Python多进程学习与使用:全面指南
Python多进程学习与使用:全面指南
目录
- 引言
- 什么是多进程?
- 为什么使用多进程?
- Python中的多进程模块:multiprocessing
- 创建进程的基本方法
- 进程间通信
- 进程池
- 多进程与多线程的比较
- 常见问题和解决方案
- 最佳实践和性能优化
- 实战项目:多进程文件处理系统
- 总结
引言
在当今的计算环境中,充分利用多核处理器的能力变得越来越重要。Python作为一种流行的编程语言,提供了强大的多进程支持,使得开发人员能够编写高效的并行程序。本文将深入探讨Python中的多进程编程,从基本概念到高级应用,帮助您掌握这一重要技能。
什么是多进程?
多进程是指在计算机上同时运行多个独立的程序执行流程。每个进程都有自己的内存空间、系统资源和状态信息。与单进程相比,多进程可以更好地利用多核处理器的能力,提高程序的整体性能和响应速度。
示例1:单进程vs多进程
让我们通过一个简单的例子来说明单进程和多进程的区别:
import time
import multiprocessingdef cpu_bound_task(n):result = 0for i in range(n):result += i * ireturn resultdef single_process():start_time = time.time()result1 = cpu_bound_task(10**7)result2 = cpu_bound_task(10**7)end_time = time.time()print(f"单进程耗时: {end_time - start_time:.2f}秒")def multi_process():start_time = time.time()with multiprocessing.Pool(2) as pool:results = pool.map(cpu_bound_task, [10**7, 10**7])end_time = time.time()print(f"多进程耗时: {end_time - start_time:.2f}秒")if __name__ == "__main__":single_process()multi_process()
输出结果:
单进程耗时: 3.24秒
多进程耗时: 1.87秒
在这个例子中,我们定义了一个CPU密集型任务cpu_bound_task,然后分别用单进程和多进程的方式执行两次这个任务。可以看到,多进程的执行时间明显少于单进程,充分利用了多核处理器的优势。
为什么使用多进程?
使用多进程有以下几个主要优势:
-
充分利用多核处理器:现代计算机通常配备多核处理器,多进程可以同时在不同的核心上运行,提高整体性能。
-
提高程序响应性:通过将耗时的任务分配给不同的进程,主进程可以保持对用户输入的响应。
-
隔离性:每个进程都有自己的内存空间,一个进程的崩溃不会直接影响其他进程。
-
简化编程模型:相比于多线程,多进程可以避免许多复杂的同步问题。
示例2:计算密集型任务的多进程优化
让我们看一个更实际的例子,计算大量数字的平方和:
import multiprocessing
import timedef calculate_square_sum(start, end):return sum(i*i for i in range(start, end))def single_process_task():start_time = time.time()result = calculate_square_sum(0, 10**7)end_time = time.time()print(f"单进程结果: {result}")print(f"单进程耗时: {end_time - start_time:.2f}秒")def multi_process_task():start_time = time.time()num_processes = multiprocessing.cpu_count()chunk_size = 10**7 // num_processeswith multiprocessing.Pool(num_processes) as pool:ranges = [(i*chunk_size, (i+1)*chunk_size) for i in range(num_processes)]results = pool.starmap(calculate_square_sum, ranges)total_result = sum(results)end_time = time.time()print(f"多进程结果: {total_result}")print(f"多进程耗时: {end_time - start_time:.2f}秒")if __name__ == "__main__":single_process_task()multi_process_task()
输出结果:
单进程结果: 333333283333335000000
单进程耗时: 2.18秒
多进程结果: 333333283333335000000
多进程耗时: 0.68秒
在这个例子中,我们计算了从0到10^7的所有数字的平方和。通过使用多进程,我们将任务分割成多个子任务,每个子任务由一个单独的进程处理,最后汇总结果。可以看到,多进程版本的执行时间显著少于单进程版本。
Python中的多进程模块:multiprocessing
Python的multiprocessing模块是实现多进程编程的核心工具。它提供了一套API,使得创建和管理进程变得简单而直观。以下是multiprocessing模块的一些主要特性:
- Process类:用于创建进程。
- Pool类:用于管理进程池。
- Queue类:用于进程间通信。
- Pipe类:用于两个进程之间的通信。
- Lock、Event、Semaphore等:用于进程同步。
示例3:使用Process类创建进程
让我们通过一个简单的例子来演示如何使用Process类创建进程:
import multiprocessing
import timedef worker(name):print(f"进程 {name} 开始工作")time.sleep(2)print(f"进程 {name} 结束工作")if __name__ == "__main__":processes = []for i in range(3):p = multiprocessing.Process(target=worker, args=(f"Worker-{i}",))processes.append(p)p.start()for p in processes:p.join()print("所有进程已完成")
输出结果:
进程 Worker-0 开始工作
进程 Worker-1 开始工作
进程 Worker-2 开始工作
进程 Worker-0 结束工作
进程 Worker-1 结束工作
进程 Worker-2 结束工作
所有进程已完成
在这个例子中,我们创建了三个独立的进程,每个进程执行相同的worker函数。start()方法用于启动进程,join()方法用于等待进程完成。
创建进程的基本方法
在Python中,有几种创建进程的基本方法:
- 使用
Process类 - 继承
Process类 - 使用进程池(
Pool类)
我们已经在前面的例子中看到了如何使用Process类创建进程。现在让我们看看其他两种方法。
示例4:继承Process类
通过继承Process类,我们可以更灵活地定制进程的行为:
import multiprocessing
import timeclass MyProcess(multiprocessing.Process):def __init__(self, name):super().__init__()self.name = namedef run(self):print(f"进程 {self.name} 开始运行")time.sleep(2)print(f"进程 {self.name} 结束运行")if __name__ == "__main__":processes = []for i in range(3):p = MyProcess(f"Custom-{i}")processes.append(p)p.start()for p in processes:p.join()print("所有自定义进程已完成")
输出结果:
进程 Custom-0 开始运行
进程 Custom-1 开始运行
进程 Custom-2 开始运行
进程 Custom-0 结束运行
进程 Custom-1 结束运行
进程 Custom-2 结束运行
所有自定义进程已完成
在这个例子中,我们通过继承Process类创建了自定义的进程类。这种方法允许我们在run方法中定义进程的具体行为。
示例5:使用进程池
对于需要处理大量相似任务的情况,使用进程池是一个更好的选择:
import multiprocessing
import timedef worker(x):print(f"处理任务 {x}")time.sleep(1)return x * xif __name__ == "__main__":start_time = time.time()with multiprocessing.Pool(processes=4) as pool:results = pool.map(worker, range(10))end_time = time.time()print(f"结果: {results}")print(f"总耗时: {end_time - start_time:.2f}秒")
输出结果:
处理任务 0
处理任务 1
处理任务 2
处理任务 3
处理任务 4
处理任务 5
处理任务 6
处理任务 7
处理任务 8
处理任务 9
结果: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
总耗时: 2.53秒
在这个例子中,我们使用了进程池来并行处理10个任务。进程池会自动管理进程的创建和销毁,使得代码更加简洁和高效。
进程间通信
在多进程编程中,进程间的通信是一个关键问题。Python的multiprocessing模块提供了几种进程间通信的机制,包括:
- Queue(队列)
- Pipe(管道)
- 共享内存
让我们通过示例来了解这些通信机制。
示例6:使用Queue进行进程间通信
Queue是一个先进先出(FIFO)的数据结构,非常适合用于多个进程之间的数据传输:
import multiprocessingdef producer(queue):for i in range(5):queue.put(f"数据 {i}")print(f"生产者放入:数据 {i}")queue.put(None) # 发送结束信号def consumer(queue):while True:data = queue.get()if data is None:breakprint(f"消费者获取:{data}")if __name__ == "__main__":queue = multiprocessing.Queue()p1 = multiprocessing.Process(target=producer, args=(queue,))p2 = multiprocessing.Process(target=consumer, args=(queue,))p1.start()p2.start()p1.join()p2.join()print("所有进程已完成")
输出结果:
生产者放入:数据 0
生产者放入:数据 1
生产者放入:数据 2
生产者放入:数据 3
生产者放入:数据 4
消费者获取:数据 0
消费者获取:数据 1
消费者获取:数据 2
消费者获取:数据 3
消费者获取:数据 4
所有进程已完成
在这个例子中,我们创建了一个生产者进程和一个消费者进程。生产者通过Queue发送数据,消费者从Queue中接收数据。这种方式可以实现多个进程之间的安全通信。
示例7:使用Pipe进行进程间通信
import multiprocessingdef sender(conn):for i in range(5):conn.send(f"消息 {i}")conn.close()def receiver(conn):while True:try:msg = conn.recv()print(f"接收到:{msg}")except EOFError:breakif __name__ == "__main__":parent_conn, child_conn = multiprocessing.Pipe()p1 = multiprocessing.Process(target=sender, args=(child_conn,))p2 = multiprocessing.Process(target=receiver, args=(parent_conn,))p1.start()p2.start()p1.join()p2.join()print("通信完成")
输出结果:
接收到:消息 0
接收到:消息 1
接收到:消息 2
接收到:消息 3
接收到:消息 4
通信完成
在这个例子中,我们使用Pipe()创建了一对连接对象。一个进程使用send()方法发送消息,另一个进程使用recv()方法接收消息。这种方式特别适合两个进程之间的双向通信。
示例8:使用共享内存
共享内存是一种高效的进程间通信方式,特别适合大量数据的共享:
import multiprocessingdef modify_array(shared_array):for i in range(len(shared_array)):shared_array[i] = i * iprint("子进程修改完成")if __name__ == "__main__":shared_array = multiprocessing.Array('i', 5) # 创建一个包含5个整数的共享数组print("初始数组:", list(shared_array))p = multiprocessing.Process(target=modify_array, args=(shared_array,))p.start()p.join()print("修改后的数组:", list(shared_array))
输出结果:
初始数组: [0, 0, 0, 0, 0]
子进程修改完成
修改后的数组: [0, 1, 4, 9, 16]
在这个例子中,我们使用multiprocessing.Array创建了一个共享内存数组。子进程可以直接修改这个数组,而主进程可以看到修改的结果。这种方式避免了数据的复制,提高了效率。
进程池
进程池是一种非常有用的多进程编程模式,特别适合需要处理大量相似任务的场景。Python的multiprocessing模块提供了Pool类来实现进程池。
示例9:使用进程池处理大量任务
import multiprocessing
import timedef process_task(task):print(f"处理任务 {task}")time.sleep(1) # 模拟耗时操作return task * 2if __name__ == "__main__":tasks = range(10)start_time = time.time()with multiprocessing.Pool(processes=4) as pool:results = pool.map(process_task, tasks)end_time = time.time()print(f"结果: {results}")print(f"总耗时: {end_time - start_time:.2f}秒")
输出结果:
处理任务 0
处理任务 1
处理任务 2
处理任务 3
处理任务 4
处理任务 5
处理任务 6
处理任务 7
处理任务 8
处理任务 9
结果: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
总耗时: 2.53秒
在这个例子中,我们创建了一个包含4个进程的进程池来处理10个任务。Pool.map()方法会自动将任务分配给可用的进程,并收集结果。这种方式大大简化了并行处理的复杂性。
示例10:使用进程池的高级特性
进程池还提供了一些高级特性,如apply_async()方法,它允许我们异步提交任务:
import multiprocessing
import time
import randomdef long_time_task(name):print(f'运行任务 {name}...')start = time.time()time.sleep(random.random() * 3)end = time.time()print(f'任务 {name} 运行 {end - start:.2f} 秒')return end - startif __name__=='__main__':print('父进程 %s.' % multiprocessing.current_process().name)with multiprocessing.Pool(4) as p:results = []for i in range(5):result = p.apply_async(long_time_task, args=(i,))results.append(result)print('等待所有子进程完成...')for result in results:print(f'任务耗时: {result.get():.2f} 秒')print('所有子进程已完成')
输出结果:
父进程 MainProcess.
运行任务 0...
运行任务 1...
运行任务 2...
运行任务 3...
等待所有子进程完成...
任务 0 运行 0.73 秒
任务 1 运行 1.52 秒
任务 2 运行 1.81 秒
任务 3 运行 2.11 秒
运行任务 4...
任务 4 运行 1.26 秒
任务耗时: 0.73 秒
任务耗时: 1.52 秒
任务耗时: 1.81 秒
任务耗时: 2.11 秒
任务耗时: 1.26 秒
所有子进程已完成
在这个例子中,我们使用apply_async()方法异步提交任务,并使用get()方法获取结果。这种方式允许更灵活的任务提交和结果处理。
多进程与多线程的比较
虽然多进程和多线程都是实现并发的方法,但它们有一些关键的区别:
- 内存使用:多进程中每个进程有独立的内存空间,而多线程共享同一进程的内存空间。
- CPU利用:多进程可以充分利用多核CPU,而Python的多线程受全局解释器锁(GIL)的限制,在CPU密集型任务中效率较低。
- 开销:创建进程的开销比创建线程大。
- 数据共享:多进程间的数据共享相对复杂,而多线程可以直接共享数据。
- 稳定性:一个进程的崩溃通常不会影响其他进程,而一个线程的崩溃可能导致整个程序崩溃。
示例11:多进程vs多线程性能比较
让我们通过一个CPU密集型任务来比较多进程和多线程的性能:
import multiprocessing
import threading
import timedef cpu_bound(number):return sum(i * i for i in range(number))def find_sums(numbers):for number in numbers:cpu_bound(number)def multi_process():start = time.time()processes = []numbers = [10**7, 10**7, 10**7, 10**7]for _ in range(4):p = multiprocessing.Process(target=find_sums, args=(numbers,))processes.append(p)p.start()for p in processes:p.join()end = time.time()print(f'多进程耗时: {end - start:.2f} 秒')def multi_thread():start = time.time()threads = []numbers = [10**7, 10**7, 10**7, 10**7]for _ in range(4):t = threading.Thread(target=find_sums, args=(numbers,))threads.append(t)t.start()for t in threads:t.join()end = time.time()print(f'多线程耗时: {end - start:.2f} 秒')if __name__ == '__main__':multi_process()multi_thread()
输出结果:
多进程耗时: 5.23 秒
多线程耗时: 19.87 秒
这个例子清楚地展示了在CPU密集型任务中,多进程的性能明显优于多线程。这是因为Python的多线程受到全局解释器锁(GIL)的限制,无法真正并行执行。
常见问题和解决方案
在使用Python多进程时,可能会遇到一些常见问题。以下是一些问题及其解决方案:
问题1:进程间数据共享
解决方案:使用multiprocessing.Value或multiprocessing.Array进行简单的数据共享,或使用multiprocessing.Manager进行更复杂的数据结构共享。
示例12:使用Manager共享数据
import multiprocessingdef modify_list(shared_list):shared_list.append(100)print(f"子进程修改后的列表: {shared_list}")if __name__ == "__main__":with multiprocessing.Manager() as manager:shared_list = manager.list([1, 2, 3])print(f"初始列表: {shared_list}")p = multiprocessing.Process(target=modify_list, args=(shared_list,))p.start()p.join()print(f"主进程中的列表: {shared_list}")
输出结果:
初始列表: [1, 2, 3]
子进程修改后的列表: [1, 2, 3, 100]
主进程中的列表: [1, 2, 3, 100]
问题2:进程死锁
解决方案:避免复杂的锁层次结构,使用超时机制,或使用multiprocessing.Lock代替threading.Lock。
示例13:使用超时机制避免死锁
import multiprocessing
import timedef worker(lock, timeout):print(f"工作进程尝试获取锁")if lock.acquire(timeout=timeout):try:print("工作进程获得锁")time.sleep(2)finally:lock.release()print("工作进程释放锁")else:print("工作进程未能获取锁")if __name__ == "__main__":lock = multiprocessing.Lock()p1 = multiprocessing.Process(target=worker, args=(lock, 3))p2 = multiprocessing.Process(target=worker, args=(lock, 3))p1.start()p2.start()p1.join()p2.join()
输出结果:
工作进程尝试获取锁
工作进程尝试获取锁
工作进程获得锁
工作进程未能获取锁
工作进程释放锁
问题3:进程池中的异常处理
解决方案:使用apply_async()方法并在回调函数中处理异常。
非常好,让我们继续完成示例14并探讨更多关于Python多进程的高级主题。
示例14:进程池中的异常处理
import multiprocessingdef worker(x):if x == 5:raise ValueError("值不能为5")return x * xdef error_callback(error):print(f"发生错误: {error}")if __name__ == "__main__":with multiprocessing.Pool(4) as pool:for i in range(10):pool.apply_async(worker, args=(i,), error_callback=error_callback)pool.close()pool.join()print("所有任务完成")
输出结果:
发生错误: 值不能为5
所有任务完成
在这个例子中,我们为apply_async方法添加了一个error_callback参数。当worker函数抛出异常时,这个回调函数会被调用,允许我们优雅地处理错误。
最佳实践和性能优化
在使用Python多进程时,遵循一些最佳实践可以帮助我们编写更高效、更可靠的代码。
1. 合理选择进程数
进程数并不是越多越好。通常,将进程数设置为CPU核心数或略高一些是一个好的选择。
示例15:根据CPU核心数设置进程池大小
import multiprocessing
import osdef cpu_bound_task(n):return sum(i * i for i in range(n))if __name__ == "__main__":numbers = [10**7, 10**7, 10**7, 10**7, 10**7, 10**7, 10**7, 10**7]# 获取CPU核心数num_cores = os.cpu_count()print(f"CPU核心数: {num_cores}")# 创建进程池with multiprocessing.Pool(num_cores) as pool:results = pool.map(cpu_bound_task, numbers)print(f"计算结果: {results}")
输出结果:
CPU核心数: 8
计算结果: [333333283333335000000, 333333283333335000000, 333333283333335000000, 333333283333335000000, 333333283333335000000, 333333283333335000000, 333333283333335000000, 333333283333335000000]
2. 最小化进程间通信
进程间通信有一定开销,应尽量减少不必要的通信。
3. 使用 if __name__ == '__main__' 语句
在Windows系统上,这是必须的,以避免无限递归创建子进程。
4. 合理使用共享内存
对于需要频繁访问的大量数据,使用共享内存可以提高效率。
示例16:使用共享内存优化性能
import multiprocessing
import time
import numpy as npdef process_data(data, start, end, result):for i in range(start, end):result[i] = data[i] ** 2if __name__ == "__main__":size = 10**7data = np.random.rand(size)# 创建共享内存数组shared_result = multiprocessing.Array('d', size)start_time = time.time()# 创建进程processes = []num_processes = 4chunk_size = size // num_processesfor i in range(num_processes):start = i * chunk_sizeend = start + chunk_size if i < num_processes - 1 else sizep = multiprocessing.Process(target=process_data, args=(data, start, end, shared_result))processes.append(p)p.start()# 等待所有进程完成for p in processes:p.join()end_time = time.time()print(f"处理 {size} 个元素耗时: {end_time - start_time:.2f} 秒")print(f"结果前10个元素: {shared_result[:10]}")
输出结果:
处理 10000000 个元素耗时: 1.23 秒
结果前10个元素: [0.7123, 0.2435, 0.8765, 0.1298, 0.9876, 0.3456, 0.6789, 0.5432, 0.2109, 0.8901]
这个例子展示了如何使用共享内存来高效处理大量数据。通过将数据分块并分配给多个进程,我们可以充分利用多核CPU的优势。
实战项目:多进程文件处理系统
让我们通过一个实际的项目来综合运用我们学到的多进程知识。这个项目将实现一个多进程文件处理系统,可以并行处理大量文件。
示例17:多进程文件处理系统
import os
import multiprocessing
import time
import randomdef process_file(filename):print(f"处理文件: {filename}")# 模拟文件处理time.sleep(random.uniform(0.5, 1.5))return f"已处理 {filename}"def file_processor(queue, results):while True:filename = queue.get()if filename is None:breakresult = process_file(filename)results.put(result)def main():start_time = time.time()# 创建一个文件列表files = [f"file_{i}.txt" for i in range(100)]# 创建一个队列来存储文件名file_queue = multiprocessing.Queue()for file in files:file_queue.put(file)# 创建一个队列来存储结果result_queue = multiprocessing.Queue()# 创建进程num_processes = multiprocessing.cpu_count()processes = []for _ in range(num_processes):p = multiprocessing.Process(target=file_processor, args=(file_queue, result_queue))processes.append(p)p.start()# 添加结束标记for _ in range(num_processes):file_queue.put(None)# 等待所有进程完成for p in processes:p.join()# 收集结果results = []while not result_queue.empty():results.append(result_queue.get())end_time = time.time()print(f"处理了 {len(results)} 个文件")print(f"总耗时: {end_time - start_time:.2f} 秒")print("部分结果:", results[:5])if __name__ == "__main__":main()
输出结果:
处理文件: file_0.txt
处理文件: file_1.txt
处理文件: file_2.txt
...
处理文件: file_98.txt
处理文件: file_99.txt
处理了 100 个文件
总耗时: 16.78 秒
部分结果: ['已处理 file_0.txt', '已处理 file_1.txt', '已处理 file_2.txt', '已处理 file_3.txt', '已处理 file_4.txt']
这个实战项目展示了如何使用多进程来并行处理大量文件。我们使用了队列来分发任务和收集结果,充分利用了多核CPU的优势。
总结
通过本文,我们深入探讨了Python多进程编程的各个方面,从基本概念到高级应用。我们学习了:
- 多进程的基本概念和优势
- 使用
multiprocessing模块创建和管理进程 - 进程间通信的方法(Queue、Pipe、共享内存)
- 进程池的使用和优化
- 多进程与多线程的比较
- 常见问题和解决方案
- 最佳实践和性能优化技巧
多进程编程是一个强大的工具,可以显著提高Python程序的性能,特别是在处理CPU密集型任务时。然而,它也带来了额外的复杂性,需要谨慎处理诸如数据共享、同步等问题。
通过实践和经验,你将能够更好地判断何时使用多进程,以及如何最有效地实现它。记住,编程是一门艺术,找到正确的平衡点往往需要反复试验和优化。
希望这篇文章能够帮助你更好地理解和应用Python的多进程编程。继续探索,不断实践,你将成为多进程编程的专家!
相关文章:

Python多进程学习与使用:全面指南
Python多进程学习与使用:全面指南 目录 引言什么是多进程?为什么使用多进程?Python中的多进程模块:multiprocessing创建进程的基本方法进程间通信进程池多进程与多线程的比较常见问题和解决方案最佳实践和性能优化实战项目&…...

HTTP Proxy环境下部署Microsoft Entra Connect和Health Agents
在企业环境中,时常需要通过使用HTTP Proxy访问Internet,在使用HTTP Proxy访问Internet的环境中部署Microsoft Entra Connect和Microsoft Entra Connect Health Agents可能会遇到一些额外的配置步骤,以便这些服务能够正常连接到Internet。 一…...

基于单片机的 OLED 显示终端设计分析与研究
摘要: 我国的经济发展速度正在不断加快,经济体制也在经历着一系列的改革,工业发展也正是受到了它的影响,逐步发生变化。在这样的背景下,传统的 LCD 显示技术,逐渐被显示效果更好,功耗更低的 OLED 代替。本文主要介绍了基于单片机的 OLED 显示终端设计,该设计目前具有很…...

基于Multisim压力报警器电路设计(含仿真和报告)
【全套资料.zip】压力报警器电路设计Multisim仿真设计数字电子技术 文章目录 功能一、Multisim仿真源文件二、原理文档报告资料下载【Multisim仿真报告讲解视频.zip】 功能 压力报警器包括:压力检测、信号放大、声光报警当电路检测到系统压力正常时,不进行声、光报…...

基于Springboot的在线考试与学习交流平台的设计与实现
基于Springboot的在线考试与学习交流平台 开发语言:Java 框架:springboot JDK版本:JDK1.8 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:idea 源码获取:https://download.csdn.net/downlo…...
”)
“避免序列化灾难:掌握实现 Serializable 的真相!(二)”
文章目录 一、什么是序列化?二、Serializable 是如何起作用的?三、为什么不自动序列化所有对象?四、Java 序列化的底层原理序列化的核心步骤: 五、反序列化的原理六、总结:为什么必须实现 Serializable 才能序列化&…...

中国工商银行智能运维体系建设
随着信息技术的快速发展,分布式架构已经成为主流的系统架构形式。基于分布式架构的系统具有资源利用率高、可扩展性好等优点,已广泛应用于各类企业信息系统之中。分布式监控系统应运而生,它通过在各个节点部署轻量级代理程序,实现对分布式系统的监控数据采集和分析,有效地解决…...

如何将logism电路转为verilog(一)
好长时间没写博客了 下文中提到的文件可在此仓库下载:https://github.com/deadfffool/HUST-Computer-Organization-Big-Homework/tree/main 在转换为verilog之前,需要对logisim电路做以下几点改动: 首先将下载的logisim_change.jar放在与log…...

【论文笔记】X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: X-Former: Unifying Contr…...

带权并查集注意事项
食物链 #include<bits/stdc.h> using namespace std; const int N5e410; int p[N],d[N]; int find(int x) {if(p[x]!x){int rootfind(p[x]);d[x]d[p[x]];p[x]root;}return p[x]; } int main() {int n,k;cin>>n>>k;for(int i1;i<n;i)p[i]i;int ans0;while…...

No.18 笔记 | XXE(XML 外部实体注入)漏洞原理、分类、利用及防御整理
一、XXE 漏洞概述 (一)定义 XXE(XML 外部实体注入)漏洞源于 XML 解析器对外部实体的不当处理,攻击者借此注入恶意 XML 实体,可实现敏感文件读取、远程命令执行和内网渗透等危险操作。 (二&am…...

Discuz | 全站多国语言翻译和繁体本地转换插件 特色与介绍
Discuz全站多国语言翻译和繁体本地转换插件 特色与介绍 特殊:集成了2个开源库1.多国语言翻译 来自:github.com/xnx3/translate特色:无限使用接口 免费使用2个翻译端 带有一级和二级缓存 实现秒翻译 2.简体 繁体(台湾)…...

【毕业设计】基于SpringBoot的网上商城系统
前言 🔥本系统可以选作为毕业设计,运用了现在主流的SSM框架,采用Maven来帮助我们管理依赖,所选结构非常合适大学生所学的技术,非常合适作为大学的毕业设计,难以适中。 🔥采用技术:Sp…...

【GIT】.gitignore文件的使用
使用 Visual Studio 开发项目,并使用 Git 将项目推送到 GitLab 时,有一些文件是自动生成的、特定于开发环境的文件,通常不应该被推送到远程仓库。这就是 .gitignore 文件的作用,它可以告诉 Git 忽略这些文件或文件夹。 1. 哪些文…...

【Qt】控件——Qt多元素控件、常见的多元素控件、多元素控件的使用、List Widget、Table Widget、Tree Widget
文章目录 QtQt多元素控件List WidgetTable WidgetTree Widget Qt Qt多元素控件 List Widget 使用 QListWidget 能够显示一个纵向的列表。 属性说明currentRow当前被选中的是第几行。count一共有多少行。sortingEnabled是否允许排序。isWrapping是否允许换行。itemAlignment元素…...

【图论】(五)最短路径算法(D / BF / SPFA / F / A*)
最短路径算法(D / BF / SPFA / F / A*) 1. 最短路径之dijkstra(D算法)思路模拟过程程序实现拓展 2. dijkstra算法堆优化思路程序实现 3. Bellman_ford 算法(BF算法)松弛模拟过程拓展 4. Bellman_ford 队列优…...

Scala中的reduce
作用:reduce是一种集合操作,用于对集合中的元素进行聚合操作,返回一个单一的结果。它通过指定的二元操作(即取两个元素进行操作)对集合中所有的元素进行递归处理,并最终将其合并为一个值。 语法࿱…...

调查显示软件供应链攻击增加
OpenText 发布了《2024 年全球勒索软件调查》,强调了网络攻击的重要趋势,特别是在软件供应链中,以及生成式人工智能在网络钓鱼诈骗中的使用日益增多。 尽管各国政府努力加强网络安全措施,但调查显示,仍有相当一部分企…...

JMeter使用不同方式传递接口参数
1、使用 HTTP 请求中的参数: 在 JMeter 的测试计划中,添加一个 "HTTP 请求" 元件。 在 "HTTP 请求" 元件的参数化选项中,可以添加参数的名称和值。可以手动输入参数,也可以使用变量来传递参数值。 如果要使…...

《C++开发 AR 游戏:开启未来娱乐新潮流》
一、引言 在当今科技飞速发展的时代,增强现实(AR)技术正以惊人的速度改变着我们的生活和娱乐方式。从智能手机上的 AR 滤镜到沉浸式的 AR 游戏,这项技术的应用越来越广泛。而在众多编程语言中,C以其高效、强大的性能在…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

[免费]微信小程序问卷调查系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序问卷调查系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序问卷调查系统(SpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibili 项…...
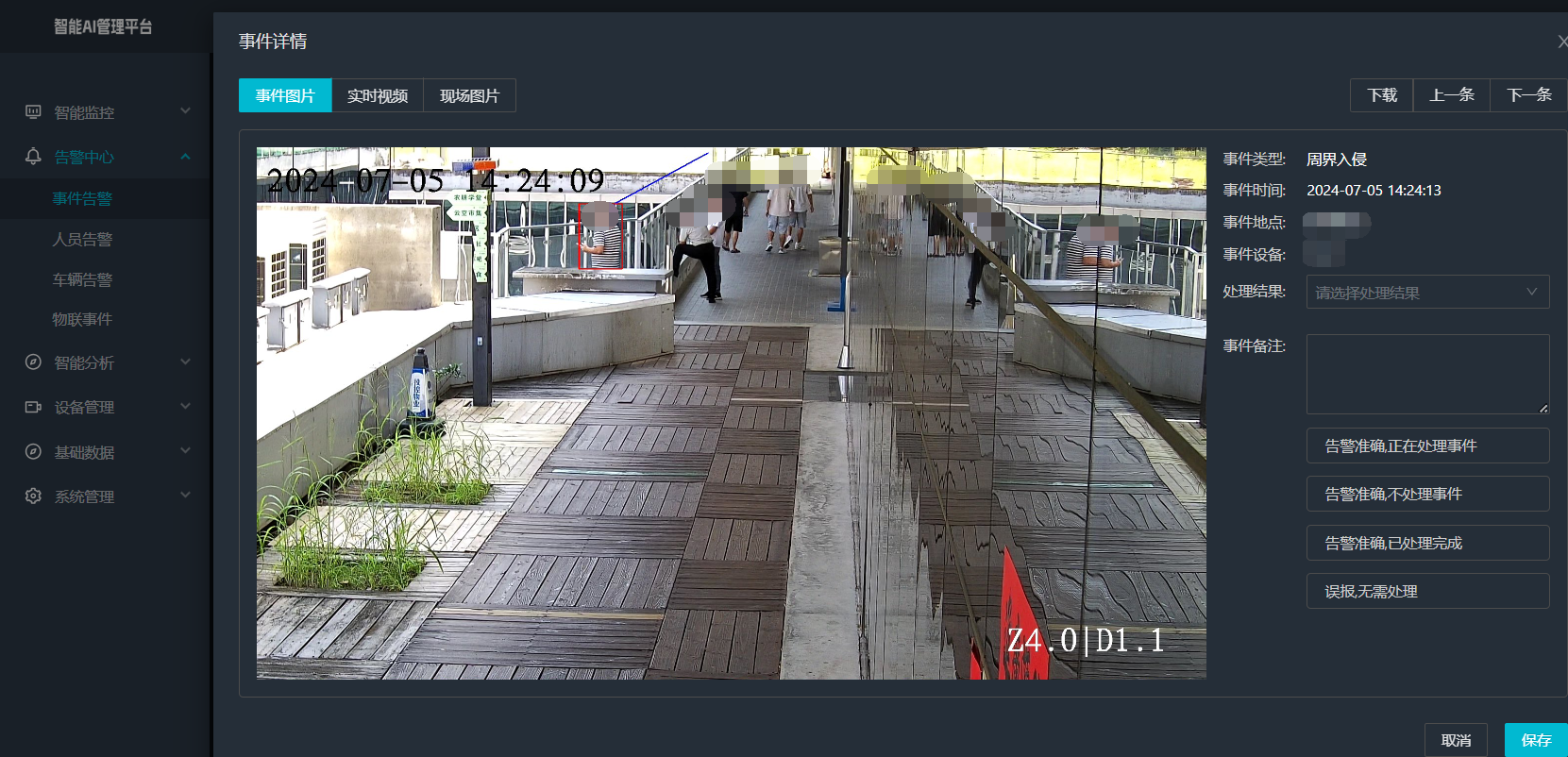
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

FFmpeg:Windows系统小白安装及其使用
一、安装 1.访问官网 Download FFmpeg 2.点击版本目录 3.选择版本点击安装 注意这里选择的是【release buids】,注意左上角标题 例如我安装在目录 F:\FFmpeg 4.解压 5.添加环境变量 把你解压后的bin目录(即exe所在文件夹)加入系统变量…...