动态量化:大模型在端侧CPU快速推理方案

作为一款高性能的推理引擎框架,MNN高度关注Transformer模型在移动端的部署并持续探索优化大模型在端侧的推理方案。本文介绍权重量化的模型在MNN CPU后端的推理方案:动态量化。动态量化指在运行时对浮点型feature map数据进行8bit量化,然后与8bit/4bit的权重数据做矩阵乘法并将结果反量化为浮点类型输出。
虽然动态量化方案设计的初衷是在移动端高效地推理LLM模型,但方案本身适用于所有模型的各个推理场景,例如语音识别类模型TTS、ASR等进行权重量化后也能在端侧实现高效推理,推理耗时和运行时内存占用都能降低50%,和浮点模型相比最大相对误差可以控制在10%以内。文章首先从数学表达式开始描述动态量化的计算原理,接着从模型推理的角度拆解计算过程,然后介绍MNN CPU后端的矩阵乘逻辑,最后以Qwen2-1.5B模型为例,介绍在CPU后端使用动态量化进行LLM模型推理的详细步骤并测试MNN CPU后端对LLM模型和传统CV模型的推理性能。

基础知识
▐ 动态量化计算原理的解析式
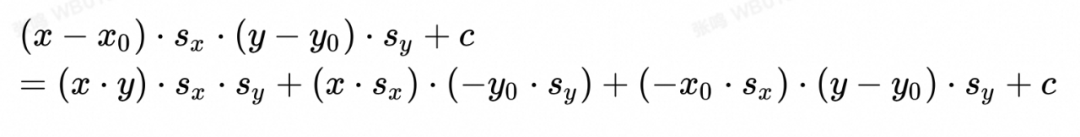
▐ 符号解释
x: 动态量化之后的 int8_t 类型输入数据,[E, L];
x0: 动态量化Input数据时的量化参数zeropoint值;
sx: 动态量化Input数据时的量化参数scale值;
y: 在转模型时就已经量化过的int8_t类型权重,[L, H];
y0: 直接从模型文件中读取权重的量化参数zeropoint
sy: 直接从模型文件中读取权重的量化参数scale
c: 常量值,下文称做bias值,[1, H]
注:
下文中x,y 的反量化zeropoint特指 x0, y0;但x,y的反量化bias则指(-x0 * sx),(-y0 * sy);
x的反量化过程是:xf = (x - x0) * sx = x * sx + (-x0 * sx),y的反量化同理
▐ 拆解计算过程
可离线计算的项
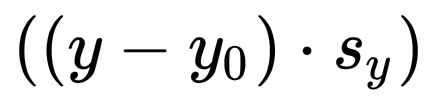 :在L维度对y reduce sum, shape: [1, H]
:在L维度对y reduce sum, shape: [1, H]
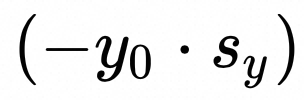 :y的量化参数bias,向量 [1, H]
:y的量化参数bias,向量 [1, H]
需在线计算的项
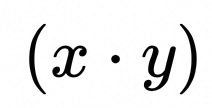 :int8_t 类型数据矩阵乘法累加到int32_t类型, [E, H]
:int8_t 类型数据矩阵乘法累加到int32_t类型, [E, H]
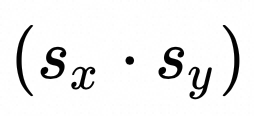 :x和y的量化参数Scale相乘,[1, H]
:x和y的量化参数Scale相乘,[1, H]
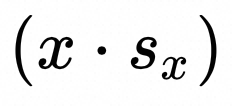 :在L维度对 x reduce sum, shape: [E, 1]
:在L维度对 x reduce sum, shape: [E, 1]
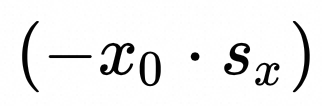 :x 的量化参数bias, 标量
:x 的量化参数bias, 标量
在矩阵乘Kernel 内部计算的项
在矩阵乘Kernel内部计算的项一定属于1.3.2节“需在线计算的项”:
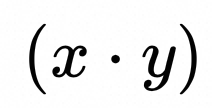 :int8_t 类型数据矩阵乘法累加到int32_t类型, [E, H]
:int8_t 类型数据矩阵乘法累加到int32_t类型, [E, H]
kernel外计算之后传入矩阵乘Kernel的项
离线计算的项和一些需在线计算的项会通过 QuanPostTreatParameters 结构体传入矩阵乘kernel中。
struct QuanPostTreatParameters {const float* scale;const float* biasFloat;int32_t maxValue;int32_t minValue;int32_t useInt8 = 1; // Save result as int8_t dataType; otherwise float32.float roundValuePos = 0.5f;float roundValueNeg = -0.5f;float* srcKernelSum;float* weightQuanBias;float* fp32minmax;ssize_t blockNum = 1;const int32_t* bias;const float* extraScale = nullptr;const float* extraBias = nullptr;
};
// (sx * sy): x和y的量化参数Scale相乘,[1, H]
QuanPostTreatParameters.scale
// (x * sx): 在L维度对 x reduce sum,shape: [E, 1]
QuanPostTreatParameters.srcKernelSum
// (-y0*sy): 权重反量化的参数bias,shape: [1, H]
QuanPostTreatParameters.weightQuanBias
// (-x0*sx)(y-y0)*sy+c: 原矩阵乘bias与计算过程中“新增项”相加之后的bias,shape: [1, H]
QuanPostTreatParameters.biasFloat
/* 该结构体中的其他项暂时不要关注,后续会有说明。*/MNN CPU 矩阵乘计算逻辑本节分为两个方面,第一,MNN CPU的矩阵乘的分块计算逻辑;第二,MNN CPU的矩阵乘算子在各平台的计算加速方法。
▐ 矩阵乘的分块计算
分块计算的优点是降低读取Input和weight数据时的cache miss率;各CPU后端(Arm、x86_x64)可使用的汇编指令不同,决定了各后端的分块大小也不同。
符号说明
input shape: [E, L] ,weight shape [L, H],output shape [E, H],L是reduce维度。
EP, LP, HP 分别表示 E, L, H 维度的分块大小
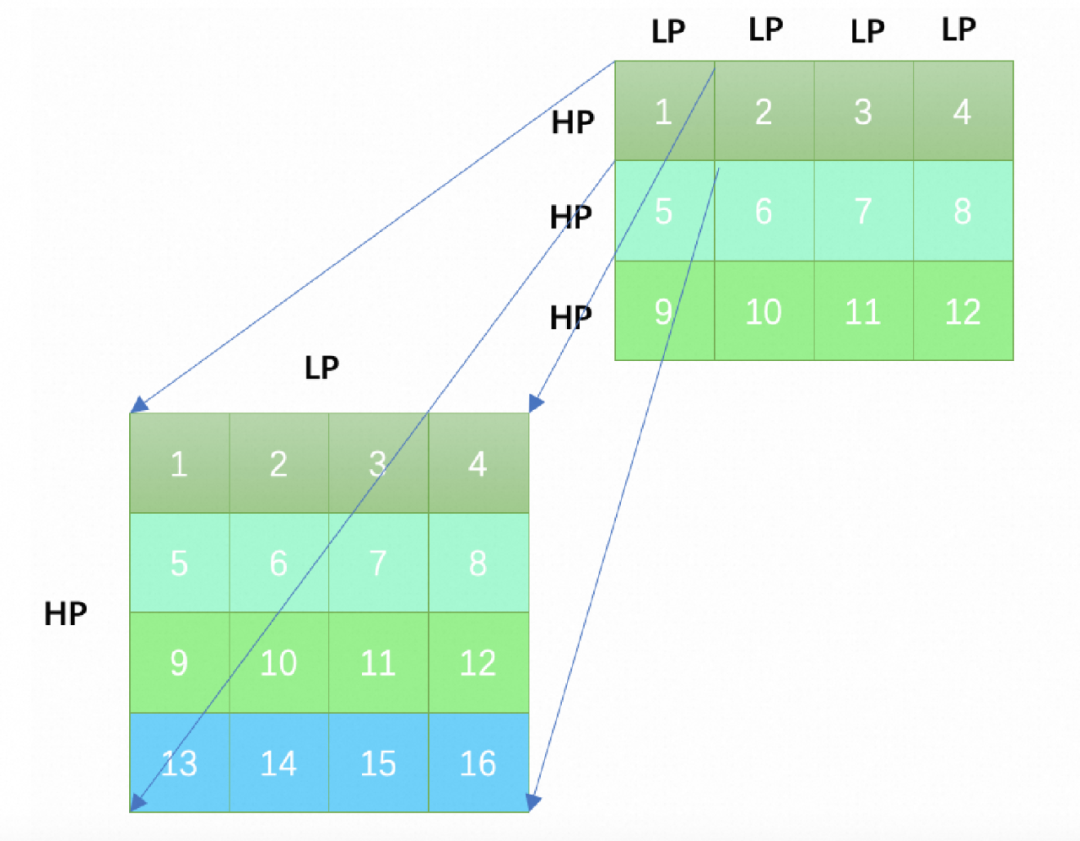
Input和weight分块后在内存中的排列逻辑
以weight分块为例,如图1。在L和H维度分别按照LP和HP分块,如果L或H不能被LP或HP整除,会在最后一个子块补0以保证分块之后的每一个小方块的大小都是(HP*LP)。分块之后weight矩阵的12个子块之间会按照图示中的“1,2,3,...,12”的顺序在内存中排列。在各子块内部,如编号为“1”的块中有16个数据,其排列顺序按照图1. 中的“1,2,3,...,16”的顺序在内存中排列。
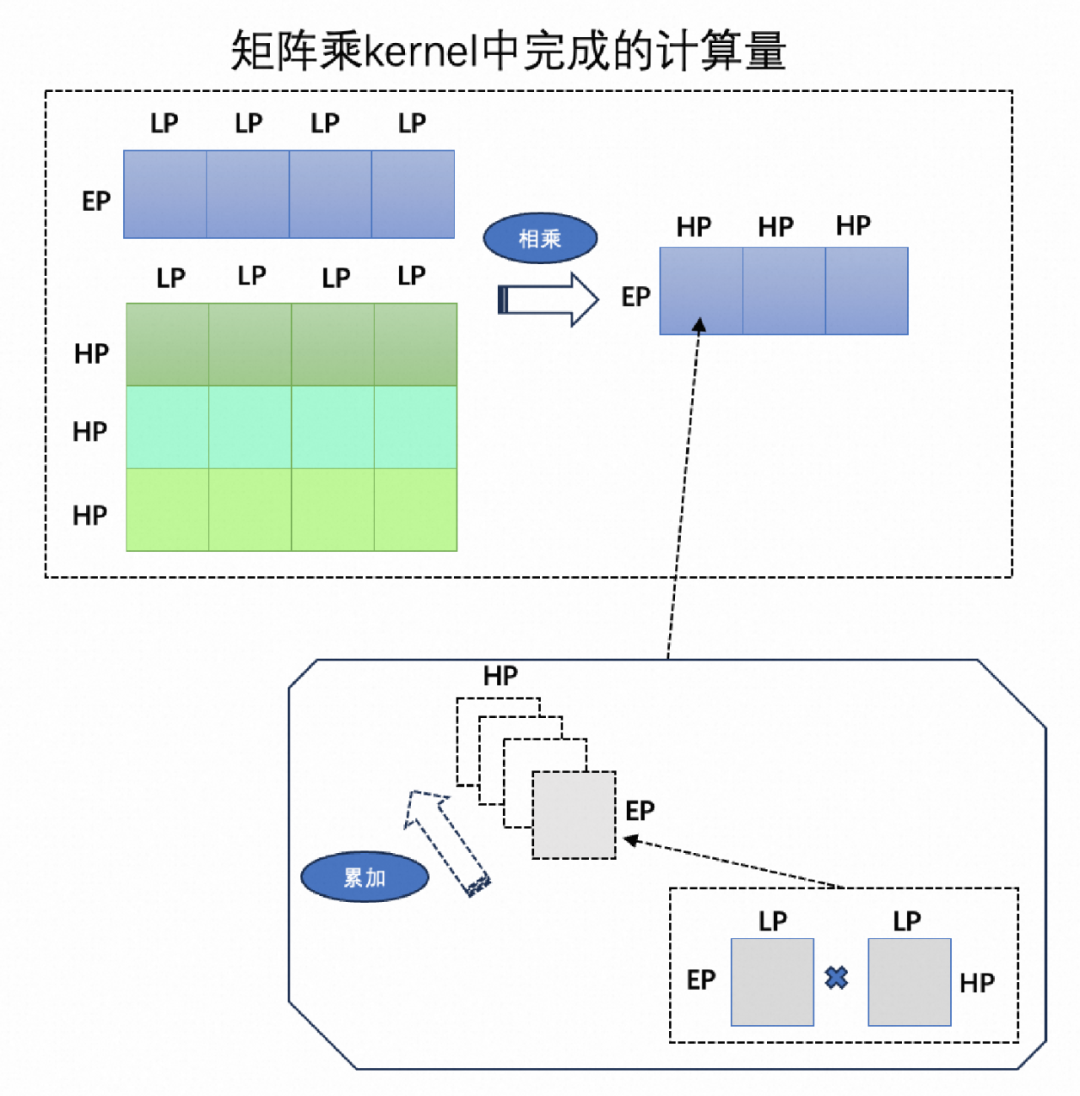
矩阵乘内部分块计算的顺序
下文中描述shape时,默认在内存中的排列顺序是括号内从右到左的顺序。图2. 描述了矩阵乘kernel内部input和weight分块后的计算逻辑:
最小计算单元是:(EP, 4*LP)的输入数据和(HP, 4*LP)的weight数据做乘加操作得到(EP, HP)的输出子块。
按照图2. 中output矩阵的子块编号,依次计算1,2,3号子块,矩阵乘kernel内部最多计算得到output矩阵中(EP * H)个数据。
矩阵乘的外部调用逻辑
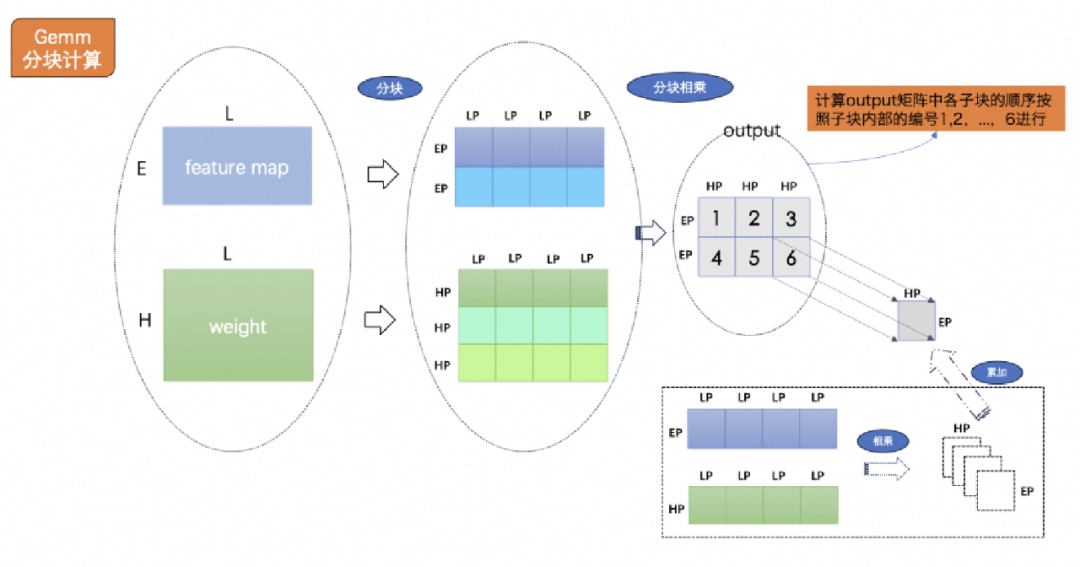
如果一个ONNX模型中含有MatMul算子,并且该算子的两个输入中的一个是常量,那么MNN转模型工具(MNNConvert)会将该MatMul算子转换成MNN模型中的卷积算子。MNN的矩阵乘Kernel通常在卷积算子中被调用,而MNN CPU 的卷积算子的输入输出数据在内存中的排布都是(C/4, N, H, W, 4),其中C表示Channel,N表示Batch,H和W分别表示Height和Width。上文中E、 L、 H分别对应卷积中的(N * OW * OH)、(OC * IC * KH * KW)、OC。
做矩阵分块的过程中,会将Input 数据从 (IC/4, N, IH, IW, 4)重排为(E/EP, L/LP, EP, LP),weight 数据从(OC, IC, KH, KW) 重排为(H/HP, L/LP, HP, LP)。每一个矩阵乘kernel完成的计算量最多是EP*H,所以要完成E*H的计算量,需要调用矩阵乘kernel ((E+EP)/EP) 次。如下图3. 所示,要得到最终的output矩阵的结果,则需要分2次调用矩阵乘kernel. 虽然得到的输出子块是(EP, HP)的大小,在往目标地址写入输出数据时直接按照(C/4, N, H, W, 4)的顺序。
▐ MNN CPU的矩阵乘算子在各平台的计算加速
下图4. 表示用int8_t类型的输入数据和权重数据得到浮点输出的计算过程,该过程可分为三个阶段:
第一阶段:基于 int8_t 类型的feature map和weight做矩阵乘法得到int32_t类型output,再将int32_t output 反量化到float32_t output;
第二阶段:基于 float32_t output 加上 weight_dequant_bias * intput_reduce_sum_by_axis_L;
第三阶段:最后加上 bias (维度:H),这里的bias 来自于矩阵乘A*B+C中的C和input数据的量化bias乘以weight_reduce_sum_by_axis_L之后的和。
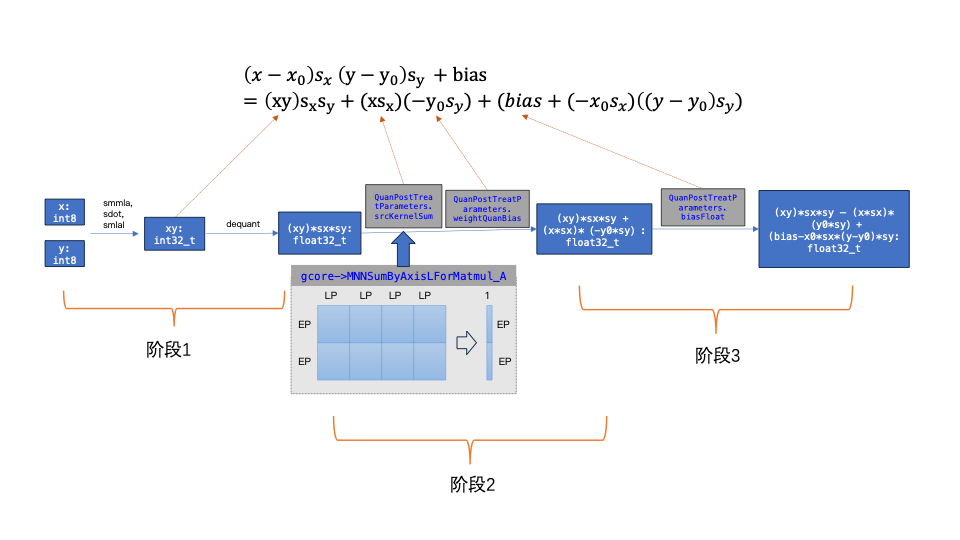
第一阶段的计算耗时是矩阵乘kernel计算耗时中占比最大的部分,在不同CPU后端对矩阵乘的加速几乎都集中在该阶段。诸如Armv8.6和v8.2后端都有指令专门针对int8_t类型数据的内积进行计算加速,另外x86_x64的AVX512后端提供了VNNI指令集也对int8_t类型数据的计算提供了优化。
CPU Arm后端的矩阵乘优化
1. 在不支持SMMLA和SDOT指令的Armv8/v7后端,只能使用最基础的smull和smlal指令做int8_t数据的内积操作。为了提高每次读取数据的效率,设置 LP=16保证一次读取16个int8_t数据填满向量寄存器。另外EP=4, HP=4.
2. Armv8.6后端支持Arm汇编指令SMMLA,Armv8.2后端支持汇编指令SDOT(计算原理分别如图5. 上下图所示)。
SMMLA指令的输入数据是两个128位的向量寄存器,将第一个输入向量寄存器中的128位数据看作一个(2x8)的矩阵,其中每个数据类型是int8_t. 将第二个输入向量寄存器中的128位数据看作一个(8x2)的矩阵,其中每个数据类型也是int8_t. smmla指令将两个源向量寄存器做矩阵乘法得到一个(2x2)的输出矩阵,并存储在一个128位的向量寄存器中,该输出寄存器中的数据由4个int32_t类型数据组成。
SDOT指令的输入数据被看做是两个一维的向量,每4个对应位置的int8_t数据做内积得到1个int32_t的数据,最终结果是4个int32_t的数据。
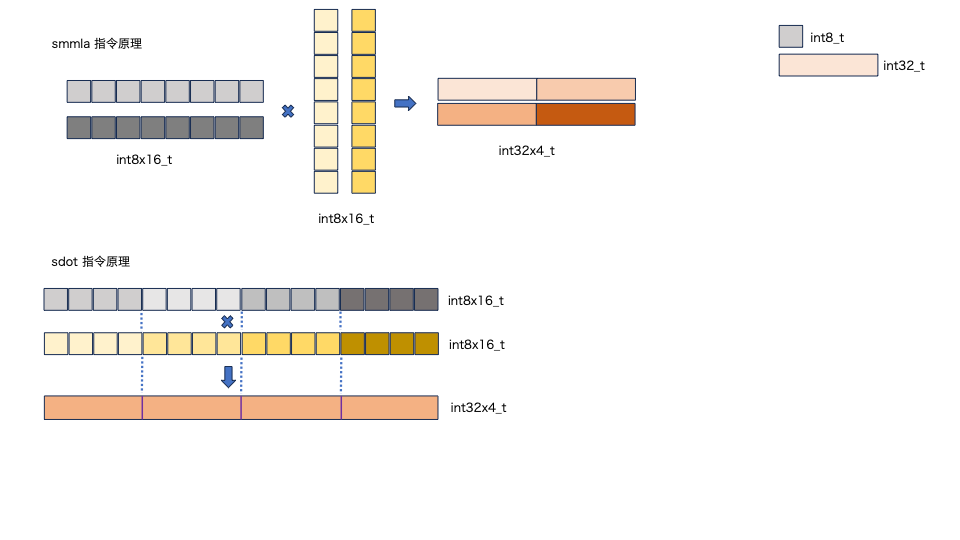
根据Armv8.6和v8.2后端指令特点,矩阵乘的分块大小分别是:
Armv8.6:EP=10, LP=8, HP=8(因为SMMLA指令对每8个int8_t数据做内积,所以LP=8)
Armv8.2:EP=12, LP=4, HP=8(因为SDOT指令对每4个int8_t数据做内积,所以LP=4)
从把向量寄存器用满的角度,分别设置EP=10和12;从最大程度降低读取weight值的cache miss率的角度,设置HP=8
CPU x86_x64后端的矩阵乘优化
AVX512后端的VNNI指令集专门针对int8_t整数运算进行了优化,其他后端因为没有该指令集故基于int8_t数据的矩阵乘法性能一般比基于float数据的矩阵乘差。这里直接列举出x86_x64个后端的分块大小:
不使用SSE、AVX2、AVX512等指令的C++版本:EP=2,LP=16,HP=4
SSE: EP=4,LP=16,HP=4
AVX2: EP=4,LP=4,HP=8
AVX512: EP=4,LP=4,HP=64
MNN CPU后端对端侧LLM模型推理的精度优化▐ weight分组量化
转模型阶段的支持
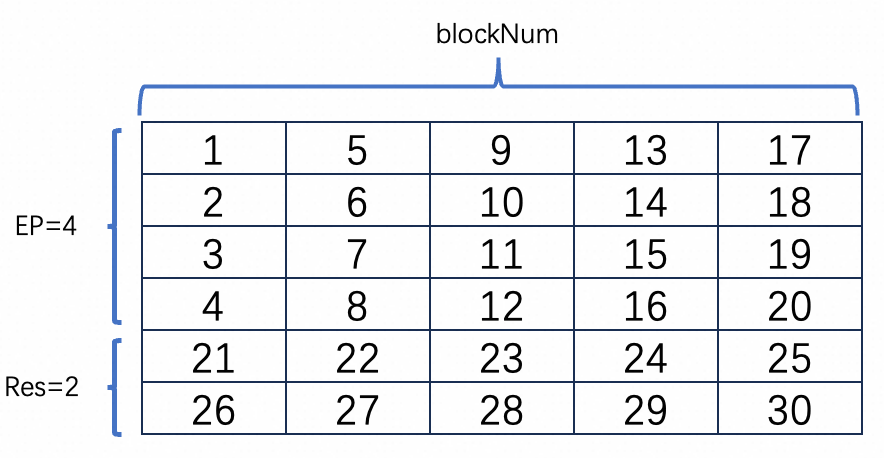
通常权重矩阵[OC, IC, KH, KW]的量化参数维度是[1, OC],即每(IC*KH*KW)个数据共享一个量化scale和zeropoint,最后求得OC * 2个量化参数(包含scale和zeropoint)。(IC*KH*KW)个数据分布差异较大会影响权值量化的精度,因此在转模型阶段会对将(IC*KH*KW)个数据分为m组进行量化,即最后得到的量化参数有(OC*m*2)个。转模型工具MNNConvert 接受可选参数 --weightQuantBlock 来指定共享量化参数的元素个数,如 --weightQuantBlock 128 会得到 (OC*(IC*KW*KH/128)*2)个量化参数。当且仅当weightQuantBlock参数设置的值能整除 (IC * KH * KW)时才会生效,否则依然得到(OC * 2)个量化参数。
CPU后端支持
一些计算项shape的变化:当采取weight分组量化后,等价于 reduce axis L被分成m组,上文中结构体QuanPostTreatParameters.blockNum=m. 相应地,一些项的shape也发生如下改变。和上文保持一致,该项在内存中按照方括号内从右往左的顺序排列。
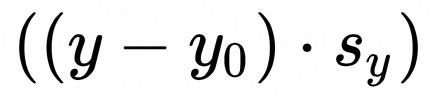 shape 变化:[1, H] -> [m, H]
shape 变化:[1, H] -> [m, H]
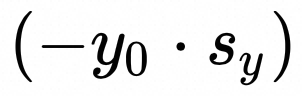 :y的量化参数bias,向量 [m, H]
:y的量化参数bias,向量 [m, H]
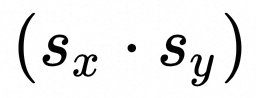 :x和y的量化参数Scale相乘,[m, H]
:x和y的量化参数Scale相乘,[m, H]
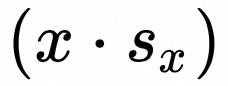 :在L维度对 x reduce sum, shape: [(E+EP-1)/EP, m, EP],在内存中如下图方块编号顺序排列。
:在L维度对 x reduce sum, shape: [(E+EP-1)/EP, m, EP],在内存中如下图方块编号顺序排列。
1. 矩阵乘kernel调用逻辑的变化:得到一个output数据的子块(EP, H)之前只需要调用一次矩阵乘kernel,在对weight进行分组量化后由于每组的量化参数不同,需要在外层调用m次矩阵乘kernel。
2. 矩阵乘内部的计算逻辑变化:首次调用矩阵乘kernel会将结果数据直接写入目标地址,后面的(m-1)次调用都需要将本次计算的结果在目标地址中的已有值基础上进行累加之后再写入目标地址。
▐ 在LLM推理的prefill阶段分sequence量化
为提高端侧LLM模型权重量化后的推理精度,MNN在动态量化推理时prefill阶段对不同sequence的数据分别求解量化参数进行动态量化。在MNN CPU的动态量化卷积算子中,sequence对应的是卷积输入输出数据的Batch值,后文表述中会把在prefill阶段对输入数据分sequence量化简称为“Batch quant”或“Batch量化”。
当前仅支持input->width==1&&input->height==1&&output->width==1&& output->height==1的数据做Batch量化。虽然在非Batch量化中对输入数据是采取非对称量化的方式;但为了降低矩阵乘算子内部计算的复杂度,Batch量化中对输入数据是采取对称量化的方式,即x0=0. MNN CPU后端支持Batch量化应用在权重进行分组量化的模型中,即与3.1节所述是不冲突的。
为了快速适配现有的矩阵乘kernel和CPU动态量化算子,在QuanPostTreatParameters.extraScale中存储Input数据不同batch所对应的dequant scale值。此时矩阵乘kernel外部不会计算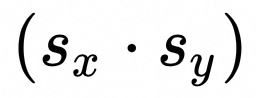 项,直接将权重的反量化Scale
项,直接将权重的反量化Scale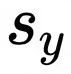 传入QuanPostTreatParameters.scale。同时在矩阵乘kernel内部根据QuanPostTreatParameters.extraScale是否为空指针决定是否乘以该项。
传入QuanPostTreatParameters.scale。同时在矩阵乘kernel内部根据QuanPostTreatParameters.extraScale是否为空指针决定是否乘以该项。

代码逻辑
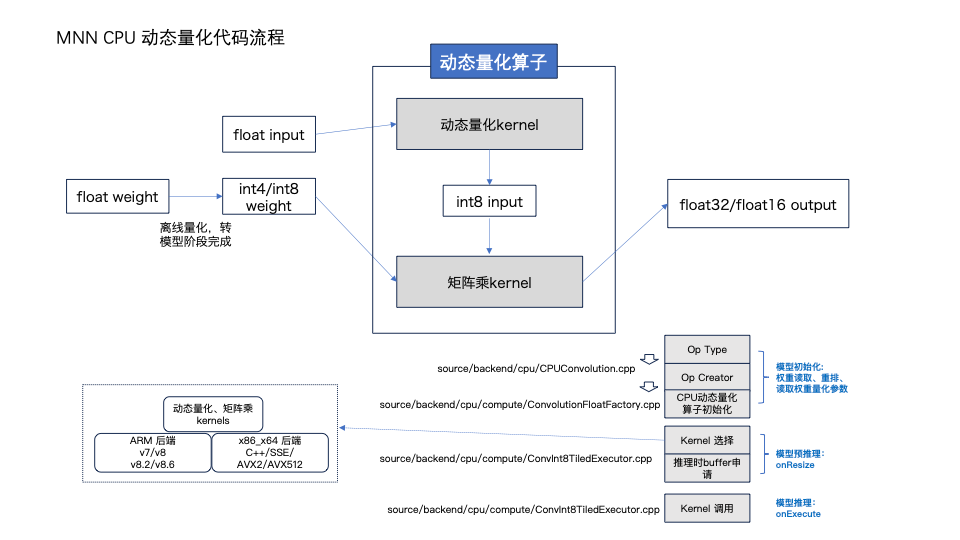
CPU 动态量化算子:DenseConvInt8TiledExecutor
CPU 动态量化算子会根据不同后端来选择矩阵乘算子和矩阵乘的分块大小,目前支持ARM后端(Armv8.6、Armv8.2、Armv8、Armv7)和x86_x64后端(SSE、AVX2、AVX512)。
CPU 动态量化算子支持输出float32或float16,由用户指定精度,precision low表示使用输出float16,precision normal/high表示输出float32。
MNN中有两个结构体 CoreInt8Functions 和 CoreFunctions 与后端紧密联系,在模型加载阶段会根据推理后端为结构体中的各函数指针赋值内容。CoreInt8Functions 包含的通常是与int8_t类型相关的kernel或经常在量化场景下使用的kernel,CoreFunctions 包含的通常是浮点类型相关的kernel.
// CPU 后端结构体指针,如果当前推理使用的是ARM V8.2后端,
// core和gcore指向ARM V8.2的函数结构体
auto core = static_cast<CPUBackend*>(backend())->int8Functions();
auto gcore = static_cast<CPUBackend*>(backend())->functions();
// 例如:获取ARM V8.2后端的Int8矩阵乘分块
int HP, LP, EP;
core->MNNGetGemmUnit(&HP, &LP, &EP);
// 例如:获取ARM V8.2后端的Int8矩阵乘kernel
auto mGemmKernel = core->Int8GemmKernel;MNN中有结构体 CoreInt8Functions 包含与int8_t类型相关的各类函数指针,其中在动态量化算子中被调用的矩阵乘kernel函数指针有:
Int8GemmKernel:weight是8bit量化的,输出结果是float32
Int8GemmKernel_W4:weight是4bit量化的,输出结果是float32
MNNGemmInt8AddBiasScale_Unit_FP16:weight是8bit量化的,输出结果是float16
MNNGemmInt8AddBiasScale_w4_Unit_FP16:weight是4bit量化的,输出结果是float16
不同后端的矩阵乘分块大小也通过CoreInt8Functions中的函数指针MNNGetGemmUnit得到。

MNN CPU动态量化的使用及性能加速效果
重要:使用MNN CPU进行权重量化模型推理时,当且仅当打开编译宏 MNN_LOW_MEMORY,并且设置推理时memory=low才会使用动态量化进行推理。
▐ 使用MNN CPU动态推理教程:以安卓手机测试LLM模型为例
关于MNN中指定推理时memory的办法:
自行编写demo时设置
BackendConfig backendConfig; backendConfig.memory=Memory_Low;
若使用MNN 测试工具llm_demo,只需要在config.json文件中指定"memory": "low"
在llm.mnn和llm.mnn.weight的同一个目录下新建推理时需要的config.json文件
必须包含的内容:
llm_model:大语言模型文件名
llm_weight: 与llm_model对应的大语言模型的权值文件
可选项:
backend_type: 推理后端,默认0表示CPU推理
thread_num:推理时使用的线程数,默认4线程
precision:推理精度,默认nomal。low表示动态量化输出数据是float16类型,使用CPU推理时 normal/high都表示动态量化输出数据是float32类型
memory:推理时内存,默认normal。要使用CPU动态量化特性需设置成low.
在安卓手机上的编译和demo运行:
git clone:https://github.com/alibaba/MNN.git
cd MNN&&mkdir build&&cd build
命令行设置编译选项编译
cmake .. \
-DCMAKE_TOOLCHAIN_FILE=$ANDROID_NDK/build/cmake/android.toolchain.cmake \
-DANDROID_ABI="arm64-v8a" \
-DANDROID_STL=c++_static \
-DANDROID_NATIVE_API_LEVEL=android-21 \
-DMNN_BUILD_FOR_ANDROID_COMMAND=true \
-DCMAKE_BUILD_TYPE=Release \
-DMNN_LOW_MEMORY=ON \
-DMNN_SUPPORT_TRANSFORMER_FUSE=ON \
-DMNN_ARM82=ON \
-DMNN_BUILD_LLM=ON
make -j4运行:./llm_demo Qwen2-1.5B-Instruct/config.json ./prompt.txt
▐ LLM 模型在MNN CPU后端使用动态量化推理时的性能
测试机器:小米14(骁龙8Gen3)
测试模型: Qwen2-1.5B-Instruct
线程数:4
config.json和prompt.txt内容如下,为了保持各配置下输出token一致,这里设置了"max_new_tokens": 300
测试包含float32和float16的性能数据,只需要更改config.json文件中"precison": "low" 或 "high". "low"表示float16,"high"表示float32。
"memory"必须设置为"low"才能使用动态量化推理,否则会在模型加载阶段将权重反量化为浮点,然后使用浮点型矩阵乘推理,严重影响LLM模型推理速度。
{"llm_model": "llm.mnn","llm_weight": "llm.mnn.weight","max_new_tokens": 300,"backend_type": "cpu","thread_num": 4,"precision": "low","memory": "low"
}In recent years, with the rapid development of technology and the deepening of globalization, the digital economy has become a new engine driving the growth of the world economy. The digital economy has not only changed people's way of life and promoted the rapid flow of information and resources, but also reshaped the business models and competitive landscape of traditional industries. Although the development of the digital economy has provided new momentum for global economic growth, it has also brought a series of challenges, such as data security, privacy protection, digital divide, and market monopolies. In light of these background, please analyze in detail the role of the digital economy in promoting world economic growth, including but not limited to its contribution to improving productivity, creating employment opportunities, and promoting sustainable development. At the same time, discuss how to address the challenges that arise during the development of the digital economy, including how to protect personal data security and privacy, narrow the digital divide to ensure the inclusiveness and fairness of the digital economy, and how to formulate effective policies to avoid the emergence of market monopolies, ultimately achieving the healthy and sustainable development of the digital economy.表格中的第一个数据表示Prefill速度,第二个数据表示Decode速度。
权重量化方法 | Precison | 4 线程, Armv8.6 |
权重4bit量化 | high | 302.49 tok/s - 41.42 tok/s |
▐ CV 模型在MNN CPU后端使用动态量化推理时的性能
第三列括号内的红色数据是动态量化较浮点模型推理的加速比。
测试机器:小米14(骁龙8Gen3)
模型 | 推理参数 | 动态量化推理 | 浮点模型 |
mobilenetv3 | fp32 - 四线程 | 2.63 ms (加速比1.46) | 3.86 ms |
mobilenetv3 | fp32 - 单线程 | 4.03 ms(加速比1.69) | 6.85 ms |
mobilenetv3 | fp16 - 四线程 | 2.29 ms(加速比1.05) | 2.41 ms |
mobilenetv3 | fp16 - 单线程 | 3.19 ms(加速比1.14) | 3.65 ms |
mobilenetv2 | fp32 - 四线程 | 2.55 ms(加速比1.62) | 4.13 ms |
mobilenetv2 | fp32 - 单线程 | 4.42 ms (加速比1.84) | 8.15 ms |
mobilenetv2 | fp16 - 四线程 | 2.13 ms(加速比1.11) | 2.37 ms |
mobilenetv2 | fp16 - 单线程 | 3.58 ms(加速比1.14) | 4.08 ms |
resnet50 | fp32 - 四线程 | 13.09 ms (加速比3.31) | 43.29 ms |
resnet50 | fp32 - 单线程 | 23.09 ms (加速比3.08) | 71.18 ms |
resnet50 | fp16 - 四线程 | 11.82 ms (加速比1.87) | 22.09 ms |
resnet50 | fp16 - 单线程 | 21.71 ms (加速比1.63) | 35.38 ms |
yolov4 | fp32 - 四线程 | 181.43 ms(加速比1.99) | 362.68 ms |
yolov4 | fp32 - 单线程 | 383.78 ms(加速比1.68) | 644.92 ms |
yolov4 | fp16 - 四线程 | 193.74 ms(加速比1.21) | 235.59 ms |
yolov4 | fp16 - 单线程 | 454.80 ms(加速比1.10) | 501.23 ms |

结语
MNN CPU动态量化方案在Transformer类模型和传统CV模型的推理中都有不错的表现,虽然文章中Transformer模型的性能数据来自于LLM模型的测试,但语音类模型使用动态量化推理的性能较浮点模型相比都有显著的提升。采用动态量化方法的好处不仅提升推理性能和降低运行时内存,算法同学从浮点模型得到权重量化模型的过程也比PTQ方案简单许多,模型转换过程更加高效,模型的精度理论上要高于PTQ方式得到的量化模型。
团队介绍我们是大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
相关文章:
动态量化:大模型在端侧CPU快速推理方案
作为一款高性能的推理引擎框架,MNN高度关注Transformer模型在移动端的部署并持续探索优化大模型在端侧的推理方案。本文介绍权重量化的模型在MNN CPU后端的推理方案:动态量化。动态量化指在运行时对浮点型feature map数据进行8bit量化,然后与…...

什么是零拷贝以及其应用场景是什么?
写在前面 本文看下什么是零拷贝,以及其具体的应用场景有哪些。 1:什么是零拷贝 想要解释清楚什么是零拷贝,需要先来看下常规的阻塞io一次io的过程,这里以从文件读取内容然后写到socket为例来看下,如下: …...
是什么?为什么要开源?)
开源(open source)是什么?为什么要开源?
为什么开源这个问题挺复杂,这里就从社会面以及个人两个角度来说。当然个人层面的开源其实是建立在社会面形成开源氛围后开始的。 社会面开源 这里举一个例子,既互联网从 web1.0 到 web3.0 (开源 → 闭源 → 再开源)的历程&#…...

基于Spring Boot的论坛网站:从零到部署
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...

vue开发的一个小插件vue.js devtools
可打开谷歌商城的情况下,不可打开的可以到极简插件里面去下载 极简插件官网_Chrome插件下载_Chrome浏览器应用商店 搜索vue即可...

GraphLLM:基于图的框架,通过大型语言模型处理数据
GraphLLM是一个创新的框架,它允许用户通过一个或多个大型语言模型(LLM)来处理数据。这个框架不仅提供了一个强大的代理,能够执行网络搜索和运行Python代码,还提供了一套工具来抓取网页数据,并将其重新格式化…...

HarmonyOS 5.0应用开发——Navigation实现页面路由
【高心星出品】 Navigation实现页面路由 Navigation:路由导航的根视图容器,一般作为页面(Entry)的根容器去使用,包括单页面(stack)、分栏(split)和自适应(a…...

物联网行业应用实训室建设方案
一、建设背景 随着物联网技术的迅猛发展和广泛应用,物联网产业已跃升为新时代的经济增长引擎,对于产业升级和社会信息化水平的提升具有举足轻重的地位。因此,为了满足这一领域的迫切需求,培养具备物联网技术应用能力的优秀人才成…...

SOLIDWORKS 2025更灵活零件建模
SOLIDWORKS 2025更灵活零件建模 北京众联亿诚是达索官方授权的SOLIDWORKS经销商,专业经销SOLIDWORKS正版软件并提供免费试用、培训认证、二次开发等增值服务。 在工程设计领域,SOLIDWORKS作为一款功能强大的三维CAD软件,一直以其优越的性能…...

智能巡检机器人的大模型训练
随着工业自动化和智能化进程的不断加快,智能巡检机器人已成为维护和管理复杂设备的重要工具。在电力、石油化工、煤矿、数据中心等行业中,智能巡检机器人通过自主巡检、故障检测等功能,提高了设备管理的效率和安全性。大模型训练在智能巡检机…...

RabbitMQ系列学习笔记(九)--路由模式
文章目录 一、路由模式原理二、多重绑定三、路由模式实战1、消费者代码2、生产者代码3、运行结果分析 本文参考 尚硅谷RabbitMQ教程丨快速掌握MQ消息中间件rabbitmq RabbitMQ 详解 Centos7环境安装Erlang、RabbitMQ详细过程(配图) 一、路由模式原理 使用发布订阅模式时&#x…...

[OS] pthreads-1
线程的基本概念 线程是进程中的一个单一的执行流。一个进程可以包含多个线程,这些线程共享进程中的资源,并且在相同的地址空间中执行。多线程是提高应用程序并行性的流行方法。例如,在浏览器中,不同的标签页可以视作独立的线程。…...

ThreeJS入门(137):THREE.StringKeyframeTrack 知识详解,示例代码
作者: 还是大剑师兰特 ,曾为美国某知名大学计算机专业研究生,现为国内GIS领域高级前端工程师,CSDN知名博主,深耕openlayers、leaflet、mapbox、cesium,webgl,ThreeJS,canvas…...

用大模型或者向量模型比如huggingface上的模型,处理一批图片,对该图片进行分类,检索
要使用大模型或向量模型对图片进行分类和检索,通常可以采用以下几种方法: 1. **图像分类**:使用预训练的图像分类模型(如ResNet、EfficientNet等)对图片进行分类。 2. **图像特征提取**:使用预训练的模型(如CLIP、ResNet等)提取图像的特征向量,然后进行相似度检索。 …...

Mac 使用 zsh 终端提示 zsh: killed 的问题
我的脚本的内容为: #!/bin/bashset -epids$(ps -ef | grep consul | grep -v grep | awk {print $2})for pid in $pids; doecho "kill process: $pid"kill -9 $pid donecd $(dirname $0)nohup ./consul agent -dev > nohup.log &可以看到这是一个…...

数字后端零基础入门系列 | Innovus零基础LAB学习Day6
今天没有具体的数字IC后端lab实验。今天的重点是熟悉掌握静态时序分析STA中的几类timing path以及setup和hold检查机制(包含setup和hold计算公式)。 芯片流片失败的那些故事 数字后端零基础入门系列 | Innovus零基础LAB学习Day5 等大家把今天内容学习…...

(Linux驱动学习 -13).SPI驱动实验
目录 一.SPI驱动相关结构体与函数 1.struct spi_master 结构体 2.申请 spi_master - spi_alloc_master 3.释放 spi_master - spi_master_put 4.向内核注册 spi_master - spi_register_master 5.注销掉 spi_master 6.struct spi_driver 结构体 7.向内核注册 spi_driver -…...

Angular 框架入门教程:从安装到路由、服务与状态管理详解
一、引言 在前端开发领域,Angular 是一个强大且流行的框架。它由 Google 维护,基于 TypeScript,采用模块化设计,提供了组件化开发、依赖注入、路由、表单处理等丰富功能,旨在帮助开发者构建高效、可维护的单页应用程序…...

【华为HCIP实战课程十八】OSPF的外部路由类型,网络工程师
一、外部路由类型: 上节讲的外部路由类型,无关乎COST大小,OSPF外部路由类型1优先于外部路由类型2 二、转发地址实验拓扑 我们再SW3/R5/R6三台设备运行RIP,SW3即运行RIP又运行OSPF SW3配置rip [SW3-rip-1]ver 2 [SW3-rip-1]network 10.0.0.0 AR5去掉ospf配置和AR6配置rip…...
)
oss 简单命令(已亲测)
1、 服务器本地文件复制到OSS指定目录 ./ossutil cp -r /opt/post/afc/afcServer/afcenter/logs/ oss://oss-name/ScBak/20230608/ -c /opt/post/ossconfig 2、在oss服务器上创建文件夹 ./ossutil mkdir oss://oss-name/ScBak/20230608/dam -c /opt/post/ossconfig 3、查…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...