Django一分钟:DRF ViewSet烹饪指南,创建好用的视图集
本文将介绍django视图集的内部实现,并带你重写部分代码自己组装强大且趁手的视图集,以满足自定义的业务需求,避免编写大量重复代码。
一、基础知识
Django Rest framework框架允许你将一组相关视图的逻辑组合到一个类中,也就是我们所谓的视图集ViewSet。
与APIView相比,ViewSet更加抽象,更难理解。APIView的使用方法非常直观,需要你提供诸如.get()或.post()之类的处理方法,并由其自动将请求分发到对应的方法上。ViewSet则不同,它要求你提供诸如.list()或.create()这类操作方法,在实现了这些方法之后,使用.as_view()方法请操作方法映射到不同的处理方法上,比如list->get、destroy->delete。
一个简单的示例
from django.contrib.auth.models import User
from django.shortcuts import get_object_or_404
from myapps.serializers import UserSerializer
from rest_framework import viewsets
from rest_framework.response import Responseclass UserViewSet(viewsets.ViewSet):"""一个简单的视图集,实现获取用户列表和查询单个用户的功能"""def list(self, request):queryset = User.objects.all()serializer = UserSerializer(queryset, many=True)return Response(serializer.data)def retrieve(self, request, pk=None):queryset = User.objects.all()user = get_object_or_404(queryset, pk=pk)serializer = UserSerializer(user)return Response(serializer.data)
在很多普通业务中,增删改查的操作是相同的,比如请求数据列表的操作,无非是三步:数据库获取查询集->序列化->返回响应。drf预制了这些重复的工作,将通用的方法封装进了ModelViewSet,借助ModelViewSet我们可以非常轻松的完成增删改查等工作(对应APIView就是ModelAPIView):
class AccountViewSet(viewsets.ModelViewSet):"""只需要指定查询集和序列化器即可"""queryset = Account.objects.all()serializer_class = AccountSerializerpermission_classes = [IsAccountAdminOrReadOnly]
ModelViewSet本身不提供这些通用的list或create之类的方法,而是由一些列Mixin类来实现,ModelViewSet负责把它们组合起来:
class ModelViewSet(mixins.CreateModelMixin,mixins.RetrieveModelMixin,mixins.UpdateModelMixin,mixins.DestroyModelMixin,mixins.ListModelMixin,GenericViewSet): pass
就以CreateModelMixin为例,CreateModelMixin为我们提供了一个通用的和符合标准的create()方法,其过程也就是获取查询集->序列化->返回,没有特殊需求我们的视图集继承它就能获取预制的create方法,不需要再自己实现:
class CreateModelMixin:"""Create a model instance."""def create(self, request, *args, **kwargs):serializer = self.get_serializer(data=request.data)serializer.is_valid(raise_exception=True)self.perform_create(serializer)headers = self.get_success_headers(serializer.data)return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)def perform_create(self, serializer):serializer.save()def get_success_headers(self, data):try:return {'Location': str(data[api_settings.URL_FIELD_NAME])}except (TypeError, KeyError):return {}
细心观察在CreateModelMixin中我们获取序列化器的方法是get_serializer,此外一些其它的Minxin类中,你可能发现其获取查询集的方法是get_queryset或者filter_queryset,还有诸如paginate_queryset这样的方法,一个典型的示例就是ListModelMixin:
class ListModelMixin:"""List a queryset."""def list(self, request, *args, **kwargs):queryset = self.filter_queryset(self.get_queryset())page = self.paginate_queryset(queryset)if page is not None:serializer = self.get_serializer(page, many=True)return self.get_paginated_response(serializer.data)serializer = self.get_serializer(queryset, many=True)return Response(serializer.data)
这些方法并非凭空而来而是由GenericViewSet类来提供,准确说是它的父类GenericAPIView:
class GenericViewSet(ViewSetMixin, generics.GenericAPIView): pass
GenericViewSet继承GenericAPIView为各种Mixin提供统一的获取查询集、序列化器、分页、授权等等接口。
class GenericAPIView(views.APIView):...queryset = Noneserializer_class = None...def get_queryset(self):...def get_object(self):...def get_serializer(self, *args, **kwargs):...def get_serializer_class(self):...def get_serializer_context(self):...def filter_queryset(self, queryset):...def paginator(self):...def paginate_queryset(self, queryset):...def get_paginated_response(self, data):...
二、灵活自定义
drf预制的Mixin足够标准和通用,但如果我们的业务中有特殊需求,我们就需要对drf预制的Mixin重新烹饪,实际操作并不困难,接下来我们通过几个具体的场景来实际体会一下。
自定义响应格式
假如我想让视图集返回的响应遵循如下格式:
{"status": "ok","code": 200,"messages": [],"result": {"user": {"id": 123,"name": "shazow"}}
}
我们可以先实现一个自定义的响应类来替换掉Mixin中使用的响应类。
import json
from rest_framework.response import Responseclass Rep(Response):"""struct json response"""def __init__(self, result=None, message=None, status=None, code=None, **kwargs):if message is None:message = []data = {"status": status,"code": code,"message": message,"result": result}super().__init__(data, code, **kwargs)@staticmethoddef ok(result=None, message=None, code=None, **kwargs):return Rep(result=result, message=message, status="ok", code=code, **kwargs)@staticmethoddef err(result=None, message=None, code=None, **kwargs):return Rep(result=result, message=message, status="err", code=code, **kwargs)
以RetrieveModelMixin为例,你可以继承并重写retrieve,也可以干脆复制一份到自己的项目中,再修改retrieve方法,我们这里选择复制一份到自己的项目中。为了和原来的RetrieveModelMixin做区分,且将其命名为XRetrieveModelMixin:
class XRetrieveModelMixin:"""Retrieve a model instance."""# 使用我们自己的Rep响应类替换了Response响应类def retrieve(self, request, *args, **kwargs):try:instance = self.get_object()except Http404:return Rep.err(None, ["查询数据不存在"], status.HTTP_404_NOT_FOUND)serializer = self.get_serializer(instance)return Rep.ok(serializer.data, None, code=status.HTTP_200_OK)# 对比原来的
# class RetrieveModelMixin:
# """
# Retrieve a model instance.
# """
# def retrieve(self, request, *args, **kwargs):
# instance = self.get_object()
# serializer = self.get_serializer(instance)
# return Response(serializer.data)
自动记录创建和更新数据的用户
细心观察drf的Minxin类并不是将全部分逻辑写在一个create方法或者update方法中,实际上它把实现功能的代码拆分到了多个函数中。
以CreateModelMixin类为例,你可以看到create的方法由perform_create方法和get_success_headers组合而来:
class CreateModelMixin:"""Create a model instance."""def create(self, request, *args, **kwargs):serializer = self.get_serializer(data=request.data)serializer.is_valid(raise_exception=True)self.perform_create(serializer)headers = self.get_success_headers(serializer.data)return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)def perform_create(self, serializer):serializer.save()def get_success_headers(self, data):try:return {'Location': str(data[api_settings.URL_FIELD_NAME])}except (TypeError, KeyError):return {}
这样非常有利于我们进行重写,假如我们想对serializer.save()的过程做些修改,比如记录创建用户,我们就可以通过重写perform_create来实现:
class TrackerModelViewSet(ModelViewSet):def perform_create(self, serializer):serializer.save(created_by=self.request.user)# 记录更新操作的用户;perform_update来自UpdateModelMixindef perform_update(self, serializer):serializer.save(updated_by=self.request.user)
三、总结
学习drf是如何预制Mixin的,我们可以预制自己的Mixin类和视图集,运用得当我们可以打造属于自己的趁手工具以从大量重复工作中解脱。
相关文章:

Django一分钟:DRF ViewSet烹饪指南,创建好用的视图集
本文将介绍django视图集的内部实现,并带你重写部分代码自己组装强大且趁手的视图集,以满足自定义的业务需求,避免编写大量重复代码。 一、基础知识 Django Rest framework框架允许你将一组相关视图的逻辑组合到一个类中,也就是我…...

SEO友好的wordpress模板 应该具体哪些特征
在数字营销的时代,搜索引擎优化(SEO)对于任何网站来说都是至关重要的。WordPress作为全球最受欢迎的内容管理系统之一,提供了大量的模板(也称为主题)供用户选择。一个SEO友好的WordPress模板不仅可以帮助您的网站在搜索引擎中获得更好的排名,…...

1.MySQL存储过程基础(1/10)
引言 数据库管理系统(Database Management System, DBMS)是现代信息技术中不可或缺的一部分。它提供了一种系统化的方法来创建、检索、更新和管理数据。DBMS的重要性体现在以下几个方面: 数据组织:DBMS 允许数据以结构化的方式存…...

linux中使用docker命令时提示权限不足
问题:成功安装docker后,使用docker相关命令时提示权限不足(permission denied) liubailiubai:~$ docker version Client: Version: 24.0.5 API version: 1.43 Go version: go1.20.14 Git commit: ced0996 Built: Tue Jun 25 22:3…...

Lucene最新最全面试题及参考答案
目录 Lucene主要功能及应用场景 Lucene 的索引结构是怎样的? Lucene 中的 Segment 是如何工作的? 如何在 Lucene 中实现文档的增删改查? Lucene 中存储的数据类型有哪些? 解释一下 Lucene 的索引过程。 Lucene 的搜索过程包含哪些步骤? 什么是倒排索引?为什么它对…...

使用keras-tuner微调神经网络超参数
目录 随机搜索RandomSearch HyperBand 贝叶斯优化BayesianOptimization 附录 本文将介绍keras-tuner提供了三种神经网络超参数调优方法。它们分别是随机搜索RandomSearch、HyperBand和贝叶斯优化BayesianOptimization。 首先需要安装keras-tuner依赖库,安装命令如…...
)
【ECMAScript 从入门到进阶教程】第三部分:高级主题(高级函数与范式,元编程,正则表达式,性能优化)
第三部分:高级主题 第十章 高级函数与范式 在现代 JavaScript 开发中,高级函数与函数式编程范式正在逐渐成为开发者追求的目标。这种范式关注于函数的使用,消除副作用,提高代码的可读性和可维护性。 10.1. 高阶函数 高阶函数是…...
LabVIEW光偏振态检测系统
开发一套LabVIEW的高精度光偏振态检测系统,采用机械转动法结合光电探测器和高性能数据采集硬件,能快速、准确地测量光的偏振状态。该系统广泛应用于物理研究、激光技术和光学工业中。 系统组成 该光偏振态检测系统主要由以下硬件和软件模块构成…...
线程与信号之间的关系详解)
Linux线程(八)线程与信号之间的关系详解
本小节将对线程各方面的细节做深入讨论,其主要包括线程与信号之间牵扯的问题、线程与进程控制(fork()、exec()、exit()等)之间的交互。之所以出现了这些问题,其原因在于线程技术的问世晚于信号、进程控制等,然而线程的…...

红帽操作系统Linux基本命令2( Linux 网络操作系统 06)
本文接着上篇Linux常用命令-1继续往后学习其他常用命令。 2.3 目录操作类命令 1.mkdir命令 mkdir命令用于创建一个目录。该命令的语法为: 上述目录名可以为相对路径,也可以为绝对路径。 mkdir命令的常用参数选项如下。 -p:在创…...

降重秘籍:如何利用ChatGPT将重复率从45%降至10%以下?
AIPaperGPT,论文写作神器~ https://www.aipapergpt.com/ 重复率高达45%?很多人一查论文的重复率,瞬间想“完了,这次真的要重写了”。但其实不用这么绝望!有了ChatGPT,降重真的没那么难。今天就教你几招&a…...

sql-labs靶场第九关测试报告
目录 一、测试环境 1、系统环境 2、使用工具/软件 二、测试目的 三、操作过程 1、寻找注入点 2、注入数据库 ①寻找注入方法 ②爆库,查看数据库名称 ③爆表,查看security库的所有表 ④爆列,查看users表的所有列 ⑤成功获取用户名…...

AI大模型的转折点,关注哪些机遇?
近期,人工智能领域取得又一突破性进展,OpenAI官方隆重推出了其最新力作——模型o1。这款模型的最大亮点在于,它融合了强化学习(RL)的训练方法,并在模型推理过程中采用了更为深入的内部思维链(ch…...

Stable Diffusion 常用大模型及其特点
SD(Stable Diffusion)的常用大模型及其特点可以归纳如下: 一、基础大模型 SD 1.x 特点:Stable Diffusion的早期版本,主要用于图像生成任务。这里的1.x表示1系列的主要版本,x是一个变量,表示具体…...

macos安装mongodb
文章目录 说明安装和配置安装mongodb配置PATH变量 验证日志及数据存放目录 mac启动和关闭mongodb后台启动失败问题mongodb-compass(GUI) 说明 Homebrew core 列表目前已经将 MongoDB 移除,不再为其提供支持。但是使用国内镜像的brew还是可以安装的!这里直接从官网下…...
IDEA基础开发配置以及和git的联动
1.1方向一:工具介绍 我今天要介绍的就是学习Java大部分情况下都会选择的一款工具-----IDEA,这个和我们熟悉的这个pycharm一样,都是属于这个Jetbrains公司的,虽然我对于这个并不是很了解,但是确实知道一点,…...

【前端】前端数据转化为后端数据
【前端】前端数据转化为后端数据 写在最前面格式化数组代码解释hasOwnProperty是什么? 🌈你好呀!我是 是Yu欸 🌌 2024每日百字篆刻时光,感谢你的陪伴与支持 ~ 🚀 欢迎一起踏上探险之旅,挖掘无限…...
LabVIEW回转支承间隙自动化检测系统
开发了一种基于LabVIEW软件的回转支承间隙检测系统,通过高精度传感器和数据采集卡,自动化、高效地测量回转支承的轴向间隙和径向间隙,提高了检测精度和生产质量。以下是对系统的详细描述与应用案例分析,希望能为有类似需求的开发者…...

数据结构-4.3.串的存储结构
一.串的顺序存储: 1.静态数组会由系统自动回收;动态数组需要手动回收; 2.优点:随机存取,可以立即找到所需的字符;缺点:插入和删除较麻烦; 3.串的顺序存储方案: 对于方…...

LeetCode讲解篇之34. 在排序数组中查找元素的第一个和最后一个位置
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 这题让我们求目标值的左边界和右边界,我们可以采用二分查找搜索有序数组内大于等于目标值的最左边的下标 然后我们只需要在有序数组查找一下大于等于target的最左边下标 如果该下标越界或者下标对应…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

在四层代理中还原真实客户端ngx_stream_realip_module
一、模块原理与价值 PROXY Protocol 回溯 第三方负载均衡(如 HAProxy、AWS NLB、阿里 SLB)发起上游连接时,将真实客户端 IP/Port 写入 PROXY Protocol v1/v2 头。Stream 层接收到头部后,ngx_stream_realip_module 从中提取原始信息…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
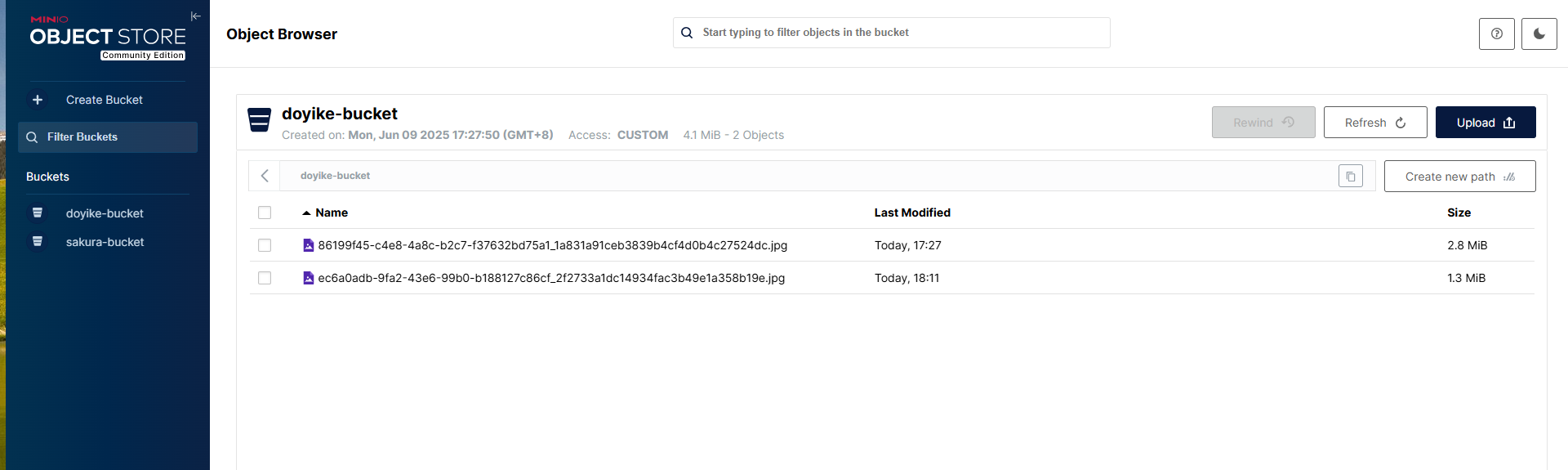
Linux部署私有文件管理系统MinIO
最近需要用到一个文件管理服务,但是又不想花钱,所以就想着自己搭建一个,刚好我们用的一个开源框架已经集成了MinIO,所以就选了这个 我这边对文件服务性能要求不是太高,单机版就可以 安装非常简单,几个命令就…...

【安全篇】金刚不坏之身:整合 Spring Security + JWT 实现无状态认证与授权
摘要 本文是《Spring Boot 实战派》系列的第四篇。我们将直面所有 Web 应用都无法回避的核心问题:安全。文章将详细阐述认证(Authentication) 与授权(Authorization的核心概念,对比传统 Session-Cookie 与现代 JWT(JS…...