12 循环神经网络(基础篇) Basic RNN
文章目录
- 问题引入
- 关于权重
- 权重共享
- RNN Cell
- RNN原理
- RNN计算过程
- 代码实现
- RNN Cell
- 维度说明
- 代码
- RNN
- 维度说明
- NumLayers
- 说明
- 计算过程
- 代码
- 参考实例
- 问题分析
- 多分类问题
- 代码
- RNN Cell
- RNN
- 改进
- Embedding
- 网络结构
- Embedding说明
- Linear说明
- 代码
课程来源: 链接
课程文本参考:Birandaの
问题引入
在前篇中所提到的线性网络,大致上都是稠密网络(DNN)这种网络的输入大多是样本的多维度的特征,以此来得到一个想要的输出。
显然,面对序列问题,即处理视频流、预测天气、自然语言等等问题时,此时输入的x1⋯xnx_1 \cdots x_nx1⋯xn实际上是一组有序列性即存在前后关系的样本。每个xix_ixi为一个样本的所包含的特征元组。
针对这样的问题,我们也会想到利用线性的全连接网络来进行处理,但事实上,全连接网络所需要计算的权重太多,并不能够解决问题。
关于权重
对于一张128通道的图片,若想要利用5×55 \times 55×5的卷积核将它转换成一张64通道的图片,则需要计算的权重有大约20W个
128×52×64=204800128 \times 5^2 \times 64 = 204800 128×52×64=204800
即卷积层的权重数目只与通道数以及卷积核大小有关,但全连接层的权重数与转成一维向量以后的整个数据量有关
若转为一维向量以后,输入为4096个元素,输出为1024个元素,则需要计算的权重大约有400W个
4096×1024=41943044096 \times 1024 = 4194304 4096×1024=4194304
显然,全连接层所需要计算的权重远多于卷积层
权重共享
给定一张输入图片,用一个固定大小的卷积核去对图片进行处理,卷积核内的参数即为权重,而卷积核是对输入图片进行步长为stride的扫描计算,也就是说原图中的每一个像素都会参与到卷积计算中,因此,对于整个卷积核而言,权重都是一样的,即共享。
权重共享,实际上是计划通过将输入图片的一个局部特征映射成输出图片的一个像素点而发挥作用的,也就是通过卷积核,使得输出层的每一个像素只与输入层一个局部的方块相连接,这就避免了在全连接情形下的,输出层的每个像素都在或多或少的被输入层的任意一个像素影响这一复杂的情况。
另外,图像信息的特征:图片底层特征与特征在图片中的位置无关,也是权重共享的一个依据。例如对于图像的边缘特征,无论边缘处在图像的什么位置,都是以同样的方法定义,作为同样的特征进行区别的。
因此,为了能够较好地解决序列问题,也要利用到权重共享的思路方法,来减少在计算过程中所需要的权重。因此产生了RNN
RNN Cell
RNN原理
| 模块名称 | 作用 |
|---|---|
| xtx_txt | 表时刻ttt时的输入数据 |
| RNN Cell | 本质上是一个线性层 |
| hth_tht | 表时刻ttt时得到的输出(隐含层) |
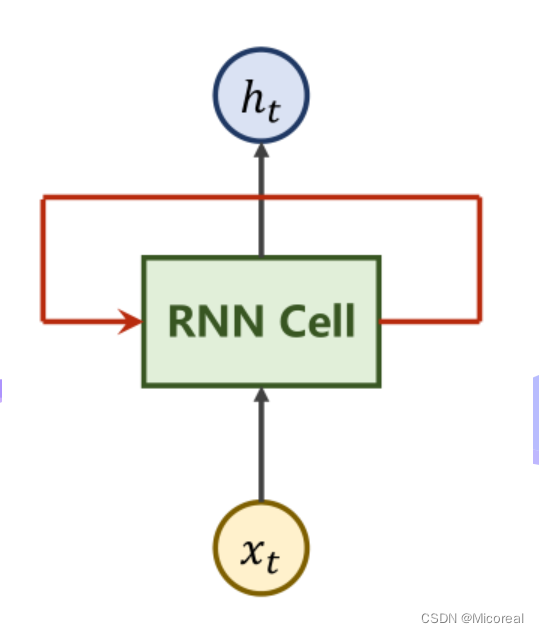
本质上,RNN Cell为一个线性层Linear,在ttt时刻下的NNN维向量,经过Cell后即可变为一个MMM维的向量hth_tht,而与其他线性层不同,RNN Cell为一个共享的线性层。即重复利用,权重共享。将上图展开来看如下。
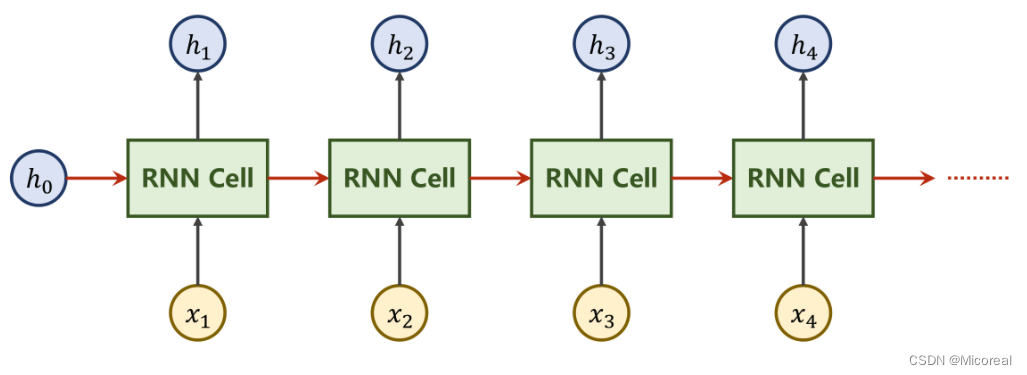
由于x1⋯xnx_1 \cdots x_nx1⋯xn,为一组序列信息,每一个xix_ixi都至少应包含xi−1x_{i-1}xi−1的信息。也就是说,针对x2x_2x2的操作所得到的h2h_2h2中,应当包含x1x_1x1的信息,因此在设计中,把x1x_1x1处理后得到的h1h_1h1一并向下传递。
上图中的h0h_0h0是一种前置信息。例如若实现图像到文本的转换,可以利用CNN+FC对图像进行操作,再将输出的向量作为h0h_0h0参与到RNN的运算中。
若没有可获知的前置信息,可将h0h_0h0设置为与xix_ixi同维度的零向量。
图中的RNN Cell为同一个Linear,即让设计好的Linear反复参与运算,实现权重共享。
RNN计算过程
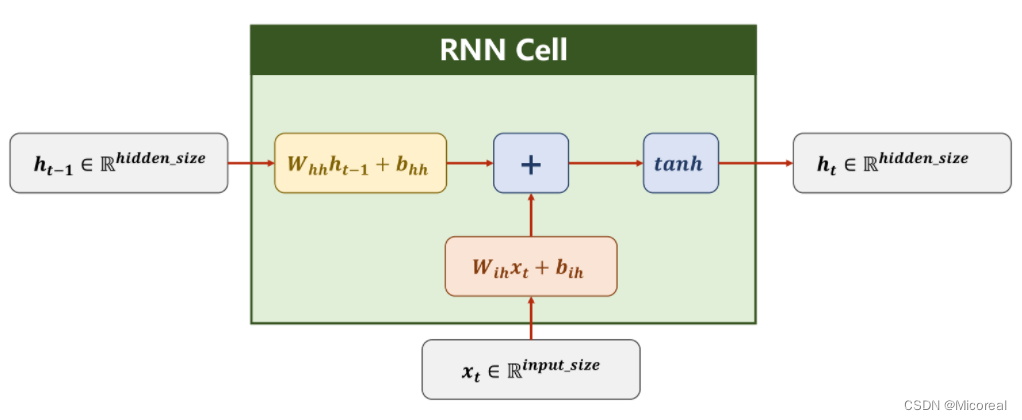
对上图中的符号做出解释如下
| 符号 | 标注 |
|---|---|
| hth_ththt−1h_{t-1}ht−1 | 隐藏层hidden的结果向量 |
| xtx_txt | 输入层的输入向量 |
| Rhidden_sizeR ^{hidden\_size}Rhidden_size | 表隐藏层的向量维度 |
| Rinput_sizeR^{input\_size}Rinput_size | 表输入层的向量维度 |
| WihW_{ih}Wih | 用于计算输入的权重,维度大小为hidden_size×input_sizehidden\_size \times input\_sizehidden_size×input_size |
| bihb_{ih}bih | 用于计算输入时的偏置量 |
| WhhW_{hh}Whh | 用于计算隐藏层的权重,维度大小为hidden_size×hidden_sizehidden\_size \times hidden\_sizehidden_size×hidden_size |
| bhhb_{hh}bhh | 用于计算隐藏层时的偏置量 |
| tanh | 激活函数,值域为(−1,+1)(-1, +1)(−1,+1) |
| + | 求和模块 |
在RNN计算过程中,分别对输入xtx_txt以及前文的隐藏层输出ht−1h_{t-1}ht−1进行线性计算,再进行求和,对所得到的一维向量,利用tanh激活函数进行激活,由此可以得到当前隐藏层的输出hth_tht,其计算过程如下:
ht=tanh(Wihxt+bih+Whhht−1+bhh)h_t = tanh(W_{ih}x_t + b_{ih} + W_{hh}h_{t-1} + b_{hh}) ht=tanh(Wihxt+bih+Whhht−1+bhh)
实际上,在框中的RNN Cell,的计算过程中为线性计算。
Whhht−1+Wihxt=[WhhWih][hx]W_{hh}h_{t-1}+W_{ih}x_{t} = \begin{bmatrix} {W_{hh}}&{W_{ih}} \end{bmatrix} \begin{bmatrix} h\\ x \end{bmatrix} Whhht−1+Wihxt=[WhhWih][hx]
即在实际运算的过程中,这两部分是拼接到一起形成矩阵再计算求和的,最终形成一个大小为hidden_size×1hidden\_size \times 1hidden_size×1的张量。
代码实现
代码实现有两种模式,一是实现自己的RNN Cell,再自己重写循环调用等逻辑。二是直接调用RNN的网络。
重点在于控制其输入输出的维度。
RNN Cell
#输入维度input_size,隐藏层维度hidden_size
cell = torch.nn.RNNCell(input_size = input_size, hidden_size = hidden_size)#输入的input 的维度(B*input_size), hidden的维度(B*hidden_size)
#输出的hidden维度(B*hidden_szie)
hidden = cell(input, hidden)
维度说明
为说明输入输出维度大小,假定当前有如下配置的数据
| 参数 | 值 | 说明 |
|---|---|---|
| BatchSize | 1 | 批量大小 |
| SeqLen | 3 | 样本数目x1x_1x1x2x_2x2x3x_3x3 |
| InputSize | 4 | 输入维度 |
| HiddenSize | 2 | 隐藏层(输出)维度 |
对于RNN Cell而言在hidden = cell(input, hidden)中
| 参数 | 值 | 说明 |
|---|---|---|
| input | ([1, 4]) | input.shape=(batch_size,input_size)input.shape = (batch\_size, input\_size)input.shape=(batch_size,input_size) |
| hidden | ([1, 2]) | output.shape=(batch_size,hidden_size)output.shape = (batch\_size, hidden\_size)output.shape=(batch_size,hidden_size) |
而整个数据集的维度应为
dataset.shape=(seqLen,batch_size,input_size)dataset.shape = (seqLen, batch\_size, input\_size) dataset.shape=(seqLen,batch_size,input_size)
代码
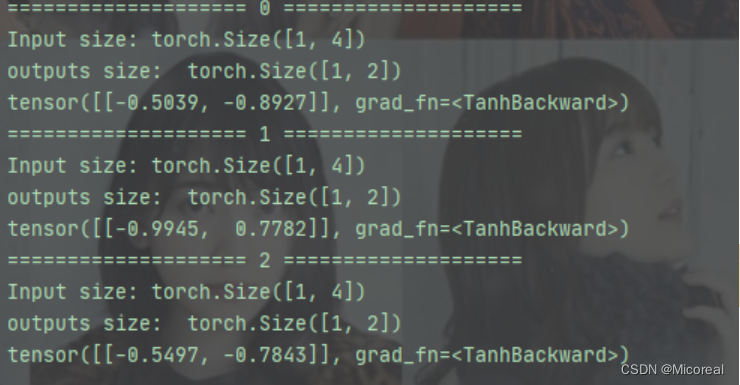
import torchbatch_size = 1
seq_len = 3
input_size = 4
hidden_size =2cell = torch.nn.RNNCell(input_size = input_size, hidden_size = hidden_size)
#维度最重要
dataset = torch.randn(seq_len,batch_size,input_size)
#初始化时设为零向量
hidden = torch.zeros(batch_size, hidden_size)for idx,input in enumerate(dataset):print('=' * 20,idx,'=' * 20)print('Input size:', input.shape)hidden = cell(input, hidden)print('outputs size: ', hidden.shape)print(hidden)
RNN
#说明input维度,hidden维度,以及RNN层数
#RNN计算耗时大,不建议层数过深
cell = torch.nn.RNN(input_size = input_size, hidden_size = hidden_size, num_layers = num_layers)#inputs指的是X1……Xn的整个输入序列
#hidden指的是前置条件H0
#out指的是每一次迭代的H1……Hn隐藏层序列
#hidden_out指的是最后一次迭代得到输出Hn
out, hidden_out = cell(inputs, hidden)
维度说明
为说明输入输出维度大小,假定当前有如下配置的数据
| 参数 | 值 | 说明 |
|---|---|---|
| BatchSize | 1 | 批量大小 |
| SeqLen | 5 | 样本数目x1x_1x1x2x_2x2x3x_3x3x4x_4x4x5x_5x5 |
| InputSize | 4 | 输入维度 |
| HiddenSize | 2 | 隐藏层(输出)维度 |
| numLayers | 3 | RNN层数 |
对于RNN而言,在out, hidden_out = cell(inputs, hidden)
| 参数 | 值 | 说明 |
|---|---|---|
| input | ([5, 1, 4]) | input.shape=(seqLen,batch_size,input_size)input.shape = (seqLen, batch\_size, input\_size)input.shape=(seqLen,batch_size,input_size) |
| hidden | ([3, 1, 2]) | hidden.shape=(numLayers,batch_size,hidden_size)hidden.shape = (numLayers, batch\_size,hidden\_size)hidden.shape=(numLayers,batch_size,hidden_size) |
| out | ([5, 1, 2]) | out.shape=(seqLen,batch_size,hidden_size)out.shape = (seqLen, batch\_size,hidden\_size)out.shape=(seqLen,batch_size,hidden_size) |
| hidden_out | ([3, 1, 2]) | hidden_out.shape=(numLayers,batch_size,hidden_size)hidden\_out.shape = (numLayers, batch\_size,hidden\_size)hidden_out.shape=(numLayers,batch_size,hidden_size) |
NumLayers
说明
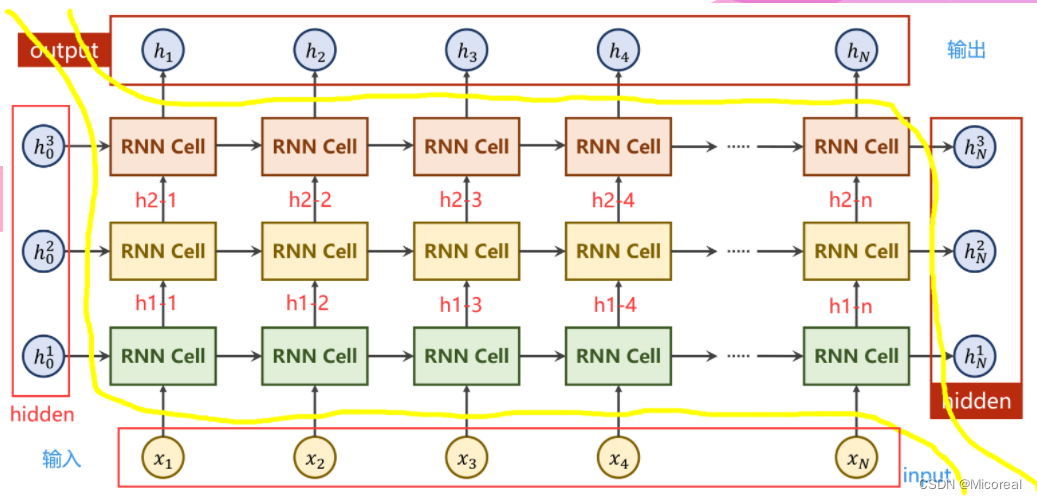
其中,左侧及下侧为输入部分,右侧及上侧为输出部分。
左侧是每一层RNN的前置条件,下侧为输入序列。右侧为每一层的隐藏层最终输出,上侧为隐藏层输出序列。
计算过程
在输入序列中的第jjj个样本经过第iii层RNN Cell计算过后,所产生的隐藏层输出记为hjih^i_jhji,该输出分别向更深层的Cell即i+1i+1i+1层RNN Cell,以及更靠后的序列即第j+1j+1j+1个样本进行传递。
若iii为最后一层,则作为该样本的最终结果out_put输出。否则将继续向第i+1i+1i+1层RNN传递。
若jjj为序列中最后一个样本,则作为本层RNN的隐藏层最终结果hidden_out输出。否则将继续向第j+1j+1j+1个样本传递。
图示是一张展开图,实际上,每一层的RNN Cell是同一个网络,以此来实现权重共享。
代码
import torchbatch_size = 1
seq_len = 5
input_size = 4
hidden_size =2
num_layers = 3
#其他参数
#batch_first=True 维度从(SeqLen*Batch*input_size)变为(Batch*SeqLen*input_size)
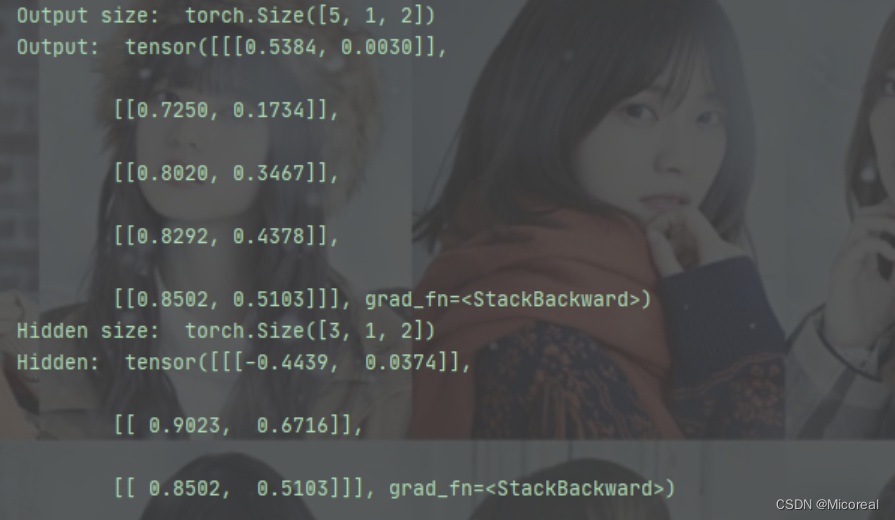
cell = torch.nn.RNN(input_size = input_size, hidden_size = hidden_size, num_layers = num_layers)inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)out, hidden = cell(inputs, hidden)print("Output size: ", out.shape)
print("Output: ", out)
print("Hidden size: ", hidden.shape)
print("Hidden: ", hidden)
输出结果:
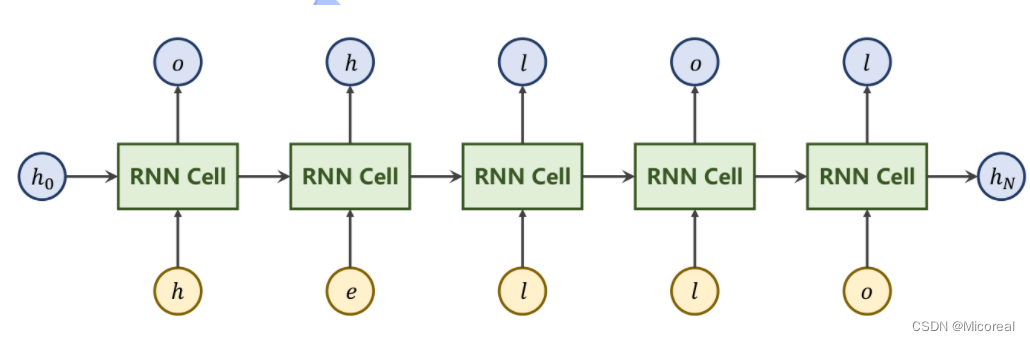
参考实例
假定现在有一个序列到序列(seq→seq)(seq \to seq)(seq→seq)的任务,比如将“hello”转换为“ohlol”。
即利用RNN实现如下输出
问题分析
原输入“hello”并不是一个向量,需要将其转变为一组数字向量。
对输入序列的每一个字符(单词)构造字典(词典),此时每一个字符都会有一个唯一的数字与其一一对应。即将字符向量转换为数字向量。之后利用独热编码(One-Hot)的思想,即可将每个数字转换为一个向量。
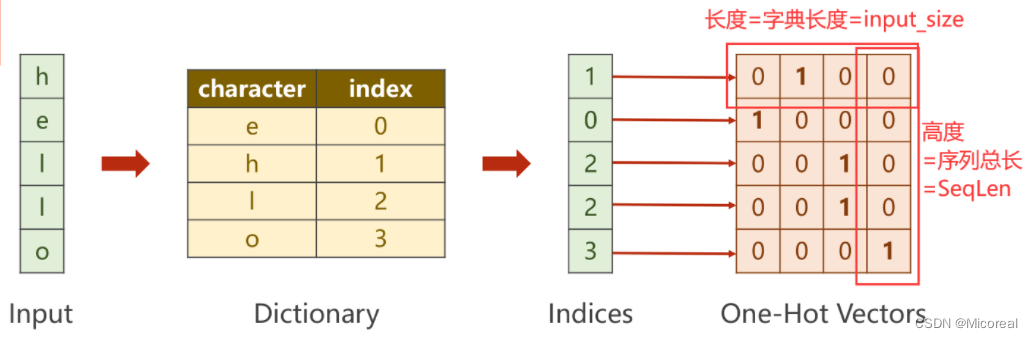
对输出序列按照上述要求构造字典。
多分类问题
对于序列中的每一个输入,都有一个数字输出与其对应,即本质上是在求当前输入所映射到输出字典中最大概率的值。即变为多分类问题。而此时的输出维度为3。
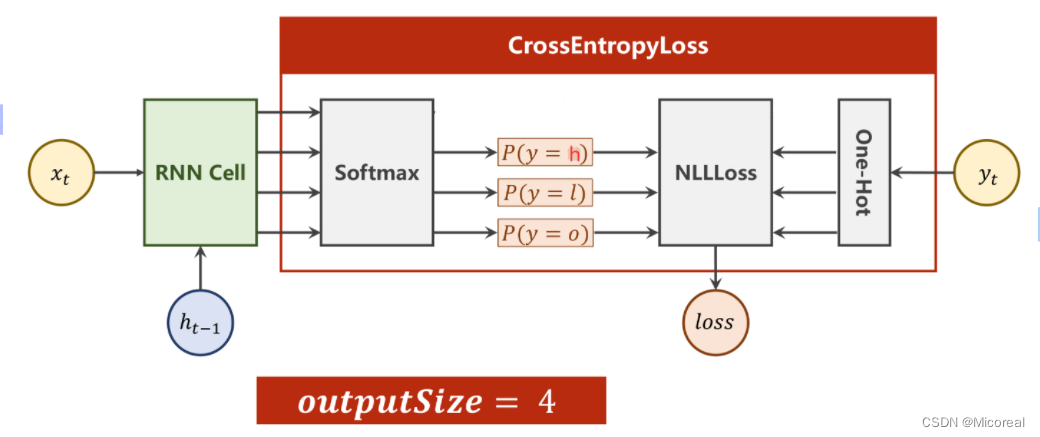
其中RNNCell的输出维度为4,经过Softmax求得映射之后的概率分别是多少,再利用输出对应的独热向量,计算NLLLoss。
代码
RNN Cell
import torchinput_size = 4
hidden_size = 3
batch_size = 1#构建输入输出字典
idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [2, 0, 1, 2, 1]
# y_data = [3, 1, 2, 2, 3]
one_hot_lookup = [[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]
#构造独热向量,此时向量维度为(SeqLen*InputSize)
x_one_hot = [one_hot_lookup[x] for x in x_data]
#view(-1……)保留原始SeqLen,并添加batch_size,input_size两个维度
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
#将labels转换为(SeqLen*1)的维度
labels = torch.LongTensor(y_data).view(-1, 1)class Model(torch.nn.Module):def __init__(self, input_size, hidden_size, batch_size):super(Model, self).__init__()self.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.rnncell = torch.nn.RNNCell(input_size = self.input_size,hidden_size = self.hidden_size)def forward(self, input, hidden):# RNNCell input = (batchsize*inputsize)# RNNCell hidden = (batchsize*hiddensize)hidden = self.rnncell(input, hidden)return hidden#初始化零向量作为h0,只有此处用到batch_sizedef init_hidden(self):return torch.zeros(self.batch_size, self.hidden_size)net = Model(input_size, hidden_size, batch_size)criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)for epoch in range(15):#损失及梯度置0,创建前置条件h0loss = 0optimizer.zero_grad()hidden = net.init_hidden()print("Predicted string: ",end="")#inputs=(seqLen*batchsize*input_size) labels = (seqLen*1)#input是按序列取的inputs元素(batchsize*inputsize)#label是按序列去的labels元素(1)for input, label in zip(inputs, labels):hidden = net(input, hidden)#序列的每一项损失都需要累加loss += criterion(hidden, label)#多分类取最大_, idx = hidden.max(dim=1)print(idx2char_2[idx.item()], end='')loss.backward()optimizer.step()print(", Epoch [%d/15] loss = %.4f" % (epoch+1, loss.item()))
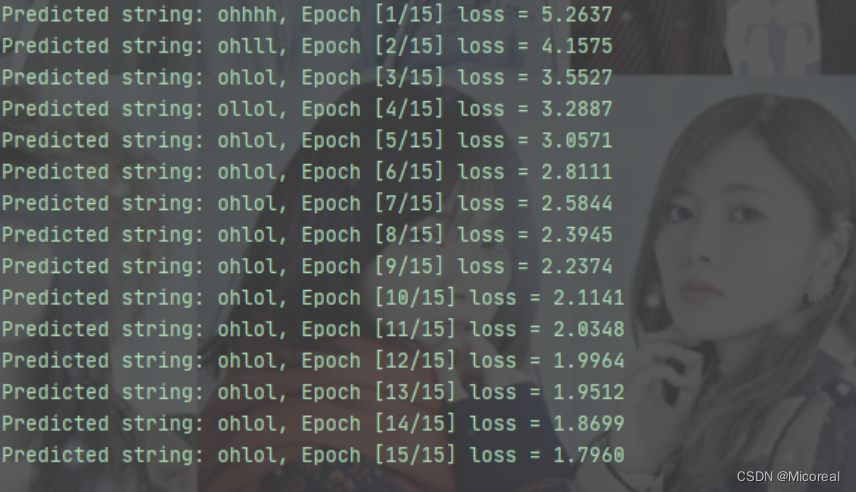
RNN
import torchinput_size = 4
hidden_size = 3
batch_size = 1
num_layers = 1
seq_len = 5
#构建输入输出字典
idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [2, 0, 1, 2, 1]
# y_data = [3, 1, 2, 2, 3]
one_hot_lookup = [[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]x_one_hot = [one_hot_lookup[x] for x in x_data]inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
#labels(seqLen*batchSize,1)为了之后进行矩阵运算,计算交叉熵
labels = torch.LongTensor(y_data)class Model(torch.nn.Module):def __init__(self, input_size, hidden_size, batch_size, num_layers=1):super(Model, self).__init__()self.batch_size = batch_size #构造H0self.input_size = input_sizeself.hidden_size = hidden_sizeself.num_layers = num_layersself.rnn = torch.nn.RNN(input_size = self.input_size,hidden_size = self.hidden_size,num_layers=num_layers)def forward(self, input):hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)out, _ = self.rnn(input, hidden)#reshape成(SeqLen*batchsize,hiddensize)便于在进行交叉熵计算时可以以矩阵进行。return out.view(-1, self.hidden_size)net = Model(input_size, hidden_size, batch_size, num_layers)criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)#RNN中的输入(SeqLen*batchsize*inputsize)
#RNN中的输出(SeqLen*batchsize*hiddensize)
#labels维度 hiddensize*1
for epoch in range(15):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted string: ',''.join([idx2char_2[x] for x in idx]), end = '')print(", Epoch [%d/15] loss = %.3f" % (epoch+1, loss.item()))
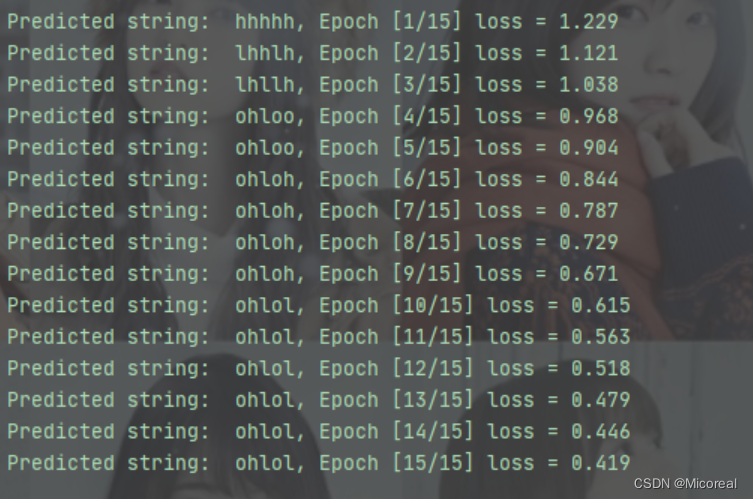
改进
独热编码在实际问题中容易引起很多问题:
- 独热编码向量维度过高,每增加一个不同的数据,就要增加一维
- 独热编码向量稀疏,每个向量是一个为1其余为0
- 独热编码是硬编码,编码情况与数据特征无关
综上所述,需要一种低维度的、稠密的、可学习数据的编码方式
Embedding
目的是为了对数据进行降维
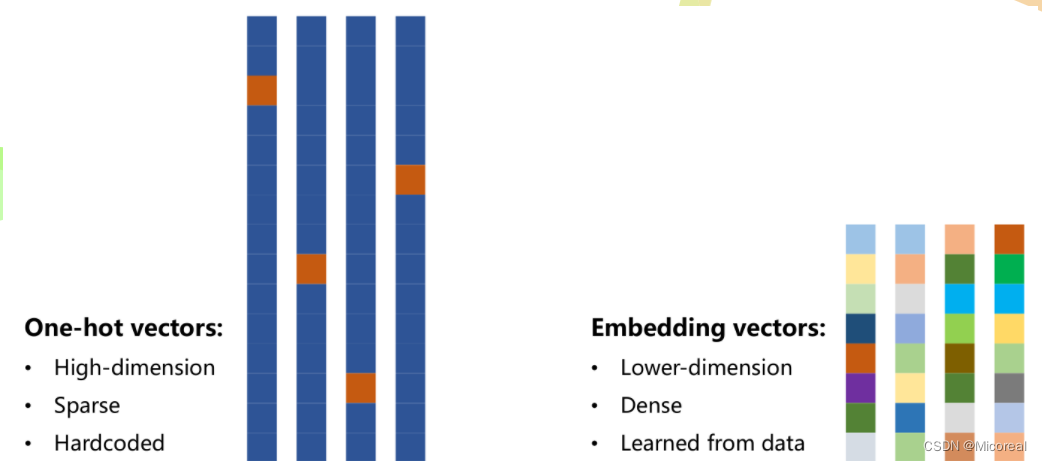
若从Input_Size转化为Embedding_Size,以下图为例,即需要把四维的向量转换为5维,则仅需要如下图所示的矩阵,将独热编码的向量与Embedding的矩阵相乘即可。
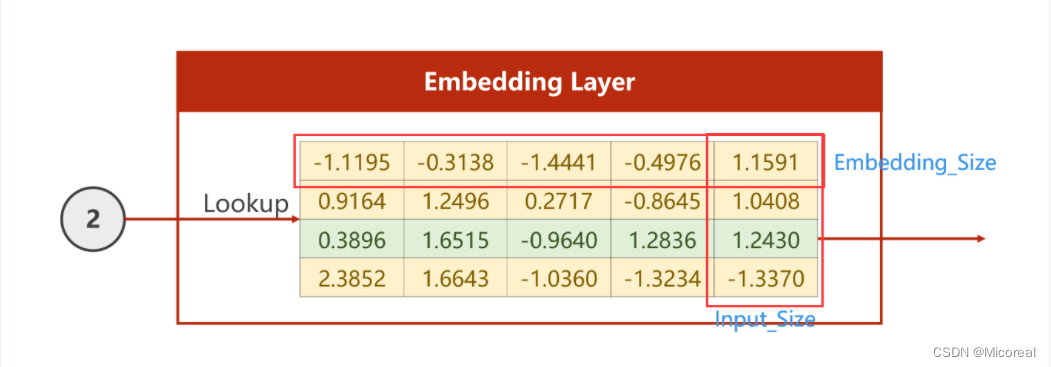
即将上图矩阵转置,再右乘向量即可

如此即可将原先四维的One-Hot编码变为五维的Embedding编码
网络结构
增加Embedding层实现降维,增加线性层使之在处理输入输出维度不同的情况下更加稳定。
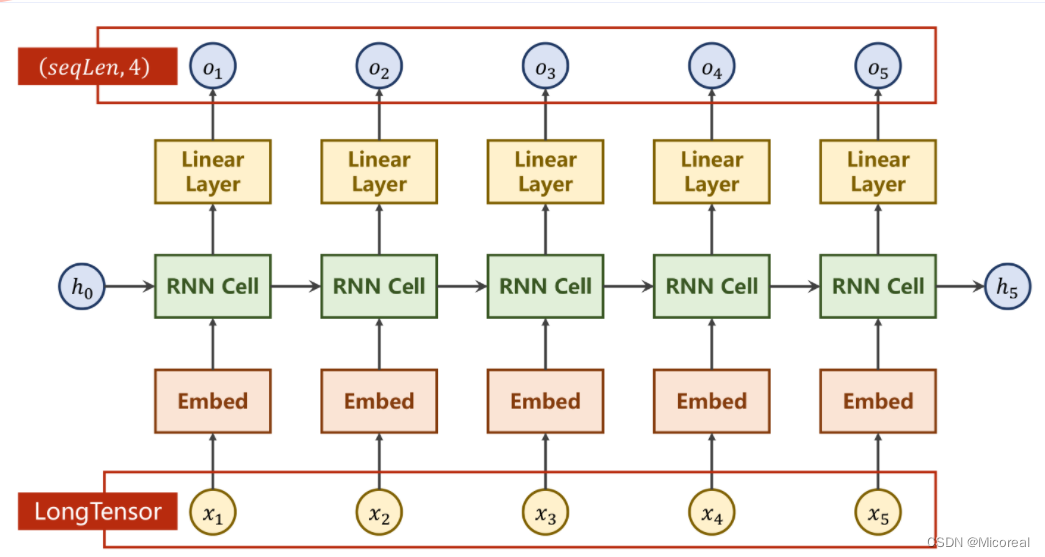
其中的Embedding层的输入必须是LongTensor类型。
Embedding说明
| 字段 | 类型 | 说明 |
|---|---|---|
| num_embedding | torch.nn.Embedding的参数 | 表示输入的独热编码的维数 |
| embedding_dim | torch.nn.Embedding的参数 | 表示需要转换成的维数 |
| Input | torch.nn.Embedding的输入量 | LongTensor类型 |
| Output | torch.nn.Embedding的输出量 | 为数据增加一个维度(embedding_dim) |
Linear说明
对于线性层,输入和输出的第一个维度(Batch)一直到倒数第二个维度都会保持不变。但会对最后一个维度(in_features)做出改变(out_features)

代码
import torchinput_size = 4
num_class = 4
hidden_size = 8
embedding_size =10
batch_size = 1
num_layers = 2
seq_len = 5idx2char_1 = ['e', 'h', 'l', 'o']
idx2char_2 = ['h', 'l', 'o']x_data = [[1, 0, 2, 2, 3]]
y_data = [3, 1, 2, 2, 3]#inputs 作为交叉熵中的Inputs,维度为(batchsize,seqLen)
inputs = torch.LongTensor(x_data)
#labels 作为交叉熵中的Target,维度为(batchsize*seqLen)
labels = torch.LongTensor(y_data)class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self .emb = torch.nn.Embedding(input_size, embedding_size)self.rnn = torch.nn.RNN(input_size = embedding_size,hidden_size = hidden_size,num_layers=num_layers,batch_first = True)self.fc = torch.nn.Linear(hidden_size, num_class)def forward(self, x):hidden = torch.zeros(num_layers, x.size(0), hidden_size)x = self.emb(x)x, _ = self.rnn(x, hidden)x = self.fc(x)return x.view(-1, num_class)net = Model()criterion = torch.nn.CrossEntropyLoss()
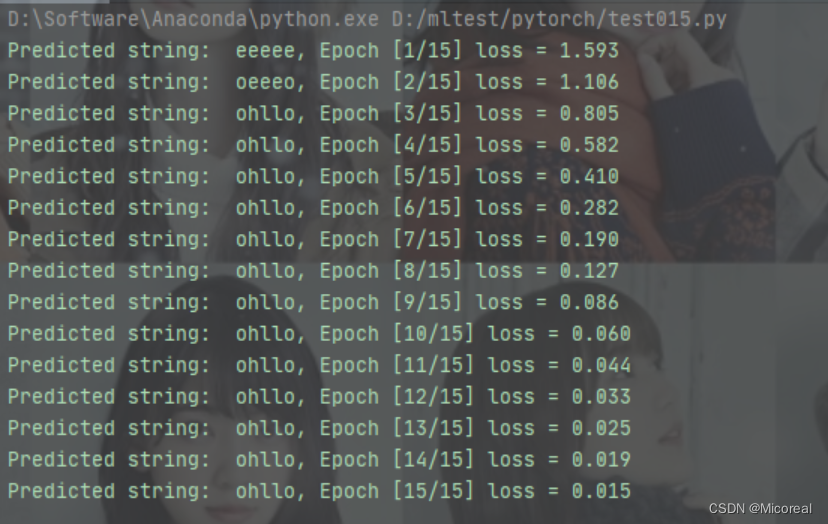
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)for epoch in range(15):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted string: ',''.join([idx2char_1[x] for x in idx]), end = '')print(", Epoch [%d/15] loss = %.3f" % (epoch+1, loss.item()))
输出结果:
相关文章:
12 循环神经网络(基础篇) Basic RNN
文章目录问题引入关于权重权重共享RNN CellRNN原理RNN计算过程代码实现RNN Cell维度说明代码RNN维度说明NumLayers说明计算过程代码参考实例问题分析多分类问题代码RNN CellRNN改进Embedding网络结构Embedding说明Linear说明代码课程来源: 链接课程文本参考…...
【C语言必经之路——第11节】初阶指针(2)
五、指针的运算1、指针与整数相加减看一下下面的代码:#include<stdio.h> int my_strlen(char* str) {int count0;while(*str!\0){count;str;//指针加减整数}return count; } int main() {int lenmy_strlen("abcdef");printf("%d\n",len);…...
第一个SpringBoot程序)
SpringBoot学习(1)第一个SpringBoot程序
之前的SpringMVc就不在记录了,好像时间不太够了,但是springmvc作为javaweb的升级学一学对于springboot还是有较大的帮助的。 首先我们需要引入依赖,但是请注意,其中的一个不算是依赖,写法有所不同 首先需要引入 <…...

什么是热迁移?90%的企业都理解错误
科技的发展,新冠的冲击,让市场竞争愈发激烈。尽管云计算服务为企业免除了基础硬件的建设和维护成本,当企业需要进行业务跨架调整、升级维护、环境测试等场景而进行云迁移,其过程中所带来的停机时间,就变得尤为头疼了。…...

Scratch少儿编程案例-丝滑版贪吃蛇
专栏分享 点击跳转=>Unity3D特效百例点击跳转=>案例项目实战源码点击跳转=>游戏脚本-辅助自动化点击跳转=>Android控件全解手册点击跳转=>Scratch编程案例👉关于作者...

Linux系统之网卡子接口配置方法
Linux系统之网卡子接口配置方法一、本地系统环境检查1.检查系统版本2.检查系统内核版本3.检查本地IP地址二、网卡子接口介绍1.网卡子接口简介2.网卡子接口的优点3.网卡子接口的缺点三 加载802.1q 模块1.查看系统802.1q 模块信息2.加载802.1q 模块3.检查802.1q 模块加载状态四、…...

2023上半年软考中级系统集成项目管理工程师2月25日开班
系统集成项目管理工程师是全国计算机技术与软件专业技术资格(水平)考试(简称软考)项目之一,是由国家人力资源和社会保障部、工业和信息化部共同组织的国家级考试,既属于国家职业资格考试,又是职…...

YOLO-V5轻松上手
之前介绍了YOLO-V1~V4版本各做了哪些事以及相较于之前版本的改进。有的人或许会想“直接学习最近版本的算法不好吗”,在我看来,每一个年代的版本/算法都凝聚着当年学术界的智慧,即便是它被淘汰了也依旧有值得思考的地方,或是可以使…...

CSS的优先级理解
权重 的 4个等级定义我们把特殊性分为4个等级,每一个等级代表一类选择器,每个等级的值相加得出选择器的权重。4个等级的定义如下:第一等级:代表内联样式,如style"",权值为 1000第二等级ÿ…...
前端工程师leetcode算法面试必备-二分搜索算法(中)
一、前言 二分搜索算法本身并不是特别复杂,核心点主要集中在: 有序数组:指的是一个递增或者递减的区间(特殊情况如:【852. 山脉数组的峰顶索引】); 中间数:用来确定搜索目标落在左…...
【数据库】MySQL 单表查询,多表查询
目录 单表查询 一,创建表worker 1,创建表worker的sql代码如下: 2,向worker表中插入信息 二, 按要求进行单表查询 1、显示所有职工的基本信息。 2、查询所有职工所属部门的部门号,不显示重复的部门号。 …...

【c++】vector实现(源码剖析+手画图解)
vector是我接触的第一个容器,好好对待,好好珍惜! 目录 文章目录 前言 二、vector如何实现 二、vector的迭代器(原生指针) 三、vector的数据结构 图解: 四、vector的构造及内存管理 1.push_back() …...

VScode查看python f.write()的文件乱码
VScode查看python f.write()的文件乱码 在使用 VScode 编写 python 代码, print(),汉字正常显示, 使用 with open()as f: f.write()文件后, 在 …...

excel应用技巧:如何用函数制作简易抽奖动图
利用INDEX函数和随机整数函数RANDBETWEEN配合,在Excel中做一个简单的抽奖器,可以随机抽取姓名或者奖品。有兴趣的伙伴可以做出来试试,撞撞2023年好运气。每次年会大家最期待的就是抽奖环节。为了看看自己今年运气怎么样,会不会获奖…...
CSI Tool 安装及配置记录
一、Ubuntu安装 1.下载Ubuntu 首先安装Ubuntu 14.04 LTS 64位下载地址(页面中第一个链接) 2.制作启动盘(注意备份) 可以使用官方的工具Rufus,下载地址:https://rufus.ie/ 打开Rufus,先备份…...
| 真题+思路+代码)
华为OD机试 - 最低位排序(Python)| 真题+思路+代码
最低位排序 题目 给定一个非空数组(列表),起元素数据类型为整型, 请按照数组元素十进制最低位从小到大进行排序, 十进制最低位相同的元素,相对位置保持不变, 当数组元素为负值时,十进制最低为等同于去除符号位后对应十进制值最低位。 输入 给定一个非空数组(列表) 其…...

C#开发的OpenRA使用TrimExcess方法
C#开发的OpenRA使用TrimExcess方法 当你在细看OpenRA的代码,就会发现在下面这段代码添加了一个方法: foreach (var nodes in levels) nodes.TrimExcess(); 在上面代码里遍历整个节点列表,把所有节点都调用TrimExcess方法处理一下, 这样做的意义何在?为什么我们在一般的代码…...
ImageMagick任意文件读取漏洞(CVE-2022-44268)
0x00 前提 前几天爆出一个 ImageMagick 漏洞 ,可以造成一个任意文件读取的危害比较可观,最近有时间来复现学习一下 主要是影响的范围很大,很多地方都有这个问题,需要来学习一下 0x01 介绍 ImageMagick 是一个免费的开源软件套…...

第十九篇 ResNet——论文翻译
文章目录 摘要1 引言2 相关工作3 深度残差学习3.1 残差学习3.2 快捷恒等映射3.3 网络架构3.4 实现4 实验4.1 ImageNet 分类4.2 CIFAR-10 和分析4.3 PASCAL 和 MS COCO 上的物体检测🐇🐇🐇🐇🐇🐇 🐇 欢迎阅读 【AI浩】 的博客🐇 👍 阅读完毕,可以动动小手赞一…...
RiProRiProV2主题美化顶部增加一行导航header导航通知
背景: 有些网站的背景顶部有一行罪行公告,样式不错,希望自己的网站也借鉴过来,本教程将指导如何操作,并调整成自己想要的样式。 比如网友搭的666资源站 xd素材中文网...

影墨·今颜开源模型价值解析:FLUX.1-dev二次开发与私有化训练路径
影墨今颜开源模型价值解析:FLUX.1-dev二次开发与私有化训练路径 1. 项目背景与核心价值 「影墨今颜」是一款基于FLUX.1-dev开源模型深度优化的AI影像生成系统,它将全球顶尖的生成引擎与东方美学理念完美融合,为用户提供极具真实感和艺术价值…...

Nanbeige 4.1-3B应用场景:AI内容共创平台前端——游戏化交互提升用户停留时长
Nanbeige 4.1-3B应用场景:AI内容共创平台前端——游戏化交互提升用户停留时长 1. 项目背景与设计理念 在当今AI对话系统普遍采用极简设计的背景下,我们为Nanbeige 4.1-3B大语言模型开发了一套独特的"像素冒险"风格前端界面。这套设计源于以下…...

全球企业不动产领域AI试点普及率飙升至92%,但仅5%企业实现大部分既定目标 | 美通社头条
、美通社消息:仲量联行3月19日发布《AI赋能商业地产:挑战、实践与未来布局》全球房地产科技调研中文版报告。报告显示,全球企业不动产领域AI试点普及率已从2023年不足5% 飙升至92%,但仅5%企业实现AI规模化价值兑现。与此同时&…...

Realistic Vision V5.1 虚拟摄影棚环境配置详解:Linux常用命令与依赖安装
Realistic Vision V5.1 虚拟摄影棚环境配置详解:Linux常用命令与依赖安装 如果你对Linux系统不太熟悉,但又想在自己的服务器或电脑上部署Realistic Vision V5.1这个强大的AI图像生成模型,可能会被一堆命令行操作吓到。别担心,这篇…...

OpenCore配置工具OCAT:让黑苹果配置变得简单的完整指南
OpenCore配置工具OCAT:让黑苹果配置变得简单的完整指南 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools OCAuxiliaryTool…...

Neo区块链智能合约测试框架完整指南:编写高质量测试用例的10个技巧
Neo区块链智能合约测试框架完整指南:编写高质量测试用例的10个技巧 【免费下载链接】neo 项目地址: https://gitcode.com/gh_mirrors/an/antshares Neo区块链测试框架是确保智能合约安全可靠的关键工具。作为领先的区块链平台,Neo提供了完善的单…...

LLaVA-NeXT-Video:突破零样本视频理解的AnyRes与长度泛化技术
1. 从图片到视频的零样本理解革命 当你第一次看到LLaVA-NeXT-Video处理长视频的场景,可能会想起小时候玩拼图的感觉。这个模型就像个天才儿童,能把高分辨率视频自动拆解成若干个小块(我们称之为"视觉token"),…...

终极PDF文本提取指南:使用pdftotext快速解锁文档价值
终极PDF文本提取指南:使用pdftotext快速解锁文档价值 【免费下载链接】pdftotext Simple PDF text extraction 项目地址: https://gitcode.com/gh_mirrors/pd/pdftotext 在当今数字化办公环境中,PDF文本提取已成为数据处理的必备技能。pdftotext作…...
的5个高级用法:从分页功能到全局状态管理)
uniapp混入(mixins)的5个高级用法:从分页功能到全局状态管理
Uniapp混入(mixins)的5个高阶实战技巧:从代码复用走向架构优化 在Uniapp开发中,混入(mixins)常被简单理解为代码复用的工具,但它的潜力远不止于此。当项目规模增长到一定程度时,如何优雅地管理跨组件的公共逻辑、统一处理生命周期…...

架构演进之 DDD:从 CRUD 到领域驱动设计
前言:每一个贫血模型背后,都有一个渐行渐远的业务在软件开发的早期阶段,我们通常从一个简单的 CRUD 应用开始。随着业务逻辑日益复杂,代码库逐渐膨胀,我们开始面临一个普遍的问题:业务逻辑散落在各处&#…...