Caffeine+Redis两级缓存架构
Caffeine+Redis两级缓存架构
在高性能的服务项目中,我们一般会将一些热点数据存储到 Redis这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。
但是在一些场景下单纯使用 Redis 的分布式缓存不能满足高性能的要求,所以还需要加入使用本地缓存Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存(Caffeine)作为一级缓存,再加上分布式缓存(Redis)作为二级缓存的两级缓存架构。
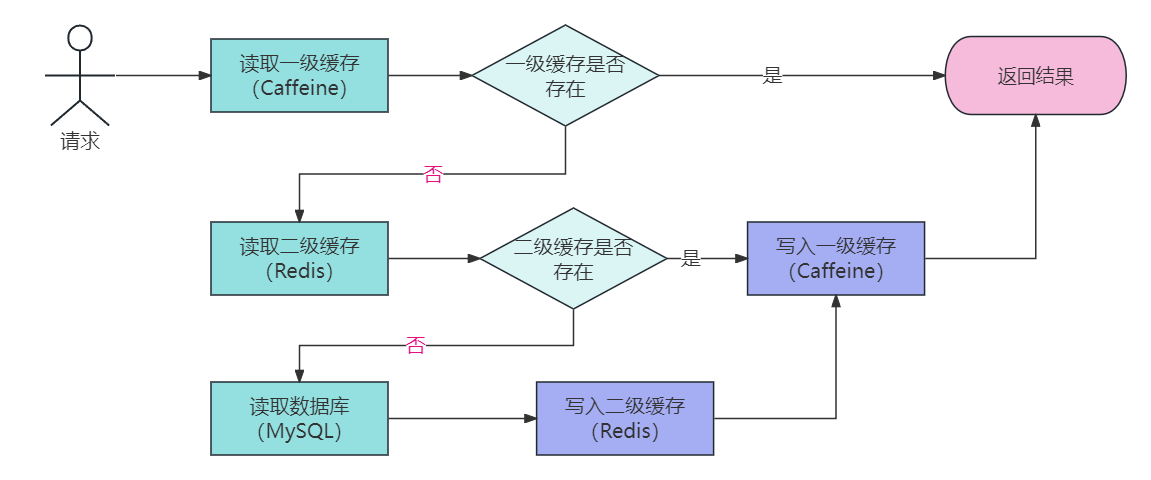
两级缓存架构优缺点
优点:
- 一级缓存基于应用的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度;
- 使用一级缓存能够减少和 Redis 的二级缓存的远程数据交互,减少网络 I/O 开销,降低这一过程中在网络通信上的耗时。
缺点:
- 数据一致性问题:两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,一级缓存、二级缓存应该同步更新。
- 分布式多应用情况下:一级缓存之间也会存在一致性问题,当一个节点下的本地缓存修改后,需要通知其他节点也刷新本地一级缓存中的数据,否则会出现读取到过期数据的情况。
- 缓存的过期时间、过期策略以及多线程的问题
Caffeine+Redis两级缓存架构实战
1、准备表结构和数据
准备如下的表结构和相关数据
DROP TABLE IF EXISTS user;CREATE TABLE user
(id BIGINT(20) NOT NULL COMMENT '主键ID',name VARCHAR(30) NULL DEFAULT NULL COMMENT '姓名',age INT(11) NULL DEFAULT NULL COMMENT '年龄',email VARCHAR(50) NULL DEFAULT NULL COMMENT '邮箱',PRIMARY KEY (id)
);插入对应的相关数据
DELETE FROM user;INSERT INTO user (id, name, age, email) VALUES
(1, 'Jone', 18, 'test1@baomidou.com'),
(2, 'Jack', 20, 'test2@baomidou.com'),
(3, 'Tom', 28, 'test3@baomidou.com'),
(4, 'Sandy', 21, 'test4@baomidou.com'),
(5, 'Billie', 24, 'test5@baomidou.com');2、创建项目
创建一个SpringBoot项目,然后引入相关的依赖,首先是父依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.6</version><relativePath/> <!-- lookup parent from repository --></parent>
具体的其他的依赖
<!-- spring-boot-starter-web 的依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- 引入MyBatisPlus的依赖 --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><!-- 数据库使用MySQL数据库 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!-- 数据库连接池 Druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.14</version></dependency><!-- lombok依赖 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>
3、配置信息
然后我们需要在application.properties中配置数据源的相关信息
spring.datasource.driverClassName=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/mp?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.username=root
spring.datasource.password=123456spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
然后我们需要在SpringBoot项目的启动类上配置Mapper接口的扫描路径

4、添加User实体
添加user的实体类
@ToString
@Data
public class User {private Long id;private String name;private Integer age;private String email;
}
5、创建Mapper接口
在MyBatisPlus中的Mapper接口需要继承BaseMapper.
/*** MyBatisPlus中的Mapper接口继承自BaseMapper*/
public interface UserMapper extends BaseMapper<User> {
}
6、测试操作
然后来完成对User表中数据的查询操作
@SpringBootTest
class MpDemo01ApplicationTests {@Autowiredprivate UserMapper userMapper;@Testvoid queryUser() {List<User> users = userMapper.selectList(null);for (User user : users) {System.out.println(user);}}}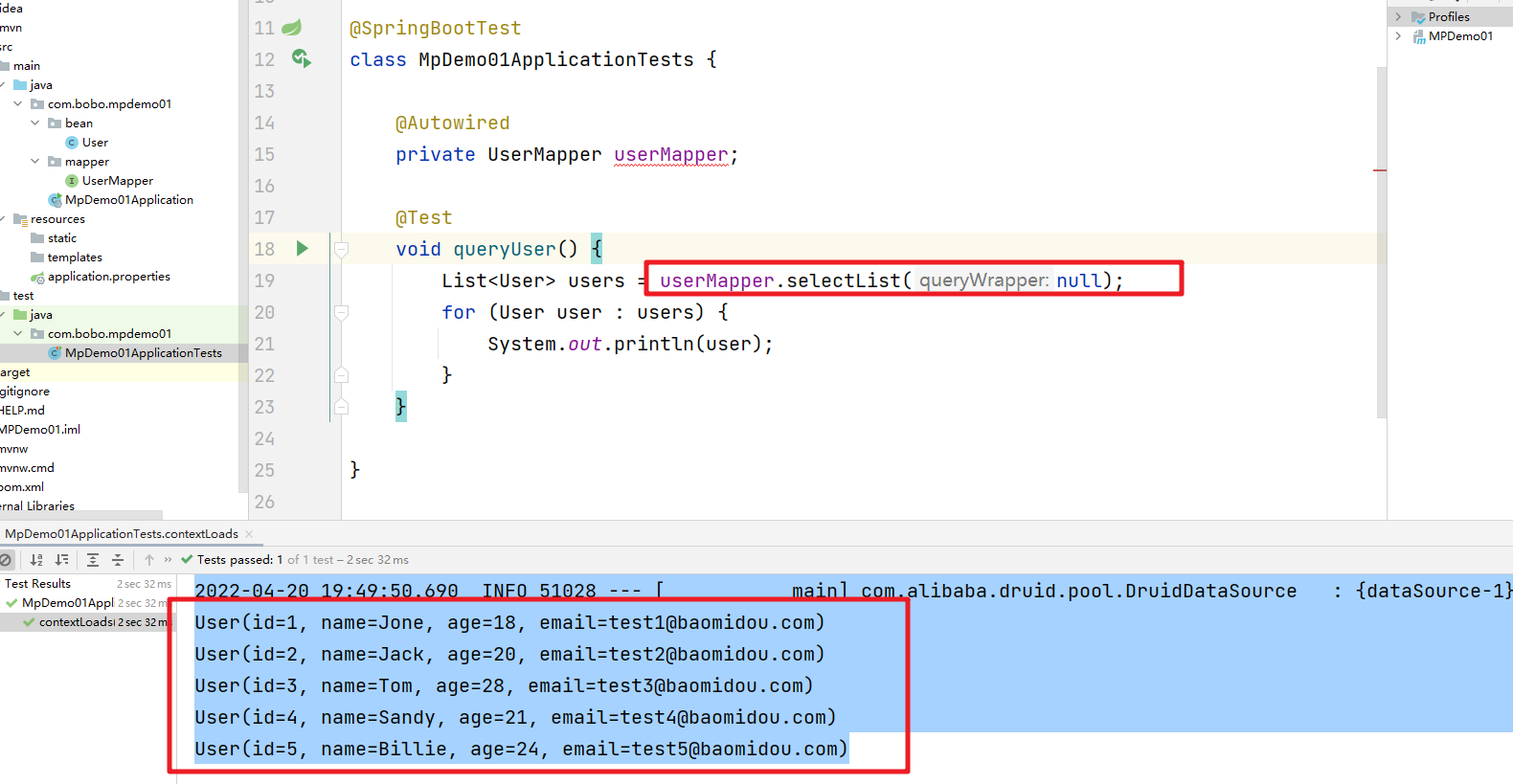
7、日志输出
为了便于学习我们可以指定日志的实现StdOutImpl来处理
# 指定日志输出
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl

然后操作数据库的时候就可以看到对应的日志信息了:
手动两级缓存架构实战
@Configuration
public class CaffeineConfig {@Beanpublic Cache<String,Object> caffeineCache(){return Caffeine.newBuilder().initialCapacity(128)//初始大小.maximumSize(1024)//最大数量.expireAfterWrite(15, TimeUnit.SECONDS)//过期时间 15S.build();}
}
//Caffeine+Redis两级缓存查询public User query1_2(long userId){String key = "user-"+userId;User user = (User) cache.get(key,k -> {//先查询 Redis (2级缓存)Object obj = redisTemplate.opsForValue().get(key);if (Objects.nonNull(obj)) {log.info("get data from redis:"+key);return obj;}// Redis没有则查询 DB(MySQL)User user2 = userMapper.selectById(userId);log.info("get data from database:"+userId);redisTemplate.opsForValue().set(key, user2, 30, TimeUnit.SECONDS);return user2;});return user;}
在 Cache 的 get 方法中,会先从Caffeine缓存中进行查找,如果找到缓存的值那么直接返回。没有的话查找 Redis,Redis 再不命中则查询数据库,最后都同步到Caffeine的缓存中。
通过案例演示也可以达到对应的效果。
另外修改、删除的代码可以看代码案例!
注解方式两级缓存架构实战
在 spring中,提供了 CacheManager 接口和对应的注解
- @Cacheable:根据键从缓存中取值,如果缓存存在,那么获取缓存成功之后,直接返回这个缓存的结果。如果缓存不存在,那么执行方法,并将结果放入缓存中。
- @CachePut:不管之前的键对应的缓存是否存在,都执行方法,并将结果强制放入缓存。
- @CacheEvict:执行完方法后,会移除掉缓存中的数据。
使用注解,就需要配置 spring 中的 CacheManager ,在这个CaffeineConfig类中
@Beanpublic CacheManager cacheManager(){CaffeineCacheManager cacheManager=new CaffeineCacheManager();cacheManager.setCaffeine(Caffeine.newBuilder().initialCapacity(128).maximumSize(1024).expireAfterWrite(15, TimeUnit.SECONDS));return cacheManager;}
EnableCaching
在启动类上再添加上 @EnableCaching 注解

在UserService类对应的方法上添加 @Cacheable 注解
//Caffeine+Redis两级缓存查询-- 使用注解@Cacheable(value = "user", key = "#userId")public User query2_2(long userId){String key = "user-"+userId;//先查询 Redis (2级缓存)Object obj = redisTemplate.opsForValue().get(key);if (Objects.nonNull(obj)) {log.info("get data from redis:"+key);return (User)obj;}// Redis没有则查询 DB(MySQL)User user = userMapper.selectById(userId);log.info("get data from database:"+userId);redisTemplate.opsForValue().set(key, user, 30, TimeUnit.SECONDS);return user;}
然后就可以达到类似的效果。
@Cacheable 注解的属性:
| 参数 | 解释 | col3 |
|---|---|---|
| key | 缓存的key,可以为空,如果指定要按照SpEL表达式编写,如不指定,则按照方法所有参数组合 | @Cacheable(value=”testcache”, key=”#userName”) |
| value | 缓存的名称,在 spring 配置文件中定义,必须指定至少一个 | 例如:@Cacheable(value=”mycache”) |
| condition | 缓存的条件,可以为空,使用 SpEL 编写,返回 true 或者 false,只有为 true 才进行缓存 | @Cacheable(value=”testcache”, condition=”#userName.length()>2”) |
| methodName | 当前方法名 | #root.methodName |
| method | 当前方法 | #root.method.name |
| target | 当前被调用的对象 | #root.target |
| targetClass | 当前被调用的对象的class | #root.targetClass |
| args | 当前方法参数组成的数组 | #root.args[0] |
| caches | 当前被调用的方法使用的Cache | #root.caches[0].name |
这里有一个condition属性指定发生的条件
示例表示只有当userId为偶数时才会进行缓存
//只有当userId为偶数时才会进行缓存@Cacheable(value = "user", key = "#userId", condition="#userId%2==0")public User query2_3(long userId){String key = "user-"+userId;//先查询 Redis (2级缓存)Object obj = redisTemplate.opsForValue().get(key);if (Objects.nonNull(obj)) {log.info("get data from redis:"+key);return (User)obj;}// Redis没有则查询 DB(MySQL)User user = userMapper.selectById(userId);log.info("get data from database:"+userId);redisTemplate.opsForValue().set(key, user, 30, TimeUnit.SECONDS);return user;}
CacheEvict
@CacheEvict是用来标注在需要清除缓存元素的方法或类上的。
当标记在一个类上时表示其中所有的方法的执行都会触发缓存的清除操作。
@CacheEvict可以指定的属性有value、key、condition、allEntries和beforeInvocation。其中value、key和condition的语义与@Cacheable对应的属性类似。即value表示清除操作是发生在哪些Cache上的(对应Cache的名称);key表示需要清除的是哪个key,如未指定则会使用默认策略生成的key;condition表示清除操作发生的条件。下面我们来介绍一下新出现的两个属性allEntries和beforeInvocation。
//清除缓存(所有的元素)@CacheEvict(value="user", key = "#userId",allEntries=true)public void deleteAll(long userId) {System.out.println(userId);}//beforeInvocation=true:在调用该方法之前清除缓存中的指定元素@CacheEvict(value="user", key = "#userId",beforeInvocation=true)public void delete(long userId) {System.out.println(userId);}
自定义注解实现两级缓存架构实战
首先定义一个注解,用于添加在需要操作缓存的方法上:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DoubleCache {String cacheName();String key(); //支持springEl表达式long l2TimeOut() default 120;CacheType type() default CacheType.FULL;
}
l2TimeOut 为可以设置的二级缓存 Redis 的过期时间
CacheType 是一个枚举类型的变量,表示操作缓存的类型
public enum CacheType {FULL, //存取PUT, //只存DELETE //删除
}从前面我们知道,key要支持 springEl 表达式,写一个ElParser的方法,使用表达式解析器解析参数:
public class ElParser {public static String parse(String elString, TreeMap<String,Object> map){elString=String.format("#{%s}",elString);//创建表达式解析器ExpressionParser parser = new SpelExpressionParser();//通过evaluationContext.setVariable可以在上下文中设定变量。EvaluationContext context = new StandardEvaluationContext();map.entrySet().forEach(entry->context.setVariable(entry.getKey(),entry.getValue()));//解析表达式Expression expression = parser.parseExpression(elString, new TemplateParserContext());//使用Expression.getValue()获取表达式的值,这里传入了Evaluation上下文String value = expression.getValue(context, String.class);return value;}
}
package com.msb.caffeine.cache;import com.github.benmanes.caffeine.cache.Cache;
import lombok.AllArgsConstructor;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.data.redis.core.RedisTemplate;import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;import java.lang.reflect.Method;
import java.util.Objects;
import java.util.TreeMap;
import java.util.concurrent.TimeUnit;@Slf4j
@Component
@Aspect
@AllArgsConstructor
public class CacheAspect {private final Cache cache;private final RedisTemplate redisTemplate;@Pointcut("@annotation(com.msb.caffeine.cache.DoubleCache)")public void cacheAspect() {}@Around("cacheAspect()")public Object doAround(ProceedingJoinPoint point) throws Throwable {MethodSignature signature = (MethodSignature) point.getSignature();Method method = signature.getMethod();//拼接解析springEl表达式的mapString[] paramNames = signature.getParameterNames();Object[] args = point.getArgs();TreeMap<String, Object> treeMap = new TreeMap<>();for (int i = 0; i < paramNames.length; i++) {treeMap.put(paramNames[i],args[i]);}DoubleCache annotation = method.getAnnotation(DoubleCache.class);String elResult = ElParser.parse(annotation.key(), treeMap);String realKey = annotation.cacheName() + ":" + elResult;//强制更新if (annotation.type()== CacheType.PUT){Object object = point.proceed();redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);cache.put(realKey, object);return object;}//删除else if (annotation.type()== CacheType.DELETE){redisTemplate.delete(realKey);cache.invalidate(realKey);return point.proceed();}//读写,查询CaffeineObject caffeineCache = cache.getIfPresent(realKey);if (Objects.nonNull(caffeineCache)) {log.info("get data from caffeine");return caffeineCache;}//查询RedisObject redisCache = redisTemplate.opsForValue().get(realKey);if (Objects.nonNull(redisCache)) {log.info("get data from redis");cache.put(realKey, redisCache);return redisCache;}log.info("get data from database");Object object = point.proceed();if (Objects.nonNull(object)){//写入RedisredisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);//写入Caffeinecache.put(realKey, object);}return object;}
}切面中主要做了下面几件工作:
- 通过方法的参数,解析注解中 key 的 springEl 表达式,组装真正缓存的 key。
- 根据操作缓存的类型,分别处理存取、只存、删除缓存操作。
- 删除和强制更新缓存的操作,都需要执行原方法,并进行相应的缓存删除或更新操作。
- 存取操作前,先检查缓存中是否有数据,如果有则直接返回,没有则执行原方法,并将结果存入缓存。
然后使用的话就非常方便了,代码中只保留原有业务代码,再添加上我们自定义的注解就可以了:
@DoubleCache(cacheName = "user", key = "#userId",type = CacheType.FULL)public User query3(Long userId) {User user = userMapper.selectById(userId);return user;}@DoubleCache(cacheName = "user",key = "#user.userId",type = CacheType.PUT)public int update3(User user) {return userMapper.updateById(user);}@DoubleCache(cacheName = "user",key = "#user.userId",type = CacheType.DELETE)public void deleteOrder(User user) {userMapper.deleteById(user);}
两级缓存架构的缓存一致性问题
就是如果一个应用修改了缓存,另外一个应用的caffeine缓存是没有办法感知的,所以这里就会有缓存的一致性问题

解决方案也很简单,就是在Redis中做一个发布和订阅。
遇到修改缓存的处理,需要向对应的频道发布一条消息,然后应用同步监听这条消息,有消息则需要删除本地的Caffeine缓存。
核心代码如下:
相关文章:
Caffeine+Redis两级缓存架构
CaffeineRedis两级缓存架构 在高性能的服务项目中,我们一般会将一些热点数据存储到 Redis这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。 但是在一些场景下单纯使用 Redis 的分布…...

kafka和zookeeper单机部署
安装kafka需要jdk和zookeeper环境,因此先部署单机zk的测试环境。 zookeeper离线安装 下载地址: zookeeper下载地址:Index of /dist/zookeeper 这里下载安装 zookeeper-3.4.6.tar.gz 版本,测试环境单机部署 上传服务器后解压缩 …...

别了,公有云!下云迁移真的是大趋势么?
【科技明说 | 科技热点关注】 不知道你们还有没有印象,早在2022年,IBM发布了《IBM 企业转型指数:云现状》中也反映了这一趋势:80%的企业已经考虑或正在考虑将已经部署到公有云上的工作负载迁回私有的基础设施。 然而&…...
网关在不同行业自动化生产线的应用
网关在不同行业自动化生产线的应用,展示了其作为信息与物理世界交汇点的广泛影响力,尤其在推动行业智能化、自动化方面发挥了不可估量的作用。以下是网关技术在污水处理、智慧农业、智慧工厂、电力改造及自动化控制等领域的深入应用剖析。 1. 污水处理 …...
)
C++ socket编程(1)
这里是一个socket编程Demo,不考虑出错情况,代码简单,便于了解socket流程。 Demo分为服务器程序和客户端程序,运行需要先启动服务器程序,再启动客户端程序。 服务器会等待连接,客户端连接后,服…...

C# 文件夹类的实现与文件属性处理
在现代软件开发中,处理文件和文件夹是非常常见的任务。 C# 提供了丰富的类库来操作这些文件系统的基本元素。本篇文章将探讨如何在 C# 中实现一个简单的文件夹类,以及如何获取文件名、文件路径、大小和创建日期等文件属性。 一、使用 System.IO 命…...

基于SSM框架和Layui的学院课程安排系统的设计与实现(源码+定制+定制)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

【论文笔记】DKTNet: Dual-Key Transformer Network for small object detection
【引用格式】:Xu S, Gu J, Hua Y, et al. Dktnet: dual-key transformer network for small object detection[J]. Neurocomputing, 2023, 525: 29-41. 【网址】:https://cczuyiliu.github.io/pdf/DKTNet%20Dual-Key%20Transformer%20Network%20for%20s…...

设计模式之适配器模式(Adapter)
一、适配器模式介绍 适配器模式(adapter pattern )的原始定义是:将类的接口转换为客户期望的另一个接口, 适配器可以让不兼容的两个类一起协同工作。 适配器模式是用来做适配,它将不兼容的接口转换为可兼容的接口,让原本由于接口…...

[git] github管理项目之环境依赖管理
导出依赖到 requirements.txt pip install pipreqs pipreqs . --encodingutf8 --force但是直接使用pip安装不了torch,需要添加源!! pip install -r requirements.txt -f https://download.pytorch.org/whl/torch_stable.html想到一个麻烦的…...

【STM32 Blue Pill编程实例】-SD卡文件读写(SPI接口)
SD卡文件读写(SPI接口) 文章目录 SD卡文件读写(SPI接口)1、SD卡模块介绍2、硬件准备与接线3、模块配置3.1 SPI接口配置3.2 SPI接口的片选信号引脚配置3.3 FATFS配置4、代码实现在本文中,我们将介绍如何将 microSD 卡与 STM32 Blue Pill 连接,并在STM32CubeIDE中对SD卡进行…...

为什么需要软件测试?
软件测试 软件测试是评估和验证计算机程序或系统是否按预期运行的过程。 它涉及执行程序或系统以识别预期结果和实际结果之间的任何错误或差距。 目标是确保软件满足指定的要求,没有缺陷,并在不同场景中可靠地工作。 为什么需要软件测试?…...

成为超人:普通人如何白手起家,富一代和富二代的根本区别是什么?
成为超人:普通人如何白手起家,富一代和富二代的根本区别是什么? 我的问题是事业就讲 10 年装逼学习法失效① 光说不练,还是太懒真正的勤奋,解决温饱后,只专注赚钱这件事 ② 信念飘摇,随波流转万…...

Java 集合 Collection常考面试题
理解集合体系图 collection中 list 是有序的,set 是无序的 什么是迭代器 主要遍历 Collection 集合中的元素,所有实现了 Collection 的集合类都有一个iterator()方法,可以返回一个 iterator 的迭代器。 ArrayList 和 Vector 的区别? ArrayList 可以存放 null,底层是由数…...

C++继承与菱形继承(一文了解全部继承相关基础知识和面试点!)
目的减少重复代码冗余 Class 子类(派生类) : 继承方式 父类(基类) 继承方式共有三种:公共、保护、私有 父类的私有成员private无论哪种继承方式都不可以被子类使用 保护protected权限的内容在类内是可以访问,但是在…...

谷歌DeepMind 德米斯·哈萨比斯 因蛋白质预测AI荣获诺贝尔化学奖
2024年诺贝尔化学奖的一半授予了谷歌DeepMind的联合创始人兼首席执行官德米斯哈萨比斯和公司总监约翰M朱姆珀,以表彰他们在利用人工智能预测蛋白质结构方面的研究成果。另一半奖项则授予华盛顿大学生物化学教授大卫贝克,以表彰他在计算蛋白质设计领域的贡…...

内网笔记大全
内网笔记大全 1、基础命令 Windows 1、net user #查看用户 2、net view #查看在线主机 3、systeminfo #查看操作系统的基本配置 4、ipconfig /all #详细显示当前网络配置信息和网卡信息 5、net localgroup #查看本地组信息 6、net localgroup administrators #查看管理员组 7、…...
参数说明)
peft.LoraConfig()参数说明
LoraConfig()介绍 LoraConfig()是peft库中的一个配置类,用于设置大模型微调方法LoRA(Low-Rank Adaptation)的相关参数。PEFT 库为各种参数高效的微调方法(如 LoRA)提供了封装,以减少微调大模型时的计算资源…...
的FPGA设计(接收与发送模块))
串口(UART)的FPGA设计(接收与发送模块)
目录 串口基础知识 一、什么是串口?有哪些特点? 二、常见的串口通信协议有哪些?他们有什么区别?...

JSON 格式化工具:快速便捷地格式化和查看 JSON 数据
JSON 格式化工具:快速便捷地格式化和查看 JSON 数据 为什么需要 JSON 格式化工具? 在日常开发和调试中,JSON 是非常常见的数据交换格式。无论是前端与后端的接口调用,还是数据存储和处理,JSON 格式都扮演着重要角色。…...
附Matlab代码)
【数字信号调制】基于8相移键控8-PSK调制数字通信系统(含模拟噪声信道上的信号传输,包括调制、噪声添加、解调以及符号和比特错误率的性能评估)附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室🍊个人信条:格物致知,完整Matlab代码及仿真咨询…...
用户手册:轻松掌握CMS后台管理操作技巧)
白卷(White-Jotter)用户手册:轻松掌握CMS后台管理操作技巧
白卷(White-Jotter)用户手册:轻松掌握CMS后台管理操作技巧 【免费下载链接】White-Jotter 白卷是一款使用 VueSpring Boot 开发的前后端分离项目,附带全套开发教程。(A simple CMS developed by Spring Boot and Vue.js with development tut…...
)
零成本搭建家庭Linux服务器:樱花frp+SSH避坑指南(含端口冲突解决)
零成本搭建家庭Linux服务器:从设备选型到SSH优化全攻略 家里那台吃灰的旧电脑其实是个宝藏——只要稍加改造,就能变身成为你的专属Linux服务器。不需要昂贵的云服务费用,利用闲置硬件和免费内网穿透工具,我们完全可以打造一个稳定…...
:主流BPMN2.0流程设计器横向评测与实战选型指南)
activiti7(三):主流BPMN2.0流程设计器横向评测与实战选型指南
1. 主流BPMN2.0设计器全景概览 在企业级流程自动化领域,选择合适的设计工具直接影响开发效率和维护成本。目前市场上主流的BPMN2.0设计器主要分为三类:IDE插件、独立应用和在线工具。我在实际项目中使用过超过10种设计器,发现每种工具都有其独…...

开源飞行控制器固件开发:从环境诊断到功能验证的完整实践
开源飞行控制器固件开发:从环境诊断到功能验证的完整实践 【免费下载链接】inav INAV: Navigation-enabled flight control software 项目地址: https://gitcode.com/gh_mirrors/in/inav 开源飞行控制器固件开发是无人机技术领域的核心实践,涉及硬…...
)
实验室省钱秘籍:用免费工具替代昂贵分析仪器的3种场景(含质谱数据解读案例)
实验室省钱秘籍:用免费工具替代昂贵分析仪器的3种场景 在科研经费日益紧张的今天,高校实验室和中小企业研发团队常常面临一个现实困境:高端分析仪器动辄数百万的采购成本和维护费用,与有限的预算形成鲜明对比。但鲜为人知的是&…...

JDY-23蓝牙模块:从参数解析到智能家居实战应用
1. JDY-23蓝牙模块核心参数解析 第一次拿到JDY-23蓝牙模块时,我注意到它比想象中更小巧——尺寸只有19.614.941.8mm,差不多相当于一枚硬币大小。但别被它的体积欺骗了,这个模块的性能参数相当亮眼。最让我惊喜的是它的工作电压范围࿰…...

计算机组成原理视角下的AI算力:剖析万象熔炉·丹青幻境的GPU资源利用
计算机组成原理视角下的AI算力:剖析万象熔炉丹青幻境的GPU资源利用 最近在折腾一个挺有意思的AI绘画模型,叫“万象熔炉丹青幻境”。名字听着挺玄乎,其实就是个能根据文字描述生成各种风格图片的模型。玩了几次之后,我发现它生成图…...

Golang实现AI智能体权限最小化与动态沙箱系统
摘要 随着OpenClaw安全危机在2026年3月15日全面爆发——全国23所高校宣布今日为"龙虾清剿日",强制卸载OpenClaw,工信部紧急发布"六要六不要"安全建议——AI智能体权限失控已成为行业级安全隐患。本文基于Golang构建企业级AI智能体动态沙箱系统,实现Linu…...

InstructPix2Pix效果展示集:油画风、复古胶片感,指令生成惊艳作品
InstructPix2Pix效果展示集:油画风、复古胶片感,指令生成惊艳作品 1. 惊艳效果开场:当AI成为你的私人修图师 想象一下这样的场景:你有一张普通的照片,只需要用英语说一句话,比如"把这张照片变成梵高…...