决策树C4.5算法详解及实现
C4.5决策树是一种广泛使用的机器学习算法,它用于分类任务。它是在ID3算法的基础上改进的,主要通过生成决策树来构建分类模型。C4.5通过以下步骤工作:
1. 数据集分裂
C4.5通过选择具有最高信息增益率的特征来分裂数据集。信息增益率(Gain Ratio)是在决策树构建过程中用于选择最优分裂特征的度量标准。它是基于信息增益进行的改进,旨在解决信息增益偏向于取值较多的属性的问题。具体实现信息增益率需要以下几个步骤:
1. 计算数据集的熵(Entropy)
熵用于衡量数据集的纯度或混乱度。假设数据集 ( S (S (S) 中有 ( n (n (n) 类,那么熵 ( E n t r o p y ( S ) (Entropy(S) (Entropy(S)) 的计算公式为:
E n t r o p y ( S ) = − ∑ i = 1 n p i log 2 ( p i ) Entropy(S) = - \sum_{i=1}^{n} p_i \log_2(p_i) Entropy(S)=−i=1∑npilog2(pi)
其中, ( p i (p_i (pi) 是第 ( i (i (i) 类在数据集 ( S (S (S) 中出现的概率。
熵越高,数据集的混乱度越高;熵越低,数据集越接近纯净。
2. 计算信息增益(Information Gain)
信息增益度量的是某个属性 ( A (A (A) 在分裂数据集 ( S (S (S) 后带来的熵的减少。计算步骤如下:
-
假设属性 ( A (A (A) 有 ( v (v (v) 个不同取值,将数据集 ( S (S (S) 按照 ( A (A (A) 的不同取值划分为 ( v (v (v) 个子集 ( S 1 , S 2 , . . . , S v (S_1, S_2, ..., S_v (S1,S2,...,Sv)。
-
计算划分后数据集的条件熵:
E n t r o p y ( S ∣ A ) = ∑ j = 1 v ∣ S j ∣ ∣ S ∣ E n t r o p y ( S j ) Entropy(S|A) = \sum_{j=1}^{v} \frac{|S_j|}{|S|} Entropy(S_j) Entropy(S∣A)=j=1∑v∣S∣∣Sj∣Entropy(Sj)
其中, ( ∣ S j ∣ (|S_j| (∣Sj∣) 是子集 ( S j (S_j (Sj) 中样本的数量, ( ∣ S ∣ (|S| (∣S∣) 是原始数据集的样本数量。 -
计算信息增益:
G a i n ( S , A ) = E n t r o p y ( S ) − E n t r o p y ( S ∣ A ) Gain(S, A) = Entropy(S) - Entropy(S|A) Gain(S,A)=Entropy(S)−Entropy(S∣A)
信息增益表示属性 ( A (A (A) 划分数据集后带来的熵的减少。信息增益越大,意味着通过该属性的划分能让数据集变得更加纯净。
3. 计算分裂信息(Split Information)
分裂信息衡量的是属性 ( A (A (A) 划分数据集的固有不确定性。它的计算公式为:
S p l i t I n f o ( A ) = − ∑ j = 1 v ∣ S j ∣ ∣ S ∣ log 2 ( ∣ S j ∣ ∣ S ∣ ) SplitInfo(A) = - \sum_{j=1}^{v} \frac{|S_j|}{|S|} \log_2\left(\frac{|S_j|}{|S|}\right) SplitInfo(A)=−j=1∑v∣S∣∣Sj∣log2(∣S∣∣Sj∣)
分裂信息越大,表示属性 ( A (A (A) 的取值越多,数据集的划分越细致。
4. 计算信息增益率(Gain Ratio)
信息增益率是在信息增益的基础上,除以分裂信息来防止属性值过多的偏倚。公式为:
G a i n R a t i o ( A ) = G a i n ( S , A ) S p l i t I n f o ( A ) Gain\ Ratio(A) = \frac{Gain(S, A)}{SplitInfo(A)} Gain Ratio(A)=SplitInfo(A)Gain(S,A)
信息增益率通过对信息增益进行归一化,避免选择取值较多的属性(如ID号、日期等)导致的偏倚。最终,在构建决策树时,选择信息增益率最高的属性作为最优分裂属性。
5. 选择最优特征
在所有候选特征中,计算每个特征的信息增益率,并选择具有最大信息增益率的特征进行数据集划分。
例子:
假设我们有一个小数据集 ( S (S (S) ,包含水果分类问题,属性 ( A (A (A) 可能是水果的颜色,取值为红色、绿色、黄色等。在计算信息增益时,属性颜色可能划分出多个子集(红色的水果、绿色的水果等),然后通过计算该划分带来的熵减少量得到信息增益。最终,通过计算分裂信息,得到信息增益率。这个过程会在所有候选属性上执行,从而选择最佳分裂特征。
特点
1. 处理连续属性
C4.5可以处理连续属性。它通过计算属性的多个分裂点并找到能带来最大信息增益率的分裂点来处理数值型数据。例如,它可以把数值型属性转换为“< 某个阈值”和“>= 某个阈值”的二元划分。
2. 处理缺失值
C4.5能够处理数据集中存在缺失值的情况。它通过估算该特征对分类的贡献进行处理,而不是简单地删除缺失数据。
3. 剪枝(Pruning)
决策树的一个问题是容易过拟合。C4.5通过后剪枝方法来减少树的复杂性,从而提高泛化能力。剪枝通过在构建树后删除那些对分类贡献较小的分支来实现。
总结
C4.5通过使用信息增益率来选择最优的分裂特征,能够处理连续值和缺失值,并通过后剪枝来防止过拟合。这使得它比ID3更加灵活和实用,尤其在复杂的实际应用中。
全部代码
import numpy as np
from collections import Counter
from TreeDisp import visualize_tree# 计算熵
def entropy(y):counts = np.bincount(y)probabilities = counts / len(y)return -np.sum([p * np.log2(p) for p in probabilities if p > 0])# 根据特征值划分数据集
def split_dataset(X, y, feature_index, threshold):left_indices = X[:, feature_index] <= thresholdright_indices = X[:, feature_index] > thresholdreturn X[left_indices], X[right_indices], y[left_indices], y[right_indices]# 计算信息增益
def information_gain(y, y_left, y_right):p_left = len(y_left) / len(y)p_right = len(y_right) / len(y)return entropy(y) - (p_left * entropy(y_left) + p_right * entropy(y_right))#计算分裂信息
def Split_Information(y, y_left, y_right):p_left = len(y_left) / len(y)p_right = len(y_right) / len(y)return - (p_left * np.log2(p_left) + p_right * np.log2(p_right))def Gain_Ratio(y, y_left, y_right):return information_gain(y, y_left, y_right)/Split_Information(y, y_left, y_right)# 选择最佳分裂点
def best_split(X, y):best_gain_ratio = -1best_feature_index = 0best_threshold = 0n_features = X.shape[1]for feature_index in range(n_features):thresholds = np.unique(X[:, feature_index])for threshold in thresholds:X_left, X_right, y_left, y_right = split_dataset(X, y, feature_index, threshold)if len(y_left) == 0 or len(y_right) == 0:continuegain_ratio = Gain_Ratio(y, y_left, y_right)if gain_ratio > best_gain_ratio:best_gain_ratio = gain_ratiobest_feature_index = feature_indexbest_threshold = thresholdreturn best_feature_index, best_threshold# 构建决策树节点
class Node:def __init__(self, feature_index=None, threshold=None, left=None, right=None, value=None):self.feature_index = feature_index # 用于分裂的特征索引self.threshold = threshold # 分裂点self.left = left # 左子树self.right = right # 右子树self.value = value # 叶节点的值(类标签)# 递归构建决策树
def build_tree(X, y, depth=0, max_depth=10):n_samples, n_features = X.shapen_labels = len(np.unique(y))# 停止条件:数据纯度高或达到最大深度if n_labels == 1 or depth == max_depth:leaf_value = Counter(y).most_common(1)[0][0]return Node(value=leaf_value)# 找到最佳分裂点feature_index, threshold = best_split(X, y)# 分裂数据集X_left, X_right, y_left, y_right = split_dataset(X, y, feature_index, threshold)# 构建左、右子树left_subtree = build_tree(X_left, y_left, depth + 1, max_depth)right_subtree = build_tree(X_right, y_right, depth + 1, max_depth)return Node(feature_index, threshold, left_subtree, right_subtree)# 预测新样本
def predict(sample, tree):if tree.value is not None:return tree.valuefeature_value = sample[tree.feature_index]if feature_value <= tree.threshold:return predict(sample, tree.left)else:return predict(sample, tree.right)# 使用决策树模型进行训练和预测
def decision_tree_classifier(X_train, y_train, X_test, max_depth=10):tree = build_tree(X_train, y_train, max_depth=max_depth)dot_tree = visualize_tree(tree, iris.feature_names)dot_tree.render('iris_tree_1', format='png', cleanup=True) # 将图保存为 PNG 文件predictions = [predict(sample, tree) for sample in X_test]return np.array(predictions)# 测试手动实现的决策树
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 使用手动实现的决策树进行训练和预测
y_pred = decision_tree_classifier(X_train, y_train, X_test, max_depth=5)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy * 100:.2f}%')相关文章:

决策树C4.5算法详解及实现
C4.5决策树是一种广泛使用的机器学习算法,它用于分类任务。它是在ID3算法的基础上改进的,主要通过生成决策树来构建分类模型。C4.5通过以下步骤工作: 1. 数据集分裂 C4.5通过选择具有最高信息增益率的特征来分裂数据集。信息增益率…...

prompt learning
prompt learning 对于CLIP(如上图所示)而言,对其prompt构造的更改就是在zero shot应用到下游任务的时候对其输入的label text进行一定的更改,比如将“A photo of a{obj}”改为“[V1][V2]…[Vn][Class]”这样可学习的V1-Vn的token…...

适用于 Windows 11 的 5 大数据恢复软件 [免费和付费]
为什么我们需要Windows 11数据恢复软件? 计算机用户经常遇到的一件事就是数据丢失,这种情况随时可能发生。错误地删除重要文件和文件夹可能会非常令人担忧,但幸运的是,有一种方法可以恢复 PC 上丢失的数据。本文将向您展示可用于…...

vue实现获取当前时间并实时显示
以下代码可以实现获取当前时间并实时显示,朋友们直接copy使用即可,希望可以帮助到有需要的朋友们! <template><div class"time">{{ datetimeStr }}</div> </template> <script>export default {data…...
【论文阅读】SRCNN
学习资料 论文题目:Learning a Deep Convolutional Network for Image Super-Resolution(学习深度卷积网络用于图像超分辨率)论文地址:link.springer.com/content/pdf/10.1007/978-3-319-10593-2_13.pdf代码:作者提出的…...

数据结构与算法——Java实现 32.堆
目录 堆 大顶堆 威廉姆斯建堆算法 Floyd建堆算法 Floyd建堆算法复杂度 大顶堆代码实现 人的想法和感受是会随着时间的认知改变而改变, 原来你笃定不会变的事,也会在最后一刻变得释然 —— 24.10.10 堆 堆是基于二叉树实现的数据结构 大顶堆任意一个父节…...
)
深度学习 .dot()
在 MXNet 中,.dot() 是用于计算两个数组的点积(矩阵乘法)的方法。这个方法适用于一维和二维数组,并返回它们的点积结果。 语法 ndarray1.dot(ndarray2) 参数 ndarray1: 第一个输入数组。ndarray2: 第二个输入数组,…...
idea2024 git merge 时丢失 Merge remote-tracking branch问题
idea2024 git merge 时丢失 Merge remote-tracking branch问题 处理建议 直接修改本地git的配置 git config --global merge.ff false 分析 在 IntelliJ IDEA 中进行 Git merge 操作时,有时你可能会遇到提交历史中丢失 Merge remote-tracking branch 的信息&#…...
pdf怎么删除多余不想要的页面?删除pdf多余页面的多个方法
pdf怎么删除多余不想要的页面?在日常办公或学习中,我们经常会遇到需要处理PDF文件的情况。PDF文件因其格式稳定、不易被篡改的特点而广受青睐,但在编辑方面却相对不如Word等文档灵活。有时,在接收或创建的PDF文件中,可…...

树莓派应用--AI项目实战篇来啦-3.OpenCV 读取写入和显示图像
1. 介绍 在计算机视觉和图像处理领域,读取和显示图像是最基础且常见的操作之一,OpenCV作为一个强大的计算机视觉库,提供了丰富的功能来处理图像数据。 读取、显示和写入图像是图像处理和计算机视觉的基础,即使裁剪、调整大…...

一句话就把HTTPS工作原理讲明白了
号主:老杨丨11年资深网络工程师,更多网工提升干货,请关注公众号:网络工程师俱乐部 上午好,我的网工朋友。 在当今互联网高度发达的时代,信息安全已成为不容忽视的重要议题。 随着越来越多的个人信息和敏感…...
中间有3个缓存)
CPU 和处理核心(Core)中间有3个缓存
一、CPU 和处理核心(Core)的关系 CPU和处理核心之间的关系是整体与部分的关系。随着多核技术的发展,现代CPU通过包含多个处理核心来提高其并行处理能力和整体性能,同时在核心之间实现资源的有效共享和独立使用。这种架构的进步使…...
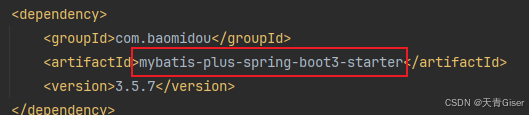
前后分离项目记录
一.前端设置 1.打包问题 打包报错 Thread Loader时,增加以下代码: 2.上线时api设置 二.Nginx问题 1.缓存问题:添加如下代码以禁止缓存,否则在关闭nginx后仍然可以访问页面 2.跨域问题在后端加CrossOrigin注解即可 3.上线时co…...

一句话木马的多种变形方式
今天来和大家聊一聊,一句话木马的多种变形方式。 经常有客户的网站碰到被上传小马和大马,这里的“马”是木马的意思,可不是真实的马。 通常,攻击者利用文件上传漏洞,上传一个可执行并且能被解析的脚本文件,…...
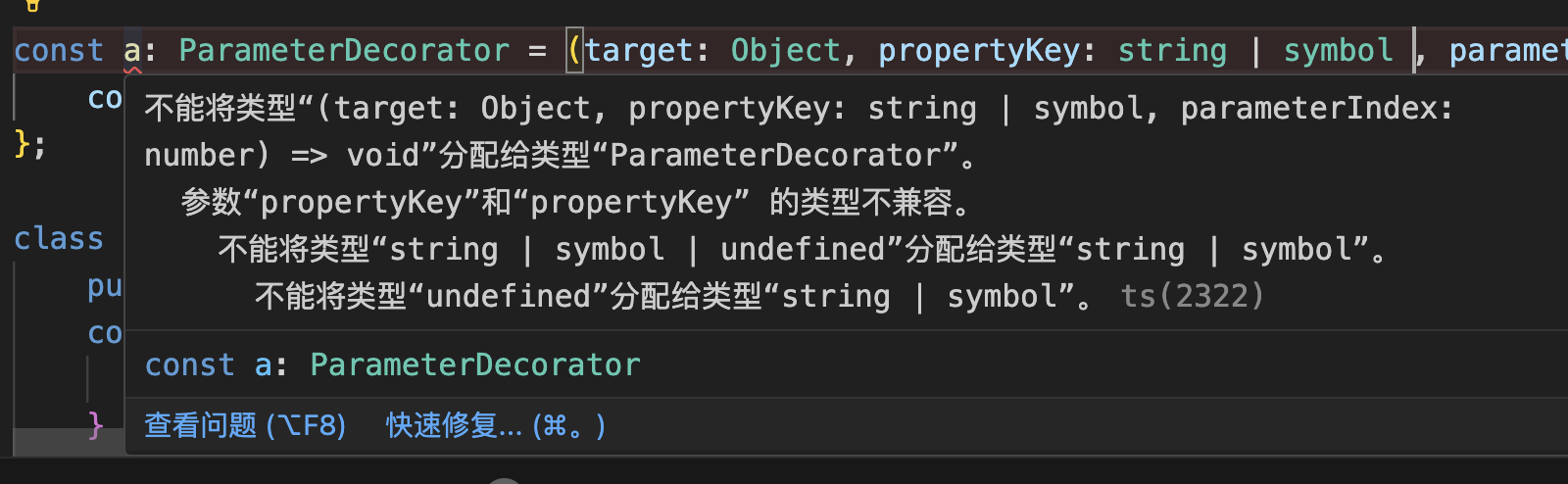
【NestJS入门到精通】装饰器
目录 方法装饰器通过prototype添加属性、方法 属性装饰器拓展 方法装饰器参数装饰器 方法装饰器 ClassDecorator 定义了一个类装饰器 a,并将其应用于类 A。装饰器 a 会在类 A 被定义时执行。 const a:ClassDecorator (target:any)>{console.log(target,targe…...
XML 编辑最简单好用的 QXmlEdit 软件已经完整中文化
XML 编辑最简单好用的 QXmlEdit 软件已经完整中文化 简介一、软件界面二、安装下载2.1 QXmlEdit 官方网站下载2.2 QXmlEdit 源代码下载2.3 QXmlEdit 软件中文版下载 三、QXmlEdit 编辑 ADCP 测量项目的 MMT 文件3.1 应用 XML 文件缩进3.2 使用 QXmlEdit 缩进编辑保存后…...

ref标签、style的scope
ref标签 作用:用于注册模板引用。 用在普通DOM标签上,获取的是DOM节点。用在组件标签上,获取的是组件实例对象。 DOM: <template><div class"person"><h2 ref"title2">上海</h2>&l…...

22年408数据结构
第一题: 解析: 观察一下这个程序:我们注意到最外层的循环是从i1开始的,每次ii*2,直到i<n为止,假设程序总共执行k次执行,则有2^(k1)>n。则k1>log(2)n这里是以2为底n的对数, k>log(2)…...
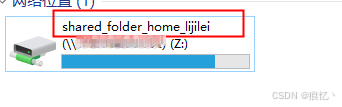
ubuntu 虚拟机将linux文件夹映射为windows网络位置
在使用虚拟机时可以选择将windows的文件夹设置为共享文件夹方便在虚拟机中访问windows中的文件,同理,也可以将linux的文件夹共享为一个网络文件夹,通过windows的添加一个网络位置功能,将linux的文件夹映射到windows本地,方便windows访问使用linux的文件夹 参照如下:https://blo…...

Pytho逻辑回归算法:面向对象的实现与案例详解
这里写目录标题 Python逻辑回归算法:面向对象的实现与案例详解引言一、逻辑回归算法简介1.1 损失函数1.2 梯度下降 二、面向对象的逻辑回归实现2.1 类的设计2.2 Python代码实现2.3 代码详解 三、逻辑回归案例分析3.1 案例一:简单二分类问题问题描述数据代…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...