Spring Boot框架中的IO
1. 文件资源的访问与管理
在 Spring Boot 中,资源文件的访问与管理是常见的操作需求,比如加载配置文件、读取静态文件或从外部文件系统读取文件。Spring 提供了多种方式来处理资源文件访问,包括通过 ResourceLoader、@Value 注解以及 ApplicationContext 获取资源。下面我们详细介绍这几种常见的文件资源访问与管理方法。
1.1 使用 ResourceLoader 加载资源
ResourceLoader 是 Spring 提供的一个接口,用于加载各种类型的资源文件。它支持从多种来源加载资源,包括类路径、文件系统、URL 等。你可以通过 ResourceLoader 来轻松访问文件资源。
1.1.1 加载类路径资源
你可以通过 ResourceLoader 来加载类路径中的资源文件(例如 src/main/resources 下的文件)。以下示例展示如何加载类路径中的文件:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.Resource;
import org.springframework.core.io.ResourceLoader;
import org.springframework.stereotype.Service;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;@Service
public class FileResourceService {@Autowiredprivate ResourceLoader resourceLoader;public String loadClasspathFile() throws IOException {// 加载类路径下的资源文件Resource resource = resourceLoader.getResource("classpath:data/example.txt");// 读取文件内容try (BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8))) {return reader.lines().reduce("", (acc, line) -> acc + line + "\n");}}
}
ResourceLoader.getResource("classpath:..."):用于加载类路径下的文件资源。classpath:前缀通常用于读取位于src/main/resources中的文件 (相当于替代了src/main/resources这个路径)
1.1.2 加载文件系统资源
除了类路径,ResourceLoader 还可以加载文件系统中的资源文件。
public String loadFileSystemFile() throws IOException {// 加载文件系统中的文件资源Resource resource = resourceLoader.getResource("file:/path/to/your/file.txt");// 读取文件内容try (BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8))) {return reader.lines().reduce("", (acc, line) -> acc + line + "\n");}
}
ResourceLoader.getResource("file:..."):用于从文件系统加载文件资源。
1.1.3 加载 URL 资源
ResourceLoader 还可以加载远程 URL 资源,比如从网络上加载文件:
public String loadUrlFile() throws IOException {// 加载 URL 资源Resource resource = resourceLoader.getResource("https://example.com/file.txt");// 读取文件内容try (BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8))) {return reader.lines().reduce("", (acc, line) -> acc + line + "\n");}
}
ResourceLoader.getResource("https://..."):用于从网络 URL 加载资源文件。
1.2 使用 @Value 注入文件路径
@Value 注解可以从配置文件中注入资源文件路径,这是一种简化的方式,特别是在需要配置外部资源时非常有用。@Value 注解不仅可以用于注入配置文件中的字符串,还可以直接注入 Resource 对象。
1.2.1 注入文件路径
通过 @Value 可以直接注入文件路径作为字符串,并使用传统的 IO 来读取文件:
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;@Service
public class FilePathService {// 注入文件路径@Value("${file.path}")private String filePath;public String readFileContent() throws IOException {Path path = Paths.get(filePath);return new String(Files.readAllBytes(path), StandardCharsets.UTF_8);}
}
@Value("${file.path}"):可以从application.properties或application.yml文件中注入文件路径。
1.2.2 注入 Resource
你还可以直接通过 @Value 注入 Resource 对象,然后使用 Resource 对象的 getInputStream() 方法读取文件内容。
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;@Service
public class ResourceService {// 注入类路径下的资源文件@Value("classpath:data/example.txt")private Resource resource;public String loadFileContent() throws IOException {try (BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8))) {return reader.lines().reduce("", (acc, line) -> acc + line + "\n");}}
}
@Value("classpath:..."):注入类路径下的资源文件,直接注入为Resource类型。
1.3 使用 ApplicationContext 获取资源
ApplicationContext 是 Spring 容器的核心接口,它不仅可以管理 Bean,还提供了资源加载功能。通过 ApplicationContext.getResource() 方法,可以访问与 ResourceLoader 相同的功能。
1.3.1 通过 ApplicationContext 加载资源
你可以通过 ApplicationContext.getResource() 方式来加载各种资源文件。
import org.springframework.context.ApplicationContext;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;@Service
public class AppContextResourceService {private final ApplicationContext applicationContext;public AppContextResourceService(ApplicationContext applicationContext) {this.applicationContext = applicationContext;}public String loadFileFromClasspath() throws IOException {// 通过 ApplicationContext 获取类路径下的文件Resource resource = applicationContext.getResource("classpath:data/example.txt");// 读取文件内容try (BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8))) {return reader.lines().reduce("", (acc, line) -> acc + line + "\n");}}public String loadFileFromFileSystem() throws IOException {// 通过 ApplicationContext 获取文件系统中的文件Resource resource = applicationContext.getResource("file:/path/to/your/file.txt");// 读取文件内容try (BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream(), StandardCharsets.UTF_8))) {return reader.lines().reduce("", (acc, line) -> acc + line + "\n");}}
}
- 这里对
ApplicationContext使用的注入方式是构造器注入 。
1.4 总结
在 Spring Boot 中,访问和管理文件资源有多种方式:
ResourceLoader:可以加载类路径、文件系统和 URL 等多种来源的文件资源,非常灵活。@Value注入:可以直接注入文件路径或者Resource对象,适合简化资源加载。ApplicationContext.getResource():通过 Spring 的ApplicationContext获取资源,提供与ResourceLoader类似的功能。
2. 文件上传与下载
在 Spring Boot 中,文件的上传与下载是常见的操作,特别是在处理 Web 应用时。Spring Boot 提供了 MultipartFile 来处理文件上传,同时通过 ResponseEntity 可以简便地实现文件下载功能。处理大文件时,常常需要考虑性能和资源管理的问题,如文件大小限制、分块上传和流式下载等。
2.1 文件上传
2.1.1 使用 MultipartFile 处理文件上传请求
Spring Boot 内置了对文件上传的支持,使用 MultipartFile 来处理上传的文件。可以通过 @RequestParam 或 @ModelAttribute 来接收文件上传请求,并将文件保存到指定路径。
示例:
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;@RestController
public class FileUploadController {private static final String UPLOAD_DIR = "uploads/";@PostMapping("/upload")public String uploadFile(@RequestParam("file") MultipartFile file) {if (file.isEmpty()) {return "上传文件为空";}try {// 确保上传目录存在Path uploadPath = Paths.get(UPLOAD_DIR);if (!Files.exists(uploadPath)) {Files.createDirectories(uploadPath);}// 保存文件到目标目录Path filePath = uploadPath.resolve(file.getOriginalFilename());file.transferTo(filePath.toFile());return "文件上传成功: " + file.getOriginalFilename();} catch (IOException e) {e.printStackTrace();return "文件上传失败";}}
}
MultipartFile:Spring 提供的接口,用于处理文件上传。可以通过file.getOriginalFilename()获取文件名,通过file.transferTo()保存文件到服务器。
2.1.2 配置文件上传路径及处理大文件上传策略
Spring Boot 提供了配置属性来限制文件上传的大小和请求体的大小,从而避免过大文件上传造成的服务器压力。你可以在 application.properties 中配置这些参数。
配置示例:
# 单个文件最大上传大小,单位为字节,10MB
spring.servlet.multipart.max-file-size=10MB
# 请求体最大大小,单位为字节,50MB
spring.servlet.multipart.max-request-size=50MB
# 配置文件上传临时路径
spring.servlet.multipart.location=/tmp/upload
2.2 文件下载
Spring Boot 提供了通过 ResponseEntity 返回文件下载响应的能力。你可以设置 Content-Type 和 Content-Disposition 头,指定文件名和下载方式。
2.2.1 使用 ResponseEntity 响应文件下载请求
ResponseEntity 可以用于向客户端返回文件,客户端可以根据响应头下载文件。
示例:
import org.springframework.core.io.Resource;
import org.springframework.core.io.UrlResource;
import org.springframework.http.HttpHeaders;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;import java.nio.file.Path;
import java.nio.file.Paths;@RestController
public class FileDownloadController {private static final String DOWNLOAD_DIR = "uploads/";@GetMapping("/download/{filename}")public ResponseEntity<Resource> downloadFile(@PathVariable String filename) {try {Path filePath = Paths.get(DOWNLOAD_DIR).resolve(filename).normalize();Resource resource = new UrlResource(filePath.toUri());if (resource.exists()) {return ResponseEntity.ok().header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + resource.getFilename() + "\"").body(resource);} else {return ResponseEntity.notFound().build();}} catch (Exception e) {e.printStackTrace();return ResponseEntity.internalServerError().build();}}
}
解释代码:
Path filePath = Paths.get(DOWNLOAD_DIR).resolve(filename).normalize();
Resource resource = new UrlResource(filePath.toUri());
-
Paths.get(DOWNLOAD_DIR):Paths.get()是一个用于构造路径对象的静态方法,它返回一个Path实例。这里的DOWNLOAD_DIR是一个字符串变量,表示文件的存储目录,例如"uploads/"。Paths.get(DOWNLOAD_DIR)相当于从文件系统中的这个路径创建一个Path对象。 -
.resolve(filename):resolve()方法用于将一个相对路径追加到已有的路径中。filename是客户端请求中传入的文件名,这样会将filename追加到DOWNLOAD_DIR路径中。例如,如果DOWNLOAD_DIR是"uploads/",filename是"test.txt",那么执行后filePath会指向"uploads/test.txt"。 -
.normalize():normalize()方法会清理路径中的冗余部分,例如去除多余的.和..。它用于确保路径是标准的和安全的。 -
new UrlResource(filePath.toUri()):UrlResource是 Spring 的Resource接口的一个实现类。filePath.toUri()将文件系统的路径转换为URI,UrlResource通过这个URI来定位资源文件。
2.2.2 配置下载时的 Content-Disposition 头部信息
Content-Disposition 头部信息用于告诉浏览器以附件(attachment)的形式下载文件,并指定文件名。通过 ResponseEntity 的 header() 方法可以设置这个信息。
return ResponseEntity.ok().header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + resource.getFilename() + "\"").body(resource);
ResponseEntity.ok():创建一个ResponseEntity对象,表示 HTTP 响应的状态是 200 OK。-
HttpHeaders.CONTENT_DISPOSITION:这个头部的值用于告诉浏览器如何处理响应内容。Content-Disposition是 HTTP 响应头中的一个属性,它可以控制浏览器如何显示文件。这里的attachment指定了文件应该以下载的方式处理,而不是直接在浏览器中展示。 -
attachment; filename="...":attachment表示告诉浏览器下载这个文件而不是直接打开。filename="..."指定了浏览器下载时建议的文件名。在这里,resource.getFilename()返回资源的实际文件名。通过这种方式,下载时浏览器会显示文件名并提示用户保存文件。 -
body(resource):将文件的内容(resource对象)作为 HTTP 响应的主体,返回给客户端。
2.3 大文件的上传与下载
处理大文件时,内存的使用和服务器的负载是重要的考虑因素。对于上传来说,分块上传是常用方案;而对于下载来说,流式下载可以有效避免内存溢出问题。
2.3.1 大文件的分块上传
大文件的上传可以通过分块上传来实现,即客户端将文件分成多个部分,逐个上传。后端接收每个块并将其合并,完成文件上传。
实现思路:
- 前端分块上传:前端将大文件切分成多个小块(例如 1MB 一块),每个块单独发送给服务器。
- 后端接收并合并:服务器接收到每一块后,暂存到一个临时目录中,等待所有块都上传完毕后再将其合并成完整文件。
配置示例:文件大小限制与临时存储目录
spring.servlet.multipart.max-file-size=10MB
spring.servlet.multipart.max-request-size=50MB
spring.servlet.multipart.location=/tmp/upload
前端文件分块上传思路
在前端,文件被分割成多个小块,每个块可以单独上传。前端将通过循环或并发请求将这些块传给服务器。每个块包含元数据信息,比如块编号、总块数等。
// 这是一个基本的前端分块上传的示例代码
const file = document.getElementById("fileInput").files[0];
const chunkSize = 1 * 1024 * 1024; // 每块大小1MB
const totalChunks = Math.ceil(file.size / chunkSize);for (let chunkIndex = 0; chunkIndex < totalChunks; chunkIndex++) {const start = chunkIndex * chunkSize;const end = Math.min(start + chunkSize, file.size);const chunk = file.slice(start, end);const formData = new FormData();formData.append("file", chunk);formData.append("chunkIndex", chunkIndex);formData.append("totalChunks", totalChunks);formData.append("fileName", file.name);fetch("/uploadChunk", {method: "POST",body: formData}).then(response => {console.log(`Chunk ${chunkIndex + 1}/${totalChunks} uploaded`);});
}
file.slice(start, end):将文件从start到end位置切片,生成每个块的数据,确保每块大小相同,最后一块可能小于指定的chunkSize。const formData = new FormData():构造FormData对象,用于包装分块数据和元数据信息,便于发送到服务器。formData.append("file", chunk):将当前块的数据添加到FormData中,chunk是从文件切片得到的数据。formData.append("chunkIndex", chunkIndex):将当前块的索引(块编号)添加到FormData中,便于后端按顺序处理文件块。formData.append("totalChunks", totalChunks):将总块数添加到FormData,使后端知道文件被分成多少块,便于合并。formData.append("fileName", file.name):将文件名添加到FormData,确保后端能够识别是哪一个文件的块。fetch("/uploadChunk", { method: "POST", body: formData }):通过fetchAPI 发送 POST 请求,将当前文件块和相关信息上传到服务器。.then(response => { ... }):在上传每块成功后执行回调函数,打印上传进度。
后端分块上传处理代码
后端负责接收这些块,并且根据块编号将它们暂时存储,等所有块上传完成后再合并。
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;@RestController
public class ChunkUploadController {private static final String UPLOAD_DIR = "uploads/";@PostMapping("/uploadChunk")public String uploadChunk(@RequestParam("file") MultipartFile file,@RequestParam("chunkIndex") int chunkIndex,@RequestParam("totalChunks") int totalChunks,@RequestParam("fileName") String fileName) {try {// 创建文件临时存储目录Path tempDir = Paths.get(UPLOAD_DIR, "temp", fileName);if (!tempDir.toFile().exists()) {tempDir.toFile().mkdirs();}// 将每一块临时存储到文件系统中File chunkFile = new File(tempDir + "/" + fileName + ".part" + chunkIndex);try (FileOutputStream out = new FileOutputStream(chunkFile)) {out.write(file.getBytes());}// 如果是最后一个块,开始合并所有文件if (chunkIndex == totalChunks - 1) {mergeChunks(fileName, totalChunks);}return "Chunk uploaded successfully";} catch (IOException e) {e.printStackTrace();return "Failed to upload chunk";}}private void mergeChunks(String fileName, int totalChunks) throws IOException {Path tempDir = Paths.get(UPLOAD_DIR, "temp", fileName);Path mergedFile = Paths.get(UPLOAD_DIR, fileName);try (FileOutputStream out = new FileOutputStream(mergedFile.toFile())) {for (int i = 0; i < totalChunks; i++) {File chunkFile = tempDir.resolve(fileName + ".part" + i).toFile();byte[] bytes = java.nio.file.Files.readAllBytes(chunkFile.toPath());out.write(bytes);chunkFile.delete(); // 合并后删除临时块文件}}tempDir.toFile().delete(); // 删除临时目录}
}
@RequestParam("file") MultipartFile file:接收前端传来的文件块,MultipartFile是 Spring 提供的用于处理文件上传的类。Path tempDir = Paths.get(UPLOAD_DIR, "temp", fileName):生成临时存储目录,用于保存每个块文件,确保每个文件的块存储在一个独立的文件夹中。if (!tempDir.toFile().exists()) { tempDir.toFile().mkdirs(); }:检查并创建临时目录,如果不存在,则创建一个用于存储块文件的目录。File chunkFile = new File(tempDir + "/" + fileName + ".part" + chunkIndex):为每个块生成一个唯一的临时文件名,块文件的命名格式为fileName.partN,其中 N 是块的索引。FileOutputStream out = new FileOutputStream(chunkFile):创建文件输出流,将当前文件块的数据写入临时文件。out.write(file.getBytes()):将当前块的数据写入到临时文件中。if (chunkIndex == totalChunks - 1):检查是否是最后一个块,如果是最后一个块,则触发文件合并操作。mergeChunks(fileName, totalChunks):调用合并方法,将所有块文件合并为一个完整的文件。for (int i = 0; i < totalChunks; i++):遍历所有块文件,按顺序读取它们的内容并写入到最终的合并文件中。byte[] bytes = java.nio.file.Files.readAllBytes(chunkFile.toPath()):读取每个块文件的字节数据。out.write(bytes):将读取到的块文件内容写入到最终合并的文件中。chunkFile.delete():合并完成后,删除临时块文件,释放存储空间。tempDir.toFile().delete():在所有块文件合并完成并删除后,删除用于存放临时文件的目录。
2.3.2 流式下载
对于大文件的下载,可以使用流式下载,即文件内容按块读取并逐步写入响应流,避免将整个文件加载到内存中。
示例:
import org.springframework.core.io.InputStreamResource;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;@RestController
public class LargeFileDownloadController {private static final String DOWNLOAD_DIR = "uploads/";@GetMapping("/stream-download/{filename}")public ResponseEntity<InputStreamResource> downloadLargeFile(@PathVariable String filename) throws FileNotFoundException {File file = new File(DOWNLOAD_DIR + filename);if (!file.exists()) {return ResponseEntity.notFound().build();}// 创建文件流FileInputStream fileInputStream = new FileInputStream(file);return ResponseEntity.ok().header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + file.getName() + "\"").contentLength(file.length()).contentType(MediaType.APPLICATION_OCTET_STREAM).body(new InputStreamResource(fileInputStream));}
}
InputStreamResource:用于将输入流作为响应体,支持流式下载。contentLength(file.length()):告知客户端文件的大小,帮助客户端预估下载进度。
2.4 总结
1. 文件上传:使用 MultipartFile 来接收文件,并配置 application.properties 来限制文件大小和请求体大小。
- 可以通过
spring.servlet.multipart.max-file-size和spring.servlet.multipart.max-request-size来设置文件上传限制。
2. 文件下载:使用 ResponseEntity 来响应下载请求,配置 Content-Disposition 头部信息确保文件作为附件下载。
3. 大文件的上传与下载:
- 分块上传:前端将文件分块上传,后端合并。
- 流式下载:使用
InputStreamResource和流式下载,避免将大文件完全加载到内存中。
3. 文件的读写操作
3.1 文件读取
文件读取可以通过多种方式完成,具体取决于文件的大小、内容格式以及读取的需求。Java NIO 提供了高效的文件读取方法,适合处理各种类型的文件。
3.1.1 使用 Files.readAllBytes()
Files.readAllBytes() 方法用于一次性将文件的所有内容读取为一个字节数组。适用于小型文件,因为一次性读取会将所有内容加载到内存中。
示例:
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.io.IOException;public class FileReadExample {public static void main(String[] args) throws IOException {Path path = Paths.get("example.txt");byte[] fileBytes = Files.readAllBytes(path); // 读取整个文件为字节数组System.out.println(new String(fileBytes)); // 打印文件内容}
}
- 一次性将文件的所有字节读取为字节数组。这适合处理小型文件。
Files.readAllBytes(path)将文件内容全部加载到内存中,因此不适合处理大文件。path是文件的路径对象。
3.1.2 使用 Files.readString()
Files.readString() 方法直接将文件的内容读取为一个字符串。它是 Java 11 引入的方法,适用于小型文本文件读取。
示例:
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.io.IOException;public class FileReadExample {public static void main(String[] args) throws IOException {Path path = Paths.get("example.txt");String content = Files.readString(path); // 读取文件为字符串System.out.println(content); // 打印文件内容}
}
- 读取文件的内容并返回为
String。适合处理小型文本文件。 Files.readString(path)直接将整个文件作为字符串返回,非常方便处理文本文件。从 Java 11 开始支持。
3.1.3 使用 Files.readAllLines()
Files.readAllLines() 方法将文件的所有行读取为 List<String>,适合逐行读取文本内容。
示例:
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.io.IOException;
import java.util.List;public class FileReadExample {public static void main(String[] args) throws IOException {Path path = Paths.get("example.txt");List<String> lines = Files.readAllLines(path); // 读取文件为行列表lines.forEach(System.out::println); // 逐行打印文件内容}
}
- 方便读取多行内容,适合配置文件、日志等逐行处理的文本。
Files.readAllLines(path)逐行读取文件内容,并将每一行存储为String,用List集合存储这些String。适合处理需要分行读取的文本文件。由于将所有行加载到内存中,不适合非常大的文件。
3.1.4 使用 BufferedReader 逐行读取大文件
当文件非常大时,不适合一次性加载到内存,可以使用 BufferedReader 进行逐行读取。
示例:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;public class LargeFileReadExample {public static void main(String[] args) {try (BufferedReader br = new BufferedReader(new FileReader("largefile.txt"))) {String line;while ((line = br.readLine()) != null) {System.out.println(line); // 逐行处理文件内容}} catch (IOException e) {e.printStackTrace();}}
}
new FileWriter("largefile.txt")
- 作用:
FileWriter是一个基础类,用于将文本数据写入到文件中。这里"largefile.txt"是要写入的文件名。FileWriter是一个不带缓冲的写入流,直接操作文件系统的 I/O 操作。 - 限制:
FileWriter本身不具备缓冲区功能,每次写入都会直接触发 I/O 操作,这样可能导致频繁的磁盘访问,降低性能,尤其在处理大量数据时。
new BufferedWriter(new FileWriter("largefile.txt"))
- 作用:
BufferedWriter是对FileWriter的增强,增加了缓冲区。使用缓冲区可以减少直接与磁盘的交互,通过缓冲区将小块数据累积起来,只有在缓冲区满了或者关闭BufferedWriter时才一次性写入磁盘。 - 关键点:
BufferedWriter内部会将数据临时存储在内存中,只有当缓冲区满或者显式调用flush()时才会触发写入磁盘的操作。这种设计减少了频繁的磁盘 I/O,显著提升了写入效率。- 通过这种 装饰器模式,即
new BufferedWriter(new FileWriter()),可以给现有的流(FileWriter)增加额外功能(缓冲功能),而无需改变FileWriter本身。
3.2 文件写入
文件写入在 Java 中也有多种方式,适用于写入文本、二进制文件等。
3.2.1 使用 Files.write() 进行文件写入
Files.write() 方法可以将字节数组或字符串写入到文件中。如果文件不存在,它会自动创建文件。
示例:写入字符串到文件
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.io.IOException;public class FileWriteExample {public static void main(String[] args) throws IOException {Path path = Paths.get("output.txt");String content = "This is a test.";Files.write(path, content.getBytes()); // 将字符串写入文件}
}
- 将字节数组或字符串写入文件。如果文件不存在,会自动创建文件。
Files.write(path, content.getBytes())将字符串转换为字节后写入文件。简单高效,适合写入小文件。
3.2.2 使用 BufferedWriter 处理大文件写入
BufferedWriter 通过使用缓冲区提高了文件写入的效率,尤其适合处理大文件写入。
示例:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;public class LargeFileWriteExample {public static void main(String[] args) {try (BufferedWriter writer = new BufferedWriter(new FileWriter("largefile.txt"))) {for (int i = 0; i < 1000; i++) {writer.write("This is line " + i); // 写入行数据writer.newLine(); // 写入换行符}} catch (IOException e) {e.printStackTrace();}}
}
- 通过缓冲区逐行写入文件内容,适合处理大文件,提高写入效率。
BufferedWriter.write()逐行写入数据,通过BufferedWriter.newLine()插入换行符。通过缓冲机制减少 I/O 操作,提高性能。
3.3 处理 JSON、XML 等格式文件
对于 JSON 和 XML 格式文件,通常需要使用第三方库来进行解析和写入。Spring Boot 提供了对 Jackson 库的良好支持,用于处理 JSON,而 XML 可以使用 Jackson 或其他库如 JAXB 处理。
3.3.1 使用 Jackson 处理 JSON 文件
Jackson 是处理 JSON 文件的最常用库。它提供了序列化和反序列化功能,可以将对象转换为 JSON 文件,或将 JSON 文件解析为对象。
读取 JSON 文件
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.File;
import java.io.IOException;public class JsonReadExample {public static void main(String[] args) throws IOException {ObjectMapper objectMapper = new ObjectMapper();User user = objectMapper.readValue(new File("user.json"), User.class); // 读取 JSON 文件为对象System.out.println(user);}
}
写入 JSON 文件
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.File;
import java.io.IOException;public class JsonWriteExample {public static void main(String[] args) throws IOException {ObjectMapper objectMapper = new ObjectMapper();User user = new User("John", "Doe");objectMapper.writeValue(new File("user.json"), user); // 将对象写入 JSON 文件}
}
ObjectMapper.writeValue用来将 Java 对象序列化为 JSON 并写入到文件。这里new File("user.json")指定要写入的目标文件,而user是需要被序列化的 Java 对象。
3.3.2 处理 XML 文件
可以使用 Jackson 的 XmlMapper 或者 JAXB 来处理 XML 文件。XmlMapper 类似于 ObjectMapper,适用于 XML 格式。
使用 XmlMapper 读取 XML 文件
import com.fasterxml.jackson.dataformat.xml.XmlMapper;
import java.io.File;
import java.io.IOException;public class XmlReadExample {public static void main(String[] args) throws IOException {XmlMapper xmlMapper = new XmlMapper();User user = xmlMapper.readValue(new File("user.xml"), User.class); // 读取 XML 文件为对象System.out.println(user);}
}
使用 XmlMapper 写入 XML 文件
import com.fasterxml.jackson.dataformat.xml.XmlMapper;
import java.io.File;
import java.io.IOException;public class XmlWriteExample {public static void main(String[] args) throws IOException {XmlMapper xmlMapper = new XmlMapper();User user = new User("John", "Doe");xmlMapper.writeValue(new File("user.xml"), user); // 将对象写入 XML 文件}
}
4. 总结
1. 文件读取:
- 使用
Files.readAllBytes()、Files.readString()、Files.readAllLines()适合小型文件。 - 使用
BufferedReader逐行读取适合大文件。
2. 文件写入:
- 使用
Files.write()写入字节或字符串到文件。 - 使用
BufferedWriter逐行写入适合处理大文件。
3. JSON/XML 文件处理:
- 使用
Jackson处理 JSON 文件,可以轻松将对象与 JSON 互相转换。 - 使用
Jackson的XmlMapper处理 XML 文件,方法类似。
4. 日志文件的管理
在 Spring Boot 中,日志记录是应用程序监控和调试的重要手段。SLF4J(Simple Logging Facade for Java)是一个通用的日志框架抽象层,它允许开发者使用统一的日志 API,而底层可以灵活绑定不同的日志实现(如 Logback、Log4j2)。Spring Boot 默认使用 SLF4J 与 Logback 组合来进行日志管理。
通过 SLF4J,开发者可以记录不同级别的日志信息,例如 TRACE、DEBUG、INFO、WARN 和 ERROR,帮助更好地跟踪应用程序的状态和错误信息,尤其在生产环境中,日志是排查问题的核心工具。
4.1 使用 @Slf4j 记录日志
@Slf4j 是由 Lombok 提供的注解,它可以简化日志记录器的创建。在 Spring Boot 中,通过添加 @Slf4j,开发者无需手动创建日志记录器,Lombok 会自动生成一个 log 对象。然后,开发者可以使用 log 对象记录不同级别的日志。
4.1.1 @Slf4j 的工作原理
当在类上使用 @Slf4j 注解时,Lombok 自动生成了一个名为 log 的日志记录器实例。开发者可以通过 log.info()、log.debug()、log.warn()、log.error()、log.trace() 等方法,在不同的场景下记录相应级别的日志信息。
4.1.2 log 对象的日志级别
log 对象提供了多种日志级别,每个日志级别代表不同的日志重要性和记录目的。Spring Boot 默认支持以下日志级别(从高到低):
ERROR:表示严重错误,通常是应用程序无法继续运行的异常情况。WARN:表示可能存在问题,但程序可以继续运行。INFO:表示应用程序的正常运行状态,可以帮助跟踪应用程序的主要流程。DEBUG:表示详细的调试信息,通常用于开发和调试环境,不建议在生产环境中启用。TRACE:表示非常详细的跟踪信息,通常用于极度精细的调试场景。
4.1.3 日志记录示例
以下是一个使用 @Slf4j 注解的 Spring Boot 控制器示例,展示了如何记录不同级别的日志信息。
示例代码:
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@Slf4j // Lombok 自动生成 log 对象
public class LogController {@GetMapping("/log")public String logExample() {log.info("Info level log message"); // 记录 INFO 级别日志log.debug("Debug level log message"); // 记录 DEBUG 级别日志log.warn("Warn level log message"); // 记录 WARN 级别日志log.error("Error level log message"); // 记录 ERROR 级别日志return "Log example completed";}
}
4.1.4 五种日志记录方法的区别
-
log.trace():用于记录非常详细的追踪信息,一般用于调试时追踪程序执行的最细节步骤。通常仅在开发环境使用,生产环境中几乎不会启用。 -
log.debug():用于记录调试信息,帮助开发者了解应用程序内部的运行逻辑。常用于开发和测试环境,生产环境中也很少启用。 -
log.info():用于记录系统的常规操作状态,比如系统启动、请求处理、用户登录等。适用于生产环境,帮助运维团队了解应用程序的正常运行情况。 -
log.warn():用于记录警告信息,表明应用程序可能出现非预期的情况,但程序仍可以继续运行。这通常用于标记可能需要注意的问题。 -
log.error():用于记录严重错误信息,表明应用程序遇到了无法正常继续运行的错误。开发者可以通过这些日志快速定位问题的根源,帮助修复错误。
4.1.5 控制日志级别输出
日志级别的输出可以通过配置文件来控制。在 Spring Boot 中,日志输出通常由 application.properties 或 logback-spring.xml 配置文件来管理。如果日志级别设置为 INFO,则 DEBUG 和 TRACE 级别的日志将不会输出。通过配置文件,开发者可以灵活控制不同环境下的日志输出。
示例:配置日志级别为 INFO
# 全局日志级别设置为 INFO,忽略 DEBUG 和 TRACE 级别日志
logging.level.root=INFO# 对特定包启用 DEBUG 级别日志
logging.level.com.example=DEBUG
logging.level.root=INFO:设置全局日志级别为INFO,表示只输出INFO级别及以上的日志(即INFO、WARN、ERROR),忽略DEBUG和TRACE级别日志。logging.level.com.example=DEBUG:对指定包com.example启用DEBUG级别日志,适合对特定模块进行详细调试。
4.2 配置日志文件存储路径和滚动策略
Spring Boot 使用 Logback 作为默认的日志框架,提供了灵活的日志文件管理功能。通过配置文件,开发者可以控制日志的输出路径、日志文件的大小限制、日志保存时间等。
4.2.1 日志文件存储路径配置
在 application.properties 文件中,开发者可以自定义日志文件的输出路径、文件名、文件大小和日志保存历史等参数。
示例:
# 配置日志文件的路径和文件名
logging.file.name=logs/myapp.log# 设置日志文件的最大大小,文件超过 10MB 后滚动生成新文件
logging.file.max-size=10MB# 设置日志文件的最大保留天数,最多保留 7 个历史文件
logging.file.max-history=7
logging.file.name:指定日志文件的存储路径和文件名。如果没有指定,日志将输出到控制台。logging.file.max-size:设置日志文件的最大大小,超过此大小后,日志系统会滚动生成新文件。logging.file.max-history:设置保留的历史日志文件数量,超过这个数量的旧日志文件将被删除。
4.2.2 复杂的日志滚动策略
当需要更复杂的日志管理(如按时间滚动、文件压缩、删除旧日志等),可以通过 logback-spring.xml 文件进行详细配置。Logback 提供了丰富的日志管理功能,可以按时间或文件大小滚动日志文件,并支持自动压缩和删除旧日志。
示例:
<configuration><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>logs/myapp.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 按日期和大小滚动日志文件 --><fileNamePattern>logs/myapp-%d{yyyy-MM-dd}.%i.log</fileNamePattern><!-- 单个日志文件最大大小 --><maxFileSize>10MB</maxFileSize><!-- 保存的历史日志文件天数 --><maxHistory>7</maxHistory></rollingPolicy><encoder><!-- 日志格式 --><pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><root level="INFO"><appender-ref ref="FILE" /></root>
</configuration>
RollingFileAppender:定义日志滚动的策略,使用时间和文件大小进行日志文件的切换。TimeBasedRollingPolicy:基于时间(如按天)和文件大小(如 10MB)进行日志滚动。maxFileSize:每个日志文件的最大大小,超过此大小后会创建新的文件。maxHistory:最大日志保存天数,超过此时间的旧日志文件会被删除。pattern:定义日志的输出格式,如时间戳、线程名、日志级别和日志消息。
5. 文件的异常处理
在处理文件操作时,异常是不可避免的。Java 提供了多种异常类来处理文件操作过程中的问题,如 IOException、FileNotFoundException 等。为了保证应用程序的稳定性,开发者需要对这些异常进行适当的处理,尤其是在生产环境中,确保异常不会导致程序崩溃。Spring Boot 也提供了全局异常处理机制,可以通过 @ControllerAdvice 进行统一处理文件操作中的异常。
5.1 文件操作的常见异常
文件操作涉及的异常通常与 I/O(输入/输出)相关。以下是文件操作中常见的异常及其处理方式。
5.1.1 IOException
IOException 是文件操作过程中最常见的异常之一。它是 Java 中的通用 I/O 异常类,表示在读、写、关闭流或文件时出现的任何输入输出问题。
示例:
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;public class FileIOExceptionExample {public void writeFile(String content, String path) {try (FileWriter writer = new FileWriter(new File(path))) {writer.write(content);} catch (IOException e) {// 处理 IOExceptionSystem.err.println("An I/O error occurred: " + e.getMessage());e.printStackTrace();}}
}
- 常见原因:如文件系统不可写、文件权限不足、磁盘空间不足等。
- 处理方式:通过
try-catch块捕获异常并记录错误日志,避免应用程序崩溃。
代码解释:
System.err:标准错误流,通常用于输出错误信息,默认情况下也会输出到控制台。和System.out类似,但专门用于显示错误或异常信息。常见的使用场景是将异常信息输出到控制台。e.printStackTrace()会打印异常发生时的调用链,开发者可以通过这条链追踪到错误的源头,快速调试程序。
5.1.2 FileNotFoundException
FileNotFoundException 是 IOException 的子类,表示程序尝试打开的文件不存在或文件路径无效。通常在读取文件时可能发生。
示例:
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;public class FileNotFoundExceptionExample {public void readFile(String path) {try (Scanner scanner = new Scanner(new File(path))) {while (scanner.hasNextLine()) {System.out.println(scanner.nextLine());}} catch (FileNotFoundException e) {// 处理 FileNotFoundExceptionSystem.err.println("File not found: " + e.getMessage());}}
}
- 常见原因:文件路径不正确,文件被移动或删除。
- 处理方式:提示用户文件不存在,并建议检查文件路径是否正确。
5.1.3 其他常见异常
SecurityException:当应用程序没有访问文件的权限时,会抛出此异常。EOFException:表示文件结束异常,通常在读取超出文件内容时发生。
5.1.4 try-with-resources 语法
在处理文件操作时,使用 try-with-resources 是一种最佳实践。这种语法确保在完成文件操作后,资源(如文件流)会自动关闭,避免资源泄漏问题。
示例:
public void readFileWithResources(String path) {try (FileReader fileReader = new FileReader(new File(path))) {// 读取文件} catch (IOException e) {// 处理 IOException 和其子类System.err.println("Error occurred: " + e.getMessage());}
}
- 优点:无需显式调用
close()方法,资源会自动关闭,避免了可能的资源泄漏。
5.2 全局异常处理
在实际开发中,单独为每个文件操作编写 try-catch 代码会导致代码冗余。Spring Boot 提供了全局异常处理机制,允许开发者通过 @ControllerAdvice 统一处理应用程序中的异常,包括文件操作异常。
5.2.1 使用 @ControllerAdvice 处理文件操作中的异常
@ControllerAdvice 是 Spring 提供的全局异常处理注解,能够集中处理应用中的所有异常,包括文件操作异常。结合 @ExceptionHandler 注解,可以为特定的异常类型提供处理逻辑。
示例:全局异常处理文件操作
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.http.ResponseEntity;
import java.io.FileNotFoundException;
import java.io.IOException;@ControllerAdvice
public class GlobalExceptionHandler {// 处理 FileNotFoundException 异常@ExceptionHandler(FileNotFoundException.class)public ResponseEntity<String> handleFileNotFound(FileNotFoundException e) {// 返回自定义的响应和状态码return ResponseEntity.status(404).body("File not found: " + e.getMessage());}// 处理 IOException 异常@ExceptionHandler(IOException.class)public ResponseEntity<String> handleIOException(IOException e) {// 返回自定义的响应和状态码return ResponseEntity.status(500).body("I/O error occurred: " + e.getMessage());}
}
@ExceptionHandler(FileNotFoundException.class):捕获所有FileNotFoundException异常,并返回自定义的 404 状态码和错误消息。@ExceptionHandler(IOException.class):捕获所有IOException异常,并返回自定义的 500 状态码,表示服务器发生 I/O 错误。
5.2.2 在实际方法中捕获异常
当你定义了 @ExceptionHandler(FileNotFoundException.class) 方法后,Spring 会自动捕获所有抛出的 FileNotFoundException 异常,并通过该方法处理异常响应。你无需在具体的方法中手动捕获该异常,而是可以将异常的处理逻辑统一到全局异常处理类中。
示例:在控制器中抛出异常
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.File;
import java.io.FileNotFoundException;
import java.util.Scanner;@RestController
public class FileController {@GetMapping("/read-file")public String readFile() throws FileNotFoundException {File file = new File("nonexistentfile.txt");Scanner scanner = new Scanner(file); // 如果文件不存在,会抛出 FileNotFoundExceptionreturn "File read successfully";}
}
5.3 总结
文件操作的常见异常:
- 主要涉及
IOException、FileNotFoundException等异常,通过try-catch块进行捕获和处理,确保程序在文件操作失败时不会崩溃。 - 使用
try-with-resources可以自动关闭资源,避免资源泄漏问题。
全局异常处理:
- 使用
@ControllerAdvice和@ExceptionHandler处理文件操作中的异常,实现统一的异常处理逻辑。 - 全局异常处理不仅简化了代码,还提供了统一的错误响应格式,提升了应用程序的健壮性和可维护性。
6. 安全性与权限控制
在处理文件上传、下载等操作时,确保文件访问的安全性和权限控制是非常重要的。Spring Boot 提供了强大的 Spring Security 框架,用于实现访问控制和权限验证。同时,开发者还需要注意处理文件路径,以防止目录遍历攻击等安全问题。
6.1 文件访问的权限控制
通过 Spring Security,可以控制用户对文件上传、下载等操作的权限,确保只有授权用户才能执行这些敏感操作。这种权限控制可以基于角色、用户、URL、方法等多种方式进行配置。
6.1.1 文件上传与下载的权限控制
在实际应用中,文件上传和下载功能需要根据用户的权限进行控制。例如,只有管理员或特定用户组可以上传文件,而普通用户只能查看或下载文件。
配置示例:使用 Spring Security 控制文件上传与下载
首先,在 SecurityConfig 类中配置权限控制逻辑。确保文件上传和下载的 URL 仅对有特定权限的用户开放。
import org.springframework.context.annotation.Bean;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {@Overrideprotected void configure(HttpSecurity http) throws Exception {http.authorizeRequests()// 配置上传文件的权限:需要 ADMIN 角色.antMatchers("/upload").hasRole("ADMIN")// 配置下载文件的权限:所有经过认证的用户都可以下载.antMatchers("/download/**").authenticated()// 其他所有请求允许匿名访问.anyRequest().permitAll().and().formLogin().and().logout().permitAll();}
}
6.1.2 基于方法的权限控制
除了基于 URL 的权限控制,Spring Security 还支持基于方法的权限控制。通过 @PreAuthorize 注解,可以在文件处理的具体方法上设置权限。
示例:在文件上传方法上设置权限
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.web.bind.annotation.RestController;@RestController
public class FileController {@PostMapping("/upload")@PreAuthorize("hasRole('ADMIN')") // 仅 ADMIN 角色可以上传文件public String uploadFile(@RequestParam("file") MultipartFile file) {// 上传文件逻辑return "File uploaded successfully!";}@GetMapping("/download/{filename}")@PreAuthorize("isAuthenticated()") // 仅经过认证的用户可以下载文件public ResponseEntity<Resource> downloadFile(@PathVariable String filename) {// 文件下载逻辑}
}
@PreAuthorize注解:用于方法级别的权限控制,hasRole('ADMIN')表示只有拥有ADMIN角色的用户才能调用该方法。
6.2 防止目录遍历攻击
目录遍历攻击(Directory Traversal Attack)是一种安全漏洞,攻击者通过操控输入的文件路径,试图访问应用程序未授权的文件或目录。通常,攻击者通过构造相对路径符号(如 ../)来绕过系统的目录访问限制,从而访问系统中的敏感文件或资源。为了防止这种攻击,开发者需要采取安全的路径处理和验证方法。
6.2.1 目录遍历攻击的原理
目录遍历攻击的目标是通过操控文件路径让应用程序访问到超出预期范围的文件或目录。攻击者利用相对路径中的 ../(父目录符号)跳出合法目录,访问敏感文件,例如系统配置文件、密码文件等。
示例:
假设应用程序允许下载文件,并且文件存储在 uploads/ 目录中。
正常请求:
http://example.com/download?file=myfile.txt
- 访问文件:
uploads/myfile.txt
攻击请求:
http://example.com/download?file=../../etc/passwd
- 如果没有正确处理,应用程序可能会访问:
/etc/passwd(Linux 系统的用户密码文件)。
6.2.2 如何防止目录遍历攻击
为了防止目录遍历攻击,开发者可以通过使用 Java NIO 提供的 Paths.get()、resolve() 和 normalize() 方法来确保路径的合法性,并在操作前对路径进行验证。
1. 使用 Paths.get() 和 resolve() 方法构建安全路径
-
Paths.get():用于安全地将字符串路径转换为Path对象,避免直接拼接字符串带来的安全问题。手动拼接路径可能导致安全隐患,而Paths.get()能确保路径的正确解析。
-
resolve():用于将相对路径与基准路径拼接,确保路径合法。resolve()能够避免通过相对路径符号(如../)跳出指定目录的攻击手段。
示例:
Path basePath = Paths.get("mysource", "uploads");
Path filePath = basePath.resolve("myfile.txt"); // 结果是 "mysource/uploads/myfile.txt"
解释:
Paths.get()可以用来生成一个目录路径或包含文件名的完整路径。所以Paths.get()中如果将路径与路径拼接,则文件名的拼接交给resolve处理,如果Paths.get()将路径与文件名进行了拼接,则不需要resolve。resolve()用来将文件名拼接到已有的路径对象上。- 一般情况下,使用
Paths.get()来构建一个路径对象,路径中可以是多级目录,再通过resolve()拼接文件名。
2. 使用 normalize() 方法标准化路径
- 作用:
normalize()方法用于清理路径中的冗余部分,特别是移除相对路径中的../,从而防止目录遍历攻击。通过标准化路径,可以消除恶意用户通过相对路径符号绕过目录限制的企图。
示例:
Path filePath = Paths.get("uploads").resolve("../etc/passwd").normalize();
// 结果是标准化路径,可以通过进一步的路径验证确保安全
- 解释:即使用户试图通过
../来访问上层目录,调用normalize()后,路径会被标准化,去掉非法部分,确保最终路径安全。
3. 路径验证
在处理文件路径时,需要验证用户输入的路径是否仍然在合法的目录范围内。通过检查路径是否以指定的合法目录开头,防止目录遍历攻击。
示例:
if (!filePath.startsWith(Paths.get("uploads"))) {throw new SecurityException("Illegal file access attempt!");
}
解释:
filePath.startsWith():此方法用于检查一个路径是否以特定的根路径(如uploads目录)开头。它返回true或false,根据路径是否在指定的基础目录中决定。Paths.get("uploads"):这是你应用程序中允许访问的合法上传目录。例如,uploads可能是存储用户上传文件的根目录。filePath.startsWith(Paths.get("uploads"))检查filePath是否位于uploads目录中。如果返回false,则说明用户可能尝试通过目录遍历攻击访问系统中的其他敏感文件。
6.2.3 完整防御示例
通过 Paths.get()、resolve()、normalize() 和路径验证,可以防止目录遍历攻击,确保文件路径在合法范围内。
示例代码:
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.Files;
import java.nio.file.InvalidPathException;
import org.springframework.core.io.Resource;
import org.springframework.core.io.UrlResource;
import org.springframework.http.HttpHeaders;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;@RestController
public class FileController {private static final String UPLOAD_DIR = "uploads/";@GetMapping("/download/{filename}")public ResponseEntity<Resource> downloadFile(@PathVariable String filename) {try {// 构建文件路径,并对用户输入的文件名进行标准化处理Path filePath = Paths.get(UPLOAD_DIR).resolve(filename).normalize();// 验证路径是否仍然在合法的目录范围内,防止目录遍历攻击if (!filePath.startsWith(Paths.get(UPLOAD_DIR))) {throw new SecurityException("Illegal file access attempt!");}// 加载并返回文件资源Resource resource = new UrlResource(filePath.toUri());if (resource.exists()) {return ResponseEntity.ok().header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + resource.getFilename() + "\"").body(resource);} else {return ResponseEntity.notFound().build();}} catch (InvalidPathException | IOException e) {return ResponseEntity.internalServerError().build();}}
}
关键步骤:
- 路径安全拼接:使用
Paths.get()和resolve()安全构建路径,避免直接使用字符串拼接。 - 路径标准化:通过
normalize()移除路径中的../等不合法符号,防止目录遍历攻击。 - 路径验证:确保标准化后的路径仍然在合法的目录范围内,防止访问不应公开的文件。
6.3 总结
1. 文件访问的权限控制:
- 通过
Spring Security控制文件上传和下载权限,确保只有授权用户能够执行这些操作。 - 可以通过 URL 级别和方法级别(使用
@PreAuthorize)的方式实现权限控制。
2. 防止目录遍历攻击:
- 使用安全的路径处理方法(如
Paths.get()、normalize()),确保用户输入的文件路径不会导致非法访问。 - 严格限制文件访问范围,验证路径始终在允许的目录中,防止攻击者利用恶意路径获取敏感文件。
7. 与云存储的集成
在现代应用程序中,将文件存储在云端而不是本地存储已经成为常见的做法。通过集成云存储服务,可以实现大规模、安全、便捷的文件管理。常见的云存储服务包括阿里云 OSS(对象存储服务)和腾讯云 COS(对象存储服务)。这些服务不仅提供了文件上传和下载的基础功能,还支持文件管理、备份、访问控制等功能。
7.1 与阿里云 OSS 或腾讯云 COS 的集成
阿里云 OSS 和腾讯云 COS 是常用的云存储服务,分别提供了用于文件管理的 API 接口,允许开发者将文件上传到云端,或从云端下载、管理文件。
7.1.1 集成步骤概述
1. 创建云存储服务账号:
在阿里云或腾讯云上注册账号,进入云存储服务(OSS 或 COS)控制台,创建存储空间(Bucket),并获取 API 密钥和相关配置。
2. 引入 SDK:
使用官方提供的 SDK,可以轻松集成 OSS 或 COS 的功能。
阿里云 OSS SDK:https://help.aliyun.com/document_detail/32008.html
腾讯云 COS SDK:https://cloud.tencent.com/document/product/436/10199
3. 配置云存储的访问凭证:
在 Spring Boot 项目中,将云存储服务的 API 密钥、存储空间名称等配置放入 application.properties 文件中。
示例:阿里云 OSS 配置
# 阿里云 OSS 配置
aliyun.oss.endpoint=oss-cn-hangzhou.aliyuncs.com
aliyun.oss.access-key-id=<your-access-key-id>
aliyun.oss.access-key-secret=<your-access-key-secret>
aliyun.oss.bucket-name=<your-bucket-name>
示例:腾讯云 COS 配置
# 腾讯云 COS 配置
tencent.cos.region=ap-guangzhou
tencent.cos.secret-id=<your-secret-id>
tencent.cos.secret-key=<your-secret-key>
tencent.cos.bucket-name=<your-bucket-name>
7.1.2 引入 Maven 依赖
在 Spring Boot 项目中,通过 Maven 引入相应的云存储 SDK。
阿里云 OSS SDK 依赖
<dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.13.0</version>
</dependency>
腾讯云 COS SDK 依赖
<dependency><groupId>com.qcloud</groupId><artifactId>cos_api</artifactId><version>5.6.10</version>
</dependency>
7.1.3 初始化客户端
在 Spring Boot 中,需要通过配置类或服务类来初始化云存储服务的客户端。
阿里云 OSS 客户端初始化示例
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class OssConfig {@Value("${aliyun.oss.endpoint}")private String endpoint;@Value("${aliyun.oss.access-key-id}")private String accessKeyId;@Value("${aliyun.oss.access-key-secret}")private String accessKeySecret;@Beanpublic OSS ossClient() {return new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);}
}
腾讯云 COS 客户端初始化示例
import com.qcloud.cos.COSClient;
import com.qcloud.cos.ClientConfig;
import com.qcloud.cos.auth.BasicCOSCredentials;
import com.qcloud.cos.region.Region;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class CosConfig {@Value("${tencent.cos.secret-id}")private String secretId;@Value("${tencent.cos.secret-key}")private String secretKey;@Value("${tencent.cos.region}")private String region;@Beanpublic COSClient cosClient() {BasicCOSCredentials credentials = new BasicCOSCredentials(secretId, secretKey);ClientConfig clientConfig = new ClientConfig(new Region(region));return new COSClient(credentials, clientConfig);}
}
7.2 文件的云端管理
文件的云端管理包括文件上传、下载和删除等基本操作。在集成了云存储服务(如阿里云 OSS 或腾讯云 COS)之后,开发者可以通过 SDK 或 REST API 对文件进行云端管理操作。这不仅能有效管理大量文件,还能确保文件的高可用性、安全性和可扩展性。下面详细讲解如何通过阿里云 OSS 和腾讯云 COS 进行文件的上传、下载和删除。
7.2.1 文件上传
阿里云 OSS 文件上传示例
在阿里云 OSS 中,文件上传通过 putObject() 方法实现。你需要提供存储空间的 bucket 名称、文件的名称以及文件的输入流。
import com.aliyun.oss.OSS;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import java.io.IOException;@RestController
public class OssController {@Autowiredprivate OSS ossClient;@Value("${aliyun.oss.bucket-name}")private String bucketName;@PostMapping("/upload")public String uploadFile(@RequestParam("file") MultipartFile file) throws IOException {String fileName = file.getOriginalFilename();ossClient.putObject(bucketName, fileName, file.getInputStream()); // 上传文件到云端return "File uploaded successfully!";}
}
MultipartFile:Spring MVC 提供的文件类型,代表从前端上传的文件。ossClient.putObject():用于将文件上传到阿里云 OSS。传入参数包括存储桶名称、文件名和文件输入流。
腾讯云 COS 文件上传示例
腾讯云 COS 的文件上传通过 putObject() 方法实现,类似于阿里云 OSS。
import com.qcloud.cos.COSClient;
import com.qcloud.cos.model.PutObjectRequest;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import java.io.File;
import java.io.IOException;@RestController
public class CosController {@Autowiredprivate COSClient cosClient;@Value("${tencent.cos.bucket-name}")private String bucketName;@PostMapping("/upload")public String uploadFile(@RequestParam("file") MultipartFile file) throws IOException {File localFile = convertMultipartFileToFile(file); // 将文件转换为本地文件PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName, file.getOriginalFilename(), localFile);cosClient.putObject(putObjectRequest); // 上传文件到腾讯云 COSreturn "File uploaded successfully!";}// 将 MultipartFile 转换为本地文件private File convertMultipartFileToFile(MultipartFile file) throws IOException {File convFile = new File(System.getProperty("java.io.tmpdir") + "/" + file.getOriginalFilename());file.transferTo(convFile);return convFile;}
}
MultipartFile:前端上传的文件。PutObjectRequest:封装文件上传请求。上传时需指定存储桶名称、文件名和本地文件路径。- 本地文件转换:由于 COS SDK 需要本地文件,因此先将
MultipartFile转换为File,再通过putObject()上传。
7.2.2 文件下载
文件下载是通过云存储服务提供的 getObject() 方法获取文件,并将文件流返回给客户端。
阿里云 OSS 文件下载示例
import com.aliyun.oss.model.OSSObject;
import org.springframework.web.bind.annotation.*;import javax.servlet.http.HttpServletResponse;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.IOException;@RestController
public class OssDownloadController {@Autowiredprivate OSS ossClient;@Value("${aliyun.oss.bucket-name}")private String bucketName;@GetMapping("/download/{fileName}")public void downloadFile(@PathVariable String fileName, HttpServletResponse response) throws IOException {// 从 OSS 获取文件OSSObject ossObject = ossClient.getObject(bucketName, fileName);try (InputStream inputStream = ossObject.getObjectContent();OutputStream outputStream = response.getOutputStream()) {byte[] buffer = new byte[1024];int length;while ((length = inputStream.read(buffer)) != -1) {outputStream.write(buffer, 0, length); // 将文件内容写入响应}}}
}
ossClient.getObject():用于从 OSS 获取指定文件。response.getOutputStream():通过 HTTP 响应流将文件内容返回给客户端,支持文件下载功能。
腾讯云 COS 文件下载示例
import com.qcloud.cos.model.COSObject;
import org.springframework.web.bind.annotation.*;import javax.servlet.http.HttpServletResponse;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.IOException;@RestController
public class CosDownloadController {@Autowiredprivate COSClient cosClient;@Value("${tencent.cos.bucket-name}")private String bucketName;@GetMapping("/download/{fileName}")public void downloadFile(@PathVariable String fileName, HttpServletResponse response) throws IOException {// 从 COS 获取文件COSObject cosObject = cosClient.getObject(bucketName, fileName);try (InputStream inputStream = cosObject.getObjectContent();OutputStream outputStream = response.getOutputStream()) {byte[] buffer = new byte[1024];int length;while ((length = inputStream.read(buffer)) != -1) {outputStream.write(buffer, 0, length); // 将文件内容写入响应}}}
}
cosClient.getObject():用于从 COS 获取指定文件。- 通过 HTTP 响应流返回文件:将文件流写入
response.getOutputStream(),客户端通过 HTTP 请求下载文件。
7.2.3 文件删除
文件删除操作使用 deleteObject() 方法来删除云端存储的文件。
阿里云 OSS 文件删除示例
import org.springframework.web.bind.annotation.*;@RestController
public class OssDeleteController {@Autowiredprivate OSS ossClient;@Value("${aliyun.oss.bucket-name}")private String bucketName;@DeleteMapping("/delete/{fileName}")public String deleteFile(@PathVariable String fileName) {ossClient.deleteObject(bucketName, fileName); // 删除 OSS 上的文件return "File deleted successfully!";}
}
ossClient.deleteObject():用于删除 OSS 中的文件。提供存储桶名称和文件名即可删除指定文件。
腾讯云 COS 文件删除示例
import org.springframework.web.bind.annotation.*;@RestController
public class CosDeleteController {@Autowiredprivate COSClient cosClient;@Value("${tencent.cos.bucket-name}")private String bucketName;@DeleteMapping("/delete/{fileName}")public String deleteFile(@PathVariable String fileName) {cosClient.deleteObject(bucketName, fileName); // 删除 COS 上的文件return "File deleted successfully!";}
}
cosClient.deleteObject():用于删除 COS 中的文件。传入存储桶名称和文件名,即可删除指定文件。
8. 文件操作中的性能优化
在 Java 中进行文件操作时,处理大文件或频繁的文件读写操作可能会引发性能瓶颈。通过优化文件的 I/O(输入/输出)操作,可以显著提高程序的性能。性能优化的方式主要包括使用缓冲流和 Java NIO(New I/O)来减少阻塞,提高文件读写效率,尤其在处理大文件时,这些技术尤为关键。
8.1 使用缓冲流提高文件读写性能
Java I/O 包中的 缓冲流 提供了一种高效的文件读写方式。默认情况下,直接使用 FileReader、FileWriter 等类进行读写操作时,每次读写操作都会访问磁盘,这可能导致性能下降。通过使用缓冲流(BufferedReader 和 BufferedWriter),可以显著减少对磁盘的直接访问,提升文件 I/O 的效率。
8.1.1 BufferedReader 和 BufferedWriter 的作用
-
BufferedReader:用于缓冲字符输入流,提供更高效的读取操作,尤其是逐行读取文件时。它减少了磁盘访问次数,通过内存缓冲区来提升读取速度。 -
BufferedWriter:用于缓冲字符输出流,减少每次写操作对磁盘的访问,尤其是在频繁写入的情况下。BufferedWriter通过将数据存储到内存缓冲区,再统一写入磁盘,提升写入性能。
8.1.2 具体使用
BufferedReader 示例:读取文件
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;public class BufferedReaderExample {public void readFile(String filePath) throws IOException {try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {String line;while ((line = reader.readLine()) != null) {System.out.println(line);}}}
}
- 解释:
BufferedReader通过内部缓冲机制减少对文件的逐行读取操作,每次读取较大的块,而不是每次直接从文件读取一行。这样可以大大提高性能,尤其是在读取大文件时。
BufferedWriter 示例:写入文件
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;public class BufferedWriterExample {public void writeFile(String filePath, String content) throws IOException {try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {writer.write(content);}}
}
- 解释:
BufferedWriter通过在内存中收集一定量的数据后再一次性写入文件,避免了每次写操作都直接访问磁盘,从而提高了写入性能。
8.1.3 性能提升的原理
-
减少 I/O 操作:每次 I/O 操作(如读取或写入)都涉及到操作系统和硬件层的交互,而这些操作通常是性能瓶颈。使用缓冲流可以通过批量操作来减少这种交互次数,从而提高整体性能。
-
内存缓冲区:通过使用缓冲区,将小块数据暂存在内存中,只有当缓冲区满时才写入文件或从文件中读取,避免频繁访问磁盘。
8.2 使用 NIO 非阻塞 IO 进行大文件处理
Java NIO(New Input/Output)引入了一种更高效的文件操作方式,尤其是在处理大文件时,NIO 提供的 FileChannel 和 MappedByteBuffer 等类能够显著提升性能。通过这些类,程序可以直接操作文件的字节,而不是像传统 IO 一样必须经过缓慢的流式读取和写入。尤其在处理大文件时,NIO 的非阻塞特性可以减少文件操作的阻塞等待,提高整体响应性能。
Java NIO(New I/O)引入了一种高效的文件处理机制,特别是对于大文件。NIO 的核心是通道(Channel)和缓冲区(Buffer)的模型,这比传统的流式 I/O 更加高效和灵活,尤其适用于非阻塞 I/O 操作。
8.2.1 FileChannel 的基本用法
FileChannel 是专门用于操作文件的通道类,支持对文件进行高效的读写操作,并且允许随机访问文件的任何位置。它不直接与文件交互,而是通过 ByteBuffer 作为缓冲区来操作数据。
FileChannel 的创建
从 RandomAccessFile 创建 FileChannel
FileChannel 可以通过 RandomAccessFile 的 getChannel() 方法获取。RandomAccessFile 允许读写文件的任意位置,因此配合 FileChannel 可以实现随机访问。
RandomAccessFile file = new RandomAccessFile("example.txt", "rw");
FileChannel fileChannel = file.getChannel();
从 FileInputStream 或 FileOutputStream 获取
如果只需要文件的读取或写入功能,可以通过 FileInputStream 或 FileOutputStream 的 getChannel() 方法获取 FileChannel。
FileInputStream fis = new FileInputStream("example.txt");
FileChannel readChannel = fis.getChannel();FileOutputStream fos = new FileOutputStream("example.txt");
FileChannel writeChannel = fos.getChannel();
FileChannel 的基本操作
1. 读取数据到缓冲区(ByteBuffer)
ByteBuffer buffer = ByteBuffer.allocate(1024); // 分配缓冲区
int bytesRead = fileChannel.read(buffer); // 读取数据到缓冲区
buffer.flip(); // 准备读取缓冲区内容
- 使用
FileChannel.read(ByteBuffer)方法可以将数据从文件通道读取到缓冲区中。
2. 从缓冲区写入数据到文件
ByteBuffer buffer = ByteBuffer.wrap("Hello World!".getBytes());
fileChannel.write(buffer); // 将缓冲区内容写入文件
- 使用
FileChannel.write(ByteBuffer)方法可以将缓冲区中的数据写入文件。
3. 随机访问文件
fileChannel.position(100); // 跳到文件的第100字节处
fileChannel.read(buffer); // 从该位置读取数据
- 通过
position(long newPosition)方法,FileChannel支持文件的随机读写。可以跳转到文件中的任意位置进行操作。
4. 文件截断
fileChannel.truncate(1024); // 将文件大小截断为1024字节
truncate(long size)方法用于截断文件,文件的大小将被调整为给定的大小。超出该大小的部分将被丢弃。
5. 强制将缓冲区的数据刷写到磁盘
fileChannel.force(true); // 强制将文件内容和元数据写入磁盘
force(boolean metaData)方法用于确保所有文件数据(以及文件的元数据)被同步写入到磁盘,避免数据丢失。
8.2.2 缓冲区(Buffer)
缓冲区(Buffer)是 Java NIO 中用于处理数据的核心部分。它是一块内存区域,提供了存储数据的能力,特别适合 I/O 操作。缓冲区将数据从通道中读入或从程序中写出到通道。缓冲区不仅在文件操作中使用,还可以用于网络传输等场景。
缓冲区的类型
根据存储的数据类型不同,Java NIO 提供了多种缓冲区类型。每种缓冲区对应不同的数据类型,它们继承自 Buffer 类。常见的缓冲区包括:
ByteBuffer:字节缓冲区,处理字节数据。CharBuffer:字符缓冲区,处理字符数据。IntBuffer、FloatBuffer、DoubleBuffer等:处理不同基本数据类型的缓冲区。
缓冲区的属性
每个缓冲区都有一些重要的属性,这些属性决定了缓冲区在读写数据时的状态和行为。这些属性包括 capacity、position、limit 和 mark。
1.capacity(容量)
缓冲区的容量表示它最多能容纳的数据元素个数。容量是创建缓冲区时确定的,并且不能改变。
2.position(位置)
缓冲区的当前位置,用于指示下一个要读或写的元素的索引。缓冲区的 position 会随着数据的读写操作自动更新。
3.limit(限制)
缓冲区的限制是指在写模式下,限制你能写入的数据量。在读模式下,限制是缓冲区中可以读取的数据的数量。通常当缓冲区从写模式切换到读模式时,会将 limit 设置为数据的实际大小。
4.mark(标记)
标记用于记录缓冲区中的某个特定位置。你可以在稍后调用 reset() 方法恢复到该位置。mark 通常用于在某个地方做标记以便后续回退到这个位置。
5.缓冲区属性的关系:
capacity:缓冲区的总大小,不能改变。position:当前正在处理的位置,指向缓冲区的某个索引。limit:限制当前能读写的最大位置。mark:做标记,可以用来回退到某个位置。
缓冲区的使用状态主要有两种:
- 写模式:通常在将数据写入缓冲区时使用,这时
position表示下一个写入的位置,limit通常等于capacity。 - 读模式:当缓冲区切换为读模式(例如在调用
flip()之后),position被重置为 0,limit设置为缓冲区的写入位置,表示可以读取的有效数据范围。
缓冲区的常用方法
1.flip()
buffer.flip(); // 切换到读模式
将缓冲区从写模式切换到读模式。调用 flip() 后,limit 被设置为当前的 position,而 position 被重置为 0,表示从缓冲区的头开始读取数据。
2.clear()
buffer.clear(); // 清除缓冲区,准备重新写入数据
清除缓冲区,准备再次写入数据。clear() 并不会清除缓冲区中的数据,只是将 position 置为 0,limit 置为 capacity,表示可以重新写入数据。
3.rewind()
buffer.rewind(); // 重置 position 为 0,准备重新读取
重置 position 为 0,允许重新读取缓冲区中的数据,而不改变 limit。
4.compact()
buffer.compact(); // 压缩缓冲区,保留未读取的数据
将未读的数据复制到缓冲区的起始位置,然后将 position 设置到未读数据的后面,准备写入新的数据。
5.hasRemaining()
if (buffer.hasRemaining()) {// 还有未读数据
}
检查缓冲区是否还有未读的数据(即 position < limit)。
8.2.3 FileChannel 示例:读取文件
import java.io.RandomAccessFile;
import java.nio.channels.FileChannel;
import java.nio.ByteBuffer;
import java.io.IOException;public class FileChannelExample {public void readFile(String filePath) throws IOException {// 使用 RandomAccessFile 打开文件,"r" 表示以只读模式打开try (RandomAccessFile file = new RandomAccessFile(filePath, "r");FileChannel fileChannel = file.getChannel()) { // 获取 FileChannel// 分配一个 1024 字节大小的 ByteBuffer 作为缓冲区ByteBuffer buffer = ByteBuffer.allocate(1024);// 从通道中读取数据到缓冲区while (fileChannel.read(buffer) > 0) {buffer.flip(); // 将缓冲区从写模式切换为读模式// 逐字节读取缓冲区中的内容while (buffer.hasRemaining()) {System.out.print((char) buffer.get()); // 输出字符}buffer.clear(); // 清空缓冲区,准备下一次读操作}}}
}
代码解析:
-
RandomAccessFile file = new RandomAccessFile(filePath, "r"):RandomAccessFile用于打开文件,模式"r"表示以只读方式打开。与普通FileInputStream不同,RandomAccessFile支持随机访问文件中的任意位置。
-
FileChannel fileChannel = file.getChannel():getChannel()方法获取该文件的FileChannel。通过FileChannel,我们可以直接操作文件的数据,支持高效的文件读写。
-
ByteBuffer buffer = ByteBuffer.allocate(1024):- 分配一个容量为 1024 字节的
ByteBuffer,这是内存中的缓冲区。数据会从FileChannel读入到这个缓冲区中。
- 分配一个容量为 1024 字节的
-
fileChannel.read(buffer):- 从文件通道读取数据到
ByteBuffer缓冲区中,返回值表示读取的字节数。如果读取的字节数大于 0,说明文件中还有数据没有读完。
- 从文件通道读取数据到
-
buffer.flip():- 在读取完文件数据后,调用
flip()将缓冲区从写模式切换为读模式,准备从缓冲区读取数据。
- 在读取完文件数据后,调用
-
buffer.hasRemaining():hasRemaining()方法检查缓冲区中是否还有未读取的数据。如果有,则逐字节输出缓冲区中的内容。
-
buffer.clear():- 每次读取完数据后,调用
clear()清空缓冲区,为下一次读操作做准备。
- 每次读取完数据后,调用
8.2.4 MappedByteBuffer 的作用
MappedByteBuffer 是 Java NIO 中的一个特殊类,它允许将文件的某个部分映射到内存中进行直接访问。这种内存映射文件方式使得文件读写操作非常高效,尤其适用于处理大文件时,可以避免频繁的磁盘 I/O 操作。
MappedByteBuffer 的特点:
- 直接内存映射:将文件的部分或全部内容直接映射到内存中,程序操作内存数据时,相当于直接操作文件数据。
- 适用于大文件处理:因为操作的是内存中的映射数据,不需要每次都访问磁盘,尤其适用于需要随机读写大文件的场景。
MappedByteBuffer 示例:处理大文件
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.io.IOException;public class MappedByteBufferExample {public void processLargeFile(String filePath) throws IOException {// 以读写模式打开文件try (RandomAccessFile file = new RandomAccessFile(filePath, "rw");FileChannel fileChannel = file.getChannel()) {// 将文件的前1MB映射到内存,MapMode.READ_WRITE 表示可读可写MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 1024 * 1024);// 修改映射到内存中的文件内容buffer.put(0, (byte) 65); // 将第一个字节修改为 'A' (ASCII 65)// 读取映射文件的部分内容byte firstByte = buffer.get(0);System.out.println("First byte of the file: " + (char) firstByte);}}
}
代码解析:
-
RandomAccessFile file = new RandomAccessFile(filePath, "rw"):- 以读写模式打开文件,
"rw"表示允许读写操作。
- 以读写模式打开文件,
-
FileChannel fileChannel = file.getChannel():- 获取文件的
FileChannel,通过它来对文件进行操作。
- 获取文件的
-
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 1024 * 1024):map()方法将文件的前 1MB 映射到内存中,MapMode.READ_WRITE表示映射的内容可以读写。参数0表示从文件开头开始映射,1024 * 1024表示映射 1MB 数据。- 映射的文件内容可以直接像操作内存数组一样进行访问。
-
buffer.put(0, (byte) 65):- 将内存映射文件的第一个字节修改为
65,即字符'A'的 ASCII 码值。
- 将内存映射文件的第一个字节修改为
-
byte firstByte = buffer.get(0):- 读取内存映射文件的第一个字节。
-
内存同步:
- 映射到内存中的内容会自动同步到文件,无需手动写回。因此,修改
MappedByteBuffer中的数据实际上就等于修改了文件。
- 映射到内存中的内容会自动同步到文件,无需手动写回。因此,修改
注意事项:
为避免将整个文件映射到内存引发的内存不足问题,通常使用分块映射策略。分块映射可以将文件按部分映射到内存,每次只操作文件的一部分,而不是整个文件。
9. 单元测试与集成测试
在文件上传和下载功能开发完成后,进行充分的测试是确保代码质量的关键步骤。在 Spring Boot 中,我们可以使用 单元测试 和 集成测试 来验证这些功能。单元测试主要是验证各个组件(如服务层、控制器层)的功能是否正常,而集成测试则是确保整个应用程序的各个部分能够协同工作。
9.1 模拟文件上传和下载的单元测试
单元测试的重点是确保业务逻辑和方法功能的正确性。在文件上传和下载功能中,可以使用 MockMultipartFile 来模拟文件上传,验证控制器和服务层的行为。
9.1.1 MockMultipartFile 的使用
MockMultipartFile 是 Spring 提供的一个模拟文件上传的类,可以在单元测试中使用,模拟客户端上传的文件,而无需真正地上传文件。
示例:模拟文件上传的单元测试
假设我们有一个文件上传的服务,负责将上传的文件保存到本地文件系统中,服务代码如下:
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;import java.io.File;
import java.io.IOException;@Service
public class FileUploadService {public String uploadFile(MultipartFile file) throws IOException {String filePath = "uploads/" + file.getOriginalFilename();file.transferTo(new File(filePath)); // 将文件保存到指定路径return filePath;}
}
我们可以通过 MockMultipartFile 模拟上传文件的单元测试:
import org.junit.jupiter.api.Test;
import org.springframework.mock.web.MockMultipartFile;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import static org.junit.jupiter.api.Assertions.assertEquals;@SpringBootTest
public class FileUploadServiceTest {@Autowiredprivate FileUploadService fileUploadService;@Testpublic void testFileUpload() throws Exception {// 创建一个 MockMultipartFile 模拟上传文件MockMultipartFile mockFile = new MockMultipartFile("file", // 参数名"testfile.txt", // 文件名"text/plain", // 文件类型"Hello, World!".getBytes()); // 文件内容// 调用上传服务,验证结果String filePath = fileUploadService.uploadFile(mockFile);assertEquals("uploads/testfile.txt", filePath); // 验证文件路径}
}
代码解析:
-
MockMultipartFile:创建模拟的上传文件。在这里,我们模拟了一个名为testfile.txt的文本文件,内容为"Hello, World!"。 -
fileUploadService.uploadFile(mockFile):调用上传文件的服务,模拟文件的上传。 -
assertEquals():验证文件是否被上传到了指定路径。
9.1.2 模拟文件下载的单元测试
文件下载也可以通过 MockMvc 或其他手段来验证。假设我们有一个简单的文件下载服务:
import org.springframework.core.io.Resource;
import org.springframework.core.io.UrlResource;
import org.springframework.stereotype.Service;import java.nio.file.Path;
import java.nio.file.Paths;@Service
public class FileDownloadService {public Resource downloadFile(String fileName) throws Exception {Path filePath = Paths.get("uploads").resolve(fileName).normalize();Resource resource = new UrlResource(filePath.toUri());if (resource.exists()) {return resource;} else {throw new Exception("File not found");}}
}
文件下载的单元测试可以模拟调用该服务:
import org.junit.jupiter.api.Test;
import org.springframework.core.io.Resource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import static org.junit.jupiter.api.Assertions.assertTrue;@SpringBootTest
public class FileDownloadServiceTest {@Autowiredprivate FileDownloadService fileDownloadService;@Testpublic void testFileDownload() throws Exception {// 假设 uploads 文件夹中有一个文件 testfile.txtResource resource = fileDownloadService.downloadFile("testfile.txt");assertTrue(resource.exists()); // 验证文件是否存在}
}
代码解析:
-
downloadFile("testfile.txt"):调用下载服务,模拟下载testfile.txt文件。 -
assertTrue(resource.exists()):验证文件是否存在于指定路径。
9.2 测试文件读写功能的集成测试
集成测试是为了确保应用程序的各个部分能够协同工作。使用 MockMvc 可以模拟对控制器的 HTTP 请求,测试文件上传和下载 API 的整体功能。MockMvc 是 Spring 提供的一个工具,可以模拟 Web 请求,并验证响应内容。
9.2.1 使用 MockMvc 测试文件上传 API
假设我们有一个文件上传的控制器:
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.beans.factory.annotation.Autowired;@RestController
@RequestMapping("/files")
public class FileController {@Autowiredprivate FileUploadService fileUploadService;@PostMapping("/upload")public String uploadFile(@RequestParam("file") MultipartFile file) throws Exception {return fileUploadService.uploadFile(file); // 调用服务上传文件}
}
使用 MockMvc 来测试该控制器的文件上传功能:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.http.MediaType;
import org.springframework.mock.web.MockMultipartFile;
import org.springframework.test.web.servlet.MockMvc;
import org.springframework.test.web.servlet.setup.MockMvcBuilders;
import org.springframework.web.context.WebApplicationContext;import static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.multipart;
import static org.springframework.test.web.servlet.result.MockMvcResultMatchers.status;@SpringBootTest
public class FileUploadControllerTest {@Autowiredprivate WebApplicationContext webApplicationContext;private MockMvc mockMvc;@Testpublic void testFileUpload() throws Exception {mockMvc = MockMvcBuilders.webAppContextSetup(webApplicationContext).build();MockMultipartFile mockFile = new MockMultipartFile("file", "testfile.txt", "text/plain", "Hello, World!".getBytes());mockMvc.perform(multipart("/files/upload") // 模拟文件上传请求.file(mockFile).contentType(MediaType.MULTIPART_FORM_DATA)).andExpect(status().isOk()); // 验证返回状态}
}
代码解析:
-
MockMvcBuilders.webAppContextSetup():设置MockMvc上下文。 -
multipart("/files/upload"):模拟对/files/upload的文件上传请求。 -
andExpect(status().isOk()):验证上传操作是否返回了 200 OK 状态。
9.2.2 使用 MockMvc 测试文件下载 API
文件下载的控制器如下:
import org.springframework.web.bind.annotation.*;
import org.springframework.core.io.Resource;
import org.springframework.http.ResponseEntity;
import org.springframework.beans.factory.annotation.Autowired;@RestController
@RequestMapping("/files")
public class FileDownloadController {@Autowiredprivate FileDownloadService fileDownloadService;@GetMapping("/download/{fileName}")public ResponseEntity<Resource> downloadFile(@PathVariable String fileName) throws Exception {Resource resource = fileDownloadService.downloadFile(fileName);return ResponseEntity.ok().body(resource);}
}
使用 MockMvc 测试文件下载功能:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.web.servlet.MockMvc;
import org.springframework.test.web.servlet.setup.MockMvcBuilders;
import org.springframework.web.context.WebApplicationContext;import static org.springframework.test.web.servlet.request.MockMvcRequestBuilders.get;
import static org.springframework.test.web.servlet.result.MockMvcResultMatchers.status;@SpringBootTest
public class FileDownloadControllerTest {@Autowiredprivate WebApplicationContext webApplicationContext;private MockMvc mockMvc;@Testpublic void testFileDownload() throws Exception {mockMvc = MockMvcBuilders.webAppContextSetup(webApplicationContext).build();mockMvc.perform(get("/files/download/testfile.txt")) // 模拟下载请求.andExpect(status().isOk()); // 验证返回状态}
}
代码解析:
-
get("/files/download/testfile.txt"):模拟 GET 请求,下载testfile.txt文件。 -
andExpect(status().isOk()):验证文件下载操作是否成功,返回 200 OK 状态。
相关文章:

Spring Boot框架中的IO
1. 文件资源的访问与管理 在 Spring Boot 中,资源文件的访问与管理是常见的操作需求,比如加载配置文件、读取静态文件或从外部文件系统读取文件。Spring 提供了多种方式来处理资源文件访问,包括通过 ResourceLoader、Value 注解以及 Applica…...

DBeaver连接Hive教程
hive shell:通过hive shell来操作hive,但是至多只能存在一个hive shell,启动第二个会被阻塞,也就是说hive shell不支持并发操作。 基于JDBC等协议:启动hiveserver2,通过jdbc协议可以访问hive,hi…...

Vue-Router源码实现详解
1.Hash模式 hash就是url中#后面的部分hash改变时,页面不会从新加载,会触发hashchange事件,去监听hash改变,而且也会被记录到浏览器历史记录中vue-router的hash模式,主要是通过hashchange事件,根据hash值找…...

程序员节日的日期是10月24日程序员日
程序员节日的日期是10月24日。 这一天被称为中国程序员日或1024程序员节,由博客园、CSDN等自发组织设立,旨在纪念程序员对科技世界的贡献。 程序员节日的由来和意义 1024程序员节的由来可以追溯到2010年,最初由网友提出设立一个…...

联邦学习中的数据异构性
在联邦学习(Federated Learning, FL)领域中, 异构数据(Heterogeneous Data) 是指不同客户端所持有的本地数据在特征分布、类别分布、数量等方面存在差异的数据。这种数据的异质性是联邦学习面临的一大挑战,…...

Python小程序 - 替换文件内容
1. 写入文件c:\a.txt 1)共写入10行 2)每行内容 0123456789 # 1 ls 0123456789 ln 10 with open("c:/a.txt", w,encodingUTF-8) as f:for i in range(ln):f.write(ls\n)######################################### 2 ln 10…...

k8s备份恢复(velero)
velero简介 velero官网: https://velero.io/ velero-github: https://github.com/vmware-tanzu/velero velero的特性 备份可以按集群资源的子集,按命名空间、资源类型标签选择器进行过滤,从而为备份和恢复的内容提供高度的灵活…...

LED户外屏:面对复杂环境的七大挑战
户外LED显示屏作为现代城市广告和信息传播的重要媒介,其应用范围越来越广泛。然而,与室内环境相比,户外环境的复杂多变对LED显示屏提出了更高的要求。本文将探讨户外LED显示屏在设计和应用过程中必须考虑的七个关键问题。 1. 高分辨率 户外LE…...
LabVIEW自动化流动返混实验系统
随着工业自动化的不断发展,连续流动反应器在化工、医药等领域中的应用日益广泛。传统的流动返混实验操作复杂,数据记录和处理不便,基于LabVIEW的全自动流动返混实验系统能自动测定多釜反应器、单釜反应器和管式反应器的停留时间分布ÿ…...
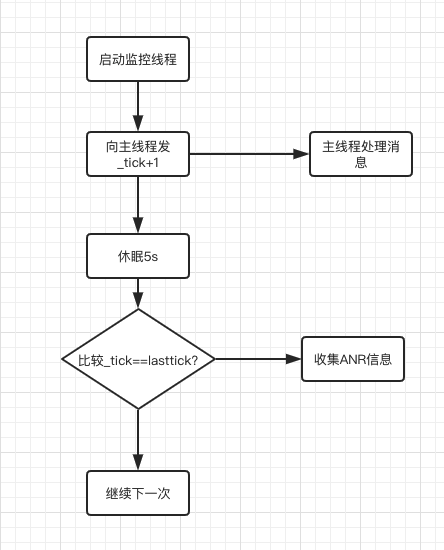
【性能优化】安卓性能优化之CPU优化
【性能优化】安卓性能优化之CPU优化 CPU优化及常用工具原理与文章参考常用ADB常用原理、监控手段原理监控手段多线程并发解决耗时UI相关 常见场景排查CPU占用过高常用系统/开源分析工具AndroidStudio ProfilerSystraceBtracePerfettoTraceView和 Profile ANR相关ANR原理及常见场…...

springboot二手图书交易系统-计算机设计毕业源码88413
目 录 摘要 1 绪论 1.1研究背景 1.2研究意义 1.3论文结构与章节安排 2 二手图书交易系统系统分析 2.1 可行性分析 2.2 系统流程分析 2.2.1 数据流程 3.3.2 业务流程 2.3 系统功能分析 2.3.1 功能性分析 2.3.2 非功能性分析 2.4 系统用例分析 2.5本章小结 3 二手…...

解决ElasticSearch启动成功却无法在浏览器访问问题
目录 前言: 问题复现 : 解决问题: 1、修改sysctl.conf文件 2、在sysctl.conf文件增加这段东西 3、 然后保存退出,输入以下命令使其生效 结语: 前言: 这篇文章是小白我今天突然启动es,发现e…...

稀土有色包芯线良好的导电性
稀土有色包芯线是一种结合了稀土元素和有色金属(如铜、铝、镁等)的特殊线材。以下是对稀土有色包芯线的详细介绍: 一、组成与结构 芯线:由稀土元素和有色金属组成的合金制成。稀土元素(如镧、铈、镁等)的添加量在一定范围内,以确保合金性能的…...

SIP 业务举例之 Call Forwarding Unconditional(无条件呼转)
目录 1. Call Forwarding Unconditional 简介 2. RFC5359 的 Call Forwarding Unconditional 信令流程 PS:Dialog 建立条件 Dialog 会话完全建立 3. Call Forwarding Unconditional 过程总结 博主wx:yuanlai45_csdn 博主qq:2777137742 想要 深入学习 5GC IMS 等通信知识…...

基于stm32的esp8266的WIFI控制风扇实验
实验案例WIFI控制风扇 项目需求 电脑通过esp8266模块远程遥控风扇。 项目框图 风扇模块封装 #include "sys.h" #include "fan.h"void fan_init(void) {GPIO_InitTypeDef gpio_initstruct;//打开时钟…...

java中的ScheduledExecutorService介绍和使用案例
ScheduledExecutorService 是 Java 并发包 java.util.concurrent 中的一个接口,它提供了一种机制,允许我们安排一个任务在给定的延迟后运行,或者定期地执行。 主要特点 单次调度:可以安排任务在一定的延迟后执行一次。周期性调度…...

4天涨粉14万!这个AI小众赛道粉丝涨疯了吧?保姆级教程免费教会你!
测一下你的搞钱灵敏度有多高,看下面两张截图,有没有发现什么异常值? 发现了吧? 第一张是10月17号截的,第二张是21号,4天时间粉丝从2.8万飙到16.6万,涨粉14万! 这个号我几天之前就发…...

RK3588 技术分享 | 在Android系统中使用NPU实现Yolov5分类检测
随着人工智能和大数据时代的到来,传统嵌入式处理器中的CPU和GPU逐渐无法满足日益增长的深度学习需求。为了应对这一挑战,在一些高端处理器中,NPU(神经网络处理单元)也被集成到了处理器里。NPU的出现不仅减轻了CPU和GPU…...

itext 转换word文档转pdf
itext 转换word文档转pdf <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>4.1.2</version><scope>compile</scope></dependency> <dependency><groupId>org.a…...
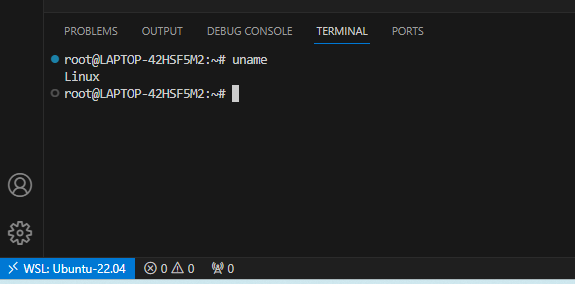
WSL-默认root登录
WSL-默认root登录 使用管理员,打开powershell PS C:\WINDOWS\system32> wsl -l 适用于 Linux 的 Windows 子系统分发版: Ubuntu-22.04 (默认) PS C:\WINDOWS\system32> ubuntu2204.exe config --default-user root PS C:\WINDOWS\system32>修改之后&…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...