Redis篇(Redis原理 - 数据结构)(持续更新迭代)
目录
一、动态字符串
二、intset
三、Dict
1. 简介
2. Dict的扩容
3. Dict的rehash
4. 知识小结
四、ZipList
1. 简介
2. ZipListEntry
3. Encoding编码
五、ZipList的连锁更新问题
六、QuickList
七、SkipList
八、RedisObject
1. 什么是 redisObject
2. Redis的编码方式
3. 五种数据结构
九、String
十、List
十一、Redis数据结构-Set结构
十二、ZSET
十三、Hash
一、动态字符串
我们都知道 Redis 中保存的 Key 是字符串,value 往往是字符串或者字符串的集合。
可见字符串是 Redis 中最常用的一种数据结构。
不过 Redis 没有直接使用 C 语言中的字符串,因为 C 语言字符串存在很多问题:
获取字符串长度的需要通过运算
非二进制安全
不可修改
Redis 构建了一种新的字符串结构,称为简单动态字符串( Simple Dynamic String ),简称 SDS。
例如,我们执行命令:

那么 Redis 将在底层创建两个 SDS,其中一个是包含 “name” 的 SDS,另一个是包含“虎哥”的 SDS。
Redis 是 C 语言实现的,其中 SDS 是一个结构体,源码如下:

例如,一个包含字符串 “name” 的 sds 结构如下:

SDS 之所以叫做动态字符串,是因为它具备动态扩容的能力,例如一个内容为 “hi” 的 SDS:

假如我们要给 SDS 追加一段字符串 “,Amy” ,这里首先会申请新内存空间:
如果新字符串小于 1M,则新空间为扩展后字符串长度的两倍 +1;
如果新字符串大于 1M,则新空间为扩展后字符串长度 +1M+1。称为内存预分配。


二、intset
IntSet 是 Redis 中 set 集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
结构如下:


其中的 encoding 包含三种模式,表示存储的整数大小不同:

为了方便查找,Redis 会将 intset 中所有的整数按照升序依次保存在 contents 数组中,结构如图:


现在,数组中每个数字都在 int16_t 的范围内,因此采用的编码方式是 INTSET_ENC_INT16,部分占用的字节大
小为:
encoding:4 字节
length:4 字节
contents:2 字节 * 3 = 6 字节


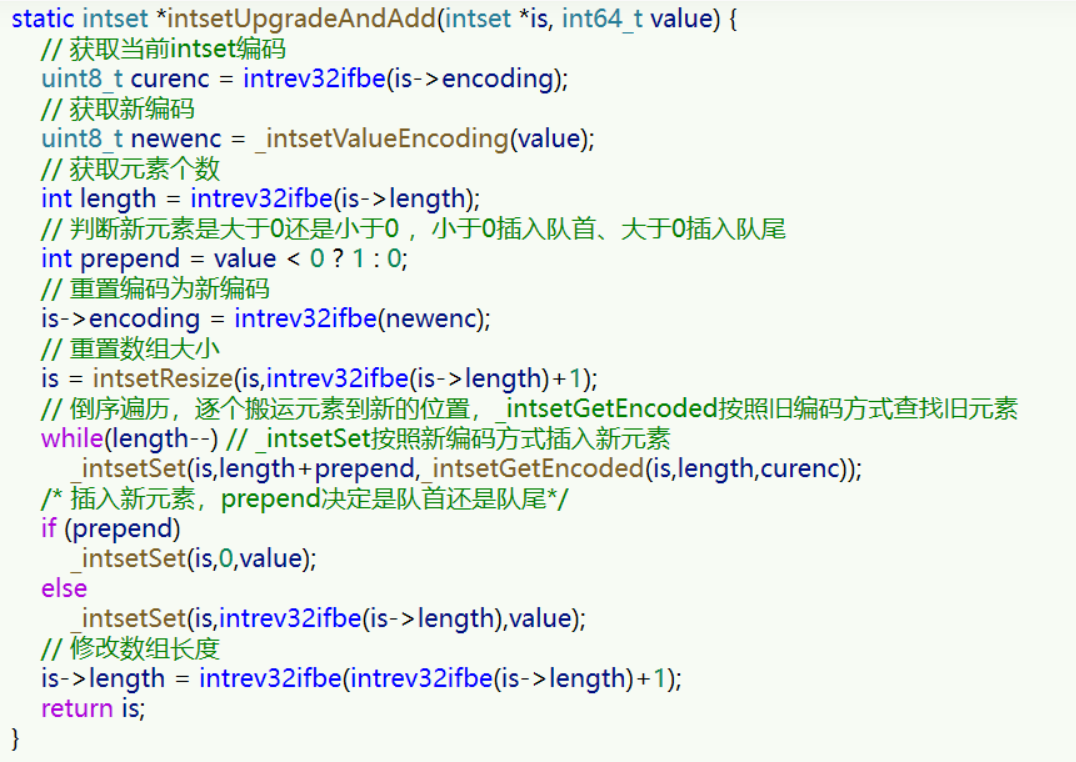
我们向该其中添加一个数字:50000,这个数字超出了 int16_t 的范围,intset 会自动升级编码方式到合适的大
小。
以当前案例来说流程如下:
- 升级编码为 INTSET_ENC_INT32, 每个整数占 4 字节,并按照新的编码方式及元素个数扩容数组
- 倒序依次将数组中的元素拷贝到扩容后的正确位置
- 将待添加的元素放入数组末尾
- 最后,将 inset 的 encoding 属性改为 INTSET_ENC_INT32,将 length 属性改为 4


源码如下:
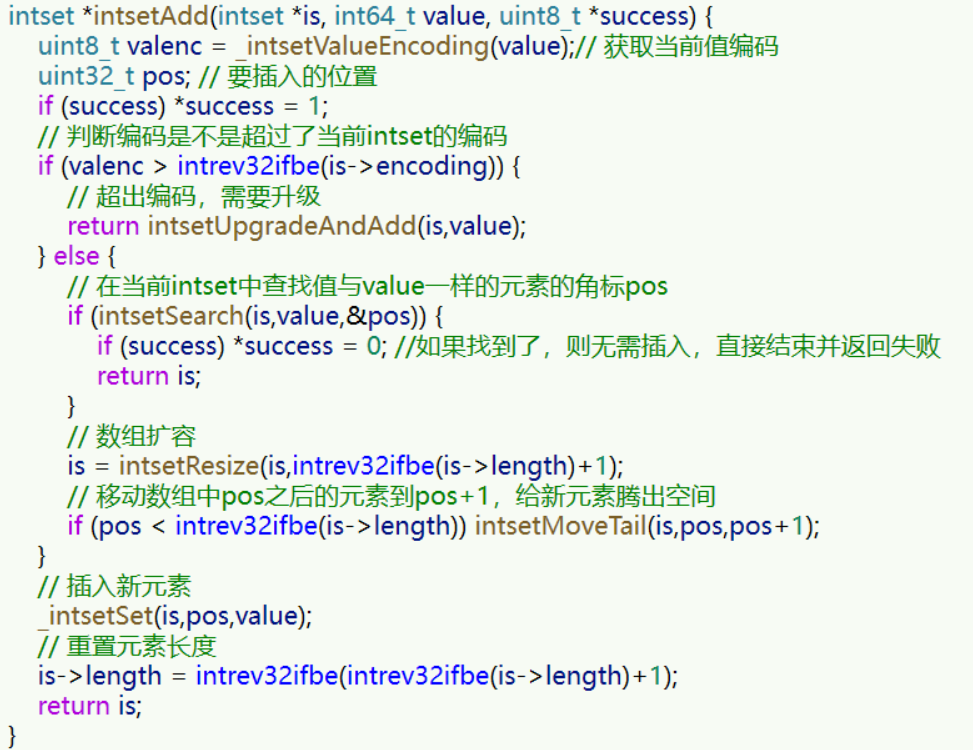
综合所述
Intset 可以看做是特殊的整数数组,具备一些特点:
- Redis 会确保 Intset 中的元素唯一、有序
- 具备类型升级机制,可以节省内存
- 底层采用二分查找方式来查询
三、Dict
1. 简介
我们知道 Redis 是一个键值型( Key-Value Pair )的数据库,我们可以根据键实现快速的增删改查。
而键与值的映射关系正是通过 Dict 来实现的。
Dict 由三部分组成,分别是:哈希表( DictHashTable )、哈希节点( DictEntry )、字典( Dict )

当我们向 Dict 添加键值对时,Redis 首先根据 key 计算出 hash 值( h ),
然后利用 h & sizemask 来计算元素应该存储到数组中的哪个索引位置。
我们存储 k1=v1,假设 k1 的哈希值 h =1,则 1&3 =1,
因此 k1=v1 要存储到数组角标 1 位置。

Dict 由三部分组成,分别是:哈希表( DictHashTable )、哈希节点( DictEntry )、字典( Dict )



2. Dict的扩容
Dict 中的 HashTable 就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,
链表过长,则查询效率会大大降低。
Dict 在每次新增键值对时都会检查负载因子( LoadFactor = used/size ) ,满足以下两种情况时会触发哈希表
扩容:
哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
哈希表的 LoadFactor > 5 ;


3. Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的 size 和 sizemask 变化,而 key 的查询与
sizemask 有关。
因此必须对哈希表中的每一个 key 重新计算索引,插入新的哈希表,这个过程称为 rehash。
过程是这样的:
- 计算新 hash 表的 realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新 size 为第一个大于等于 dict.ht[0].used + 1 的 2^n
- 如果是收缩,则新 size 为第一个大于等于 dict.ht[0].used 的 2^n (不得小于 4)
- 按照新的 realeSize 申请内存空间,创建 dictht,并赋值给 dict.ht[1]
- 设置 dict.rehashidx = 0,标示开始
- 将 dict.ht[0] 中的每一个 dictEntry 都 rehash 到 dict.ht[1]
- 将 dict.ht[1] 赋值给 dict.ht[0],给 dict.ht[1] 初始化为空哈希表,释放原来的 dict.ht[0] 的内存
- 将 rehashidx 赋值为 -1,代表rehash 结束
- 在 rehash 过程中,新增操作,则直接写入 ht[1],查询、修改和删除则会在 dict.ht[0] 和 dict.ht[1] 依次查
找并执行。
这样可以确保 ht[0] 的数据只减不增,随着 rehash 最终为空
整个过程可以描述成:

4. 知识小结
Dict的结构:
- 类似 java 的 HashTable,底层是数组加链表来解决哈希冲突
- Dict 包含两个哈希表,ht[0] 平常用,ht[1] 用来 rehash
Dict 的伸缩:
- 当 LoadFactor 大于 5 或者 LoadFactor 大于 1 并且没有子进程任务时,Dict 扩
- 当 LoadFactor 小于 0.1 时,Dict
- 扩容大小为第一个大于等于 used + 1 的 2^n
- 收缩大小为第一个大于等于 used 的 2^n
- Dict 采用渐进式 rehash,每次访问 Dict 时执行一次 rehash
- rehash 时 ht[0] 只减不增,新增操作只在 ht[1] 执行,其它操作在两个哈希表
四、ZipList
1. 简介
ZipList 是一种特殊的“双端链表” ,由一系列特殊编码的连续内存块组成。
可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。

| 属性 | 类型 | 长度 | 用途 |
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
2. ZipListEntry
ZipList 中的 Entry 并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用 16 个字节,浪费内存。
而是采用了下面的结构:

- previous_entry_length:前一节点的长度,占 1 个或 5 个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为 0xfe,后四个字节才是真实长度数据
- encoding:编码属性,记录 content 的数据类型(字符串还是整数)以及长度,占用 1 个、2 个或 5 个字节
- contents:负责保存节点的数据,可以是字符串或整数
ZipList 中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。
例如:数值 0x1234,采用小端字节序后实际存储值为:0x3412
3. Encoding编码
ZipListEntry 中的 encoding 编码分为字符串和整数两种:
字符串:如果 encoding 是以 “00”、“01” 或者 “10” 开头,则证明 content 是字符串
| 编码 | 编码长度 | 字符串大小 |
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我们要保存字符串:“ab” 和 “bc”

ZipListEntry 中的 encoding 编码分为字符串和整数两种:
整数:如果 encoding 是以 “11” 开始,则证明 content 是整数,且 encoding 固定只占用1个字节
| 编码 | 编码长度 | 整数类型 |
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24位有符整数(3 bytes) |
| 11111110 | 1 | 8位有符整数(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存数值,范围从0001~1101,减1后结果为实际值 |

五、ZipList的连锁更新问题
ZipList 的每个 Entry 都包含 previous_entry_length 来记录上一个节点的大小,长度是 1 个或 5 个字节:
如果前一节点的长度小于 254 字节,则采用 1 个字节来保存这个长度值
如果前一节点的长度大于等于 254 字节,则采用 5 个字节来保存这个长度值,第一个字节为 0xfe,后四个字节才
是真实长度数据
现在,假设我们有 N 个连续的、长度为 250~253 字节之间的 entry,因此 entry 的 previous_entry_length 属
性用 1 个字节即可表示,
如图所示:


ZipList 这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新( Cascade Update )。
新增、删除都可能导致连锁更新的发生。
综合所述
- 压缩列表的可以看做一种连续内存空间的"双向链表"
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
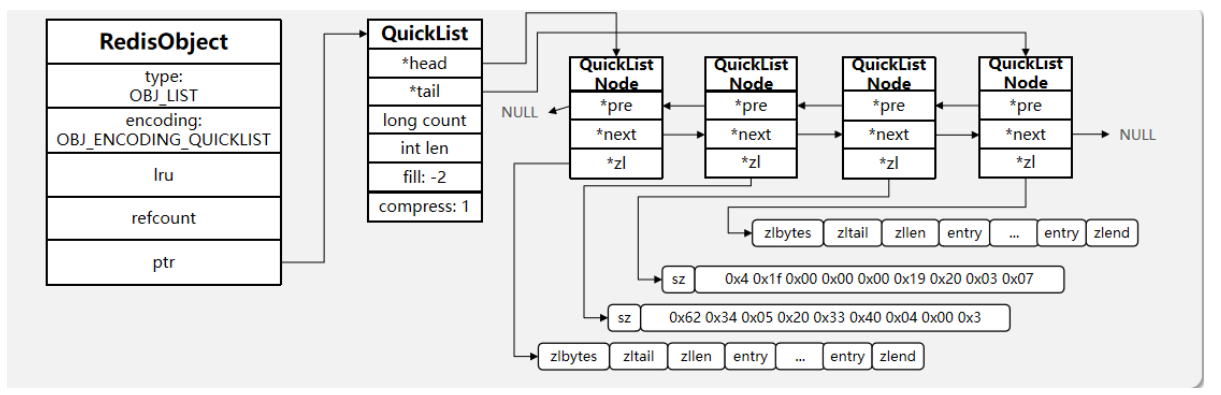
六、QuickList
问题1:ZipList 虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
答:为了缓解这个问题,我们必须限制 ZipList 的长度和 entry 大小。
问题2:但是我们要存储大量数据,超出了 ZipList 最佳的上限该怎么办?
答:我们可以创建多个 ZipList 来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个 ZipList 如何建立联系?
答:Redis 在 3.2 版本引入了新的数据结构 QuickList,它是一个双端链表,只不过链表中的每个节点都是一个
ZipList。

为了避免 QuickList 中的每个 ZipList 中 entry 过多,Redis 提供了一个配置项:list-max-ziplist-size 来限制。
如果值为正,则代表 ZipList 的允许的 entry 个数的最大值
如果值为负,则代表 ZipList 的最大内存大小,分 5 种情况:
- -1:每个 ZipList 的内存占用不能超过 4kb
- -2:每个 ZipList的 内存占用不能超过 8kb
- -3:每个 ZipList 的内存占用不能超过 16kb
- -4:每个 ZipList 的内存占用不能超过 32kb
- -5:每个 ZipList 的内存占用不能超过 64kb
其默认值为 -2:

以下是 QuickList 的和 QuickListNode 的结构源码:

我们接下来用一段流程图来描述当前的这个结构
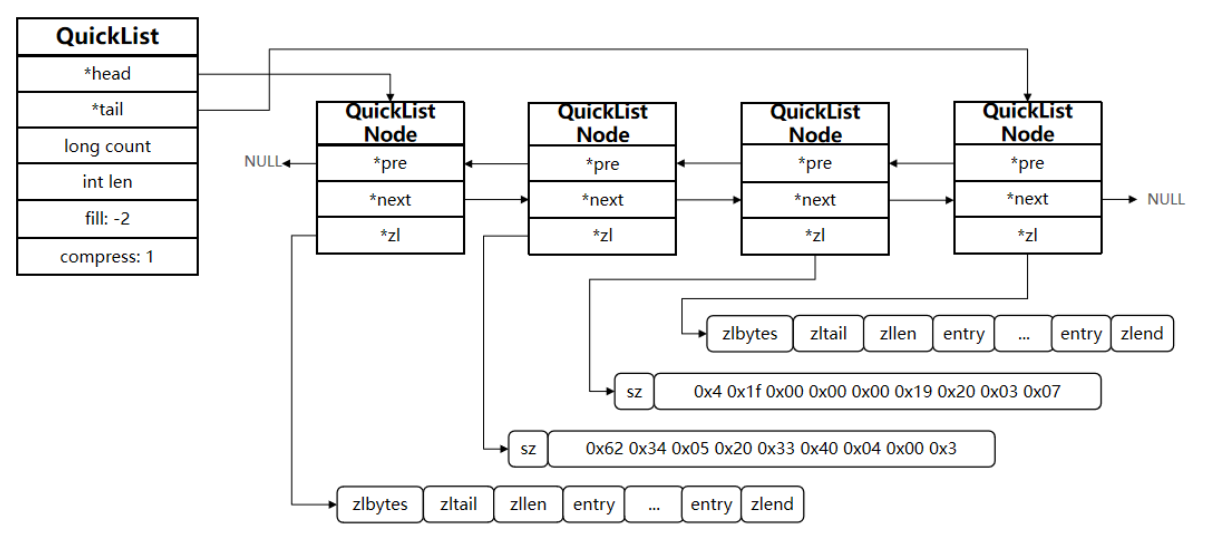
综合所述
- QuickList 是一个节点为 ZipList 的双端链表
- 节点采用 ZipList,解决了传统链表的内存占用
- 控制了 ZipList 大小,解决连续内存空间申请效率
- 中间节点可以压缩,进一步节省了内存
七、SkipList
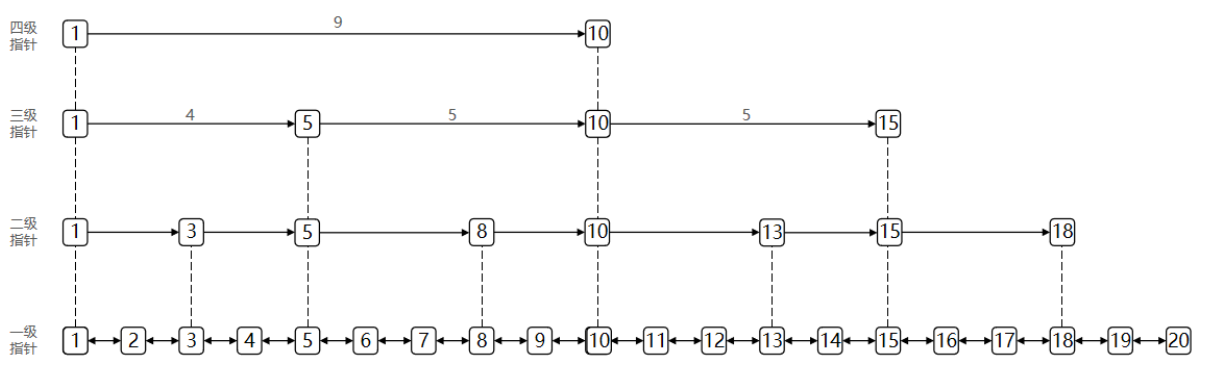
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
元素按照升序排列存储
节点可能包含多个指针,指针跨度不同。
SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
元素按照升序排列存储
节点可能包含多个指针,指针跨度不同。

SkipList(跳表)首先是链表,但与传统链表相比有几点差异:
元素按照升序排列存储
节点可能包含多个指针,指针跨度不同。
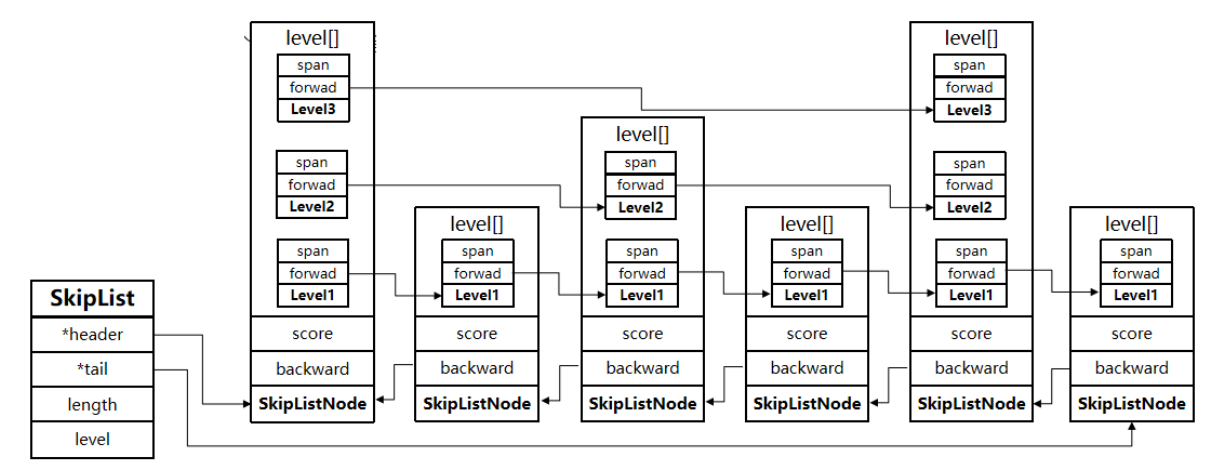
综合所述
- 跳跃表是一个双向链表,每个节点都包含 score 和 ele 值
- 节点按照 score 值排序,score 值一样则按照 ele 字典
- 每个节点都可以包含多层指针,层数是 1 到 32 之间的随机
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单
八、RedisObject
Redis 中的任意数据类型的键和值都会被封装为一个 RedisObject,也叫做 Redis 对象,源码如下:
1. 什么是 redisObject
从 Redis 的使用者的角度来看,⼀个 Redis 节点包含多个 database(非 cluster 模式下默认是 16 个,cluster 模
式下只能是 1 个),而一个 database 维护了从 key space 到 object space 的映射关系。这个映射关系的 key
是 string 类型,⽽ value 可以是多种数据类型,
比如:string , list , hash、set、sorted set 等。
我们可以看到,key 的类型固定是 string,而 value 可能的类型是多个。
⽽从 Redis 内部实现的⾓度来看,database 内的这个映射关系是用⼀个 dict 来维护的。
dict 的 key 固定用⼀种数据结构来表达就够了,这就是动态字符串 sds。而 value 则比较复杂,为了在同⼀个
dict 内能够存储不同类型的 value,这就需要⼀个通⽤的数据结构,这个通用的数据结构就是 robj,全名是
redisObject。

2. Redis的编码方式
Redis 中会根据存储的数据类型不同,选择不同的编码方式,共包含 11 种不同类型:
| 编号 | 编码方式 | 说明 |
| 0 | OBJ_ENCODING_RAW | raw编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
3. 五种数据结构
Redis 中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型的使用的编码方式如下:
| 数据类型 | 编码方式 |
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
九、String
String 是 Redis 中最常见的数据存储类型:
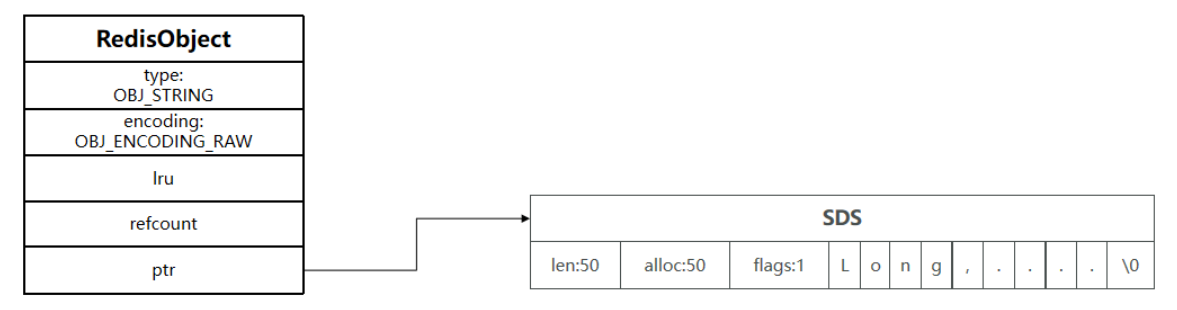
其基本编码方式是 RAW,基于简单动态字符串( SDS )实现,存储上限为 512mb。
如果存储的 SDS 长度小于 44 字节,则会采用 EMBSTR 编码,此时 object head 与 SDS 是一段连续空间。申请
内存时只需要调用一次内存分配函数,效率更高。
底层实现⽅式:动态字符串 sds 或者 long
String 的内部存储结构⼀般是 sds( Simple Dynamic String ,可以动态扩展内存),但是如果⼀个 String 类型
的 value 的值是数字,那么 Redis 内部会把它转成 long 类型来存储,从⽽减少内存的使用。
如果存储的字符串是整数值,并且大小在 LONG_MAX 范围内,则会采用 INT 编码:直接将数据保存在
RedisObject 的 ptr 指针位置(刚好 8 字节),不再需要 SDS 了。


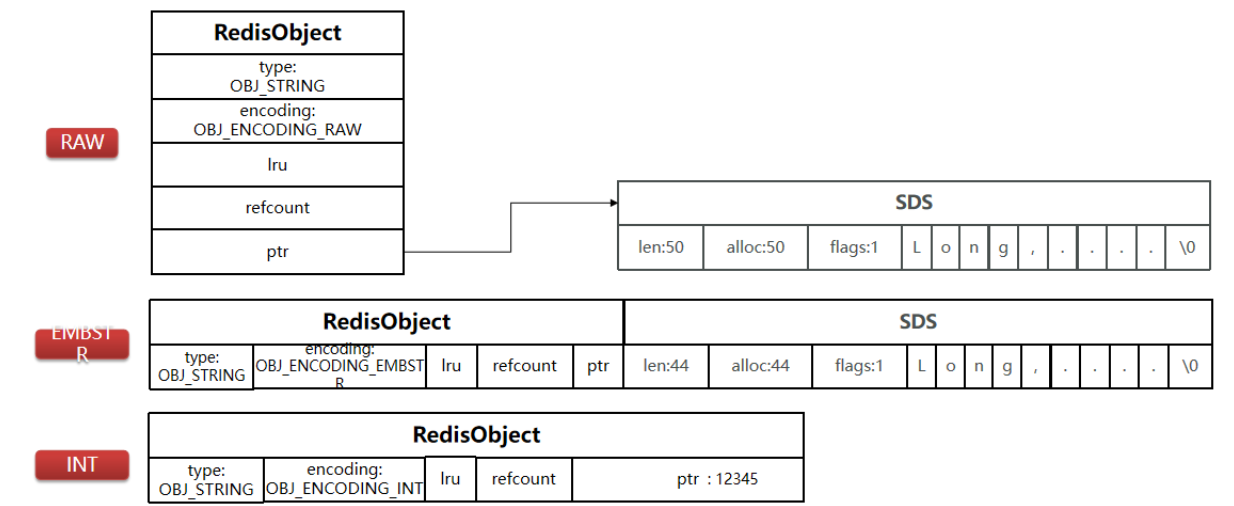
确切地说,String 在 Redis 中是⽤⼀个 robj 来表示的。
用来表示 String 的 robj 可能编码成 3 种内部表⽰:OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,
OBJ_ENCODING_INT。
其中前两种编码使⽤的是 sds 来存储,最后⼀种 OBJ_ENCODING_INT 编码直接把 string 存成了 long 型。
在对 string 进行 incr, decr 等操作的时候,如果它内部是 OBJ_ENCODING_INT 编码,那么可以直接行加减操
作;如果它内部是OBJ_ENCODING_RAW 或 OBJ_ENCODING_EMBSTR 编码,那么 Redis 会先试图把 sds 存储
的字符串转成 long 型,如果能转成功,再进行加减操作。
对⼀个内部表示成 long 型的 string 执行 append , setbit , getrange 这些命令,针对的仍然是 string 的值(即
⼗进制表示的字符串),而不是针对内部表⽰的 long 型进⾏操作。
比如字符串 ”32”,如果按照字符数组来解释,它包含两个字符,它们的 ASCII 码分别是 0x33 和 0x32 。当我
们执行命令 setbit key 70 的时候,相当于把字符 0x33 变成了 0x32,这样字符串的值就变成了 ”22”。
⽽如果将字符串 ”32” 按照内部的 64 位 long 型来解释,那么它是 0x0000000000000020,在这个基础上执
⾏ setbit 位操作,结果就完全不对了。
因此,在这些命令的实现中,会把 long 型先转成字符串再进行相应的操作。
十、List
Redis 的 List 类型可以从首、尾操作列表中的元素:

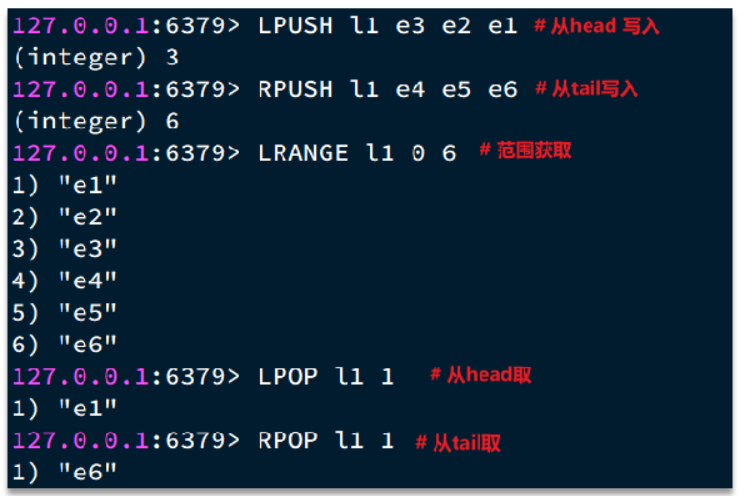
哪一个数据结构能满足上述特征?
- LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多
- ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个 ZipList,存储上限高
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
在 3.2 版本之前,Redis 采用 ZipList 和 LinkedList 来实现 List,当元素数量小于 512 并且元素大小小于 64 字节
时采用 ZipList 编码,超过则采用 LinkedList 编码。
在 3.2 版本之后,Redis 统一采用 QuickList 来实现 List:
十一、Redis数据结构-Set结构
Set 是 Redis 中的单列集合,满足下列特点:
- 不保证有序
- 保证元素
- 求交集、并集、差集

可以看出,Set 对查询元素的效率要求非常高,思考一下,什么样的数据结构可以满足?
HashTable,也就是 Redis 中的 Dict,不过 Dict 是双列集合(可以存键、值对)
Set 是 Redis 中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
为了查询效率和唯一性,set 采用 HT 编码( Dict )。Dict 中的 key 用来存储元素,value 统一为 null。
当存储的所有数据都是整数,并且元素数量不超过 set-max-intset-entries 时,Set 会采用 IntSet 编码,以节省
内存

结构如下:

十二、ZSET
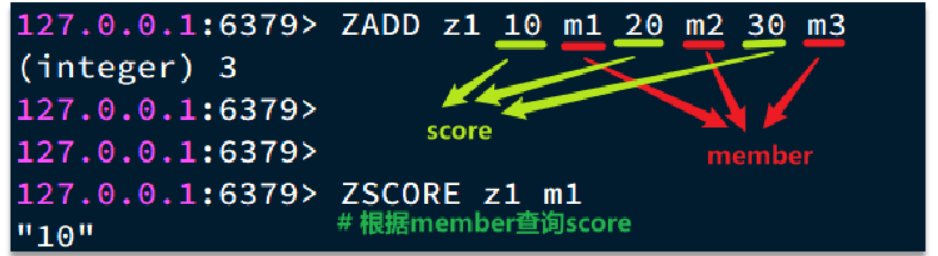
ZSet 也就是 SortedSet,其中每一个元素都需要指定一个 score 值和 member 值:
- 可以根据 score 值排序
- member 必须
- 可以根据 member 查询分数
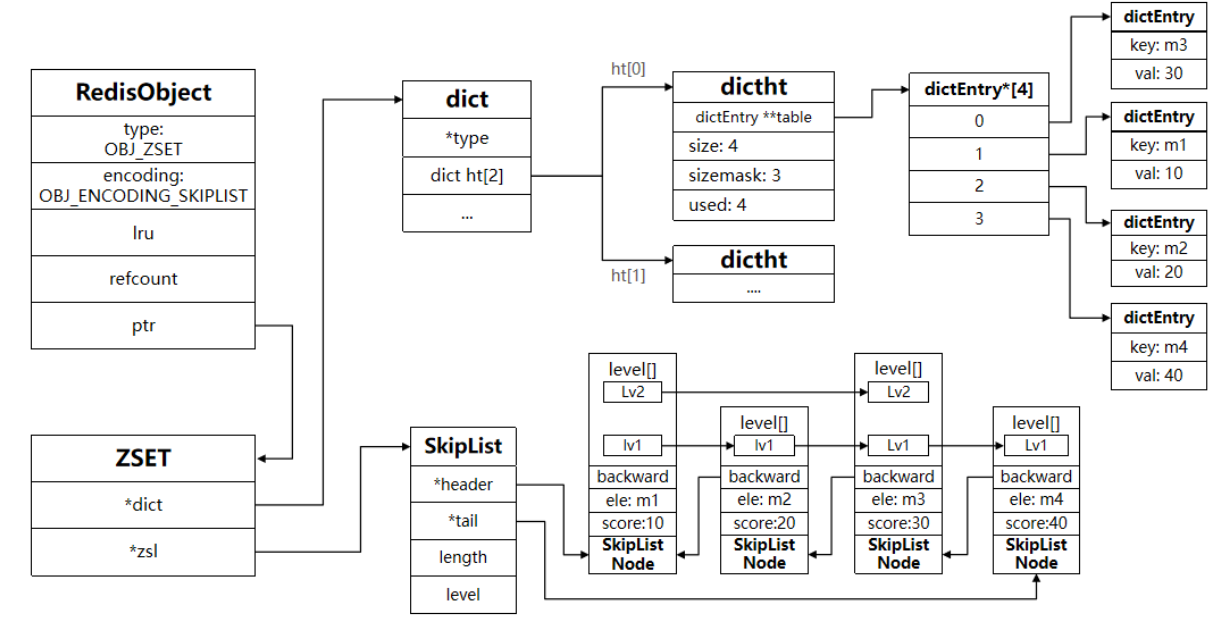
因此,zset 底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。
之前学习的哪种编码结构可以满足?
- SkipList:可以排序,并且可以同时存储 score 和 ele 值( member )
- HT(Dict):可以键值存储,并且可以根据 key 找 value

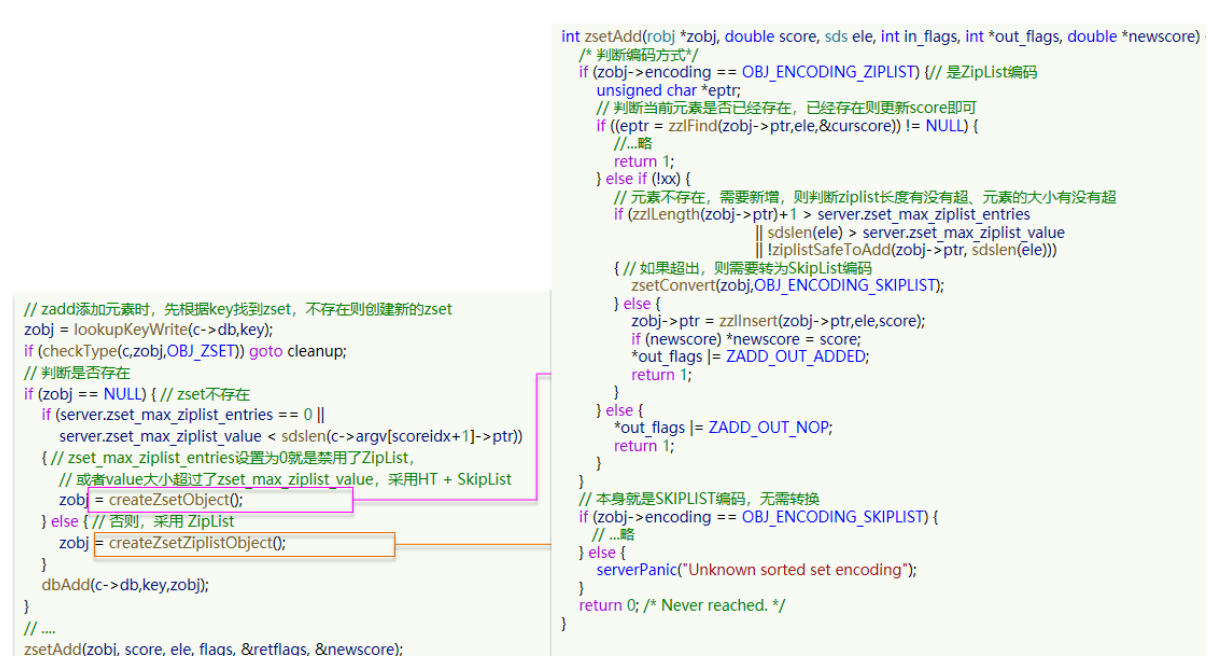
当元素数量不多时,HT 和 SkipList 的优势不明显,而且更耗内存。
因此 zset 还会采用 ZipList 结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于 zset_max_ziplist_entries,默认值 128
- 每个元素都小于 zset_max_ziplist_value字节,默认值 64
ziplist 本身没有排序功能,而且没有键值对的概念,因此需要有 zset 通过编码实现:
- ZipList 是连续内存,因此 score 和 element 是紧挨在一起的两个 entry, element 在前,score 在后
- score 越小越接近队首,score 越大越接近队尾,按照 score 值升序排列

十三、Hash
Hash 结构与 Redis 中的 Zset 非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset 的键是 member,值是 score;hash 的键和值都是任意值
- zset 要根据 score 排序;hash 则无需排序
底层实现方式:压缩列表 ziplist 或者字典 dict
当 Hash 中数据项比较少的情况下,Hash 底层才⽤压缩列表 ziplist 进⾏存储数据,随着数据的增加,底层的 ziplist 就可能会转成 dict ,
具体配置如下:
- hash-max-ziplist-entries 512
- hash-max-ziplist-value 64
当满足上面两个条件其中之⼀的时候,Redis 就使⽤ dict 字典来实现 hash。
Redis 的 hash 之所以这样设计,是因为当 ziplist 变得很⼤的时候,它有如下几个缺点:
- 每次插⼊或修改引发的 realloc 操作会有更⼤的概率造成内存拷贝,从而降低性能。
- ⼀旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更⼤的⼀块数据。
- 当 ziplist 数据项过多的时候,在它上⾯查找指定的数据项就会性能变得很低,因为 ziplist 上的查找需要进行
遍历。
总之,ziplist 本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。
⼀旦数据发⽣改动,就会引发内存 realloc,可能导致内存拷贝。
hash 结构如下:


zset 集合如下:

因此,Hash 底层采用的编码与 Zset 也基本一致,只需要把排序有关的 SkipList 去掉即可:
Hash 结构默认采用 ZipList 编码,用以节省内存。 ZipList 中相邻的两个 entry 分别保存 field 和 value
当数据量较大时,Hash 结构会转为 HT 编码,也就是 Dict,触发条件有两个:
- ZipList 中的元素数量超过了 hash-max-ziplist-entries(默认 512)
- ZipList 中的任意 entry 大小超过了 hash-max-ziplist-value(默认 64 字节)


相关文章:
Redis篇(Redis原理 - 数据结构)(持续更新迭代)
目录 一、动态字符串 二、intset 三、Dict 1. 简介 2. Dict的扩容 3. Dict的rehash 4. 知识小结 四、ZipList 1. 简介 2. ZipListEntry 3. Encoding编码 五、ZipList的连锁更新问题 六、QuickList 七、SkipList 八、RedisObject 1. 什么是 redisObject 2. Redi…...

Disco公司的DBG工艺详解
知识星球里的学员问:可以详细介绍下DBG工艺吗?DBG工艺的优势在哪里? 什么是DBG工艺? DBG工艺,即Dicing Before Grinding,划片后减薄。Dicing即金刚石刀片划切,Grinding即背面减薄,…...

大学学校用电安全远程监测预警系统
1.概述: 该系统是基于移动互联网、云计算技术,通过物联网传感终端,将办公建筑、学校、医院、工厂、体育场馆、宾馆、福利院等人员密集场所的电气安全数据,实时传输至安全用申管理服务器,为用户提供不间断的数据跟踪&a…...

C++网络编程之IP地址和端口
概述 IP地址和端口共同定义了网络通信中的源和目标。IP地址负责将数据从源设备正确地传输到目标设备,而端口则确保在目标设备上数据被交付到正确的应用或服务。因此,在网络编程中,IP地址和端口是密不可分的两个概念,共同构成了网络…...

陶瓷4D打印有挑战,水凝胶助力新突破,复杂结构轻松造
大家好!今天要和大家聊聊一项超酷的技术突破——《Direct 4D printing of ceramics driven by hydrogel dehydration》发表于《Nature Communications》。我们都知道4D打印很神奇,能让物体随环境变化而改变形状。但陶瓷因为太脆太硬,4D打印一…...

网络安全的详细学习顺序
网络安全的详细学习顺序可以按照由浅入深、逐步递进的原则进行。以下是一个建议的网络安全学习顺序: 1. 基础知识学习 计算机网络基础:理解网络架构、TCP/IP协议栈、OSI七层模型、数据链路层到应用层的工作原理。 操作系统基础:了解Window…...

人工智能与机器学习原理精解【28】
文章目录 随机森林随机森林详解随机森林的详细解释1. 随机森林的基本概念、原理和应用场景、公式和计算2. 随机森林在机器学习、深度学习等领域的重要性3. 实际应用案例及其优势和局限性4. 随机森林在解决实际问题中的价值和意义 随机森林局限性的详细归纳随机森林主要的应用领…...
)
StarRocks 中如何做到查询超时(QueryTimeout)
背景 本文基于 StarRocks 3.1.7 主要是分析以下两种超时设置的方式: SESSION 级别 SET query_timeout 10;SELECT sleep(20);SQL 级别 select /* SET_VAR(query_timeout10) */ sleep(20); 通过本文的分析大致可以了解到在Starrocks的FE端是如何进行Command的交互以及数据流走…...

Windows 开发工具使用技巧 Visual Studio使用安装和使用技巧 Visual Studio 快捷键
一、Visual Studio配置详解 1. 安装 Visual Studio 安装时,选择你所需要的组件和工作负载。Visual Studio 提供多种工作负载,例如: ASP.NET 和 Web 开发:用于 Web 应用的开发。 桌面开发(使用 .NET 或 C)…...

计算机网络-系分(5)
目录 计算机网络 DNS解析 DHCP动态主机配置协议 网络规划与设计 层次化网络设计 网络冗余设计 综合布线系统 1. 双栈技术 2. 隧道技术 3. 协议转换技术 其他网络技术 DAS(Direct Attached Storage,直连存储) NAS(Net…...

React Native使用高德地图
在React Native项目中使用高德地图,主要涉及到几个关键步骤:安装高德地图相关的React Native模块、配置项目、申请高德地图API Key、以及在实际组件中使用高德地图功能。以下是一个详细的步骤指南: 一、安装高德地图React Native模块 首先&…...

排序算法的理解
排序算法借鉴了数学里面的不等式的思想 计算机不能直接继承不等式的传递性特征,这个时候才用递归调用去人为的分成不同的部分。或者说,一部分已经大致排序好的数放在一边,另外一边再排。 这是由于计算机只能两两比较数字才会出现的情况。它…...

Yocto - 使用Yocto开发嵌入式Linux系统_04 使用Toaster来创建一个image
Using Toaster to Bake an Image 既然我们已经知道了如何在 Poky 中使用 BitBake 构建图像,那么接下来我们就来学习如何使用 Toaster 构建图像。我们将重点介绍 Toaster 最直接的使用方法,并介绍它的其他功能,让你了解它的能力。 Now that we…...

【C#生态园】后端服务与网络库:选择适合你游戏开发的利器
网络通信不再难题:六种常用游戏开发网络库详解 前言 随着网络游戏行业的蓬勃发展,对于实时多玩家游戏服务和网络通信库的需求也日益增长。在游戏开发中,选择合适的后端服务和网络库可以极大地影响游戏的性能、稳定性和用户体验。本文将介绍…...

计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-30
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-30 目录 文章目录 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-30目录1. Proof Automation with Large Language Models概览:论文研究背景:技术挑战:如何破局…...

【漏洞复现】JeecgBoot 积木报表 queryFieldBySql sql注入漏洞
》》》产品描述《《《 积木报表,是一款免费的企业级Web报表工具,像搭建积木一样在线设计报表!功能涵盖,数据报表、打印设计、图表报表、大屏设计等! 》》》漏洞描述《《《 JeecgBoot 积木报表 queryFieldBySq| 接口存在一个 SQL 注入漏洞&…...

Qt6 中相对于 Qt5 的新增特性及亮点
Qt 是一个领先的跨平台应用开发框架,涵盖了桌面、移动、嵌入式等多个平台。随着 Qt6 的发布,Qt 框架经历了重大升级和变革,带来了大量新特性和架构上的改进,使开发者可以更高效地开发现代化应用程序。本文将重点讨论 Qt6 相对于 Q…...

超轻巧modbus调试助手使用说明
一、使用说明 1.1 数据格式 和其他的modbus采集工具一样,本组件也支持各种数据格式,其实就是高字节低字节的顺序。一般是2字节表示一个数据,后面又有4字节表示一个数据,目前好像还有8字节表示一个数据的设备。不同厂家的设备对应…...

Percona Monitoring and Management
Percona Monitoring and Management (PMM)是一款开源的专用于管理和监控MySQL、MongoDB、PostgreSQL...

WarehouseController
目录 1、 WarehouseController 1.1、 //仓库信息设置 1.2、 /// 查询 1.3、 /// 删除 WarehouseController using QXQPS.Models; using QXQPS.Vo; using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Mv…...

大麦网自动购票工具:技术原理与多场景应用指南
大麦网自动购票工具:技术原理与多场景应用指南 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 在数字化票务时代,热门演出门票往往在开票瞬间售罄&…...
)
Windows下WVP+ZLMediaKit联动实战:5分钟搞定GB28181摄像头接入(附端口避坑清单)
Windows下WVPZLMediaKit联动实战:5分钟搞定GB28181摄像头接入(附端口避坑清单) 在智能视频监控领域,GB28181协议作为国家标准协议,正在成为设备互联的主流选择。但对于刚接触这一领域的开发者来说,从零开始…...
Pixel Language Portal 快速上手PyCharm:远程开发与模型调试配置详解
Pixel Language Portal 快速上手PyCharm:远程开发与模型调试配置详解 1. 为什么需要PyCharm远程开发 作为一名AI开发者,你可能经常遇到这样的困扰:本地电脑性能有限,跑不动大模型;服务器上开发又不够直观方便。PyCha…...

Tetrazine-NHBoc,cas:1380500-93-5,四嗪-氨基叔丁酯的结构特点
Tetrazine-NHBoc(四嗪-氨基叔丁酯)是一种结合了四嗪基团和N-叔丁氧羰基(NHBoc)保护基的有机化合物,以下是对其的详细介绍:一、基本信息中文名称:四嗪-氨基叔丁酯英文名称:Tetrazine-…...

闪豆视频下载器 v20260329-B站抖音爱优腾多平台批量下载,画质自选速度快
一款面向电脑端打造的多平台视频批量下载工具,支持 B 站、A 站、抖音、爱奇艺、优酷、腾讯视频等主流内容平台,覆盖范围较广,适合经常需要从不同平台保存视频内容的用户使用。 软件操作流程简单直接,解析和下载过程清晰易懂&#…...

通义千问1.5-1.8B-Chat-GPTQ-Int4实战:微信小程序集成AI对话功能开发指南
通义千问1.5-1.8B-Chat-GPTQ-Int4实战:微信小程序集成AI对话功能开发指南 最近在做一个宠物社区的小程序,想加个智能客服功能,让用户能随时问问养宠问题。一开始觉得这事儿挺复杂,得自己搞个大模型服务器,成本高不说&…...

AntimicroX完全指南:游戏手柄映射的艺术与科学
AntimicroX完全指南:游戏手柄映射的艺术与科学 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gitcode.com/GitHub_Trend…...
像素史诗落地企业知识库:用Pixel Epic构建内部行业情报自动摘要系统
像素史诗落地企业知识库:用Pixel Epic构建内部行业情报自动摘要系统 1. 企业知识管理的新挑战 在信息爆炸的时代,企业面临的最大挑战不是获取信息,而是如何从海量数据中提取有价值的知识。传统知识管理系统存在几个关键痛点: 信…...
)
ESXi 重置密码详细攻略(全场景覆盖)
本文详细覆盖 ESXi 所有常见场景的密码重置方法,包括「知道原密码改新密码」「忘记root密码(无vCenter)」「有vCenter管理(企业版)」,步骤拆解到每一步点击和命令输入,适配 ESXi 5.x/6.x/7.x/8.x 全版本,兼顾官方支持方法和实用非…...
Pixel Language Portal效果展示:多轮对话上下文跨语种一致性保持
Pixel Language Portal效果展示:多轮对话上下文跨语种一致性保持 1. 产品概览 **像素语言跨维传送门(Pixel Language Portal)**是一款突破性的多语言交互工具,基于腾讯Hunyuan-MT-7B核心引擎构建。不同于传统翻译工具的机械感,它将语言转换…...