Ollama本地部署大模型及应用
文章目录
- 前言
- 一、下载安装
- 1.Mac
- 2.Windows
- 3.linux
- 4.docker
- 5.修改配置(可选)
- 1.linux系统
- 2.window 系统
- 3.mac系统
- 二、Ollama使用
- 1.命令
- 2.模型下载
- 3.自定义模型
- 4.API 服务
- 三、Open WebUI 使用
- 四、Dify使用
前言
Ollama 是一个专注于本地部署大型语言模型的工具,通过提供便捷的模型管理、丰富的预建模型库、跨平台支持以及灵活的自定义选项,使得开发者和研究人员能够在本地环境中高效利用大型语言模型进行各种自然语言处理任务,而无需依赖云服务或复杂的基础设施设置。
以下是其主要特点和功能概述:
-
简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型。
-
轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件。
-
API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
-
预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
一、下载安装
1.Mac
下载对应的客户端软件,并安装
下载地址:https://ollama.com/download/Ollama-darwin.zip
2.Windows
下载对应的客户端软件,并安装
下载地址:https://ollama.com/download/OllamaSetup.exe
3.linux
运行命令一键下载安装
curl -fsSL https://ollama.com/install.sh | sh
查看下服务状态
systemctl status ollama
查看安装版本
ollama -v
4.docker
Docker Hub 上提供了官方的 Ollama Docker 镜像。ollama/ollama
需要配置GPU驱动可以看Ollama的docker镜像文档https://hub.docker.com/r/ollama/ollama
拉取镜像
# 使用 CPU 或者 Nvidia GPU 来推理模型
docker pull ollama/ollama
# 使用 AMD GPU 来推理模型
docker pull ollama/ollama:rocm
针对不同的设备,我们的运行指令也需要有不同的调整:
# 默认 CPU 模式运行
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama# Nvidia GPU 模式运行
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama# AMD 显卡运行
docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
5.修改配置(可选)
Ollama 可以设置的环境变量
OLLAMA_HOST:这个变量定义了Ollama监听的网络接口。通过设置OLLAMA_HOST=0.0.0.0,我们可以让Ollama监听所有可用的网络接口,从而允许外部网络访问。OLLAMA_MODELS:这个变量指定了模型镜像的存储路径。通过设置OLLAMA_MODELS=F:\OllamaCache,我们可以将模型镜像存储在E盘,避免C盘空间不足的问题。OLLAMA_KEEP_ALIVE:这个变量控制模型在内存中的存活时间。设置OLLAMA_KEEP_ALIVE=24h可以让模型在内存中保持24小时,提高访问速度。OLLAMA_PORT:这个变量允许我们更改Ollama的默认端口。例如,设置OLLAMA_PORT=8080可以将服务端口从默认的11434更改为8080。OLLAMA_NUM_PARALLEL:这个变量决定了Ollama可以同时处理的用户请求数量。设置OLLAMA_NUM_PARALLEL=4可以让Ollama同时处理两个并发请求。OLLAMA_MAX_LOADED_MODELS:这个变量限制了Ollama可以同时加载的模型数量。设置OLLAMA_MAX_LOADED_MODELS=4可以确保系统资源得到合理分配。
不同操作系统,模型默认存放在:
macOS: ~/.ollama/models
Linux: /usr/share/ollama/.ollama/models
Windows: C:\Users\xxx\.ollama\models
默认只能本地访问,如果需要局域网内其他机器也能访问(比如嵌入式设别要访问本地电脑),需要对 HOST 进行配置,开启监听任何来源IP
1.linux系统
配置文件在:/etc/systemd/system/ollama.service
[Service]
#修改HOST
Environment="OLLAMA_HOST=0.0.0.0"
#修改模型存放位置
Environment="OLLAMA_MODELS=/data/ollama/models"
#如果有多张 GPU,可以对 CUDA_VISIBLE_DEVICES 配置,指定运行的 GPU,默认使用多卡。
Environment="CUDA_VISIBLE_DEVICES=0,1"
配置修改后,需要重启 ollama
systemctl daemon-reload
systemctl restart ollama
2.window 系统
#直接在系统环境变量中加入
OLLAMA_HOST=0.0.0.0:11434
重启服务后生效
3.mac系统
使用launchctl配置环境变量
launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
重启服务后生效
文档:https://github.com/ollama/ollama/blob/main/docs/faq.md
二、Ollama使用
1.命令
终端输入ollama

ollama serve # 启动ollama
ollama create # 从模型文件创建模型
ollama show # 显示模型信息
ollama run # 运行模型,会先自动下载模型
ollama stop # 停止运行模型
ollama pull # 从注册仓库中拉取模型
ollama push # 将模型推送到注册仓库
ollama list # 列出已下载模型
ollama ps # 列出正在运行的模型
ollama cp # 复制模型
ollama rm # 删除模型
ollama models details [模型名称] # 获取更多模型信息
2.模型下载
在官方有类似 Docker 托管镜像的 Docker Hub,Ollama 也有个 Library 托管支持的大模型。
地址:https://ollama.com/library

使用命令ollama run 自动下载模型后运行
ollama run qwen2.5

3.自定义模型
如果要使用的模型不在 Ollama 模型库怎么办?
GGUF (GPT-Generated Unified Format)模型
GGUF 是由 llama.cpp 定义的一种高效存储和交换大模型预训练结果的二进制格式。
Ollama 支持采用 Modelfile 文件中导入 GGUF 模型。
这里我使用Llama3.1-8B-Chinese-Chat模型举例子
模型地址:https://modelscope.cn/models/XD_AI/Llama3.1-8B-Chinese-Chat/files

step 1:新建一个文件名为 llama3-modelfile 的文件,然后在其中指定 llama3 模型路径:
FROM /root/models/llama3.1_8b_chinese_chat_f16.gguf
step 2: 创建模型
这里的llama3.1_8b名字可以自定义
ollama create llama3.1_8b -f llama3-modelfile
step 3: 运行模型
ollama run llama3
4.API 服务
除了本地运行模型以外,还可以把模型部署成 API 服务。
执行下述指令,可以一键启动 REST API 服务:
ollama serve
下面介绍两个常用示例:
1、生成回复
curl http://129.150.63.xxx:11434/api/generate -d '{"model": "qwen2:0.5b","prompt":"Why is the sky blue?","stream":false
}'
2、模型对话
curl http://localhost:11434/api/chat -d '{"model": "qwen2:0.5b","messages": [{ "role": "user", "content": "why is the sky blue?" }],"stream":false
}'
更多参数和使用,可参考 API 文档:https://github.com/ollama/ollama/blob/main/docs/api.md
三、Open WebUI 使用
Open WebUI 是一个可扩展的自托管 WebUI,前身就是 Ollama WebUI,为 Ollama 提供一个可视化界面,可以完全离线运行,支持 Ollama 和兼容 OpenAI 的 API。
GitHub地址:https://github.com/open-webui/open-webui
文档地址:https://docs.openwebui.com/
Open WebUI 部署
我们直接采用 docker 部署 Open WebUI:
因为我们已经部署了 Ollama,故采用如下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
其中:–add-host=host.docker.internal:host-gateway 是为了添加一个主机名映射,将 host.docker.internal 指向宿主机的网关,方便容器访问宿主机服务
假设你之前没有安装过 Ollama,也可以采用如下镜像(打包安装Ollama + Open WebUI):
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
Open WebUI 使用
在打开主机 3000 端口的防火墙之后,浏览器中输入:http://your_ip:3000/,注册一个账号:

可以发现界面和 ChatGPT 一样简洁美观,首先需要选择一个模型,我部署了 qwen2.5,于是先用它试试:

右上角这里可以设置系统提示词,以及模型参数等等:

在个人设置这里,可以看到内置的 TTS 服务:

输入消息进行对话

觉得上述流程略显麻烦?没问题,你的困惑早有人帮你搞定了,GitHub 上有开发者做了 docker-compose 一键整合安装包。Ollama Docker Compose 该项目使用 Docker Compose 简化了 Ollama 的部署,从而可以轻松地在容器化环境中运行 Ollama 及其所有依赖项。
传送门:https://github.com/valiantlynx/ollama-docker
你只需要一行命令:
docker-compose up -d
就能一键启动 Ollama + Open WebUI~
启动成功后,注意看一下不同容器的端口号:
docker ps
四、Dify使用
在 Dify 中接入 Ollama
在 设置 > 模型供应商 > Ollama 中填入:

- 模型名称:llava
- 基础 URL:http://:11434
此处需填写可访问到的 Ollama 服务地址。
若 Dify 为 docker 部署,建议填写局域网 IP 地址,如:http://192.168.1.100:11434 或 docker 宿主机 IP 地址,如:http://172.17.0.1:11434。
若为本地源码部署,可填写 http://localhost:11434。 - 模型类型:对话
- 模型上下文长度:4096
模型的最大上下文长度,若不清楚可填写默认值 4096。 - 最大 token 上限:4096
模型返回内容的最大 token 数量,若模型无特别说明,则可与模型上下文长度保持一致。 - 是否支持 Vision:是
当模型支持图片理解(多模态)勾选此项,如 llava。
如果您使用Docker部署Dify和Ollama,您可能会遇到以下错误:
httpconnectionpool(host=127.0.0.1, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))httpconnectionpool(host=localhost, port=11434): max retries exceeded with url:/cpi/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>: fail to establish a new connection:[Errno 111] Connection refused'))
这个错误是因为 Docker 容器无法访问 Ollama 服务。localhost 通常指的是容器本身,而不是主机或其他容器。要解决此问题,您需要将 Ollama 服务暴露给网络。
OLLAMA_HOST=0.0.0.0
如果以上步骤无效,可以使用以下方法:
问题是在docker内部,你应该连接到host.docker.internal,才能访问docker的主机,所以将localhost替换为host.docker.internal服务就可以生效了:http://host.docker.internal:11434
相关文章:
Ollama本地部署大模型及应用
文章目录 前言一、下载安装1.Mac2.Windows3.linux4.docker5.修改配置(可选)1.linux系统2.window 系统3.mac系统 二、Ollama使用1.命令2.模型下载3.自定义模型4.API 服务 三、Open WebUI 使用四、Dify使用 前言 Ollama 是一个专注于本地部署大型语言模型…...

读代码UNET
这个后面这个大小怎么算的,这参数怎么填,怎么来的? 这是怎么看怎么算的? 这些参数设置怎么设置?卷积多大,有什么讲究?...

【java】前端RSA加密后端解密
目录 1. 说明2. 前端示例3. 后端示例3.1 pom依赖3.2 后端结构图3.3 DecryptHttpInputMessage3.4 ApiCryptoProperties3.5 TestController3.6 ApiCryptoUtil3.7 ApiDecryptParamResolver3.8 ApiDecryptRequestBodyAdvice3.9 ApiDecryptRsa3.10 ApiCryptoProperties3.11 KeyPair3…...

机器学习 | Scikit Learn中的普通最小二乘法和岭回归
在统计建模中,普通最小二乘法(OLS)和岭回归是两种广泛使用的线性回归分析技术。OLS是一种传统的方法,它通过最小化预测值和实际值之间的平方误差之和来找到数据的最佳拟合线。然而,OLS可以遭受高方差和过拟合时&#x…...

代码随想录冲冲冲 Day60 图论Part11
97. 小明逛公园 floyd算法 其实就是先用i和j拼成一个平面 然后看每次从i到j距离 这里分两种情况 1.中间没有经过别的点 2.中间有经过别的点 那么最小步数就要取这两个的最小值 所有根本逻辑是i j确定一个面 再通过不同的k去看每一个中间点 所以k要在最外层 上一次的值要…...

golang web笔记-1.创建Web Server和Handler请求
1. 创建http web server的两个方法 1.1. 方式一:http.ListenAndServe(addr string, handler Handler) addr string:监听地址,如果为"" ,那么就是所有网络接口的80接口handler Handler:如果为nil,那么就是D…...

【Python】Copier:高效的项目模板化工具
Copier 是一个开源的 Python 工具,用于基于项目模板快速生成新项目。它通过灵活的模板化系统,使开发者可以快速创建、维护和更新项目模板,从而自动化项目的初始化流程。无论是简单的文件复制,还是复杂的项目结构配置,C…...

Spring系列 BeanPostProcessor
文章目录 BeanPostProcessor注册时机执行时机 InstantiationAwareBeanPostProcessorSmartInstantiationAwareBeanPostProcessor 本文源码基于spring-beans-5.3.31 参考:https://docs.spring.io/spring-framework/reference/core/beans/factory-extension.html#beans…...

Qualitor processVariavel.php 未授权命令注入漏洞复现(CVE-2023-47253)
0x01 漏洞概述 Qualitor 8.20及之前版本存在命令注入漏洞,远程攻击者可利用该漏洞通过PHP代码执行任意代码。 0x02 复现环境 FOFA:app"Qualitor-Web" 0x03 漏洞复现 PoC GET /html/ad/adpesquisasql/request/processVariavel.php?gridValoresPopHi…...

SpringBoot的概述与搭建
目录 一.SpringBoot的概述 二.SpringBoot 特点 三.SpringBoot 的核心功能 3.1起步依赖 3.2自动配置 四.SpringBoot 开发环境构建 五.SpringBoot 配置文件 六.SpringBoot数据访问管理 七.springboot注解 八.springboot集成mybatis 九.springboot全局异常捕获与处理 一…...
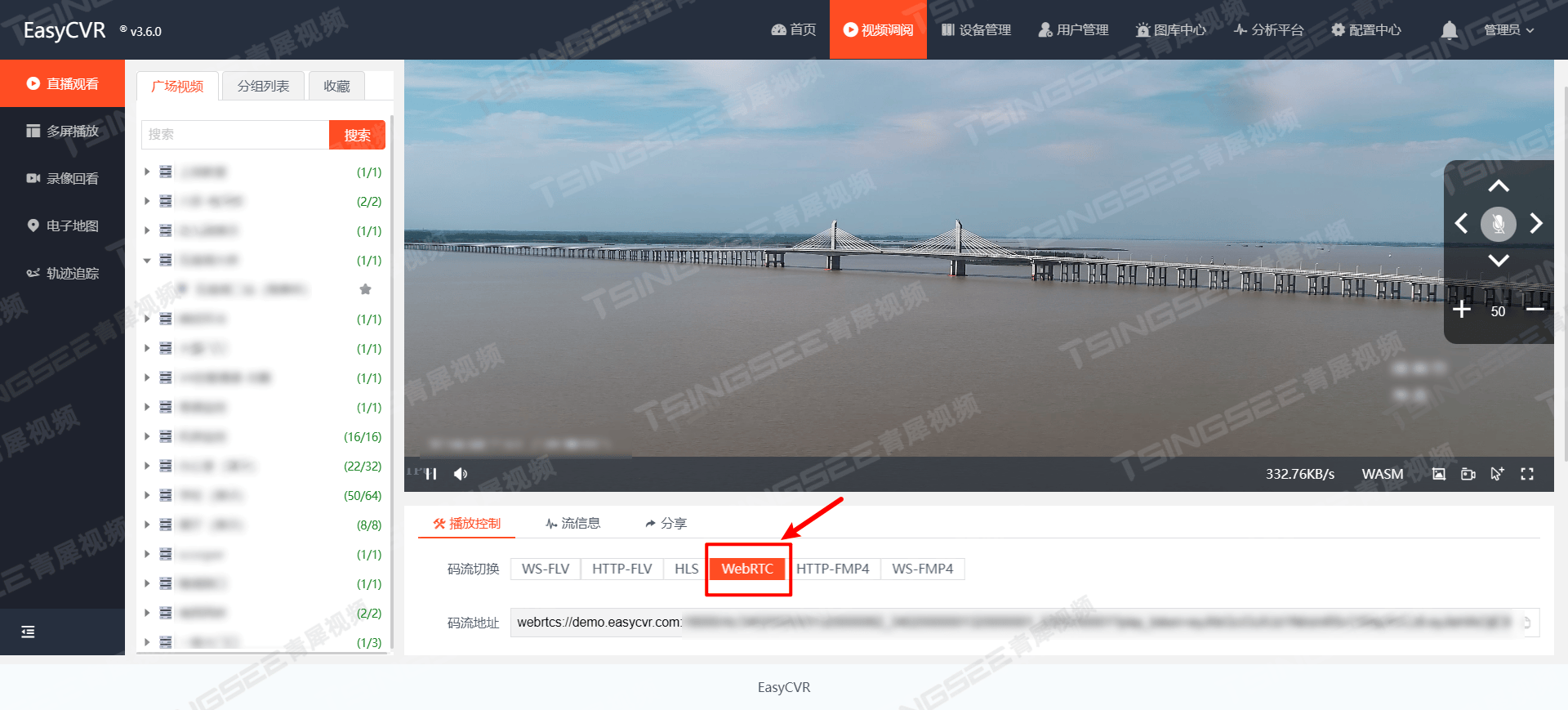
视频集成与融合项目中需要视频编码,但是分辨率不兼容怎么办?
在众多视频整合项目中,一个显著的趋势是融合多元化的视频资源,以实现统一监管与灵活调度。这一需求促使项目团队不断探索新的集成方案,确保不同来源的视频流能够无缝对接,共同服务于统一的调看与管理平台,进而提升整体…...

kafka 换盘重平衡副本 操作流程
一、起因 kakfa某块数据盘损坏,且数据无法恢复,需清空换新盘 二、梳理操作流程 查看topic信息 sh ./kafka-topics --bootstrap-server ***:9092 --list --exclude-internal 查看某个topic数据分布情况 sh ./kafka-topics --bootstrap-server ***:…...

vue3.0 + element plus 全局自定义指令:select滚动分页
需求:项目里面下拉框数据较多 ,一次性请求数据,体验差,效果就是滚动进行分页。 看到这个需求的时候,我第一反应就是封装成自定义指令,这样回头用的时候,直接调用就可以了。 第一步 第二步&…...

HarmonyOS/OpenHarmony 离线加载web资源,并实现web资源更新
关键词:h5离线包加载、h5离线包更新、沙箱 在上一篇文章中,我们已经介绍了如何将 rawfile 资源文件中的文件数据拷贝到沙箱下,那么该篇文章将介绍如何加载该沙箱目录下的文件资源(此处以打包后的web资源为例)…...

【Spark 实战】基于spark3.4.2+iceberg1.6.1搭建本地调试环境
基于spark3.4.2iceberg1.6.1搭建本地调试环境 文章目录 基于spark3.4.2iceberg1.6.1搭建本地调试环境环境准备使用maven构建sparksql编辑SparkSQL简单任务附录A iceberg术语参考 环境准备 IntelliJ IDEA 2024.1.2 (Ultimate Edition)JDK 1.8Spark 3.4.2Iceberg 1.6.1 使用mave…...

TCP连接建立中不携带数据的报文段为何不消耗序号解析
在TCP协议中,序号的使用是为了确保数据能够按照正确的顺序被接收端重组和确认。每个TCP报文段都有一个序号字段,用于标识该报文段中数据的起始位置相对于整个数据流的偏移量。 初始序号和三次握手 在TCP连接的建立过程中,三次握手是确保双方…...

JS设计模式之状态模式:优雅地管理应用中产生的不同状态
一. 前言 在过去,我们经常使用条件语句(if-else 语句)来处理应用程序中的不同状态。然而,这种方式往往会让代码变得冗长、难以维护,并可能引入潜在的 bug。而状态模式则提供了一种更加结构化和可扩展的方法来处理状态…...

C语言系列4——指针与数组(1)
我们开始C语言的指针与数组 这部分开始进阶了,得反复学习 在开始正题之前,写说一下我们都知道当写一个函数的时候需要进行传参,当实参传递给形参的时候,形参是有独立空间的,那么数组传参又是怎么样的呢,我…...

JS网页设计案例
下面是一个简单的 JavaScript 网页设计案例,展示了如何使用 HTML、CSS 和 JavaScript 创建一个动态的网页。 案例:简单的待办事项列表 1. HTML 部分 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8…...

4.2.1 通过DTS传递物理中断号给Linux
点击查看系列文章 》 Interrupt Pipeline系列文章大纲-CSDN博客 4.2.1 通过DTS传递物理中断号给Linux 参考《GICv3_Software_Overview_Official_Release_B》,下表描述了GIC V3支持的INTID(硬件中断号)的范围。 SGI (Software Generated Interrupt):软…...

FRP + Caddy 域名HTTPS配置指南
FRP Caddy 域名HTTPS配置指南 本指南提供使用FRP内网穿透配合Caddy反向代理实现域名访问和HTTPS加密的完整配置方案 📋 目录 项目概览准备工作FRP配置Caddy配置服务管理验证测试 项目概览 本方案通过以下组件实现内网服务的外网访问: 用户访问 [域名…...

基于DSP28335主控的直流有刷电机闭环控制系统:转速PID调控与上位机可视化操作指南
直流有刷电机闭环控制 主控dsp28335,直流有刷电机,采用ab编码器,进行速度闭环。 有转速指令规划处理,速度环pid控制,eqep位置解算、转速解算,可以通过上位机控制电机正反转,发送指令等。 可以直…...

刚刚!GPT-5.4 mini/nano正式发布,轻量编程模型性能逼近满血版
文章目录前言速度快到飞起,程序员终于可以少等会儿了nano来了:便宜到离谱,速度狂魔专属ChatGPT免费用户也能蹭一波福利价格涨了,但性价比其实更高了?小模型崛起,AI开始学会"分工协作"对我们普通人…...
|Flink中是怎么处理乱序数据的)
Flink知识点(二)|Flink中是怎么处理乱序数据的
在 Flink 里,“乱序”本质是 事件时间(event time) 先后顺序和 到达时间(processing time) 不一致。Flink 处理乱序数据的核心机制主要围绕:事件时间语义 Watermark 窗口触发/延迟 迟到数据处理 状态…...

【常见错误】Xilinx Vivado自带编辑器文字部分出现乱码解决办法
一、发现问题在进行FPGA开发时,常用的代码编辑器比如Sublime,但是最近发现再Sublime中编辑的代码文字部分,在用Vivado自带的编辑器打开时,会出现文字错乱的情况,如下图:而在Sublime中实际的情况却是下图这样…...

WebGAL图形化编辑器深度体验:零代码创作专业级视觉小说
WebGAL图形化编辑器深度体验:零代码创作专业级视觉小说 【免费下载链接】WebGAL A brand new web Visual Novel engine | 全新的网页端视觉小说引擎 项目地址: https://gitcode.com/gh_mirrors/we/WebGAL WebGAL是一款全新的网页端视觉小说引擎,它…...

[特殊字符] mPLUG-Owl3-2B多模态交互工具:从安装到多轮视觉问答的完整实操手册
🦉 mPLUG-Owl3-2B多模态交互工具:从安装到多轮视觉问答的完整实操手册 1. 工具简介:你的本地图文对话助手 今天给大家介绍一个特别实用的工具——mPLUG-Owl3-2B多模态交互工具。简单来说,这是一个能看懂图片并回答问题的本地AI助…...

LiuJuan20260223Zimage效果可视化:生成图分辨率、细节还原度、风格一致性实测报告
LiuJuan20260223Zimage效果可视化:生成图分辨率、细节还原度、风格一致性实测报告 1. 引言:当AI画笔遇见特定风格 你有没有想过,让AI帮你生成特定人物的图片,而且每次生成的效果都高度一致?这听起来像是为设计师或内…...

从医疗到工业:模拟与数字电路隔离在不同场景下的最佳实践
从医疗到工业:模拟与数字电路隔离在不同场景下的最佳实践 在电子系统设计中,模拟与数字电路的隔离问题就像一场精心编排的舞蹈——每个动作都需要精确协调,任何失误都可能导致整个表演失败。对于医疗设备工程师来说,这可能意味着心…...

实测速腾16线雷达在自动驾驶小车上的表现:150米测距精度对比与点云优化技巧
速腾RS-LiDAR-16激光雷达在自动驾驶小车上的实战评测:150米测距精度与点云优化全解析 当我在实验室第一次将速腾RS-LiDAR-16安装到自动驾驶小车上时,那密集的点云数据立刻让我意识到——这绝不是普通的传感器。作为一款面向高端机器人应用的16线激光雷达…...