电商选品/分析| 亚马逊常见插件爬虫实战之-helium插件
说明
插件爬虫相当于二次爬虫,二次加工信息,因为大部分插件信息也是从正规网上去获取数据,这次列举helium插件爬虫案例,其他插件爬虫也是类似这个方式.
需求
1、⽤⾕歌浏览器,下载chrome extension:“Helium 10
2、登录helium10

3、打开
- 打开Amazon⾸⻚搜索women clothes https://www.amazon.com/s?
k=women+clothes&crid=F0IYFXRNCJHD&sprefix=women+clothes%2Caps%2C113&ref=n b_sb_noss_1

点击插件,点击Xray,得到如上图的弹窗。
- 针对这个表格⾥的每⼀⾏:
(1)记录所有的信息(序号,Product,ASIN,Brand,Price,Sales,Revenue,BSR,
Seller Country/Region, Fees, Active Sellers, Ratings, Reviews, Size Tier, Buy Box, Fulfillment, Dimensions, Weight, Creation Date)等信息
(2) 在Sales,BSR和Reviews旁边如果不是空值的话,会有⼀个图标

点进图标,选All Time:

下载CSV,以每个产品的ASIN命名csv⽂件。
⽐如:
B0CRKQ44NH_sales.csv, B0CRKQ44NH_bsr.csv, B0CRKQ44NH_review.csv
也就是说,针对每个产品,我想要得到⼀个总表和三个分表(Sales,BSR和Review Count)。遍历所有的women clothes产品(我⼀共需要10000个产品)。
代码
import timefrom platforms.base_platform import ObjectPlatform
from util.xpath_operation import SeleniumOperation
from util.pd_util import PandasUtil
from urllib.parse import urlsplit
import ddddocr
import os
import sys
import datetime'''
helium 谷歌插件爬虫
'''class HeliumExtensionPlatform(ObjectPlatform):name = "heliumextensionplatform"describtion = ""config_file = "%s%s" % (name, "_config")setting_file = "%s%s" % (name, "_setting")def __init__(self, config_file_input=None, setting_file_input=None, log=None):super(HeliumExtensionPlatform, self).__init__(load_extension_2=True, login=False, logger=log)if not self.driver:print("启动失败...,请根据问题,重新启动")sys.exit(1)self.config_file = config_file_input if config_file_input else \"%s%s" % (self.base_config_package, self.config_file)self.setting_file = setting_file_input if setting_file_input else \"%s%s" % (self.base_setting_package, self.setting_file)self.config_package = __import__(self.config_file, fromlist=True)self.setting_package = __import__(self.setting_file, fromlist=True)self.log = logSeleniumOperation.log = logself.beans = {}def before_run(self):dependencies = self.config_package.basic_config["dependencies"]for depend in dependencies:self.log.info("加载依赖:{}....", depend)platform_position = __import__(dependencies[depend]["path"], fromlist=True)if hasattr(platform_position, dependencies[depend]["class"]):dependency = getattr(platform_position,dependencies[depend]["class"]) # http://blog.csdn.net/d_ker/article/details/53671952dependency_obj = dependency(self.driver, log=self.log)self.beans[depend] = dependency_objself.log.info("加载依赖:{}成功", depend)self.ocr = ddddocr.DdddOcr()print("启动%s平台" % HeliumExtensionPlatform.describtion)def run(self):url = self.config_package.basic_config["main_url"]# 打开亚马逊页面print("打开页面:", url)self.get_url_ignore_exception(url)# 解决打开url有验证码的情况self._input_code(url)page = 1print("打开url:", url)SeleniumOperation.get_url_ignore_exception(self.driver, self.config_package.basic_config["url"])while True:print("第%s页数据获取......" % page)datas = self.run_helium_extension()if datas:out_file_name = os.path.join(self.config_package.basic_config["out_path"],str(datetime.date.today()) + "_" + str(page) + ".csv")PandasUtil.write_csv_append(datas, out_file_name)elements = SeleniumOperation.get_elements(self.driver, self.setting_package.NEXT_PAGE_XPATH)if elements:next_page_element = elements[-1]text = next_page_element.textif "下一页" or "Next" in text:next_page_element.click()page += 1print("有下一页, 进入下一页,开始爬取:第%s页......" % (page))while True:time.sleep(5)url_str = self.driver.current_urlpage_str = "page=" + str(page)if page_str in url_str:self.config_package.basic_config["url"] = url_strbreakprint("当前url:%s,希望url中有关键词:%s"%(url_str,page_str))continueelse:print("找不到下一页,结束运行")break'''输入验证码'''def _input_code(self, url):while True:input_code_element = SeleniumOperation.get_element(self.driver, self.setting_package.INPUT_CODE_XPATH)if input_code_element:code = self._ocr_code()if not code:print("刷新页面,识别不出来")self.get_url_ignore_exception(url)continueelse:breakelse:returninput_code_element.clear()input_code_element.send_keys(code)SeleniumOperation.click_button_anyway(self.driver, self.setting_package.SUBMIT_CODE_XPATH)def _ocr_code(self):pic_elements = SeleniumOperation.get_elements(self.driver, self.setting_package.IMAGE_CODE_XPATH)if len(pic_elements) > 1:pic_element = pic_elements[0]image_url = pic_element.get_attribute("src")import requests# code_file_name = os.path.join(self.config_package.basic_config["out_path"],# os.path.splitext(# self.config_package.basic_config["file_name"].split("/")[-1])[# 0] + "-" + str(datetime.time()) + ".jpg")# with open(code_file_name, mode="wb") as f:# f.write(requests.get(image_url).content) # 将图片以二进制写入## with open(code_file_name, 'rb') as f: # 打开图片# img_bytes = f.read() # 读取图片res = self.ocr.classification(requests.get(image_url).content) # 识别print("识别验证码是:", res)return resreturn Nonedef run_helium_extension(self):print("开始运行helium插件")try:self.beans["helium"].before_run(data=self.config_package.basic_config)datas = self.beans["helium"].run()return datasexcept Exception as e:print("运行helium插件出错了")self.log.exception(e)return Nonefinally:self.beans["helium"].after_run()def after_run(self):print("%s 平台已经运行完成,请根据log目录查看运行日志\n" % HeliumExtensionPlatform.describtion)super(HeliumExtensionPlatform, self).after_run()if __name__ == '__main__':url = "https://www.amazon.fr/dp/B0BNW5P4PC?th=1"netloc = urlsplit(url).netlocsubfix_location = netloc.split('.')[-1]print(subfix_location)obj = HeliumExtensionPlatform()obj.run()
插件运行核心代码
import random
import timefrom extensions.basic_extension import BasicExtension
from util.xpath_operation import SeleniumOperation
from settings import ConfigPackage
from settings import SettingPackage
from settings import DownLoadPath
from selenium.webdriver.common.by import By
import os
import shutil
from util.io_util import IOUTILclass Helium10Extension(BasicExtension):name = "helium10extension"config_file = "%s%s" % (name, "_config")setting_package = "%s%s" % (name, "_setting")def __init__(self, driver, log):super(Helium10Extension, self).__init__()self.config_file = "%s%s" % (ConfigPackage, self.config_file)self.setting_file = "%s%s" % (SettingPackage, self.setting_package)self.config_package = __import__(self.config_file, fromlist=True)self.setting_package = __import__(self.setting_file, fromlist=True)self.log = logself.driver = driverself.shadow_driver = driverSeleniumOperation.log = logdef before_run(self, data=None):# XPathOperation.click_button(self.driver, self.setting_package.HELIUM10_CLICK_XPATH)url = data["url"]while self.login():passself._get_shadow_dom(url)while True:SeleniumOperation.click_button_anyway(self.shadow_driver, self.setting_package.HELIUM10_CLICK_CSS_PATH,by_type=By.CSS_SELECTOR)element = SeleniumOperation.get_element(self.shadow_driver,self.setting_package.HELIUM10_XRAY_2_CSS_PATH,loading=False, by_type=By.CSS_SELECTOR)if element:SeleniumOperation.click_button(self.shadow_driver,self.setting_package.HELIUM10_XRAY_2_CSS_PATH,by_type=By.CSS_SELECTOR)breakelse:SeleniumOperation.click_button_anyway(self.shadow_driver, self.setting_package.HELIUM10_CLICK_CSS_PATH,by_type=By.CSS_SELECTOR)element = SeleniumOperation.get_element(self.shadow_driver, self.setting_package.LOGIN_CSS_PATH,loading=False, by_type=By.CSS_SELECTOR)if element:print("需要重新登录....")self.login()self._get_shadow_dom(url)def _get_shadow_dom(self, url):while True:element = SeleniumOperation.get_element(self.driver, self.setting_package.AMAZION_XPATH)if element:self.shadow_driver = SeleniumOperation.get_shadow_root_js(self.driver,self.setting_package.SHADOW_CSS_PATH)if self.shadow_driver:returnprint("刷新页面:", url)element = SeleniumOperation.get_element(self.driver, self.setting_package.SORRY_XPATH)if element:print("回到首页")SeleniumOperation.click_button_anyway(self.driver, self.setting_package.SORRY_XPATH)time.sleep(10)SeleniumOperation.get_url_ignore_exception(self.driver, url)# def before_refresh(self):# element = SeleniumOperation.get_element(self.driver, self.setting_package.SORRY_XPATH)# if element:# SeleniumOperation.get_url_ignore_exception()def run(self):datas, shadow_driver = self.run_page(0)# if not next_page:# print("没有下一页,结束运行.....")# return datasprint("关闭x-ray")click_result = Falsewhile not click_result:element = SeleniumOperation.get_element(shadow_driver, self.setting_package.ALL_CLOSE_CSS_PATH,by_type=By.CSS_SELECTOR)if not element:print("x-ray已经关闭了")breakclick_result = SeleniumOperation.click_button_anyway(shadow_driver, self.setting_package.ALL_CLOSE_CSS_PATH,by_type=By.CSS_SELECTOR)return datasdef run_page(self, begin_index):datas = []count = 0while True:shadow_driver = SeleniumOperation.get_shadow_root_js(self.driver,self.setting_package.SHADOW_DETAIL_PATH)if shadow_driver:count += 1print("X_RAY 树加载出来")elements = SeleniumOperation.get_elements(shadow_driver, self.setting_package.TABLE_CSS_PATH,loading=False,by_type=By.CSS_SELECTOR)if elements and len(elements) > begin_index:breakprint("等待数据出来.......")element = SeleniumOperation.get_element(shadow_driver, self.setting_package.NEW_UI_CSS_PATH,loading=False,by_type=By.CSS_SELECTOR)if element:print("现在是旧的ui,切换新的ui")SeleniumOperation.click_button_anyway(shadow_driver, self.setting_package.NEW_UI_CSS_PATH,loading=False,by_type=By.CSS_SELECTOR)if elements and count > 20 and begin_index > 0:print("重新点击load mores的按钮")SeleniumOperation.click_button_anyway(shadow_driver, self.setting_package.LOAD_MORE_CSS_PATH,by_type=By.CSS_SELECTOR)print("等待X-RAY加载完成")time.sleep(5) # 这个X-RAY隐藏树加载有点慢print("找到%s条数据" % len(elements))elements = elements[begin_index:]print("只要获取%s条数据" % len(elements))for index, element in enumerate(elements):print("获取第%s条数据" % (index + 1))datas.append(self.load_data(element))# # 基于xpath也能找到# child_element = SeleniumOperation.get_element(element, self.setting_package.ORDER_XPATH,# loading=True)# if child_element:# print("xpath方式找到儿子的元素", child_element.text)print("开始下载csv文件")# 下载文件for index, data in enumerate(datas):print("下载第%s个商品:%s 的csv文件" % (index + 1, data['Product']))self.download_all_time_csv(elements[index], data, shadow_driver)# load_more_element = SeleniumOperation.get_element(shadow_driver, self.setting_package.LOAD_MORE_CSS_PATH,# by_type=By.CSS_SELECTOR)# loads_more = False# if load_more_element:# print("还有loads more,尝试loads more点击")# loads_more = SeleniumOperation.click_button_anyway(shadow_driver, self.setting_package.LOAD_MORE_CSS_PATH,# by_type=By.CSS_SELECTOR)return datas, shadow_driverdef download_all_time_csv(self, element, data, shadow_driver):while SeleniumOperation.click_button_anyway(element, self.setting_package.COLUMNS_CSS_PATH["BSR"] + self.setting_package.BSR_CLICK_CSS_PATH,loading=True,by_type=By.CSS_SELECTOR) \or SeleniumOperation.click_button_anyway(element,self.setting_package.COLUMNS_CSS_PATH["Reviews"] + self.setting_package.REVIEWS_CLICK_CSS_PATH,loading=True,by_type=By.CSS_SELECTOR) \or SeleniumOperation.click_button_anyway(element, self.setting_package.COLUMNS_CSS_PATH["Sales"] + self.setting_package.SALE_CLICK_CSS_PATH,loading=True,by_type=By.CSS_SELECTOR):print("进入sales、bsr 、reviews趋势图页面")element = SeleniumOperation.get_element(shadow_driver, self.setting_package.SALE_CLICK_SWITCH_CSS_PATH,loading=True,by_type=By.CSS_SELECTOR)if element:break## else:# print("商品:%s三个地方都不可点击无法下载,ASIN号:%s" % (data["Product"], data["Asin"]))# returnfile_name = data["Asin"] if data["Asin"] else random.Random(10000)if not self.download_files_csv(shadow_driver, self.setting_package.SALE_CLICK_SWITCH_CSS_PATH):print("下载商品{}的sales csv文件失败".format(data["Product"]))self.log.error("下载商品{}的sales csv文件失败".format(data["Product"]))else:self.wait_loaded_and_rename(file_name + "_sales.csv", data)print("下载商品%s的bsr csv文件" % (data["Product"]))if not self.download_files_csv(shadow_driver, self.setting_package.BSR_CLICK_SWITCH_CSS_PATH):print("下载商品{}的bsr csv文件失败".format(data["Product"]))self.log.error("下载商品{}的bsr csv文件失败".format(data["Product"]))else:self.wait_loaded_and_rename(file_name + "_bsr.csv", data)print("下载商品%s的reviews csv文件" % (data["Product"]))if not self.download_files_csv(shadow_driver, self.setting_package.REVIEWS_CLICK_SWITCH_CSS_PATH):print("下载商品%s的reviews csv文件" % (data["Product"]))self.log.error("下载商品{}的reviews csv文件失败".format(data["Product"]))else:self.wait_loaded_and_rename(file_name + "_reviews.csv", data)click_result = Falsewhile not click_result:print("关闭窗口")element = SeleniumOperation.get_element(shadow_driver, self.setting_package.CLOSE_CSS_PATH, loading=True,by_type=By.CSS_SELECTOR)if not element:print("进入sales、bsr 、reviews趋势图页面已经关闭")breakclick_result = SeleniumOperation.click_button_anyway(shadow_driver, self.setting_package.CLOSE_CSS_PATH,loading=True, by_type=By.CSS_SELECTOR)def download_files_csv(self, shadow_driver, css_path):click_result = SeleniumOperation.click_button_anyway(shadow_driver, css_path, loading=True,by_type=By.CSS_SELECTOR)if click_result:# 选择 all——time时间while True:times_elements = SeleniumOperation.get_elements(shadow_driver, self.setting_package.ALL_TIME_CSS_PATH,loading=False,by_type=By.CSS_SELECTOR)if times_elements and len(times_elements) > 1:times_elements[-1].click()breaktime.sleep(5)# 点击下载入口click_result = SeleniumOperation.click_button_anyway(shadow_driver,self.setting_package.DOWNLOAD_ENTRY_CSS_PATH,by_type=By.CSS_SELECTOR)while not click_result:time.sleep(5)click_result = SeleniumOperation.click_button_anyway(shadow_driver,self.setting_package.DOWNLOAD_ENTRY_CSS_PATH,by_type=By.CSS_SELECTOR)# 下载csv文件return SeleniumOperation.click_button_anyway(shadow_driver, self.setting_package.DOWNLOAD_CSV_CSS_PATH,by_type=By.CSS_SELECTOR)def wait_loaded_and_rename(self, filename, data):download_file_name = SeleniumOperation.get_downloaded_filename(self.driver, 5) # wait_time 根据实际需要进行调整if download_file_name:try:shutil.move(os.path.join(DownLoadPath, download_file_name),os.path.join(DownLoadPath, filename))print("文件:%s下载完成" % (filename))returnexcept:passlast_file, last_name = IOUTIL.get_last_filename(DownLoadPath)if "_sales" in last_name or "_bsr" in last_name or "_reviews" in last_name:print("下载商品{}的sales csv文件失败".format(data["Product"]))self.log.error("下载商品{}的sales csv文件失败".format(data["Product"]))returnresult = IOUTIL.rename(last_file, last_name, filename)if not result:self.log.error("文件:{}修改成新文件名:{}出错了,请手动修改".format(last_name, filename))def load_data(self, element):element_data = {}for key, values in self.setting_package.COLUMNS_CSS_PATH.items():child_element = SeleniumOperation.get_element(element, values,loading=True,by_type=By.CSS_SELECTOR)if child_element:text = child_element.textelement_data[key] = textelse:print("找不到%s的元素,请查询是否path问题,默认设置为空")element_data[key] = "None"return element_datadef after_run(self, data=None):passdef _is_login(self):# 判断是否登陆了element = SeleniumOperation.get_element(self.shadow_driver, self.setting_package.HELIUM10_CLICK_CSS_PATH,by_type=By.CSS_SELECTOR)return True if element else Falsedef login(self):try:print("进入尝试自动登录.......")current_url = self.driver.current_urlif "https://members.helium10.com/dashboard?accountId=" in current_url:print("已经登录成功")return FalseSeleniumOperation.get_url_ignore_exception(self.driver, self.config_package.basic_config["login_url"])element = SeleniumOperation.get_element(self.driver, self.setting_package.EMAIL_XPATH)if not element:print("找不到登录输入信息, 可能已经登录成功")return Falseelement.send_keys(self.config_package.basic_config["email"])element = SeleniumOperation.get_element(self.driver, self.setting_package.PASSWORD_XPATH)element.send_keys(self.config_package.basic_config["password"])element = SeleniumOperation.get_element(self.driver, self.setting_package.CAPTCHAID_XPATH)if element:input("请在页面手动操作登陆验证码,然后输入任意按键继续:")SeleniumOperation.click_button(self.driver, self.setting_package.LOGIN_XPATH)return Falseexcept:self.log.exception("登录失败")return True

相关文章:
电商选品/分析| 亚马逊常见插件爬虫实战之-helium插件
说明 插件爬虫相当于二次爬虫,二次加工信息,因为大部分插件信息也是从正规网上去获取数据,这次列举helium插件爬虫案例,其他插件爬虫也是类似这个方式. 需求 1、⽤⾕歌浏览器,下载chrome extension:“Helium 10 2、登录helium10 3、打开 打开Amazo…...

遇到慢SQL、SQL报错,应如何快速定位问题 | OceanBase优化实践
在数据库的使用中,大家时常会遇到慢SQL,或执行出错的SQL。对于某些SQL问题,其错误原因显而易见,但也有不少情况难以直观判断。面对这类问题,我们应当如何应对?如何准确识别SQL错误的根源?是否需…...
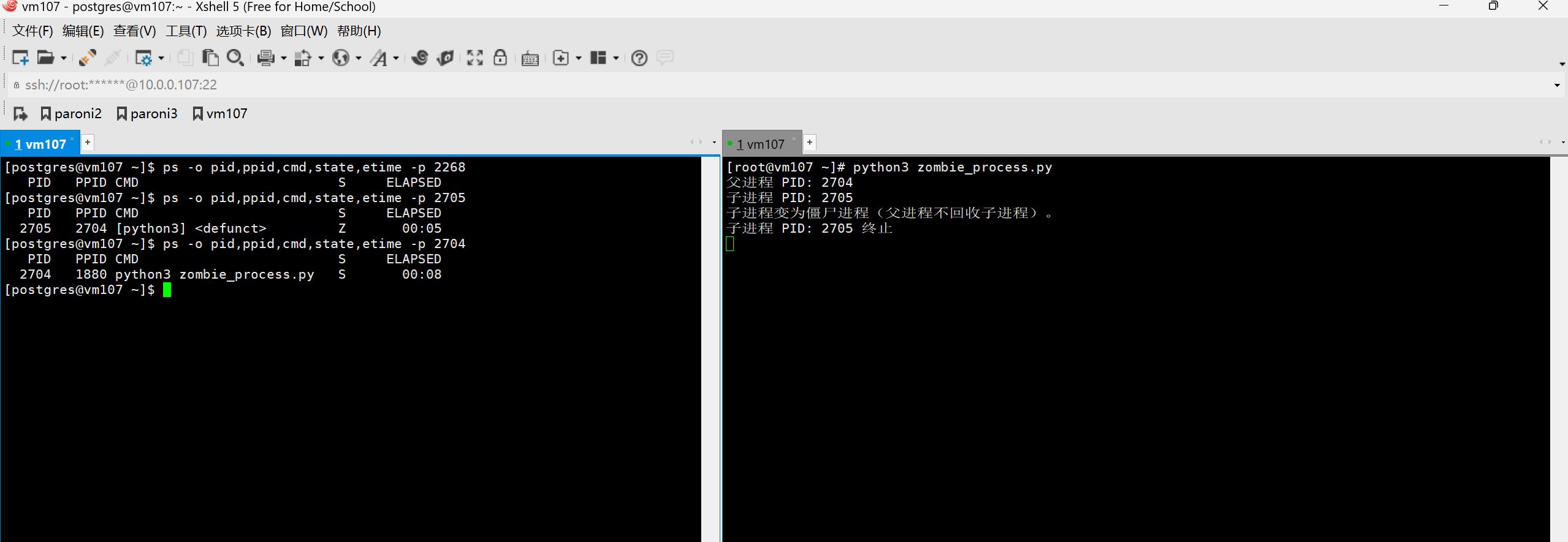
postgresql僵尸进程的处理思路
简介 僵尸进程(zombie process)是指一个已经终止但仍然在进程表中保留条目的进程。正常情况下,当一个进程完成执行并退出时,操作系统会通过父进程调用的wait()或waitpid()系统调用来收集该子进程的退出状态。如果父进程未及时调用…...

Springboot 练习
Springboot练习——分页查询 Emp类 package com.wzb.pojo20240930;import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor;import java.time.LocalDate; import java.time.LocalDateTime;Data NoArgsConstructor AllArgsConstructor public…...

ISA-95制造业中企业和控制系统的集成的国际标准-(3)
ISA-95 文章目录 ISA-95ISA-95设备对象模型一、设备对象模型是什么?二、设备对象模型常见组织 ISA-95设备对象模型 ISA-95 标准中的设备对象模型侧重于表示制造和生产过程中使用的物理和逻辑设备及资源。 一、设备对象模型是什么? 设备对象模型提供了…...

MATLAB中图形导出功能的详细使用指南
在MATLAB中,图形的导出是一个常见的需求,无论是为了报告、演示还是进一步的分析。MATLAB提供了多种方式来导出图形,包括使用图形用户界面(GUI)的工具,以及通过编程方式使用特定的函数。本文将详细介绍如何在MATLAB中导出图形&…...

助农小程序|助农扶贫系统|基于java的助农扶贫系统小程序设计与实现(源码+数据库+文档)
助农扶贫系统小程序 目录 基于java的助农扶贫系统小程序设计与实现 一、前言 二、系统功能设计 三、系统实现 5.1.1 农户管理 5.1.2 用户管理 5.1.3 订单统计 5.2.1 商品信息管理 5.3.1 商品信息 5.3.2 订单信息 5.3.3 商品评价 5.3.4 商品退货 四、数据库设计 1、…...

SpringBoot上传图片实现本地存储以及实现直接上传阿里云OSS
一、本地上传 概念:将前端上传的文件保存到自己的电脑 作用:前端上传的文件到后端,后端存储的是一个临时文件,方法执行完毕会消失,把临时文件存储到本地硬盘中。 1、导入文件上传的依赖 <dependency><grou…...

git clone或repo init 时报错:fatal: 协议错误:错误的行长度 xxx
执行repo init或git clone时报错:protocol error: bad line length 或协议错误:错误的行长度 系统版本:Ubuntu20.04 repo version v2.47 repo launcher version 2.45 git version 2.25.1 报错信息 fatal: 协议错误:错误的行长度 948 fatal: 远端意外挂断了 repo: err…...
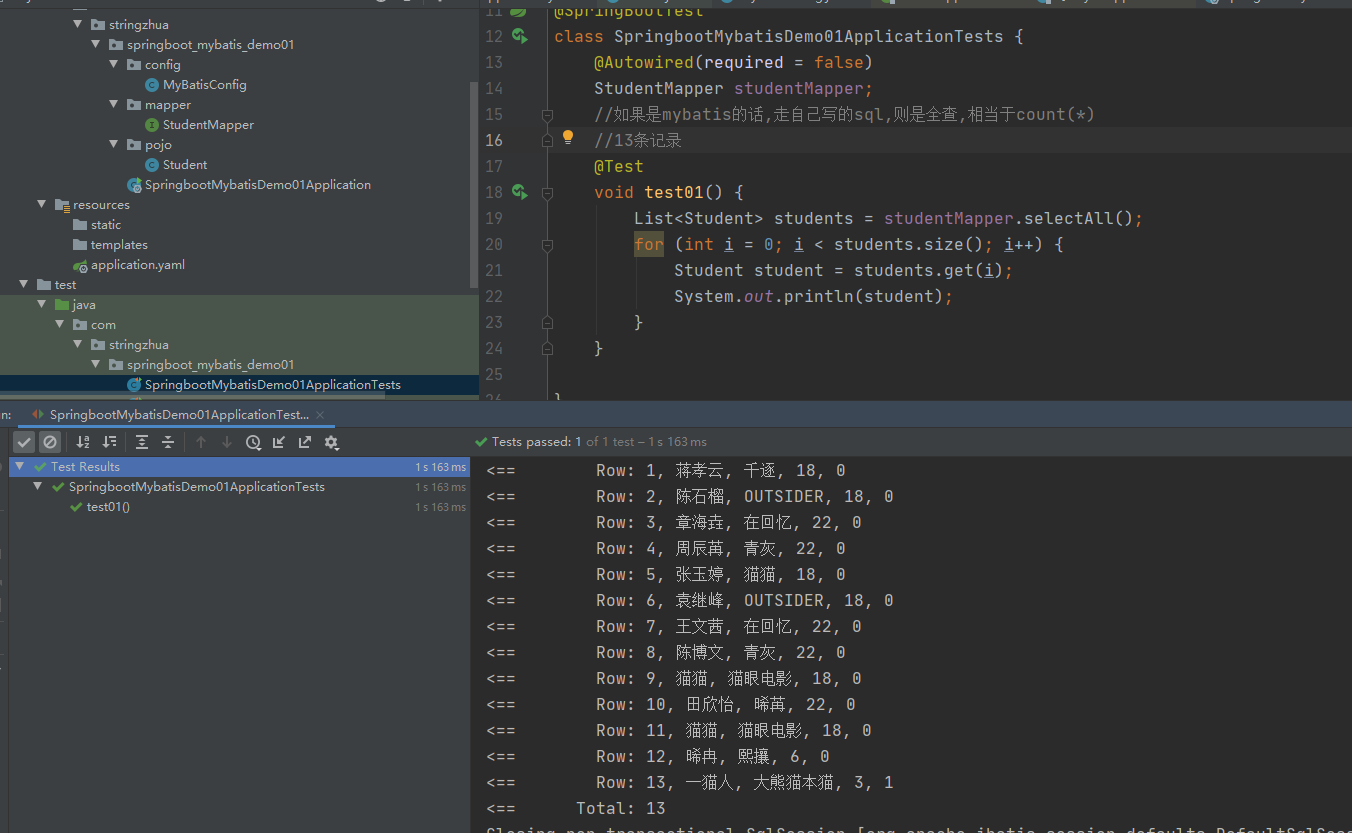
SpringBoot2(Spring Boot 的Web开发 springMVC 请求处理 参数绑定 常用注解 数据传递 文件上传)
SpringBoot2(Spring Boot 的Web开发 springMVC 请求处理 参数绑定 常用注解 数据传递 文件上传) 一、Spring Boot的Web开发 1.静态资源映射规则 总结:只要静态资源放在类路径下: called /static (or /public or /resources or …...

成都网安周暨CCS2024 | 大模型安全与产业应用创新研讨活动成功举办
9月11日-12日,作为2024年国家网络安全宣传周成都系列活动的重磅活动之一,CCS 2024成都网络安全系列活动在成都举行。“大模型安全与产业应用创新研讨活动”同期举办,本场活动由百度安全、成都无糖信息联合承办,特邀云安全联盟CSA大…...

React 解释常见的 hooks: useState / useRef / useContext / useReducer
前言 如果对 re-render 概念还不清楚,建议先看 React & 理解 re-render 的作用、概念,并提供详细的例子解释 再回头看本文。 如果对 React 基础语法还不熟练,建议先看 React & JSX 日常用法与基本原则 再回头看本文。 useState useS…...

telnet发送邮件教程:安全配置与操作指南?
telnet发送邮件的详细步骤?怎么用telnet命令发邮件? 尽管现代邮件客户端和服务器提供了丰富的功能和安全性保障,但在某些特定场景下,了解如何使用telnet发送邮件仍然是一项有价值的技能。AokSend将详细介绍如何安全配置和操作tel…...

超强大的 Nginx 可视化管理工具
今天给大家介绍一款 Nginx 可视化管理界面,非常好用,小白也能立马上手。 nginx-proxy-manager 是一个反向代理管理系统,它基于 NGINX,具有漂亮干净的 Web UI。还可以获得受信任的 SSL 证书,并通过单独的配置、自定义和…...

Android 安装应用-提交阶段之后剩下的操作
它的实现代码在executePostCommitSteps(commitRequest)中,看一下它的代码: /*** On successful install, executes remaining steps after commit completes and the package lock* is released. These are typically more expensive or require calls t…...

buuctf [ACTF2020 新生赛]Include
学习笔记。 开启靶机。 进入靶场: 我们跟进 tips瞅瞅: 额,纯小白,能想到的就是先F12看看,在CTRLu、以及抓包。 得,不会了,看wp呗,不会死磕没脑子0,0? 参考:…...

JS使用MutationObserver接口来监听DOM的更新
在JavaScript中,可以使用MutationObserver接口来监听DOM的更新。以下是一个使用MutationObserver的示例代码,它监听一个DOM节点的变化,并在变化发生时输出信息 // 选择目标节点 const targetNode document.getElementById(some-id);// 创建…...

图解C#高级教程(三):泛型
本讲用许多代码示例介绍了 C# 语言当中的泛型,主要包括泛型类、接口、结构、委托和方法。 文章目录 1. 为什么需要泛型?2. 泛型类的定义2.1 泛型类的定义2.2 使用泛型类创建变量和实例 3. 使用泛型类实现一个简单的栈3.1 类型参数的约束3.2 Where 子句3…...

240930_CycleGAN循环生成对抗网络
240930_CycleGAN循环生成对抗网络 CycleGAN,也算是笔者记录GAN生成对抗网络的第四篇,前三篇可以跳转 240925-GAN生成对抗网络-CSDN博客 240929-DCGAN生成漫画头像-CSDN博客 240929-CGAN条件生成对抗网络-CSDN博客 在第三篇中,我们采用了p…...

ide 使用技巧与插件推荐
ide 使用技巧与插件推荐 一、IDE 使用技巧 1. 快捷键 掌握常用快捷键: Windows: 使用 Ctrl、Alt 和 Shift 的组合。 Mac: 使用 Cmd、Option 和 Shift。 常用快捷键示例: VS Code: Ctrl P: 快速打开文件。 Ctrl Shift P: 打开命令面板。 Ctrl /…...

测试1111
测试1111...
)
保姆级教程:JCG Q30 Pro免拆刷OpenWrt 24.10(附常见问题排查)
JCG Q30 Pro免拆刷OpenWrt 24.10全流程指南与深度优化 为什么选择OpenWrt与JCG Q30 Pro的完美组合 在智能家居和网络设备高度发达的今天,路由器早已不再是简单的网络连接设备。对于技术爱好者而言,一台能够自由定制、性能强劲的路由器,就像…...

SAS9.4在Win10/Win11上的完整避坑实录:从环境准备到逻辑库报错全解决
SAS9.4在Win10/Win11上的完整避坑指南:从环境准备到逻辑库报错全解析 作为统计分析领域的标杆软件,SAS9.4在学术研究和商业分析中占据重要地位。然而,其复杂的安装过程和频繁出现的系统兼容性问题,常常让初学者望而却步。本文将系…...
预测控制附matlab代码)
【数据驱动】基于深度学习LSTM模型的建筑温控系统(地源热泵 GSHP)预测控制附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

rate-limiter-flexible限流器组合:构建多层次的防护体系终极指南
rate-limiter-flexible限流器组合:构建多层次的防护体系终极指南 【免费下载链接】node-rate-limiter-flexible animir/node-rate-limiter-flexible: 是一个用于 Node.js 的可扩展的速率限制库,可以方便地实现 Node.js 应用的速率限制。适合对 Node.js、…...

EasyAnimateV5-7b-zh-InP开源镜像优势:Magvit压缩率提升与生成质量平衡点
EasyAnimateV5-7b-zh-InP开源镜像优势:Magvit压缩率提升与生成质量平衡点 1. 模型核心能力解析 EasyAnimateV5-7b-zh-InP是一个专门针对图像到视频转换任务的7B参数模型,它在视频生成领域展现出了独特的技术优势。与传统的文本生成视频或视频控制类模型…...

洛谷:P4995 跳跳!
题目描述你是一只小跳蛙,你特别擅长在各种地方跳来跳去。这一天,你和朋友小 F 一起出去玩耍的时候,遇到了一堆高矮不同的石头,其中第 i 块的石头高度为 hi,地面的高度是 h00。你估计着,从第 i 块石头跳…...

实战指南:Python3离线环境下的依赖管理与库迁移
1. 为什么需要离线环境管理Python依赖? 在企业级开发场景中,经常会遇到服务器无法连接外网的情况。比如金融行业的交易系统、政府部门的政务平台,或者工厂车间的物联网设备,这些环境通常出于安全考虑会进行物理隔离。我第一次接触…...

Nunchaku-flux-1-dev在互联网产品设计中的应用:用户旅程图智能生成
Nunchaku-flux-1-dev在互联网产品设计中的应用:用户旅程图智能生成 1. 引言 互联网产品团队经常面临一个共同挑战:如何快速理解用户在各个环节的真实体验?传统方法依赖人工访谈、问卷调研和手动绘制用户旅程图,整个过程耗时耗力…...

Local AI MusicGen入门必看:Text-to-Music一键部署实操手册
Local AI MusicGen入门必看:Text-to-Music一键部署实操手册 1. 快速了解:你的私人AI作曲家 Local AI MusicGen是一个基于Meta MusicGen-Small模型的本地音乐生成工具。它最大的特点就是简单易用——你不需要懂任何乐理知识,只需要输入一段文…...