打的Kimi,还有多少人在用? 去年,月之暗面创始人杨植麟别提有多风光了。90后清华学霸,国产大模型六小虎之一,手握十几亿美金的融资。旗下的AI助手Kimi烧钱如流水,单月光是投流就花费2个亿。 疯…...