Redis 缓存淘汰策略:LRU 和 LFU 的缺点及解决方案详解
引言
Redis 是一款高性能的内存数据库,它的缓存淘汰机制是保障内存使用效率和应用性能的关键。为了在内存有限的情况下保证缓存数据的有效性,Redis 提供了多种缓存淘汰策略,其中 LRU(Least Recently Used,最近最少使用)和 LFU(Least Frequently Used,最不常使用)是两种非常常见的淘汰算法。然而,这两种算法在实际应用中也存在一定的缺陷。本文将详细分析 Redis 中 LRU 和 LFU 的优缺点,并探讨如何优化这些算法的应用场景。
第一部分:Redis 缓存淘汰机制概述
1.1 Redis 缓存的作用
在高性能分布式系统中,Redis 通常用作缓存层,负责存储经常访问的数据,减少数据库的直接读写压力。当 Redis 作为缓存使用时,由于内存是有限的,因此需要一种机制来决定在内存耗尽时,应该删除哪些数据。这就涉及到缓存淘汰策略的选择。
1.2 Redis 缓存淘汰策略介绍
Redis 提供了多种缓存淘汰策略,其中最常用的包括以下几种:
- noeviction:当内存不足时,直接返回错误,不进行任何数据的淘汰。
- allkeys-lru:淘汰最近最少使用的键(基于 LRU 算法)。
- volatile-lru:只淘汰设置了过期时间的键中最近最少使用的键。
- allkeys-lfu:淘汰最不常使用的键(基于 LFU 算法)。
- volatile-lfu:只淘汰设置了过期时间的键中最不常使用的键。
- allkeys-random:随机淘汰键。
- volatile-random:随机淘汰设置了过期时间的键。
其中,LRU 和 LFU 算法是为了优化缓存命中率,确保最热数据优先留存在内存中,而不常用或较早使用的数据被淘汰。
第二部分:LRU 算法的工作原理与缺点
2.1 LRU 算法简介
LRU 是一种基于时间的淘汰算法。LRU 算法的基本思路是:在内存不足时,淘汰最近最少被访问的缓存项。换句话说,LRU 认为一个数据最近没有被访问,未来也很少会被访问,因此将其淘汰。
LRU 算法的基本步骤:
- 每次访问缓存时,将该项标记为最近使用。
- 当缓存满时,删除最久未使用的缓存项。
Redis 提供了两种方式来实现 LRU:
- 精确 LRU:追踪每个键的访问时间,淘汰真正最少访问的键。
- 抽样 LRU:在内存占用超过设定的最大值时,通过抽样方式从一组键中选择最近最少使用的键来淘汰,减少性能开销。
示例代码:Redis 配置 LRU 策略
# 配置 Redis 使用 allkeys-lru 策略
maxmemory-policy allkeys-lru
maxmemory 100mb
2.2 LRU 算法的缺点
尽管 LRU 是一种经典的缓存淘汰策略,但它在实际应用中存在一些不足:
-
冷数据效应:
LRU 只关注数据的最近使用情况,但如果某个冷门数据在过去短时间内被意外访问了一次,它就可能被标记为"最近使用",从而被留在缓存中。这种冷数据占用内存空间,可能导致热门数据被淘汰,降低缓存命中率。 -
周期性数据访问问题:
如果某些数据是周期性访问的(如每日、每周访问的数据),这些数据可能在某个周期内被淘汰掉,导致下次访问时需要重新加载,增加了不必要的开销。 -
实现复杂度和性能开销:
精确 LRU 需要为每个键记录其最近的访问时间,这在大规模数据存储时会增加额外的内存和 CPU 开销。为了解决这一问题,Redis 通过抽样机制实现近似 LRU,但这可能导致淘汰结果不够精确。
2.3 解决方案:优化 LRU 的替代策略
2.3.1 使用 LFU 替代 LRU
相比 LRU 只关注最近的使用情况,LFU 更关注数据的使用频率。对于那些短时间内被频繁访问的数据,LFU 可以更好地保留它们,避免短期的“冷数据”影响缓存命中率。
2.3.2 LRU 与 TTL 结合
为了解决冷数据长时间占用内存的问题,可以通过设置数据的 TTL(Time To Live)来确保冷数据在一定时间后自动过期。即使数据最近被访问过,如果它的 TTL 到期了,也会被淘汰。
# 结合 LRU 和 TTL
maxmemory-policy volatile-lru
在上述策略中,Redis 只会淘汰那些设置了过期时间的键,从而避免了冷数据长期占用内存。
第三部分:LFU 算法的工作原理与缺点
3.1 LFU 算法简介
LFU(Least Frequently Used)是一种基于使用频率的缓存淘汰算法。LFU 认为使用次数少的数据在未来也不会被频繁使用,因此优先淘汰使用频率最低的数据。
LFU 算法的基本步骤:
- 每次访问缓存时,增加该数据的访问次数计数。
- 当缓存满时,删除使用频率最低的数据项。
Redis 在 4.0 版本之后引入了 LFU 淘汰策略,利用 LFU 机制跟踪每个键的访问频率,并在需要淘汰数据时优先删除访问频率最低的键。
示例代码:Redis 配置 LFU 策略
# 配置 Redis 使用 allkeys-lfu 策略
maxmemory-policy allkeys-lfu
3.2 LFU 算法的缺点
尽管 LFU 解决了 LRU 的一些问题,但它也有自己的不足:
-
数据老化问题:
LFU 过于关注数据的累积访问次数,可能导致某些“历史热门数据”被长期保留,即使它已经很长时间未被访问。由于这些数据的频率值较高,LFU 认为它们是重要的数据,从而不被淘汰。这会导致缓存中充斥着过去热门但当前已经不再需要的数据。 -
频率漂移问题:
如果某些数据在短时间内被大量访问,LFU 会迅速增加它们的访问频率。然而,随着时间的推移,这些数据的访问频率没有自然衰减,可能导致这些数据长期占据缓存空间,影响缓存命中率。 -
实现复杂性:
LFU 需要为每个键维护一个访问频率计数器,而这个计数器本身会占用额外的内存。此外,频率统计的实现和存储逻辑也需要更多的计算资源,尤其是在频繁访问的高并发场景下,可能带来性能开销。
3.3 解决方案:优化 LFU 算法的替代策略
3.3.1 频率衰减机制
为了防止历史数据长期占用缓存,LFU 可以引入频率衰减机制。即根据时间或访问间隔,对缓存数据的访问频率进行衰减,使得过去热门的数据逐渐“冷却”,从而让新的热门数据有机会保留在缓存中。
Redis 提供了 lfu-decay-time 参数,用于控制访问频率的衰减速度。例如,设置 lfu-decay-time = 1 时,每分钟会衰减一次频率值。
# 配置 LFU 的衰减时间
lfu-decay-time 1
3.3.2 LRU + LFU 组合策略
为了解决 LFU 和 LRU 各自的缺点,可以将这两者进行组合。在这种组合策略中,可以首先淘汰那些使用频率较低且最近未被访问的数据,从而保证数据的时效性和频率重要性。
第四部分:LRU 和 LFU 的比较与应用场景
4.1 LRU 与 LFU 的对比
| 特点 | LRU | LFU |
|---|
|
| 关注点 | 最近使用的时间 | 使用频率 |
| 优点 | 简单高效,适合短期频繁访问的数据 | 保留高频使用的数据 |
| 缺点 | 冷数据问题,容易保留短期无用数据 | 频率老化问题,无法及时淘汰过期数据 |
| 适用场景 | 数据访问有时效性,关注最近使用数据 | 数据访问有长期稳定的频率 |
4.2 应用场景
4.2.1 LRU 应用场景
- 短期热点数据:LRU 适合于访问模式呈现明显短期热点的数据场景。例如,社交网络中用户的最新消息、最近使用的文档等。
4.2.2 LFU 应用场景
- 长期热点数据:LFU 适用于那些访问频率较为稳定且长期使用的数据场景。例如,电商系统中的商品推荐、热门商品缓存等场景。
第五部分:Redis 缓存淘汰的实际应用与优化策略
5.1 优化缓存命中率
为提高缓存命中率,除了合理选择淘汰策略外,还可以采取以下措施:
- 缓存预热:在系统启动或高峰期来临前,提前将常用数据加载到缓存中,减少高并发时的缓存穿透和缓存雪崩问题。
- 缓存分层:结合本地缓存与分布式缓存,使用二级缓存架构来降低 Redis 的负载。
- 合理的 TTL 设置:对于缓存中的冷数据,可以通过合理设置过期时间来自动淘汰,从而避免长期占用内存。
5.2 实现缓存淘汰策略的自适应调整
在实际生产环境中,不同的业务场景下,缓存数据的访问模式可能会发生变化。可以通过监控缓存命中率、缓存使用量等指标,动态调整 Redis 的淘汰策略。例如,在短期热点数据较多的情况下,可以选择 LRU 策略;而在长期稳定数据访问量较大的情况下,采用 LFU 策略。
第六部分:总结
Redis 中的 LRU 和 LFU 算法各有优缺点。LRU 适用于访问模式中有短期热点的数据,而 LFU 则更适合那些访问频率较为稳定的长期热点数据。然而,这两种策略在实际使用中都有一定的缺陷。通过结合 TTL、频率衰减、缓存分层等策略,开发者可以有效优化缓存的淘汰机制,提升 Redis 的整体性能。
核心要点回顾:
- LRU 的缺点:容易受到短期冷数据影响,可能导致热点数据被过早淘汰。
- LFU 的缺点:历史热门数据可能长期占用内存,无法及时淘汰。
- 优化策略:通过频率衰减、LRU 与 LFU 结合、动态调整策略等方式解决这些问题。
通过合理选择缓存淘汰策略,并结合实际业务场景,开发者能够更好地利用 Redis 提供的内存管理功能,确保系统的高效稳定运行。
相关文章:

Redis 缓存淘汰策略:LRU 和 LFU 的缺点及解决方案详解
引言 Redis 是一款高性能的内存数据库,它的缓存淘汰机制是保障内存使用效率和应用性能的关键。为了在内存有限的情况下保证缓存数据的有效性,Redis 提供了多种缓存淘汰策略,其中 LRU(Least Recently Used,最近最少使用…...

软件工程pipeline梳理
文章目录 软件工程pipeline梳理为什么需要梳理软件工程的pipeline软件工程pipeline的概念与注意点软件工程pipeline中的最大挑战rethink相关资料 软件工程pipeline梳理 为什么需要梳理软件工程的pipeline 反思自己日常工作中的认知和行为。以算法/软件工程师为代表的技术工种往…...
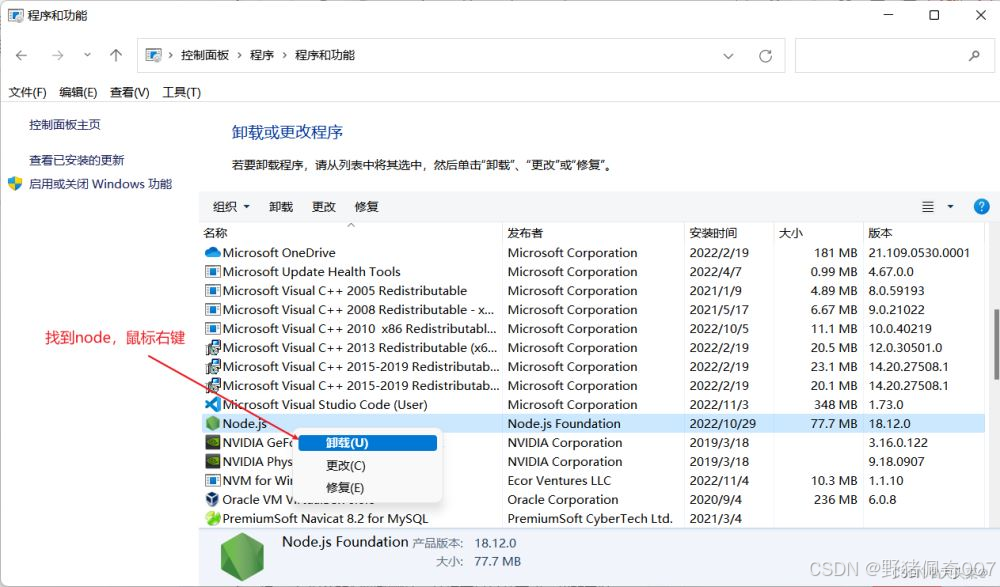
npm运行时出现npm ERR! builtins is not a function报错!
项目场景: 项目运行时什么都没动都没改突然运行不起来了,报错 TypeError: builtins is not a function 代码什么都没动,不是代码问题,排查后只有可能是node和npm的问题,所以卸载掉node重装重启 解决方案: …...
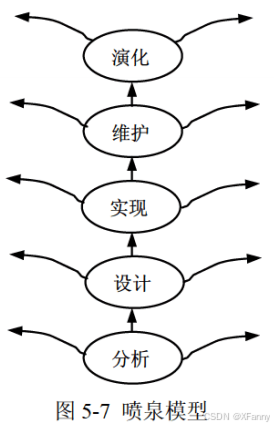
2024年软件设计师中级(软考中级)详细笔记【5】软件工程基础知识上(分值10+)
第5章软件工程 目录 前言第5章 软件工程基础知识(上)(分值10)5.1 软件工程概述5.1.4 软件过程 5.2 软件过程模型5.2.1 瀑布模型 (Waterfall Model)5.2.2 增量模型5.2.3 演化模型5.2.4 喷泉模型(Water Fountain Model&a…...

C++:vector(题目篇)
文章目录 前言一、只出现一次的数字二、只出现一次的数字 II三、只出现一次的数字 III四、杨辉三角五、删除有序数组中的重复项六、数组中出现次数超过一半的数字七、电话号码的字母组合总结 前言 今天我们一起来看vector相关的题目~ 一、只出现一次的数字 只出现一次的数字…...

JS 怎么监听复制事件 并获取复制内容 并修改复制文本内容
需求背景: 需要禁用部分文本内容的复制事件,并且在复制事件发生时,将复制的文本内容通过接口传给后端。 上代码: // 使用Dom获取需要操作禁用时间的元素let element: any document.getElementById(test1);// 为该元素添加 copy 事…...

安卓使用.9图实现阴影效果box-shadow: 0 2px 6px 1px rgba(0,0,0,0.08);
1.安卓实现阴影效果有很多种,一般UX设计会给以H5参数box-shadow: 0 2px 6px 1px rgba(0,0,0,0.08);这种方式提供背景阴影效果,这里记录一下实现过程 2.界面xml源码 <?xml version"1.0" encoding"utf-8"?> <layout xmlns…...

CSS3-Day1
CSS3圆角 border-radius CSS3盒阴影 box-shadow CSS3边界图片 border-image CSS3 background-clip属性 padding-box 沿着边框填充 content-box 在边框外面 CSS3 线性渐变 线性渐变 - 从上到下(默认情况下)#grad { background-image: linear…...

网站集群批量管理-Ansible(ad-hoc)
1. 概述 1. 自动化运维: 批量管理,批量分发,批量执行,维护 2. 无客户端,基于ssh进行管理与维护 2. 环境准备 环境主机ansible10.0.0.7(管理节点)nfs01 10.0.0.31(被管理节点)backup10.0.0.41(被管理节点) 2.1 创建密钥认证 安装sshpass yum install -y sshpass #!/bin/bash ##…...

github学生认证(Github Copilot)
今天想配置一下Github Copilot,认证学生可以免费使用一年,认证过程中因为各种原因折腾了好久,记录一下解决方法供大家参考。 p.s.本文章只针对Github学生认证部分遇到的问题及解决方法,不包括配置copilot的全部流程~ 1、准备工作…...

【SQL调优指南--附带实例】
以下是50个SQL调优的例子,每个例子都附带了可执行的SQL语句: 删除重复记录: DELETE FROM table_name WHERE id NOT IN (SELECT MIN(id) FROM table_name GROUP BY col1, col2);使用索引来加速查询: ALTER TABLE table_name ADD…...

Java基础(下)
泛型 Java 泛型(Generics) 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。 编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型 ArrayList<Person> persons new Arra…...

【python】极简教程1-何为程序
程序可以简单地理解为一系列执行运算的指令。这些运算可以是数学计算、符号运算(如检索或替换文档中的内容)或图形运算(如处理图像或播放视频)。 不同编程语言的基础指令大致相同,包括: 输入:从键盘、文件、网络或其他设备获取数据。输出:将数据显示在屏幕上、保存到文…...
【Transformer】Selective Attention Improves Transformer
这篇论文主要介绍了一种新方法——选择性注意力(Selective Attention),用于改善Transformer模型的性能和效率。 🤓 摘要 无关元素在注意力机制中的存在会降低模型性能。论文提出了一种无需额外参数的简单调整方法,即…...
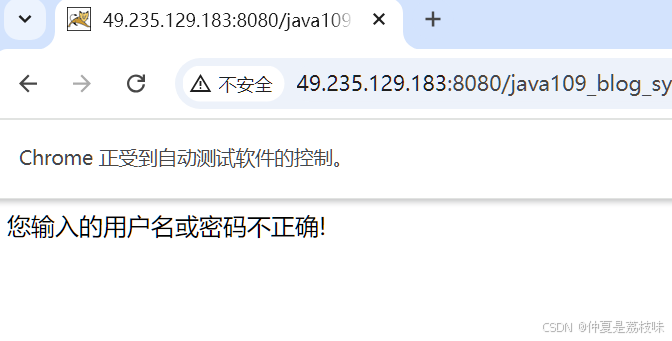
博客项目自动化测试(一)
1. 确认博客系统的环境搭建 http://49.235.129.183:8080/java109_blog_system/blog_list.html,即可访问我的小项目; 2. 确定测试用例 测试用例如下所示: 3. 关于登录的测试用例 3.1 初始化和退出浏览器 代码如下: package Blo…...
商品比价、数据分析、自营商城上货)
电商商品API接口系列(商品详情数据)商品比价、数据分析、自营商城上货
电商商品API接口系列中的商品详情数据接口,在商品比价、数据分析以及自营商城上货等方面发挥着重要作用。以下是对这些应用场景的详细分析: 一、商品详情数据接口概述 商品详情数据接口是电商平台上用于提供商品详细信息的API接口。这些接口允许开发者…...
冒泡排序和选择排序)
排序算法总结(一)冒泡排序和选择排序
访问www.tomcoding.com网站,学习Oracle内部数据结构,详细文档说明,下载Oracle的exp/imp,DUL,logminer,ASM工具的源代码,学习高技术含量的内容。 冒泡排序 这个算法可以说是排序算法中最著名的…...

伺服电动缸
美国EXLAR原装K系列伺服缸 高精度运动,运动平稳,低噪音,高速度 向下翻动查看更多 力姆泰克伺服电动缸 k系列电动缸采用Exlar滚柱丝杠技术,提供多种不同性能等级的产品,可外配第三方电机。 通用型设计,无…...

深度学习中的logit到底是什么?
1. 问题 在做深度学习的过程中,经常会碰到logit。这个和在学校学的概率有出入,因而想弄明白这到底是个什么参数。 2. 使用logit的原因 定义几率(odds)和 logit 函数的主要原因在于使用了线性空间转换,使得非线性的概…...

idea使用记录
文章目录 1、idea调出maven窗口2、跳转到指定行 1、idea调出maven窗口 首先尝试菜单栏View→Tool Windows→Maven,如果没有maven那很有可能是idea没有识别到这是一个maven项目,此时可以尝试在项目的pom文件上右击,选择“add as maven projec…...

TVBoxOSC无线投屏完全指南:多设备协同与电视大屏无缝连接
TVBoxOSC无线投屏完全指南:多设备协同与电视大屏无缝连接 【免费下载链接】TVBoxOSC TVBoxOSC - 一个基于第三方项目的代码库,用于电视盒子的控制和管理。 项目地址: https://gitcode.com/GitHub_Trending/tv/TVBoxOSC 你是否曾遇到过这样的场景&…...

零基础上手小米智能家居集成:3步完成Home Assistant设备联动配置
零基础上手小米智能家居集成:3步完成Home Assistant设备联动配置 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 小米智能家居集成项目(ha_xiao…...

用Unity粒子系统让道具发光!Health Pickup旋转动画全流程拆解
Unity3D道具发光特效实战:Health Pickup旋转动画与粒子系统深度解析 在3D游戏开发中,道具的视觉反馈直接影响玩家的拾取欲望和使用体验。本文将深入讲解如何通过Unity的粒子系统和动画控制器,为Health Pickup道具打造一套"旋转发光"…...

基于单片机的贪吃蛇游戏设计[单片机]-计算机毕业设计源码+LW文档
摘要:本文详细阐述了基于单片机设计贪吃蛇游戏的全过程。通过需求分析明确游戏功能与性能要求,采用AT89C51单片机为核心控制单元,结合LCD12864显示屏、矩阵键盘等硬件设备实现游戏的基本框架。在软件设计方面,利用C语言编写程序&a…...

GLM-4.7-Flash应用场景探索:从内容创作到代码生成,实测效果分享
GLM-4.7-Flash应用场景探索:从内容创作到代码生成,实测效果分享 1. 为什么选择GLM-4.7-Flash? 1.1 新一代MoE架构大模型 GLM-4.7-Flash采用了创新的混合专家架构(MoE),总参数量达到300亿,但在…...

Llama-3.2V-11B-cot保姆级教程:模型权重校验SHA256完整性检查
Llama-3.2V-11B-cot保姆级教程:模型权重校验SHA256完整性检查 1. 为什么需要校验模型权重 在部署Llama-3.2V-11B-cot这类大型多模态模型时,模型权重文件的完整性至关重要。一个损坏或不完整的权重文件可能导致: 模型无法正常加载推理结果异…...

FFMpegCore实战踩坑记:从Windows部署到Linux Docker,我的配置血泪史
FFMpegCore实战踩坑记:从Windows部署到Linux Docker,我的配置血泪史 开发环境里跑得欢,生产环境里泪两行——这大概是我最近用FFMpegCore做音视频处理项目最真实的写照。作为一个.NET开发者,本以为把本地测试通过的代码扔到服务器…...

The Riemannian Geometry of Conceptual Spaces: Behavioral Evidence for Cognitive Manifolds
《认知流形的行为证据:概念空间的黎曼几何结构》 主标题:The Riemannian Geometry of Conceptual Spaces: Behavioral Evidence for Cognitive Manifolds 副标题:A Psychometric and Computational Study 方见华 世毫九实验室 关键词…...

MobaXterm许可证生成工具:实现专业版功能的开源解决方案
MobaXterm许可证生成工具:实现专业版功能的开源解决方案 【免费下载链接】MobaXterm-keygen 项目地址: https://gitcode.com/gh_mirrors/moba/MobaXterm-keygen 在远程计算环境管理领域,MobaXterm Professional Edition以其集成化的终端服务能力…...

3分钟掌握「阅读」APP书源导入:告别小说断更,实现阅读自由!
3分钟掌握「阅读」APP书源导入:告别小说断更,实现阅读自由! 【免费下载链接】Yuedu 📚「阅读」APP 精品书源(网络小说) 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 你是否遇到过这样的情况…...